Redis 采用事件驱动机制来处理大量的网络 IO。它并没有使用 libevent 或者 libev 这样的成熟开源方案,而是自己实现一个非常简洁的事件驱动库 ae_event。Redis 基于事件驱动,来实现相应的事务机制。本文做了对应的源码解析并分析了不同场景下事务 ACID 的性质。
Redis事件调度
Redis中的事件驱动库只关注网络IO,以及定时器。该事件库处理下面两类事件:
- 文件事件(file event):用于处理 Redis 服务器和客户端之间的网络 IO。
- 时间事件(time eveat):Redis 服务器中的一些操作(比如 serverCron 函数)需要在给定的时间点执行,而时间事件就是处理这类定时操作的抽象。
文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器,也就是文件事件处理器。文件事件处理器采用了单线程方式运行,原因如下:
- Redis 是基于内存的,内存的读写速度非常快。因此 CPU 不是 Redis 的瓶颈,Redis 的瓶颈最有可能是机器内存的大小或者网络带宽。
- Redis 是单线程的,省去上下文切换线程的时间以及锁的性能消耗。
- Redis 使用 IO 多路复用模型,可以处理并发的连接,提升 IO 的效率。
- Redis 采用的单线程多进程集群的方案可以更好的利用每个核心的性能。
Redis 使用的IO多路复用技术主要有:select、epoll、evport和kqueue等。每个 IO 多路复用函数库在 Redis 源码中都对应一个单独的文件,比如 ae_select.c,ae_epoll.c,ae_kqueue.c 等。Redis 会根据不同的操作系统,按照不同的优先级选择多路复用技术。事件响应框架一般都采用该架构,比如 netty 和 libevent。
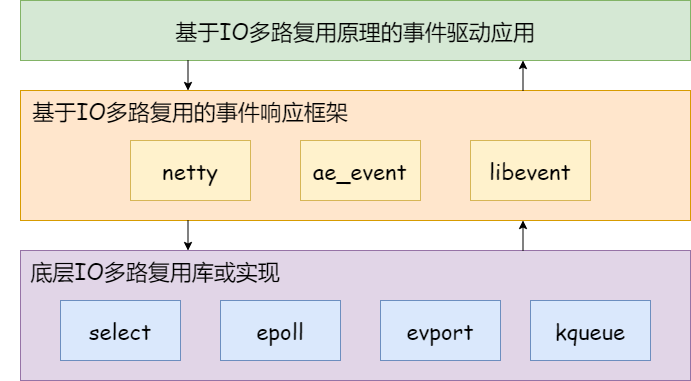
IO多路复用程序的实现
下图是文件事件处理器,它有四个组成部分,分别是套接字、I/O多路复用程序、文件事件分派器以及事件处理器。
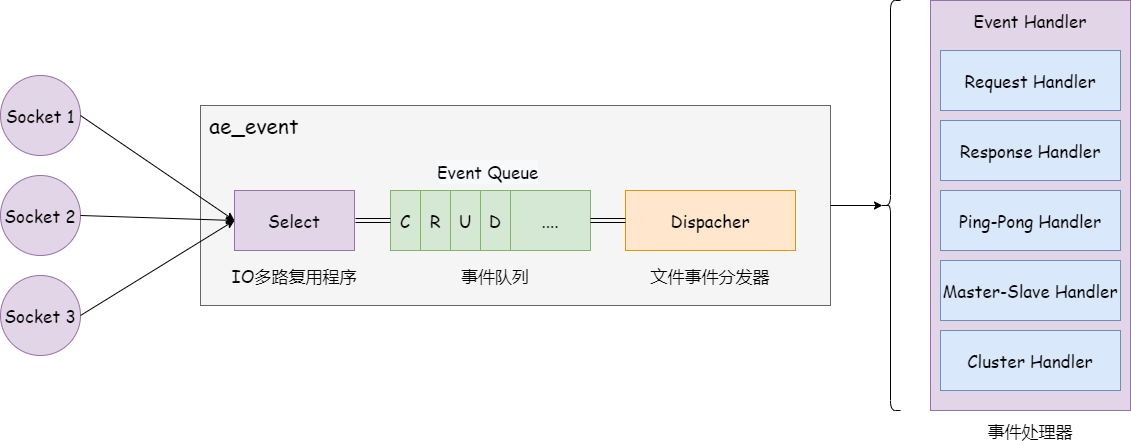
文件事件是对套接字操作的抽象,每当一个套接字准备好执行 accept、read、write 和 close 等操作时,就会产生一个文件事件。因为 Redis 通常会连接多个套接字,所以多个文件事件有可能并发的出现。IO 多路复用程序负责监听多个 Socket,并向文件事件派发器传递那些产生了事件的 Socket。
尽管多个文件事件可能会并发地出现,但 IO 多路复用程序会将所有待处理的事件都放到同一个队列(也就是后文中描述的aeEventLoop的fired就绪事件表)里边,然后文件事件处理器会以有序、同步、单 Socket 的方式处理该队列中的套接字,也就是处理就绪的文件事件。
文件事件的类型
IO 多路复用程序可以监听多个 Socket 的ae.h/AE_READABLE事件和ae.h/AE_WRITABLE事件,这两类事件和 Socket 操作之间的对应关系如下:
- 当 Socket 变得可读时(客户端对 Socket 执行 write 操作,或者执行 close 操作),或者有新的可应答 Socket 出现时(客户端对服务器的监听 Socket 执行 connect 操作), Socket 产生 AE READABLE 事件。
- 当 Socket 变得可写时(客户端对 Socket 执行 read 操作), Socket 产生 AE_WRITABLE 事件。
IO 多路复用程序允许服务器同时监听套接字的 AE_READABLE 事件和 AE_WRITABLE 事件,如果一个套接字同时产生了这两种事件,那么文件事件分派器会优先处理 AE_READABLE 事件。也就是说,如果一个 Socket 又可读又可写的话,那么服务器将先读 Socket,后写 Socket。
C/S之间事件处理过程
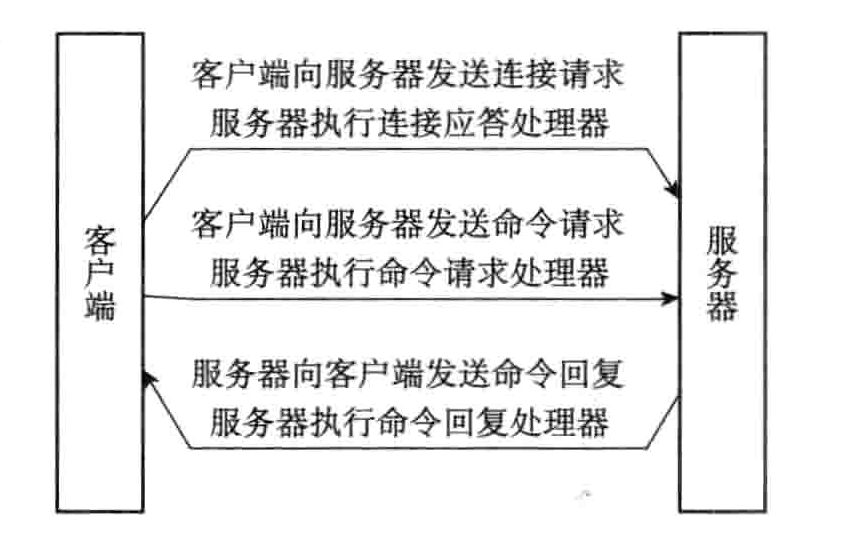
- 客户端向服务端发起建立 Socket 连接的请求,那么监听套接字将产生 AE_READABLE 事件,触发连接应答处理器执行。处理器会对客户端的连接请求进行应答,然后创建客户端 Socket,以及客户端状态,并将客户端套接字的 AE_READABLE 事件与命令请求处理器关联。
- 客户端建立连接后,向服务器发送命令,那么客户端 Socket 将产生 AE_READABLE 事件,触发命令请求处理器执行,处理器读取客户端命令,然后传递给相关程序去执行。
- 执行命令获得相应的命令回复,为了将命令回复传递给客户端,服务器将客户端 Socket 的 AE_WRITEABLE 事件与命令回复处理器关联。当客户端试图读取命令回复时,客户端 Socket 产生 AE_WRITEABLE 事件,触发命令回复处理器将命令回复全部写入到 Socket 中。
时间事件
下面为时间事件结构代码
typedef struct aeTimeEvent {
/* 全局唯一ID */
long long id; /* time event identifier. */
/* 秒精确的UNIX时间戳,记录时间事件到达的时间*/
long when_sec; /* seconds */
/* 毫秒精确的UNIX时间戳,记录时间事件到达的时间*/
long when_ms; /* milliseconds */
/* 时间处理器 */
aeTimeProc *timeProc;
/* 事件结束回调函数,析构一些资源*/
aeEventFinalizerProc *finalizerProc;
/* 私有数据 */
void *clientData;
/* 前驱节点 */
struct aeTimeEvent *prev;
/* 后继节点 */
struct aeTimeEvent *next;
} aeTimeEvent;时间事件的类型
- 定时事件:让一段程序在指定的时间之后执行一次。
- 周期性事件:让一段程序每隔指定时阃就执行一次。
实现逻辑
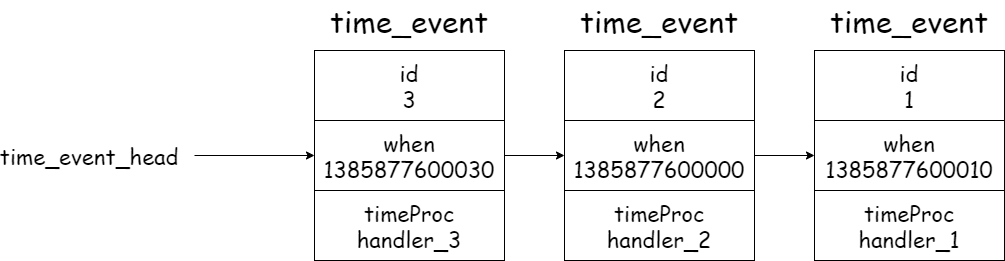
服务器将所有时间事件都放在一个无序链表中,每当时间事件执行器运行时,它就遍历整个链表,查找所有已到达的时间事件,并调用相应的事件处理器。
一个时间事件是定时事件还是周期性事件取决于时间处理器的返回值:
- 如果返回值是 AE_NOMORE,那么这个事件是一个定时事件,该事件在达到后删除,之后不会再重复
- 如果返回值是非 AE_NOMORE 的值,那么这个事件为周期性事件,当一个时间事件到达后,服务器会根据时间处理器的返回值,对时间事件的
when属性进行更新,让这个事件在一段时间后再次达到。
Redis 将所有时间事件都放在一个无序链表中,每次 Redis 会遍历整个链表,查找所有已经到达的时间事件,并且调用相应的事件处理器。注意,我们说保存时间事件的链表为无序链表,指的不是链表不按 ID 排序,而是说该链表不按 when 属性的大小排序。正因为链表没有按 when 属性进行排序,所以当时间事件执行器运行的时候,它必须遍历链表中的所有时间事件,这样才能确保服务器中所有已到达的时间事件都会被处理。
无序链表并不影响时间事件处理器的性能
在目前版本中,正常模式下的 Redis 服务器只使用 serverCron 一个时间事件,而在 benchmark 模式下,服务器也只使用两个时间事件。在这种情况下,服务器几乎是将无序链表退化成一个指针来使用,所以使用无序链表来保存时间事件,并不影响事件执行的性能。
serverCron
持续运行的 Redis 服务器需要定期对自身的资源和状态进行检查和调整,从而确保服务器可以长期、稳定地运行,这些定期操作由redis.c/serverCron函数负责执行,它的主要工作包括:
- 更新服务器的各类统计信息,比如时间、内存占用、数据库占用情况等。
- 清理数据库中的过期键值对。
- 关闭和清理连接失效的客户端。
- 尝试进行AOF或RDB持久化操作。
- 如果服务器是主服务器,那么对从服务器进行定期同步。
- 如果处于集群模式,对集群进行定期同步和连接测试。
Redis 服务器以周期性事件的方式来运行 serverCron 函数,在服务器运行期间,每隔一段时间,serverCron 就会执行一次,直到服务器关闭为止。
在 Redis 2.6 版本,服务器默认规定 serverCron 每秒运行 10 次,平均每间隔 100 毫秒运行一次。
从 Redis 2.8 开始,用户可以通过修改hz选项来调整 serverCron 的每秒执行次数。
由于 serverCron 文件事件和时间事件之间是合作关系,服务器会轮流处理这两种事件,并且处理事件的过程中也不会进行抢占。因此时间事件的实际处理时间通常会比设定的到达时间晚一些。
源码分析
创建事件管理器
Redis 服务端在其初始化函数 initServer中,会创建事件管理器aeEventLoop对象。
/* 函数 aeCreateEventLoop 将创建一个事件管理器 */
aeEventLoop *aeCreateEventLoop(int setsize) {
aeEventLoop *eventLoop;
int i;
/* 创建事件状态结构 */
if ((eventLoop = zmalloc(sizeof(*eventLoop))) == NULL) goto err;
/* 创建未就绪事件表、就绪事件表 */
eventLoop->events = zmalloc(sizeof(aeFileEvent)*setsize);
eventLoop->fired = zmalloc(sizeof(aeFiredEvent)*setsize);
if (eventLoop->events == NULL || eventLoop->fired == NULL) goto err;
/* 设置数组大小 */
eventLoop->setsize = setsize;
/* 初始化执行最近一次执行时间 */
eventLoop->lastTime = time(NULL);
/* 初始化时间事件结构 */
eventLoop->timeEventHead = NULL;
eventLoop->timeEventNextId = 0;
eventLoop->stop = 0;
eventLoop->maxfd = -1;
eventLoop->beforesleep = NULL;
eventLoop->aftersleep = NULL;
/* 将多路复用io与事件管理器关联起来 */
if (aeApiCreate(eventLoop) == -1) goto err;
/* 初始化监听事件 */
for (i = 0; i < setsize; i++)
eventLoop->events[i].mask = AE_NONE;
return eventLoop;
err:
.....
}static int aeApiCreate(aeEventLoop *eventLoop) {
aeApiState *state = zmalloc(sizeof(aeApiState));
if (!state) return -1;
/* 初始化epoll就绪事件表 */
state->events = zmalloc(sizeof(struct epoll_event)*eventLoop->setsize);
if (!state->events) {
zfree(state);
return -1;
}
/* 创建 epoll 实例 */
state->epfd = epoll_create(1024); /* 1024 is just a hint for the kernel */
if (state->epfd == -1) {
zfree(state->events);
zfree(state);
return -1;
}
/* 事件管理器与epoll关联 */
eventLoop->apidata = state;
return 0;
}
typedef struct aeApiState {
/* epoll_event 实例描述符*/
int epfd;
/* 存储epoll就绪事件表 */
struct epoll_event *events;
} aeApiState;aeApiState对象中epfd存储epoll的标识,events是一个epoll就绪事件数组,当有epoll事件发生时,所有发生的epoll事件和其描述符将存储在这个数组中。这个就绪事件数组由应用层开辟空间、内核负责把所有发生的事件填充到该数组。
创建文件事件
aeFileEvent是文件事件结构,对于每一个具体的事件,都有读处理函数和写处理函数等。Redis 调用aeCreateFileEvent函数针对不同的套接字的读写事件注册对应的文件事件。
typedef struct aeFileEvent {
/* 监听事件类型掩码,值可以是 AE_READABLE 或 AE_WRITABLE */
int mask;
/* 读事件处理器 */
aeFileProc *rfileProc;
/* 写事件处理器 */
aeFileProc *wfileProc;
/* 多路复用库的私有数据 */
void *clientData;
} aeFileEvent;
/* 使用typedef定义的处理器函数的函数类型 */
typedef void aeFileProc(struct aeEventLoop *eventLoop,
int fd, void *clientData, int mask);
比如说,Redis 进行主从复制时,从服务器需要主服务器建立连接,它会发起一个 socekt连接,然后调用aeCreateFileEvent函数针对发起的socket的读写事件注册了对应的事件处理器,也就是syncWithMaster函数。
aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL);
/* 符合aeFileProc的函数定义 */
void syncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) {....}aeCreateFileEvent的参数fd指的是具体的socket套接字,proc指fd产生事件时,具体的处理函数,clientData则是回调处理函数时需要传入的数据。aeCreateFileEvent主要做了三件事情:
- 以
fd为索引,在events未就绪事件表中找到对应事件。 - 调用
aeApiAddEvent函数,该事件注册到具体的底层 I/O 多路复用中,本例为epoll。 - 填充事件的回调、参数、事件类型等参数。
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
aeFileProc *proc, void *clientData)
{
/* 取出 fd 对应的文件事件结构, fd 代表具体的 socket 套接字 */
aeFileEvent *fe = &eventLoop->events[fd];
/* 监听指定 fd 的指定事件 */
if (aeApiAddEvent(eventLoop, fd, mask) == -1)
return AE_ERR;
/* 置文件事件类型,以及事件的处理器 */
fe->mask |= mask;
if (mask & AE_READABLE) fe->rfileProc = proc;
if (mask & AE_WRITABLE) fe->wfileProc = proc;
/* 私有数据 */
fe->clientData = clientData;
if (fd > eventLoop->maxfd)
eventLoop->maxfd = fd;
return AE_OK;
}如上文所说,Redis 基于的底层 I/O 多路复用库有多套,所以aeApiAddEvent也有多套实现,下面的源码是epoll下的实现。其核心操作就是调用epoll的epoll_ctl函数来向epoll注册响应事件。
static int aeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) {
aeApiState *state = eventLoop->apidata;
struct epoll_event ee = {0}; /* avoid valgrind warning */
/* 如果 fd 没有关联任何事件,那么这是一个 ADD 操作。如果已经关联了某个/某些事件,那么这是一个 MOD 操作。 */
int op = eventLoop->events[fd].mask == AE_NONE ?
EPOLL_CTL_ADD : EPOLL_CTL_MOD;
/* 注册事件到 epoll */
ee.events = 0;
mask |= eventLoop->events[fd].mask; /* Merge old events */
if (mask & AE_READABLE) ee.events |= EPOLLIN;
if (mask & AE_WRITABLE) ee.events |= EPOLLOUT;
ee.data.fd = fd;
/* 调用epoll_ctl 系统调用,将事件加入epoll中 */
if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return -1;
return 0;
}事件处理
因为 Redis 中同时存在文件事件和时间事件两个事件类型,所以服务器必须对这两个事件进行调度,决定何时处理文件事件,何时处理时间事件,以及如何调度它们。
下图为事件管理器示意图,其事件驱动库的代码主要是在src/ae.c中实现的
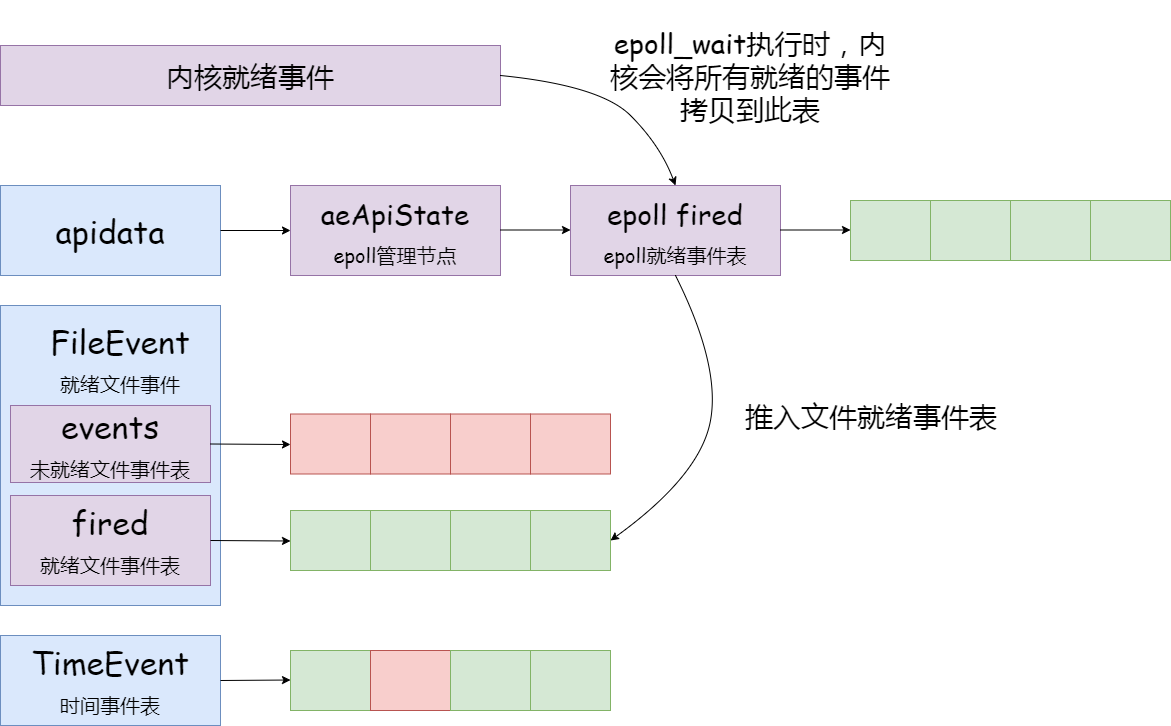
aeMain函数以一个无限循环不断地调用aeProcessEvents函数来处理所有的事件。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
/* 如果有需要在事件处理前执行的函数,那么执行它 */
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
/* 开始处理事件*/
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}下面是aeProcessEvents的伪代码,它会首先计算距离当前时间最近的时间事件,以此计算一个超时时间;然后调用aeApiPoll函数去等待底层的I/O多路复用事件就绪;aeApiPoll函数返回之后,会处理所有已经产生文件事件和已经达到的时间事件。
/* 伪代码 */
int aeProcessEvents(aeEventLoop *eventLoop, int flags) {
/* 获取到达时间距离当前时间最接近的时间事件*/
time_event = aeSearchNearestTimer();
/* 计算最接近的时间事件距离到达还有多少毫秒*/
remaind_ms = time_event.when - unix_ts_now();
/* 如果事件已经到达,那么remaind_ms为负数,将其设置为0 */
if (remaind_ms < 0) remaind_ms = 0;
/* 根据 remaind_ms 的值,创建 timeval 结构*/
timeval = create_timeval_with_ms(remaind_ms);
/* 阻塞并等待文件事件产生,最大阻塞时间由传入的 timeval 结构决定,如果remaind_ms 的值为0,则aeApiPoll 调用后立刻返回,不阻塞*/
/* aeApiPoll调用epoll_wait函数,等待I/O事件*/
aeApiPoll(timeval);
/* 处理所有已经产生的文件事件*/
processFileEvents();
/* 处理所有已经到达的时间事件*/
processTimeEvents();
}与aeApiAddEvent类似,aeApiPoll也有多套实现,它其实就做了两件事情,调用epoll_wait阻塞等待epoll的事件就绪,超时时间就是之前根据最快达到时间事件计算而来的超时时间;然后将就绪的epoll事件转换到fired就绪事件。aeApiPoll就是上文所说的I/O多路复用程序。
static int aeApiPoll(aeEventLoop *eventLoop, struct timeval *tvp)
{
aeApiState *state = eventLoop->apidata;
int retval, numevents = 0;
// 调用epoll_wait函数,等待时间为最近达到时间事件的时间计算而来。
retval = epoll_wait(state->epfd,state->events,eventLoop->setsize,
tvp ? (tvp->tv_sec*1000 + tvp->tv_usec/1000) : -1);
// 有至少一个事件就绪?
if (retval > 0)
{
int j;
/*为已就绪事件设置相应的模式,并加入到 eventLoop 的 fired 数组中*/
numevents = retval;
for (j = 0; j < numevents; j++) {
int mask = 0;
struct epoll_event *e = state->events+j;
if (e->events & EPOLLIN)
mask |= AE_READABLE;
if (e->events & EPOLLOUT)
mask |= AE_WRITABLE;
if (e->events & EPOLLERR)
mask |= AE_WRITABLE;
if (e->events & EPOLLHUP)
mask |= AE_WRITABLE;
/* 设置就绪事件表元素 */
eventLoop->fired[j].fd = e->data.fd;
eventLoop->fired[j].mask = mask;
}
}
// 返回已就绪事件个数
return numevents;
}processFileEvent是处理就绪文件事件的伪代码,也是上文所述的文件事件分派器,它其实就是遍历fired就绪事件表,然后根据对应的事件类型来调用事件中注册的不同处理器,读事件调用rfileProc,而写事件调用wfileProc。
void processFileEvent(int numevents) {
for (j = 0; j < numevents; j++) {
/* 从已就绪数组中获取事件 */
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
int fired = 0;
int invert = fe->mask & AE_BARRIER;
/* 读事件 */
if (!invert && fe->mask & mask & AE_READABLE) {
/* 调用读处理函数 */
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
/* 写事件. */
if (fe->mask & mask & AE_WRITABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
if (invert && fe->mask & mask & AE_READABLE) {
if (!fired || fe->wfileProc != fe->rfileProc) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
processed++;
}
}而processTimeEvents是处理时间事件的函数,它会遍历aeEventLoop的事件事件列表,如果时间事件到达就执行其timeProc函数,并根据函数的返回值是否等于AE_NOMORE来决定该时间事件是否是周期性事件,并修改器到达时间。
static int processTimeEvents(aeEventLoop *eventLoop) {
int processed = 0;
aeTimeEvent *te;
long long maxId;
time_t now = time(NULL);
....
eventLoop->lastTime = now;
te = eventLoop->timeEventHead;
maxId = eventLoop->timeEventNextId-1;
/* 遍历时间事件链表 */
while(te) {
long now_sec, now_ms;
long long id;
/* 删除需要删除的时间事件 */
if (te->id == AE_DELETED_EVENT_ID) {
aeTimeEvent *next = te->next;
if (te->prev)
te->prev->next = te->next;
else
eventLoop->timeEventHead = te->next;
if (te->next)
te->next->prev = te->prev;
if (te->finalizerProc)
te->finalizerProc(eventLoop, te->clientData);
zfree(te);
te = next;
continue;
}
/* id 大于最大maxId,是该循环周期生成的时间事件,不处理 */
if (te->id > maxId) {
te = te->next;
continue;
}
aeGetTime(&now_sec, &now_ms);
/* 事件已经到达,调用其timeProc函数*/
if (now_sec > te->when_sec ||
(now_sec == te->when_sec && now_ms >= te->when_ms))
{
int retval;
id = te->id;
retval = te->timeProc(eventLoop, id, te->clientData);
processed++;
/* 如果返回值不等于 AE_NOMORE,表示是一个周期性事件,修改其when_sec和when_ms属性*/
if (retval != AE_NOMORE) {
aeAddMillisecondsToNow(retval,&te->when_sec,&te->when_ms);
} else {
/* 一次性事件,标记为需删除,下次遍历时会删除*/
te->id = AE_DELETED_EVENT_ID;
}
}
te = te->next;
}
return processed;
}删除事件
当不在需要某个事件时,需要把事件删除掉。例如: 如果 fd 同时监听读事件、写事件。当不在需要监听写事件时,可以把该 fd 的写事件删除。
aeDeleteEventLoop函数的执行过程总结为以下几个步骤
1、根据fd在未就绪表中查找到事件
2、取消该fd对应的相应事件标识符
3、调用aeApiFree函数,内核会将epoll监听红黑树上的相应事件监听取消。
Redis事务调度
Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
事务的实现
一个事务从开始到结束通常会经历以下三个阶段:
- 事务开始
- 命令入队
- 事务执行
事务开始
MULTI 命令的执行标志着事务的开始:
redis> MULTI
OK MULTI 命令可以将执行该命令的客户端从非事务状态切换至事务状态,这一切换是通过在客户端状态的 flags 属性中打开 REDIS_MULTI 标识来完成的。
命令入队
入队前判断
当一个客户端处于非事务状态时,这个客户端发送的命令会立即被服务器执行。与此不同的是,当一个客户端切换到事务状态之后,服务器会根据这个客户端发来的不同命令执行不同的操作。
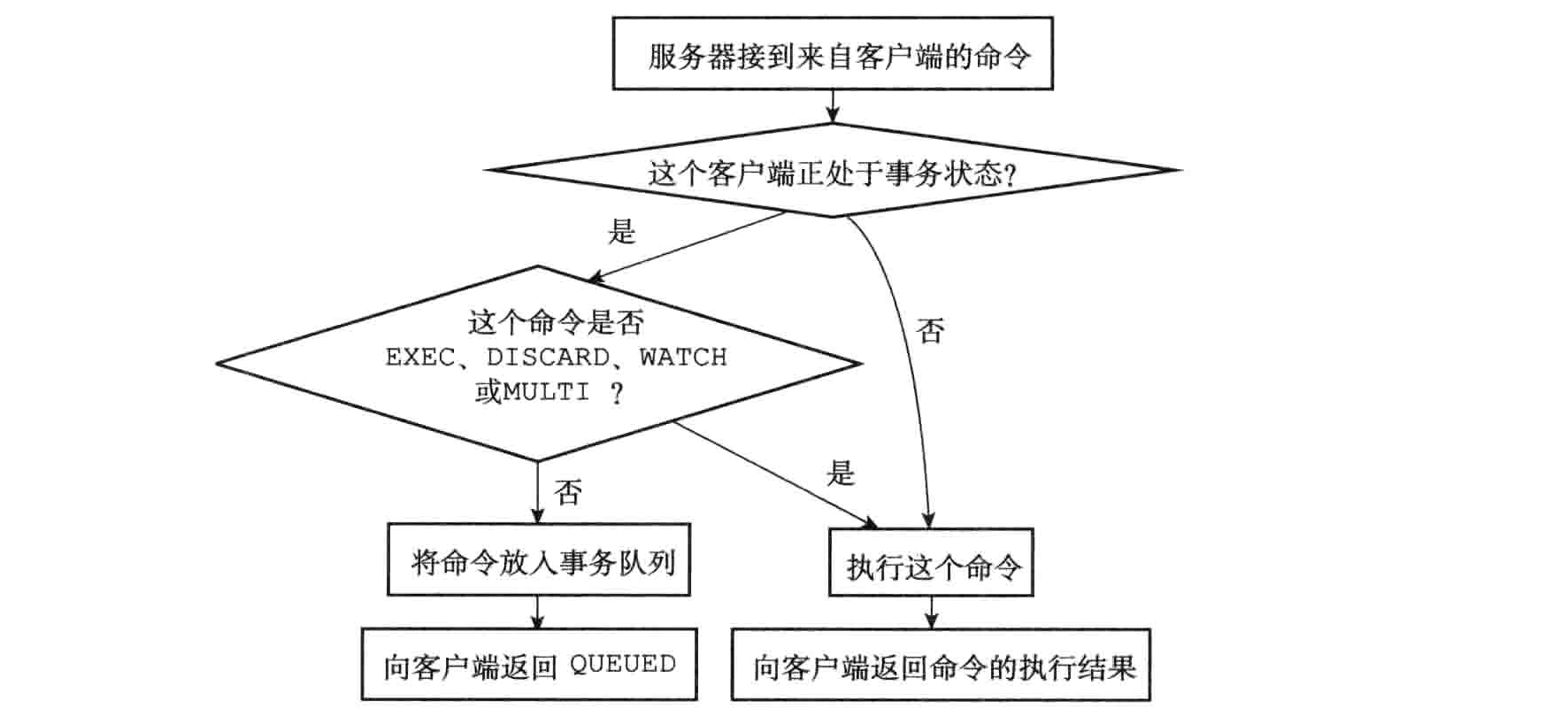
事务队列
每个 Redis 客户端都有自己的事务状态,这个事务状态保存在客户端状态的 mstate 属性里面:
typedef struct redisClient {
//...
//事务声明队列
multiState mstate;
//...
}事务状态包含一个事务队列,以及一个已入队命令的计数器(也可以说是事务队列的长度):
typedef struct multiState {
//事务队列 FIFO
multiCmd *commands;
//已入队命令计数
int count;
} multiState;事务队列是一个 multiCmd 类型的数组,数组中的每个 multiCmd 结构都保存了一个已入队命令的相关信息,包括指向命令实现函数的指针、命令的参数,以及参数的数量:
typedef struct multiCmd {
//参数
robj **argv;
//参数数量
int argc;
//命令指针
struct redisCommand *cmd;
} multiCmd;下图是事务状态数据结构
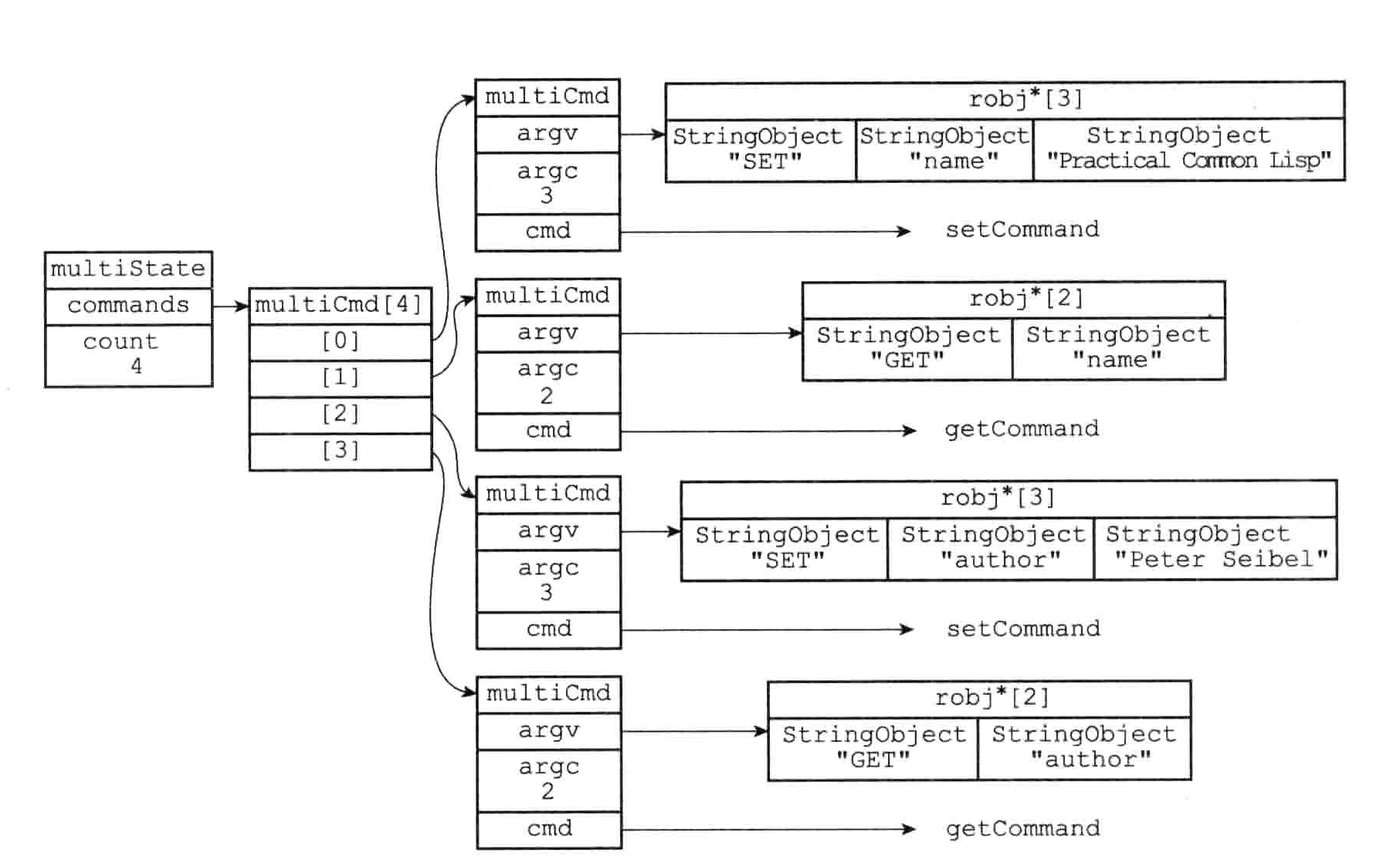
事务执行
当一个处于事务状态的客户端向服务器发送 EXEC 命令时,这个 EXEC 命令将立即被服务器执行。服务器会遍历这个客户端的事务队列,执行队列中保存的所有命令,最后将执行命令所得的结果全部返回给客户端。
def EXEC():
#创建空白的回复队列
reply_queue = []
#遍历事务队列中的每个项
#读取命令的参数,参数的个数,以及要执行的命令
for argv, argc, cmd in client.mstate.commands:
#执行命令,并取得命令的返回值
reply = execute_command(cmd, argv, argc)
#将返回值追加到回复队列末尾
reply_queue.append(reply)
#移除REDTS_MULTI标识,让客户端回到非事务状态
client.flags &= ~REDIS_MULTI
#清空客户端的事务状态,包括:
#1)清零入队命令计数器
#2)释放事务队列
client.state.count = 0
release_transaction_queue(client.mstate.commands)
#将事务的执行结果返回给客户端
send_reply_to_client(client, reply_queue)WATCH命令的实现
WATCH 命令是一个乐观锁(optimistic locking),它可以在 EXEC 命令执行之前,监视任意数量的数据库键,并在 EXEC 命令执行时,检查被监视的键是否至少有一个已经被修改过了,如果是的话,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
WATCH "name"
MULTI
SET "name" "peter"
EXEC在事务运行期间,监视的键被修改,服务器会拒绝执行客户端事务,并返回空回复。
使用WATCH命令监视数据库键
每个 Redis 数据库都保存着一个 watched_keys 字典,这个字典的键是某个被 WATCH 命令监视的数据库键,而字典的值则是一个链表,链表中记录了所有监视相应数据库键的客户端:
typedef struct redisDb {
//...
//正在被WATCH命令监视的键
dict *watched_keys;
//...
} redisDb;通过 watched_keys 字典,服务器可以清楚地知道哪些数据库键正在被监视,以及哪些客户端正在监视这些数据库键。
下图是客户端 c1、c2、c10086 在监视 “name” 键,c3、c10086 在监视 “age” 键,c2、c4 在监视 “address” 键。其中 c10086 是运行 WATCH 命令后新增的。
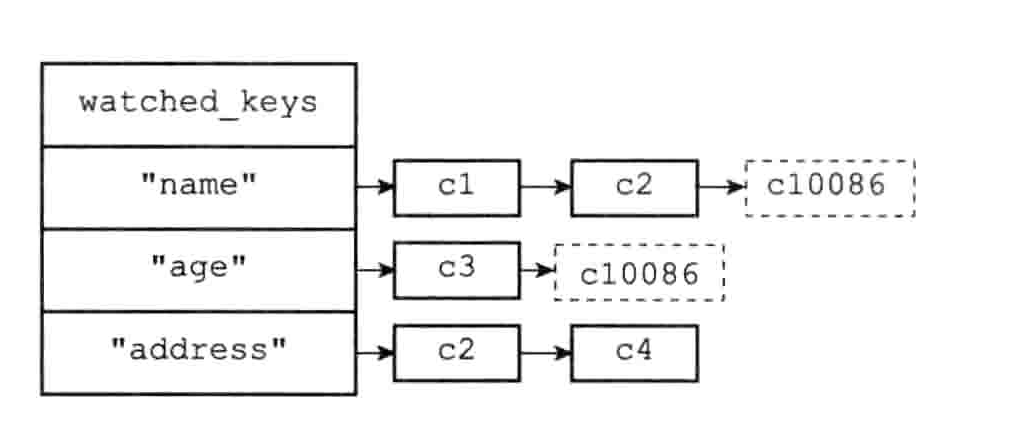
监视机制的触发
所有对数据库进行修改的命令,比如 SET、PUSH、SADD、ZREM、DEL、FLUSHDB 等等,在执行之后都会调用 multi.c/touchWatchKey 函数对 watched_keys 字典进行检查,查看是否有客户端正在监视刚刚被命令修改过的数据库键,如果有的话,那么 touchWatchKey 函数会将监视被修改键的客户端的 REDIS_DIRTY_CAS 标识打开,表示该客户端的事务安全性已经被破坏。
客户端向服务器发送 EXEC 命令,如果客户端的 REDIS_DIRTY_CAS 标识已经打开,则表明客户端提交事务不再安全,因此服务端会拒绝执行客户端提交的事务。
事务的ACID性质
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有耐久性(Durability)。
原子性
事务具有原子性指的是,数据库将事务中的多个操作当作一个整体来执行,服务器要么就执行事务中的所有操作,要么就一个操作也不执行。
Redis 的事务和传统的关系型数据库事务的最大区别在于,Redis 不支持事务回滚机制(rollback),即使事务队列中的某个命令在执行期间出现了错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止。
Redis 的作者在事务功能的文档中解释说,不支持事务回滚是因为这种复杂的功能和 Redis 追求简单高效的设计主旨不相符,并且他认为,Redis 事务的执行时错误通常都是编程错误产生的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,所以他认为没有必要为 Redis 开发事务回滚功能。
一致性
事务具有一致性指的是,如果数据库在执行事务之前是一致的,那么在事务执行之后,无论事务是否执行成功,数据库也应该仍然是一致的。”一致”指的是数据符合数据库本身的定义和要求,没有包含非法或者无效的错误数据。Redis 通过谨慎的错误检测和简单的设计来保证事务的一致性。
1. 入队错误
如果一个事务在入队命令的过程中,出现了命令不存在,或者命令的格式不正确等情况,那么该事务在执行时,Redis 将拒绝执行这个事务。
2.6.5 版本以前入队错误 Redis 会直接忽略并继续向下执行
2. 执行错误
关于执行错误有两个需要说明的地方:
- 执行过程中发生的错误都是一些不能在入队时被服务器发现的错误,这些错误只会在命令实际执行时被触发。
- 即使在事务的执行过程中发生了错误,服务器也不会中断事务的执行,它会继续执行事务中余下的其他命令,并且已执行的命令(包括执行命令所产生的结果)不会被出错的命令影响。
对数据库键执行了错误类型的操作是事务执行期间最常见的错误之一
3. 服务器停机
如果 Redis 服务器在执行事务的过程中停机,那么根据服务器所使用的持久化模式,可能有以下情况出现
- 如果服务器运行在无持久化的内存模式下,那么重启之后的数据库将是空白的,因此数据总是一致的。
- 如果服务器运行在 RDB 模式下,那么在事务中途停机不会导致不一致性,因为服务器可以根据现有的 RDB 文件来恢复数据,从而将数据库还原到一个一致的状态。如果找不到可供使用的 RDB 文件,那么重启之后的数据库将是空白的,而空白数据库总是一致的。
- 如果服务器运行在 AOF 模式下,那么在事务中途停机不会导致不一致性,因为服务器可以根据现有的 AOF 文件来恢复数据,从而将数据库还原到一个一致的状态。如果找不到可供使用的 AOF 文件,那么重启之后的数据库将是空白的,而空白数据库总是一致的。
综上所述,无论 Redis 服务器运行在哪种持久化模式下,事务执行中途发生的停机都不会影响数据库的一致性。
隔离性
事务的隔离性指的是,即使数据库中有多个事务并发地执行,各个事务之间也不会互相影响,并且在并发状态下执行的事务和串行执行的事务产生的结果完全相同。
因为 Redis 使用单线程的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间不会对事务进行中断,因此,Redis 的事务总是以串行的方式运行的,并且事务也总是具有隔离性的。
耐久性
事务的耐久性指的是,当一个事务执行完毕时,执行这个事务所得的结果已经被保存到永久性存储介质(比如硬盘)里面了,即使服务器在事务执行完毕之后停机,执行事务所得的结果也不会丢失。
因为Reds的事务不过是简单地用队列包裹起了一组 Redis 命令,Redis 并没有为事务提供任何额外的持久化功能,所以 Redis 事务的耐久性由 Redis 所使用的持久化模式决定:
- 当服务器在无持久化的内存模式下运作时,事务不具有耐久性:一旦服务器停机包括事务数据在内的所有服务器数据都将丢失。
- 当服务器在 RDB 持久化模式下运作时,服务器只会在特定的保存条件被满足时,才会执行 BGSAVE 命令,对数据库进行保存操作,并且异步执行的 BGSAVE 不能保证事务数据被第一时间保存到硬盘里面,因此 RDB 持久化模式下的事务也不具有耐久性。
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 always 时程序总会在执行命令之后调用同步(sync)函数,将命令数据真正地保存到硬盘里面,因此这种配置下的事务是具有耐久性的。
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 everysec 时,程序会每秒同步一次命令数据到硬盘。因为停机可能会恰好发生在等待同步的那一秒钟之内,这可能会造成事务数据丢失,所以这种配置下的事务不具有耐久性。
- 当服务器运行在 AOF 持久化模式下,并且 appendfsync 选项的值为 no 时,程序会交由操作系统来决定何时将命令数据同步到硬盘。因为事务数据可能在等待同步的过程中丢失,所以这种配置下的事务不具有耐久性。
no-appendfsync-on-rewrite 配置选项对耐久性的影响
配置选项 no-appendfsync-on-rewrite 可以配合 appendfsync 选项为 always 或者 everysec 的 AOF 持久化模式使用。当 no-appendfsync-on-rewrite 选项处于打开状态时,在执行 BGSAVE 命令或者 BGREWRITEAOF 命令期间,服务器会暂时停止对 AOF 文件进行同步,从而尽可能地减少 IO 阻塞。但是这样来,关于 “always模式的AOF持久化可以保证事务的耐久性” 这一结论将不再成立,因为在服务器停止对 AOF 文件进行同步期间,事务结果可能会因为停机而丢失。
因此,如果服务器打开了 no-appendfsync-on-rewrite 选项,那么即使服务器运行在 always 模式的 AOF 持久化之下,事务也不具有耐久性。在默认配置下,no-appendfsync-on-rewrite 处于关闭状态。