Go 基础语法
声明
Go 主要有四种类型的声明语句:var、const、type 和 func,分别对应变量、常量、类型和函数实体对象的声明。
变量
s := "" //只能用在函数内部,而不能用于包变量
var s string //默认初始化为 "" 也可以声明多个变量 var a, b, c string
var s = "" //可以声明多个变量 var a, b, c = "", "", ""
var s string = "" //显式地标明变量的类型创建变量:new
表达式new(T)将创建一个 T 类型的匿名变量,初始化为 T 类型的零值,然后返回变量地址,返回的指针类型为*T。
p := new(int) // p, *int 类型, 指向匿名的 int 变量
fmt.Println(*p) // "0"
*p = 2 // 设置 int 匿名变量的值为 2
fmt.Println(*p) // "2"用 new 创建变量和普通变量声明语句方式创建变量没有什么区别,除了不需要声明一个临时变量的名字外,我们还可以在表达式中使用 new(T)。换言之,new函数类似是一种语法糖,而不是一个新的基础概念。
当然也可能有特殊情况:如果两个类型都是空的,也就是说类型的大小是 0,例如struct{}和[0]int,有可能有相同的地址(依赖具体的语言实现)(译注:请谨慎使用大小为 0 的类型,因为如果类型的大小为 0 的话,可能导致 Go 语言的自动垃圾回收器有不同的行为,具体请查看runtime.SetFinalizer函数相关文档)。
常量
const s = ""
const s string = ""
const {
e = 2.71828
pi = 3.14159
}类型
一个类型声明语句创建了一个新的类型名称,和现有类型具有相同的底层结构。新命名的类型提供了一个方法,用来分隔不同概念的类型,这样即使它们底层类型相同也是不兼容的。
type 类型名字 底层类型类型声明语句一般出现在包一级,因此如果新创建的类型名字的首字符大写,则在包外部也可以使用。
func main() {
type Score int
var math Score = 100
//做数值运算不改变自定义类型
fmt.Printf("Type(math):%T Type(math-50):%T\n", math, math - 50)
//该自定义类型与int底层数据结构相同,所以 == 结果为 true
fmt.Printf("math == 100 -> %t\n", math == 100)
//T(x)可将基础类型转为自定义类型,int(T)可将自定义类型转为基础类型
fmt.Printf("Type(100):%T Type(Score(100)):%T Type(int(Score)):%T\n", 100, Score(100), int(Score(100)))
}数据类型
一维数组
声明数组时需要指定元素类型及元素个数
var variable_name [SIZE] variable_type初始化方式
array := [10]int32 {1, 2, 3, 4}
array := [...]int32 {1, 2, 3, 4}
//创建一个长度为11的一维数组,下标为9元素的设置为1,下标为10元素的设置为2
array := [...]int {9: 1, 10: 2} //[0 0 0 0 0 0 0 0 0 1 2]
//创建一个长度为12的一维数组,下标为9元素的设置为1,后续依次初始化
array := [...]int {9: 1, 2, 3} //[0 0 0 0 0 0 0 0 0 1 2 3]多维数组
声明数组时需要指定元素类型及元素个数
var variable_name [SIZE_1][SIZE_2][SIZE_3] variable_typeSlice
数组和 Slice 之间有着紧密的联系。一个 Slice 是一个轻量级的数据结构,提供了访问数组子序列元素的功能,而且 Slice 的底层引用了一个数组对象。多个 Slice 之间可以共享底层的数据,并且引用的数组部分区间可能重叠。
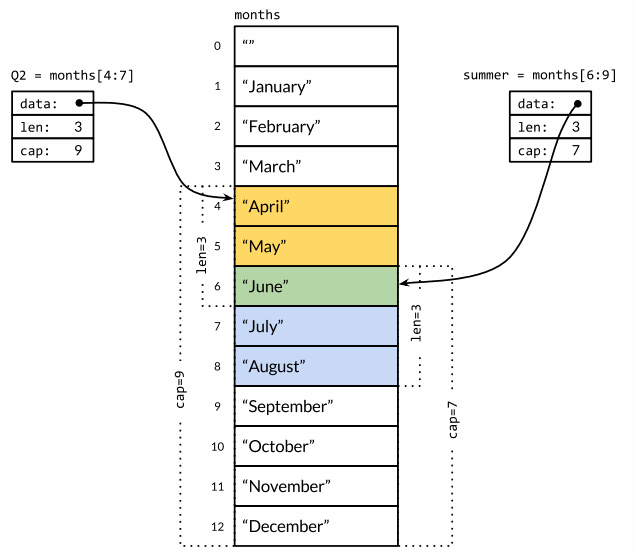
如果切片操作超出 cap(s) 的上限将导致一个 panic 异常,但是超出 len(s) 则是意味着扩展了 Slice,因为新 Slice 的长度会变大。
因为 Slice 值包含指向第一个 Slice 元素的指针,因此向函数传递 Slice 将允许在函数内部修改底层数组的元素。换句话说,复制一个 Slice 只是对底层的数组创建了一个新的 Slice 别名。更改 Slice 会对底层数组造成影响。
切片定义
var identifier []type //与数组不同的是,切片不需要说明长度需要注意的是,不执行创建或者初始化操作,slice 默认值为 nil
创建切片
slice := make([]T, length)
slice := make([]T, length, capacity)length 代表当前数组长度,capacity 代表当前预分配空间容量
切片初始化及切片属性获取
slice := []int {1, 2, 3}
fmt.Printf("len=%d cap=%d slice=%v", len(s), cap(s), s)
//len=3 cap=3 slice=[1 2 3]切片截取
s := arr[:]
s := arr[startIndex:]
s := arr[:endIndex]
s := arr[startIndex:endIndex]缺省 startIndex 代表从 arr 的首个元素下标开始,缺省 endIndex 代表到 arr 的末尾元素结束。
切片添加及拷贝
func main() {
s := []int {1,2,3}
printSlice(s)
//添加一个或多个元素
s1 := append(s, 4,5,6)
printSlice(s1)
//拷贝 s1 内容到 s2
s2 := make([]int, len(s1), 2 * cap(s1))
copy(s2, s1)
printSlice(s2)
}
func printSlice(s []int) {
fmt.Printf("len=%d cap=%d slice=%v\n", len(s), cap(s), s)
}Map
内置的 make 函数可以创建一个 map:
ages := make(map[string]int) // mapping from strings to ints
ages := make(map[string]map[string]bool) // mapping from strings to [strings]bool我们也可以用 map 字面值的语法创建 map,同时还可以指定一些最初的 key/value:
ages := map[string]int{
"alice": 31,
"charlie": 34,
}
ages := map[string]int{}因此,另一种创建空的map的表达式是map[string]int{}。
使用内置的 delete 函数可以删除元素:
delete(ages, "alice") // remove element ages["alice"]所有这些操作是安全的,即使这些元素不在 map 中也没有关系;如果一个查找失败将返回 value 类型对应的零值,例如,即使 map 中不存在 “bob” 下面的代码也可以正常工作,因为 ages[“bob”] 失败时将返回 0。
ages["bob"] = ages["bob"] + 1 // happy birthday!但是map中的元素并不是一个变量,因此我们不能对 map 的元素进行取址操作:
_ = &ages["bob"] // compile error: cannot take address of map element禁止对 map 元素取址的原因是 map 可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
要想遍历 map 中全部的 key/value 对的话,可以使用 range 风格的 for 循环实现,和之前的 slice 遍历语法类似。下面的迭代语句将在每次迭代时设置 name 和 age 变量,它们对应下一个键/值对:
for name, age := range ages {
fmt.Printf("%s\t%d\n", name, age)
}通过 key 作为索引下标来访问 map 将产生一个 value。如果 key 在 map 中是存在的,那么将得到与 key 对应的 value;如果 key 不存在,那么将得到 value 对应类型的零值。
age, ok := ages["bob"]
if !ok { /* "bob" is not a key in this map; age == 0. */ }结构体
结构体定义
type struct_variable_type struct {
member definition;
member definition;
...
member definition;
}
//Initialization
variable_name := struct_variable_type{value1, value2, ...}如果结构体成员名字是以大写字母开头的,那么该成员就是导出的。一个结构体可能同时包含导出和未导出的成员。
Note:由于普通函数形参传递方式采取的是值传递,因此在方法体内必须使用引用传递的方式修改结构体中的内容。当然,使用指针传递结构体效率会更高。
结构体初始化
type Point struct{ X, Y int }
//可初始化未导出成员
p := Point{1, 2}
//不可初始化未导出成员
p := Point{X: 1, Y: 2}因为结构体通常通过指针处理,可以用下面的写法来创建并初始化一个结构体变量,并返回结构体的地址:
pp := &Point{1, 2}
//它和下面的语句是等价的
//pp := new(Point)
//*pp = Point{1, 2}结构体嵌入和匿名成员
结构体嵌入
type Parent struct {
X int
}
type Child struct {
P Parent //嵌入
Y int
}
s := Child{P: Parent{X: 1}, Y: 2}
fmt.Println(s.P.X) //调用链长结构体匿名成员
拷贝形式的匿名成员
type Parent struct {
X int
}
type Child struct {
Parent //匿名成员
Y int
}
s := Child{Parent: Parent{X: 1}, Y: 2}
fmt.Println(s.X) //调用链短引用形式的匿名成员
type Parent struct {
X int
}
type Child struct {
*Parent //引用形式的匿名成员
Y int
}
s := Child{Parent: Parent{X: 1}, Y: 2}
fmt.Println(s.X) //调用链短其他编码格式
Go 语言对于这些标准格式的编码和解码都有良好的支持,由标准库中的encoding/json、encoding/xml、encoding/asn1等包提供支持(译注:Protocol Buffers的支持由 github.com/golang/protobuf 包提供),并且这类包都有着相似的 API 接口。
对于复杂的打印格式,一般需要将格式化代码分离出来以便更安全地修改。这些功能是由text/template和html/template等模板包提供的,它们提供了一个将变量值填充到一个文本或HTML格式的模板的机制。
流程控制
判断
if condition {
} else if condition {
} else {
}循环
//方式 1
for init; condition; post { }
//example: for i := 1; i < 5; i++ { }
//方式 2
for condition { }
//example: for i < 5 { }
//方式 3 无限循环
for { }
//方式 4
for key, value := range specific_type { //如果不需要 key 可用 _ 代替
specific_type_new[key] = value
}Note:range 关键字用于 for 循环中迭代字符串(string)、数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。
Note:for 中可使用 break 和 continue 关键字
分支
与 Java 不同的是,不需要 break 中断执行。
switch flag {
case case_1: handle_1
case case_2, case_3: handle_2
default: handle_3
}跳转
值得一提的是,Go 启用了 Java 消灭掉的 goto 关键字,用法如下:
LOOP: for a < 20 {
if a == 15 {
a++
goto LOOP
}
fmt.Printf("%d\n", a)
a++
}函数
函数定义
func function_name ([parameter list]) [return_types] {
}对于 return_types 来说,一个函数可以有 0 个或多个返回值。
函数变量
在 Go 中,函数可以作为变量进行使用。该变量对应的是函数的地址。
//已声明函数变量
printer := fmt.Println
//匿名函数变量
var printer = func(str string) {
fmt.Println(str)
}
printer("hello world")闭包
func main() {
next := getSequence()
println(next())
println(next())
next2 := getSequence()
println(next2())
}
func getSequence() func() int {
i := 0
return func() int {
i++
return i
}
}
//1
//2
//1main函数和init函数
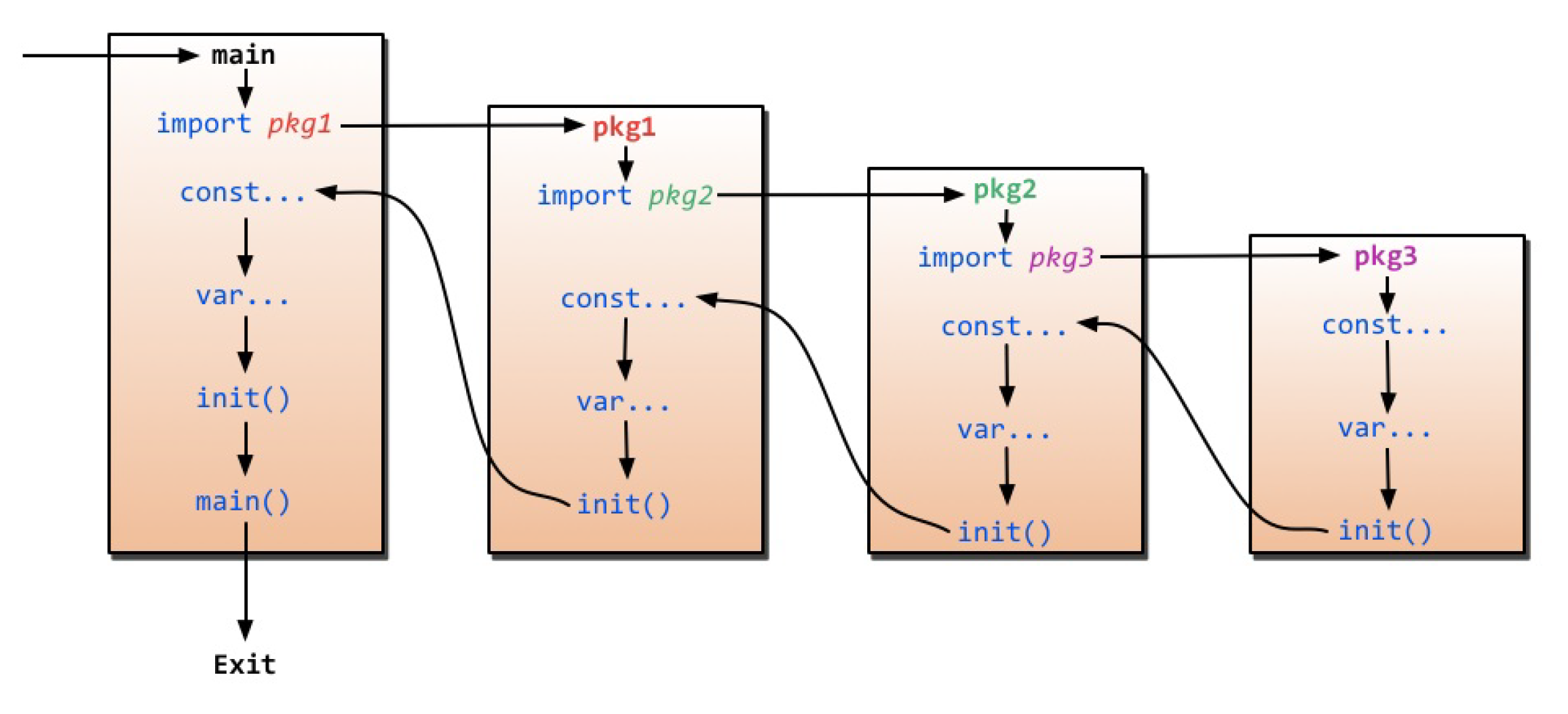
Go 里面有两个保留的函数:init 函数(能够应用于所有的 package)和 main 函数(只能应用于 package main)。这两个函数在定义时不能有任何的参数和返回值。虽然一个 package 里面可以写任意多个 init 函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个 package 中每个文件只写一个 init 函数。Go 程序会自动调用 init() 和 main(),所以你不需要在任何地方调用这两个函数。每 package 中的 init 函数都是可选的,但 package main 就必须包含一个 main 函数。程序的初始化和执行都起始于 main 包。如果 main 包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到 fmt 包,但它只会被导入一次,因为没有必要导入多次)。当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行 init 函数(如果有的话)依次类推。等所有被导入的包都加载完毕了,就会开始对 main 包中的包级常量和变量进行初始化,然后执行 main 包中的 init 函数(如果存在的话),最后执行 main 函数。下图详细地解释了整个执行过程:
方法
方法定义
在函数声明时,在其名字之前放上一个变量,即是一个方法。这个附加的参数会将该函数附加到这种类型上,即相当于为这种类型定义了一个独占的方法。
func main() {
var c Circle = Circle{"1"}
c.draw()
}
type Circle struct {
id string
}
//在不需要获取调用对象实例时,可以不命名 func (Circle) draw() {
func (c Circle) draw() {
println("Circle: " + c.id)
}上面的代码里附加参数 c 叫做方法的接收器(receiver),而 receiver.function_signature的表达式叫做选择器(selector)。方法调用的过程可以想象成向函数发送了一个消息,消息通过 receiver 接收,并以 selector 的方式选择对应的实例进行处理。
在 Go 语言中,我们并不会像其它语言那样用 this 或者 seIf 作为接收器;我们可以任意的选择接收器的名字。由于接收器的名字经常会被使用到,所以保持其在方法间传递时的一致性和简短性是不错的主意。这里的建议是可以使用其类型的第一个字母。
基于指针对象的方法定义
当调用一个函数时,会对其每一个参数值进行拷贝,如果一个函数需要更新一个变量,或者函数的其中一个参数实在太大我们希望能够避免进行这种默认的拷贝,这种情况下我们就需要用到指针了。
func (c *Circle) draw() {
println("Circle: " + c.id)
}上面的方法可以通过(*Circle).draw调用这个方法的名字是。这里的括号是必须的;没有括号的话这个表达式可能会被理解为*(Circle.draw)。
在现实的程序里,一般会约定如果Point这个类有一个指针作为接收器的方法,那么所有Point的方法都必须有一个指针接收器,即使是那些并不需要这个指针接收器的函数。
只有类型(Point)和指向他们的指针(*Point),才可能是出现在接收器声明里的两种接收器。此外,为了避免歧义,在声明方法时,如果一个类型名本身是一个指针的话,是不允许其出现在接收器中的,比如下面这个例子:
type P *int
func (P) f() { /* ... */ } // compile error: invalid receiver type在每一个合法的方法调用表达式中,也就是下面三种情况里的任意一种情况都是可以的:
要么接收器的实际参数和其形式参数是相同的类型,比如两者都是类型 T 或者都是类型 *T:
Point{1, 2}.Distance(q) // Point
pptr.ScaleBy(2) // *Point或者接收器实参是类型 T,但接收器形参是类型 *T,这种情况下编译器会隐式地为我们取变量的地址:
p.ScaleBy(2) // implicit (&p)或者接收器实参是类型 *T,形参是类型 T。编译器会隐式地为我们解引用,取到指针指向的实际变量:
pptr.Distance(q) // implicit (*pptr)如果命名类型 T 的所有方法都是用 T 类型自己来做接收器(而不是*T),那么拷贝这种类型的实例就是安全的;调用他的任何一个方法也就会产生一个值的拷贝。但是如果一个方法使用指针作为接收器,你需要避免对其进行拷贝,因为这样可能会破坏掉该类型内部的不变性。比如你对 bytes.Buffer 对象进行了拷贝,那么可能会引起原始对象和拷贝对象只是别名而已,实际上它们指向的对象是一样的。紧接着对拷贝后的变量进行修改可能会有让你有意外的结果。
方法表达式
func main() {
var c Circle = Circle{}
p := Circle.draw //选择器
p(c) //接收器
fmt.Printf("%T\n",p)
q := (*Circle).draw
q(&c)
fmt.Printf("%T\n",q)
}
type Circle struct { }
func (c Circle) draw() { }
//func(main.Circle)
//func(*main.Circle)接口
对于接口来说,通过 new 关键字创建接口对应的方法实现 struct。
func main() {
var sp Sharp
sp = new(Circle)
sp.draw()
sp = new(Triangle)
sp.draw()
}
type Sharp interface {
draw()
}
type Circle struct {}
func (Circle) draw() {
println("Circle")
}
type Triangle struct {}
func (Triangle) draw() {
println("Triangle")
}类型断言
Go 提供了断言的功能。Go 中的所有类型都实现了 interface{} 的接口。当一个数据通过 interface{} 的方式传入方法体内会被自动转换成 interface{} 的类型。
func main() {
validate("hello")
}
func validate(a interface{}) {
value, ok := a.(string)
if !ok {
fmt.Println("It's not ok for type string")
return
}
fmt.Println("The value is", value)
}配合 switch 有更加简洁易用的语法
func main() {
validate(nil)
}
func validate(x interface{}) {
switch i := x.(type) {
case nil:
fmt.Println("x's type is ", i)
case func(int) bool:
fmt.Println("x's type is ", i)
case int:
fmt.Println("x's type is ", i)
default:
fmt.Println("No such type")
}
}特性
面向对象三大特性
封装
type Data struct {
id int
}
func (d *Data) getId() int {
return d.id
}
func (d *Data) setId(id int) {
d.id = id
}
func main() {
d := &Data{1}
println(d.getId())
d.setId(2)
println(d.getId())
}继承
type Parent struct {
p int
}
type Child struct {
Parent
c int
}
func main() {
c := Child{Parent{1}, 2}
fmt.Println(c.p)
}多态
type Sharp interface {
draw()
}
type Circle struct {}
func (Circle) draw() {
println("Circle")
}
type Triangle struct {}
func (Triangle) draw() {
println("Triangle")
}
func main() {
var sp Sharp
sp = new(Circle)
sp.draw()
sp = new(Triangle)
sp.draw()
}Deferred机制
defer println(3)
defer println(2)
panic("panic exception")
defer println(1)
//Console
2
3延迟执行函数会在程序执行结束或发生 panic 异常后倒序执行。
Panic异常
Go的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等。这些运行时错误会引起painc异常。
一般而言,当 panic 异常发生时,程序会中断运行,并立即执行在该 goroutine 中被延迟的函数(defer 机制)。随后,程序崩溃并输出日志信息。日志信息包括 panic value 和函数调用的堆栈跟踪信息。panic value 通常是某种错误信息。对于每个 goroutine,日志信息中都会有与之相对的,发生 panic 时的函数调用堆栈跟踪信息。通常,我们不需要再次运行程序去定位问题,日志信息已经提供了足够的诊断依据。因此,在我们填写问题报告时,一般会将 panic 异常和日志信息一并记录。
不是所有的 panic 异常都来自运行时,直接调用内置的 panic 函数也会引发 panic 异常;panic 函数接受任何值作为参数。当某些不应该发生的场景发生时,我们就应该调用 panic。比如,当程序到达了某条逻辑上不可能到达的路径:
switch s := suit(drawCard()); s {
case "Spades": // ...
case "Hearts": // ...
case "Diamonds": // ...
case "Clubs": // ...
default:
panic(fmt.Sprintf("invalid suit %q", s)) // Joker?
}断言函数必须满足的前置条件是明智的做法,但这很容易被滥用。除非你能提供更多的错误信息,或者能更快速的发现错误,否则不需要使用断言,编译器在运行时会帮你检查代码。
func Reset(x *Buffer) {
if x == nil {
panic("x is nil") // unnecessary!
}
x.elements = nil
}虽然 Go 的 panic 机制类似于其他语言的异常,但 panic 的适用场景有一些不同。由于 panic 会引起程序的崩溃,因此 panic 一般用于严重错误,如程序内部的逻辑不一致。对于大部分漏洞,我们应该使用 Go 提供的错误机制,而不是 panic,尽量避免程序的崩溃。在健壮的程序中,任何可以预料到的错误,如不正确的输入、错误的配置或是失败的 I/O 操作都应该被优雅的处理,最好的处理方式,就是使用 Go 的错误机制。
Recover捕获异常
通常来说,不应该对 panic 异常做任何处理,但有时,也许我们可以从异常中恢复,至少我们可以在程序崩溃前,做一些操作。
如果在 deferred 函数中调用了内置函数 recover,并且定义该 defer 语句的函数发生了 panic 异常,recover 会使程序从 panic 中恢复,并返回 panic value。导致 panic 异常的函数不会继续运行,但能正常返回。在未发生 panic 时调用 recover,recover会返回nil。
让我们以语言解析器为例,说明 recover 的使用场景。考虑到语言解析器的复杂性,即使某个语言解析器目前工作正常,也无法肯定它没有漏洞。因此,当某个异常出现时,我们不会选择让解析器崩溃,而是会将 panic 异常当作普通的解析错误,并附加额外信息提醒用户报告此错误。
func Parse(input string) (s *Syntax, err error) {
defer func() {
if p := recover(); p != nil {
err = fmt.Errorf("internal error: %v", p)
}
}()
// ...parser...
}deferred 函数帮助 Parse 从 panic 中恢复。在 deferred 函数内部,panic value 被附加到错误信息中;并用 err 变量接收错误信息,返回给调用者。我们也可以通过调用 runtime.Stack 往错误信息中添加完整的堆栈调用信息。
不加区分的恢复所有的 panic 异常,不是可取的做法;因为在 panic 之后,无法保证包级变量的状态仍然和我们预期一致。比如,对数据结构的一次重要更新没有被完整完成、文件或者网络连接没有被关闭、获得的锁没有被释放。此外,如果写日志时产生的 panic 被不加区分的恢复,可能会导致漏洞被忽略。
虽然把对 panic 的处理都集中在一个包下,有助于简化对复杂和不可以预料问题的处理,但作为被广泛遵守的规范,你不应该试图去恢复其他包引起的 panic 。公有的 API 应该将函数的运行失败作为 error 返回,而不是 panic。同样的,你也不应该恢复一个由他人开发的函数引起的 panic ,比如说调用者传入的回调函数,因为你无法确保这样做是安全的。
基于以上原因,安全的做法是有选择性的 recover。换句话说,只恢复应该被恢复的 panic 异常,此外,这些异常所占的比例应该尽可能的低。为了标识某个 panic 是否应该被恢复,我们可以将 panic value 设置成特殊类型。在 recover 时对 panic value 进行检查,如果发现 panic value 是特殊类型,就将这个 panic 作为 error 处理,如果不是,则按照正常的 panic 进行处理(在下面的例子中,我们会看到这种方式)。
下面的例子是 title 函数的变形,如果 HTML 页面包含多个 <title>,该函数会给调用者返回一个错误(error)。在 soleTitle 内部处理时,如果检测到有多个<title>,会调用 panic,阻止函数继续递归,并将特殊类型 bailout 作为 panic 的参数。
// soleTitle returns the text of the first non-empty title element
// in doc, and an error if there was not exactly one.
func soleTitle(doc *html.Node) (title string, err error) {
type bailout struct{}
defer func() {
switch p := recover(); p {
case nil: // no panic
case bailout{}: // "expected" panic
err = fmt.Errorf("multiple title elements")
default:
panic(p) // unexpected panic; carry on panicking
}
}()
// Bail out of recursion if we find more than one nonempty title.
forEachNode(doc, func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "title" &&
n.FirstChild != nil {
if title != "" {
panic(bailout{}) // multiple titleelements
}
title = n.FirstChild.Data
}
}, nil)
if title == "" {
return "", fmt.Errorf("no title element")
}
return title, nil
}在上例中,deferred 函数调用 recover,并检查 panic value。当 panic value 是 bailout{} 类型时,deferred 函数生成一个 error 返回给调用者。当 panic value 是其他 non-nil 值时,表示发生了未知的 panic 异常,deferred 函数将调用 panic 函数并将当前的 panic value 作为参数传入;此时,等同于 recover 没有做任何操作。(请注意:在例子中,对可预期的错误采用了 panic,这违反了之前的建议,我们在此只是想向读者演示这种机制。)
有些情况下,我们无法恢复。某些致命错误会导致 Go 在运行时终止程序,如内存不足。