介绍 ZooKeeper 客户端的会话创建过程以及会话的技术内幕。
客户端
ZooKeeper 的客户端主要由以下几个核心组件组成
- ZooKeeper 实例:客户端的入口。
- ClientWatchManager:客户端 Watcher 管理器。
- HostProvider:客户端地址列表管理器。
- ClientCnxn:客户端核心线程,其内部又包含两个线程,即 SendThread 和 EventThread。前者是一个 IO 线程,主要负责 ZooKeeper 客户端和服务端之间的网络 IO 通信;后者是一个事件线程,主要负责对服务端事件进行处理。
ZooKeeper 客户端的初始化与启动环节,实际上就是 ZooKeeper 对象的实例化过程。客户端的整个初始化和启动过程大体可以分为以下 3 个步骤。
- 设置默认 Watcher
- 设置 ZooKeeper 服务器地址列表
- 创建 ClientCnxn
一次会话的创建过程
下图是客户端一次会话创建的基本过程。在这个流程图中,所有以白色作为底色的框图流程可以看作是第一阶段,我们称之为初始化阶段;以斜线底纹表示的流程是第二阶段,称之为会话创建阶段;以点状底纹表示的则是客户端在接收到服务端响应后的对应处理,称之为响应处理阶段。
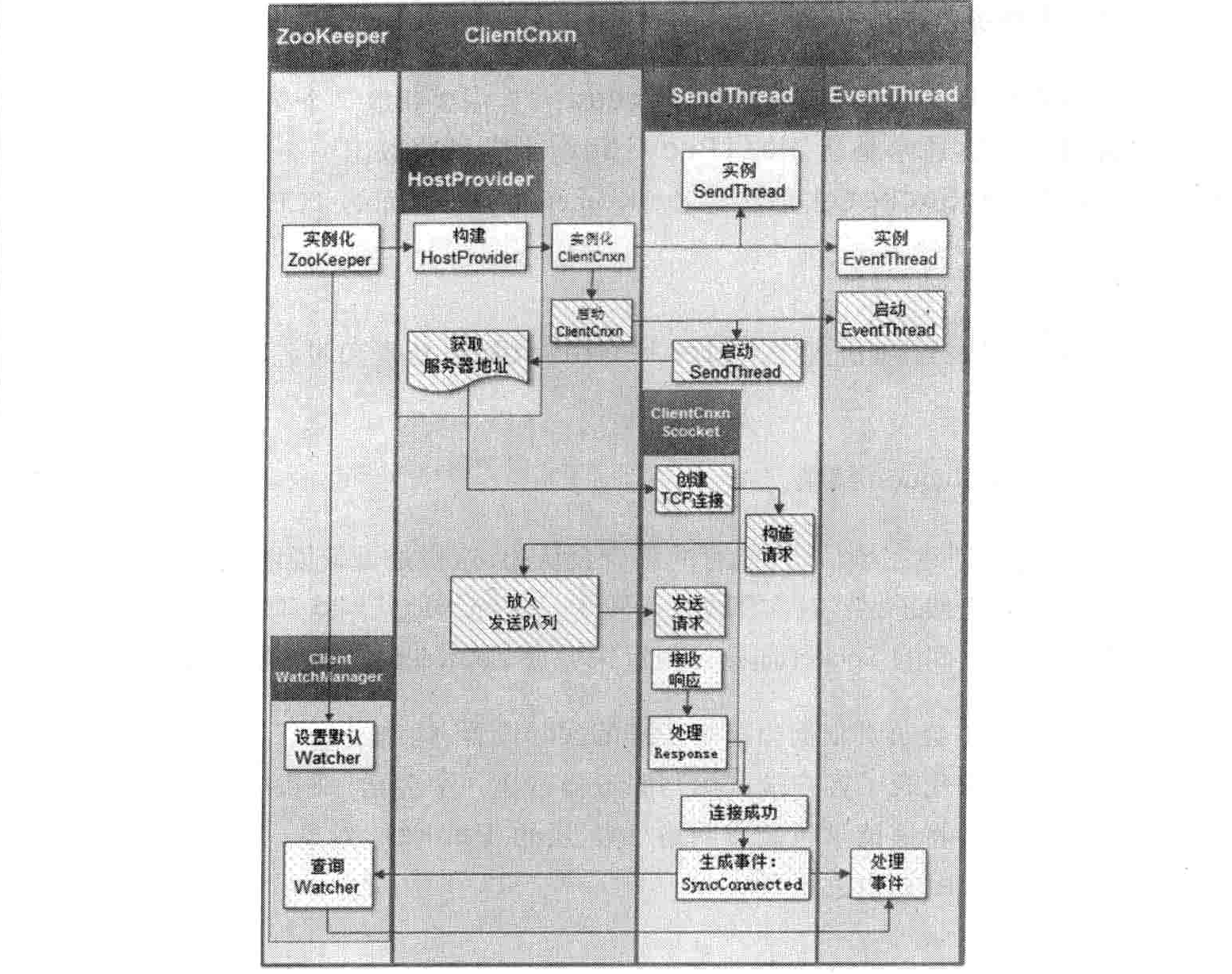
初始化阶段
初始化 ZooKeeper 对象
通过调用 ZooKeeper 的构造方法来实例化一个 ZooKeeper 对象,在初始化过程中,会创建一个客户端的 Watcher 管理器:ClientWatchManager。
设置会话默认 Watcher
如果在构造方法中传入了一个 Watcher 对象,那么客户端会将这个对象作为默认 Watcher 保存在 ClientWatchManager 中。构造 ZooKeeper 服务器地址列表管理器:HostProvider
对于构造方法中传入的服务器地址,客户端会将其存放在服务器地址列表管理器 HostProvider 中。
创建并初始化客户端网络连接器:ClientCnxn
ZooKeeper客户端首先会创建一个网络连接器 ClientCnxn,用来管理客户端与服务器的网络交互。另外,客户端在创建 ClientCnxn 的同时,还会初始化客户端两个核心队列 outgoingQueue 和 pendingQueue,分别作为客户端的请求发送队列和服务端响应的等待队列。ClientCnxn 连接器的底层 IO 处理器是 ClientCnxnSocket,因此在这一步中,客户端还会同时创建 ClientCnxnSocket 处理器。初始化 SendThread 和 EventThread
客户端会创建两个核心网络线程 SendThread 和 EventThread,前者用于管理客户端和服务端之间的所有网络 IO,后者则用于进行客户端的事件处理。同时,客户端还会将 ClientCnxnSocket 分配给 SendThread 作为底层网络 IO 处理器,并初始化 EventThread 的待处理事件队列 waitingEvents,用于存放所有等待被客户端处理的事件。
会话创建阶段
启动 SendThread 和 EventThread
SendThread 首先会判断当前客户端的状态,进行一系列清理性工作,为客户端发送“会话创建”请求做准备。
获取一个服务器地址
在开始创建 TCP 连接之前,SendThread 首先需要获取一个 ZooKeeper 服务器的目标地址,这通常是从 HostProvider 中随机获取出一个地址,然后委托给 ClientCnxnSocket 去创建与 ZooKeeper 服务器之间的 TCP 连接。
创建 TCP 连接
获取到一个服务器地址后,ClientCnxnSocket 负责和服务器创建一个 TCP 长连接。
构造 ConnectRequest 请求
在 TCP 连接创建完毕后,客户端只是纯粹地从网络 TCP 层面完成了客户端与服务端之间的 Socket 连接,但远未完成 ZooKeeper 客户端的会话创建。
SendThread 会负责根据当前客户端的实际设置,构造出一个 ConnectRequest 请求,该请求代表了客户端试图与服务器创建一个会话。同时,ZooKeeper 客户端还会进一步将该请求包装成网络 IO 层的 Packet 对象,放入请求发送队列 outgoingQueue 中去。
响应处理阶段
接收服务端响应
ClientCnxnSocket 接收到服务端的响应后,会首先判断当前的客户端状态是否是“已初始化”,如果尚未完成初始化,那么就认为该响应一定是会话创建请求的响应,直接交由 readConnectResult 方法来处理该响应
处理 Response
ClientCnxnSocket 会对接收到的服务端响应进行反序列化,得到 ConnectResponse 对象,并从中获取到 ZooKeeper 服务端分配的会话 sessionid。
连接成功
连接成功后,一方面需要通知 SendThread 线程,进一步对客户端进行会话参数的设置,包括 readTimeout 和 connectTimeout 等,并更新客户端状态;另一方面,需要通知地址管理器 HostProvider 当前成功连接的服务器地址。
生成事件:SyncConnected-None
为了能够让上层应用感知到会话的成功创建,SendThread 会生成一个事件 SyncConnected-None,代表客户端与服务器会话创建成功,并将该事件传递给 EventThread 线程查询 Watcher
EventThread 线程收到事件后,会从 ClientWatchManager 管理器中査询出对应的 Watcher,针对 SyncConnected-None 事件,那么就直接找出步骤 2 中存储的默认 Watcher,然后将其放到 EventThread 的 waitingEvents 队列中去
处理事件
EventThread 不断地从 waitingEvents 队列中取出待处理的 Watcher 对象然后直接调用该对象的 process 接口方法,以达到触发 Watcher 的目的。
服务器地址列表
ZooKeepe r客户端内部在接收到服务器地址列表后,会将其首先放入一个 ConnectStringParser 对象中封装起来。ConnectStringParser 是一个服务器地址列表的解析器,该类的基本结构如下:
public final class ConnectStringParser {
private static final int DEFAULT_PORT = 2181;
private final String chrootPath;
private final ArrayList<InetSocketAddress> serverAddresses = new ArrayList<InetSocketAddress>();ConnectStringParser 解析器将会对传入的 connectString 做两个主要处理:
- 解析 chrootPath
- 保存服务器地址列表
Chroot:客户端隔离命名
Chroot 特性允许每个客户端为自己设置一个命名空间(Namespace)。如果一个 ZooKeeper 客户端设置了 Chroot,那么该客户端对服务器的任何操作,都将会被限制在其自己的命名空间下。
客户端可以通过在 connectString 中添加后缀的方式来设置 Chroot,如下所示:
192.168.0.1:2181,192.168.0.1:2181,192.168.0.1:2181/apps/X举个例子来说,如果我们希望为应用 X 分配apps/X下的所有子节点,那么该应用可以将其所有 ZooKeeper 客户端的 Chroot 设置为/apps/X的。一旦设置了 Chroot 之后,那么对这个客户端来说,所有的节点路径都以apps/X为根节点,它和 ZooKeeper 发起的所有请求中相关的节点路径,都将是一个相对路径——相对于/apps/X的路径。例如通过 ZooKeeper 客户端 API 创建节点/test_chroot,那么实际上在服务端被创建的节点是apps/X/test_chroot通过设置 Chroot,我们能够将一个客户端应用与 ZooKeeper 服务端的一棵子树相对应,在那些多个应用共用一个 ZooKeeper 集群的场景下,这对于实现不同应用之间的相互隔离非常有帮助。
HostProvider:地址列表管理器
在 ConnectStringParser 解析器中会对服务器地址做一个简单的处理,并将服务器地址和相应的端口封装成一个 InetSocketAddress 对象,以 ArrayList 形式保存在 ConnectStringParser.serverAddresses 属性中。然后,经过处理的地址列表会被进一步封装到 StaticHostProvider 类中。
StaticHostProvider 是 HostProvider 接口的具体实现。HostProvider 类定义了一个客户端的服务器地址管理器:
public interface HostProvider {
//返回当前服务器地址列表的个数
public int size();
//返回一个服务器地址 InetSocketAddress,以便客户端进行服务器连接(实现是一个环形队列)
public InetSocketAddress next(long spinDelay);
//如果客户端与服务器成功创建连接,就通过调用这个方法来回调通知HostProvide
public void onConnected();
/**
* Update the list of servers. This returns true if changing connections is necessary for load-balancing, false otherwise.
* @param serverAddresses new host list
* @param currentHost the host to which this client is currently connected
* @return true if changing connections is necessary for load-balancing, false otherwise
*/
boolean updateServerList(Collection<InetSocketAddress> serverAddresses,
InetSocketAddress currentHost);
}对HostProvider设想
StaticHostProvider 只是 ZooKeeper 官方提供的对于地址列表管理器的默认实现方式,也是最通用和最简单的一种实现方式。读者如果有需要的话,完全可以在满足上面提到的 HostProvider 三要素的前提下,实现自己的服务器地址列表管理器。
配置文件方式
在 ZooKeeper 默认的实现方式中,是通过在构造方法中传入服务器地址列表的方式来实现地址列表的设置,但其实通常开发人员更习惯于将例如 IP 地址这样的配置信息保存在一个单独的配置文件中统一管理起来。针对这样的需求,我们可以自己实现一个 HostProvider,通过在应用启动的时候加载这个配置文件来实现对服务器地址列表的获取。
动态变更的地址列表管理器
在 ZooKeeper 的使用过程中,我们会碰到这样的问题:ZooKeeper 服务器集群的整体迁移或个别机器的变更,会导致大批客户端应用也跟着一起进行变更。出现这个尴尬局面的本质原因是因为我们将一些可能会动态变更的 IP 地址写死在程序中了。因此,实现动态变更的地址列表管理器,对于提升 ZooKeeper 客户端用户使用体验非常重要。
为了解决这个问题,最简单的一种方式就是实现这样一个 HostProvider:地址列表管理器能够定时从 DNS 或一个配置管理中心上解析出 ZooKeeper 服务器地址列表,如果这个地址列表变更了,那么就同时更新到 serverAddresses 集合中去,这样在下次需要获取服务器地址(即调用
next()方法)的时候,就自然而然使用了新的服务器地址,随着时间推移,慢慢地就能够在保证客户端透明的情况下实现 ZooKeeper 服务器机器的变更。实现同机房优先策略
随着业务增长,系统规模不断扩大,我们对于服务器机房的需求也日益旺盛。同时,随着系统稳定性和系统容灾等问题越来越被重视,很多互联网公司会出现多个机房,甚至是异地机房。多机房,在提高系统稳定性和容灾能力的同时,也给我们带来了一个新的困扰:如何解决不同机房之间的延时。我们以目前主流的采用光电波传输的网络带宽架构(光纤中光速大约为 20 万公里每秒,千兆带宽)为例,对于杭州和北京之间相隔 1500 公里的两个机房计算其网络延时:
需要注意的是,这个 15 毫秒仅仅是一个理论上的最小值,在实际的情况中,我们的网络线路并不能实现直线铺设,同时信号的干扰、光电信号的转换以及自身的容错修复对网络通信都会有不小的影响,导致了在实际情况中,两个机房之间可能达到 30~40 毫秒,甚至更大的延时。
所以在目前大规模的分布式系统设计中,我们开始考虑引入“同机房优先”的策略。所谓的“同机房优先”是指服务的消费者优先消费同一个机房中提供的服务。举个例子来说,一个服务 F 在杭州机房和北京机房中都有部署,那么对于杭州机房中的服务消费者,会优先调用杭州机房中的服务,对于北京机房的客户端也一样。
对于 ZooKeeper 集群来说,为了达到容灾要求,通常会将集群中的机器分开部署在多个机房中,因此同样面临上述网络延时问题。对于这种情况,就可以实现一个能够优先和同机房 ZooKeeper 服务器创建会话的 HostProvider。
ClientCnxn:网络 IO
ClientCnxn 是 ZooKeeper 客户端的核心工作类,负责维护客户端与服务端之间的网络连接并进行一系列网络通信。
Packet
Packet 是 ClientCnxn 内部定义的一个对协议层的封装,作为 ZooKeeper 中请求与响应的载体,其数据结构如下图所示。
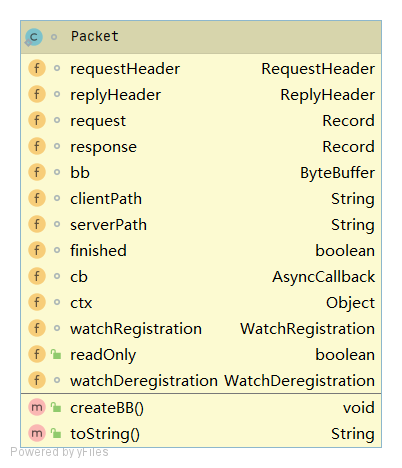
Packet 中包含了最基本的请求头(requestHeader)、响应头(replyHeader)、请求体(request)、响应体(response)、节点路径(clientPath / serverPath)和注册的 Watcher( watchRegistration)等信息。
而真正通过createBB()被序列化成可用于底层网络传输的 ByteBuffer 对象的只有 requestHeader、request 和 readonly 三个属性。
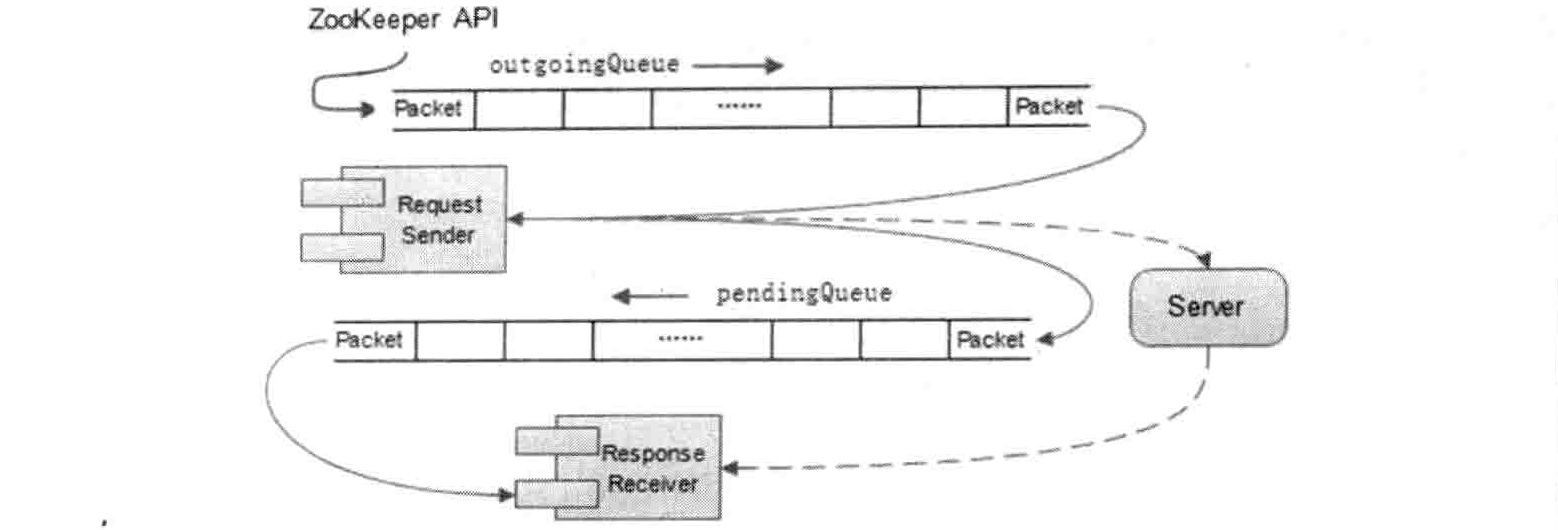
outgoingQueue 和 pendingQueue
ClientCnxn 中,有两个比较核心的队列 outgoingQueue 和 pendingQueue,分别代表客户端的请求发送队列和服务端响应的等待队列。Outgoing 队列是一个请求发送队列,专门用于存储那些需要发送到服务端的 Packet 集合。Pending 队列是为了存储那些已经从客户端发送到服务端的,但是需要等待服务端响应的 Packet 集合。
ClientCnxnSocket:底层Socket通信层
ClientCnxnSocket 定义了底层 Socket 通信的接口。在使用 ZooKeeper 客户端的时候,可以通过在zookeeper.clientCnxnSocket这个系统变量中配置 ClientCnxnSocket 实现类的全类名,以指定底层 Socket 通信层的自定义实现,例如,-Dzookeeper.clientCnxnSocket=org.apache.zookeeper.ClientCnxnSocketNIO。在 ZooKeeper 中,其默认的实现是 ClientCnxnSocketNIO。该实现类使用 Java 原生的 NIO 接口,其核心是 doIO 逻辑,主要负责对请求的发送和响应接收过程。
请求发送
在正常情况下(即客户端与服务端之间的 TCP 连接正常且会话有效的情况下),会从 outgoingQueue 队列中提取出一个可发送的 Packet 对象,同时生成一个客户端请求序号 XID 并将其设置到 Packet 请求头中去,然后将其序列化后进行发送。这里提到了“获取一个可发送的 Packet 对象”,那么什么样的 Packet 是可发送的呢?在 outgoingQueue 队列中的 Packet 整体上是按照先进先出的顺序被处理的,但是如果检测到客户端与服务端之间正在处理 SASL 权限的话,那么那些不含请求头(requestReader)的 Packet(例如会话创建请求)是可以被发送的,其余的都无法被发送。
请求发送完毕后,会立即将该 Packet 保存到 pendingQueue 队列中,以便等待服务端响应返回后进行相应的处理,如下图所示。
响应接收
客户端获取到来自服务端的完整响应数据后,根据不同的客户端请求类型,会进行不同的处理。
- 如果检测到当前客户端还尚未进行初始化,那么说明当前客户端与服务端之间正在进行会话创建,那么就直接将接收到的 ByteBuffer(incomingBuffer)序列化成 ConnectResponse 对象。
- 如果当前客户端已经处于正常的会话周期,并且接收到的服务端响应是一个事件,那么 ZooKeeper 客户端会将接收到的 ByteBuffer(incomingBuffer)序列化成 WatcherEvent 对象,并将该事件放入待处理队列中。
- 如果是一个常规的请求响应(指的是 Create、GetData 和 Exist 等操作请求),那么会从 pendingQueue 队列中取出一个 Packet 来进行相应的处理。ZooKeeper 客户端首先会通过检验服务端响应中包含的 XID 值来确保请求处理的顺序性,然后再将接收到的 ByteBuffer(incomingBuffer)序列化成相应的 Response 对象。
最后,会在 finishPacket 方法中处理 Watcher 注册等逻辑。
SendThread
SendThread 是客户端 ClientCnxn 内部一个核心的 IO 调度线程,用于管理客户端和服务端之间的所有网络 IO 操作。在 ZooKeeper 客户端的实际运行过程中,一方面,SendThread 维护了客户端与服务端之间的会话生命周期,其通过在一定的周期频率内向服务端发送一个 PING 包来实现心跳检测。同时,在会话周期内,如果客户端与服务端之间出现 TCP 连接断开的情况,那么就会自动且透明化地完成重连操作。
另一方面,SendThread 管理了客户端所有的请求发送和响应接收操作,其将上层客户端 API 操作转换成相应的请求协议并发送到服务端,并完成对同步调用的返回和异步调用的回调。同时,SendThread 还负责将来自服务端的事件传递给 EventThread 去处理。
EventThread
EventThread 是客户端 ClientCnxn 内部的另一个核心线程,负责客户端的事件处理,并触发客户端注册的 Watcher 监听。EventThread 中有一个 waitingEvents 队列,用于临时存放那些需要被触发的 Object,包括那些客户端注册的 Watcher 和异步接口中注册的回调器 Async Callback。同时,EventThread 会不断地从 waitingEvents 这个队列中取出 Object,识别出其具体类型(Watcher 或者 Async Callback),并分别调用 process和 processResult 接口方法来实现对事件的触发和回调。
会话
简单地说,ZooKeeper 的连接与会话就是客户端通过实例化 ZooKeeper 对象来实现客户端与服务器创建并保持 TCP 连接的过程。
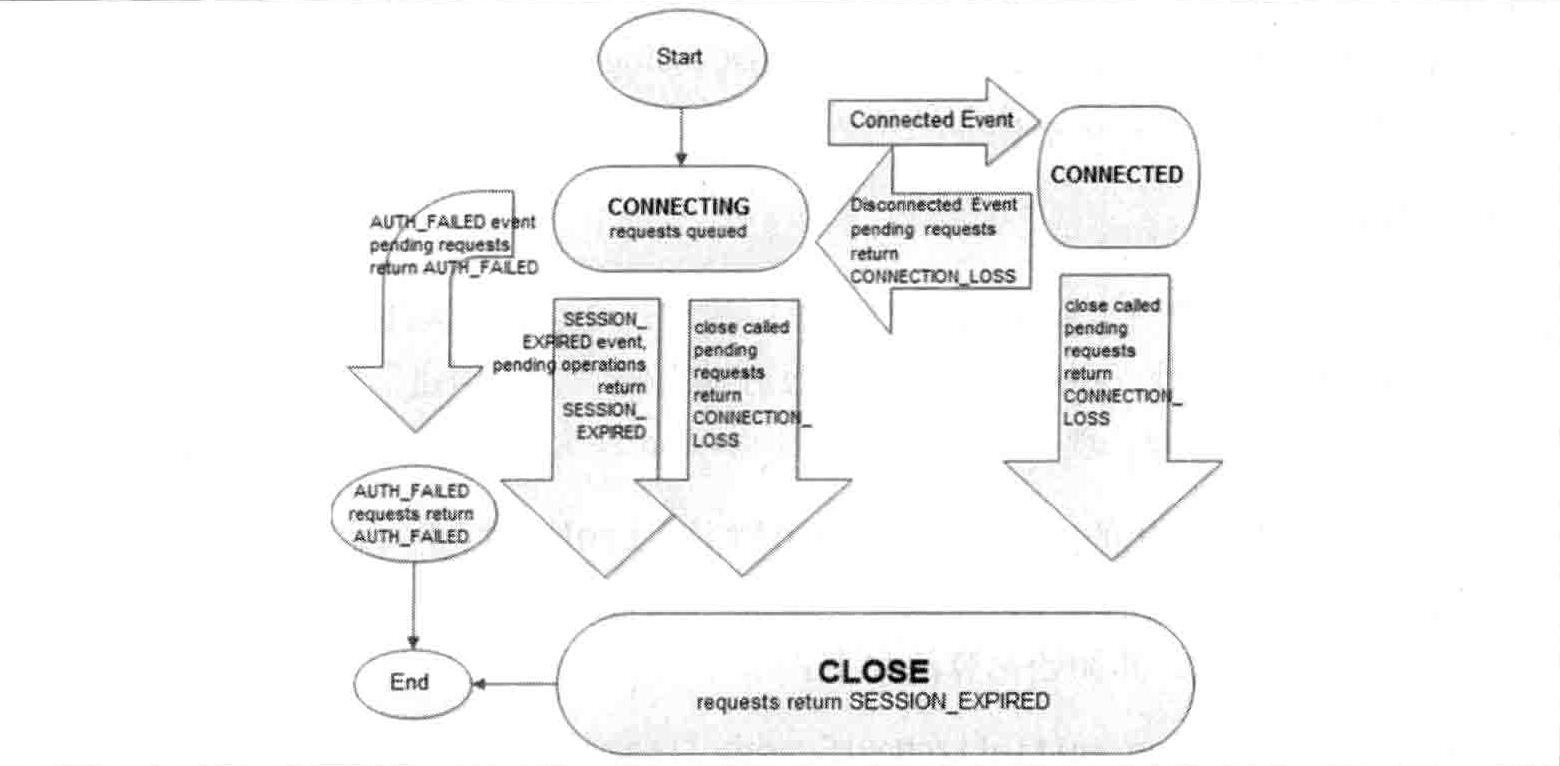
会话状态
在 ZooKeeper 客户端与服务端成功完成连接创建后,就建立了一个会话。ZooKeeper 会话在整个运行期间的生命周期中,会在不同的会话状态之间进行切换,这些状态一般可以分为 CONNECTING、CONNECTED、RECONNECTING、RECONNECTED 和 CLOSE 等。一旦客户端开始创建 ZooKeeper 对象,那么客户端状态就会变成 CONNECTING,同时客户端开始从上述服务器地址列表中逐个选取 IP 地址来尝试进行网络连接,直到成功连接上服务器,然后将客户端状态变更为 CONNECTED。
通常情况下,伴随着网络闪断或是其他原因,客户端与服务器之间的连接会出现断开情况。一旦碰到这种情况,ZooKeeper 客户端会自动进行重连操作,同时客户端的状态再次变为 CONNECTING,直到重新连接上 ZooKeeper 服务器后,客户端状态又会再次转变成 CONNECTED。因此,通常情况下,在 ZooKeeper 运行期间,客户端的状态总是介于 CONNECTING 和 CONNECTED 两者之一。
另外,如果出现诸如会话超时、权限检査失败或是客户端主动退出程序等情况,那么客户端的状态就会直接变更为 CLOSE。下图展示了 ZooKeeper 客户端会话状态的变更情况。
会话创建
Session
Session 是 ZooKeeper 中的会话实体,代表了一个客户端会话。其包含以下 4 个基本属性:
- sessionId:会话 ID,用来唯一标识一个会话,每次客户端创建新会话的时候,ZooKeeper 都会为其分配一个全局唯一的 sessionID。
- TimeOut:会话超时时间。客户端在构造 ZooKeeper 实例的时候,会配置一个 sessiontimeout 参数用于指定会话的超时时间。ZooKeeper 客户端向服务器发送这个超时时间后,服务器会根据自己的超时时间限制最终确定会话的超时时间。
- TickTime:下次会话超时时间点。为了便于 ZooKeeper 对会话实行“分桶策略”管理,同时也是为了高效低耗地实现会话的超时检查与清理,ZooKeeper 会为每个会话标记一个下次会话超时时间点。TickTime 是一个 13 位的 long 型数据,其值接近于当前时间加上 TimeOut,但不完全相等。
- isClosing:该属性用于标记一个会话是否已经被关闭。通常当服务端检测到一个会话已经超时失效的时候,会将该会话的 isClosing 属性标记为“已关闭”,这样就能确保不再处理来自该会话的新请求了。
sessionID
在上面我们也已经提到了,sessionId 用来唯一标识一个会话,因此 ZooKeeper 必须保证 sessionId 的全局唯一性。在每次客户端向服务端发起“会话创建”请求时,服务端都会为其分配一个 sessionId,现在我们就来看看 sessionId 究竟是如何生成的。
在 SessionTracker 初始化的时候,会调用 initializeNextSession 方法来生成一个初始化的 sessionID,之后在 ZooKeeper 的正常运行过程中,会在该 sessionID 的基础上为每个会话进行分配,其初始化算法如下:
public static long initializeNextSession(long id) {
long nextSid;
nextSid = (Time.currentElapsedTime() << 24) >>> 8;
nextSid = nextSid | (id <<56);
return nextSid;
}从上面的代码片段中,可以看出 sessionID 的生成大体可以分为以下 5 个步骤:

经过上述算法计算之后,我们就可以得到一个单机唯一的序列号。可以将上述算法概括为:高 8 位确定了所在机器,后 56 位使用当前时间的毫秒表示进行随机。
实现细节
为什么是左移 24 位?

该算法是否完美?
上述算法虽然看起来非常严谨,基本看不出什么明显的问题,但其实并不完美。上述算法的根基在步骤 1,即能够获取到一个随机的,且在单机范围内不会出现重复的随机数,我们将其称为“基数”— ZooKeeper 选择了使用 Java 语言自带的当前时间的毫秒数来作为该基数。针对当前时间的毫秒表示,通常情况下没有什么问题,但如果假设到了 2022 年 04 月 08 日时,System.currentTimeMillis()的值会是多少呢?可以通过如下计算方式得到:

在这种情况下,相信读者已经发现了,即使左移 24 位,还是有问题,因为 24 位后还是负数,所以完美的解决方案是:
public static long initializeNextSession(long id) {
long nextSid;
//无符号右移,而非有符号右移,就可以避免高位数值对SID的干扰了
nextSid = (Time.currentElapsedTime() << 24) >>> 8;
nextSid = nextSid | (id <<56);
return nextSid;
}SessionTracker
SessionTracker 是 ZooKeeper 服务端的会话管理器,负责会话的创建、管理和清理等工作。可以说,整个会话的生命周期都离不开 SessionTracker 的管理。每一个会话在 SessionTracker 内部都保留了三份,具体如下。
- sessionsById:这是一个
HashMap<Long, SessionImp>类型的数据结构,用于根据 sessionId 来管理 Session 实体。 - sessionsWithTimeout:这是一个
ConcurrentHashMap<Long, Integer>类型的数据结构,用于根据 sessionId 来管理会话的超时时间。该数据结构和 ZooKeeper 内存数据库相连通,会被定期持久化到快照文件中去。 - sessionSets:这是一个
HashMap<Long, Sessions>类型的数据结构,用于根据下次会话超时时间点来归档会话,便于进行会话管理和超时检查。
创建连接
服务端对于客户端的“会话创建”请求的处理,大体可以分为四大步骤,分别是处理 ConnectRequest 请求、会话创建、处理器链路处理和会话响应。在 ZooKeeper 服务端,首先将会由 NIOServerCnxn 来负责接收来自客户端的“会话创建”请求,并反序列化出 ConnectRequest 请求,然后根据 ZooKeeper 服务端的配置完成会话超时时间的协商。随后,SessionTracker 将会为该会话分配一个 sessionID,并将其注册到 sessionsById 和 sessionsWithTimeout 中去,同时进行会话的激活。之后,该“会话请求”还会在 ZooKeeper 服务端的各个请求处理器之间进行顺序流转,最终完成会话的创建。
会话管理
分桶策略
ZooKeeper 的会话管理主要是由 SessionTracker 负责的,其采用了一种特殊的会话管理方式,我们称之为“分桶策略”。所谓分桶策略,是指将类似的会话放在同一区块中进行管理,以便于 ZooKeeper 对会话进行不同区块的隔离处理以及同一区块的统一处理,如下图所示。
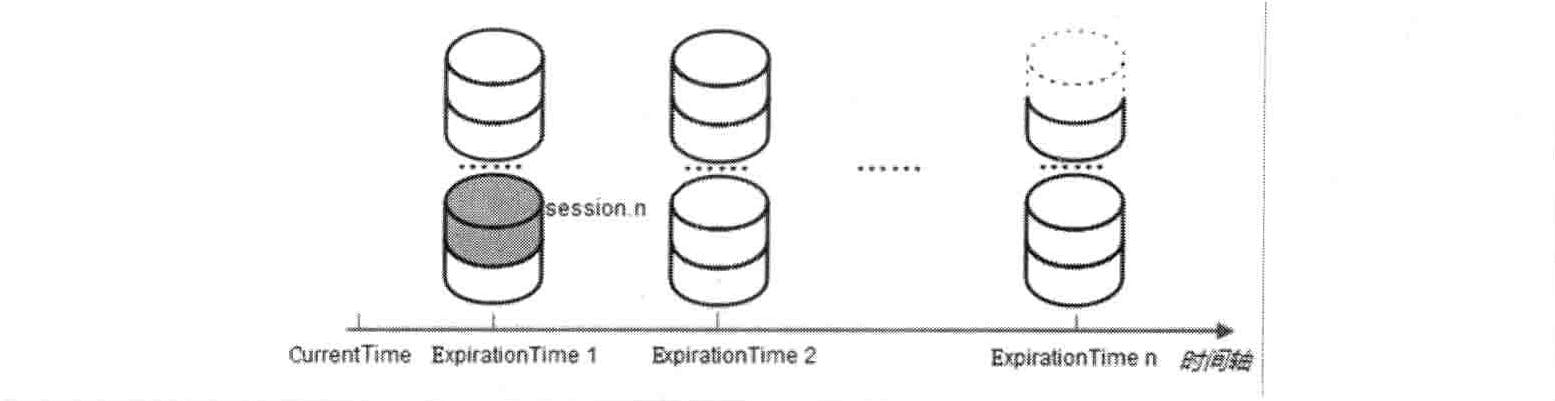
我们可以看到,ZooKeeper 将所有的会话都分配在了不同的区块之中,分配的原则是每个会话的“下次超时时间点”(ExpirationTime)。ExpirationTime 是指该会话最近一次可能超时的时间点,对于一个新创建的会话而言,其会话创建完毕后,ZooKeeper 就会为其计算 ExpirationTime,计算方式如下:
ExpirationTime = CurrentTime + SessionTimeout;那么,上图中横坐标所标识的时间,是否就是通过上述公式计算出来的呢?答案是否定的,在 ZooKeeper 的实际实现中,还做了一个处理。ZooKeeper 的 Leader 服务器在运行期间会定时地进行会话超时检查,其时间间隔是 Expirationlnterval,单位是毫秒,默认值是 tickTime 的值,即默认情况下,每隔 2000 毫秒进行一次会话超时检查。为了方便对多个会话同时进行超时检查,完整的 ExpirationTime 的计算方式如下:
ExpirationTime_ = CurrentTime + SessionTimeout;
ExpirationTime = (ExpirationTime_ / ExpirationInterval + 1) x ExpirationInterval;会话激活
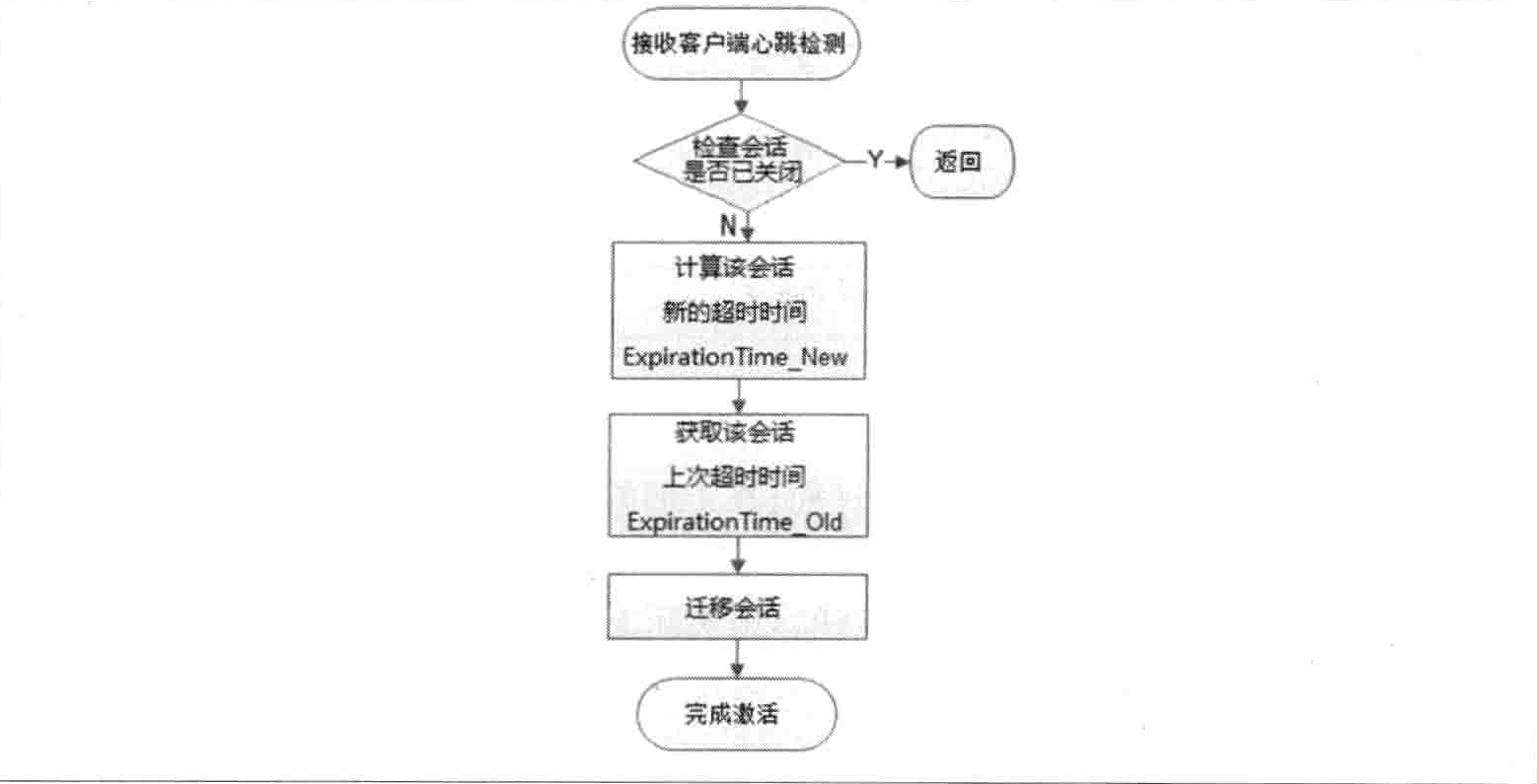
为了保持客户端会话的有效性,在 ZooKeeper 的运行过程中,客户端会在会话超时时间过期范围内向服务端发送 PING 请求来保持会话的有效性,我们俗称“心跳检测”。同时,服务端需要不断地接收来自客户端的这个心跳检测,并且需要重新激活对应的客户端会话,我们将这个重新激活的过程称为 TouchSession。会话激活的过程,不仅能够使服务端检测到对应客户端的存活性,同时也能让客户端自己保持连接状态。其主要流程如下图所示。
检验该会话是否已经被关闭
Leader 会检査该会话是否已经被关闭,如果该会话已经被关闭,那么不再继续激活该会话。
计算该会话新的超时时间 ExpirationTime_New
如果该会话尚未关闭,那么就开始激活会话。首先需要计算出该会话下一次超时时间点,使用的就是上面提到的计算公式。
定位该会话当前的区块
获取该会话老的超时时间 ExpirationTime_Old,并根据该超时时间来定位到其所在的区块。迁移会话
将该会话从老的区块中取出,放入 ExpirationTime_New 对应的新区块中。
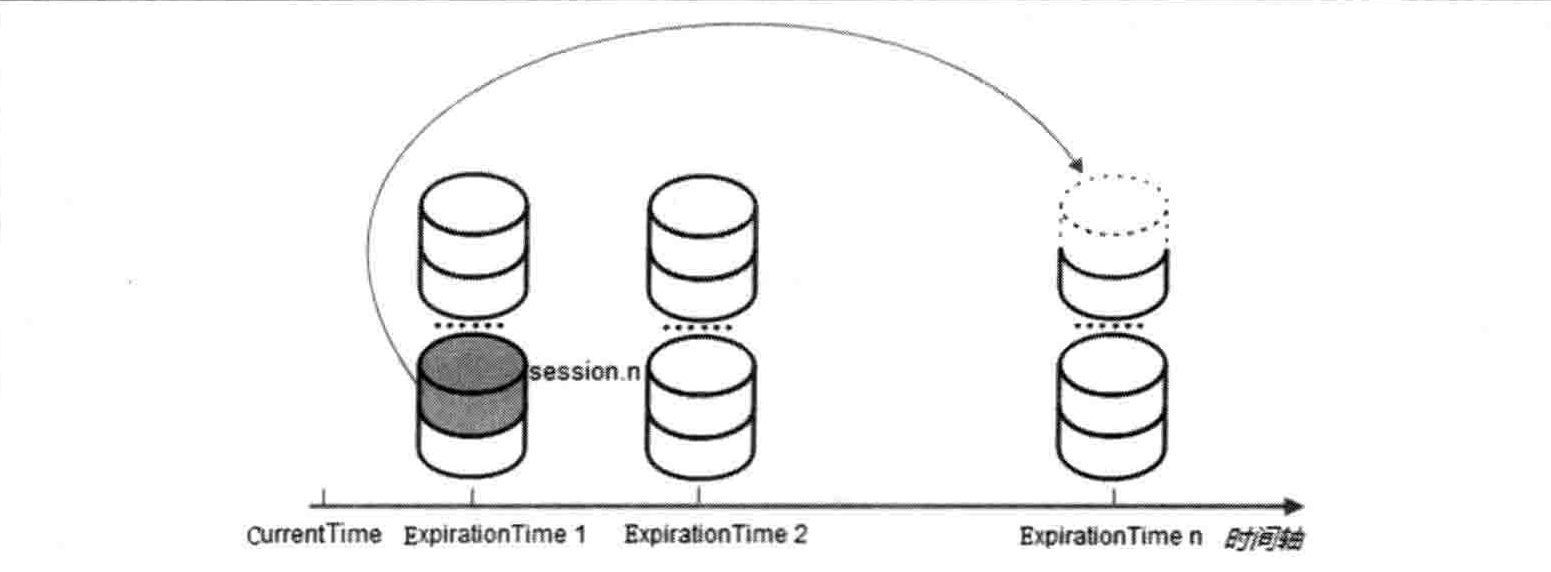
通过以上 4 步,就基本完成会话激活的过程。在上面的会话激活过程中,我们可以看到,只要客户端发来心跳检测,那么服务端就会进行一次会话激活。心跳检测由客户端主动发起,以 PING 请求的形式向服务端发送。但实际上,在 ZooKeeper 服务端的设计中,只要客户端有请求发送到服务端,那么就会触发一次会话激活。因此,总的来讲,大体会出现以下两种情况下的会话激活。
- 只要客户端向服务端发送请求,包括读或写请求,那么就会触发一次会话激活。
- 如果客户端发现在 sessionTimeout / 3 时间内尚未和服务器进行过任何通信,即没有向服务端发送任何请求,那么就会主动发起一个 PING 请求,服务端收到该请求后,就会触发上述第一种情况下的会话激活。
会话超时检查
在 ZooKeeper 中,会话超时检查同样是由 SessionTracker 负责的。SessionTracker 中有个单独的线程专门进行会话超时检查,这里我们将其称为“超时检查线程”,其工作机制的核心思路其实非常简单:逐个依次地对会话桶中剩下的会话进行清理。
如果一个会话被激活,那么 ZooKeeper 会将其从上一个会话桶迁移到下一个会话桶中。于是,expirationTime I 桶中留下的所有会话都是尚未被激活的。因此,超时检查线程的任务就是定时检查出这个会话桶中所有剩下的未被迁移的会话。
那么超时检査线程是如何做到定时检査的呢?这里就和 ZooKeeper 会话的分桶策略紧密联系起来了。在会话分桶策略中,我们将 ExpirationInterval 的倍数作为时间点来分布会话,因此,超时检査线程只要在这些指定的时间点上进行检查即可,这样既提高了会话检査的效率,而且由于是批量清理,因此性能非常好 —— 这也是为什么 ZooKeeper 要通过分桶策略来管理客户端会话的最主要的原因。因为在实际生产环境中,一个 ZooKeeper 集群的客户端会话数可能会非常多,逐个依次检查会话的方式会非常耗费时间。
会话清理
当 SessionTracker 的会话超时检査线程整理出一些已经过期的会话后,那么就要开始进行会话清理了。会话清理的步骤大致可以分为以下 7 步。
标记会话状态为“已关闭”
由于整个会话清理过程需要一段的时间,因此为了保证在此期间不再处理来自该客户端的新请求,SessionTracker 会首先将该会话的 isClosing 属性标记为 true。这样,即使在会话清理期间接收到该客户端的新请求,也无法继续处理了
发起“会话关闭”请求
为了使对该会话的关闭操作在整个服务端集群中都生效,ZooKeeper 使用了提交“会话关闭”请求的方式,并立即交付给 PrepRequestProcessor 处理器进行处理。
收集需要清理的临时节点
在 ZooKeeper 中,一旦某个会话失效后,那么和该会话相关的临时(EPHEMERAL)节点都需要被一并清除掉。因此,在清理临时节点之前,首先需要将服务器上所有和该会话相关的临时节点都整理出来在 ZooKeeper 的内存数据库中,为每个会话都单独保存了一份由该会话维护的所有临时节点集合,因此在会话清理阶段,只需要根据当前即将关闭的会话的 sessionID 从内存数据库中获取到这份临时节点列表即可。
但是,在实际应用场景中,情况并没有那么简单,有如下的细节需要处理:在 ZooKeeper 处理会话关闭请求之前,正好有以下两类请求到达了服务端并正在处理中。
- 节点删除请求,删除的目标节点正好是上述临时节点中的一个。
临时节点创建请求,创建的目标节点正好是上述临时节点中的一个。
对于这两类请求,其共同点都是事务处理尚未完成,因此还没有应用到内存数据库中,所以上述获取到的临时节点列表在遇上这两类事务请求的时候,会存在不一致的情况。
假定我们当前获取的临时节点列表是 ephemerals,那么针对第一类请求,我们需要将所有这些请求对应的数据节点路径从 ephemerals 中移除,以避免重复删除。针对第二类请求,我们需要将所有这些请求对应的数据节点路径添加到 ephemerals 中去,以删除这些即将会被创建但是尚未保存到内存数据库中去的临时节点。
添加“节点删除”事务变更
完成该会话相关的临时节点收集后,ZooKeeper 会逐个将这些临时节点转换成“节点删除”请求,并放入事务变更队列 outstandingChanges 中去。
删除临时节点
在上面的步骤中,我们已经收集了所有需要删除的临时节点,并创建了对应的“节点删除”请求,FinalRequestProcessor 处理器会触发内存数据库,删除该会话对应的所有临时节点。
移除会话
完成节点删除后,需要将会话从 SessionTracker 中移除。主要就是从上面提到的个数据结构(sessionsByRd、sessionsWithTimeout 和 sessionSets)中将该会话移除掉。
关闭 NIOServerCnxn
最后,从 NIOServerCnxnFactory 找到该会话对应的 NIOServerCnxn,将其关闭。
重连
当客户端和服务端之间的网络连接断开时,ZooKeeper 客户端会自动进行反复的重连,直到最终成功连接上 ZooKeeper 集群中的一台机器。在这种情况下,再次连接上服务端的客户端有可能会处于以下两种状态之一。
- CONNECTED:如果在会话超时时间内重新连接上了 ZooKeeper 集群中任意一台机器,那么被视为重连成功。
- EXPIRED:如果是在会话超时时间以外重新连接上,那么服务端其实已经对该会话进行了会话清理操作,因此再次连接上的会话将被视为非法会话。
在 ZooKeeper 中,客户端与服务端之间维持的是一个长连接,在 sessionTimeout 时间内,服务端会不断地检测该客户端是否还处于正常连接 —— 服务端会将客户端的毎次操作视为一次有效的心跳检测来反复地进行会话激活。因此,在正常情况下,客户端会话是一直有效的。然而,当客户端与服务端之间的连接断开后,用户在客户端可能主要会看到两类异常:CONNECTION_LOSS(连接断开)和 SESSION_EXPIRED(会话过期)。那么该如何正确处理 CONNECTION LOSS和 SESSION EXPIRED呢?
连接断开:CONNECTION_LOSS
有时会因为网络闪断导致客户端与服务器断开连接,或是因为客户端当前连接的服务器出现问题导致连接断开,我们统称这类问题为“客户端与服务器连接断开”现象,即 CONNECTION_LOSS。在这种情况下,ZooKeeper 客户端会自动从地址列表中重新逐个选取新的地址并尝试进行重新连接,直到最终成功连接上服务器。
举个例子,假设某应用在使用 ZooKeeper 客户端进行 setData 操作的时候,正好出现了 CONNECTION_LOSS 现象,那么客户端会立即接收到事件 None-Disconnected 通知,同时会抛出异常:org.apache.zookeeper.KeeperException$ConnectionLossException。在这种情况下,我们的应用需要做的事情就是捕获住 ConnectionLossException,然后等待 ZooKeeper 的客户端自动完成重连。一旦客户端成功连接上一台 ZooKeeper 机器后,那么客户端就会收到事件 None-SyncConnected通知,之后就可以重试刚刚出错的 setData 操作。
会话失效:SESSION_EXPIRED
SESSION_EXPIRED 是指会话过期,通常发生在 CONNECTION_LOSS 期间。客户端和服务器连接断开之后,由于重连期间耗时过长,超过了会话超时时间(sessionTimeout)限制后还没有成功连接上服务器,那么服务器认为这个会话已经结束了,就会开始进行会话清理。但是另一方面,该客户端本身不知道会话已经失效,并且其客户端状态还是 DISCONNECTED。之后,如果客户端重新连接上了服务器,那么很不幸,服务器会告诉客户端该会话已经失效(SESSION_EXPIRED)。在这种情况下,用户就需要重新实例化一个 ZooKeeper 对象,并且看应用的复杂情况,重新恢复临时数据。
会话转移:SESSION_MOVED
会话转移是指客户端会话从一台服务器机器转移到了另一台服务器机器上。正如上文中提到,假设客户端和服务器 S1 之间的连接断开后,如果通过尝试重连后,成功连接上了新的服务器 S2 并且延续了有效会话,那么就可以说会话从 S1 转移到了 S2 上。
会话转移现象其实在 ZooKeeper 中一直存在,但是在 3.2.0 版本之前,会话转移的概念并没有被明确地提出来,于是就会出现如下所述的异常场景。
假设我们的 ZooKeeper 服务器集群有三台机器:S1、S2 和 S3。在开始的时候,客户端 C1 与服务器 S1 建立连接且维持着正常的会话,某一个时刻,C1 向服务器发送了一个请求 R1:
setData("/$7_4_4/session_moved", 1)。但是在请求发送到服务器之前,客户端和服务器恰好发生了连接断开,并且在很短的时间内重新连接上了新的 ZooKeeper 服务器S2。之后,C1 又向服务器 S2 发送了一个请求 R2:setdata("/$7_4_4/session_moved’, 2)。这个时候,S2 能够正确地处理请求R2,但是很不幸的事情发生了,请求 R1 也最终到达了服务器 S1,于是,S1 同样处理了请求 R1,于是,对于客户端 C 来说,它的第 2 次请求 R2 就被请求 R 覆盖了。
当然,上面这个问题非常罕见,只有在 C1 和 S1 之间的网路非常慢的情况下才会发生,读者也可以参见 ZooKeeper 的 ISSUE:ZOOKEEPER-417 了解更多相关的内容。但是,不得不说,一旦发生这个问题,将会产生非常严重的后果。
因此,在 3.2.0 版本之后,ZooKeeper 明确提出了会话转移的概念,同时封装了 SessionMovedException 异常。之后,在处理客户端请求的时候,会首先检查会话的所有者(Owner):如果客户端请求的会话 Owner 不是当前服务器的话,那么就会直接抛出 SessionMovedException 异常。当然,由于客户端已经和这个服务器断开了连接,因此无法收到这个异常的响应。只有多个客户端使用相同的 sessionId/sessionPasswd 创建会话时,才会收到这样的异常。因为一旦有一个客户端会话创建成功,那么 ZooKeeper 服务器就会认为该 sessionID 对应的那个会话已经发生了转移,于是,等到第二个客户端连接上服务器后,就被认为是“会话转移”的情况了。