Java 与 C++ 之间有堵由内存动态分配和垃圾收集技术所围成的“高墙”,墙外面的人想进去,墙里面的人却想出来。
运行时数据区
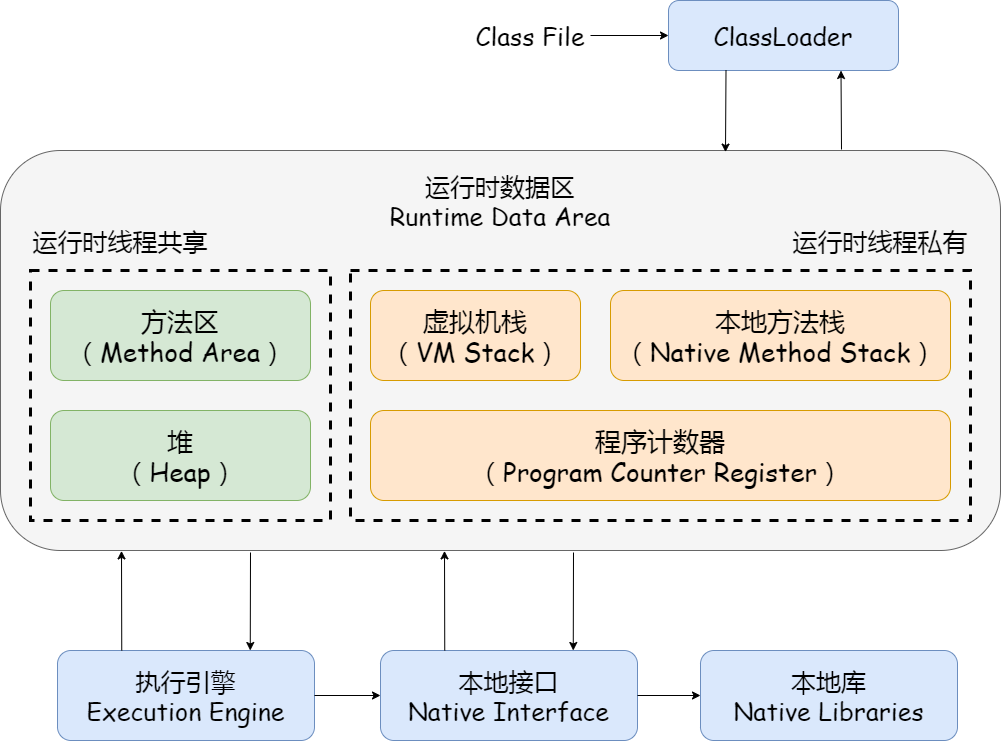
运行时线程共享
JVM 支持的多个线程同时执行时,这些线程共用 JVM 提供的方法区和堆运行时线程私有
JVM 支持的多个线程同时执行时,每一个线程都有自己的虚拟机栈、本地方法栈、程序计数器
程序计数器
由于 Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个 Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是 Native 方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
虚拟机栈
虚拟机栈与线程同时创建,用于存储栈帧。它用来描述 Java 方法执行的内存模型。每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于储存局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
另外,它在方法调用和返回中也扮演了很重要的角色。因为除了栈帧的出栈和入栈之外,Java 虚拟机栈不会再受其他因素的影响,所以栈帧可以在堆中分配,Java 虚拟机栈所使用的内存不需要保证是连续的。
局部变量表存放了编译期可知的各种基本数据类型( boolean、byte、char、 short、int、 float、long、 double)、对象引用( reference类型 )和 returnAddress 类型(指向了一条字节码指令的地址)。其中 64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间(slot),其余的数据类型只占用 1 个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在 Java 虚拟机规范中,对这个区域规定两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常:如果虚拟机栈可以动态扩展(当前大部分的 JVM 都可动态扩展,只不过 Java 虚拟机规范中也允许固定长度的虚拟机栈),如果扩展时无法申请到足够的内存,就会抛出 OutOfMemoryError 异常。
线程数量与内存的关系
我们固定堆内存大小,不断增加栈内存大小,以测试栈内存不断增大对 JVM 创建线程数的影响。
| Xms | Xmx | Xss | Threads |
|---|---|---|---|
| 512m | 512m | 1m | 63790 |
| 512m | 512m | 10m | 60803 |
| 512m | 512m | 64m | 32651 |
| 512m | 512m | 128m | 20678 |
| 512m | 512m | 512m | 6556 |
从数据可以发现线程创建数量是随着虚拟机内存的增多而减少的。其实也很好理解,虚拟机栈内存是线程私有的,也就是说每一个线程都会占有指定的内存大小,我们粗略的可以认为进程的内存大小为:堆内存 + 线程内存 * 栈内存。
一个进程的最大内存是有限制的,因此根据上述公式可以得出,线程数量也同样会受到堆内存的影响。两者的关系如下图。
| Xms | Xmx | Xss | Threads |
|---|---|---|---|
| 64m | 64m | 1m | 92376 |
| 128m | 128m | 1m | 90948 |
| 256m | 256m | 1m | 90423 |
| 512m | 512m | 1m | 87931 |
| 1024m | 1024m | 1m | 83195 |
可以看到,虽然也是呈反比关系,但影响并不是很大。
操作系统则会将进程内存的大小控制在最大地址空间以内,下面的公式是一个相对比较精确的计算线程数量的公式,其中 ReservedOsMemory 是系统保留内存,一般在 136 MB 左右:线程数量 = (MaxProcessMemory - JVM Heap Memory - ReservedOsMemory) / ThreadStackSize。
当然线程数量还与操作系统的一些内核配置有很大关系,比如在 Linux 下,下面三个内核配置信息也可以决定线程数量大小。
/proc/sys/kernel/threads-max/proc/sys/kernel/pid_max/proc/sys/vm/max_map_count
本地方法栈
当 JVM 使用其他语言(例如 C 语言)来实现指令集解释器时,可以使用本地方法栈。如果 JVM 不支持 native 方法,或是本身不依赖传统栈,那么可以不提供本地方法栈,如果支持本地方法栈,那这个栈一般会在线程创建的时候按线程分配。
本地方法栈( Native Method Stack )与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行 Java 方法〔也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。在虚拟机规范中对本地方法栈中方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如 Sun Hotspot 虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出 StackOverflow Error 和 OutOfMemory Error 异常。
堆
堆(Heap)在虚拟机启动的时候就被创建,并且此内存区域的唯一目的就是存放对象实例以及数组。但是随着 JIT 编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化发生,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
从内存回收的角度看,由于 GC 基本都采用的是分代收集算法堆可按照下图划分。
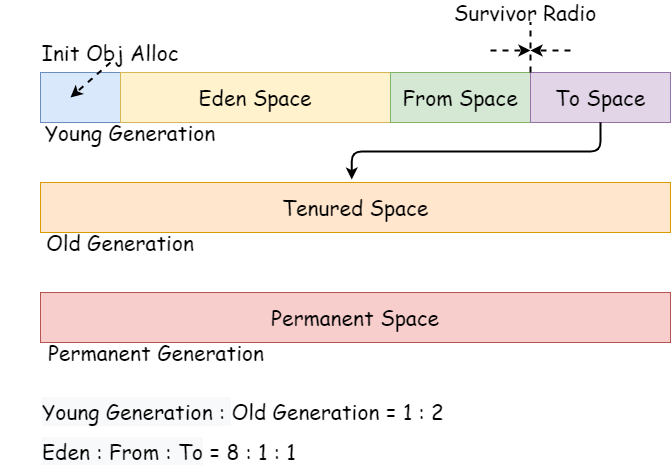
从内存分配的角度看,线程共享的堆中可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)。
堆存储了被自动內存管理系统( Automatic Storage Management System,也就是 GC)所管理的各种对象,这些受管理的对象无需也无法显式地销毁。JVM 并未假设采用何种具体技术去实现自动内存管理系统。虚拟机实现者可以根据系统的实际需要来选择自动内存管理技术。堆的容量可以是固定的,也可以随着程序执行的需求动态扩展,并在不需要过多空间时自动收缩。堆所使用的内存不需要保证是连续的。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出 OutOfMemoryError 异常。
方法区
方法区( Method Area )是可供各个线程共享的运行时内存区域。方法区与传统语言中的编译代码存储区( storage area for compiled code )或者操作系统进程的正文段( text segment )的作用非常类似,它存储了已被 JVM 加载的类的结构信息,例如,运行时常量池( runtime constant pool )、字段和方法数据、构造函数和普通方法的字节码内容,还包括一些在类、实例、接口初始化时用到的特殊方法。
方法区在虚拟机启动的时候创建,虽然方法区是堆的逻辑组成部分,但是简单的虚拟机实现可以选择在这个区域不实现垃圾收集与压缩。Java 虚拟机规范也不限定实现方法区的内存位置和编译代码的管理策略。方法区的容量可以是固定的,也可以随着程序执行的需求动态扩展,并在不需要过多空间时自动收缩。方法区在实际内存空间中可以是不连续的。
这区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说,这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收确实是必要的。在 Sun 公司的 BUG 列表中,曾出现过的若干个严重的 BUG 就是由于低版本的 HotSpot 虚拟机对此区域未完全回收而导致内有泄漏根据 Java 虚拟机规范的规定;当方法区无法满足内存分配需求时,将抛出 OutOfMemoryError 异常。
对于习惯在 HotSpot 虚拟机上开发、部署程序的开发者来说,很多人都更愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为 HotSpot 虚拟机的设计团队选择把 GC 分代收集扩展至方法区,或者说使用永久代来实现方法区而已,这样 HotSpot 的垃圾收集器可以像管理 Heap 一样管理这部分内存,能够省去专门为方法区编写内存管理代码的工作。在 HotSpot JVM 中,方法区还被细分为持久代和代码缓存区,代码缓存区主要用于存储编译后的本地代码(和硬件相关)以及 JIT(Just In Time)编译器生成的代码,当然不同的 JVM 会有不同的实现。
对于其他虚拟机(如 BEA JRockit、IBM J9 等)来说不存在永久代的概念的。原则上,如何实现方法区属于虚拟机实现细节不受虚拟机规范约束,但使用永久代来实现方法区,现在看来并不是一个好主意,因为这样更容易遇到内存溢出问题(永久代有-XX:MaxPermSize的上限,J9 和 JRockit 只要没有触碰到进程可用内存的上限,例如 32 位系统中的 4GB 就不会出现问题),而且有极少数方法(例如String.intern())会因这个原因导致不同虚拟机下有不同的表现。因此,对于 HotSpot 虚拟机,根据官方发布的路线图信息,现在也有放弃永久代并逐步改为采用 Native Memory 来实现方法区的规划了,在目前已经发布的 JDK1.7 的 HotSpot 中,已经把原本放在永久代的字符串常量池移出。
Java8 元空间
在 JDK 1.8 版本中,持久代区域被元空间(Meta Space)取代了。元空间同样是堆内存的一部分,JVM 为每个类加载器分配一块内存块列表,进行线性分配,块的大小取决于类加载器的类型,sun/反射/代理 对应的类加载器块会小一些,之前的版本会单独卸载回收某个类,而现在则是 GC 过程中发现某个类加载器已经具备回收条件,则会对整个类加载器相关的元空间全部回收,这样就可以减少内存碎片,节省 GC 扫描和压缩的时间。
直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是 Java 虚拟机规范中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致 OutOfMemoryError 异常出现。
在 JDK1.4 中新加人了 NIO(New Input/Output)类,引人了一种基于通道(Channel)与缓冲区(Buffer)的 IO 方式,它可以使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
显然,本机直接内存的分配不会受到 Java 堆大小的限制,但是,既然是内存,肯定还是会受到本机总内存(包括 RAM 以及 SWAP 区或者分页文件)大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机参数时,会根据实际内存设置-Xmx等参数信息,但经常忽略直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现 OutOfMemoryError 异常。
对象探秘
对象的创建
虚拟机遇到一条 new 指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程。
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。对象所需内存的大小在类加载完成后便可完全确定,为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来。假设 Java 堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为“指针碰撞”(Bump the Pointer)。如果 Java 堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为“空闲列表”(Free List)。选择哪种分配方式由 Java 堆是否规整决定,而 Java 堆是否规整又由所采用的垃圾收集器是否带有压缩整理功能决定。因此,在使用 Serial、ParDew 等带 Compact 过程的收集器时,系统采用的分配算法是指针碰撞,而使用 CMS 这种基于 Mark-Sweep 算法的收集器时,通常采用空闲列表。
对象的访问定位
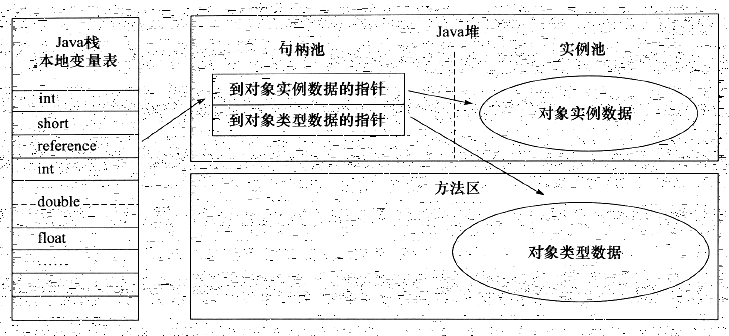
建立对象是为了使用对象,Java 程序需要通过栈上的 reference 数据来操作堆上的具体对象。由于 reference 类型在 Java 虚拟机规范中只规定了一个指向对象的引用,并没有定义这个引用应该通过何种方式去定位、访问堆中的对象的具体位置,所以对象访间方式也是取决于虚拟机实现而定的。目前主流的访问方式有使用句柄和直接指针两种
- 如果使用句柄访问的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各直的具体地址信息,如下图所示。
- 如果使用直接指针访问,那么 Java 堆对象的布局中就必须考虑如何放置访问类型数据的相关信息,而 reference 中存储的直接就是对象地址,如下图所示。
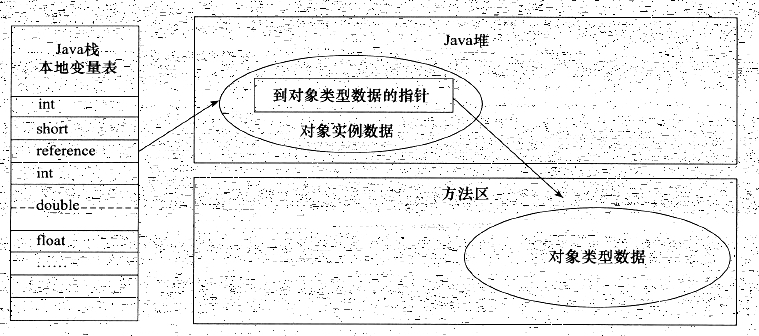
这两种对象访问方式各有优势,使用句柄来访问的最大好处就是 reference 中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中的实例数据指针,而 reference本身不需要修改。使用直接指针访问方式的最大好处就是速度更快,它节省了一次指针定位的时间开销,由于对象的访问在 Java 中非常频繁,因此这类开销积少成多后也是一项非常可观的执行成本。就 Sun HotSpot 而言,它是使用第二种方式进行对象访问的,但从整个软件开发的范围来看,各种语言和框架使用句柄来访问的情况也十分常见。
方法区的回收
很多人认为方法区(或者 HotSpot 虚拟机中的永久代)是没有垃圾收集的,Java 虚拟机规范中确实说过可以不要求虚拟机在方法区实现垃圾收集,而且在方法区中进行垃圾收集的“性价比”一般比较低:在堆中,尤其是在新生代中,常规应用进行一次垃圾收集一般可以回收 70%~95% 的空间,而永久代的垃圾收集效率远低于此。
永久代的垃圾收集主要回收两部分内容:废弃常量和无用的类。回收废弃常量与回收 Java 堆中的对象非常类似。以常量池中字面量的回收为例,假如一个字符串“abc”已经进入了常量池中,但是当前系统没有任何一个 String 对象是叫做“abc”的,换句话说,就是没有任何 String 对象引用常量池中的“abc”常量,也没有其他地方引用了这个字面量,如果这时发生内存回收,而且必要的话,这个“abc”常量就会被系统清理出常量池。常量池中的其他类(接口)、方法、字段的符号引用也与此类似。
判定一个常量是否是“废弃常量”比较简单,而要判定一个类是否是“无用的类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是“无用的类”
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的
java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
虚拟机可以对满足上述 3 个条件的无用类进行回收,这里说的仅仅是“可以”,而并不是和对象一样,不使用了就必然会回收。是否对类进行回收,HotSpot 虚拟机提供了-Xnoclassgc参数进行控制,还可以使用-verbose:class以及-XX:+TraceClassLoading、-XX:+TraceLoading查看类加载和卸载信息,其中-verbose:class和-XX:+TraceClassLoading可以在 Product 版的虚拟机中使用,-XX:+TraceClassUnLoading参数需要 FastDebug 版的虚拟机支持。
在大量使用反射、动态代理、CGLib 等 ByteCode 框架、动态生成 JSP 以及 OSGi 这类频繁自定义 ClassLoader 的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
垃圾收集器与内存分配策略
回收策略
回收策略,即垃圾收集器在对堆进行回收前,要确定这些对象之中哪些还“存活”着,哪些已经“死去”(即不可能再被仼何途径使用的对象)。
引用计数算法
客观地说,引用计数算法( Reference Counting)的实现简单,判定效率也很高。原理如下:给对象中添加一个引用计数器,每当有一个地方引用它时,计数器的值就加 1,每当有一个引用失效时,计数器的值就减 1。任何时刻只要对象的计数器值为 0,那么就可以被判定为垃圾对象。但是,至少主流的 Java 虚拟机里面没有选用引用计数算法来管理内存,其中最主要的原因是它很难解决对象之间相互循环引用的问题。实际上这两个对象已经不可能再被访问,但是它们因为互相引用着对方,导致它们的引用计数都不为 0,于是引用计数算法无法通知 GC 收集器回收它们。
可达性分析算法
在主流的商用程序语言(Java、C#,甚至包括前面提到的古老的 Lisp)的主流实现中,都是称通过可达性分析(Reachability Analysis)来判定对象是否存活的。这个算法的基本思路就是通过一系列的称为“ GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到 GC Roots 没有任何引用链相连(用图论的话来说,就是从 GC Roots 到这个对象不可达)时,则证明此对象是不可用的。如下图所示,对象 5、6、7 虽然互相有关联,但是它们到 GC Roots 是不可达的,所以它们将会被判定为是可回收的对象。
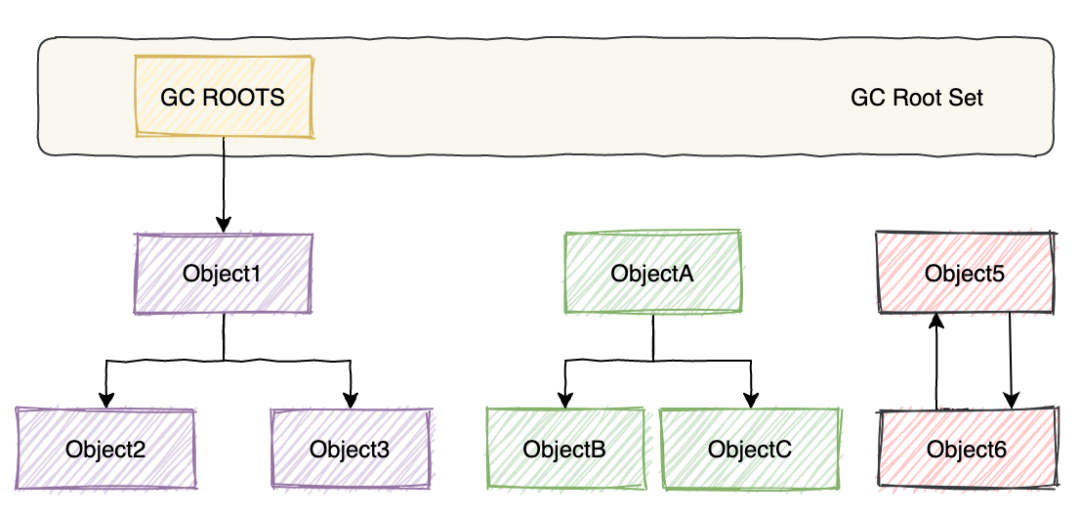
在Java语言中,可作为 GC Roots 的对象包括下面几种
- 虚拟机栈(栈帧中的本地变量表)中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中 JNI(即一般说的 Native 方法)引用的对象。
垃圾收集算法
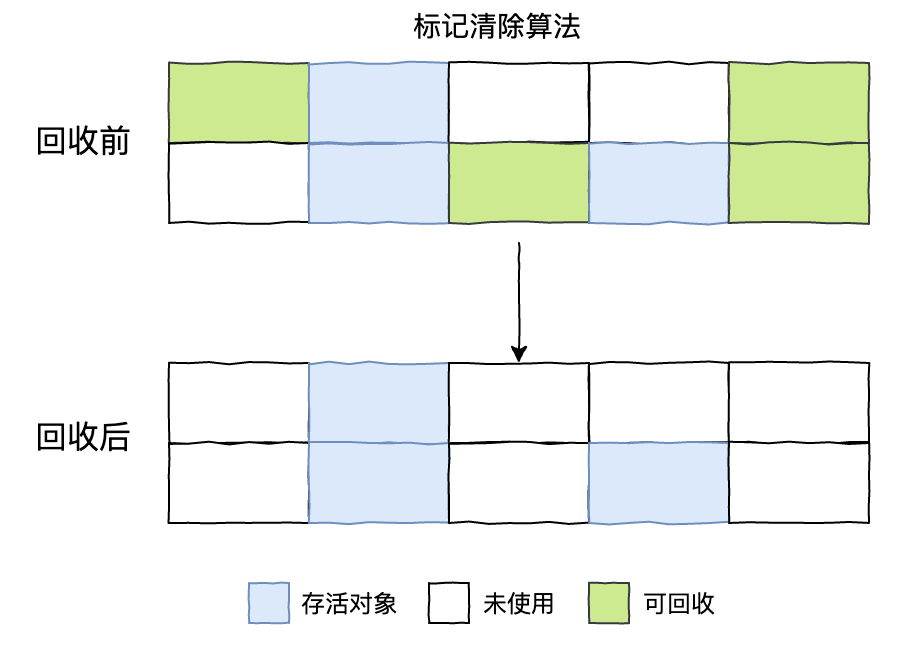
标记-清除算法
标记-清除(Mark-Sweep)算法,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
缺点:
效率问题
标记和清除两个过程的效率都不高。
空间问题
标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
复制算法
为了解决效率问题,“复制”(Copying)的收集算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,未免太高了一点。
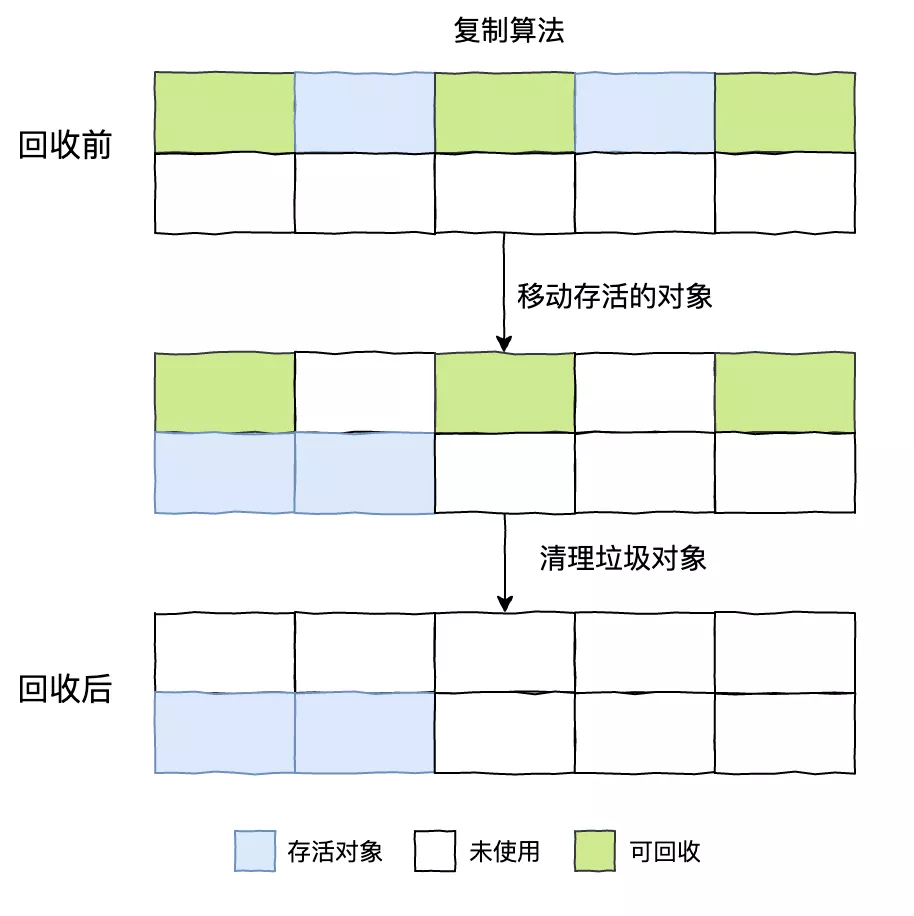
现在的商业虚拟机都采用这种收集算法来回收新生代;IBM 公司的专门研究表明,新生代中的对象 98% 是“朝生夕死”的,所以并不需要按照 1:1 的比例来划分内存空间,而是将内存分为一块较大的 Eden 空间和两块较小的 Survivor 空间,每次使用 Eden 和其中一块 Survivor,当回收时,将 Eden 和 Survivor 中还存活着的对象一次性地复制到另外一块 Survivor 空间上,最后清理掉 Eden 和刚才用过的 Survivor 空间。HotSpot 虚拟机默认 Eden 和 Survivor 的大小比例是 8:1,也就是每次新生代中可用内存空间为整个新生代容量的 90%(80%+10%),只有 10% 的内存会被“浪费”。当然,98% 的对象可回收只是般场景下的数据,我们没有办法保证每次回收都只有不多于 10% 的对象存活,当 Survivor 空间不够用時时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
内存的分配担保机制:如果另外一块 Survivor 空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制进入老年代。
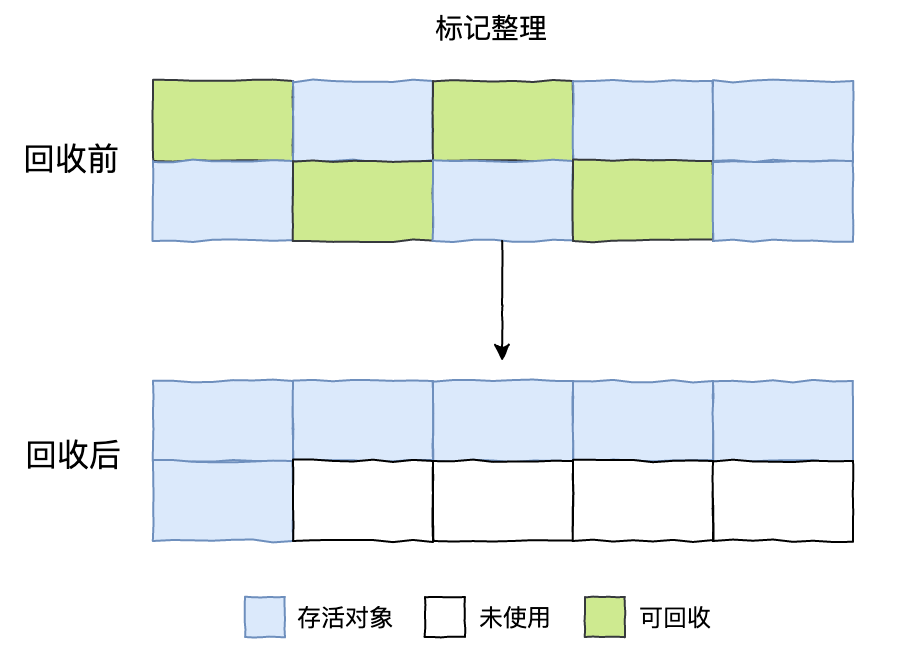
标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费 50% 的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都 100% 存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记一清理”或者“标记一整理”算法来进行回收。
HotSpot的算法实现
枚举根节点
从可达性分析中从 GC Roots 节点找引用链这个操作为例,可作为 GC Roots 的节点主要在全局性的引用(例如常量或类静态属性)与执行上下文(例如栈帧中的本地变量表)中,现在很多应用仅仅方法区就有数百兆,如果要逐个检查这里面的引用,那么必然会消耗很多时间。
另外,可达性分析对执行时间的敏感还体现在 GC 停顿上,因为这项分析工作必须在一个能确保一致性的快照中进行—这里“一致性”的意思是指在整个分析期间整个执行系统看起来就像被冻结在某个时间点上,不可以出现分析过程中对象引用关系还在不断变化的情况,该点不满足的话分析结果准确性就无法得到保证。这点是导致 GC 进行时必须停顿所有 Java 执行线程(Sun 将这件事情称为“Stop The World”)的其中一个重要原因,即使是在号称(几乎)不会发生停顿的 CMS 收集器中,枚举根节点时也是必须要停顿的。
由于目前的主流 Java 虚拟机使用的都是准确式 GC,所以当执行系统停顿下来后,并不需要一个不漏地检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法直接得知哪些地方存放着对象引用。在 HotSpot 的实现中,是使用一组称为 OopMap 的数据结构来达到这个目的的,在类加载完成的时候,HotSpot 就把对象内什么偏移量上是什么类型的数据计算出来,在 JIT 编译过程中,也会在特定的位置记录下栈和寄存器中哪些位置是引用。这样,GC在扫描时就可以直接得知这些信息了。
安全点
在 OopMap 的协助下,HotSpot 可以快速且准确地完成 GC Roots 枚举,但一个很现实的问题随之而来:可能导致引用关系变化,或者说 OopMap 内容变化的指令非常多,如果为每一条指令都生成对应的 OopMap 那将会需要大量的额外空间,这样 GC 的空间成本将会变得很高。
实际上,HotSpot 也的确没有为每条指令都生成 OopMap,前面巳经提到,只是在“特定的位置”记录了这些信息,这些位置称为安全点(Safepoint),即程序执行时并非在所有地方都能停顿下来开始 GC,只有在到达安全点时才能暂停。Safepoint 的选定既不能太少以致于让 GC 等待时间太长,也不能过于频繁以致于过分增大运行时的负荷。所以,安全点的选定基本工是以程序“是否具有让程序长时间执行的特征”为标准进行选定的 —— 因为每条指令执行的时间都非常短暂,程序不太可能因为指令流长度太长这个原因而过长时间运行,“长时间执行”的最明显特征就是指令序列复用,例如方法调用、循环跳转、异常跳转等,所以具有这些功能的指令才会产生 Safepoint。
对于 Safepoint,另一个需要考虑的问题是如何在 GC 发生时让所有线程(这里不包括执行 JNI 调用的线程)都“跑”到最近的安全点上再停顿下来。这里有两种方案可供选择:抢先式中断(Preemptive Suspension)和主动式中断(Voluntary Suspension),其中抢先式中断不需要线程的执行代码主动去配合,在 GC 发生时,首先把所有线程全部中断,如果发现有线程中断的地方不在安全点上,就恢复线程,让它“跑”到安全点上。现在几乎没有虚拟机实现采用抢先式中断来暂停线程从而响应 GC 事件。
而主动式中断的思想是当 GC 需要中断线程的时候,不直接对线程操作,仅仅简单地设置一个标志,各个线程执行时主动去轮询这个标志,发现中断标志为真时就自己中断挂起轮询标志的地方和安全点是重合的,另外再加上创建对象需要分配内存的地方。下面代码清单中的 test 指令是 HotSpot 生成的轮询指令,当需要暂停线程时,虚拟机把 0xl60100 的内存贞设置为不可读,线程执行到 test 指令时就会产生一个自陷异常信号,在预先注册的异常处理器中暂停线程实现等待,这样一条汇编指令便完成安全点轮询和触发线程中断。

安全区域
使用 Safepoint 似乎已经完美地解决了如何进入 GC 的问题,但实际情况却并不一定。Safepoint 机制保证了程序执行时,在不太长的时间内就会遇到可进入 GC 的 Safepoint。
但是,程序“不执行”的时候呢?所谓的程序不执行就是没有分配 CPU 时间,典型的例子就是线程处于 Sleep 状态或者 Blocked 状态,这时候线程无法响应 JVM 的中断请求,“走”到安全的地方去中断挂起,JVM 也显然不太可能等待线程重新被分配 CPU 时间。对于这种情况,就需要安全区域(Safe Region)来解决。
安全区域是指在一段代码片段之中,引用关系不会发生变化。在这个区域中的任意地方开始 GC 都是安全的,也可以把 Safe Region 看做是被扩展了的 Safepoint。
在线程执行到 Safe Region 中的代码时,首先标识自己已经进入了 Safe Region,那样,当在这段时间里 JVM 要发起 GC 时,就不用管标识自己为 Safe Region 状态的线程了。在线程要离开 Safe Region 时,它要检查系统是否已经完成了根节点枚举(或者是整个 GC 过程),如果完成了,那线程就继续执行,否则它就必须等待直到收到可以安全离开 Safe Region 的信号为止。
垃圾收集器
收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
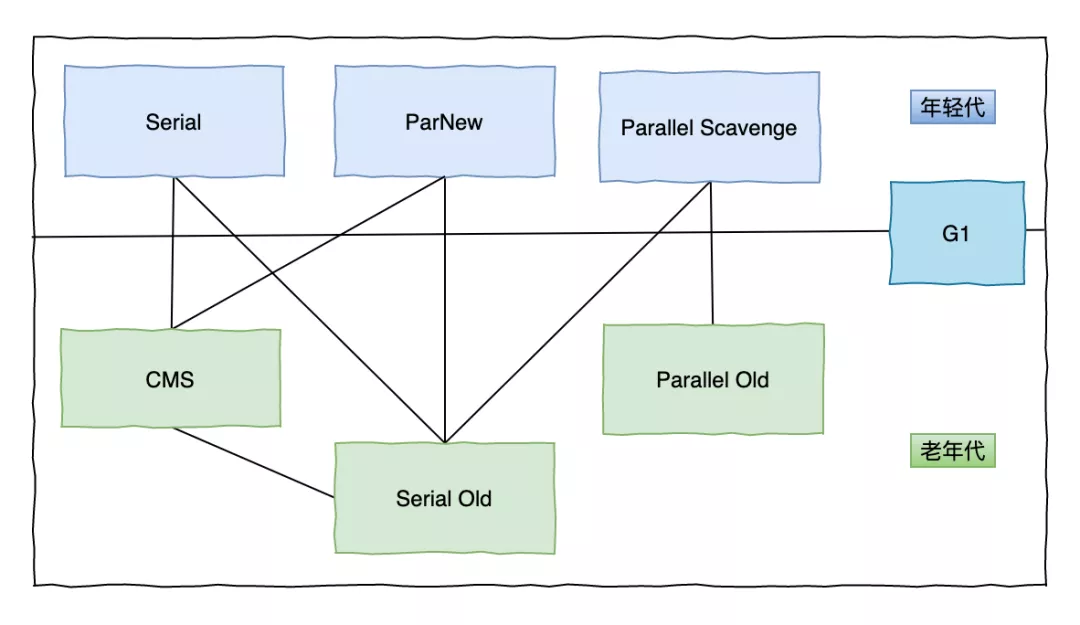
Serial收集器
为单线程环境设计,在垃圾回收时需要暂停其他所有工作线程,直到它收集结束。 简单而高效(与其他收集器的但线程相比),对于限定单个 CPU 的环境来说,Serial 收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。Serial 收集器对于运行在 Client 模式下的虚拟机来说是一个很好的选择。因为需回收内容少,也就意味着停顿时间在可接受范围内的同时,可以满足比较高的性能。
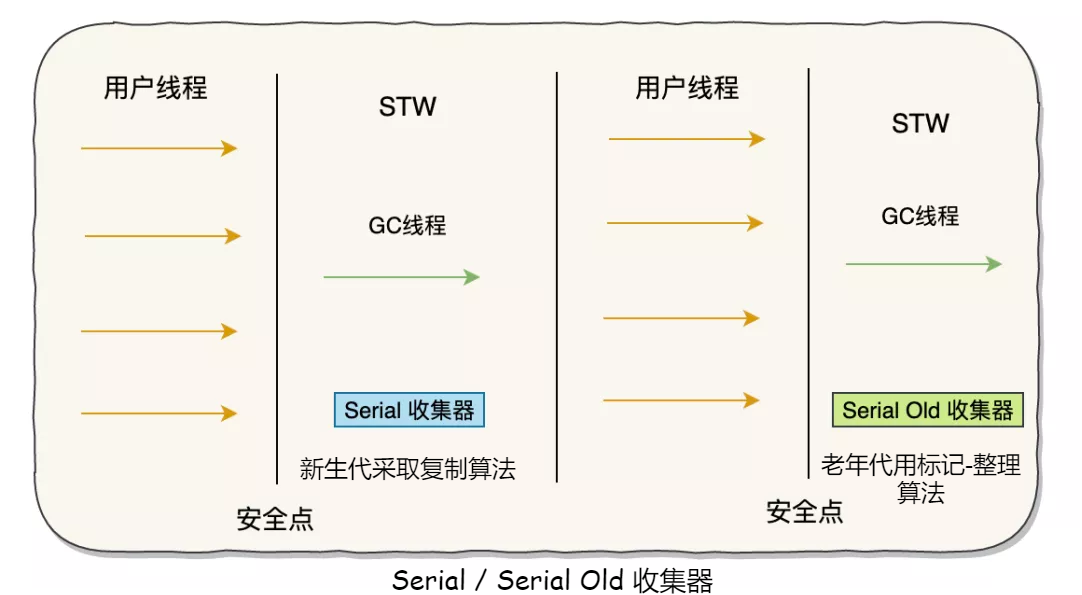
ParNew收集器
ParNew 收集器其实就是 Serial 收集器的多线程版本,行为和 Serial 基本一样。
它是许多运行在 Server 模式下的虚拟机中首选的新生代收集器,其中有一个与性能无关但很重要的原因是,除了 Serial 收集器外,目前只有它能与 CMS 收集器配合工作。
ParNew 收集器在单 CPU 的环境中绝对不会有比 Serial 收集器更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个 CPU 的环境中都不能百分之百地保证可以超越 Serial 收集器。当然,随着可以使用的 CPU 的数量的增加,它对于 GC 时系统资源的有效利用还是很有好处的。它默认开启的收集线程数与 CPU 的数量相同。
并行和并发区别
- 并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
- 并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个CPU上。
相关参数
-XX:+UseParNewGC启用ParNew收集器(新生代)-XX:ParallelGCThreads垃圾收集的线程数
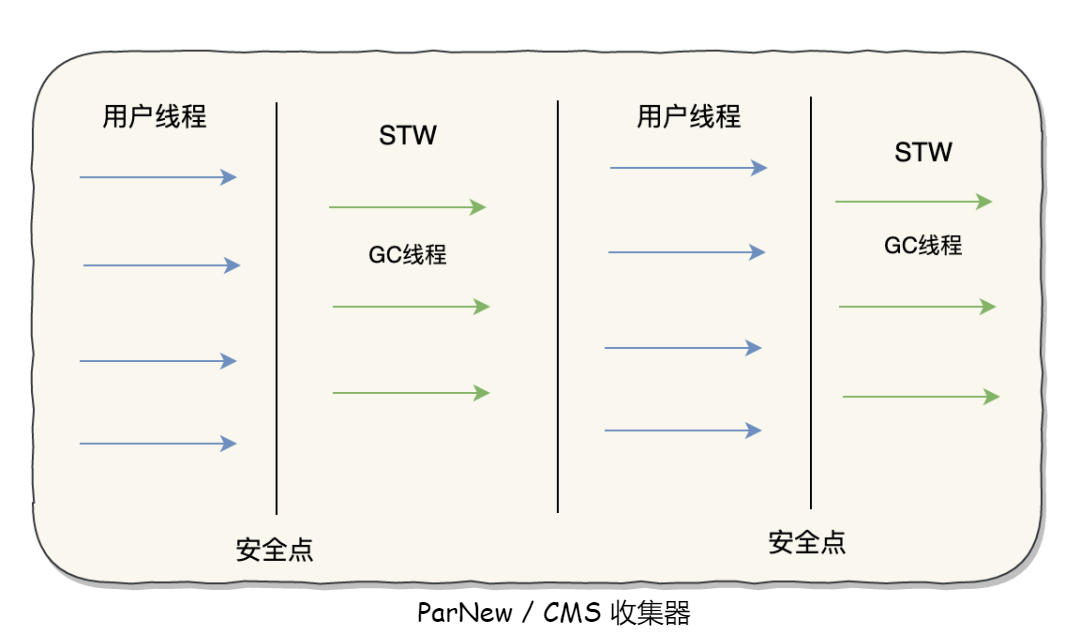
Parallel Scavenge收集器
Parallel Scavenge 收集器,也可以叫吞吐量优先收集器。回收过程与 Parnew 类似,多个垃圾收集线程并行工作,此时用户线程是暂停的,适用于大数据处理等弱交互场景。
Parallel Scavenge 收集器的特点是它的关注点与其他收集器不同,CMS 等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而 Parallel Scavenge 收集器的目标则是达到一个可控制的吞吐量(Throughput)。所谓吞吐量就是 CPU 用于运行用户代码的时间与 CPU 总消耗时间的比值,即吞吐量=运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间)。
停顿时间和吞吐量区别
- 停顿时间越短就越适合需要与用户交互的程序,良好的响应速度能提升用户体验。
- 高吞吐量则可以高效率地利用CPU时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。
相关参数
-XX:UseParallelGC 或 -XX:UseParallelOldGC 打开PS收集器(可相互激活)
-XX:MaxGCPauseMilli 控制最大垃圾收集停顿时间
MaxGCPauseMillis参数允许的值是一个大于0的毫秒数,收集器将尽可能地保证内存回收花费的时间不超过设定值。不过大家不要认为如果把这个参数的值设置得稍小一点就能使得系统的垃圾收集速度变得更快,GC停顿时间缩短是以牺牲吞吐量和新生代空间来换取的:系统把新生代调小一些,收集300MB新生代肯定比收集500MB快吧,这也直接导致垃圾收集发生得更频繁一些,原来10秒收集一次、每次停顿100毫秒,现在变成5秒收集一次、每次停顿70毫秒。停顿时间的确在下降,但吞吐量也降下来了。
-XX:GCTime Ratio 直接设置吞吐量大小
GCTime Ratio参数的值应当是一个大于0且小于100的整数,也就是垃圾收集时间占总时间的比率,相当于是吞吐量的倒数。如果把此参数设置为19,那允许的最大GC时间就占总时间的5%(即1/(1+19),默认值为9,就是允许最大1%(即1/(1+99))的垃圾收集时间。
-XX:+UseAdaptiveSizePolicy 自适应调节新生代的大小(-Xmn)、Eden与 Survivor区的比例(- XX:Survivorratio)、晋升老年代对象年龄 (- XX:PretenureSizeThreshold)等细节参数
这种调节方式称为GC自适应的调节策略(GC Ergonomics)。使用 Parallel Scavenge收集器配合自适应调节策略,可以把内存管理的调优任务交给虚拟机去完成。只需要把基本的内存数据设置好(如-Xmx设置最大堆),然后使用 MaxGCPause Millis参数(更关注最大停顿时间)或 GCTimeRatio(更关注吞吐量)参数给虚拟机设立一个优化目标,那具体细节参数的调节工作就由虚拟机完成了。自适应调节策略也是ParallelScavenge收集器与ParNew收集器的一个重要区别。
Serial Old收集器
Serial Old 是 Serial 收集器的老年代版本,它同样是一个单线程收集器,使用“标记整理”算法。这个收集器的主要意义也是在于给 Client 模式下的虚拟机使用。如果在 Server 模式下,那么它主要还有两大用途:一种用途是在 JDK1.5 以及之前的版本中与 Parallel Scavenge 收集器搭配使用,另一种用途就是作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
Parallel Old收集器
“吞吐量优先”收集器终于有了比较名副其实的应用组合,在注重吞吐量以及 CPU 资源敏感的场合,都可以优先考虑 Parallel Scavenge 加 Parallel Old 收集器。Parallel Old 收集器的工作过程如下图所示。
CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。用户线程和垃圾回收线程同时执行(不一定并行,可能交替),不需要停顿用户线程。适用于对响应时间有要求的场景。根据 Mark Sweep 得知,CMS 收集器是基于“标记-清除”算法实现的。
步骤
初始标记(CMS initial mark)
初始标记只是标记一下 GC Roots 能直接关联到的对象,速度很快。该过程仍需要“Stop The World”。
并发标记(CMS concurrent mark)
并发标记阶段就是进行 GC Roots Tracing 的过程。
重新标记(CMS remark)
重新标记阶段则是为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般会比初始标记阶段稍长些,但远比并发标记的时间短。该过程仍需要“Stop The World”。
并发清除(CMS concurrent sweep)
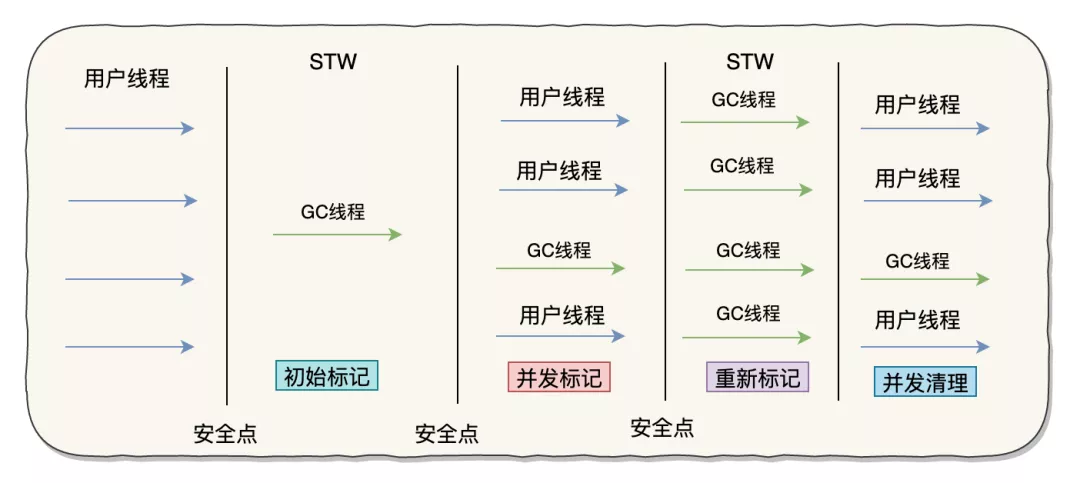
优势:并发收集、低停顿
缺点
CMS 收集器对 CPU 资源非常敏感。
其实,面向并发设计的程序都对 CPU 资源比较敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分线程(或者说 CPU 资源)而导致应用程序变慢,总吞吐量会降低。CMS 默认启动的回收线程数是(CPU数量+3)/4,也就是当CPU在 4 个以上时,并发回收时垃圾收集线程不少于25%的CPU资源,并且随着 CPU 数量的增加而下降。但是当 CPU 不足4个(譬如2个)时,CMS 对用户程序的影响就可能变得很大,如果本来 CPU 负载就比较大,还分出一半的运算能力去执行收集器线程,就可能导致用户程序的执行速度忽然降低了 50%,其实也让人无法接受。为了应付这种情况,虚拟机提供了一种称为增量式并发收集器”(Incremental Concurrent Mark Sweep/i-CMS)的 CMS 收集器变种,所做的事情和单 CPU 年代 PC 机操作系统使用抢占式来模拟多任务机制的思想样,就是在并发标记、清理的时候让 GC 线程、用户线程交替运行,尽量减少 GC 线程的独占资源的时间,这样整个垃圾收集的过程会更长,但对用户程序的影响就会显得少一些,也就是速度下降没有那么明显。实践证明,增量时的 CMS 收集器效果很一般,在目前版本中,iCMS 已经被声明为“deprecated”,即不再提倡用户使用。
CMS收集器无法处理浮动垃圾(Floating Garbage),可能出现“Concurrent Mode Failure”失败而导致另一次 Full GC 的产生。
由于 CMS 并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉。这部分垃圾就称为“浮动垃圾”。也是由于在垃圾收集阶段用户线程还需要运行,那也就还需要预留有足够的内存空间给用户线程使用,因此 CMS 收集器不能像其他收集器那样等到老年代几乎完全被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运作使用。在 JDK1.5 的默认设置下,CMS 收集器当老年代使用了 68% 的空间后就会被激活,这是一个偏保守的设置,如果在应用中老年代增长不是太快,可以适当调高参数
-XX:CMSInitiatingOccupancyFraction的值来提高触发百分比,以便降低内存回收次数从而获取更好的性能,在 JDK1.6 中,CMS 收集器的启动阈值已经提升至 92%。要是 CMS 运行期间预留的内存无法满足程序需要,就会出现一次“Concurrent Mode Failure”失败,这时虚拟机将启动后备预案:临时启用 Serial Old 收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说参数-XX:CMSInitiatingOccupancyFraction设置得太高很容易导致大量“Concurrent Mode Failure”失败,性能反而降低。CMS 是一款基于“标记-清除”算法实现的收集器,这意味着收集结束时会有大量空间碎片产生。
空间碎片过多时,将会给大对象分配带来很大麻烦,往往会出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前触发一次 Full GC。为了解决这个问题,CMS 收集器提供了一个
-XX:+UseCMSCompactAtFullCollection开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。虚拟机设计者还提供了另外一个参数-XX:CMSFullGCsBeforeCompaction,这个参数是用于设置执行多少次不压缩的 Full GC 后,跟着来一次带压缩的(默认值为0,表示每次进入 Full GC 时都进行碎片整理)。
相关参数
- -XX:+UseConcMarkSweepGC 开启CMS(默认打开ParNewGC),开启此参数后,使用ParNew(Young) + CMS (Old) + Serial Old(CMS出错的后备收集器)的收集器组合。
G1收集器
G1 回收的目标不再是整个新生代或者是老年代。G1 可以回收堆内存的任何空间来进行,不再是根据年代来区分,而是那块空间垃圾多就去回收,通过 Mixed GC 的方式去进行回收。在多核的场景下效果较佳。
先看下堆空间的划分:
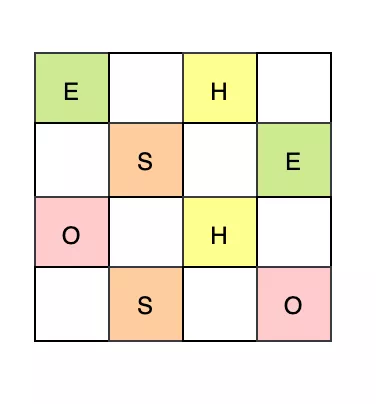
G1 垃圾回收器把堆划分成大小相同的 Region,每个 Region 都会扮演一个角色,分别为 H、S、E、O。
- E 代表伊甸区
- S 代表 Survivor 区
- H 代表的是 Humongous 区
- O 代表 Old 区
特点
并行与并发
G1 能充分利用多 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿的时间,部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 Java 程序继续执行。
分代收集
与其他收集器一样,分代概念在 G1 中依然得以保留。虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次 GC 的旧对象以获取更好的收集效果。
空间整合
与 CMS 的“标记-清理”算法不同,G1 从整体来看是基于“标记一整理”算法实现的收集器,从局部(两个 Region之间)上来看是基于“复制”算法实现的,但无论如何,这两种算法都意味着 G1 运作期间不会产生内存空间碎片,收集后能提供规整的可用内存。这种特性有利于程序长时间运行,分配大对象时不会因为无法找到连续内存空间而提前触发下一次 GC。
可预测的停顿
这是 G1 相对于 CMS 的另一大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒,这几乎已经是实时 Java(RTSJ)的垃圾收集器的特征了。
其他介绍
在 G1 之前的其他收集器进行收集的范围都是整个新生代或者老年代。使用 G1 收集器时,它将整个 Java 堆划分为多个大小相等的独立区域(Region)(化整为零),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分 Region(不需要连续)的集合。G1 收集器之所以能建立可预测的停顿时间模型,是因为它可以有计划地避免在整个 Java 堆中进行全区域的垃圾收集。G1 跟踪各个 Region 里面的垃圾堆积的价值大小(回收所获得的空间大小以及回收所需时间的经验值),在后台维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region(这也就是 Garbage-First 名称的来由)。这种使用 Region 划分内存空间以及有优先级的区域回收方式,保证子 G1 收集器在有限的时间内可以获取尽可能高的收集效率。
在 G1收集器中, Region 之间的对象引用以及其他收集器中的新生代与老年代之间的对象引用,虚拟机都是使用 Remembered Set 来避免全堆扫描的。G1 中每个 Region 都有一个与之对应的 Remembered Set,虚拟机发现程序在对 Reference 类型的数据进行写操作时,会产生一个 Write Barrier 暂时中断写操作,检查 Reference 引用的对象是否处于不同的 Region之中(在分代的例子中就是检查是否老年代中的对象引用了新生代中的对象),如果是,便通过 CardTable 把相关引用信息记录到被引用对象所属的 Region 的 Remembered Set 之中。当进行内存回收时,在 GC 根节点的枚举范围中加入 Remembered Set 即可保证不对全堆扫描也不会有遗漏如果不计算维护 Remembered Set 的操作。
运行过程
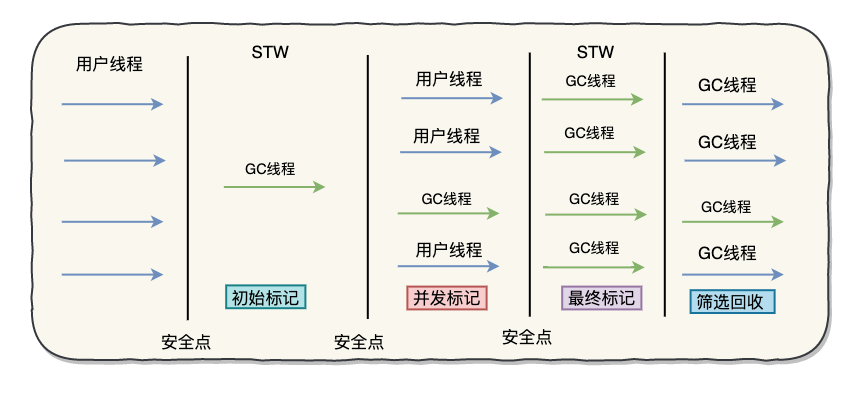
初始标记(Initial Marking)
初始标记阶段仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMs(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能在正确可用的 Region中创建新对象,这阶段需要停顿线程,但耗时很短。
并发标记(Concurrent Marking)
并发标记阶段是从 GC Root开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时较长,但可与用户程序并发执行。
最终标记(Final Marking)
最终标记阶段是为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs的数据合并到 Remembered Set 中,这阶段需要停顿线程,但是可并行执行。
筛选回收(Live Data Counting and Evacuation)
筛选回收阶段首先对各个 Region 的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划,这个阶段也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅提高收集效率。
理解GC日志
[GC (System.gc()) [PSYoungGen: 7335K->2017K(38400K)] 7335K->2025K(125952K), 0.0442526 secs] [Times: user=0.14 sys=0.00, real=0.04 secs]
[Full GC (System.gc()) [PSYoungGen: 2017K->0K(38400K)] [ParOldGen: 8K->1945K(87552K)] 2025K->1945K(125952K), [Metaspace: 3384K->3384K(1056768K)], 0.0175568 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
Heap
PSYoungGen total 38400K, used 333K [0x00000000d5b80000, 0x00000000d8600000, 0x0000000100000000)
eden space 33280K, 1% used [0x00000000d5b80000,0x00000000d5bd34a8,0x00000000d7c00000)
from space 5120K, 0% used [0x00000000d7c00000,0x00000000d7c00000,0x00000000d8100000)
to space 5120K, 0% used [0x00000000d8100000,0x00000000d8100000,0x00000000d8600000)
ParOldGen total 87552K, used 1945K [0x0000000081200000, 0x0000000086780000, 0x00000000d5b80000)
object space 87552K, 2% used [0x0000000081200000,0x00000000813e6410,0x0000000086780000)
Metaspace used 3394K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 368K, capacity 388K, committed 512K, reserved 1048576K[GC (System.gc()) [PSYoungGen: 7335K->2017K(38400K)] 7335K->2025K(125952K), 0.0442526 secs] [Times: user=0.14 sys=0.00, real=0.04 secs] Full GC 和 GC 代表垃圾收集的停顿类型,如果是 Full GC 则代表这次 GC 发生了 Stop-The-World。一般来说,Full GC 是出现了分配担保失败之类的问题导致的 STW。而示例这种形式则会标明是通过System.gc()来调用的。
后面方括号内部的7335K->2017K(38400K)含义是“GC 前该内存区域已使用容量→GC 后该内存区域已使用容量(该内存区域总容量)”。而在方括号之外的7335K->2025K(125952K)表示“GC 前 Java 堆已使用容量->GC 后 Java 堆已使用容量(Java 堆总容量)”
再往后,0.0442526 secs表示该内存区域 GC 所占用的时间,单位是秒。有的收集器会给出更具体的时间数据,如[Times : user=0.01 sys=0.00 real=0.02 secs],这里面的 user、sys 和 real 与 Linux 的 time 命令所输出的时间含义一致,分别代表用户态消耗的CPU时间、内核态消耗的CPU事件和操作从开始到结束所经过的墙钟时间(Wall Clock Time)。
CPU 时间与墙钟时间的区别是,墙钟时间包括各种非运算的等待耗时,例如等待磁盘 IO、等待线程阻塞,而 CPU 时间不包括这些耗时,但当系统有多 CPU 或者多核的话,多线程操作会叠加这些 CPU 时间,所以读者看到 user 或 sys 时间超过 real 时间是完全正常的。
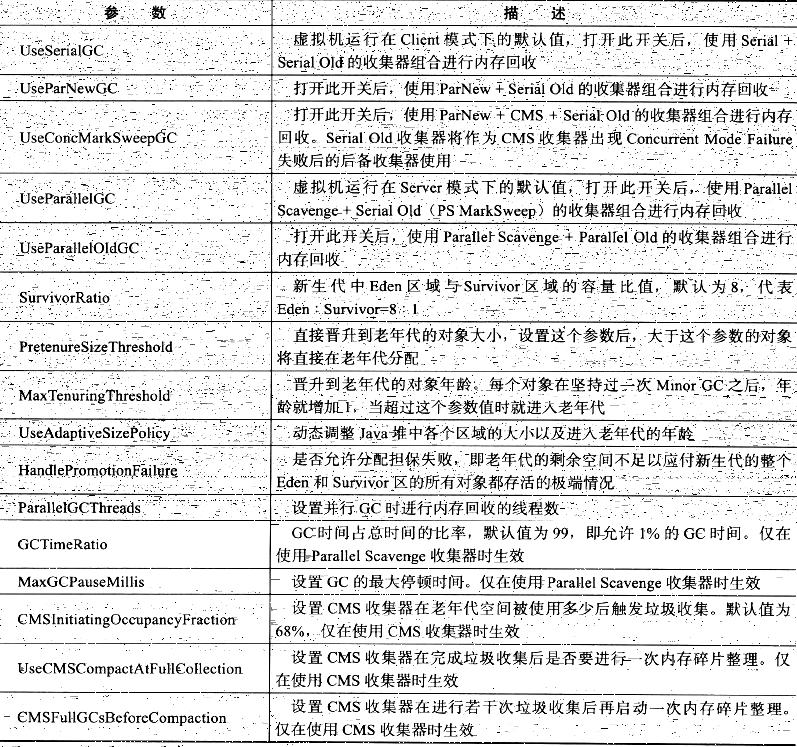
垃圾收集器参数
内存分配与回收策略
对于 Serial-Serial Old 收集器来说,大多数情况下,对象在新生代 Eden 区中分配,当 Eden 区没有足够的空间分配时,JVM 将发起一次 Minor GC,如果依旧放不下,只好通过分配担保机制提前转移到老年代去。而如果对象本身就是需要占据大量连续内存空间的Java对象(超过-XX:PretenureSizeThreshold就会被虚拟机判定为大对象),会被直接分配在老年代。这样做的好处是避免了新生代发生大量的内存复制(复制收集算法)。不过经常出现大对象容易导致内存还有不少空间时就提前触发垃圾收集以获取足够的连续空间来“安置”它们。
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这点,虚拟机给每个对象定义了一个对象年龄(Age)计数器。如果对象在 Eden 出生并经过第一次 Minor GC 后仍然存活,并且能被 Survivor 容纳的话,将被移动到 Survivor 空间中,并且对象年龄设为 1。对象在 Survivor 区中每“熬过”一次 Minor GC,年龄就增加 1 岁,当它的年龄增加到一定程度(默认为 15 岁),就将会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
新生代 GC Minor GC
指发生在新生代的垃圾收集动作,因为 Java 对象大多都具备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
老年代 GC(Major GC / Full GC)
指发生在老年代的 GC,出现了 Major GC,经常会伴随至少一次的 Minor GC。但非绝对的,在 Parallel Scavenge 收集器的收集策略里就有直接进行 Major GC 的策略选择过程。Major GC 的速度一般会比 Minor GC 慢10倍以上。
动态对象年龄判定
为了能更好地适应不同程序的内存状况,虚拟机并不是永远地要求对象的年龄必须达到了 MaxTenuringThreshold 才能晋升老年代,如果在 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到 MaxTenuringThreshold 中要求的年龄。
空间分配担保
在发生 Minor GC 之前;虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间。如果这个条件成立,那么 Minor GC 可以确保是安全的;如果不成立,则虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败。如果允许;那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次 Minor GC,尽管这次 Minor GC 是有风险的:如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一次 Full GC。
下面解释一下“冒险”是冒了什么风险:前面提到过,新生代使用复制收集算法,但为了内存利用率,只使用其中一个 Survivor 空间来作为轮换备份,因此当出现大量对象在 Minor GC 后仍然存活的情况(最极端的情況就是内存回收后新生代中所有对象都存活),就需要老年代进行分配担保,把 Survivor 无法容纳的对象直接进入老年代。老年代要进行这样的担保前提是老年代本身还有容纳这些对象的剩余空间,一共有多少对象会活下来在实际完成内存回收之前是无法明确知道的,所以只好取之前每一次回收晋升到老年代对象容量的平均大小值作为经验值,与老年代的剩余空间进行比较,决定是否进行 Full GC 来让老年代腾出更多空间。
取平均值进行比较其实仍然是一种动态概率的手段,也就是说,如果某次 Minor GC 存活后的对象突增,远远高于平均值的话,依然会导致担保失败(Handle Promotion Failure)。如果出现了 Handle Promotion Failure 失败,那就只好在失败后重新发起一次 Full GC。虽然担保失败时绕的圈子是最大的,但大部分情况下都还是会将 Handle Promotion Failure 开关打开,避免 Full GC 过于频繁。
OutOfMemory
堆(Heap)溢出
堆用于存储对象实例,只要不断地创建对象,并且保证 GC Roots 到对象之间有可达路径来避免垃圾回收机制清除这些对象。当对象数量到达最大堆的容量限制后,应用程序再次试图向堆空间添加更多的数据,但堆却没有足够的空间来容纳这些数据时,将会触发java.lang.OutOfMemoryError: Java heap space异常。需要注意的是:即使有足够的物理内存可用,只要达到堆空间设置的大小限制,此异常仍然会被触发。
如果只是单纯地增加堆空间不能解决所有的问题。如果你的程序存在内存泄漏,一味的增加堆空间也只是推迟java.lang.OutOfMemoryError: Java heap space错误出现的时间而已,并未解决这个隐患。除此之外,垃圾收集器在 GC 时,应用程序会停止运行直到 GC 完成,而增加堆空间也会导致 GC 时间延长,进而影响程序的吞吐量。
这两个区域的大小可以在 JVM(Java 虚拟机)启动时通过参数-Xmx和-XX:MaxPermSize设置,如果你没有显式设置,则将使用特定平台的默认值。
原因分析
流量/数据量峰值:应用程序在设计之初均有用户量和数据量的限制,某一时刻,当用户数量或数据量突然达到一个峰值,并且这个峰值已经超过了设计之初预期的阈值,那么以前正常的功能将会停止,并触发java.lang.OutOfMemoryError: Java heap space异常。
内存泄漏:特定的编程错误会导致你的应用程序不停的消耗更多的内存,每次使用有内存泄漏风险的功能就会留下一些不能被回收的对象到堆空间中,随着时间的推移,泄漏的对象会消耗所有的堆空间,最终触发java.lang.OutOfMemoryError: Java heap space错误。
虚拟机栈和本地方法栈溢出
由于在 HotSpot 虚拟机中并不区分虚拟机栈和本地方法栈,因此,对于 HotSpot 来说,虽然-Xoss参数(设置本地方法栈大小)存在,但实际上是无效的,栈容量只由-Xss参数设定。关于虚拟机栈和本地方法栈,在 Java 虚拟机规范中描述了两种异常:
- 如果线程请求的栈深度大于虚拟机所允许的最大深度,将抛出 StackOverflowError 异常。
- 如果虚拟机在扩展栈时无法申请到足够的内存空间,则抛出 OutOfMemoryError 异常。
这里把异常分成两种情况,看似更加严谨,但却存在着一些互相重叠的地方:当栈空间无法继续分配时,到底是内存太小,还是已使用的栈空间太大,其本质上只是对同一件事情的两种描述而已。
在下面的实验中,将实验范围限制于单线程中的操作,尝试了下面两种方法均无法让虚拟机产生 OutOfMemoryError 异常,尝试的结果都是获得 StackOverflowError 异常。
- 使用
-Xss参数减少栈内存容量。结果:抛出 StackOverflowError 异常,异常出现时输出的堆栈深度相应缩小。 - 定义了大量的本地变量,增大此方法帧中本地变量表的长度。结果:抛出 StackOverflowError 异常时输出的堆栈深度相应缩小。
实验结果表明:在单个线程下,无论是由于栈帧太大还是虚拟机栈容量太小,当内存无法分配的时候,虚拟机抛出的都是 StackOverflowError 异常。
如果测试时不限于单线程,通过不断地建立线程的方式倒是可以产生内存溢出异常。但是这样产生的内存溢出异常与栈空间是否足够大并不存在任何联系。或者准确地说,在这种情况下,为每个线程的栈分配的内存越大,反而越容易产生内存溢出异常。
其实原因不难理解,操作系统分配给每个进程的内存是有限制的,譬如 32 位的 Windows 限制为 2GB。虚拟机提供了参数来控制 Java 堆和方法区的这两部分内存的最大值剩余的内存为 2GB(操作系统限制)减去-Xmx(最大堆容量),再减去 MaxPermSize(最大方法区容量),程序计数器消耗内存很小,可以忽略掉。如果虚拟机进程本身耗费的内存不计算在内,剩下的内存就由虚拟机栈和本地方法栈“瓜分”了。每个线程分配到的栈容量越大,可以建立的线程数量自然就越少,建立线程时就越容易把剩下的内存耗尽。
这一点读者需要在开发多线程的应用时特别注意,出现 StackOverflowError 异常时有错误堆栈可以阅读,相对来说,比较容易找到问题的所在。而且,如果使用虚拟机默认参数,栈深度在大多数情况下(因为每个方法压入栈的帧大小并不是一样的,所以只能说在大多数情况下)达到 1000~2000 完全没有问题,对于正常的方法调用(包括递归),这个深度应该完全够用了。但是,如果是建立过多线程导致的内存溢出,在不能减少线程数或者更换 64 位虚拟机的情况下,就只能通过减少最大堆和减少栈容量来换取更多的线程。如果没有这方面的处理经验,这种通过“减少内存”的手段来解决内在溢出的方式会比较难以想到。
方法区和运行时常量池溢出
由于运行时常量池是方法区的一部分,因此这两个区域的溢出测试就放在一起进行。
从 JDK1.7 开始逐步“去永久代”。对于程序的实际影响。String.intern()是一个 Native 方法,它的作用是:如果字符串常量池中已经包含一个等于此 String 对象的字符串,则返回代表池中这个字符串的 String 对象;否则,将此 String 对象包含的字符串添加到常量池中,并且返回此 String 对象的引用。
while(true){
String.valueOf(i++).intern();
}在 JDK1.6 及之前的版本中,由于常量池分配在永久代内,我们可以通过-XX:PermSize和-XX:MaxPermSize限制方法区大小,从而间接限制其中常量池的容量。并且该代码会导致永久代 OOM。而使用 JDK1.7 运行会导致 Heap OOM。
对于intern()方法来说,在 JDK1.6 和 JDK1.7 中运行是有差异的。产生差异的原因是:在 JDK1.6 中,intern()方法会把首次遇到的字符串实例复制到永久代中,返回的也是永久代中这个字符串实例的引用。而 JDK1.7(以及部分其他虚拟机,例如 JRockit)的intern()实现不会再复制实例,只是在常量池中记录首次出现的实例引用,因此intern()返回的引用和字符串实例是同一个。
程序如果抛出java.lang.OutOfMemoryError: PermGen space错误就表明永久代所在区域的内存已被耗尽。持久代主要存储的是每个类的信息,比如:类加载器引用、运行时常量池(所有常量、字段引用、方法引用、属性)、字段(Field)数据、方法(Method)数据、方法代码、方法字节码等等。因此,我们可以得出出现java.lang.OutOfMemoryError: PermGen space错误的原因是:太多的类或者太大的类被加载到permanent generation(持久代)。
import javassist.ClassPool;
public class MicroGenerator {
public static void main(String[] args) throws Exception {
//通过字节码加载大量的类来填满方法区
for (int i = 0; i < 100000000; i++) {
generate("cn.moondev.User" + i);
}
}
public static Class generate(String name) throws Exception {
ClassPool pool = ClassPool.getDefault();
return pool.makeClass(name).toClass();
}
}运行时请设置 JVM 参数:-XX:MaxPermSize=5m,值越小越好。需要注意的是 JDK8 已经完全移除持久代空间,取而代之的是元空间(Metaspace),所以示例最好的 JDK1.7 或者 1.6 下运行。
Redeploy-time
更复杂和实际的一个例子就是 Redeploy(重新部署)。在从服务器卸载应用程序时,当前的 ClassLoader 以及加载的 Class 在没有实例引用的情况下,持久代的内存空间会被 GC 清理并回收。如果应用中有类的实例对当前的 ClassLoader 的引用,那么 Permgen 区的 Class 将无法被卸载,导致 Permgen 区的内存一直增加直到出现 OOM Permgen space 错误。
不幸的是,许多第三方库以及糟糕的资源处理方式(比如:线程、JDBC驱动程序、文件系统句柄)使得卸载以前使用的类加载器变成了一件不可能的事。反过来就意味着在每次重新部署过程中,应用程序所有的类的先前版本将仍然驻留在Permgen区中,你的每次部署都将生成几十甚至几百M的垃圾。
就以线程和 JDBC 驱动来说说。很多人都会使用线程来处理一下周期性或者耗时较长的任务,这个时候一定要注意线程的生命周期问题,你需要确保线程不能比你的应用程序活得还长。否则,如果应用程序已经被卸载,线程还在继续运行,这个线程通常会维持对应用程序的 ClassLoader 的引用,造成的结果就不再多说。多说一句,开发者有责任处理好这个问题,特别是如果你是第三方库的提供者的话,一定要提供线程关闭接口来处理清理工作。
让我们想象一个使用JDBC驱动程序连接到关系数据库的示例应用程序。当应用程序部署到服务器上的时:服务器创建一个 ClassLoader 实例来加载应用所有的类(包含相应的 JDBC 驱动)。根据 JDBC 规范,JDBC 驱动程序(比如:com.mysql.jdbc.Driver)会在初始化时将自己注册到java.sql.DriverManager中。该注册过程中会将驱动程序的一个实例存储在 DriverManager 的静态字段内,代码可以参考:
package com.mysql.jdbc;
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can\'t register driver!");
}
}
}
//..................................
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
public static synchronized void registerDriver(java.sql.Driver driver,DriverAction da) throws SQLException {
if(driver != null) {
registeredDrivers.addIfAbsent(new DriverInfo(driver, da));
} else {
throw new NullPointerException();
}
}现在,当从服务器上卸载应用程序的时候,java.sql.DriverManager仍将持有那个驱动程序的引用,进而持有用于加载应用程序的 ClassLoader 的一个实例的引用。这个 ClassLoader 现在仍然引用着应用程序的所有类。如果此程序启动时需要加载 2000 个类,占用约 10MB 永久代(PermGen)内存,那么只需要 5~10 次重新部署,就会将默认大小的永久代(PermGen)塞满,然后就会触发java.lang.OutOfMemoryError: PermGen space错误并崩溃。
解决方案
解决初始化时的OutOfMemoryError*
当在应用程序启动期间触发由于PermGen耗尽引起的OutOfMemoryError时,解决方案很简单。 应用程序需要更多的空间来加载所有的类到PermGen区域,所以我们只需要增加它的大小。 为此,请更改应用程序启动配置,并添加(或增加,如果存在)-XX:MaxPermSize参数,类似于以下示例:
java -XX:MaxPermSize=512m com.yourcompany.YourClass解决Redeploy时的`OutOfMemoryError
分析 dump 文件:首先,找出引用在哪里被持有;其次,给 Web 应用程序添加一个关闭的 hook,或者在应用程序卸载后移除引用。你可以使用如下命令导出 dump 文件:
jmap -dump:format=b,file=dump.hprof <process-id>如果是你自己代码的问题请及时修改,如果是第三方库,请试着搜索一下是否存在”关闭”接口,如果没有给开发者提交一个 bug 或者 issue 吧。
解决运行时OutOfMemoryError
首先你需要检查是否允许 GC 从PermGen卸载类,JVM 的标准配置相当保守,只要类一创建,即使已经没有实例引用它们,其仍将保留在内存中,特别是当应用程序需要动态创建大量的类但其生命周期并不长时,允许 JVM 卸载类对应用大有助益,你可以通过在启动脚本中添加以下配置参数来实现:
-XX:+CMSClassUnloadingEnabled默认情况下,这个配置是未启用的,如果你启用它,GC将扫描PermGen区并清理已经不再使用的类。但请注意,这个配置只在UseConcMarkSweepGC的情况下生效,如果你使用其他GC算法,比如:ParallelGC或者Serial GC时,这个配置无效。所以使用以上配置时,请配合:
-XX:+UseConcMarkSweepGC如果你已经确保JVM可以卸载类,但是仍然出现内存溢出问题,那么你应该继续分析dump文件,使用以下命令生成dump文件:
jmap -dump:file=dump.hprof,format=b <process-id>当你拿到生成的堆转储文件,并利用像 Eclipse Memory Analyzer Toolkit 这样的工具来寻找应该卸载却没被卸载的类加载器,然后对该类加载器加载的类进行排查,找到可疑对象,分析使用或者生成这些类的代码,查找产生问题的根源并解决它。
方法区溢出也是一种常见的内存溢出异常,一个类要被垃圾收集器回收掉,判定条件是比较苛刻的。在经常动态生成大量 Class 的应用中,需要特别注意类的回收状况。这类场景除了上面提到的程序使用字节码增强和动态语言之外,常见的还有:大量 JSP 或动态产生 JSP 文件的应用(JSP 第一次运行时需要编译为 Java 类)、基于 OSGi 的应用(即使是同一个类文件,被不同的加载器加载也会视为不同的类)等。
直接内存溢出
DirectMemory 容量可通过-XX:MaxDirectMemorySize指定,如果不指定,则默认与 Java 堆最大值(-Xmx指定)一样。示例代码越过了 DirectByteBuffer 类,直接通过反射获取 Unsafe 实例进行内存分配(Unsafe 类的getUnsafe()方法限制了只有引导类加载器才会返回实例,也就是设计者希望只rt.jar中的类才能使用 Unsafe 的功能)。因为,虽然使用 DirectByteBuffer 分配内存也会抛出内存溢出异常,但它抛出异常时并没有真正向操作系统申请分配内存,而是通过计算得知内存无法分配,于是手动抛出异常,真正申请分配内存的方法是unsafe. allocateMemory()。
public class DirectMemoryOOM {
private static final int _1MB = 1024 * 1024;
public static void main(String[] args) throws Exception {
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
while (true) {
unsafe.allocateMemory(_1MB);
}
}由 DirectMemory 导致的内存溢出,一个明显的特征是在 Heap Dump 文件中不会看见明显的异常,如果读者发现 OOM 之后 Dump 文件很小,而程序中又直接或间接使用了 NIO,那就可以考虑检查一下是不是这方面的原因。
GC overhead limit exceeded
JRE 包含一个内置的垃圾回收进程,而在许多其他的编程语言中,开发者需要手动分配和释放内存。
Java 应用程序只需要开发者分配内存,每当在内存中特定的空间不再使用时,一个单独的垃圾收集进程会清空这些内存空间。垃圾收集器怎样检测内存中的某些空间不再使用已经超出本文的范围,但你只需要相信 GC 可以做好这些工作即可。
默认情况下,当应用程序花费超过 98% 的时间用来做 GC 并且回收了不到 2% 的堆内存时,会抛出java.lang.OutOfMemoryError:GC overhead limit exceeded错误。具体的表现就是你的应用几乎耗尽所有可用内存,并且GC多次均未能清理干净。
下面的代码初始化一个map并在无限循环中不停的添加键值对,运行后将会抛出GC overhead limit exceeded错误
public class Wrapper {
public static void main(String args[]) throws Exception {
Map map = System.getProperties();
Random r = new Random();
while (true) {
map.put(r.nextInt(), "value");
}
}
}正如你所预料的那样,程序不能正常的结束,事实上,当我们使用如下参数启动程序时:
java -Xmx100m -XX:+UseParallelGC Wrapper我们很快就可以看到程序抛出java.lang.OutOfMemoryError: GC overhead limit exceeded错误。但如果在启动时设置不同的堆空间大小或者使用不同的GC算法,比如这样:
java -Xmx10m -XX:+UseParallelGC Wrapper我们将看到如下错误:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Hashtable.rehash(Unknown Source)
at java.util.Hashtable.addEntry(Unknown Source)
at java.util.Hashtable.put(Unknown Source)
at com.tarot.Wrapper.main(Wrapper.java:12)使用以下GC算法:-XX:+UseConcMarkSweepGC 或者-XX:+UseG1GC,启动命令如下:
java -Xmx100m -XX:+UseConcMarkSweepGC Wrapper
java -Xmx100m -XX:+UseG1GC Wrapper得到的结果是这样的:
Exception: java.lang.OutOfMemoryError thrown from
the UncaughtExceptionHandler in thread "main"错误已经被默认的异常处理程序捕获,并且没有任何错误的堆栈信息输出。
以上这些变化可以说明,在资源有限的情况下,你根本无法无法预测你的应用是怎样挂掉的,什么时候会挂掉,所以在开发时,你不能仅仅保证自己的应用程序在特定的环境下正常运行。
解决方案
首先是一个毫无诚意的解决方案,如果你仅仅是不想看到java.lang.OutOfMemoryError:GC overhead limit exceeded的错误信息,可以在应用程序启动时添加如下JVM参数:
-XX:-UseGCOverheadLimit但是强烈建议不要使用这个选项,因为这样并没有解决任何问题,只是推迟了错误出现的时间,错误信息也变成了我们更熟悉的java.lang.OutOfMemoryError: Java heap space而已。
另一个解决方案,如果你的应用程序确实内存不足,增加堆内存会解决GC overhead limit问题,就如下面这样,给你的应用程序1G的堆内存:
java -Xmx1024m com.yourcompany.YourClass但如果你想确保你已经解决了潜在的问题,而不是掩盖java.lang.OutOfMemoryError: GC overhead limit exceeded错误,那么你不应该仅止步于此。你要记得还有profilers和memory dump analyzers这些工具,你需要花费更多的时间和精力来查找问题。还有一点需要注意,这些工具在 Java 运行时有显著的开销,因此不建议在生产环境中使用。
Unable to create new native thread
JVM 中的线程完成自己的工作也是需要一些空间的,当有足够多的线程却没有那么多的空间时就会像这样:
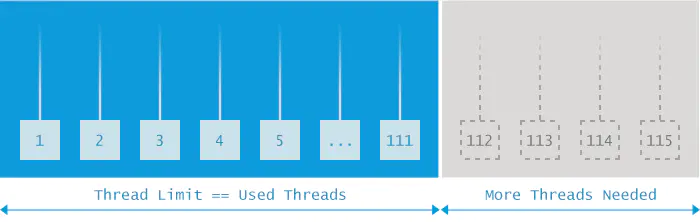
出现java.lang.OutOfMemoryError:Unable to create new native thread就意味着Java应用程序已达到其可以启动线程数量的极限了。
原因分析
当 JVM 向 OS 请求创建一个新线程时,而OS却无法创建新的native线程时就会抛出Unable to create new native thread错误。一台服务器可以创建的线程数依赖于物理配置和平台,建议运行下文中的示例代码来测试找出这些限制。总体上来说,抛出此错误会经过以下几个阶段:
- 运行在 JVM 内的应用程序请求创建一个新的线程
- JVM 向 OS 请求创建一个新的 native 线程
- OS 尝试创建一个新的 native 线程,这时需要分配内存给新的线程
- OS 拒绝分配内存给线程,因为 32 位 Java 进程已经耗尽内存地址空间(2-4 GB内存地址已被命中)或者 OS 的虚拟内存已经完全耗尽
Unable to create new native thread错误将被抛出
解决方案
可以通过在 OS 级别增加线程数限制来绕过这个错误。如果你限制了 JVM 可在用户空间创建的线程数,那么你可以检查并增加这个限制:
// macOS 10.12上执行
$ ulimit -u
709Out of swap space
Java 应用程序在启动时会指定所需要的内存大小,可以通过-Xmx和其他类似的启动参数来指定。在 JVM 请求的总内存大于可用物理内存的情况下,操作系统会将内存中的数据交换到磁盘上去。
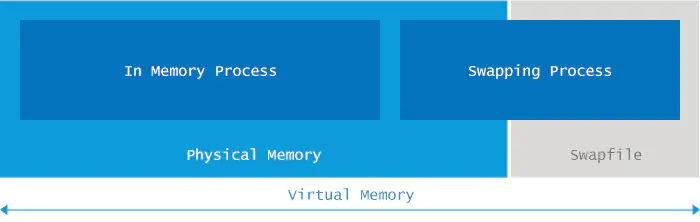
Out of swap space表示交换空间也将耗尽,并且由于缺少物理内存和交换空间,再次尝试分配内存也将失败。
原因分析
当应用程序向 JVM native heap 请求分配内存失败并且 native heap 也即将耗尽时,JVM会抛出Out of swap space错误。该错误消息中包含分配失败的大小(以字节为单位)和请求失败的原因。
Native Heap Memory 是 JVM 内部使用的 Memory,这部分的 Memory 可以通过 JDK 提供的 JNI 的方式去访问,这部分 Memory 效率很高,但是管理需要自己去做,如果没有把握最好不要使用,以防出现内存泄露问题。JVM 使用 Native Heap Memory 用来优化代码载入(JTI 代码生成),临时对象空间申请,以及 JVM 内部的一些操作。
这个问题往往发生在 Java 进程已经开始交换的情况下,现代的 GC 算法已经做得足够好了,当时当面临由于交换引起的延迟问题时,GC 暂停的时间往往会让大多数应用程序不能容忍。
java.lang.OutOfMemoryError:Out of swap space往往是由操作系统级别的问题引起的,例如:
- 操作系统配置的交换空间不足。
- 系统上的另一个进程消耗所有内存资源。
还有可能是本地内存泄漏导致应用程序失败,比如:应用程序调用了native code连续分配内存,但却没有被释放。
解决方案
通常最简单的方法就是增加交换空间,不同平台实现的方式会有所不同,比如在 Linux 下可以通过如下命令实现:
# 创建并附加一个大小为640MB的新交换文件
swapoff -a
dd if=/dev/zero of=swapfile bs=1024 count=655360
mkswap swapfile
swapon swapfileJava GC 会扫描内存中的数据,如果是对交换空间运行垃圾回收算法会使GC暂停的时间增加几个数量级,因此你应该慎重考虑使用上文增加交换空间的方法。
如果你的应用程序部署在 JVM 需要同其他进程激烈竞争获取资源的物理机上,建议将服务隔离到单独的虚拟机中。但在许多情况下,您唯一真正可行的替代方案是:
- 升级机器以包含更多内存
- 优化应用程序以减少其内存占用
当您转向优化路径时,使用内存转储分析程序来检测内存中的大分配是一个好的开始。
Requested array size exceeds VM limit
Java 对应用程序可以分配的最大数组大小有限制。不同平台限制有所不同,但通常在1到21亿个元素之间。

当你遇到Requested array size exceeds VM limit错误时,意味着你的应用程序试图分配大于 Java 虚拟机可以支持的数组。
原因分析
该错误由 JVM 中的native code抛出。JVM 在为数组分配内存之前,会执行特定于平台的检查:分配的数据结构是否在此平台中是可寻址的。
你很少见到这个错误是因为 Java 数组的索引是 int 类型。Java 中的最大正整数为2 ^ 31 - 1。 并且平台特定的限制可以非常接近这个数字,例如:我的环境上(64 位 macOS,运行 JDK1.8)可以初始化数组的长度高达Integer.MAX_VALUE-2。如果再将数组的长度增加1到 Integer.MAX_VALUE-1 会导致熟悉的 OutOfMemoryError。
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit但是,在使用 OpenJDK 6 的 32 位 Linux 上,在分配具有大约 11 亿个元素的数组时,您将遇到Requested array size exceeded VM limit的错误。 要理解你的特定环境的限制,运行下文中描述的小测试程序。
for (int i = 3; i >= 0; i--) {
try {
int[] arr = new int[Integer.MAX_VALUE-i];
System.out.format("Successfully initialized an array with %,d elements.\n", Integer.MAX_VALUE-i);
} catch (Throwable t) {
t.printStackTrace();
}
}该示例重复四次,并在每个回合中初始化一个长原语数组。 该程序尝试初始化的数组的大小在每次迭代时增加 1,最终达到 Integer.MAX_VALUE。 现在,当使用 Hotspot 7 在 64 位 Mac OS X 上启动代码片段时,应该得到类似于以下内容的输出:
java.lang.OutOfMemoryError: Java heap space
at eu.plumbr.demo.ArraySize.main(ArraySize.java:8)
java.lang.OutOfMemoryError: Java heap space
at eu.plumbr.demo.ArraySize.main(ArraySize.java:8)
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at eu.plumbr.demo.ArraySize.main(ArraySize.java:8)
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at eu.plumbr.demo.ArraySize.main(ArraySize.java:8)注意,在出现Requested array size exceeded VM limit之前,出现了更熟悉的Java heap space。 这是因为初始化2 ^ 31 - 1个元素的数组需要腾出 8G 的内存空间,大于 JVM 使用的默认值。
解决方案
java.lang.OutOfMemoryError:Requested array size exceeds VM limit可能会在以下任一情况下出现:
- 数组增长太大,最终大小在平台限制和
Integer.MAX_INT之间 - 你有意分配大于
2 ^ 31 - 1个元素的数组
在第一种情况下,检查你的代码库,看看你是否真的需要这么大的数组。也许你可以减少数组的大小,或者将数组分成更小的数据块,然后分批处理数据。
在第二种情况下,记住 Java 数组是由 int 索引的。因此,当在平台中使用标准数据结构时,数组不能超过2 ^ 31-1个元素。事实上,在编译时就会出错:error:integer number too large。
Kill process or sacrifice child
操作系统是建立在进程的概念之上,这些进程在内核中作业,其中有一个非常特殊的进程,名叫“内存杀手(Out of memory killer)”。当内核检测到系统内存不足时,OOM killer被激活,然后选择一个占用内存最多的进程杀掉。
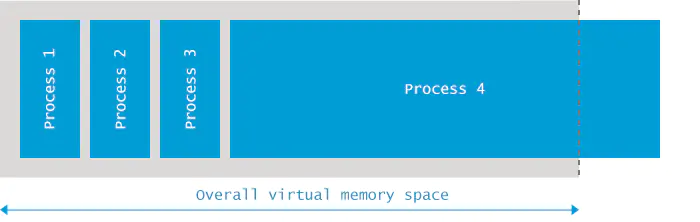
当可用虚拟虚拟内存(包括交换空间)消耗到让整个操作系统面临风险时,就会产生Out of memory:Kill process or sacrifice child错误。在这种情况下,OOM Killer 会选择“流氓进程”并杀死它。
原因分析
默认情况下,Linux 内核允许进程请求比系统中可用内存更多的内存,但大多数进程实际上并没有使用完他们所分配的内存。
一般情况下都没有问题,但当大多数应用程序都消耗完自己的内存时,麻烦就来了,因为这些应用程序的内存需求加起来超出了物理内存(包括 swap)的容量,内核(OOM killer)必须杀掉一些进程才能腾出空间保障系统正常运行。
示例
当你在Linux上运行如下代码:
public static void main(String[] args){
List<int[]> l = new java.util.ArrayList();
for (int i = 10000; i < 100000; i++) {
try {
l.add(new int[100000000]);
} catch (Throwable t) {
t.printStackTrace();
}
}
}在 Linux 的系统日志中/var/log/kern.log会出现以下日志:
Jun 4 07:41:59 plumbr kernel: [70667120.897649] Out of memory: Kill process 29957 (java) score 366 or sacrifice child
Jun 4 07:41:59 plumbr kernel: [70667120.897701] Killed process 29957 (java) total-vm:2532680kB, anon-rss:1416508kB, file-rss:0kB注意:你可能需要调整交换文件和堆大小,否则你将很快见到熟悉的Java heap space异常。在原作者的测试用例中,使用-Xmx2g指定的2g堆,并具有以下交换配置:
swapoff -a
dd if=/dev/zero of=swapfile bs=1024 count=655360
mkswap swapfile
swapon swapfile