由于异常并不会给功能带来实质性的提升,因此在业务代码中会经常忽略它的重要性。但需要注明的是,通过妥善的异常处理开发出更高质量的软件。
异常
异常主要有着通知的作用,在发生异常后,可进行异常报警、错误重试、故障恢复等操作。
影响软件强健度的因素
影响软件强健度的因素有四种:fault(缺陷)、error(错误)、failure(失效)、exception(异常)。
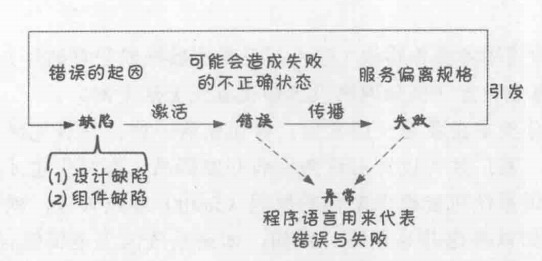
fault
fault(缺陷)是假设或是经过判断之后所确定导致错误(error)发生的原因。
其依据存在时间长短可分为以下三类:
- 瞬时缺陷(transient fault)
- 间歇缺陷(intermittent fault)
- 永久缺陷(permanent fault)
其依据产生原因可分为以下两类:
- 设计缺陷(design fault):软件开发过程中的固有的问题。
- 组件缺陷(component fault):组件因物理设备导致或组件间交互所产生的问题。
failure
当一个软件组件(function、method、service)所提供的服务与其功能规格(functional specification)相符,可以称组件提供了正确的服务(corrent service)。如果组件偏离了正确服务,我们称之为服务失败(service failure)。
exception
异常(exception)是程序语言中表达错误与失败的一种概念。
流程的切分
服务间边界
服务间通过 RPC、HTTP 等方式进行交互,调用失败时,不需要了解其具体含义上的异常信息,只需要知道三类信息:调用服务是否存活、传入参数合法性、调用服务正确性。
模块(或功能)间边界及函数间边界
微服务中的模块与函数其实本质上是相同的,目的是为了抽象出一个层次化的业务异常结构。但又是相区别的,模块的层次化异常结构与安全网更高层,也就是更偏近于业务侧。例如:将交易模块的整体异常捕获并转化为业务异常信息。而函数的层次化异常结构与安全网更底层。例如:将参数错误、计算错误、SQL错误等封装为通用的异常实例。
总的来说,模块间边界更业务化、更细化,函数间边界更底层化、通用化。
异常处理等级
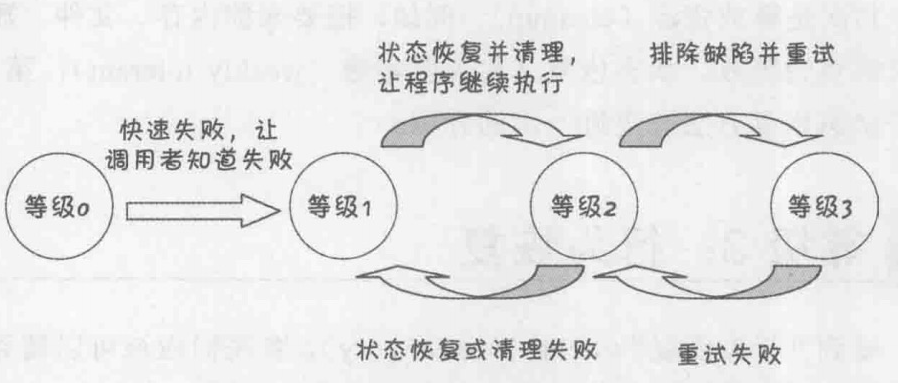
异常处理随着处理能力的不同被分为四个等级,并且可以通过升级和降级来解决现实中遇到的问题。
| 项目 | 等级0 | 等级1 | 等级2 | 等级3 |
|---|---|---|---|---|
| 名称 | 未定义(Undefined) | 错误报告(Error-reporting) | 状态恢复(State-recovery) | 行为恢复(Behavior-recovery) |
| 服务 | 隐式或显式失败 | 显式失败 | 显式失败 | 持续提供 |
| 状态 | 未知或不正确 | 未知或不正确 | 正确 | 正确 |
| 生命周期 | 终止或继续 | 终止 | 继续 | 继续 |
| 如何达成 | NA | 1. 传递所有未被处理的异常 2. 在主程序中报告所有的异常 |
1. 错误处理(error handling) 2. 资源清理(cleanup) |
1. 缺陷处理(fault handling) 2. 重试(retry,and/or) 3. 设计多样性(design diversity),功能多样性(functional diversity),数据多样性(data diversity),时序多样性(temporal diversity) |
| 别名 | NA | 快速失败(failing-fast) | 弱容错(weakly tolerant) | 强容错(strongly tolerant) |
等级1:错误报告
错误报告(error-reporting),是指函数不捕捉异常,将所有发生的异常传递到它的调用者(向上传递)。
建立安全网
在各模块边界通过统一使用一个 try 语句建立安全网,可以捕获所有异常以避免程序异常终止。此外,还可以将异常转换为更易理解的异常信息并写入日志文件。
等级2:状态恢复
与错误报告不同的是,状态恢复要求当错误发生后,服务必须保证系统仍然处于正确状态。由于整个系统的状态还是正确的,因此,当异常发生之后,系统仍然可以继续执行。
要想达到状态恢复的状态级别,需要多做两件事。首先是错误处理(error handling),让系统恢复到正确的状态,例如事务回滚。其次是释放资源(cleanup),将之前用到的内存、磁盘等资源正确的释放。状态恢复又称为“弱容错”(weakly tolerant)。
错误处理关注系统内部的状态,而资源清理强调“外部资源(操作系统或执行环境)”的清理,避免资源泄漏,连接池用尽等情况。
错误处理(向后恢复)
错误处理的目的在于移除错误造成的不正确状态,将系统恢复到一个没有错误的状态(error-free state)。向后恢复(backward recovery)是指当错误发生的时候,将系统恢复至错误发生之前所保留的状态,所以称为“向后恢复”(也可以称为回滚)。
向后恢复是假设系统发生错误之前处在正确状态,这个假设需要成立,否则保留这个状态就没有意义了。向后恢复需借助不会被系统失败所影响的稳定存储装置(stable storage,例如硬盘)来保留状态。我们在异常处理中所说的错误处理就是指采用硬盘。
依据其实现方法不同,又可以细分为以下两种。
- 基于状态的(state-based):存储一个完整的正确状态,待错误发生之后丢弃整个错误状态,以所存储的正确状态来取代。例如检查点(check pointing)、 快照(snapshot)和时光机(time machine)等都属于这一类。
- 基于操作的(operation-based):不采用存储完整正确状态的方式,改以存储改变状态的事件或是操作。当错误发生之后,利用这些存储下来的状态改变记录,反向取消原本的操作以达到状态复原的效果。例如审计轨迹(audit trail)和日志记录(logging)等。
基于状态的向后恢复
读取文件时建立恢复点(check pointing),当执行失败后,回退到恢复点重试。
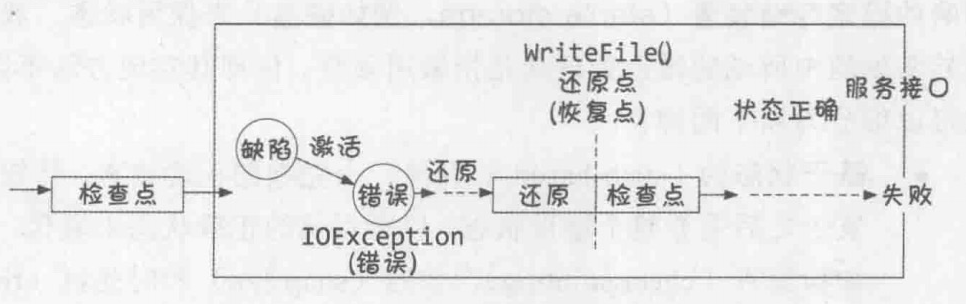
基于操作的向后恢复
以操作为基础的向后恢复方法,是采取撤销(undo)原本操作的方式来还原系统的状态。举个例子,假设某在线游戏被黑客入侵,有些玩家的宝物被盗,此时系统处在一个不正确的状态。在这种情况下,由于整个在线游戏世界一直在改变,系统并没有存在一个合适的检查
点(正确状态的备份)可以用来执行状态还原。如果系统平常针对宝物买卖的交易与玩家状态改变都有妥善记录在日志文件中,则可以利用日志文件的数据来反向回推出每一位受害玩家的正确状态。要用这种方法来还原状态,系统必须记录足够的额外信息。
常见的方式有使用冗余数据与冗余函数来达成状态还原。以在线游戏为例,每一笔宝物事务数据或是玩家的状态改变,都必须要写入到日志文件(冗余资料),日后才可以利用这个日志文件来恢复数据。
另一个常见的程序设计技巧则是套用 Command 设计模式,将每一个操作包装成一个独立的类别, 在此类中提供 do 和 undo(冗余函数)两个动作相反的函数,如此便可通过 undo 函数来执行状态还原。
向后恢复的限制
- 耗费资源:记录的操作日志或是快照都会消耗计算机的计算资源、时间和存储空间。
- 系统暂停:其次,在保存与还原系统状态的当下,向后恢复方法可能会要求系统暂时停止(halt)运作、降低系统的服务等级或是拉长系统的响应时间。最后,在分布式系统或是采用嵌套向后恢复的应用中,当一个函数或是进程还原到之前的状态,便可能会引发骨牌效应,触发其他函数或是进程的向后恢复动作。
资源清理
由操作系统或是执行环境(例如 JVM)所管理的外部资源,像是内存、硬盘空间和数据库连接,一般来说都是有限的共享资源。如果使用完毕的资源迟迟没有归还,最后还是会导致资源耗尽,系统无法运作。
一般的资源清理涉及到两方面内容:内存管理、资源释放。
等级3:行为恢复
行为恢复要求当错误发生后,服务仍然是正确的,系统仍然可以正常运行。
要达到强健度等级 3 的阶段,除了要做到强健度等级 2 的错误处理(error handling)和资源清理(cleanup)之外,还需要“想其他方法来达成原本的任务”。为了不让下次执行再度失败,需要先启动缺陷处理(fault handling)以排除造成失败的原因。造成错误的缺陷排除之后,便可套用重试(retry)与设计多样性(design diversity)、功能多样性(functional diversity)、数据多样性(data diversity)、时序多样性(temporal diversity)等设计技巧,尝试继续提供服务。行为恢复又称为“强容错”(strongly tolerant)。
重试
成功执行缺陷之后,只要在新的系统配置之下重试原本的操作(此时,原本操作的实现方式可能已经改变,例如采用备用组件取代原本失效的组件),系统应该就可以提供正确的服务。
重试的结果能否成功,有很大的程度受到缺陷处理的重新配置所影响。针对瞬时缺陷或是间歇缺陷,重新配置的实现结果有可能并不需要改变任何系统配置,仅通过重试原本实现(retry with the pirmary)即可。但如果是永久缺陷或是想要彻底解决间歇缺陷,只是重试原本的实现显然是行不通的。因此,重新配置阶段便必须要使用替换的组件或是新的执行路径来取代有缺陷的组件。此时的重试就称为“重试替代方案”(retry with alternative)。
制作与执行替代方案的技巧,可以分成以下四大类。
设计多样性(design diversity)
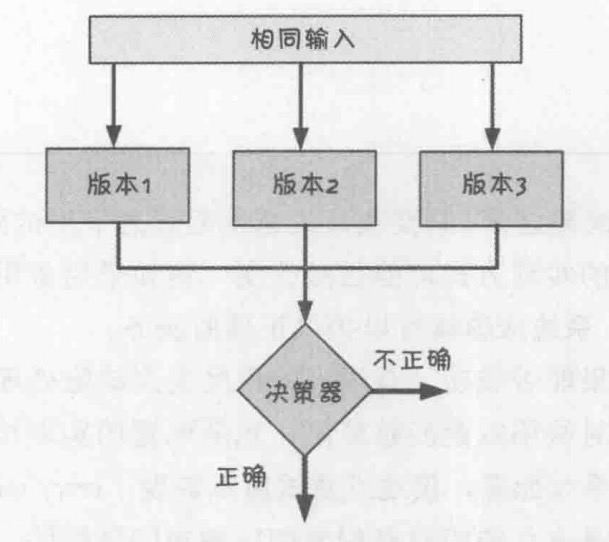
将同一份规格交给不同团队设计与实现出多个功能相同的版本。设计多样性在软件容错设计中是一种很常见的作法,常见的方式有 N 版本程序设计(N-Version Programming, NVP)与恢复区块(recovery block)。
N 版本程序设计,即在同一时间一个函数的多个版本同时执行,其执行结果交由决策器来判断,最后选出一个正确的结果。虽然这三个实现版本有一个存在着缺陷(很可能是设计缺陷),但因为采用设计多样性的容错策略,这个缺陷并没有对系统服务造成影响。N 版本程序设计的结构如下图所示。
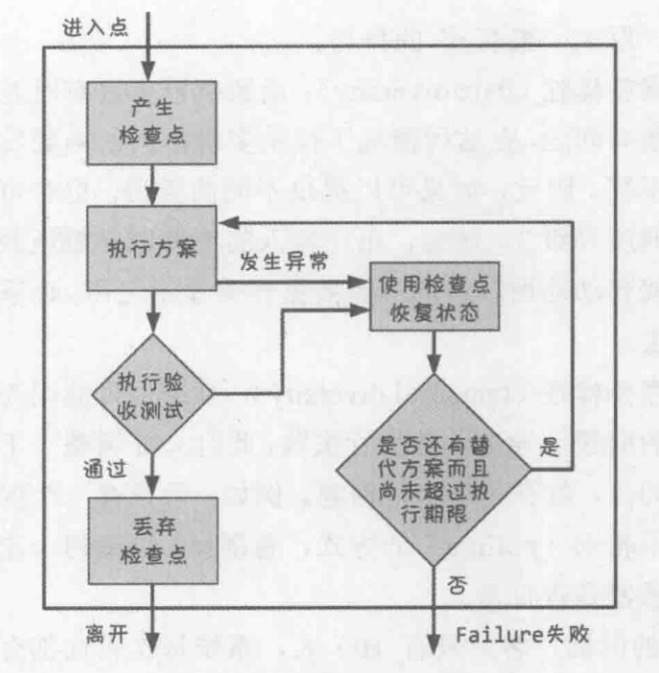
恢复区块,即首先产生检查点,接着执行主要方案。如果主要方案执行过程中没有发生异常,且其结果通过验收测试,则代表主要方案执行成功,丢弃检查点之后便可正常离开恢复区块。反之,若执行主要方案发生异常或其执行结果没有通过验收测试,则使用检查点来恢复系统状态。接着判断是否有替代方案可供选择,而且尚未超过执行期限(例如最多执行三种不同替代方案或是运行时间不能超过30秒)。如果条件都成立,则重新执行替代方案,若不成立则代表恢复区块失效,丢出代表失败的异常。恢复区块的结构如下图所示。
因为设计多样性的成本实在太高了(尤其是 N 版本程序设计),因此在异常处理领域,实际上很少有机会需要采用这个策略来达到强健度等级 3。
比较接近一点的作法则是用函数策略来达到强健度等级 3。比较接近一点的作法则是用函数
来仿真恢复区块的结构,针对已知可能会失效且重要性较高的函数,提供一种或多种实现方式的替代方案。但不像容错设计所要求的设计多样性,需要由不同团队来设计与实现个别版本,在异常处理的领域,替代方案通常由同一个团队设计与实现。
功能多样性(functional diversity)
广义来说,功能多样性也属于设计多样性的一种,不同之处在于功能多样性是采用不同的输入与不同的设计、实现方式来达到相同的功能(设计多样性则是采用相同的输入,不同的设计、实现)。功能多样性又称为“多才多艺的系统”(resourceful system),这种系统可能
需要具备人工智能的能力,也就是系统必须知道如何通过不同的方式来完成相同的目标。例如,假设乡民们使用一个具备功能多样性的高铁订票函数来预订过年期间从台北到高雄的来
回车票。这个函数发现直达车票已经被订完了,但是它有能力用分段的方式,先订从台北到台中,然后再订台中到高雄的车票。针对相同的目标(台北到高雄),具有多种功能可以完成此目标。
在异常处理的领域,除非针对已知且非常重要的功能,否则不太会套用这么繁重的功能。
数据多样性(data diversity)
函数执行失败有时是因为输入的参数有问题,在这种情况下提供多份不同的函数实现可能也无济于事。因此,如果可以提供不同的数据,也有可能可以达到强健度等级 3。例如,用户输入的字体或是颜色数据错误,系统就自动选用默认的一.组数据作为显示之用,让系统可以运行下去。
时序多样性(temporal diversity)
系统也可能因为性能或是时序的问题而导致函数执行失败,此时只要调整一下函数执行的
时间点,就有可能解决问题。例如,假设有一个保安监控系统采用轮询(polling)的方式,每隔60秒询问一次客户家中的传感器是否正常。刚开始的时候,客户只有 100 人,系统每次轮询都会得到正确的结果。但随着生意越做越大,同时间要监控的客户量增加到 1000 人。因为客户数量增加,导致每次询问的失败比例也增加,不是发生超时(timeout)。就是因为系统负载太重而无法在排定的时间点启动轮询。这时候,如果系统调整了轮询间隔(polling interval),就有可能降低轮询失败的几率。
缺陷处理(向前恢复)
系统失败的原因是因为程序的执行触发了某个缺陷(fault)而导致错误(error), 最后形成系统失败(failure)。强健度等级 2 修正了错误状态,但是如果没有进一步的把系统中的缺陷给排除,系统继续执行下去,还是有很高的机会再度触发同一个缺陷,结果最后还是形成
系统失败。缺陷处理就是探讨如何排除缺陷的方法。
严格来讲,它比较偏向容错处理的领域,但是在某些特定的状况之下,异常处理还是可以应用缺陷处理的技巧来提升系统的强健度。依据 Avizienis 等人的分类,缺陷处理包含以下四个操作。
- 诊断(diagnosis):鉴定与记录错误发生的原因,包含错误发生的位置与种类。
- 隔离(isolation):将失败的组件从系统中隔离,以防止后续的操作继续使用这个失败的组件。
- 重新配置(reconfiguration):如果系统有冗余或是备用的组件,则将系统重新配置以便使用这些冗余或备用组件。或是重新指派工作,让没有发生问题的组件来取代被隔离的组件。
- 重新初始化(reinitialization)):确认重新配置之后的系统可运作之后,重新设置系统以便采用这个新的配置。
具备缺陷处理的系统需要有足够的知识与资源,才能够诊断与隔离缺陷,进而做到自我调适(重新配置与重新初始化)。
向前恢复(forward recovery)是状态恢复的一种方式,但因为它让系统“向前”恢复到一个没有错误的状态,也等于说没有发生 failure,因此达到强健度等级 3。
刚刚介绍过的 N 版本程序设计其实就是一种向前恢复加上设计多样性(design diversity)的容错技巧”。因为有多个版本同时执行(可能在一台计算机上,也有可能在不同的计算机上),所以即使有任何一个版本发生 error,整个系统还是可以(向前)回到一个没有错误的状态。
另一种向前恢复的作法需要搭配日志文件,经常应用在数据库系统当中。假设乡民们在一个月前执行了一次数据库备份,一个月后的某一天,因为不明原因数据库文件突然损坏,幸好数据库的事务日志文件还存在。因此你利用备份文件,先将数据库状态恢复到一个月前的状态,再利用事务日志文件,让数据库的状态(向前)来到系统刚刚损坏之前的正确状态。
有些数据库针对实时事务提供向前恢复,当事务进行时会将所需的数据先搬移到内存中,等待事务完成之后,再将事务历史记录写入硬盘中,最后才把内存中的数据写入数据库。如果事务历史记录已经成功写入硬盘,但是内存中的数据尚未写入数据库,此时如果数据库
系统当机,待下次启动之后,数据库便会参考事务历史记录的数据,自动将数据库的内容向前恢复到正确状态。
升级和降级
异常的设计
命名规则讨论
Wirfs-Brock 认为异常类的命名应当遵循以“哪里出了问题”命名。就如同 JDK 正在做的一样,IllegalArgumentException 等异常大多是根据该规则而产生。
但业务中会产生的大量异常,如果一一为其创建实例显然不太现实。业务异常通过遵循以“谁丢出异常”命名则可以很好的完成异常层次结构的构建。例如:使用 TransactionException 来代替所有交易异常。可以大范围的缩减异常类的创建。
将低层异常转成高层所理解的异常
需要了解的是,我们以一个树形的继承关系来管理全部的 Throwable。如果我们现在有一个方法 getText(),当我们底层实现使用数据库来获取用到的数据,该方法应抛出 SQLException;如果使用文件来获取,该方法应抛出 IOException。但无论其以任何底层实现去获取数据,它都应该抛出一个自定义异常 TextManipulationException,而不是 SQLException 或其他。这样做的好处是不论该方法如何修改,都不会影响到丢出异常的类型,而且有助于上层调用者的异常处理设计。而这种聚合底层异常转为高层异常的行为叫做:同构型异常(homogeneous exception)。下面是示例:
orign:
情况1: void getText() throws IOException, SQLException;
情况2: void getText() throws IOException;
情况3: void getText() throws SQLException;
good result:
void getText() throws TextManipulationException;同构型异常可以缓解因为使用已查异常(checked exception)所造成的函数接口改变的问题。因为一个函数只声明一个或少量同构型异常,所以可以避免函数将实现细节所遭遇的异常直接声明在接口上往外传递,也有助于实践“将低层异常转成高层所理解的异常”这条规则。
使用异常的误区
使用异常当作判断条件
将异常当作判断条件是一个非常常见的现象,以把字符串解析为正整数为例有以下三种“经典”写法。
/**
* 异常判断法
* @param str 正整数字符串
* @return 解析错误返回 -1
*/
public static int parseInt(String str) {
try {
return Integer.parseInt(str);
} catch (NumberFormatException e) {
return -1;
}
}
/**
* 正则判断法
* @param str 正整数字符串
* @return 解析错误返回 -1
*/
public static int parseInt(String str) {
if (str.matches("^[1-9]\\d*$"))
return Integer.parseInt(str);
else {
return 0;
}
}
/**
* 简单判断法
* @param str 正整数字符串
* @return 解析错误返回 -1
*/
public static int parseInt(String str) {
for (int i = 0; i < str.length(); i++) {
if (!Character.isDigit(str.charAt(i))) {
return -1;
}
}
return Integer.parseInt(str);
}性能测试
我们通过生成的 10000000 个 1000000 以内的随机正整数作为正例,数字结尾带字母作为反例来测试这三个函数的性能。
| 测试用例 | 全部反例 | 一半反例 | 全部正例 |
|---|---|---|---|
| 异常判断法 | 5237 | 1396 | 268 |
| 正则判断法 | 5247 | 1589 | 7183 |
| 简单判断法 | 261 | 161 | 342 |
我们可以看到,无论在什么情况下,正则匹配的性能永远是最低的。而我们需要讨论的是异常判断法和简单判断法,在全部是反例的情况下,异常逻辑的性能是非常低的,而简单判断法的性能更加稳定。对于偶发性的反例场景,反倒异常判断法是更好的做法。因为结合上面所讲,可以抛出异常来提示调用者关注这个问题。
异常与 JVM 关系
耗时测试
我们对建立 Object 对象、建立 Exception 对象、try-catch 新建且抛出的 Exception 对象三个行为做了测试统计,建立对象耗时 575817ms,建立异常对象耗时 9589080ms,建立、抛出并接住异常对象耗时 47394475ms。
从测试数据可以看出,建立一个异常对象,是建立一个普通 Object 耗时的 20 倍,而 try-catch 一个异常对象,所花费时间大约是建立异常对象的 4 倍。那我们来看看占用时间的“大头”:抛出、接住异常,系统到底做了什么事情?
public void catchException() {
try {
throw new Exception();
} catch (Exception e) {
}
} 字节码的运作过程
使用javap -verbose命令输出它的字节码,结果如下:
public void catchException();
Code:
Stack=2, Locals=2, Args_size=1
0: new #58; //class java/lang/Exception
3: dup
4: invokespecial #60; //Method java/lang/Exception."<init>":()V
7: athrow
8: astore_1
9: return
Exception table:
from to target type
0 8 8 Class java/lang/Exception 偏移地址为 0 的 new 指令:该指令首先会在常量池找到第 58 项常量,此常量现在为 CONSTANT_Class_info 型的符号引用,类解析阶段被翻译为 java.lang.Exception 类的直接引用,接着虚拟机会在 Java 堆中开辟相应大小的实例空间,并将此空间的引用压入操作栈的栈顶。
偏移地址为 3 的 dup 指令:该指令就简单的把栈顶的值复制了一份,重新压入栈顶,这时候操作栈中有 2 份刚刚 new 出来的 exception 对象的引用。
偏移地址为 4 的 invokespecial 指令:该指令将第一个 exception 对象引用出栈,以它为接收者调用了 Excepiton 类的实例构造器,这句执行完后栈顶还剩下一份 exception 对象的引用。简单的来说这 3 条字节码只是执行了 new Exception() 这句 Java 代码应该做的事情,和创建任何一个 Java 对象没有任何区别。这一部分耗费的时间在上面分析过,创建一个异常对象只占创建、抛出并接住异常的 20% 时间。
偏移地址为 7 的 athrow 指令:该指令运作过程大致是以下几步:
检查栈顶异常对象类型,必须是一个 reference 类型的值,且是
java.lang.Throwable的子类(虚拟机规范中要求如果遇到 null 则当作 NPE 异常使用)在加载时仅作类型验证,即只检查是不是 null,是否为 referance 类型。而是否为 Throwable 的子类一般在类验证阶段的数据流分析中做,或者索性不做靠编译器保证了,编译时写到 Code 属性的 StackMapTable 中。
暂时把异常对象的引用出栈
- 搜索异常表,寻找匹配的异常 Handler
- 如果找到合适的 Handler,重新初始化 PC 寄存器指针指向此异常 Handler 的第一个指令的偏移地址。接着把当前栈帧的操作栈清空,再把刚刚出栈的异常对象引用重新入栈。
- 如果找不到合适的 Handler,只好把当前方法的 VM 栈帧出栈,然后对出栈方法的调用者(也就是当前 VM 栈顶的方法)再做一次异常 Handler 检索,直到找到一个可用的为止。
- 如果 VM 栈的栈帧抛光了都没有找到期望的 Handler,这条线程就只好被迫终止。
偏移地址为 8 的 astore_1 指令:该指令作用是把栈顶的值放到第一个 slot 的局部变量表中,刚才说过如果出现异常后,虚拟机找到了 Handler,会把那个出栈的异常引用重新入栈。因此这句 astore_1 实现的目的就是让 catch 块中的代码能访问到 catch (Exception e) 所定义的那个“e”,又顺便提一句,局部变量表从 0 开始,第 0 个 Slot 放的是方法接收者的引用,也就是使用 this 关键能访问的那个对象。
偏移地址为 9 的 return 指令:该指令是 void 方法的返回指令。
异常表
异常表,在运行期一般会实现在栈帧当中
Exception table: from to target type 0 8 8 Class java/lang/Exception上面的异常表只有一个 Handler 记录,它指明了从偏移地址 0 开始(包含0),到偏移地址 8 结束(不包含 8),如果出现了
java.lang.Exception类型的异常,那么就把 PC 寄存器指针转到 8 开始继续执行。顺便说一下,对于 Java 语言中的关键字 catch 和 finally,虚拟机中并没有特殊的字节码指令去支持它们,都是通过编译器生成字节码片段以及不同的异常处理器来实现。