作为一个高性能的 NIO 通信框架,Netty 被广泛应用于大数据处理、互联网消息中间件、游戏和金融行业等。大多数应用场景对底层的通信框架都有很高的性能要求,作为综合性能最高的 NIO 框架之一,Netty 可以完全满足不同领域对高性能通信的需求。
传统RPC框架调用性能差的三宗罪
网络传输方式问题
传统的RPC框架或者基于RMI等方式的远程服务(过程)调用采用了同步阻塞 IO,当客户端的并发压力或者网络时延增大之后,同步阻塞 IO 会由于频繁的 wait 导致 IO 线程经常性的阻塞,由于线程无法高效的工作,I/O 处理能力自然下降釆用 BIO 通信模型的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接,接收到客户端连接之后,为其创建一个新的线程处理请求消息,处理完成之后,返回应答消息给客户端,线程销毁,这就是典型的一请求一应答模型。该架构最大的问题就是不具备弹性伸缩能力,当并发访问量增加后,服务端的线程个数和并发访问数成线性正比。由于线程是 Java 虚拟机非常宝贵的系统资源,当线程数膨胀之后,系统的性能急剧下降,随着并发量的继续増加,可能会发生句柄溢岀、线程堆栈溢岀等问题,并导致服务器最终宕机。
序列化性能差
Java序列化存在如下几个典型问题:
- Java 序列化机制是 Java 内部的一种对象编解码技术,无法跨语言使用。例如对于异构系统之间的对接,Java 序列化后的码流需要能够通过其他语言反序列化成原始对象(副本),目前很难支持。
- 相比于其他开源的序列化框架,Java 序列化后的码流太大,无论是网络传输还是持久化到磁盘,都会导致额外的资源占用。
- 序列化性能差,资源占用率高(主要是CPU资源占用高)。
线程模型问题
由于采用同步阻塞 I/O,这会导致每个 TCP 连接都占用1个线程,由于线程资源是 JVM 虚拟机非常宝贵的资源,当 I/O 读写阻塞导致线程无法及时释放时,会导致系统性能急剧下降,严重的甚至会导致虚拟机无法创建新的线程。
Netty高性能之道
高效的Reactor线程模型
具体的 Reactor 线程模型的内容在《Unix I/O模型与线程模型》有详细讲解
无锁的串行设计
在大多数场景下,并行多线程处理可以提升系统的并发性能。但是,如果对于共享资源的并发访问处理不当,会带来严重的锁竞争,这最终会导致性能的下降。为了尽可能地避免锁竞争带来的性能损耗,可以通过串行化设计,即消息的处理尽可能在同一个线程内完成,期间不进行线程切换,这样就避免了多线程竞争和同步锁。
为了尽可能提升性能,Netty 采用了串行无锁化设计,在 IO 线程内部进行串行操作,避免多线程竞争导致的性能下降。表面上看,串行化设计似乎 CPU 利用率不高,并发程度不够。但是,通过调整 NIO 线程池的线程参数,可以同时启动多个串行化的线程并行运行,这种局部无锁化的串行线程设计相比一个队列 —— 多个工作线程模型性能更优。
下图是Netty串行化设计工作原理
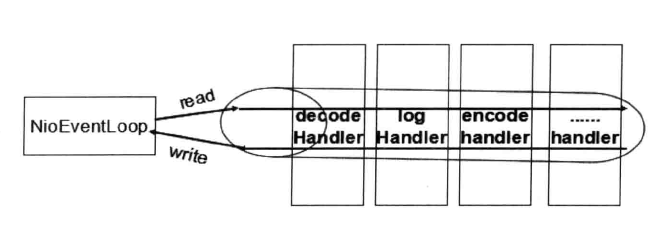
Netty 的 NioEventLoop 读取到消息之后,直接调用 ChannelPipeline 的fireChannelRead(Object msg),只要用户不主动切换线程,一直会由 NioEventLoop 调用到用户的 Handler,期间不进行线程切换。这种串行化处理方式避免了多线程操作导致的锁的竞争,从性能角度看是最优的。
高效的并发编程
Netty 的高效并发编程主要体现在如下几点:
- volatile 的大量、正确使用
- CAS 和原子类的广泛使用
- 线程安全容器的使用
- 通过读写锁提升并发性能
高性能的序列化框架
影响序列化性能的关键因素总结如下:
- 序列化后的码流大小(网络带宽的占用)
- 序列化&反序列化的性能(CPU资源占用)
- 是否支持跨语言(异构系统的对接和开发语言切换)
Netty 默认提供了对 Google Protobuf 的支持,通过扩展 Netty 的编解码接口,用户可以实现其他的高性能序列化框架,例如 Thrift 的压缩二进制编解码框架。
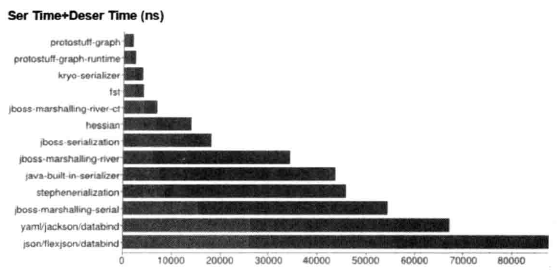
不同序列化&反序列化框架性能对比(耗时),如下图所示
不同序列化&反序列化框架性能对比(序列化码流大小),如下图所示
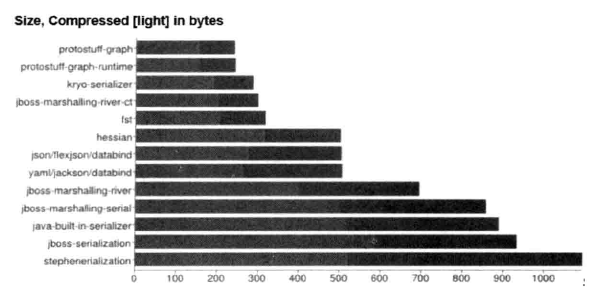
不同的应用场景对序列化框架的需求也不同,对于高性能应用场景,Netty 默认提供了 Google 的 Protobuf 二进制序列化框架,如果用户对其他二进制序列化框架有需求,也可以基于 Netty 提供的编解码框架扩展实现。
零拷贝
Netty 的“零拷贝”主要体现在如下三个方面:
其一:Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存(HEAP BUFFERS)进行 Socket 读写,JVM 会将堆内存 Buffer 拷贝一份到直接内存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
JDK内存拷贝代码如下:
public class IOUtil {
static int write(FileDescriptor var0, ByteBuffer var1, long var2, NativeDispatcher var4) throws IOException {
if (var1 instanceof DirectBuffer) {
return writeFromNativeBuffer(var0, var1, var2, var4);
//..
}
}
}其二:第二种“零拷贝”的实现 CompositeByteBuf,它对外将多个 ByteBuf 封装成一个 ByteBuf,对外提供统一封装后的 ByteBuf 接口,它的类定义如下图所示。
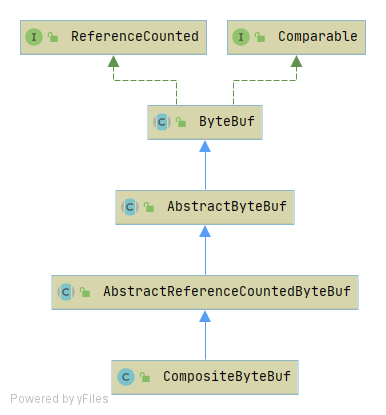
通过继承关系可以看出,CompositeByteBuf 实际就是个 ByteBuf 的装饰器,它将多个 ByteBuf 组合成一个集合,然后对外提供统一的 ByteBuf 接口。添加 ByteBuf,不需要做内存拷贝。
其三:第三种“零拷贝”就是文件传输,Netty 文件传输类 DefaultFileRegion 通过 transferTo 方法将文件发送到目标 Channel 中,下面重点看 FileChannel 的 transferTo 方法,它的 API DOC 说明如下:很多操作系统直接将文件缓冲区的内容发送到目标 Channel 中,而不需要通过循环拷贝的方式,这是一种更加高效的传输方式,提升了传输性能,降低了 CPU 和内存占用,实现了文件传输的“零拷贝”。
具体的零拷贝原理的内容在《Unix ZeroCopy》有详细讲解
内存池
随着 JVM 虚拟机和 JIT 即时编译技术的发展,对象的分配和回收是个非常轻量级的工作。但是对于缓冲区 Buffer,情况却稍有不同,特别是对于堆外直接内存的分配和回收,是一件耗时的操作。为了尽量重用缓冲区,Netty 提供了基于内存池的缓冲区重用机制。下图展现了 PooledByteBuf 继承关系图。
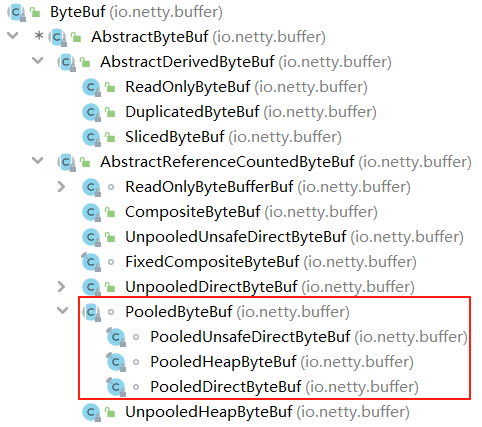
Netty 提供了多种内存管理策略,通过在启动辅助类中配置相关参数,可以实现差异化的定制。
通过性能测试,基于内存池循环利用的 ByteBuf 和普通 ByteBuf 的性能差 23 倍左右。
具体的内存池优化的内容在《Netty 内存池优化原理》有详细讲解
灵活的TCP参数配置能力
合理设置 TCP 参数在某些场景下对于性能的提升可以起到显著的效果,例如 SO_RCVBUF 和 SO_SNDBUF。如果设置不当,对性能的影响是非常大的。下面我们总结下对性能影响比较大的几个配置项。
- SO_RCVBUF 和 SO_SNDBUF:通常建议值为128KB 或者 256KB;
- SO_TCPNODELAY:NAGLE 算法通过将缓冲区内的小封包自动相连,组成较大的封包,阻止大量小封包的发送阻塞网络,从而提高网络应用效率。但是对于时延敏感的应用场景需要关闭该优化算法;
- 软中断:如果 Linux 内核版本支持 RPS(2.6.35 以上版本),开启 RPS 后可以实现软中断,提升网络吞吐量。RPS 根据数据包的源地址,目的地址以及目的和源端口,计算出一个 hash 值,然后根据这个 hash 值来选择软中断运行的 CPU。从上层来看,也就是说将每个连接和 CPU 绑定,并通过这个 hash 值,来均衡软中断在多个 CPU 上,提升网络并行处理性能。
其余配置项 ChannelOption