为了提升消息接收和发送性能,Netty 针对 ByteBuf 的申请和释放采用了池化技术,通过 PooledByteBufAllocator 可以创建基于内存池分配的 ByteBuf 对象,这样就避免了每次消息读写都申请和释放ByteBuf,这样很大程度减少了 GC 的次数,对性能提升是非常可观的。
PoolChunk内存分配
模拟内存数据结构
为了能够简单的操作内存,必须保证每次分配到的内存时连续的。Netty 中底层的内存分配和回收管理主要由 PoolChunk 实现,其内部维护一棵平衡二叉树 MemoryMap,所有子节点管理的内存也属于其父节点。每当申请超过 8KB 内存时,就会从 PoolChunk 获取。
//memoryMap初始化
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) { // move down the tree one level at a time
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
// in each level traverse left to right and set value to the depth of subtree
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}下图是 MemoryMap 的抽象表示
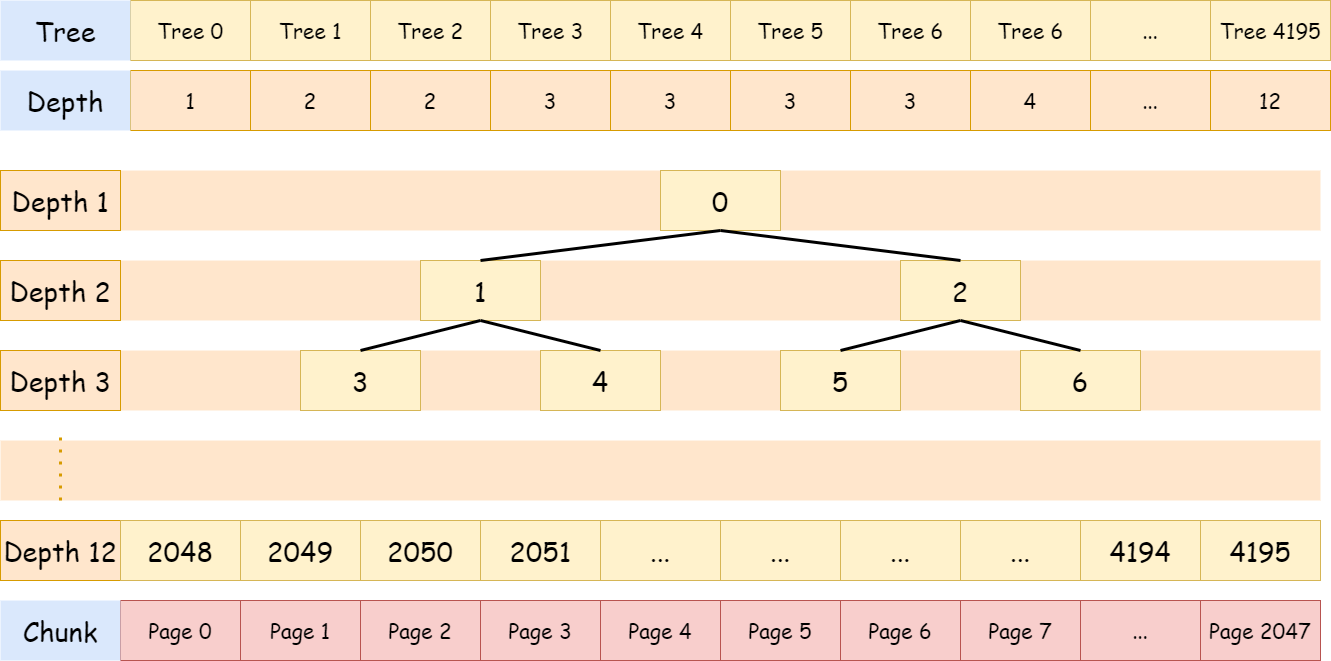
PoolChunk 默认由 2048 个 Page 组成,一个 Page 默认大小为 8k,图中树节点的值为在数组 memoryMap 的下标。
分配内存
向PoolChunk分配内存
PoolChunk 内部会保证每次分配内存大小为8K*(2^n),为了分配一个大小为chunkSize/(2^k)的节点,需要在深度为 k 的层从左开始匹配节点,下面是申请内存的大概流程:
- 如果需要分配大小 8k 的内存,则只需要在第11层,找到一个可用节点即可
- 如果需要分配大小 16k 的内存,则只需要在第10层,找到一个可用节点即可
- 如果节点 1024 存在一个已经被分配的子节点 2048,则该节点不能被分配,如需要分配大小 16k 的内存,这个时候节点 2048 已被分配,节点 2049 未被分配,就不能直接分配节点 1024,因为该节点目前只剩下 8k 内存。
需要说明的是,寻找合适内存的行为是基于深度优先算法的,但是对子节点的选取上是采用的随机选取,而不是常用的依次遍历。
申请后更新节点层级
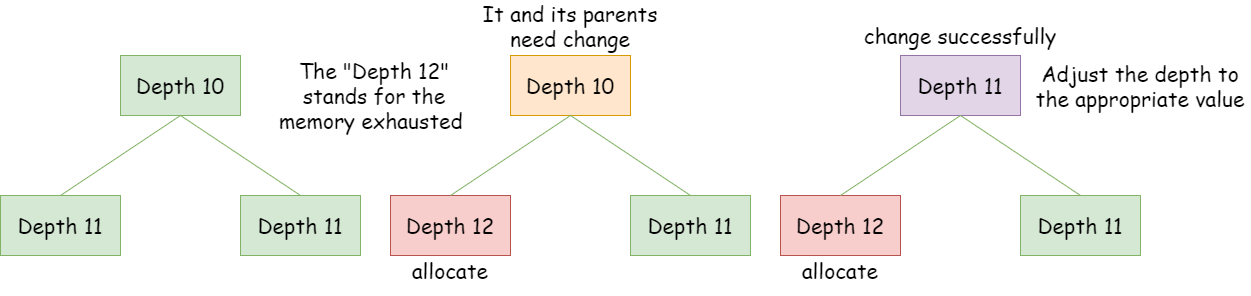
释放内存
也就是释放相应资源并且根据申请内存过程的原理对节点及其父节点值进行更新。
对节点状态的维护
无论是 Chunk 还是 Page,都通过状态位来标识内存是否可用,不同之处是 Chunk 通过在二叉树上对节点进行标识实现,Page 是通过维护块的使用状态标识来实现。
PoolSubPage内存分配
在 PoolChunk 中支持分配一块大于 pageSize 的内存,但在实际应用中,存在很多分配小内存的情况,如果也占用一个 page,明显很浪费。针对这种情况,Netty 提供了 PoolSubpage 把 PoolChunk 的一个 page 节点 8k 内存划分成更小的内存段,通过对每个内存段的标记与清理标记进行内存的分配与释放。
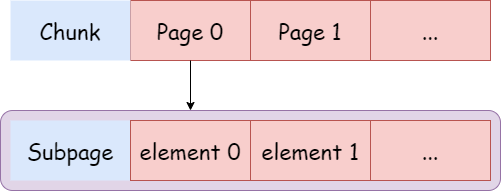
Page 中存储区域的使用状态通过一个 long 数组来维护,数组中每个 long 的每一位表示一个块存储区域的占用情况:0 表示未占用,1 表示以占用。对于一个 4 字节的 Page 来说,如果这个 Page 用来分配 1 个字节的存储区域,那么 long 数组中就只有一个 long 类型的元素,这个数值的低 4 位用来指示各个存储区域的占用情况。对于一个 128 字节的 Page 来说,如果这个 Page 也是用来分配 1 个字节的存储区域,那么 long 数组中就会包含 2 个元素,总共 128 位,每一位代表一个区域的占用情况。
申请Subpage空间
final class PoolSubpage<T> {
// 当前page在chunk中的id
private final int memoryMapIdx;
// 当前page在chunk.memory的偏移量
private final int runOffset;
// page大小
private final int pageSize;
//通过对每一个二进制位的标记来修改一段内存的占用状态
private final long[] bitmap;
PoolSubpage<T> prev;
PoolSubpage<T> next;
boolean doNotDestroy;
// 该page切分后每一段的大小
int elemSize;
// 该page包含的段数量
private int maxNumElems;
private int bitmapLength;
// 下一个可用的位置
private int nextAvail;
// 可用的段数量
private int numAvail;
...
}假设目前需要申请大小为4096的内存:
//PoolChunk
long allocate(int normCapacity) {
int firstVal = memoryMap[1];
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
return allocateRun(normCapacity, 1, firstVal);
} else {
return allocateSubpage(normCapacity, 1, firstVal);
}
}因为4096<pageSize(8192),所以采用 allocateSubpage 进行内存分配,具体实现如下:
private long allocateSubpage(int normCapacity, int curIdx, int val) {
int state = val & 3;
if (state == ST_BRANCH) {
int nextIdx = curIdx << 1 ^ nextRandom();
long res = branchSubpage(normCapacity, nextIdx);
if (res > 0) {
return res;
}
return branchSubpage(normCapacity, nextIdx ^ 1);
}
if (state == ST_UNUSED) {
return allocateSubpageSimple(normCapacity, curIdx, val);
}
if (state == ST_ALLOCATED_SUBPAGE) {
PoolSubpage<T> subpage = subpages[subpageIdx(curIdx)];
int elemSize = subpage.elemSize;
if (normCapacity != elemSize) {
return -1;
}
return subpage.allocate();
}
return -1;
}Subpage的初始化
//memoryMapIdx 当前page在chunk中的id
//runOffset 当前page在chunk.memory的偏移量
//pageSize page大小
//elemSize page切分后的elem大小
PoolSubpage(PoolChunk<T> chunk, int memoryMapIdx, int runOffset, int pageSize, int elemSize) {
this.chunk = chunk;
this.memoryMapIdx = memoryMapIdx;
this.runOffset = runOffset;
this.pageSize = pageSize;
//默认初始化bitmap长度为8
//其中分配内存大小都是处理过的,最小为16,说明一个page可以分成 8192/16 = 512 个内存段,
//一个long有64位,可以描述64个内存段,这样只需要 512/64 = 8 个long就可以描述全部内存段了
bitmap = new long[pageSize >>> 10]; // pageSize / 16 / 64
//init根据当前需要分配的内存大小,确定需要多少个bitmap元素
init(elemSize);
}
void init(int elemSize) {
doNotDestroy = true;
this.elemSize = elemSize;
if (elemSize != 0) {
maxNumElems = numAvail = pageSize / elemSize;
nextAvail = 0;
//结合上面所述的理论
//通过 maxNumElems / 64 计算出需要多少个 long 来容纳内存块数量
bitmapLength = maxNumElems >>> 6;
//计算值低于64的情况,一个long就可以容纳
if ((maxNumElems & 63) != 0) {
bitmapLength ++;
}
for (int i = 0; i < bitmapLength; i ++) {
bitmap[i] = 0;
}
}
addToPool();
}下面通过分布申请 4096 和 32 大小的内存,说明如何确定 bitmapLength 的值:
- 比如,当前申请大小 4096 的内存,maxNumElems 和 numAvail 为2,说明一个 page 被拆分成 2 个内存段,2 >>> 6 = 0,且 2 & 63 != 0,所以 bitmapLength 为 1,说明只需要一个 long 就可以描述 2 个内存段状态。
- 如果当前申请大小32的内存,maxNumElems 和 numAvail 为 256,说明一个 page 被拆分成 256 个内存段, 256 >>> 6 = 4,说明需要 4 个 long 描述 256 个内存段状态。
内存分配
long allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
//找到下一个可分配的坐标
final int bitmapIdx = nextAvail;
//确定 bitmap 的索引
int q = bitmapIdx >>> 6;
//将超出64的那一部分二进制数抹掉,得到一个小于64的数r
int r = bitmapIdx & 63;
assert (bitmap[q] >>> r & 1) == 0;
//将对应位置q设置为1
bitmap[q] |= 1L << r;
if (-- numAvail == 0) {
removeFromPool();
nextAvail = -1;
} else {
//更新当前page中下一个可分配内存段
nextAvail = findNextAvailable();
}
return toHandle(bitmapIdx);
}
private int findNextAvailable() {
int newNextAvail = -1;
loop:
for (int i = 0; i < bitmapLength; i ++) {
long bits = bitmap[i];
//~bits != 0 说明这个long所描述的64个内存段还有未分配的
if (~bits != 0) {
for (int j = 0; j < 64; j ++) {
//遍历bits每一位,找到可用的一位
if ((bits & 1) == 0) {
newNextAvail = i << 6 | j;
break loop;
}
bits >>>= 1;
}
}
}
if (newNextAvail < maxNumElems) {
return newNextAvail;
} else {
return -1;
}
}PoolChunkList内存管理
PoolChunkList 负责管理多个 chunk 的生命周期,在此基础上对内存分配进行进一步的优化。
final class PoolChunkList<T> implements PoolChunkListMetric {
private final PoolArena<T> arena;
private final PoolChunkList<T> nextList;
PoolChunkList<T> prevList;
private final int minUsage;
private final int maxUsage;
private PoolChunk<T> head;
...
}每个 PoolChunkList 实例维护了一个 PoolChunk 链表,自身也形成一个链表,为何要这么实现?
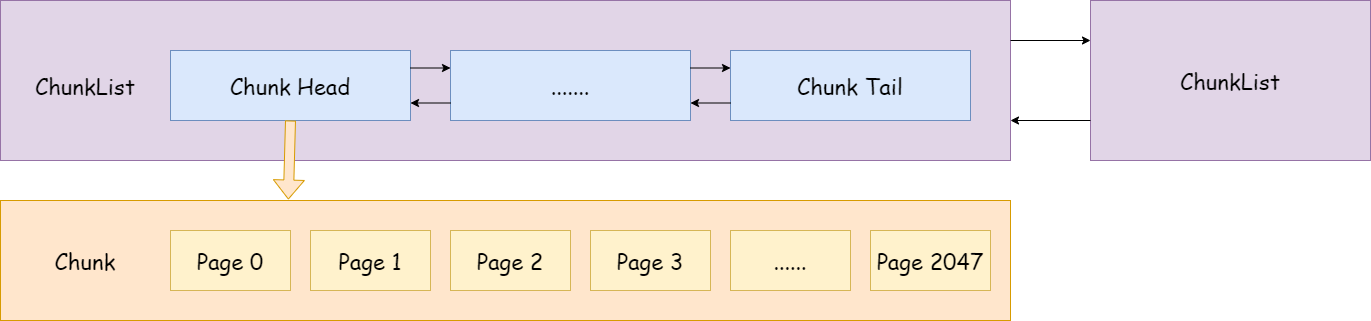
随着 chunk 中 page 的不断分配和释放,会导致很多碎片内存段,大大增加了之后分配一段连续内存的失败率,针对这种情况,可以把内存使用率超过 maxUsage 的 chunk 移动到下一个 PoolChunkList 链表
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null) {
return false;
}
for (PoolChunk<T> cur = head;;) {
long handle = cur.allocate(normCapacity);
if (handle < 0) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur);
}
return true;
}
}
}但是,随着 chunk 中内存的释放,其内存使用率也会随着下降,当下降到 minUsage 时,该 chunk 会移动到前一个列表中
void free(PoolChunk<T> chunk, long handle) {
chunk.free(handle);
if (chunk.usage() < minUsage) {
remove(chunk);
if (prevList == null) {
assert chunk.usage() == 0;
arena.destroyChunk(chunk);
} else {
prevList.add(chunk);
}
}
}从 poolChunkList 的实现可以看出,每个 chunkList 的都有一个上下限:minUsage 和 maxUsage,两个相邻的 chunkList,前一个的 maxUsage 和后一个的 minUsage 必须有一段交叉值进行缓冲,否则会出现某个 chunk 的 usage 处于临界值,而导致不停的在两个 chunk 间移动。
所以 chunk 的生命周期不会固定在某个 chunkList 中,随着内存的分配和释放,根据当前的内存使用率,在 chunkList 链表中前后移动。
PoolArena内存管理
Arena 本身是指一块区域,在内存管理中,Memory Arena 是指内存中的一大块连续的区域,PoolArena 就是 Netty 内存池实现类。
为了集中管理内存的分配和释放,同时提高分配和释放内存时候的性能,很多框架和应用都会通过预先申请一大块内存,然后通过提供相应的分配和释放接口来使用内存。这样一来,对内存的管理就被集中到几个类或者函数中,由于不再频繁使用系统调用来申请和释放内存,应用或者系统的性能也会大大提高。在这种设计思路下,预先申请的那一大块内存就被称为 Memory Arena。
不同的框架,Memory Arena 的实现不同,Netty 的 PoolArena 是由多个 Chunk 组成的大块内存区域,而每个 Chunk 则由一个或者多个 Page 组成,因此,对内存的组织和管理也就主要集中在如何管理和组织 Chunk 和 Page 了。
应用层的内存分配主要通过如下实现,但最终还是委托给 PoolArena 实现。
PooledByteBufAllocator.DEFAULT.directBuffer(128);由于 Netty 通常应用于高并发系统,不可避免的有多线程进行同时内存分配,可能会极大的影响内存分配的效率,为了缓解线程竞争,可以通过创建多个 PoolArena 细化锁的粒度,提高并发执行的效率。
PoolArena 的内部结构
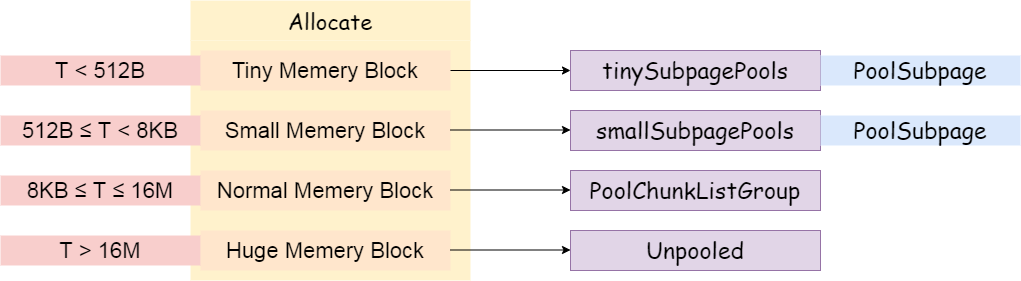
poolArena提供了两种方式进行内存分配
PoolSubpage用于分配小于8k的内存
tinySubpagePools
用于分配小于512字节的内存,默认长度为32,因为内存分配最小为16,每次增加16,直到512,区间[16,512)一共有32个不同值
smallSubpagePools
用于分配大于等于512字节的内存,默认长度为4
poolChunkList用于分配大于8k的内存
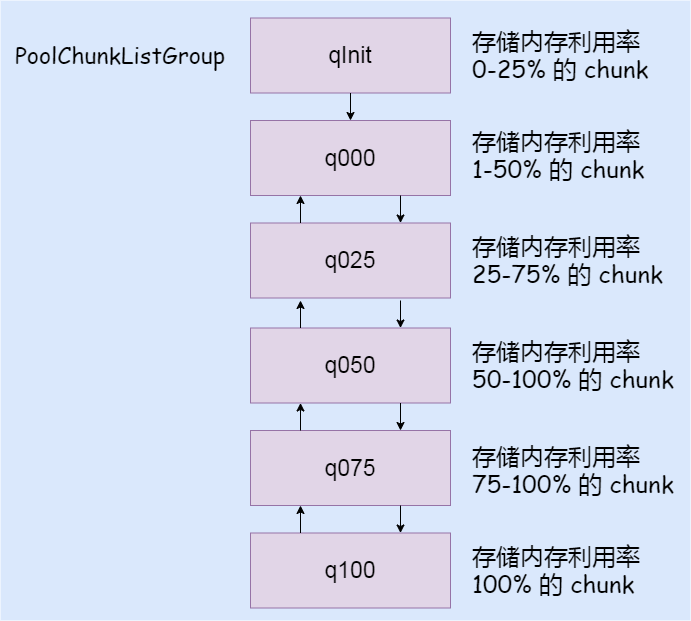
注意
qInit 前置节点为自己,且 minUsage=Integer.MIN_VALUE,意味着一个初分配的 chunk,在最开始的内存分配过程中(内存使用率<25%),即使完全释放也不会被回收,会始终保留在内存中
q000没有前置节点,当一个chunk进入到q000列表,如果其内存被完全释放,则不再保留在内存中,其分配的内存被完全回收
poolArena内存分配
默认先尝试从 poolThreadCache 中分配内存,PoolThreadCache 利用 ThreadLocal 的特性,消除了多线程竞争,提高内存分配效率;首次分配时,poolThreadCache 中并没有可用内存进行分配,当上一次分配的内存使用完并释放时,会将其加入到 poolThreadCache 中,提供该线程下次申请时使用。
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if ((normCapacity & subpageOverflowMask) == 0) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
if ((normCapacity & 0xFFFFFE00) == 0) { // < 512
tableIdx = normCapacity >>> 4;
table = tinySubpagePools;
} else {
tableIdx = 0;
int i = normCapacity >>> 10;
while (i != 0) {
i >>>= 1;
tableIdx ++;
}
table = smallSubpagePools;
}
synchronized (this) {
final PoolSubpage<T> head = table[tableIdx];
final PoolSubpage<T> s = head.next;
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
long handle = s.allocate();
assert handle >= 0;
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
return;
}
}
} else if (normCapacity > chunkSize) {
allocateHuge(buf, reqCapacity);
return;
}
allocateNormal(buf, reqCapacity, normCapacity);
}allocateNormal实现
private synchronized void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) || q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) || qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity) || q100.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
long handle = c.allocate(normCapacity);
assert handle > 0;
c.initBuf(buf, handle, reqCapacity);
qInit.add(c);
}第一次进行内存分配时,chunkList 没有 chunk 可以分配内存,需通过方法 newChunk 新建一个 chunk 进行内存分配,并添加到 qInit 列表中。如果分配如 512 字节的小内存,除了创建 chunk,还有创建 subpage, PoolSubpage 在初始化之后,会添加到 smallSubpagePools 中,其实并不是直接插入到数组,而是添加到 head 的 next 节点。下次再有分配 512 字节的需求时,直接从 smallSubpagePools 获取对应的 subpage 进行分配。
分配内存时,为什么不从内存使用率较低的q000开始?
当应用在实际运行过程中,碰到访问高峰,这时需要分配的内存是平时的好几倍,当然也需要创建好几倍的 chunk,如果先从 q000 开始,这些在高峰期创建的 chunk 被回收的概率会大大降低,延缓了内存的回收进度,造成内存使用的浪费。
而 q050 保存的是内存利用率 50%~100% 的 chunk,应该是个折中的选择!这样大部分情况下,chunk 的利用率都会保持在一个较高水平,提高整个应用的内存利用率;qInit 的 chunk 利用率低,但不会被回收;q075 和 q100 由于内存利用率太高,导致内存分配的成功率大大降低,因此放到最后。