Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。Lambda 表达式增强了集合库。Java SE 8 添加了2个对集合数据进行批量操作的包:java.util.function包以及java.util.stream包。流(Stream)就如同迭代器,但附加了许多额外的功能,能让原先复杂的代码变得简洁而优雅,这无疑得到了一些人的青睐。Lambda 表达式的本质只是一个”语法糖”,由编译器推断并帮你转换包装为常规的代码,因此你可以使用更少的代码来实现同样的功能。但随之而来的问题是难以调试。
接口、注解与函数注解
Interface接口
以下为 Interface 的特性
//**之间的关键字为interface默认增加的关键字
public interface Test {
//接口成员变量
*public static final* String CONSTANT = "CONSTANT";
//对于无方法体的接口函数,实现类必须实现
*public abstract* void a();
//对于静态方法则必须拥有方法体,可直接通过Test.b()调用该方法
*public* static void b(){
//Function Body
}
//对于默认方法必须拥有方法体,不强制重写,也不影响已有实现类
*public* default void c() {
//Function Body
}
}Annotation注解
从JVM的角度看,注解本身对代码逻辑没有任何影响,如何使用注解完全由工具决定。
注解基本介绍
Java注解的分类
编译器使用的注解(不会被编译进入
.class文件)例: @Override //编译器检查该方法是否正确地实现了覆写; @SuppressWarnings //告诉编译器忽略此处代码产生的警告。工具处理
.class文件使用的注解比如有些工具会在加载class的时候,对class做动态修改,实现一些特殊的功能。这类注解会被编译进入
.class文件,但加载结束后并不会存在于内存中。这类注解只被一些底层库使用,一般我们不必自己处理。程序运行期能够读取的注解
它们在加载后一直存在于JVM中,这也是最常用的注解。例如,一个配置了
@PostConstruct的方法会在调用构造方法后自动被调用(这是Java代码读取该注解实现的功能,JVM并不会识别该注解)。
定义注解的配置参数
- 所有基本类型;
- String;
- 枚举类型
因为配置参数必须是常量,所以,上述限制保证了注解在定义时就已经确定了每个参数的值。注解的配置参数可以有默认值,缺少某个配置参数时将使用默认值。如果参数名称是value,且只有一个参数,那么可以省略参数名称。
注解的特性
//**之间的关键字为interface默认增加的关键字
public @interface Test {
*public* int value();
*public* String name() default "Test";
*public* Class<?> clazz() default Test.class;
}注解的参数类似无参数方法,可以用default设定一个默认值(强烈推荐)。最常用的参数应当命名为value。
元注解
有一些注解可以修饰其他注解,这些注解就称为元注解(meta annotation)。Java标准库已经定义了一些元注解。
@Target
最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
- 类或接口:
ElementType.TYPE; - 字段:
ElementType.FIELD; - 方法:
ElementType.METHOD; - 构造方法:
ElementType.CONSTRUCTOR; - 方法参数:
ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
@Target(ElementType.METHOD)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}定义注解@Report可用在方法或字段上,可以把@Target注解参数变为数组{ ElementType.METHOD, ElementType.FIELD }:
@Target({
ElementType.METHOD,
ElementType.FIELD
})
public @interface Report {
...
}实际上@Target定义的value是ElementType[]数组,只有一个元素时,可以省略数组的写法。
@Retention
另一个重要的元注解@Retention定义了Annotation的生命周期:
- 仅编译期:
RetentionPolicy.SOURCE; - 仅class文件:
RetentionPolicy.CLASS; - 运行期:
RetentionPolicy.RUNTIME。
如果@Retention不存在,则该Annotation默认为CLASS。因为通常我们自定义的Annotation都是RUNTIME,所以,务必要加上@Retention(RetentionPolicy.RUNTIME)这个元注解:
@Retention(RetentionPolicy.RUNTIME)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}@Repeatable
使用@Repeatable这个元注解可以定义Annotation是否可重复。这个注解应用不是特别广泛。
@Repeatable(Reports.class)
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}
@Target(ElementType.TYPE)
public @interface Reports {
Report[] value();
}经过@Repeatable修饰后,在某个类型声明处,就可以添加多个@Report注解:
@Report(type=1, level="debug")
@Report(type=2, level="warning")
public class Hello {
}@Inherited
使用@Inherited定义子类是否可继承父类定义的Annotation。@Inherited仅针对@Target(ElementType.TYPE)类型的annotation有效,并且仅针对class的继承,对interface的继承无效:
@Inherited
@Target(ElementType.TYPE)
public @interface Report {
int type() default 0;
String level() default "info";
String value() default "";
}在使用的时候,如果一个类用到了@Report:
@Report(type=1)
public class Parent {
}则它的子类默认也定义了该注解:
public class Child extends Parent {
}读取注解
Java的注解本身对代码逻辑没有任何影响。根据@Retention的配置:
SOURCE类型的注解在编译期就被丢掉了;CLASS类型的注解仅保存在class文件中,它们不会被加载进JVM;RUNTIME类型的注解会被加载进JVM,并且在运行期可以被程序读取。
如何使用注解完全由工具决定。SOURCE类型的注解主要由编译器使用,因此我们一般只使用,不编写。CLASS类型的注解主要由底层工具库使用,涉及到class的加载,一般我们很少用到。只有RUNTIME类型的注解不但要使用,还经常需要编写。
因此,我们只讨论如何读取RUNTIME类型的注解。
因为注解定义后也是一种class,所有的注解都继承自java.lang.annotation.Annotation,因此,读取注解,需要使用反射API。
Java提供的使用反射API读取Annotation的方法包括:
判断某个注解是否存在于Class、Field、Method或Constructor:
Class.isAnnotationPresent(Class)Field.isAnnotationPresent(Class)Method.isAnnotationPresent(Class)Constructor.isAnnotationPresent(Class)
例如:
// 判断@Report是否存在于Person类:
Person.class.isAnnotationPresent(Report.class);使用反射API读取Annotation:
Class.getAnnotation(Class)Field.getAnnotation(Class)Method.getAnnotation(Class)Constructor.getAnnotation(Class)
例如:
// 获取Person定义的@Report注解:
Report report = Person.class.getAnnotation(Report.class);
int type = report.type();
String level = report.level();使用反射API读取Annotation有两种方法。方法一是先判断Annotation是否存在,如果存在,就直接读取:
Class cls = Person.class;
if (cls.isAnnotationPresent(Report.class)) {
Report report = cls.getAnnotation(Report.class);
...
}第二种方法是直接读取Annotation,如果Annotation不存在,将返回null:
Class cls = Person.class;
Report report = cls.getAnnotation(Report.class);
if (report != null) {
...
}读取方法、字段和构造方法的Annotation和Class类似。但要读取方法参数的Annotation就比较麻烦一点,因为方法参数本身可以看成一个数组,而每个参数又可以定义多个注解,所以,一次获取方法参数的所有注解就必须用一个二维数组来表示。例如,对于以下方法定义的注解:
public void hello(@NotNull @Range(max=5) String name, @NotNull String prefix) {
}要读取方法参数的注解,我们先用反射获取Method实例,然后读取方法参数的所有注解:
// 获取Method实例:
Method m = ...
// 获取所有参数的Annotation:
Annotation[][] annos = m.getParameterAnnotations();
// 第一个参数(索引为0)的所有Annotation:
Annotation[] annosOfName = annos[0];
for (Annotation anno : annosOfName) {
if (anno instanceof Range) { // @Range注解
Range r = (Range) anno;
}
if (anno instanceof NotNull) { // @NotNull注解
NotNull n = (NotNull) anno;
}
}使用注解
注解如何使用,完全由程序自己决定。例如,JUnit是一个测试框架,它会自动运行所有标记为@Test的方法。
我们来看一个@Range注解,我们希望用它来定义一个String字段的规则:字段长度满足@Range的参数定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
public @interface Range {
int min() default 0;
int max() default 255;
}在某个JavaBean中,我们可以使用该注解:
public class Person {
@Range(min=1, max=20)
public String name;
@Range(max=10)
public String city;
}但是,定义了注解,本身对程序逻辑没有任何影响。我们必须自己编写代码来使用注解。这里,我们编写一个Person实例的检查方法,它可以检查Person实例的String字段长度是否满足@Range的定义:
void check(Person person) throws IllegalArgumentException, ReflectiveOperationException {
//遍历所有Field
for (Field field : person.getClass().getFields()) {
//获取Field定义的@Range
Range range = field.getAnnotation(Range.class);
//如果@Range存在
if (range != null) {
//获取Field的值
Object value = field.get(person);
//如果值是String
if (value instanceof String) {
String s = (String) value;
//判断值是否满足@Range的min/max
if (s.length() < range.min() || s.length() > range.max()) {
throw new IllegalArgumentException("Invalid field: " + field.getName());
}
}
}
}
}这样一来,我们通过@Range注解,配合check()方法,就可以完成Person实例的检查。注意检查逻辑完全是我们自己编写的,JVM不会自动给注解添加任何额外的逻辑。
带FunctionalInterface注解的接口
注为 FunctionalInterface 的接口被称为函数式接口。java.util.function包下,有许多默认的函数式接口。是否让编译器认为这就是一个函数式接口,需要注意的有以下几点:
- 该注解只能标记在”有且仅有一个抽象方法”的接口上。
- JDK8接口中的静态方法和默认方法,都不算是抽象方法。
- 接口默认继承java.lang.Object,所以如果接口显示声明覆盖了Object中方法,那么也不算抽象方法。
- 该注解不是必须的,如果一个接口符合”函数式接口”定义,那么加不加该注解都没有影响。加上该注解能够更好地让编译器进行检查。如果编写的不是函数式接口,但是加上了@FunctionInterface,那么编译器会报错。
Supplier(生产者)
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}用法示例
static int printVal(Supplier<Integer> supplier) {
return supplier.get();
}
public static void main(String[] args) {
// val = 1 + 2 = 3
System.out.println(
printVal(() -> {
int a = 2, b = 3;
return a + b;
})
);
}Consumer(消费者)
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}accept 代码示例
class FunctionalInterfaceImplement {
static void printVal(Consumer<String> consumer) {
consumer.accept("Hello");
}
public static void main(String[] args) {
printVal(
s -> System.out.println(s)
);
}
}andThen 代码示例
class FunctionalInterfaceImplement {
static void printVal(Consumer<String> consumer1, Consumer<String> consumer2) {
consumer1.andThen(consumer2).accept("Hello");
}
public static void main(String[] args) {
printVal(
s -> System.out.println(s.toUpperCase()),
s -> System.out.println(s.toLowerCase())
);
}
}Predicate(判断者)
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
/**
* Returns a composed predicate that represents a short-circuiting logical
* AND of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code false}, then the {@code other}
* predicate is not evaluated.
*
* <p>Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ANDed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* AND of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
/**
* Returns a predicate that represents the logical negation of this
* predicate.
*
* @return a predicate that represents the logical negation of this
* predicate
*/
// negate 否定
default Predicate<T> negate() {
return (t) -> !test(t);
}
/**
* Returns a composed predicate that represents a short-circuiting logical
* OR of this predicate and another. When evaluating the composed
* predicate, if this predicate is {@code true}, then the {@code other}
* predicate is not evaluated.
*
* <p>Any exceptions thrown during evaluation of either predicate are relayed
* to the caller; if evaluation of this predicate throws an exception, the
* {@code other} predicate will not be evaluated.
*
* @param other a predicate that will be logically-ORed with this
* predicate
* @return a composed predicate that represents the short-circuiting logical
* OR of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
/**
* Returns a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}.
*
* @param <T> the type of arguments to the predicate
* @param targetRef the object reference with which to compare for equality,
* which may be {@code null}
* @return a predicate that tests if two arguments are equal according
* to {@link Objects#equals(Object, Object)}
*/
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}test 代码示例
class FunctionalInterfaceImplement {
static boolean printVal(String s, Predicate<String> predicate) {
return predicate.test(s);
}
public static void main(String[] args) {
System.out.println(
printVal(
"anc",
ele -> ele.length() > 5
)
);
}
}negate 代码示例
class FunctionalInterfaceImplement {
static boolean printVal(String s, Predicate<String> predicate) {
return predicate.negate().test(s);
}
public static void main(String[] args) {
System.out.println(
printVal(
"anc",
ele -> ele.length() > 5
)
);
}
}and/or 代码示例
class FunctionalInterfaceImplement {
static boolean printVal(String s, Predicate<String> p1,Predicate<String> p2) {
return p1.and(p2).test(s);
}
public static void main(String[] args) {
System.out.println(
printVal(
"anc",
ele -> ele.length() < 5,
ele -> ele.equals("anc")
)
);
}
}Function(转换者)
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
/**
* Returns a composed function that first applies the {@code before}
* function to its input, and then applies this function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of input to the {@code before} function, and to the
* composed function
* @param before the function to apply before this function is applied
* @return a composed function that first applies the {@code before}
* function and then applies this function
* @throws NullPointerException if before is null
*
* @see #andThen(Function)
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* Returns a composed function that first applies this function to
* its input, and then applies the {@code after} function to the result.
* If evaluation of either function throws an exception, it is relayed to
* the caller of the composed function.
*
* @param <V> the type of output of the {@code after} function, and of the
* composed function
* @param after the function to apply after this function is applied
* @return a composed function that first applies this function and then
* applies the {@code after} function
* @throws NullPointerException if after is null
*
* @see #compose(Function)
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* Returns a function that always returns its input argument.
*
* @param <T> the type of the input and output objects to the function
* @return a function that always returns its input argument
*/
static <T> Function<T, T> identity() {
return t -> t;
}
}apply 代码示例
class FunctionalInterfaceImplement {
static void printVal(String val, Function<Integer, Integer> function){
System.out.println(
function.apply(val)
);
}
public static void main(String[] args) {
printVal("12", val -> Integer.parseInt(val));
}
}Stream 流处理
Stream 机制是针对集合迭代器的增强。流允许你用声明式的方式处理数据集合。并且流也有以下特性:不存储数据、不会改变数据源、不可以重复使用。
对象流
由集合对象创建流。对支持流处理的对象调用stream()或parallelStream()。支持流处理的对象包括 Collection 集合及其子类
//Collection interface
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}由数组创建流。通过静态方法Arrays.stream()将数组转化为流
IntStream stream = Arrays.stream(new int[]{3, 2, 1});通过静态方法Stream.of() ,但是底层其实还是调用Arrays.stream()
Stream<Integer> stream = Stream.of(1, 2, 3);空流:Stream.empty()
无限流:Stream.generate()和Stream.iterate()。可以配合limit()使用可以限制一下数量
// 接受一个 Supplier 作为参数
Stream.generate(Math::random).limit(10).forEach(System.out::println);
// 初始值是 0,新值是前一个元素值 + 2
Stream.iterate(0, n -> n + 2).limit(10).forEach(System.out::println);数值流
Java8 有三个原始类型特化流接口:IntStream、LongStream、DoubleStream,分别将流中的元素特化为 int,long,double。普通对象流和原始类型特化流之间可以相互转化。
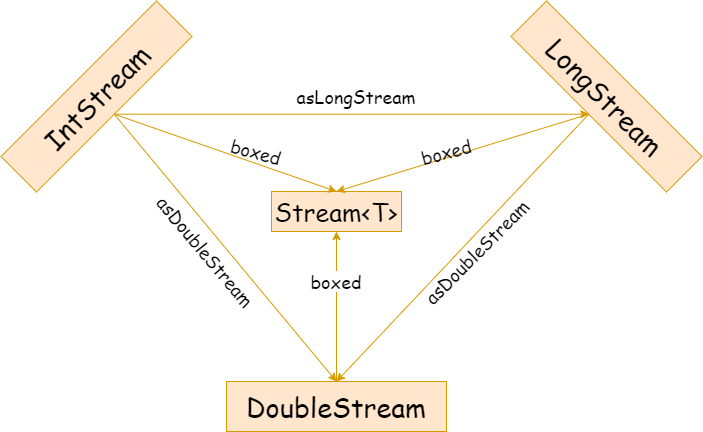
数值流可以根据边界创造流
IntStream.range(int startInclusive, int endExclusive);
IntStream.rangeClosed(int startInclusive, int endInclusive);流处理的操作类型
Stream 的所有操作连起来组合成了管道,管道有两种操作:
- 中间操作(intermediate)。调用中间操作方法返回的是一个新的流对象。
- 终值操作(terminal)。只有在调用终值方法后,将执行之前所有的中间操作,并返回结果。
| Stream 操作分类 | ||
|---|---|---|
| 中间操作 | 无状态 |
|
| 有状态 |
|
|
| 终值操作 | 非短路操作 |
|
| 短路操作 |
|
|
集合操作
Collector 被指定和四个函数一起工作,并实现累加 entries 到一个可变的结果容器,并可选择执行该结果的最终变换。 这四个函数就是:
| 接口函数 | 作用 | 返回值 |
|---|---|---|
| supplier() | 创建并返回一个新的可变结果容器 | Supplier |
| accumulator() | 把输入值加入到可变结果容器 | BiConsumer |
| combiner() | 将两个结果容器组合成一个 | BinaryOperator |
| finisher() | 转换中间结果为终值结果 | Function |
Collectors 则是重要的工具类,提供给我一些 Collector 实现。Stream 接口中 collect() 就是使用 Collector 做参数的。
Collectors.toList():转换成 List 集合。/ Collectors.toSet():转换成 Set 集合
Stream.of("a", "b", "c").collect(Collectors.toSet());Collectors.toCollection(TreeSet::new):转换成特定的集合
TreeSet<String> treeSet =
Stream.of("a", "c", "b").collect(Collectors.toCollection(TreeSet::new));Collectors.toMap(keyMapper, valueMapper, mergeFunction):转换成 Map
Map<String, String> collect =
Stream.of("a", "b", "c").collect(
Collectors.toMap(x -> x, x -> x + x, (oldVal, newVal) -> newVal))
);补充:关于合并函数
BinaryOperator<U> mergeFunction对象当 toMap 中没有用合并函数时,出现 key 重复时,会抛出异常 :
Exception in thread “main” java.lang.IllegalStateException: Duplicate key当使用合并函数时,可通过 Labmda表达式,对重复值进行处理
Collectors.minBy(Integer::compare):求最小值,相对应的当然也有maxBy方法。
Collectors.averagingInt(x -> x):求平均值,同时也有averagingDouble、averagingLong方法。
Collectors.summingInt(x -> x)):求和。
Collectors.summarizingDouble(x -> x):可以获取最大值、最小值、平均值、总和值、总数。
DoubleSummaryStatistics summaryStatistics = Stream.of(1, 3, 4)
.collect(Collectors.summarizingDouble(x -> x));
System.out.println(summaryStatistics.getAverage());Collectors.groupingBy(x -> x):有三种方法,查看源码可以知道前两个方法最终调用第三个方法,
第二个参数默认HashMap::new 第三个参数默认Collectors.toList()
//identity()是Function类的静态方法, 和 x -> x 是一个意思, 自己返回自己
Map<Integer, List<Integer>> map = Stream.of(1, 3, 3, 2)
.collect(Collectors.groupingBy(Function.identity()));
// {1=[1], 2=[2], 3=[3,3]}
Map<Integer, Integer> map = Stream.of(1, 3, 3, 2)
.collect(Collectors.groupingBy(Function.identity(), Collectors.summingInt(x -> x)));
// {1=[1], 2=[2], 3=[6]}
HashMap<Integer, List<Integer>> map = Stream.of(1, 3, 3, 2)
.collect(
Collectors.groupingBy(
Function.identity(),
HashMap::new,
Collectors.mapping(x -> x + 1, Collectors.toList())
)
);
// {1=[2], 2=[3], 3=[4, 4]}Collectors.partitioningBy(x -> x > 2),把数据分成两部分,key为ture/false。第一个方法也是调用第二个方法,第二个参数默认为Collectors.toList()
Map<Boolean, List<Integer>> map =
Stream.of(1, 3, 3, 2).collect(Collectors.partitioningBy(x -> x > 2));
Map<Boolean, Long> longMap =
Stream.of(1, 3, 3, 2)
.collect(Collectors.partitioningBy(x -> x > 1, Collectors.counting()));Collectors.joining(","):拼接字符串
Stream.of("1", "3", "3", "2").collect(Collectors.joining(","));Collectors.collectingAndThen(Collectors.toList(), x -> x.size()):先执行collect操作后再执行第二个参数的表达式。这里是先塞到集合,再得出集合长度。
Integer integer = Stream.of("1", "2", "3")
.collect(Collectors.collectingAndThen(Collectors.toList(), x -> x.size()));Collectors.mapping(...):跟 Stream 的 map 操作类似,只是参数有点区别
Stream.of(1, 3, 5).collect(Collectors.mapping(x -> x + 1, Collectors.toList()));规约操作
Optional<T> reduce(BinaryOperator<T> accumulator) 按规则累加(上一个的结果与当前数相加)
Stream.of(1, 2, 3, 4).reduce((x, y) -> x + y);
//1 + 2 + 3 + 4 = 10T reduce(T identity, BinaryOperator<T> accumulator);带初始值的累加
Stream.of(1, 2, 3, 4).reduce(10, (x, y) -> x + y);
//10(初始值) + 1 + 2 + 3 + 4 = 20<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);
第三个参数指当并行流被 fork join 出多个线程执行后,把线程执行结果当作流进行再次规约
Stream.of(1, 2, 3, 4).reduce(10, (x, y) -> x + y, (x, y) -> x * y);
//在串行流 第三个参数不起作用 10(初始值) + 1 + 2 + 3 + 4 = 20
Stream.of(1, 2, 3, 4).parallel().reduce(10, (x, y) -> x + y, (x, y) -> x + y)
//在并行流的执行结果 50(大概猜测为流拆成4线程,也就是 (10+1)+(10+2)+(10+3)+(10+4) = 50连接操作
生成的流包含第一个流的所有元素,后跟第二个流的所有元素。如果两个流中的任何一个是并行的,则生成的流将是并行的。
Stream.concat(stream1, stream2);