主要介绍了 ZooKeeper 的部署、客户端脚本的使用以及开发人员使用的原生客户端 API 以及 Curator 封装的更易用的客户端 API。
客户端脚本
连接
| 命令 | 说明 |
|---|---|
sh zkCli.sh |
默认连接 localhost:2181 |
sh zkCli.sh -server ip:port |
连接指定 zk 服务器 |
创建
| 命令 | 说明 |
|---|---|
create [-s] [-e] path data acl |
创建一个 zk 节点,不添加[-s][-e]参数默认为持久节点,[-s]为顺序节点,[-e]为临时节点 |
读取
| 命令 | 说明 |
|---|---|
ls path [watch] |
列出 ZooKeeper 指定节点下的所有子节点 |
get path [watch] |
获取 ZooKeeper 指定节点的数据内容和属性信息 |
第一次部署的 ZooKeeper 集群,默认在根节点
/下面有一个叫作/zookeeper的保留节点。
更新
| 命令 | 说明 |
|---|---|
set path data [version] |
更新指定节点的数据内容 |
删除
| 命令 | 说明 |
|---|---|
delete path [version] |
删除指定节点 |
原生客户端API
ZooKeeper 作为一个分布式服务框架,主要用来解决分布式数据一致性问题,它提供了简单的分布式原语,并且对多种编程语言提供了 API。
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>${zookeeper.version}</version>
</dependency>创建会话
客户端可以通过创建一个 ZooKeeper(org.apache.zookeeper.ZooKeeper)实例来连接 ZooKeeper 服务器。ZooKeeper 的 4 种构造方法如下。
public ZooKeeper(
String connectString,
int sessionTimeout,
Watcher watcher,
boolean canBeReadOnly
);
public ZooKeeper(
String connectString,
int sessionTimeout,
Watcher watcher,
long sessionId,
byte[] sessionPasswd
);使用任意一个构造方法都可以顺利完成与 ZooKeeper 服务器的会话(Session)创建。

注意:
ZooKeeper 客户端和服务端会话的建立是一个异步的过程,也就是说在程序中,构造方法会在处理完客户端初始化工作后立即返回,在大多数情况下,此时并没有真正建立好一个可用的会话,在会话的生命周期中处于“CONNECTION”的状态。
当该会话真正创建完毕后,ZooKeeper 服务端会向会话对应的客户端发送一个事件通知,以告知客户端,客户端只有在获取这个通知之后,才算真正建立了会话。
构造方法内部实现了与 ZooKeeper 服务器之间的 TCP 连接创建,负责维护客户端会话的生命周期。
创建一个最基本的 Zookeeper 会话实例
public static void main(String[] args) throws IOException, InterruptedException {
CountDownLatch cdl = new CountDownLatch(1);
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event);
if (Event.KeeperState.SyncConnected == event.getState()) {
cdl.countDown();
}
}
});
cdl.await();
System.out.println("Zookeeper session established.");
}创建节点
客户端可以通过 ZooKeeper 的 API 来创建一个数据节点,有如下两个接口
//同步创建节点
public String create(
final String path,
byte[] data,
List<ACL> acl,
CreateMode createMode);
//异步创建节点
public void create(
final String path,
byte[] data,
List<ACL> acl,
CreateMode createMode,
StringCallback cb,
Object ctx);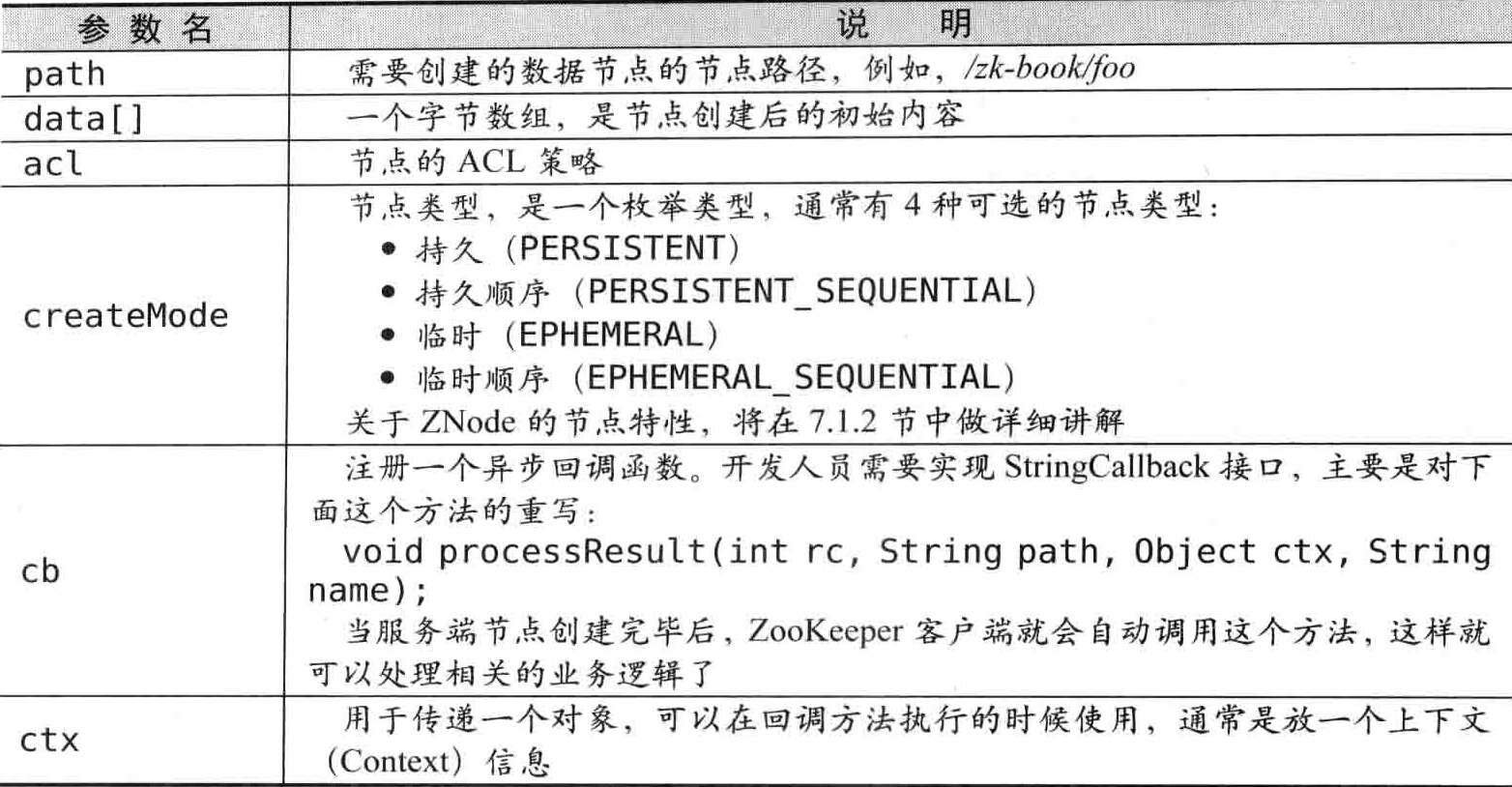
需要注意几点,无论是同步还是异步接口,ZooKeeper 都不支持递归创建,即无法在父节点不存在的情况下创建一个子节点。另外,如果一个节点已经存在了,那么创建同名节点的时候,会抛出 NodeExistsException 异常。
目前,ZooKeeper 的节点内容只支持byte[]类型,也就是说,ZooKeeper 不负责为节点内容进行序列化,开发人员需要自己使用序列化工具将节点内容进行序列化和反序列化。对于字符串,可以简单地使用String.getBytes()来生成一个字节数组;对于其他复杂对象,可以使用专门的序列化工具来进行序列化。
关于权限控制,如果你的应用场景没有太高的权限要求,那么可以不关注这个参数,只需要在 acl 参数中传入参数Ids.OPEN_ACL_UNSAFE,这就表明之后对这个节点的任何操作都不受权限控制。
使用同步API创建一个节点
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
CountDownLatch cdl = new CountDownLatch(1);
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event);
if (Event.KeeperState.SyncConnected == event.getState()) {
cdl.countDown();
}
}
});
cdl.await();
System.out.println("Zookeeper session established.");
String path1 = zooKeeper.create("zk-test-ephemeral-",
"data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
System.out.println("Success create znode: " + path1);
String path2 = zooKeeper.create("zk-test-ephemeral-",
"data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Success create znode: " + path2);
}
//Receive watched event: WatchedEvent state:SyncConnected type:None path:null
//Zookeeper session established.
//Success create znode: /zk-test-ephemeral-
//Success create znode: /zk-test-ephemeral-0000000002临时顺序节点(EPHEMERAL_SEQUENTIAL)会比临时节点(EPHEMERAL)在创建时,节点后缀多加一个数字。
使用异步API创建一个节点
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
CountDownLatch cdl = new CountDownLatch(1);
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 5000, new Watcher() {
@Override
public void process(WatchedEvent event) {
System.out.println("Receive watched event: " + event);
if (Event.KeeperState.SyncConnected == event.getState()) {
cdl.countDown();
}
}
});
cdl.await();
System.out.println("Zookeeper session established.");
zooKeeper.create("/zk-test-ephemera-",
"data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL,
new IStringCallback(),
"I am context");
zooKeeper.create("/zk-test-ephemera-",
"data".getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL,
new IStringCallback(),
"ctx");
Thread.sleep(Integer.MAX_VALUE);
}
static class IStringCallback implements AsyncCallback.StringCallback {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
System.out.println("Create path result:[" + rc + ", " + path + ", "
+ ctx + ", real path name:" + name + "]");
}
}AsyncCallback 包含 StatCallback、DataCallback、ACLCallback、ChildrenCallback、Children2Callback、StringCallback 和 VoidCallback 七种不同的回调接口,用户可以在不同的异步接口中实现不同的接口。
和同步接口方法最大的区别在于,节点的创建过程(包括网络通信和服务端的节点创建过程)是异步的。并且,在同步接口调用过程中,我们需要关注接口抛出异常的可能;但是在异步接口中,接口本身是不会抛出异常的,所有的异常都会在回调函数中通过 Result Code(响应码)来体现。
processResult方法参数说明

删除节点
客户端可以通过 ZooKeeper 的 API 来删除一个节点,有如下两个接口:
public void delete(final String path, int version);
public void delete(final String path, int version, VoidCallback cb, Object ctx);
需要注意的是,在 Zookeeper 中,只允许删除叶子节点。也就是说,如果一个节点存在至少一个子节点的话,那么该节点将无法被直接删除,必须先删除掉其所有子节点。
读取数据
读取数据,包括子节点列表的获取和节点数据的获取。ZooKeeper 分别提供了不同的 API 来获取数据。
getChildren
客户端可以通过 ZooKeeper 的 API 来获取一个节点的所有子节点,有如下8个接口可供使用:
public List<String> getChildren(final String path, Watcher watcher);
public List<String> getChildren(String path, boolean watch);
public void getChildren(final String path, Watcher watcher, ChildrenCallback cb, Object ctx);
public void getChildren(String path, boolean watch, ChildrenCallback cb, Object ctx);
public List<String> getChildren(final String path, Watcher watcher, Stat stat);
public List<String> getChildren(String path, boolean watch, Stat stat);
public void getChildren(final String path, Watcher watcher, Children2Callback cb, Object ctx);
public void getChildren(String path, boolean watch, Children2Callback cb, Object ctx);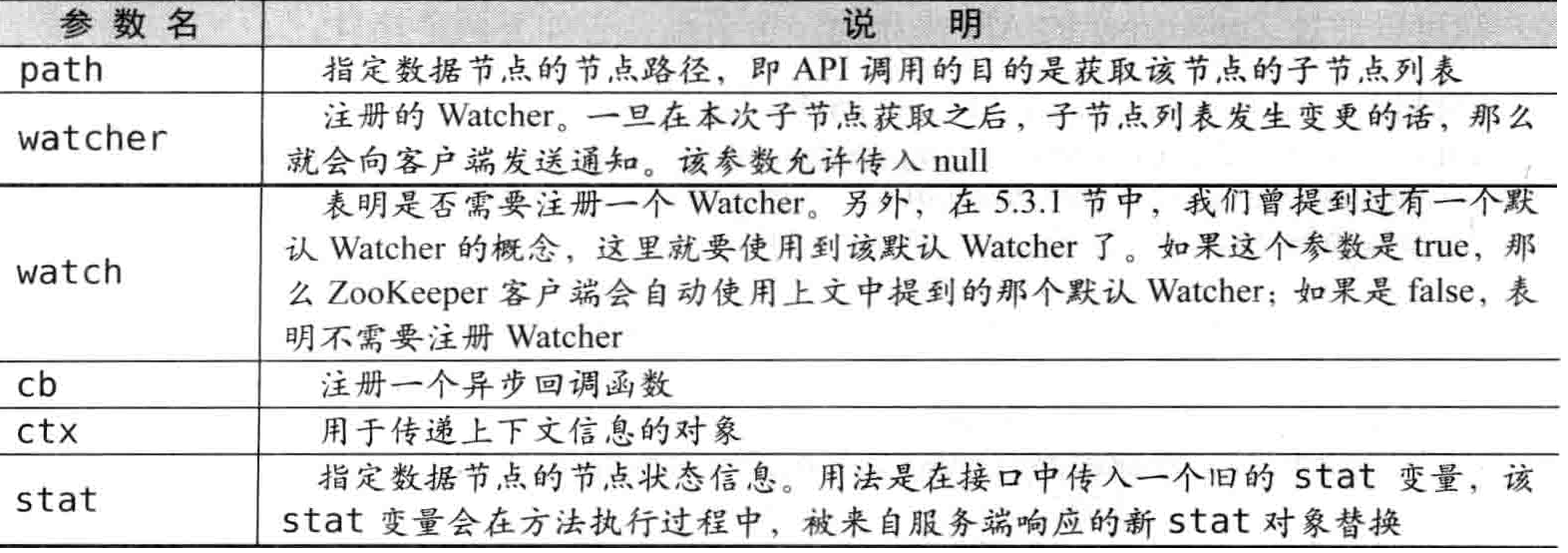
关于 Watcher,这里简单提一点,ZooKeeper 服务端在向客户端发送 Watcher “Node Children Changed” 事件通知的时候,仅仅只会发出一个通知,而不会把节点的变化情况发送给客户端,需要客户端自己重新获取。另外,由于 Watcher 通知是一次性的,即一旦触发一次通知后,该 Watcher 就失效了,因此客户端需要反复注册 Watcher。
getData
客户端可以通过 ZooKeeper 的 API 来获取一个节点的数据内容,有如下 4 个接口:
public byte[] getData(final String path, Watcher watcher, Stat stat);
public byte[] getData(String path, boolean watch, Stat stat);
public void getData(final String path, Watcher watcher, DataCallback cb, Object ctx);
public void getData(String path, boolean watch, DataCallback cb, Object ctx);
更新数据
客户端可以通过 ZooKeeper 的 APl 来更新一个节点的数据内容,有如下两个接口:
public Stat setData(final String path, byte[] data, int version);
public void setData(final String path, byte[] data, int version, StatCallback cb, Object ctx)
version 参数用于指定节点的数据版本,表明本次更新操作是针对指定的数据版本进行的。但是,上面提到的读取数据的接口 getData 中,并没有提供根据指定数据版本来获取数据的接口,那么,这里指定数据版本更新的意义何在呢?
这与 CAS 的原理有关,通俗地讲,CAS 的意思就是:“对于值 V,每次更新前都会比对其值是否是预期值 A,只有符合预期,才会将 V 原子化地更新到新值 B。”。ZooKeeper 的 setData 接口中的 version 参数正是由 CAS 原理衍化而来的。ZooKeeper 每个节点都有数据版本的概念,在调用更新操作的时候,就可以添加 version 这个参数,该参数可以对应于 CAS 原理中的“预期值”,表明是针对该数据版本进行更新的。具体来说,假如一个客户端试图进行更新操作,它会携带上次获取到的 version 值进行更新。而如果在这段时间内,ZooKeeper 服务器上该节点的数据恰好已经被其他客户端更新了,那么其数据版本一定也发生了变化,因此肯定与客户端携带的 version 无法匹配,于是便无法更新成功——因此可以有效地避免些分布式更新的并发问题,ZooKeeper 的客户端就可以利用该特性构建更复杂的应用场景,例如分布式锁服务等。
版本号如果传入 -1,说明客户端需要基于数据的最新版本进行更新操作。
每次更新都会将版本号增一。
删除数据
客户端可以通过 ZooKeeper 的 APl 来删除一个节点的数据内容,有如下两个接口:
public void delete(final String path, int version);
public void delete(final String path, int version, VoidCallback cb, Object ctx);检测节点是否存在
客户端可以通过 ZooKeeper 的 API 来检测节点是否存在,有如下 4 个接口:
public Stat exists(final String path, Watcher watcher);
public Stat exists(String path, boolean watch);
public void exists(final String path, Watcher watcher, StatCallback cb, Object ctx);
public void exists(String path, boolean watch, StatCallback cb, Object ctx);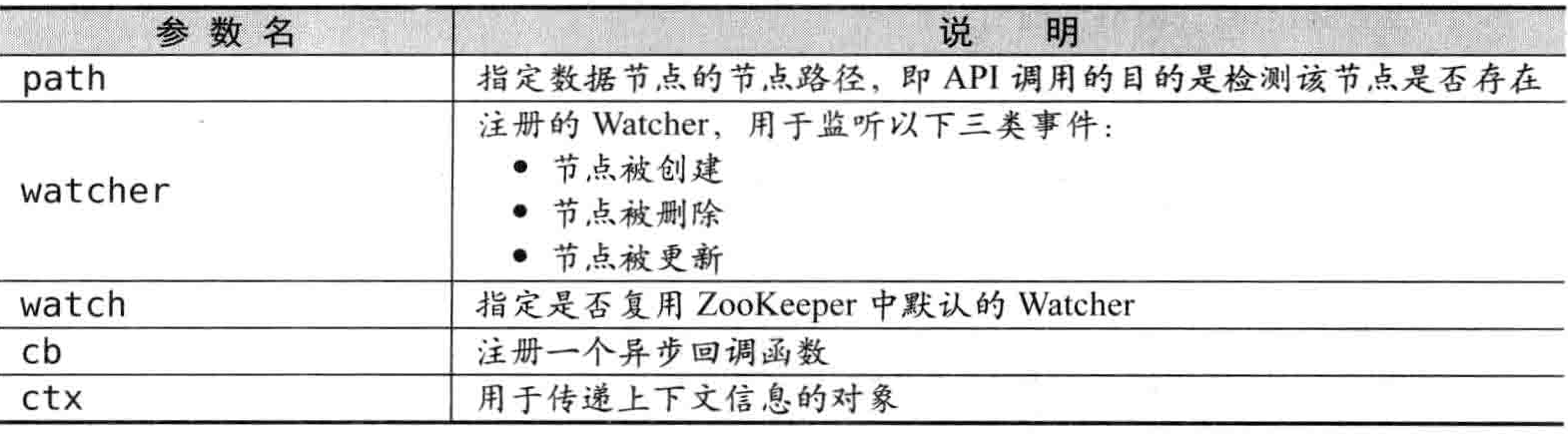
exists 接口特性
- 无论指定节点是否存在,通过调用 exists 接口都可以注册 Watcher。
- exists 接口中注册的 Watcher,能够对节点创建、节点删除和节点数据更新事件进行监听。
- 对于指定节点的子节点的各种变化,都不会通知客户端
权限控制
在 ZooKeeper 的实际使用中,我们的做法往往是搭建一个共用的 ZooKeeper 集群,统一为若干个应用提供服务。在这种情况下,不同的应用之间往往是不会存在共享数据的使用场景的,因此需要解决不同应用之间的权限问题。
为了避免存储在 ZooKeeper 服务器上的数据被其他进程干扰或人为操作修改,需要对 ZooKeeper 上的数据访问进行权限控制(Access Control)。ZooKeeper 提供了 ACL 的权限控制机制,简单的讲,就是通过设置 ZooKeeper 服务器上数据节点的 ACL,来控制客户端对该数据节点的访问权限:如果一个客户端符合该 ACL 控制,那么就可以对其进行访问,否则将无法操作。
开发人员如果要使用 ZooKeeper 的权限控制功能,需要在完成 ZooKeeper 会话创建后,给该会话添加上相关的权限信息(AuthInfo)。ZooKeeper 客户端提供了相应的 API 接口来进行权限信息的设置,如下:
addAuthInfo(String scheme, byte[] auth);
使用包含权限信息的ZooKeeper会话创建数据节点
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 50000, null);
zooKeeper.addAuthInfo("digest", "foo:true".getBytes());
zooKeeper.create("/zk-test-ephemera",
"init".getBytes(),
ZooDefs.Ids.CREATOR_ALL_ACL,
CreateMode.EPHEMERAL);
Thread.sleep(Integer.MAX_VALUE);
}使用无权限信息的ZooKeeper会话访问含权限信息的数据节点
public static void main(String[] args) throws Exception {
ZooKeeper zooKeeper = new ZooKeeper("127.0.0.1:2181", 50000, null);
zooKeeper.addAuthInfo("digest", "foo:true".getBytes());
zooKeeper.create("/zk-test-ephemera",
"init".getBytes(),
ZooDefs.Ids.CREATOR_ALL_ACL,
CreateMode.EPHEMERAL);
ZooKeeper zooKeeper2 = new ZooKeeper("127.0.0.1:2181", 50000, null);
// zooKeeper2.addAuthInfo("digest", "foo:true".getBytes());
zooKeeper2.getData("/zk-test-ephemera", true, null);
Thread.sleep(Integer.MAX_VALUE);
}不包含权限信息的客户端会话对其进行访问会输出相关异常信息:
KeeperErrorCode = NoAuth for /zk-test-ephemera
删除节点接口的权限控制
删除节点接口的权限控制比较特殊,当客户端对一个数据节点添加了权限信息后,对于删除操作而言,其作用范围是其子节点。也就是说,当我们对一个数据节点添加权限信息后,依然可以自由地删除这个节点,但是对于这个节点的子节点,就必须使用相应的权限信息才能够删除它。
Curator客户端API
Curator 是 Netflix 公司开源的一套 ZooKeeper 客户端框架,作者是 Jordan Zimmerman。和 ZkClient 一样,Curator 解决了很多 ZooKeeper 客户端非常底层的细节开发工作,包括连接重连、反复注册 Watcher 和 NodeExistsException 异常等,目前已经成为了 Apache 的顶级项目,是全世界范围内使用最广泛的 ZooKeeper 客户端之一,Patrick Hunt(ZooKeeper 代码的核心提交者)以一句 Guava is to Java what Curator is to ZooKeeper 对其进行了高度评价。
除了封装一些开发人员不需要特别关注的底层细节之外,Curator 还在 ZooKeeper 原生 API 的基础上进行了包装,提供了一套易用性和可读性更强的 Fluent 风格的客户端 API 框架。
除此之外,Curator 中还提供了 ZooKeeper 各种应用场景(Recipe,如共享锁服务、Master 选举机制和分布式计数器等)的抽象封装。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.4.2</version>
</dependency>创建会话
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
//隔离命名空间
.namespace("base")
.build();
client.start();| 重试策略 | 说明 |
|---|---|
| ExponentialBackoffRetry | 指数增长间隔型重试 |
| RetryNTimes | 重试多次 |
| RetryOneTime | 重试一次 |
| RetryUntilElapsed | 超时重试 |
也可以通过实现 RetryPolicy 接口的方式自定义重试策略
public interface RetryPolicy
{
/**
* Called when an operation has failed for some reason. This method should return
* true to make another attempt.
*
*
* @param retryCount the number of times retried so far (0 the first time)
* @param elapsedTimeMs the elapsed time in ms since the operation was attempted
* @param sleeper use this to sleep - DO NOT call Thread.sleep
* @return true/false
*/
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper);
}创建节点
在 Curator 中,可以通过以下 API 来创建节点:
CuratorFramework
-- CreateBuilder create();
CreateBuilder
-- ProtectACLCreateModePathAndBytesable<String> creatingParentsIfNeeded();
-- ACLPathAndBytesable<String> withProtectedEphemeralSequential();
-- ACLCreateModeBackgroundPathAndBytesable<String> withProtection();
CreateModable
-- T withMode(CreateMode mode);
PathAndBytesable
-- T forPath(String path, byte[] data);
-- T forPath(String path);以下是适用场景及示例
创建一个节点,初始内容为空
client.create().forPath(path);注意,如果没有设置节点属性,那么 Curator 默认创建的是持久节点,内容默认是空。这里的 client 是指上文中提到的一个已经完成会话创建并启动的 Curator 客户端实例,即 CuratorFramework 对象实例。
创建一个节点,附带初始内容
client.create().forPath(path, "init".getBytes());也可以在创建节点的时候写入初始节点内容。和 ZkClient 不同的是,Curator 仍然是按照 ZooKeeper 原生 API 的风格,使用
byte[]作为方法参数。创建一个临时节点,初始内容为空
client.create().withMode(CreateMode.EPHEMERAL).forPath(path);创建一个临时节点,并自动递归创建父节点
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path);这个接口非常有用,在使用 ZooKeeper 的过程中,开发人员经常会碰到 NoNodeException 异常,其中一个可能的原因就是试图对一个不存在的父节点创建子节点。因此,开发人员不得不在每次创建节点之前,都判断一下该父节点是否存在 —— 这个处理通常让人厌恶。在使用 Curator 之后,通过调用
creatingParentsIfNeeded接口,Curator 就能够自动地递归创建所有需要的父节点。同时要注意的一点是,由于在 ZooKeeper 中规定了所有非叶子节点必须为持久节点,调用上面这个 API 之后,只有 path 参数对应的数据节点是临时节点,其父节点均为持久节点。
删除节点
在 Curator 中,可以通过以下 API 来删除指定节点:
CuratorFramework
-- DeleteBuilder delete();
Versionable<T>
-- T withVersion(int version);
DeleteBuilder
-- DeleteBuilderBase guaranteed();
PathAndBytesable<T>
-- T forPath(String path, byte[] data);
-- T forPath(String path);以下是适用场景及示例
删除一个节点
client.delete().forPath(path);注意,使用该接口,只能删除叶子节点。
删除一个节点,并递归删除其所有子节点
client.delete().deletingChildrenIfNeeded().forPath(path);删除一个节点,强制指定版本进行删除
client.delete().withVersion(version).forPath(path);删除一个节点,强制保证删除
client.delete().guaranteed().forPath(path);注意,
guaranteed()接口是一个保障措施,只要客户端会话有效,那么 Curator 会在后台持续进行删除操作,直到节点删除成功。
这里重点讲解guaranteed()这个方法。正如该接口的官方文档中所注明的,在 ZooKeeper 客户端使用过程中,可能会碰到这样的问题:客户端执行一个删除节点操作,但是由于一些网络原因,导致删除操作失败。对于这个异常,在有些场景中是致命的,如“Master选举” —— 在这个场景中,ZooKeeper 客户端通常是通过节点的创建与删除来实现的。针对这个问题,Curator 中引入了一种重试机制:如果我们调用了guaranteed()方法,那么当客户端碰到上面这些网络异常的时候,会记录下这次失败的删除操作,只要客户端会话有效,那么其就会在后台反复重试,直到节点删除成功。通过这样的措施,就可以保证节点删除操作一定会生效。
读取数据
在 Curator 中,可以通过以下 API 来获取节点的数据内容:
CuratorFramework
-- GetDataBuilder getData();
Statable<T>
-- T storingStatIn(Stat stat);
Pathable<T>
-- T forPath(String path);以下是适用场景及示例
读取一个节点的数据内容
client.getData().forPath(path);读取一个节点的数据内容,同时获取到该节点的 stat
client.getData().storingStatIn(stat).forPath(path);
Curator 通过传入一个旧的 stat 变量的方式来存储服务端返回的最新的节点状态信息。
更新数据
在 Curator 中,可以通过以下 API 来获取节点的数据内容:
CuratorFramework
-- SetDataBuilder setData();
Versionable<T>
-- T withVersion(int version);
PathAndBytesable<T>
-- T forPath(String path, byte[] data);
-- T forPath(String path);以下是适用场景及示例
更新一个节点的数据内容
client.setData().forPath(path);调用该接口后,会返回一个 stat 对象。
更新一个节点的数据内容,强制指定版本进行更新
client.setData().withVersion(version).forPath(path);注意,withVersion 接口就是用来实现 CAS 的,version(版本信息)通常是从一个旧的 stat 对象中获取到的。
异步接口
Curator 中引入了 BackgroundCallback 接口,用来处理异步接口调用之后服务端返回的结果信息,其接口定义如下。
/**
* Functor for an async background operation
*/
public interface BackgroundCallback
{
/**
* Called when the async background operation completes
*
* @param client the client
* @param event operation result details
* @throws Exception errors
*/
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception;
}| 参数名 | 说明 |
|---|---|
| client | 当前客户端实例 |
| event | 服务端实例 |
对于 BackgroundCallback 接口,我们重点来看 CuratorEvent 这个参数。
CuratorEvent 定义了 ZooKeeper 服务端发送到客户端的一系列事件参数,其中比较重要的有事件类型和响应码两个参数。
事件类型(CuratorEventType)
| 事件类型 | 代表操作 |
|---|---|
| CREATE | Curator Framework#create() |
| DELETE | Curator Framework#delete() |
| EXISTS | Curator Framework#checkExists() |
| GET_DATA | Curator Framework#getData() |
| SET_DATA | Curator Framework#setData() |
| CHILDREN | Curator Framework#getChildren() |
| SYNC | Curator Framework#sync(String, Object) |
| GET_ACL | Curator Framework#getACL() |
| WATCHED | Watchable#usingWatcher(Watcher) / Watchable#watched() |
| CLOSING | ZooKeeper客户端与服务端连接断开事件 |
响应码(int)
响应码用于标识事件的结果状态,所有响应码都被定义在org.apache.zookeeper.KeeperException.Code类中,比较常见的响应码有 0(Ok)、-4(ConnectionLoss)、-110(NodeExists)和 -112(Session Expired)等,分别代表接口调用成功、客户端与服务端连接已断开、指定节点已存在和会话已过期等。
在 Curator 中,可以通过以下 API 来进行异步操作:
Backgroundable<T>
-- T inBackground();
-- T inBackground(Object context);
-- T inBackground(BackgroundCallback callback);
-- T inBackground(BackgroundCallback callback, Object context);
-- T inBackground(BackgroundCallback callback, Executor executor);
-- T inBackground(BackgroundCallback callback, Object context, Executor executor);在 ZooKeeper 中,所有异步通知事件处理都是由 EventThread 这个线程来处理的 —— EventThread线程用于串行处理所有的事件通知。EventThread 的“串行处理机制”在绝大部分应用场景下能够保证对事件处理的顺序性,但这个特性也有其弊端,就是一旦碰上一个复杂的处理单元,就会消耗过长的处理时间,从而影响对其他事件的处理。因此,在上面的 inBackground 接口中,允许用户传入一个 Executor 实例,这样一来,就可以把那些比较复杂的事件处理放到一个专门的线程池中去。
Curator典型使用场景API
Curator 不仅为开发者提供了更为便利的 API 接口,而且还提供了一些典型场景的使用参考。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.4.2</version>
</dependency>事件监听
ZooKeeper 原生支持通过注册 Watcher 来进行事件监听,但是其使用并不是特别方便,需要开发人员自己反复注册 Watcher,比较繁琐。Curator 引入了 Cache 来实现对 ZooKeeper 服务端事件的监听。Cache 是 Curator 中对事件监听的包装,其对事件的监听其实可以近似看作是一个本地缓存视图和远程 ZooKeeper 视图的对比过程。同时 Curator 能够自动为开发人员处理反复注册监听,从而大大简化了原生 API 开发的繁琐过程。
Cache 分为两类监听类型:节点监听和子节点监听。
NodeCache
NodeCache 用于监听指定 ZooKeeper 数据节点本身的变化
public NodeCache(CuratorFramework client, String path);
public NodeCache(CuratorFramework client, String path, boolean dataIsCompressed);
同时,NodeCache 定义了事件处理的回调接口 NodeCacheListener。当数据节点的内容发生变化的时候,就会回调该方法。
public interface NodeCacheListener
{
/**
* Called when a change has occurred
*/
public void nodeChanged() throws Exception;
}NodeCache 使用实例
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
client.create()
.creatingParentsIfNeeded()
.withMode(CreateMode.EPHEMERAL)
.forPath("/zk", "init".getBytes());
final NodeCache cache = new NodeCache(client, "/zk", false);
cache.start(true);
cache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
System.out.println("Node data update");
}
});
client.setData().forPath("/zk", "changed".getBytes());
Thread.sleep(1000);
client.delete().deletingChildrenIfNeeded().forPath("/zk");
Thread.sleep(Integer.MAX_VALUE);在上面的示例程序中,首先构造了一个 NodeCache 实例,然后调用 start 方法,该方法有个 boolean 类型的参数,默认是 false,如果设置为 true,那么 NodeCache 在第一次启动的时候就会立刻从 ZooKeeper 上读取对应节点的数据内容,并保存在 Cache 中 NodeCache 不仅可以用于监听数据节点的内容变更,也能监听指定节点是否存在如果原本节点不存在,那么 Cache 就会在节点被创建后触发 NodeCacheListener。但是,如果该数据节点被删除,那么 Curator 就无法触发 NodeCacheListener。
PathChildrenCache
PathChildrenCache 用于监听指定 ZooKeeper 数据节点的子节点变化情况。
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData);
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, ThreadFactory threadFactory);
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, ThreadFactory threadFactory);
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, final ExecutorService executorService);
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, final CloseableExecutorService executorService);
PathChildrenCache 定义了事件处理的回调接口 PathChildrenCacheListener。当数据节点的内容发生变化的时候,就会回调该方法。
/**
* Listener for PathChildrenCache changes
*/
public interface PathChildrenCacheListener
{
/**
* Called when a change has occurred
*
* @param client the client
* @param event describes the change
* @throws Exception errors
*/
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception;
}当指定节点的子节点发生变化时,就会回调该方法。PathChildrenCacheEvent 类中定义了所有的事件类型,主要包括新增子节点(CHILD ADDED)、子节点数据变更(CHILD UPDATED)和子节点删除(CHILD_ REMOVED)三类。
PathChildrenCache 使用实例
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
PathChildrenCache cache = new PathChildrenCache(client, "/zk", true);
cache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT);
cache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {
switch (event.getType()) {
case CHILD_ADDED:
System.out.println("CHILD_ADDED "+event.getData().getPath());
break;
case CHILD_UPDATED:
System.out.println("CHILD_UPDATED "+event.getData().getPath());
break;
case CHILD_REMOVED:
System.out.println("CHILD_REMOVED "+event.getData().getPath());
break;
default:
break;
}
}
});
client.create().withMode(CreateMode.PERSISTENT).forPath("/zk");
Thread.sleep(1000);
client.create().withMode(CreateMode.PERSISTENT).forPath("/zk/v1");
Thread.sleep(1000);
client.delete().forPath("/zk/v1");
Thread.sleep(1000);
client.delete().forPath("/zk");
Thread.sleep(Integer.MAX_VALUE);在上面这个示例程序中,对/zk节点进行了子节点变更事件的监听,一旦该节点新增/删除子节点,或者子节点数据发生变更,就会回调 PathChildrenCacheListener,并根据对应的事件类型进行相关的处理。同时,我们也看到,对于节点/zk本身的变更,并没有通知到客户端。
另外,和其他 ZooKeeper 客户端产品一样,Curator 也无法对二级子节点进行事件监听。也就是说,如果使用 PathChildrenCache 对/zk进行监听,那么当/zk/v1/v2节点被创建或删除的时候,是无法触发子节点变更事件的
Master选举
在分布式系统中,经常会碰到这样的场景:对于一个复杂的任务,仅需要从集群中选举出一台进行处理即可。诸如此类的分布式问题,我们统称为“Master选举”。借助 ZooKeeper,我们可以比较方便地实现 Master 选举的功能,其大体思路非常简单:
选择一个根节点,例如/master_select,多台机器同时向该节点创建一个子节点/master_select/lock,利用 ZooKeeper 的特性,最终只有一台机器能够创建成功,成功的那台机器就作为 Master。
Curator 也是基于这个思路,但是它将节点创建、事件监听和自动选举过程进行了封装,开发人员只需要调用简单的 API 即可实现 Master 选举。下面我们通过一个示例程序来看看如何使用 Curator 实现 Master 选举功能
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
LeaderSelector selector = new LeaderSelector(client, "/master",
//成功获取Master权利后调用该监听器,执行完释放Master权利,重新开始选举
new LeaderSelectorListenerAdapter() {
@Override
public void takeLeadership(CuratorFramework client) throws Exception {
System.out.println("成为 Master 角色");
Thread.sleep(2000);
System.out.println("完成 Master 操作,释放 Master 权利");
}
});
selector.autoRequeue();
selector.start();
Thread.sleep(Integer.MAX_VALUE);当一个应用程序完成 Master 逻辑后,另一个应用程序的 takeLeadership 方法才会被调用。这也就说明,当一个应用实例成为 Master 后,其他应用实例会进入等待,直到当前 Master 挂了或退出后才会开始选举新的 Master。
每选举一次 Master,就有类似/master/_c_5a394510-44fb-4c28-a00b-d2c37d0403d7-lock-0000000018的节点被创建出来。后缀的数字不断增加。
分布式锁
在分布式环境中,为了保证数据的一致性,经常在程序的某个运行点(例如,减库存操作或流水号生成等)需要进行同步控制。
下面是分布式锁接口
public interface InterProcessLock
{
/**
* Acquire the mutex - blocking until it's available. Each call to acquire must be balanced by a call
* to {@link #release()}
*
* @throws Exception ZK errors, connection interruptions
*/
public void acquire() throws Exception;
/**
* Acquire the mutex - blocks until it's available or the given time expires. Each call to acquire that returns true must be balanced by a call
* to {@link #release()}
*
* @param time time to wait
* @param unit time unit
* @return true if the mutex was acquired, false if not
* @throws Exception ZK errors, connection interruptions
*/
public boolean acquire(long time, TimeUnit unit) throws Exception;
/**
* Perform one release of the mutex.
*
* @throws Exception ZK errors, interruptions, current thread does not own the lock
*/
public void release() throws Exception;
/**
* Returns true if the mutex is acquired by a thread in this JVM
*
* @return true/false
*/
boolean isAcquiredInThisProcess();
}下面是分布式锁示例
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
InterProcessMutex lock = new InterProcessMutex(client, "/lock");
CountDownLatch cdl = new CountDownLatch(1);
for (int i = 0; i < 10; i++) {
new Thread(() -> {
try {
cdl.await();
lock.acquire();
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss|SSS");
System.out.println("订单流水号:" + sdf.format(new Date()));
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
cdl.countDown();
Thread.sleep(Integer.MAX_VALUE);分布式计数器
有了上述分布式锁实现的基础之后,我们就很容易基于其实现一个分布式计数器。分布式计数器的一个典型场景是统计系统的在线人数。基于 ZooKeeper 的分布式计数器的实现思路也非常简单:
指定一个 Zookeeper 数据节点作为计数器,多个应用实例在分布式锁的控制下,通过更新该数据节点的内容来实现计数功能。
Curator 将一系列逻辑封装在了 DistributedAtomicInteger 类中。
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
DistributedAtomicInteger atomicInteger = new DistributedAtomicInteger(client, "/counter", new RetryOneTime(3000));
AtomicValue<Integer> value = atomicInteger.add(10);
System.out.println("Result: " + value.succeeded());
Thread.sleep(Integer.MAX_VALUE);分布式Barrier
Barrier 是一种用来控制多线程之间同步的方式。
public class CyclicBarrierTest {
private static CyclicBarrier cb;
public static void main(String[] args) {
cb = new CyclicBarrier(5);
// 新建5个任务
for(int i=0; i<SIZE; i++)
new InnerThread().start();
}
static class InnerThread extends Thread{
public void run() {
try {
System.out.println(Thread.currentThread().getName() + " wait for CyclicBarrier.");
// 将cb的参与者数量加1
cb.await();
// cb的参与者数量等于5时,才继续往后执行
System.out.println(Thread.currentThread().getName() + " continued.");
} catch (Exception e) {
e.printStackTrace();
}
}
}
}CyclicBarrier 会准确地等待所有线程都处于就绪状态后才开始同时执行其他业务逻辑。如果是在同一个JVM中的话,使用 CyclicBarrier 完全可以解决诸如此类的多线程同步问题。但是,如果是在分布式环境中又该如何解决呢? Curator 中提供的 DistributedBarrier 就是用来实现分布式 Barrier 的。
CuratorFramework clientM = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
clientM.start();
DistributedBarrier barrierM = new DistributedBarrier(clientM, "/barrier");
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
DistributedBarrier barrier = new DistributedBarrier(client, "/barrier");
Thread.sleep(Math.round(Math.random() * 3000));
System.out.println("进入线程设置 Barrier" + Thread.currentThread().getName());
barrier.setBarrier();
barrier.waitOnBarrier();
System.out.println("退出");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
Thread.sleep(4000);
//手动解除Barrier
barrierM.removeBarrier();与上面不同的是,DistributedDoubleBarrier 提供了线程自发触发 Barrier 释放的模式。
for (int i = 0; i < 5; i++) {
new Thread(() -> {
try {
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3))
.build();
client.start();
DistributedDoubleBarrier barrier = new DistributedDoubleBarrier(client, "/barrier", 5);
Thread.sleep(Math.round(Math.random() * 3000));
System.out.println("进入线程" + Thread.currentThread().getName());
barrier.enter();
System.out.println("启动");
Thread.sleep(Math.round(Math.random() * 3000));
barrier.leave();
System.out.println("退出");
} catch (Exception e) {
e.printStackTrace();
}
}).start();
}
Thread.sleep(Integer.MAX_VALUE);常用工具
ZKPaths
提供了一些简单的 API 来构建 ZNode 路径、递归创建和删除节点等。
EnsurePath
EnsurePath 提供了一种能够确保数据节点存在的机制,多用于这样的业务场景中:上层业务希望对一个数据节点进行一些操作,但是操作之前需要确保该节点存在。基于 ZooKeeper 提供的原始 API 接口,为解决上述场景的问题,开发人员需要首先对该节点进行一个判断,如果该节点不存在,那么就需要创建节点。而与此同时,在分布式环境中,在 A 机器试图进行节点创建的过程中,由于并发操作的存在,另一台机器,如 B 机器,也在同时创建这个节点,于是 A 机器创建的时候,可能会抛出诸如“节点已经存在”的异常。因此开发人员还必须对这些异常进行单独的处理,逻辑通常非常琐碎。
EnsurePath 正好可以用来解决这些烦人的问题,它采取了静默的节点创建方式,其内部实现就是试图创建指定节点,如果节点已经存在,那么就不进行任何操作,也不对外抛出异常,否则正常创建数据节点。
TestingServer
为了便于开发人员进行 ZooKeeper 的开发与测试,Curator 提供了一种启动简易 Zookeeper 服务的方法 —— TestingServer。TestingServer 允许开发人员非常方便地启动一个标准的 ZooKeeper 服务器,并以此来进行一系列的单元测试。TestingServer 在 Curator 的 test 包中,读者需要单独依赖以下 Maven 依赖来获取。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-test</artifactId>
<version>2.4.2</version>
<scope>test</scope>
</dependency>以下是代码示例
TestingServer server = new TestingServer(2181);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(server.getConnectString())
.retryPolicy(new RetryOneTime(1000))
.build();
client.start();
System.out.println(client.getChildren());
server.close();TestingCluster
上文中提到,开发人员可以利用 TestingServer 来非常方便地在单元测试中启动一个 ZooKeeper 服务器,同样,Curator 也提供了启动 ZooKeeper 集群的工具类。
TestingCluster 是一个可以模拟 ZooKeeper 集群环境的 Curator 工具类,能够便于开发人员在本地模拟由 n 台机器组成的集群环境。
TestingCluster cluster = new TestingCluster(4);
cluster.start();
Thread.sleep(3000);
TestingZooKeeperServer leader = null;
for (TestingZooKeeperServer zs : cluster.getServers()) {
System.out.println(zs.getInstanceSpec().getServerId() + " " + zs.getQuorumPeer().getServerState());
System.out.println(zs.getInstanceSpec().getDataDirectory().getAbsolutePath());
if (zs.getQuorumPeer().getServerState().equals("leading")) {
leader = zs;
}
}
leader.kill();
System.out.println("--After Kill Leader");
for (TestingZooKeeperServer zs : cluster.getServers()) {
System.out.println(zs.getInstanceSpec().getServerId() + "\n" + zs.getQuorumPeer().getServerState());
System.out.println(zs.getInstanceSpec().getDataDirectory().getAbsolutePath());
}