在数据系统的残酷现实中,很多事情都可能出错:
- 数据库软件、硬件可能在任意时刻发生故障(包括写操作进行到一半时)。
- 应用程序可能在任意时刻崩溃(包括一系列操作的中间)。
- 网络中断可能会意外切断数据库与应用的连接,或数据库之间的连接。
- 多个客户端可能会同时写入数据库,覆盖彼此的更改。
- 客户端可能读取到无意义的数据,因为数据只更新了一部分。
- 客户之间的竞争条件可能导致令人惊讶的错误。
为了实现可靠性,系统必须处理这些故障,确保它们不会导致整个系统的灾难性故障。但是实现容错机制工作量巨大。需要仔细考虑所有可能出错的事情,并进行大量的测试,以确保解决方案真正管用。
数十年来,事务(transaction) 一直是简化这些问题的首选机制。事务是应用程序将多个读写操作组合成一个逻辑单元的一种方式。从概念上讲,事务中的所有读写操作被视作单个操作来执行:整个事务要么成功(提交(commit))要么失败(中止(abort),回滚(rollback))。如果失败,应用程序可以安全地重试。对于事务来说,应用程序的错误处理变得简单多了,因为它不用再担心部分失败的情况了,即某些操作成功,某些失败(无论出于何种原因)。
和事务打交道时间长了,你可能会觉得它显而易见。但我们不应将其视为理所当然。事务不是天然存在的;它们是为了简化应用编程模型而创建的。通过使用事务,应用程序可以自由地忽略某些潜在的错误情况和并发问题,因为数据库会替应用处理好这些。(我们称之为安全保证(safety guarantees))。
并不是所有的应用都需要事务,有时候弱化事务保证、或完全放弃事务也是有好处的(例如,为了获得更高性能或更高可用性)。一些安全属性也可以在没有事务的情况下实现。
事务的棘手概念
现今,几乎所有的关系型数据库和一些非关系数据库都支持事务。其中大多数遵循 IBM System R(第一个SQL数据库)在1975年引入的风格【1,2,3】。40 年里,尽管一些实现细节发生了变化,但总体思路大同小异:MySQL,PostgreSQL,Oracle,SQL Server 等数据库中的事务支持与 System R 异乎寻常地相似。
2000 年以后,非关系(NoSQL)数据库开始普及。它们的目标是在关系数据库的现状基础上,通过提供新的数据模型选择(请参阅第二章)并默认包含复制(第五章)和分区(第六章)来进一步提升。事务是这次运动的主要牺牲品:这些新一代数据库中的许多数据库完全放弃了事务,或者重新定义了这个词,描述比以前所理解的更弱得多的一套保证【4】。
随着这种新型分布式数据库的炒作,人们普遍认为事务是可伸缩性的对立面,任何大型系统都必须放弃事务以保持良好的性能和高可用性【5,6】。另一方面,数据库厂商有时将事务保证作为“重要应用”和“有价值数据”的基本要求。这两种观点都是纯粹的夸张。事实并非如此简单:与其他技术设计选择一样,事务有其优势和局限性。
事务和ACID
事务(Transaction)是由一系列对系统中数据进行访问与更新的操作所组成的一个程序执行逻辑单元(Unit),狭义上的事务特指数据库事务。一方面,当多个应用程序并发访问数据库时,事务可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。另一方面,事务为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持数据一致性的方法。
事务所提供的安全保证,通常由众所周知的首字母缩略词 ACID 来描述,ACID 代表原子性(Atomicity),一致性(Consistency),隔离性(Isolation) 和持久性(Durability)。它由Theo Härder和Andreas Reuter于1983年提出,旨在为数据库中的容错机制建立精确的术语。
但实际上,不同数据库的ACID实现并不相同。例如,我们将会看到,关于隔离性的含义就有许多含糊不清【8】。高层次上的想法很美好,但魔鬼隐藏在细节里。今天,当一个系统声称自己“符合ACID”时,实际上能期待的是什么保证并不清楚。不幸的是,ACID现在几乎已经变成了一个营销术语。
(不符合ACID标准的系统有时被称为BASE,它代表基本可用性(Basically Available),软状态(Soft State) 和最终一致性(Eventual consistency)【9】,这比ACID的定义更加模糊,似乎BASE的唯一合理的定义是“不是ACID”,即它几乎可以代表任何你想要的东西。)
BASE理论
BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,其核心思想是即使无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性 —— 但请注意,这绝不等价于系统不可用。以下两个就是“基本可用”的典型例子。
- 响应时间上的损失:正常情况下,一个在线搜索引擎需要在 0.5 秒之内返回给用户相应的査询结果,但由于出现故障(比如系统部分机房发生断电或断网故障),査询结果的响应时间增加到了 1~2 秒。
- 功能上的损失:正常情况下,在一个电子商务网站上进行购物,消费者几乎能够顺利地完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
弱状态
弱状态也称为软状态,和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。最终一致性是一种特殊的弱一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问都能够获取到最新的值。同时,在没有发生故障的前提下,数据达到一致状态的时间延迟,取决于网络延迟、系统负载和数据复制方案设计等因素。
在实际工程实践中,最终一致性存在以下五类主要变种。
因果一致性(Causal consistency)
因果一致性是指,如果进程 A 在更新完某个数据项后通知了进程 B,那么进程 B 之后对该数据项的访问都应该能够获取到进程 A 更新后的最新值,并且如果进程 B 要对该数据项进行更新操作的话,务必基于进程 A 更新后的最新值,即不能发生丢失更新情况。与此同时,与进程 A 无因果关系的进程 C 的数据访问则没有这样的限制。
读己之所写(Read your writes)
读己之所写是指,进程 A 更新一个数据项之后,它自己总是能够访问到更新过的最新值,而不会看到旧值。也就是说,对于单个数据获取者来说,其读取到的数据,一定不会比自己上次写入的值旧。因此,读己之所写也可以看作是一种特殊的因果一致性。
会话一致性(Session consistency)
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现“读己之所写”的一致性,也就是说,执行更能操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
单调读一致性(Monotonic read consistency)
单调读一致性是指如果一个进程从系统中读取出一个数据项的某个值后,那么系统对于该进程后续的任何数据访问都不应该返回更旧的值。
单调写一致性(Monotonic write consistency)
单调写一致性是指,一个系统需要能够保证来自同一个进程的写操作被顺序地执行。
让我们深入了解原子性,一致性,隔离性和持久性的定义,这可以让我们提炼出事务的思想。
原子性
一般来说,原子是指不能分解成小部分的东西。这个词在计算机的不同领域中意味着相似但又微妙不同的东西。例如,在多线程编程中,如果一个线程执行一个原子操作,这意味着另一个线程无法看到该操作的一半结果。系统只能处于操作之前或操作之后的状态,而不是介于两者之间的状态。
相比之下,ACID的原子性并不是关于 并发(concurrent) 的。它并不是在描述如果几个进程试图同时访问相同的数据会发生什么情况,这种情况包含在缩写 I 中,即隔离性。
ACID的原子性描述了当客户想进行多次写入,但在一些写操作处理完之后出现故障的情况。例如进程崩溃,网络连接中断,磁盘变满或者某种完整性约束被违反。如果这些写操作被分组到一个原子事务中,并且该事务由于错误而不能完成(提交),则该事务将被中止,并且数据库必须丢弃或撤消该事务中迄今为止所做的任何写入。
如果没有原子性,在多处更改进行到一半时发生错误,很难知道哪些更改已经生效,哪些没有生效。该应用程序可以再试一次,但冒着进行两次相同变更的风险,可能会导致数据重复或错误的数据。原子性简化了这个问题:如果事务被中止(abort),应用程序可以确定它没有改变任何东西,所以可以安全地重试。
ACID原子性的定义特征是:能够在错误时中止事务,丢弃该事务进行的所有写入变更的能力。 或许 可中止性(abortability) 是更好的术语,但本书将继续使用原子性,因为这是惯用词。
一致性
一致性这个词被赋予太多含义:
- 在第五章中,我们讨论了副本一致性,以及异步复制系统中的最终一致性问题(请参阅“复制延迟问题”)。
- 一致性哈希(Consistency Hashing))是某些系统用于重新分区的一种分区方法。
- 在CAP定理中,一致性一词用于表示线性一致性。
- 在ACID的上下文中,一致性是指数据库在应用程序的特定概念中处于“良好状态”。
很不幸,这一个词就至少有四种不同的含义。
ACID一致性的概念是,对数据的一组特定约束必须始终成立。即不变量(invariants)。例如,在会计系统中,所有账户整体上必须借贷相抵。如果一个事务开始于一个满足这些不变量的有效数据库,且在事务处理期间的任何写入操作都保持这种有效性,那么可以确定,不变量总是满足的。而对于事务的一致性本身来说,可以理解为事务执行的结果必须是使数据库从一个一致性状态转变到另一个一致性状态,因此当数据库只包含成功事务提交的结果时,就能说数据库处于一致性状态。而如果数据库系统在运行过程中发生故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。
但是,一致性的这种概念取决于应用程序对不变量的理解,应用程序负责正确定义它的事务,并保持一致性。这并不是数据库可以保证的事情:如果你写入违反不变量的脏数据,数据库也无法阻止你。 (一些特定类型的不变量可以由数据库检查,例如外键约束或唯一约束,但是一般来说,是应用程序来定义什么样的数据是有效的,什么样是无效的。—— 数据库只管存储。)
原子性,隔离性和持久性是数据库的属性,而一致性(在ACID意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母C不属于ACIDi。
i. 乔·海勒斯坦(Joe Hellerstein)指出,在论Härder与Reuter的论文中,“ACID中的C”是被“扔进去凑缩写单词的”【7】,而且那时候大家都不怎么在乎一致性。 ↩
隔离性
大多数数据库都会同时被多个客户端访问。如果它们各自读写数据库的不同部分,这是没有问题的,但是如果它们访问相同的数据库记录,则可能会遇到并发问题(竞争条件(race conditions))。
图7-1是这类问题的一个简单例子。假设你有两个客户端同时在数据库中增长一个计数器。(假设数据库没有内建的自增操作)每个客户端需要读取计数器的当前值,加 1 ,再回写新值。图7-1 中,因为发生了两次增长,计数器应该从42增至44;但由于竞态条件,实际上只增至 43 。
ACID意义上的隔离性
ACID意义上的隔离性意味着,同时执行的事务是相互隔离的:它们不能相互冒犯。传统的数据库教科书将隔离性形式化为可串行化(Serializability),这意味着每个事务可以假装它是唯一在整个数据库上运行的事务。数据库确保当多个事务被提交时,结果与它们串行运行(一个接一个)是一样的,尽管实际上它们可能是并发运行的【10】。
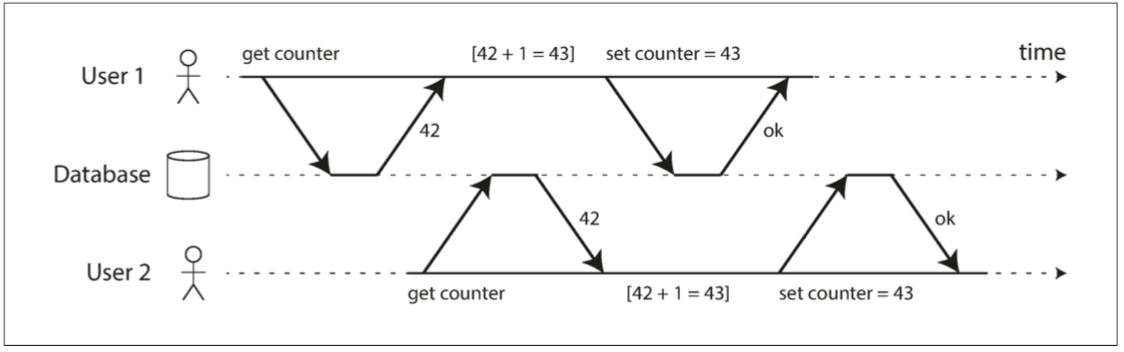
图7-1 两个客户之间的竞争状态同时递增计数器
然而实践中很少会使用可串行的隔离,因为它有性能损失。一些流行的数据库如Oracle 11g,甚至没有实现它。在Oracle中有一个名为“可串行的”隔离级别,但实际上它实现了一种叫做快照隔离(snapshot isolation) 的功能,这是一种比可串行化更弱的保证【8,11】。我们将在“弱隔离级别”中研究快照隔离和其他形式的隔离。
标准SQL规范的隔离性
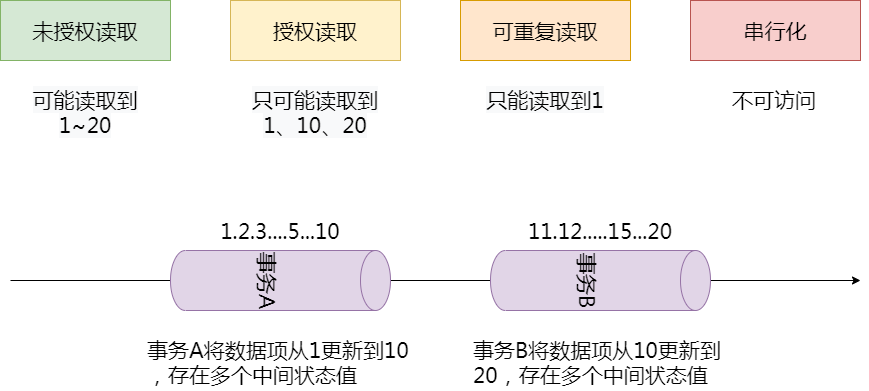
在标准 SQL 规范中,定义了 4 个事务隔离级别,不同的隔离级别对事务的处理不同,如未授权读取、授权读取、可重复读取和串行化。
未授权读取
未授权读取也被称为读未提交(Read Uncommitted),该隔离级别允许脏读取,其隔离级别最低。换句话说,如果一个事务正在处理某一数据,并对其进行了更新,但同时尚未完成事务,因此还没有进行事务提交;而与此同时,允许另一个事务也能够访问该数据。
授权读取
授权读取也被称为读已提交(Read Committed),它和未授权读取非常相近,唯一的区别就是授权读取只允许获取已经被提交的数据。需要注意的是,授权读取是不可重复读取,即如果在一个事务中多次读取了同一条数据,其内容有可能被在读取过程中提交的其他事务所修改,从而读取到同一条数据的多个版本值。
可重复读取
可重复读取(Repeatable Read),简单地说,就是保证在事务处理过程中,多次读取同一个数据时,其值都和事务开始时刻是一致的。因此该事务级别禁止了不可重复读取和脏读取,但是有可能岀现幻影数据。所谓幻影数据,就是指同样的事务操作,在前后两个时间段內执行对同一个数据项的读取,可能出现不一致的结果。在上面的例子,可重复读取隔离级别能够保证事务 B 在第一次事务操作过程中,始终对数据项读取到 1,但是在下一次事务操作中,即使事务 B(注意,事务名字虽然相同但是指的是另一次事务操作)采用同样的查询方式,就可能会读取到 10 或 20。
串行化
串行化(Serializable)是最严格的事务隔离级别。它要求所有事务都被串行执行,即事务只能一个接一个地进行处理,不能并发执行。
以上 4 个隔离级别的隔离性依次增强,分别解决不同的问题,下表对这 4 个隔离级别进行了一个对比。

事务隔离级别越高,就越能保证数据的完整性和一致性,但同时对并发性能的影响也越大。通常,对于绝大多数的应用程序来说,可以优先考虑将数据库系统的隔离级别设置为授权读取,这能够在避免脏读取的同时保证较好的并发性能。尽管这种事务隔离级别会导致不可重复读、虚读和第二类丢失更新等并发问题,但较为科学的做法是在可能出现这类问题的个别场合中,由应用程序主动采用悲观锁或乐观锁来进行事务控制。
持久性
数据库系统的目的是,提供一个安全的地方存储数据,而不用担心丢失。持久性 是一个承诺,即一旦事务成功完成,即使发生硬件故障或数据库崩溃,写入的任何数据也不会丢失。
在单节点数据库中,持久性通常意味着数据已被写入非易失性存储设备,如硬盘或SSD。它通常还包括预写日志或类似的文件(请参阅“让B树更可靠”),以便在磁盘上的数据结构损坏时进行恢复。在带复制的数据库中,持久性可能意味着数据已成功复制到一些节点。为了提供持久性保证,数据库必须等到这些写入或复制完成后,才能报告事务成功提交。
如“可靠性”一节所述,完美的持久性是不存在的 :如果所有硬盘和所有备份同时被销毁,那显然没有任何数据库能救得了你。
复制与持久性
在历史上,持久性意味着写入归档磁带。后来它被理解为写入磁盘或SSD。再后来它又有了新的内涵即“复制(replication)”。哪种实现更好一些?
真相是,没有什么是完美的:
- 如果你写入磁盘然后机器宕机,即使数据没有丢失,在修复机器或将磁盘转移到其他机器之前,也是无法访问的。这种情况下,复制系统可以保持可用性。
- 一个相关性故障(停电,或一个特定输入导致所有节点崩溃的Bug)可能会一次性摧毁所有副本(请参阅「可靠性」),任何仅存储在内存中的数据都会丢失,故内存数据库仍然要和磁盘写入打交道。
- 在异步复制系统中,当主库不可用时,最近的写入操作可能会丢失(请参阅「处理节点宕机」)。
- 当电源突然断电时,特别是固态硬盘,有证据显示有时会违反应有的保证:甚至fsync也不能保证正常工作【12】。硬盘固件可能有错误,就像任何其他类型的软件一样【13,14】。
- 存储引擎和文件系统之间的微妙交互可能会导致难以追踪的错误,并可能导致磁盘上的文件在崩溃后被损坏【15,16】。
- 磁盘上的数据可能会在没有检测到的情况下逐渐损坏【17】。如果数据已损坏一段时间,副本和最近的备份也可能损坏。这种情况下,需要尝试从历史备份中恢复数据。
- 一项关于固态硬盘的研究发现,在运行的前四年中,30%到80%的硬盘会产生至少一个坏块【18】。相比固态硬盘,磁盘的坏道率较低,但完全失效的概率更高。
- 如果SSD断电,可能会在几周内开始丢失数据,具体取决于温度【19】。
在实践中,没有一种技术可以提供绝对保证。只有各种降低风险的技术,包括写入磁盘,复制到远程机器和备份——它们可以且应该一起使用。与往常一样,最好抱着怀疑的态度接受任何理论上的“保证”。
单对象和多对象操作
回顾一下,在ACID中,原子性和隔离性描述了客户端在同一事务中执行多次写入时,数据库应该做的事情:
原子性
如果在一系列写操作的中途发生错误,则应中止事务处理,并丢弃当前事务的所有写入。换句话说,数据库免去了用户对部分失败的担忧——通过提供“宁为玉碎,不为瓦全(all-or-nothing)”的保证。
隔离性
同时运行的事务不应该互相干扰。例如,如果一个事务进行多次写入,则另一个事务要么看到全部写入结果,要么什么都看不到,但不应该是一些子集。
这些定义假设你想同时修改多个对象(行,文档,记录)。通常需要多对象事务(multi-object transaction) 来保持多块数据同步。图7-2展示了一个来自电邮应用的例子。执行以下查询来显示用户未读邮件数量:
SELECT COUNT(*)FROM emails WHERE recipient_id = 2 AND unread_flag = true但如果邮件太多,你可能会觉得这个查询太慢,并决定用单独的字段存储未读邮件的数量(一种反规范化)。现在每当一个新消息写入时,必须也增长未读计数器,每当一个消息被标记为已读时,也必须减少未读计数器。
在图7-2中,用户2 遇到异常情况:邮件列表里显示有未读消息,但计数器显示为零未读消息,因为计数器增长还没有发生ii。隔离性可以避免这个问题:通过确保用户2 要么同时看到新邮件和增长后的计数器,要么都看不到。反正不会看到执行到一半的中间结果。
ii. 可以说邮件应用中的错误计数器并不是什么特别重要的问题。但换种方式来看,你可以把未读计数器换成客户账户余额,把邮件收发看成支付交易。 ↩
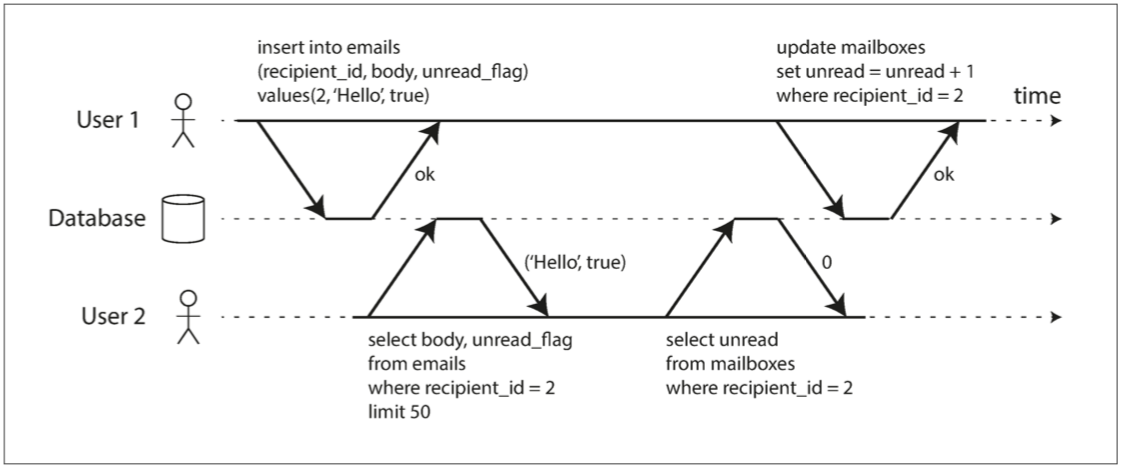
图7-2 违反隔离性:一个事务读取另一个事务的未被执行的写入(“脏读”)。
图7-3说明了对原子性的需求:如果在事务过程中发生错误,邮箱和未读计数器的内容可能会失去同步。在原子事务中,如果对计数器的更新失败,事务将被中止,并且插入的电子邮件将被回滚。

图7-3 原子性确保发生错误时,事务先前的任何写入都会被撤消,以避免状态不一致
多对象事务需要某种方式来确定哪些读写操作属于同一个事务。在关系型数据库中,通常基于客户端与数据库服务器的TCP连接:在任何特定连接上,BEGIN TRANSACTION 和 COMMIT 语句之间的所有内容,被认为是同一事务的一部分.iii
iii. 这并不完美。如果TCP连接中断,则事务必须中止。如果中断发生在客户端请求提交之后,但在服务器确认提交发生之前,客户端并不知道事务是否已提交。为了解决这个问题,事务管理器可以通过一个唯一事务标识符来对操作进行分组,这个标识符并未绑定到特定TCP连接。后续再“数据库的端到端原则”一节将回到这个主题。 ↩
另一方面,许多非关系数据库并没有将这些操作组合在一起的方法。即使存在多对象API(例如,某键值存储可能具有在一个操作中更新几个键的multi-put操作),但这并不一定意味着它具有事务语义:该命令可能在一些键上成功,在其他的键上失败,使数据库处于部分更新的状态。
单对象写入
当单个对象发生改变时,原子性和隔离性也是适用的。例如,假设您正在向数据库写入一个 20 KB的 JSON文档:
- 如果在发送第一个10 KB之后网络连接中断,数据库是否存储了不可解析的10KB JSON片段?
- 如果在数据库正在覆盖磁盘上的前一个值的过程中电源发生故障,是否最终将新旧值拼接在一起?
- 如果另一个客户端在写入过程中读取该文档,是否会看到部分更新的值?
这些问题非常让人头大,故存储引擎一个几乎普遍的目标是:对单节点上的单个对象(例如键值对)上提供原子性和隔离性。原子性可以通过使用日志来实现崩溃恢复(请参阅“让B树更可靠”),并且可以使用每个对象上的锁来实现隔离(每次只允许一个线程访问对象) 。
一些数据库也提供更复杂的原子操作iv,例如自增操作,这样就不再需要像 图7-1 那样的读取-修改-写入序列了。同样流行的是 比较和设置(CAS, compare-and-set) 操作,仅当值没有被其他并发修改过时,才允许执行写操作。
iv. 严格地说,原子自增(atomic increment) 这个术语在多线程编程的意义上使用了原子这个词。 在ACID的情况下,它实际上应该被称为 隔离的(isolated) 的或可串行的(serializable) 的增量。 但这就太吹毛求疵了。 ↩
这些单对象操作很有用,因为它们可以防止在多个客户端尝试同时写入同一个对象时丢失更新(请参阅“防止丢失更新”)。但它们不是通常意义上的事务。CAS以及其他单一对象操作被称为“轻量级事务”,甚至出于营销目的被称为“ACID”【20,21,22】,但是这个术语是误导性的。事务通常被理解为,将多个对象上的多个操作合并为一个执行单元的机制。
多对象事务的需求
许多分布式数据存储已经放弃了多对象事务,因为多对象事务很难跨分区实现,而且在需要高可用性或高性能的情况下,它们可能会碍事。但说到底,在分布式数据库中实现事务,并没有什么根本性的障碍。第九章 将讨论分布式事务的实现。
但是我们是否需要多对象事务?是否有可能只用键值数据模型和单对象操作来实现任何应用程序?
有一些场景中,单对象插入,更新和删除是足够的。但是许多其他场景需要协调写入几个不同的对象:
- 在关系数据模型中,一个表中的行通常具有对另一个表中的行的外键引用。(类似的是,在一个图数据模型中,一个顶点有着到其他顶点的边)。多对象事务使你确保这些引用始终有效:当插入几个相互引用的记录时,外键必须是正确的和最新的,不然数据就没有意义。
- 在文档数据模型中,需要一起更新的字段通常在同一个文档中,这被视为单个对象——更新单个文档时不需要多对象事务。但是,缺乏连接功能的文档数据库会鼓励非规范化(请参阅“关系型数据库与文档数据库在今日的对比”)。当需要更新非规范化的信息时,如 图7-2 所示,需要一次更新多个文档。事务在这种情况下非常有用,可以防止非规范化的数据不同步。
- 在具有二级索引的数据库中(除了纯粹的键值存储以外几乎都有),每次更改值时都需要更新索引。从事务角度来看,这些索引是不同的数据库对象:例如,如果没有事务隔离性,记录可能出现在一个索引中,但没有出现在另一个索引中,因为第二个索引的更新还没有发生。
这些应用仍然可以在没有事务的情况下实现。然而,没有原子性,错误处理就要复杂得多,缺乏隔离性,就会导致并发问题。我们将在“弱隔离级别”中讨论这些问题,并在第十二章中探讨其他方法。
处理错误和中止
事务的一个关键特性是,如果发生错误,它可以中止并安全地重试。 ACID数据库基于这样的哲学:如果数据库有违反其原子性,隔离性或持久性的危险,则宁愿完全放弃事务,而不是留下半成品。
然而并不是所有的系统都遵循这个哲学。特别是具有无主复制的数据存储,主要是在“尽力而为”的基础上进行工作。可以概括为“数据库将做尽可能多的事,运行遇到错误时,它不会撤消它已经完成的事情“ ——所以,从错误中恢复是应用程序的责任。
错误发生不可避免,但许多软件开发人员倾向于只考虑乐观情况,而不是错误处理的复杂性。例如,像Rails的ActiveRecord和Django这样的对象关系映射(ORM, object-relation Mapping) 框架不会重试中断的事务—— 这个错误通常会导致一个从堆栈向上传播的异常,所以任何用户输入都会被丢弃,用户拿到一个错误信息。这实在是太耻辱了,因为中止的重点就是允许安全的重试。
尽管重试一个中止的事务是一个简单而有效的错误处理机制,但它并不完美:
- 如果事务实际上成功了,但是在服务器试图向客户端确认提交成功时网络发生故障(所以客户端认为提交失败了),那么重试事务会导致事务被执行两次——除非你有一个额外的应用级除重机制。
- 如果错误是由于负载过大造成的,则重试事务将使问题变得更糟,而不是更好。为了避免这种正反馈循环,可以限制重试次数,使用指数退避算法,并单独处理与过载相关的错误(如果允许)。
- 仅在临时性错误(例如,由于死锁,异常情况,临时性网络中断和故障切换)后才值得重试。在发生永久性错误(例如,违反约束)之后重试是毫无意义的。
- 如果事务在数据库之外也有副作用,即使事务被中止,也可能发生这些副作用。例如,如果你正在发送电子邮件,那你肯定不希望每次重试事务时都重新发送电子邮件。如果你想确保几个不同的系统一起提交或放弃,两阶段提交(2PC, two-phase commit) 可以提供帮助(“原子提交与两阶段提交”中将讨论这个问题)。
- 如果客户端进程在重试中失效,任何试图写入数据库的数据都将丢失。
事务分类
本地事务
本地事务是指仅操作单一事务资源的、不需要全局事务管理器进行协调的事务。
本地事务是最基础的一种事务解决方案,只适用于单个服务使用单个数据源的场景。从应用角度看,它是直接依赖于数据源本身提供的事务能力来工作的,在程序代码层面,最多只能对事务接口做一层标准化的包装(如 JDBC 接口),并不能深入参与到事务的运作过程当中,事务的开启、终止、提交、回滚、嵌套、设置隔离级别,乃至与应用代码贴近的事务传播方式,全部都要依赖底层数据源的支持才能工作,这一点与后续介绍的 XA、TCC、SAGA 等主要靠应用程序代码来实现的事务有着十分明显的区别。因此,我们要想深入地讨论本地事务,便不得不越过应用代码的层次,去了解一些数据库本身的事务实现原理,弄明白传统数据库管理系统是如何通过 ACID 来实现事务的。
如今研究事务的实现原理,必定会追溯到ARIES理论(Algorithms for Recovery and Isolation Exploiting Semantics,ARIES),直接翻译过来是“基于语义的恢复与隔离算法”。ARIES 是现代数据库的基础理论,就算不能称所有的数据库都实现了 ARIES,至少也可以称现代的主流关系型数据库(Oracle、MS SQLServer、MySQL/InnoDB、IBM DB2、PostgreSQL,等等)在事务实现上都深受该理论的影响。在 20 世纪 90 年代,IBM Almaden 研究院总结了研发原型数据库系统“IBM System R”的经验,发表了 ARIES 理论中最主要的三篇论文,其中《ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging》着重解决了 ACID 的其中两个属性:原子性(A)和持久性(D)在算法层面上应当如何实现。而另一篇《ARIES/KVL: A Key-Value Locking Method for Concurrency Control of Multiaction Transactions Operating on B-Tree Indexes》则是现代数据库隔离性(I)奠基式的文章。
实现原子性和持久性
原子性和持久性在事务里是密切相关的两个属性,原子性保证了事务的多个操作要么都生效要么都不生效,不会存在中间状态;持久性保证了一旦事务生效,就不会再因为任何原因而导致其修改的内容被撤销或丢失。
众所周知,数据必须要成功写入磁盘、磁带等持久化存储器后才能拥有持久性,只存储在内存中的数据,一旦遇到应用程序忽然崩溃,或者数据库、操作系统一侧的崩溃,甚至是机器突然断电宕机等情况就会丢失,后文我们将这些意外情况都统称为“崩溃”(Crash)。实现原子性和持久性的最大困难是“写入磁盘”这个操作并不是原子的,不仅有“写入”与“未写入”状态,还客观地存在着“正在写”的中间状态。正因为写入中间状态与崩溃都不可能消除,所以如果不做额外保障措施的话,将内存中的数据写入磁盘,并不能保证原子性与持久性。下面通过具体事例来说明。
按照前面预设的场景事例,从 Fenix’s Bookstore 购买一本书需要修改三个数据:在用户账户中减去货款、在商家账户中增加货款、在商品仓库中标记一本书为配送状态。由于写入存在中间状态,所以可能发生以下情形。
- 未提交事务,写入后崩溃:程序还没修改完三个数据,但数据库已经将其中一个或两个数据的变动写入磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次不完整的购物操作,将已经修改过的数据从磁盘中恢复成没有改过的样子,以保证原子性。
- 已提交事务,写入前崩溃:程序已经修改完三个数据,但数据库还未将全部三个数据的变动都写入到磁盘,此时出现崩溃,一旦重启之后,数据库必须要有办法得知崩溃前发生过一次完整的购物操作,将还没来得及写入磁盘的那部分数据重新写入,以保证持久性。
由于写入中间状态与崩溃都是无法避免的,为了保证原子性和持久性,就只能在崩溃后采取恢复的补救措施,这种数据恢复操作被称为“崩溃恢复”(Crash Recovery,也有资料称作 Failure Recovery 或 Transaction Recovery)。
通过日志实现事务
为了能够顺利地完成崩溃恢复,在磁盘中写入数据就不能像程序修改内存中变量值那样,直接改变某表某行某列的某个值,而是必须将修改数据这个操作所需的全部信息,包括修改什么数据、数据物理上位于哪个内存页和磁盘块中、从什么值改成什么值,等等,以日志的形式——即仅进行顺序追加的文件写入的形式(这是最高效的写入方式)先记录到磁盘中。只有在日志记录全部都安全落盘,数据库在日志中看到代表事务成功提交的“提交记录”(Commit Record)后,才会根据日志上的信息对真正的数据进行修改,修改完成后,再在日志中加入一条“结束记录”(End Record)表示事务已完成持久化,这种事务实现方法被称为“Commit Logging”(提交日志)。
通过 Shadow Paging 实现事务
通过日志实现事务的原子性和持久性是当今的主流方案,但并不是唯一的选择。除日志外,还有另外一种称为“Shadow Paging”(有中文资料翻译为“影子分页”)的事务实现机制,常用的轻量级数据库 SQLite Version 3 采用的事务机制就是 Shadow Paging。
Shadow Paging 的大体思路是对数据的变动会写到硬盘的数据中,但并不是直接就地修改原先的数据,而是先将数据复制一份副本,保留原数据,修改副本数据。在事务过程中,被修改的数据会同时存在两份,一份是修改前的数据,一份是修改后的数据,这也是“影子”(Shadow)这个名字的由来。当事务成功提交,所有数据的修改都成功持久化之后,最后一步是去修改数据的引用指针,将引用从原数据改为新复制出来修改后的副本,最后的“修改指针”这个操作将被认为是原子操作,现代磁盘的写操作可以认为在硬件上保证了不会出现“改了半个值”的现象。所以 Shadow Paging 也可以保证原子性和持久性。Shadow Paging 实现事务要比 Commit Logging 更加简单,但涉及隔离性与并发锁时,Shadow Paging 实现的事务并发能力就相对有限,因此在高性能的数据库中应用不多。
日志实现事务的缺陷及优化
Commit Logging 保障数据持久性、原子性的原理并不难理解:首先,日志一旦成功写入 Commit Record,那整个事务就是成功的,即使真正修改数据时崩溃了,重启后根据已经写入磁盘的日志信息恢复现场、继续修改数据即可,这保证了持久性;其次,如果日志没有成功写入 Commit Record 就发生崩溃,那整个事务就是失败的,系统重启后会看到一部分没有 Commit Record 的日志,那将这部分日志标记为回滚状态即可,整个事务就像完全没好有发生过一样,这保证了原子性。
Commit Logging 的原理很清晰,也确实有一些数据库就是直接采用 Commit Logging 机制来实现事务的,譬如较具代表性的是阿里的 OceanBase。但是,Commit Logging 存在一个巨大的先天缺陷:所有对数据的真实修改都必须发生在事务提交以后,即日志写入了 Commit Record 之后。在此之前,即使磁盘 I/O 有足够空闲、即使某个事务修改的数据量非常庞大,占用了大量的内存缓冲区,无论有何种理由,都决不允许在事务提交之前就修改磁盘上的数据,这一点是 Commit Logging 成立的前提,却对提升数据库的性能十分不利。为了解决这个问题,前面提到的 ARIES 理论终于可以登场。ARIES 提出了“Write-Ahead Logging”的日志改进方案,所谓“提前写入”(Write-Ahead),就是允许在事务提交之前,提前写入变动数据的意思。
Write-Ahead Logging 先将何时写入变动数据,按照事务提交时点为界,划分为 FORCE 和 STEAL 两类情况。
- FORCE:当事务提交后,要求变动数据必须同时完成写入则称为 FORCE,如果不强制变动数据必须同时完成写入则称为 NO-FORCE。现实中绝大多数数据库采用的都是 NO-FORCE 策略,因为只要有了日志,变动数据随时可以持久化,从优化磁盘 I/O 性能考虑,没有必要强制数据写入立即进行。
- STEAL:在事务提交前,允许变动数据提前写入则称为 STEAL,不允许则称为 NO-STEAL。从优化磁盘 I/O 性能考虑,允许数据提前写入,有利于利用空闲 I/O 资源,也有利于节省数据库缓存区的内存。
Commit Logging 允许 NO-FORCE,但不允许 STEAL。因为假如事务提交前就有部分变动数据写入磁盘,那一旦事务要回滚,或者发生了崩溃,这些提前写入的变动数据就都成了错误。
Write-Ahead Logging 允许 NO-FORCE,也允许 STEAL,它给出的解决办法是增加了另一种被称为 Undo Log 的日志类型,当变动数据写入磁盘前,必须先记录 Undo Log,注明修改了哪个位置的数据、从什么值改成什么值,等等。以便在事务回滚或者崩溃恢复时根据 Undo Log 对提前写入的数据变动进行擦除。Undo Log 现在一般被翻译为“回滚日志”,此前记录的用于崩溃恢复时重演数据变动的日志就相应被命名为 Redo Log,一般翻译为“重做日志”。由于 Undo Log 的加入,Write-Ahead Logging 在崩溃恢复时会执行以下三个阶段的操作。
- 分析阶段(Analysis):该阶段从最后一次检查点(Checkpoint,可理解为在这个点之前所有应该持久化的变动都已安全落盘)开始扫描日志,找出所有没有 End Record 的事务,组成待恢复的事务集合,这个集合至少会包括 Transaction Table 和 Dirty Page Table 两个组成部分。
- 重做阶段(Redo):该阶段依据分析阶段中产生的待恢复的事务集合来重演历史(Repeat History),具体操作为:找出所有包含 Commit Record 的日志,将这些日志修改的数据写入磁盘,写入完成后在日志中增加一条 End Record,然后移除出待恢复事务集合。
- 回滚阶段(Undo):该阶段处理经过分析、重做阶段后剩余的恢复事务集合,此时剩下的都是需要回滚的事务,它们被称为 Loser,根据 Undo Log 中的信息,将已经提前写入磁盘的信息重新改写回去,以达到回滚这些 Loser 事务的目的。
重做阶段和回滚阶段的操作都应该设计为幂等的。为了追求高 I/O 性能,以上三个阶段无可避免地会涉及非常烦琐的概念和细节(如 Redo Log、Undo Log 的具体数据结构等),囿于篇幅限制,笔者并不打算具体介绍这些内容,如感兴趣,阅读本节开头引用的那两篇论文是最佳的途径。Write-Ahead Logging 是 ARIES 理论的一部分,整套 ARIES 拥有严谨、高性能等很多的优点,但这些也是以高度复杂为代价的。数据库按照是否允许 FORCE 和 STEAL 可以产生共计四种组合,从优化磁盘 I/O 的角度看,NO-FORCE 加 STEAL 组合的性能无疑是最高的;从算法实现与日志的角度看 NO-FORCE 加 STEAL 组合的复杂度无疑也是最高的。这四种组合与 Undo Log、Redo Log 之间的具体关系如图 3-1 所示。
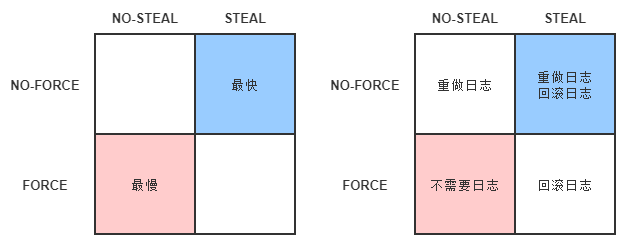
图 FORCE 和 STEAL 的四种组合关系
实现隔离性
本节我们来探讨数据库是如何实现隔离性的。隔离性保证了每个事务各自读、写的数据互相独立,不会彼此影响。只从定义上就能嗅出隔离性肯定与并发密切相关,因为如果没有并发,所有事务全都是串行的,那就不需要任何隔离,或者说这样的访问具备了天然的隔离性。但现实情况不可能没有并发,要在并发下实现串行的数据访问该怎样做?几乎所有程序员都会回答:加锁同步呀!正确,现代数据库均提供了以下三种锁。
写锁(Write Lock,也叫作排他锁,eXclusive Lock,简写为 X-Lock):如果数据有加写锁,就只有持有写锁的事务才能对数据进行写入操作,数据加持着写锁时,其他事务不能写入数据,也不能施加读锁。
读锁(Read Lock,也叫作共享锁,Shared Lock,简写为 S-Lock):多个事务可以对同一个数据添加多个读锁,数据被加上读锁后就不能再被加上写锁,所以其他事务不能对该数据进行写入,但仍然可以读取。对于持有读锁的事务,如果该数据只有它自己一个事务加了读锁,允许直接将其升级为写锁,然后写入数据。
范围锁(Range Lock):对于某个范围直接加排他锁,在这个范围内的数据不能被写入。如下语句是典型的加范围锁的例子:
SELECT * FROM books WHERE price < 100 FOR UPDATE;请注意“范围不能被写入”与“一批数据不能被写入”的差别,即不要把范围锁理解成一组排他锁的集合。加了范围锁后,不仅无法修改该范围内已有的数据,也不能在该范围内新增或删除任何数据,后者是一组排他锁的集合无法做到的。
串行化访问提供了强度最高的隔离性,ANSI/ISO SQL-92中定义的最高等级的隔离级别便是可串行化(Serializable)。可串行化完全符合普通程序员对数据竞争加锁的理解,如果不考虑性能优化的话,对事务所有读、写的数据全都加上读锁、写锁和范围锁即可做到可串行化(“即可”是简化理解,实际还是很复杂的,要分成 Expanding 和 Shrinking 两阶段去处理读锁、写锁与数据间的关系,称为 Two-Phase Lock,2PL)。但数据库不考虑性能肯定是不行的,并发控制理论(Concurrency Control)决定了隔离程度与并发能力是相互抵触的,隔离程度越高,并发访问时的吞吐量就越低。现代数据库一定会提供除可串行化以外的其他隔离级别供用户使用,让用户调节隔离级别的选项,根本目的是让用户可以调节数据库的加锁方式,取得隔离性与吞吐量之间的平衡。
可串行化的下一个隔离级别是可重复读(Repeatable Read),可重复读对事务所涉及的数据加读锁和写锁,且一直持有至事务结束,但不再加范围锁。可重复读比可串行化弱化的地方在于幻读问题#Phantom_reads)(Phantom Reads),它是指在事务执行过程中,两个完全相同的范围查询得到了不同的结果集。譬如现在准备统计一下 Fenix’s Bookstore 中售价小于 100 元的书有多少本,会执行以下第一条 SQL 语句:
SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:1,事务: T1 */
INSERT INTO books(name,price) VALUES ('深入理解Java虚拟机',90) /* 时间顺序:2,事务: T2 */
SELECT count(1) FROM books WHERE price < 100 /* 时间顺序:3,事务: T1 */根据前面对范围锁、读锁和写锁的定义可知,假如这条 SQL 语句在同一个事务中重复执行了两次,且这两次执行之间恰好有另外一个事务在数据库插入了一本小于 100 元的书籍,这是会被允许的,那这两次相同的查询就会得到不一样的结果,原因是可重复读没有范围锁来禁止在该范围内插入新的数据,这是一个事务受到其他事务影响,隔离性被破坏的表现。
提醒注意一点,这里的介绍是以 ARIES 理论为讨论目标的,具体的数据库并不一定要完全遵照着理论去实现。一个例子是 MySQL/InnoDB 的默认隔离级别为可重复读,但它在只读事务中可以完全避免幻读问题,譬如上面例子中事务 T1 只有查询语句,是一个只读事务,所以例子中的问题在 MySQL 中并不会出现。但在读写事务中,MySQL 仍然会出现幻读问题,譬如例子中事务 T1 如果在其他事务插入新书后,不是重新查询一次数量,而是要将所有小于 100 元的书改名,那就依然会受到新插入书籍的影响。
可重复读的下一个隔离级别是读已提交(Read Committed),读已提交对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。读已提交比可重复读弱化的地方在于不可重复读问题#Non-repeatable_reads)(Non-Repeatable Reads),它是指在事务执行过程中,对同一行数据的两次查询得到了不同的结果。譬如笔者想要获取 Fenix’s Bookstore 中《深入理解 Java 虚拟机》这本书的售价,同样执行了两条 SQL 语句,在此两条语句执行之间,恰好另外一个事务修改了这本书的价格,将书的价格从 90 元调整到了 110 元,如下 SQL 所示:
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */
UPDATE books SET price = 110 WHERE id = 1; COMMIT; /* 时间顺序:2,事务: T2 */
SELECT * FROM books WHERE id = 1; COMMIT; /* 时间顺序:3,事务: T1 */如果隔离级别是读已提交,这两次重复执行的查询结果就会不一样,原因是读已提交的隔离级别缺乏贯穿整个事务周期的读锁,无法禁止读取过的数据发生变化,此时事务 T2 中的更新语句可以马上提交成功,这也是一个事务受到其他事务影响,隔离性被破坏的表现。假如隔离级别是可重复读的话,由于数据已被事务 T1 施加了读锁且读取后不会马上释放,所以事务 T2 无法获取到写锁,更新就会被阻塞,直至事务 T1 被提交或回滚后才能提交。
读已提交的下一个级别是读未提交(Read Uncommitted),读未提交对事务涉及的数据只加写锁,会一直持续到事务结束,但完全不加读锁。读未提交比读已提交弱化的地方在于脏读问题#Dirty_reads)(Dirty Reads),它是指在事务执行过程中,一个事务读取到了另一个事务未提交的数据。譬如笔者觉得《深入理解 Java 虚拟机》从 90 元涨价到 110 元是损害消费者利益的行为,又执行了一条更新语句把价格改回了 90 元,在提交事务之前,同事说这并不是随便涨价,而是印刷成本上升导致的,按 90 元卖要亏本,于是笔者随即回滚了事务,场景如下 SQL 所示:
SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */
/* 注意没有COMMIT */
UPDATE books SET price = 90 WHERE id = 1; /* 时间顺序:2,事务: T2 */
/* 这条SELECT模拟购书的操作的逻辑 */
SELECT * FROM books WHERE id = 1; /* 时间顺序:3,事务: T1 */
ROLLBACK; /* 时间顺序:4,事务: T2 */不过,在之前修改价格后,事务 T1 已经按 90 元的价格卖出了几本。原因是读未提交在数据上完全不加读锁,这反而令它能读到其他事务加了写锁的数据,即上述事务 T1 中两条查询语句得到的结果并不相同。如果你不能理解这句话中的“反而”二字,请再重读一次写锁的定义:写锁禁止其他事务施加读锁,而不是禁止事务读取数据,如果事务 T1 读取数据并不需要去加读锁的话,就会导致事务 T2 未提交的数据也马上就能被事务 T1 所读到。这同样是一个事务受到其他事务影响,隔离性被破坏的表现。假如隔离级别是读已提交的话,由于事务 T2 持有数据的写锁,所以事务 T1 的第二次查询就无法获得读锁,而读已提交级别是要求先加读锁后读数据的,因此 T1 中的查询就会被阻塞,直至事务 T2 被提交或者回滚后才能得到结果。
理论上还存在更低的隔离级别,就是“完全不隔离”,即读、写锁都不加。读未提交会有脏读问题,但不会有脏写问题(Dirty Write),即一个事务的没提交之前的修改可以被另外一个事务的修改覆盖掉,脏写已经不单纯是隔离性上的问题了,它将导致事务的原子性都无法实现,所以一般谈论隔离级别时不会将它纳入讨论范围内,而将读未提交视为是最低级的隔离级别。
以上四种隔离级别属于数据库理论的基础知识,多数大学的计算机课程应该都会讲到,可惜的是不少教材、资料将它们当作数据库的某种固有属性或设定来讲解,这导致很多同学只能对这些现象死记硬背。其实不同隔离级别以及幻读、不可重复读、脏读等问题都只是表面现象,是各种锁在不同加锁时间上组合应用所产生的结果,以锁为手段来实现隔离性才是数据库表现出不同隔离级别的根本原因。
除了都以锁来实现外,以上四种隔离级别还有另一个共同特点,就是幻读、不可重复读、脏读等问题都是由于一个事务在读数据过程中,受另外一个写数据的事务影响而破坏了隔离性,针对这种“一个事务读+另一个事务写”的隔离问题,近年来有一种名为“多版本并发控制”(Multi-Version Concurrency Control,MVCC)的无锁优化方案被主流的商业数据库广泛采用。MVCC 是一种读取优化策略,它的“无锁”是特指读取时不需要加锁。MVCC 的基本思路是对数据库的任何修改都不会直接覆盖之前的数据,而是产生一个新版副本与老版本共存,以此达到读取时可以完全不加锁的目的。在这句话中,“版本”是个关键词,你不妨将版本理解为数据库中每一行记录都存在两个看不见的字段:CREATE_VERSION 和 DELETE_VERSION,这两个字段记录的值都是事务 ID,事务 ID 是一个全局严格递增的数值,然后根据以下规则写入数据。
- 插入数据时:CREATE_VERSION 记录插入数据的事务 ID,DELETE_VERSION 为空。
- 删除数据时:DELETE_VERSION 记录删除数据的事务 ID,CREATE_VERSION 为空。
- 修改数据时:将修改数据视为“删除旧数据,插入新数据”的组合,即先将原有数据复制一份,原有数据的 DELETE_VERSION 记录修改数据的事务 ID,CREATE_VERSION 为空。复制出来的新数据的 CREATE_VERSION 记录修改数据的事务 ID,DELETE_VERSION 为空。
此时,如有另外一个事务要读取这些发生了变化的数据,将根据隔离级别来决定到底应该读取哪个版本的数据。
- 隔离级别是
可重复读:总是读取 CREATE_VERSION 小于或等于当前事务 ID 的记录,在这个前提下,如果数据仍有多个版本,则取最新(事务 ID 最大)的。 - 隔离级别是
读已提交:总是取最新的版本即可,即最近被 Commit 的那个版本的数据记录。
另外两个隔离级别都没有必要用到 MVCC,因为读未提交直接修改原始数据即可,其他事务查看数据的时候立刻可以看到,根本无须版本字段。可串行化本来的语义就是要阻塞其他事务的读取操作,而 MVCC 是做读取时无锁优化的,自然就不会放到一起用。
MVCC 是只针对“读+写”场景的优化,如果是两个事务同时修改数据,即“写+写”的情况,那就没有多少优化的空间了,此时加锁几乎是唯一可行的解决方案,稍微有点讨论余地的是加锁的策略是“乐观加锁”(Optimistic Locking)还是“悲观加锁”(Pessimistic Locking)。前面笔者介绍的加锁都属于悲观加锁策略,即认为如果不先做加锁再访问数据,就肯定会出现问题。相对地,乐观加锁策略认为事务之间数据存在竞争是偶然情况,没有竞争才是普遍情况,这样就不应该在一开始就加锁,而是应当在出现竞争时再找补救措施。这种思路被称为“乐观并发控制”(Optimistic Concurrency Control,OCC),囿于篇幅与主题的原因,就不再展开了,不过笔者提醒一句,没有必要迷信什么乐观锁要比悲观锁更快的说法,这纯粹看竞争的剧烈程度,如果竞争剧烈的话,乐观锁反而更慢。
全局事务
与本地事务相对的是全局事务(Global Transaction),有一些资料中也将其称为外部事务(External Transaction),在本节里,全局事务被限定为一种适用于单个服务使用多个数据源场景的事务解决方案。请注意,理论上真正的全局事务并没有“单个服务”的约束,它本来就是 DTP(Distributed Transaction Processing)模型中的概念,但本节所讨论的内容是一种在分布式环境中仍追求强一致性的事务处理方案,对于多节点而且互相调用彼此服务的场合(典型的就是现在的微服务系统)是极不合适的,今天它几乎只实际应用于单服务多数据源的场合中,为了避免与后续介绍的放弃了 ACID 的弱一致性事务处理方式相互混淆,所以这里的全局事务所指范围有所缩减,后续涉及多服务多数据源的事务,笔者将称其为“分布式事务”。
1991 年,为了解决分布式事务的一致性问题,X/Open组织(后来并入了The Open Group)提出了一套名为X/Open XA(XA 是 eXtended Architecture 的缩写)的处理事务架构,其核心内容是定义了全局的事务管理器(Transaction Manager,用于协调全局事务)和局部的资源管理器(Resource Manager,用于驱动本地事务)之间的通信接口。XA 接口是双向的,能在一个事务管理器和多个资源管理器(Resource Manager)之间形成通信桥梁,通过协调多个数据源的一致动作,实现全局事务的统一提交或者统一回滚,现在我们在 Java 代码中还偶尔能看见的 XADataSource、XAResource 这些名字都源于此。
不过,XA 并不是 Java 的技术规范(XA 提出那时还没有 Java),而是一套语言无关的通用规范,所以 Java 中专门定义了JSR 907 Java Transaction API,基于 XA 模式在 Java 语言中的实现了全局事务处理的标准,这也就是我们现在所熟知的 JTA。JTA 最主要的两个接口是:
- 事务管理器的接口:
javax.transaction.TransactionManager。这套接口是给 Java EE 服务器提供容器事务(由容器自动负责事务管理)使用的,还提供了另外一套javax.transaction.UserTransaction接口,用于通过程序代码手动开启、提交和回滚事务。 - 满足 XA 规范的资源定义接口:
javax.transaction.xa.XAResource,任何资源(JDBC、JMS 等等)如果想要支持 JTA,只要实现 XAResource 接口中的方法即可。
JTA 原本是 Java EE 中的技术,一般情况下应该由 JBoss、WebSphere、WebLogic 这些 Java EE 容器来提供支持,但现在Bittronix、Atomikos和JBossTM(以前叫 Arjuna)都以 JAR 包的形式实现了 JTA 的接口,称为 JOTM(Java Open Transaction Manager),使得我们能够在 Tomcat、Jetty 这样的 Java SE 环境下也能使用 JTA。
现在,我们对本章的场景事例做另外一种假设:如果书店的用户、商家、仓库分别处于不同的数据库中,其他条件仍与之前相同,那情况会发生什么变化呢?假如你平时以声明式事务来编码,那它与本地事务看起来可能没什么区别,都是标个@Transactional注解而已,但如果以编程式事务来实现的话,就能在写法上看出差异,伪代码如下所示:
public void buyBook(PaymentBill bill) {
userTransaction.begin();
warehouseTransaction.begin();
businessTransaction.begin();
try {
userAccountService.pay(bill.getMoney());
warehouseService.deliver(bill.getItems());
businessAccountService.receipt(bill.getMoney());
userTransaction.commit();
warehouseTransaction.commit();
businessTransaction.commit();
} catch(Exception e) {
userTransaction.rollback();
warehouseTransaction.rollback();
businessTransaction.rollback();
}
}从代码上可看出,程序的目的是要做三次事务提交,但实际上代码并不能这样写,试想一下,如果在businessTransaction.commit()中出现错误,代码转到catch块中执行,此时userTransaction和warehouseTransaction已经完成提交,再去调用rollback()方法已经无济于事,这将导致一部分数据被提交,另一部分被回滚,整个事务的一致性也就无法保证了。为了解决这个问题,XA 将事务提交拆分成为两阶段过程:
- 准备阶段:又叫作投票阶段,在这一阶段,协调者询问事务的所有参与者是否准备好提交,参与者如果已经准备好提交则回复 Prepared,否则回复 Non-Prepared。这里所说的准备操作跟人类语言中通常理解的准备并不相同,对于数据库来说,准备操作是在重做日志中记录全部事务提交操作所要做的内容,它与本地事务中真正提交的区别只是暂不写入最后一条 Commit Record 而已,这意味着在做完数据持久化后并不立即释放隔离性,即仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。
- 提交阶段:又叫作执行阶段,协调者如果在上一阶段收到所有事务参与者回复的 Prepared 消息,则先自己在本地持久化事务状态为 Commit,在此操作完成后向所有参与者发送 Commit 指令,所有参与者立即执行提交操作;否则,任意一个参与者回复了 Non-Prepared 消息,或任意一个参与者超时未回复,协调者将自己的事务状态持久化为 Abort 之后,向所有参与者发送 Abort 指令,参与者立即执行回滚操作。对于数据库来说,这个阶段的提交操作应是很轻量的,仅仅是持久化一条 Commit Record 而已,通常能够快速完成,只有收到 Abort 指令时,才需要根据回滚日志清理已提交的数据,这可能是相对重负载的操作。
以上这两个过程被称为“两段式提交”(2 Phase Commit,2PC)协议,而它能够成功保证一致性还需要一些其他前提条件。
- 必须假设网络在提交阶段的短时间内是可靠的,即提交阶段不会丢失消息。同时也假设网络通信在全过程都不会出现误差,即可以丢失消息,但不会传递错误的消息,XA 的设计目标并不是解决诸如拜占庭将军一类的问题。两段式提交中投票阶段失败了可以补救(回滚),而提交阶段失败了无法补救(不再改变提交或回滚的结果,只能等崩溃的节点重新恢复),因而此阶段耗时应尽可能短,这也是为了尽量控制网络风险的考虑。
- 必须假设因为网络分区、机器崩溃或者其他原因而导致失联的节点最终能够恢复,不会永久性地处于失联状态。由于在准备阶段已经写入了完整的重做日志,所以当失联机器一旦恢复,就能够从日志中找出已准备妥当但并未提交的事务数据,并向协调者查询该事务的状态,确定下一步应该进行提交还是回滚操作。
上面所说的协调者、参与者都是可以由数据库自己来扮演的,不需要应用程序介入。协调者一般是在参与者之间选举产生的,而应用程序相对于数据库来说只扮演客户端的角色。两段式提交的交互时序如图 3-2 所示。
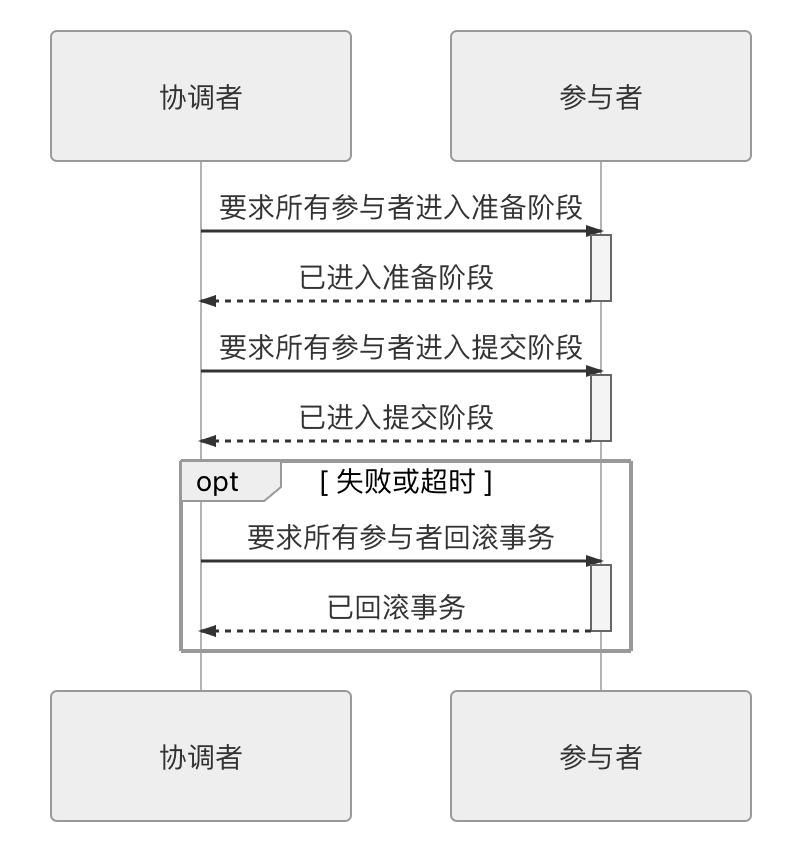
图 3-1 两段式提交的交互时序示意图
两段式提交原理简单,并不难实现,但有几个非常显著的缺点:
- 单点问题:协调者在两段提交中具有举足轻重的作用,协调者等待参与者回复时可以有超时机制,允许参与者宕机,但参与者等待协调者指令时无法做超时处理。一旦宕机的不是其中某个参与者,而是协调者的话,所有参与者都会受到影响。如果协调者一直没有恢复,没有正常发送 Commit 或者 Rollback 的指令,那所有参与者都必须一直等待。
- 性能问题:两段提交过程中,所有参与者相当于被绑定成为一个统一调度的整体,期间要经过两次远程服务调用,三次数据持久化(准备阶段写重做日志,协调者做状态持久化,提交阶段在日志写入 Commit Record),整个过程将持续到参与者集群中最慢的那一个处理操作结束为止,这决定了两段式提交的性能通常都较差。
- 一致性风险:前面已经提到,两段式提交的成立是有前提条件的,当网络稳定性和宕机恢复能力的假设不成立时,仍可能出现一致性问题。宕机恢复能力这一点不必多谈,1985 年 Fischer、Lynch、Paterson 提出了“FLP 不可能原理#Solvability_results_for_some_agreement_problems)”,证明了如果宕机最后不能恢复,那就不存在任何一种分布式协议可以正确地达成一致性结果。该原理在分布式中是与“CAP 不可兼得原理“齐名的理论。而网络稳定性带来的一致性风险是指:尽管提交阶段时间很短,但这仍是一段明确存在的危险期,如果协调者在发出准备指令后,根据收到各个参与者发回的信息确定事务状态是可以提交的,协调者会先持久化事务状态,并提交自己的事务,如果这时候网络忽然被断开,无法再通过网络向所有参与者发出 Commit 指令的话,就会导致部分数据(协调者的)已提交,但部分数据(参与者的)既未提交,也没有办法回滚,产生了数据不一致的问题。
为了缓解两段式提交协议的一部分缺陷,具体地说是协调者的单点问题和准备阶段的性能问题,后续又发展出了“三段式提交”(3 Phase Commit,3PC)协议。三段式提交把原本的两段式提交的准备阶段再细分为两个阶段,分别称为 CanCommit、PreCommit,把提交阶段改称为 DoCommit 阶段。其中,新增的 CanCommit 是一个询问阶段,协调者让每个参与的数据库根据自身状态,评估该事务是否有可能顺利完成。将准备阶段一分为二的理由是这个阶段是重负载的操作,一旦协调者发出开始准备的消息,每个参与者都将马上开始写重做日志,它们所涉及的数据资源即被锁住,如果此时某一个参与者宣告无法完成提交,相当于大家都白做了一轮无用功。所以,增加一轮询问阶段,如果都得到了正面的响应,那事务能够成功提交的把握就比较大了,这也意味着因某个参与者提交时发生崩溃而导致大家全部回滚的风险相对变小。因此,在事务需要回滚的场景中,三段式的性能通常是要比两段式好很多的,但在事务能够正常提交的场景中,两者的性能都依然很差,甚至三段式因为多了一次询问,还要稍微更差一些。
同样也是由于事务失败回滚概率变小的原因,在三段式提交中,如果在 PreCommit 阶段之后发生了协调者宕机,即参与者没有能等到 DoCommit 的消息的话,默认的操作策略将是提交事务而不是回滚事务或者持续等待,这就相当于避免了协调者单点问题的风险。三段式提交的操作时序如图 3-2 所示。
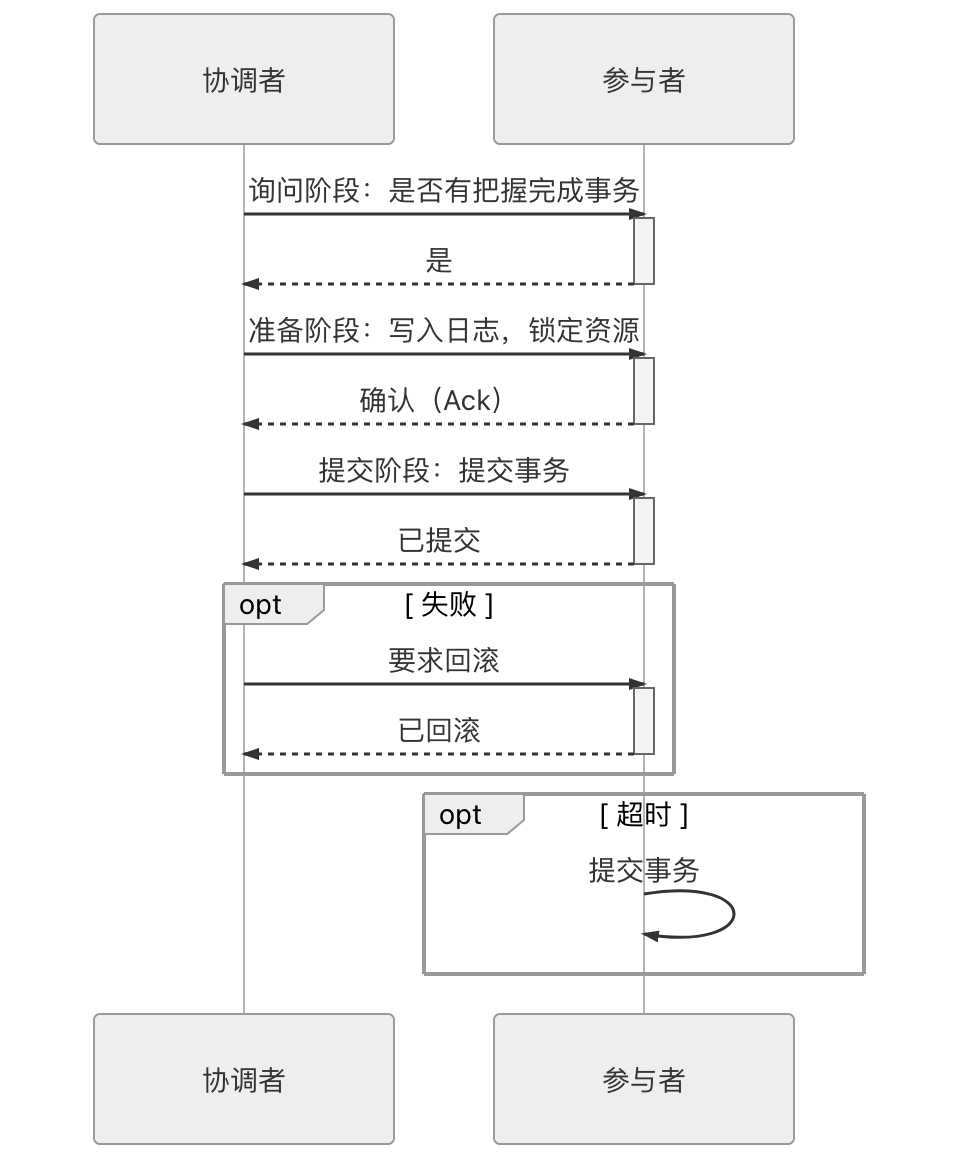
图 3-3 三段式提交的操作时序
从以上过程可以看出,三段式提交对单点问题和回滚时的性能问题有所改善,但是它对一致性风险问题并未有任何改进,在这方面它面临的风险甚至反而是略有增加了的。譬如,进入 PreCommit 阶段之后,协调者发出的指令不是 Ack 而是 Abort,而此时因网络问题,有部分参与者直至超时都未能收到协调者的 Abort 指令的话,这些参与者将会错误地提交事务,这就产生了不同参与者之间数据不一致的问题。
共享事务
与全局事务里讨论的单个服务使用多个数据源正好相反,共享事务(Share Transaction)是指多个服务共用同一个数据源。这里有必要再强调一次“数据源”与“数据库”的区别:数据源是指提供数据的逻辑设备,不必与物理设备一一对应。在部署应用集群时最常采用的模式是将同一套程序部署到多个中间件服务器上,构成多个副本实例来分担流量压力。它们虽然连接了同一个数据库,但每个节点配有自己的专属的数据源,通常是中间件以 JNDI 的形式开放给程序代码使用。这种情况下,所有副本实例的数据访问都是完全独立的,并没有任何交集,每个节点使用的仍是最简单的本地事务。而本节讨论的是多个服务之间会产生业务交集的场景,举个具体例子,在 Fenix’s Bookstore 的场景事例中,假设用户账户、商家账户和商品仓库都存储于同一个数据库之中,但用户、商户和仓库每个领域都部署了独立的微服务,此时一次购书的业务操作将贯穿三个微服务,它们都要在数据库中修改数据。如果我们直接将不同数据源就视为是不同数据库,那上一节所讲的全局事务和下一节要讲的分布式事务都是可行的,不过,针对这种每个数据源连接的都是同一个物理数据库的特例,共享事务则有机会成为另一条可能提高性能、降低复杂度的途径,当然,也很有可能是一个伪需求。
一种理论可行的方案是直接让各个服务共享数据库连接,在同一个应用进程中的不同持久化工具(JDBC、ORM、JMS 等)间共享数据库连接并不困难,某些中间件服务器,譬如 WebSphere 会内置有“可共享连接”功能来专门给予这方面的支持。但这种共享的前提是数据源的使用者都在同一个进程内,由于数据库连接的基础是网络连接,它是与 IP 地址和端口号绑定的,字面意义上的“不同服务节点共享数据库连接”很难做到,所以为了实现共享事务,就必须新增一个“交易服务器”的中间角色,无论是用户服务、商家服务还是仓库服务,它们都通过同一台交易服务器来与数据库打交道。如果将交易服务器的对外接口按照 JDBC 规范来实现的话,那它完全可以视为是一个独立于各个服务的远程数据库连接池,或者直接作为数据库代理来看待。此时三个服务所发出的交易请求就有可能做到交由交易服务器上的同一个数据库连接,通过本地事务的方式完成。譬如,交易服务器根据不同服务节点传来的同一个事务 ID,使用同一个数据库连接来处理跨越多个服务的交易事务,如图 3-4 所示。
用户账户交易服务器商家账户商品仓库数据库
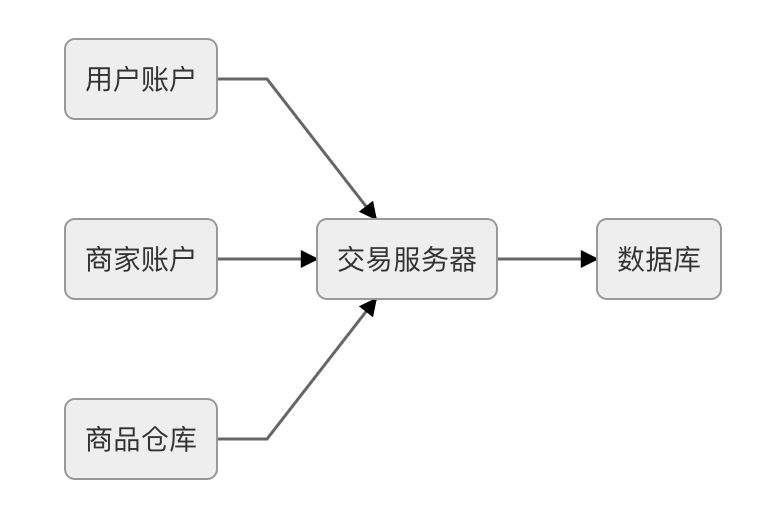
图 3-4 使用同一个数据库处理多个交易服务
之所以强调理论可行,是因为该方案是与实际生产系统中的压力方向相悖的,一个服务集群里数据库才是压力最大而又最不容易伸缩拓展的重灾区,所以现实中只有类似ProxySQL、MaxScale这样用于对多个数据库实例做负载均衡的数据库代理(其实用 ProxySQL 代理单个数据库,再启用 Connection Multiplexing,已经接近于前面所提及的交易服务器方案了),而几乎没有反过来代理一个数据库为多个应用提供事务协调的交易服务代理。这也是说它更有可能是个伪需求的原因,如果你有充足理由让多个微服务去共享数据库,就必须找到更加站得住脚的理由来向团队解释拆分微服务的目的是什么才行。
在日常开发中,上述方案还存在一类更为常见的变种形式:使用消息队列服务器来代替交易服务器。用户、商家、仓库的服务操作业务时,通过消息将所有对数据库的改动传送到消息队列服务器,通过消息的消费者来统一处理,实现由本地事务保障的持久化操作。这被称作“单个数据库的消息驱动更新”(Message-Driven Update of a Single Database)。
“共享事务”的提法和这里所列的两种处理方式在实际应用中并不值得提倡,鲜有采用这种方式的成功案例,能够查询到的资料几乎都发源于十余年前 Spring 的核心开发者Dave Syer撰写的文章《Distributed Transactions in Spring, with and without XA》。笔者把共享事务列为本章四种事务类型之一只是为了叙述逻辑的完备,尽管拆分微服务后仍然共享数据库的情况在现实中并不少见,但笔者个人不赞同将共享事务作为一种常规的解决方案来考量。
分布式事务
本章中所说的分布式事务(Distributed Transaction)特指多个服务同时访问多个数据源的事务处理机制,请注意它与DTP 模型中“分布式事务”的差异。DTP 模型所指的“分布式”是相对于数据源而言的,并不涉及服务,这部分内容已经在“全局事务”一节里进行过讨论。本节所指的“分布式”是相对于服务而言的,如果严谨地说,它更应该被称为“在分布式服务环境下的事务处理机制”。
在 2000 年以前,人们曾经寄希望于 XA 的事务机制可以在本节所说的分布式环境中也能良好地应用,但这个美好的愿望今天已经被 CAP 理论彻底地击碎了,接下来就先从 CAP 与 ACID 的矛盾说起。
刚性事务和柔性事务
由于一致性 CAP 并不能同时存在,“事务”一词的含义其实也同样被拓展了,人们把使用 ACID 的事务称为“刚性事务”,而把下面将要介绍几种分布式事务的常见做法统称为“柔性事务”。
可靠事件队列
最终一致性的概念是 eBay 的系统架构师 Dan Pritchett 在 2008 年在 ACM 发表的论文《Base: An Acid Alternative》中提出的,该论文总结了一种独立于 ACID 获得的强一致性之外的、使用 BASE 来达成一致性目的的途径。BASE 分别是基本可用性(Basically Available)、柔性事务(Soft State)和最终一致性(Eventually Consistent)的缩写。
我们继续以本章的场景事例来解释 Dan Pritchett 提出的“可靠事件队列”的具体做法,目标仍然是交易过程中正确修改账号、仓库和商家服务中的数据,图 3-7 列出了修改过程的时序图。
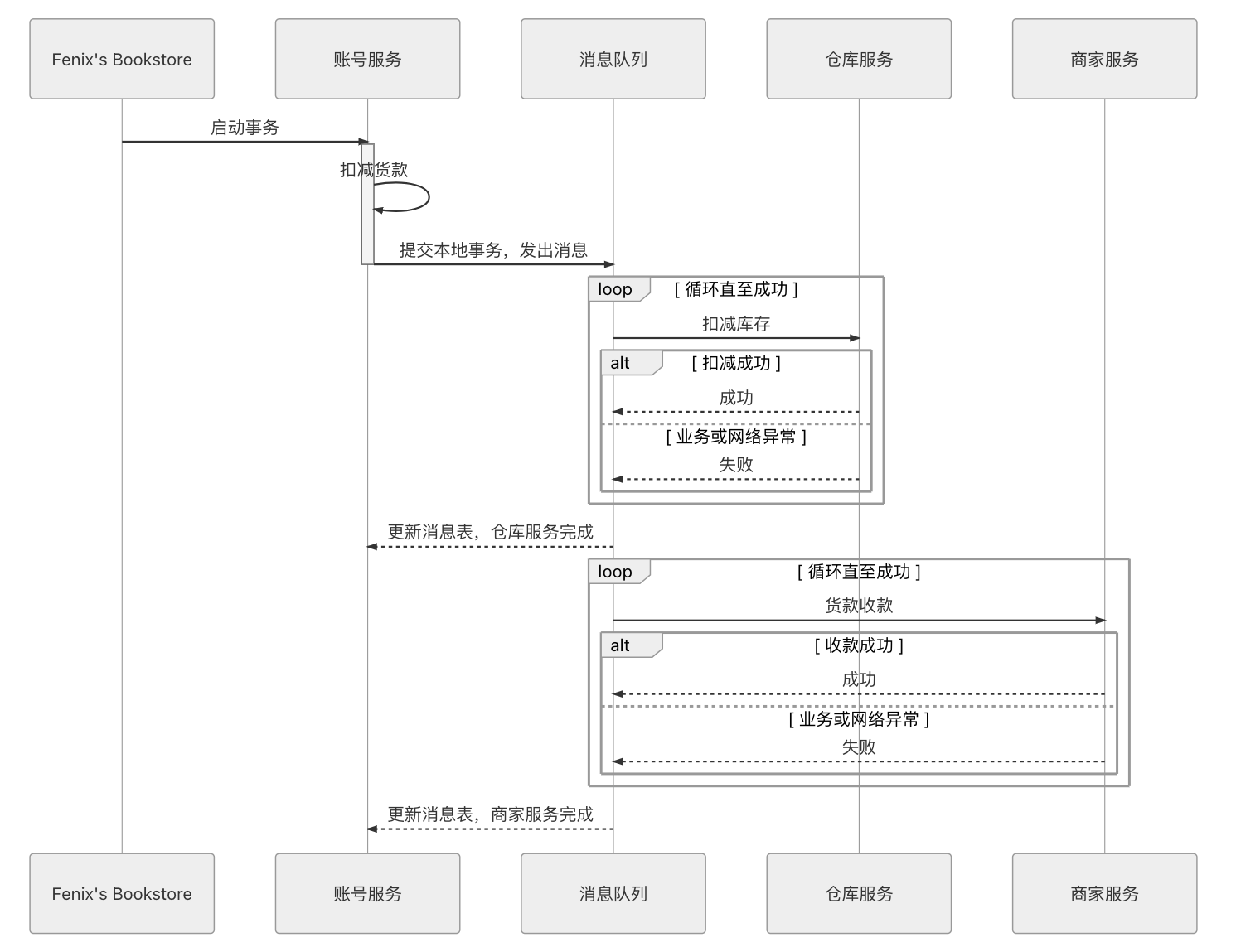
图 3-7 具体修改步骤时序图
- 最终用户向 Fenix’s Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》。
- Fenix’s Bookstore 首先应对用户账号扣款、商家账号收款、库存商品出库这三个操作有一个出错概率的先验评估,根据出错概率的大小来安排它们的操作顺序,这种评估一般直接体现在程序代码中,有一些大型系统也可能会实现动态排序。譬如,根据统计,最有可能的出现的交易异常是用户购买了商品,但是不同意扣款,或者账号余额不足;其次是仓库发现商品库存不够,无法发货;风险最低的是收款,如果到了商家收款环节,一般就不会出什么意外了。那顺序就应该安排成最容易出错的最先进行,即:账号扣款 → 仓库出库 → 商家收款。
- 账号服务进行扣款业务,如扣款成功,则在自己的数据库建立一张消息表,里面存入一条消息:“事务 ID:某 UUID,扣款:100 元(状态:已完成),仓库出库《深入理解 Java 虚拟机》:1 本(状态:进行中),某商家收款:100 元(状态:进行中)”,注意,这个步骤中“扣款业务”和“写入消息”是使用同一个本地事务写入账号服务自己的数据库的。
- 在系统中建立一个消息服务,定时轮询消息表,将状态是“进行中”的消息同时发送到库存和商家服务节点中去(也可以串行地发,即一个成功后再发送另一个,但在我们讨论的场景中没必要)。这时候可能产生以下几种情况。
- 商家和仓库服务都成功完成了收款和出库工作,向用户账号服务器返回执行结果,用户账号服务把消息状态从“进行中”更新为“已完成”。整个事务宣告顺利结束,达到最终一致性的状态。
- 商家或仓库服务中至少一个因网络原因,未能收到来自用户账号服务的消息。此时,由于用户账号服务器中存储的消息状态一直处于“进行中”,所以消息服务器将在每次轮询的时候持续地向未响应的服务重复发送消息。这个步骤的可重复性决定了所有被消息服务器发送的消息都必须具备幂等性,通常的设计是让消息带上一个唯一的事务 ID,以保证一个事务中的出库、收款动作会且只会被处理一次。
- 商家或仓库服务有某个或全部无法完成工作,譬如仓库发现《深入理解 Java 虚拟机》没有库存了,此时,仍然是持续自动重发消息,直至操作成功(譬如补充了新库存),或者被人工介入为止。由此可见,可靠事件队列只要第一步业务完成了,后续就没有失败回滚的概念,只许成功,不许失败。
- 商家和仓库服务成功完成了收款和出库工作,但回复的应答消息因网络原因丢失,此时,用户账号服务仍会重新发出下一条消息,但因操作具备幂等性,所以不会导致重复出库和收款,只会导致商家、仓库服务器重新发送一条应答消息,此过程重复直至双方网络通信恢复正常。
- 也有一些支持分布式事务的消息框架,如 RocketMQ,原生就支持分布式事务操作,这时候上述情况 2、4 也可以交由消息框架来保障。
以上这种靠着持续重试来保证可靠性的解决方案谈不上是 Dan Pritchett 的首创或者独创,它在计算机的其他领域中已被频繁使用,也有了专门的名字叫作“最大努力交付”(Best-Effort Delivery),譬如 TCP 协议中未收到 ACK 应答自动重新发包的可靠性保障就属于最大努力交付。而可靠事件队列还有一种更普通的形式,被称为“最大努力一次提交”(Best-Effort 1PC),指的就是将最有可能出错的业务以本地事务的方式完成后,采用不断重试的方式(不限于消息系统)来促使同一个分布式事务中的其他关联业务全部完成。
TCC 事务
TCC 是另一种常见的分布式事务机制,它是“Try-Confirm-Cancel”三个单词的缩写,是由数据库专家 Pat Helland 在 2007 年撰写的论文《Life beyond Distributed Transactions: An Apostate’s Opinion》中提出。
前面介绍的可靠消息队列虽然能保证最终的结果是相对可靠的,过程也足够简单(相对于 TCC 来说),但整个过程完全没有任何隔离性可言,有一些业务中隔离性是无关紧要的,但有一些业务中缺乏隔离性就会带来许多麻烦。譬如在本章的场景事例中,缺乏隔离性会带来的一个显而易见的问题便是“超售”:完全有可能两个客户在短时间内都成功购买了同一件商品,而且他们各自购买的数量都不超过目前的库存,但他们购买的数量之和却超过了库存。如果这件事情处于刚性事务,且隔离级别足够的情况下是可以完全避免的,譬如,以上场景就需要“可重复读”(Repeatable Read)的隔离级别,以保证后面提交的事务会因为无法获得锁而导致失败,但用可靠消息队列就无法保证这一点,这部分属于数据库本地事务方面的知识,可以参考前面的讲解。如果业务需要隔离,那架构师通常就应该重点考虑 TCC 方案,该方案天生适合用于需要强隔离性的分布式事务中。
在具体实现上,TCC 较为烦琐,它是一种业务侵入式较强的事务方案,要求业务处理过程必须拆分为“预留业务资源”和“确认/释放消费资源”两个子过程。如同 TCC 的名字所示,它分为以下三个阶段。
- Try:尝试执行阶段,完成所有业务可执行性的检查(保障一致性),并且预留好全部需用到的业务资源(保障隔离性)。
- Confirm:确认执行阶段,不进行任何业务检查,直接使用 Try 阶段准备的资源来完成业务处理。Confirm 阶段可能会重复执行,因此本阶段所执行的操作需要具备幂等性。
- Cancel:取消执行阶段,释放 Try 阶段预留的业务资源。Cancel 阶段可能会重复执行,也需要满足幂等性。
按照我们的场景事例,TCC 的执行过程应该如图 3-8 所示。
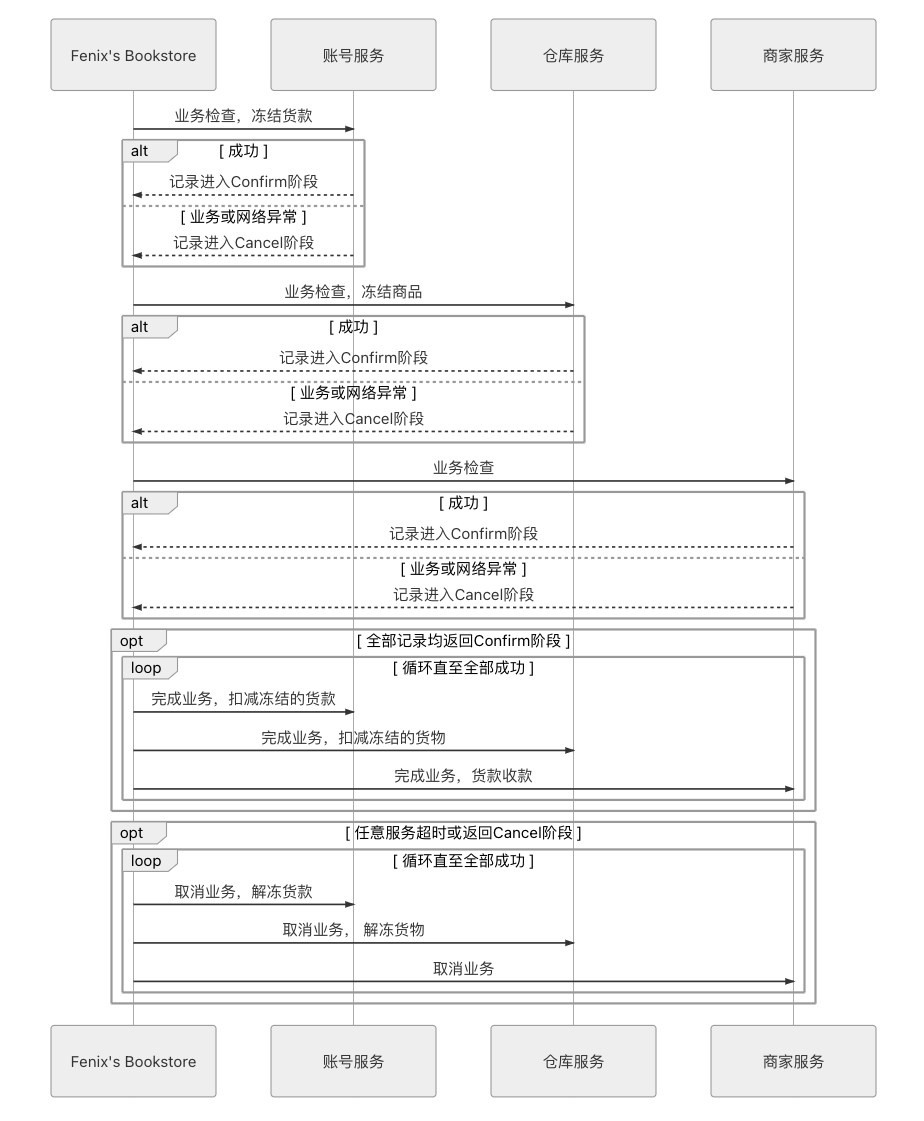
图 3-8 TCC 的执行过程
- 最终用户向 Fenix’s Bookstore 发送交易请求:购买一本价值 100 元的《深入理解 Java 虚拟机》。
- 创建事务,生成事务 ID,记录在活动日志中,进入 Try 阶段:
- 用户服务:检查业务可行性,可行的话,将该用户的 100 元设置为“冻结”状态,通知下一步进入 Confirm 阶段;不可行的话,通知下一步进入 Cancel 阶段。
- 仓库服务:检查业务可行性,可行的话,将该仓库的 1 本《深入理解 Java 虚拟机》设置为“冻结”状态,通知下一步进入 Confirm 阶段;不可行的话,通知下一步进入 Cancel 阶段。
- 商家服务:检查业务可行性,不需要冻结资源。
- 如果第 2 步所有业务均反馈业务可行,将活动日志中的状态记录为 Confirm,进入 Confirm 阶段:
- 用户服务:完成业务操作(扣减那被冻结的 100 元)。
- 仓库服务:完成业务操作(标记那 1 本冻结的书为出库状态,扣减相应库存)。
- 商家服务:完成业务操作(收款 100 元)。
- 第 3 步如果全部完成,事务宣告正常结束,如果第 3 步中任何一方出现异常,不论是业务异常或者网络异常,都将根据活动日志中的记录,重复执行该服务的 Confirm 操作,即进行最大努力交付。
- 如果第 2 步有任意一方反馈业务不可行,或任意一方超时,将活动日志的状态记录为 Cancel,进入 Cancel 阶段:
- 用户服务:取消业务操作(释放被冻结的 100 元)。
- 仓库服务:取消业务操作(释放被冻结的 1 本书)。
- 商家服务:取消业务操作(大哭一场后安慰商家谋生不易)。
- 第 5 步如果全部完成,事务宣告以失败回滚结束,如果第 5 步中任何一方出现异常,不论是业务异常或者网络异常,都将根据活动日志中的记录,重复执行该服务的 Cancel 操作,即进行最大努力交付。
由上述操作过程可见,TCC 其实有点类似 2PC 的准备阶段和提交阶段,但 TCC 是位于用户代码层面,而不是在基础设施层面,这为它的实现带来了较高的灵活性,可以根据需要设计资源锁定的粒度。TCC 在业务执行时只操作预留资源,几乎不会涉及锁和资源的争用,具有很高的性能潜力。但是 TCC 并非纯粹只有好处,它也带来了更高的开发成本和业务侵入性,意味着有更高的开发成本和更换事务实现方案的替换成本,所以,通常我们并不会完全靠裸编码来实现 TCC,而是基于某些分布式事务中间件(譬如阿里开源的Seata)去完成,尽量减轻一些编码工作量。
SAGA 事务
TCC 事务具有较强的隔离性,避免了“超售”的问题,而且其性能一般来说是本篇提及的几种柔性事务模式中最高的,但它仍不能满足所有的场景。TCC 的最主要限制是它的业务侵入性很强,这里并不是重复上一节提到的它需要开发编码配合所带来的工作量,而更多的是指它所要求的技术可控性上的约束。譬如,把我们的场景事例修改如下:由于中国网络支付日益盛行,现在用户和商家在书店系统中可以选择不再开设充值账号,至少不会强求一定要先从银行充值到系统中才能进行消费,允许直接在购物时通过 U 盾或扫码支付,在银行账号中划转货款。这个需求完全符合国内网络支付盛行的现状,却给系统的事务设计增加了额外的限制:如果用户、商家的账号余额由银行管理的话,其操作权限和数据结构就不可能再随心所欲的地自行定义,通常也就无法完成冻结款项、解冻、扣减这样的操作,因为银行一般不会配合你的操作。所以 TCC 中的第一步 Try 阶段往往无法施行。我们只能考虑采用另外一种柔性事务方案:SAGA 事务。SAGA 在英文中是“长篇故事、长篇记叙、一长串事件”的意思。
SAGA 事务模式的历史十分悠久,还早于分布式事务概念的提出。它源于 1987 年普林斯顿大学的 Hector Garcia-Molina 和 Kenneth Salem 在 ACM 发表的一篇论文《SAGAS》(这就是论文的全名)。文中提出了一种提升“长时间事务”(Long Lived Transaction)运作效率的方法,大致思路是把一个大事务分解为可以交错运行的一系列子事务集合。原本 SAGA 的目的是避免大事务长时间锁定数据库的资源,后来才发展成将一个分布式环境中的大事务分解为一系列本地事务的设计模式。SAGA 由两部分操作组成。
- 大事务拆分若干个小事务,将整个分布式事务 T 分解为 n 个子事务,命名为 T1,T2,…,Ti,…,Tn。每个子事务都应该是或者能被视为是原子行为。如果分布式事务能够正常提交,其对数据的影响(最终一致性)应与连续按顺序成功提交 Ti等价。
- 为每一个子事务设计对应的补偿动作,命名为 C1,C2,…,Ci,…,Cn。Ti 与 Ci 必须满足以下条件:
- Ti 与 Ci 都具备幂等性。
- Ti 与 Ci 满足交换律(Commutative),即先执行 Ti 还是先执行 Ci,其效果都是一样的。
- Ci 必须能成功提交,即不考虑 Ci 本身提交失败被回滚的情形,如出现就必须持续重试直至成功,或者要人工介入。
如果 T1 到 Tn 均成功提交,那事务顺利完成,否则,要采取以下两种恢复策略之一:
- 正向恢复(Forward Recovery):如果 Ti 事务提交失败,则一直对 Ti 进行重试,直至成功为止(最大努力交付)。这种恢复方式不需要补偿,适用于事务最终都要成功的场景,譬如在别人的银行账号中扣了款,就一定要给别人发货。正向恢复的执行模式为:T1,T2,…,Ti(失败),Ti(重试)…,Ti+1,…,Tn。
- 反向恢复(Backward Recovery):如果 Ti 事务提交失败,则一直执行 Ci 对 Ti 进行补偿,直至成功为止(最大努力交付)。这里要求 Ci 必须(在持续重试后)执行成功。反向恢复的执行模式为:T1,T2,…,Ti(失败),Ci(补偿),…,C2,C1。
与 TCC 相比,SAGA 不需要为资源设计冻结状态和撤销冻结的操作,补偿操作往往要比冻结操作容易实现得多。譬如,前面提到的账号余额直接在银行维护的场景,从银行划转货款到 Fenix’s Bookstore 系统中,这步是经由用户支付操作(扫码或 U 盾)来促使银行提供服务;如果后续业务操作失败,尽管我们无法要求银行撤销掉之前的用户转账操作,但是由 Fenix’s Bookstore 系统将货款转回到用户账上作为补偿措施却是完全可行的。
SAGA 必须保证所有子事务都得以提交或者补偿,但 SAGA 系统本身也有可能会崩溃,所以它必须设计成与数据库类似的日志机制(被称为 SAGA Log)以保证系统恢复后可以追踪到子事务的执行情况,譬如执行至哪一步或者补偿至哪一步了。另外,尽管补偿操作通常比冻结/撤销容易实现,但保证正向、反向恢复过程的能严谨地进行也需要花费不少的工夫,譬如通过服务编排、可靠事件队列等方式完成,所以,SAGA 事务通常也不会直接靠裸编码来实现,一般也是在事务中间件的基础上完成,前面提到的 Seata 就同样支持 SAGA 事务模式。
基于数据补偿来代替回滚的思路,还可以应用在其他事务方案上,这些方案笔者就不开独立小节,放到这里一起来解释。举个具体例子,譬如阿里的 GTS(Global Transaction Service,Seata 由 GTS 开源而来)所提出的“AT 事务模式”就是这样的一种应用。
从整体上看是 AT 事务是参照了 XA 两段提交协议实现的,但针对 XA 2PC 的缺陷,即在准备阶段必须等待所有数据源都返回成功后,协调者才能统一发出 Commit 命令而导致的木桶效应(所有涉及的锁和资源都需要等待到最慢的事务完成后才能统一释放),设计了针对性的解决方案。大致的做法是在业务数据提交时自动拦截所有 SQL,将 SQL 对数据修改前、修改后的结果分别保存快照,生成行锁,通过本地事务一起提交到操作的数据源中,相当于自动记录了重做和回滚日志。如果分布式事务成功提交,那后续清理每个数据源中对应的日志数据即可;如果分布式事务需要回滚,就根据日志数据自动产生用于补偿的“逆向 SQL”。基于这种补偿方式,分布式事务中所涉及的每一个数据源都可以单独提交,然后立刻释放锁和资源。这种异步提交的模式,相比起 2PC 极大地提升了系统的吞吐量水平。而代价就是大幅度地牺牲了隔离性,甚至直接影响到了原子性。因为在缺乏隔离性的前提下,以补偿代替回滚并不一定是总能成功的。譬如,当本地事务提交之后、分布式事务完成之前,该数据被补偿之前又被其他操作修改过,即出现了脏写(Dirty Write),这时候一旦出现分布式事务需要回滚,就不可能再通过自动的逆向 SQL 来实现补偿,只能由人工介入处理了。
通常来说,脏写是一定要避免的,所有传统关系数据库在最低的隔离级别上都仍然要加锁以避免脏写,因为脏写情况一旦发生,人工其实也很难进行有效处理。所以 GTS 增加了一个“全局锁”(Global Lock)的机制来实现写隔离,要求本地事务提交之前,一定要先拿到针对修改记录的全局锁后才允许提交,没有获得全局锁之前就必须一直等待,这种设计以牺牲一定性能为代价,避免了有两个分布式事务中包含的本地事务修改了同一个数据,从而避免脏写。在读隔离方面,AT 事务默认的隔离级别是读未提交(Read Uncommitted),这意味着可能产生脏读(Dirty Read)。也可以采用全局锁的方案解决读隔离问题,但直接阻塞读取的话,代价就非常大了,一般不会这样做。由此可见,分布式事务中没有一揽子包治百病的解决办法,因地制宜地选用合适的事务处理方案才是唯一有效的做法。
弱隔离级别
如果两个事务不触及相同的数据,它们可以安全地并行(parallel) 运行,因为两者都不依赖于另一个。当一个事务读取由另一个事务同时修改的数据时,或者当两个事务试图同时修改相同的数据时,并发问题(竞争条件)才会出现。
并发BUG很难通过测试找到,因为这样的错误只有在特殊时序下才会触发。这样的时序问题可能非常少发生,通常很难重现译注i。并发性也很难推理,特别是在大型应用中,你不一定知道哪些其他代码正在访问数据库。在一次只有一个用户时,应用开发已经很麻烦了,有许多并发用户使得它更加困难,因为任何一个数据都可能随时改变。
译注i. 轶事:偶然出现的瞬时错误有时称为Heisenbug,而确定性的问题对应地称为Bohrbugs ↩
出于这个原因,数据库一直试图通过提供事务隔离(transaction isolation) 来隐藏应用程序开发者的并发问题。从理论上讲,隔离可以通过假装没有并发发生,让你的生活更加轻松:可串行的(serializable) 隔离等级意味着数据库保证事务的效果如同串行运行(即一次一个,没有任何并发)。
实际上不幸的是:隔离并没有那么简单。可串行的隔离会有性能损失,许多数据库不愿意支付这个代价【8】。因此,系统通常使用较弱的隔离级别来防止一部分,而不是全部的并发问题。这些隔离级别难以理解,并且会导致微妙的错误,但是它们仍然在实践中被使用【23】。
弱事务隔离级别导致的并发性错误不仅仅是一个理论问题。它们造成了很多的资金损失【24,25】,耗费了财务审计人员的调查【26】,并导致客户数据被破坏【27】。关于这类问题的一个流行的评论是“如果你正在处理财务数据,请使用ACID数据库!” —— 但是这一点没有提到。即使是很多流行的关系型数据库系统(通常被认为是“ACID”)也使用弱隔离级别,所以它们也不一定能防止这些错误的发生。
比起盲目地依赖工具,我们应该对存在的并发问题的种类,以及如何防止这些问题有深入的理解。然后就可以使用我们所掌握的工具来构建可靠和正确的应用程序。
在本节中,我们将看几个在实践中使用的弱(非串行的(nonserializable))隔离级别,并详细讨论哪种竞争条件可能发生也可能不发生,以便您可以决定什么级别适合您的应用程序。一旦我们完成了这个工作,我们将详细讨论可串行化(请参阅“可串行化”)。我们讨论的隔离级别将是非正式的,通过示例来进行。如果你需要严格的定义和分析它们的属性,你可以在学术文献中找到它们[28,29,30]。
读已提交
最基本的事务隔离级别是读已提交(Read Committed)v,它提供了两个保证:
- 从数据库读时,只能看到已提交的数据(没有脏读(dirty reads))。
- 写入数据库时,只会覆盖已经写入的数据(没有脏写(dirty writes))。
我们来更详细地讨论这两个保证。
v. 某些数据库支持甚至更弱的隔离级别,称为读未提交(Read uncommitted)。它可以防止脏写,但不防止脏读。 ↩
没有脏读
设想一个事务已经将一些数据写入数据库,但事务还没有提交或中止。另一个事务可以看到未提交的数据吗?如果是的话,那就叫做脏读(dirty reads)【2】。
在读已提交隔离级别运行的事务必须防止脏读。这意味着事务的任何写入操作只有在该事务提交时才能被其他人看到(然后所有的写入操作都会立即变得可见)。如图7-4所示,用户1 设置了x = 3,但用户2 的 get x仍旧返回旧值2 (当用户1 尚未提交时)。

图7-4 没有脏读:用户2只有在用户1的事务已经提交后才能看到x的新值。
为什么要防止脏读,有几个原因:
- 如果事务需要更新多个对象,脏读取意味着另一个事务可能会只看到一部分更新。例如,在图7-2中,用户看到新的未读电子邮件,但看不到更新的计数器。这就是电子邮件的脏读。看到处于部分更新状态的数据库会让用户感到困惑,并可能导致其他事务做出错误的决定。
- 如果事务中止,则所有写入操作都需要回滚(如图7-3所示)。如果数据库允许脏读,那就意味着一个事务可能会看到稍后需要回滚的数据,即从未实际提交给数据库的数据。想想后果就让人头大。
没有脏写
如果两个事务同时尝试更新数据库中的相同对象,会发生什么情况?我们不知道写入的顺序是怎样的,但是我们通常认为后面的写入会覆盖前面的写入。
但是,如果先前的写入是尚未提交事务的一部分,又会发生什么情况,后面的写入会覆盖一个尚未提交的值?这被称作脏写(dirty write)【28】。在读已提交的隔离级别上运行的事务必须防止脏写,通常是延迟第二次写入,直到第一次写入事务提交或中止为止。
通过防止脏写,这个隔离级别避免了一些并发问题:
- 如果事务更新多个对象,脏写会导致不好的结果。例如,考虑 图7-5,以一个二手车销售网站为例,Alice和Bob两个人同时试图购买同一辆车。购买汽车需要两次数据库写入:网站上的商品列表需要更新,以反映买家的购买,销售发票需要发送给买家。在图7-5的情况下,销售是属于Bob的(因为他成功更新了商品列表),但发票却寄送给了爱丽丝(因为她成功更新了发票表)。读已提交会阻止这样的事故。
- 但是,读已提交并不能防止图7-1中两个计数器增量之间的竞争状态。在这种情况下,第二次写入发生在第一个事务提交后,所以它不是一个脏写。这仍然是不正确的,但是出于不同的原因,在“防止更新丢失”中将讨论如何使这种计数器增量安全。
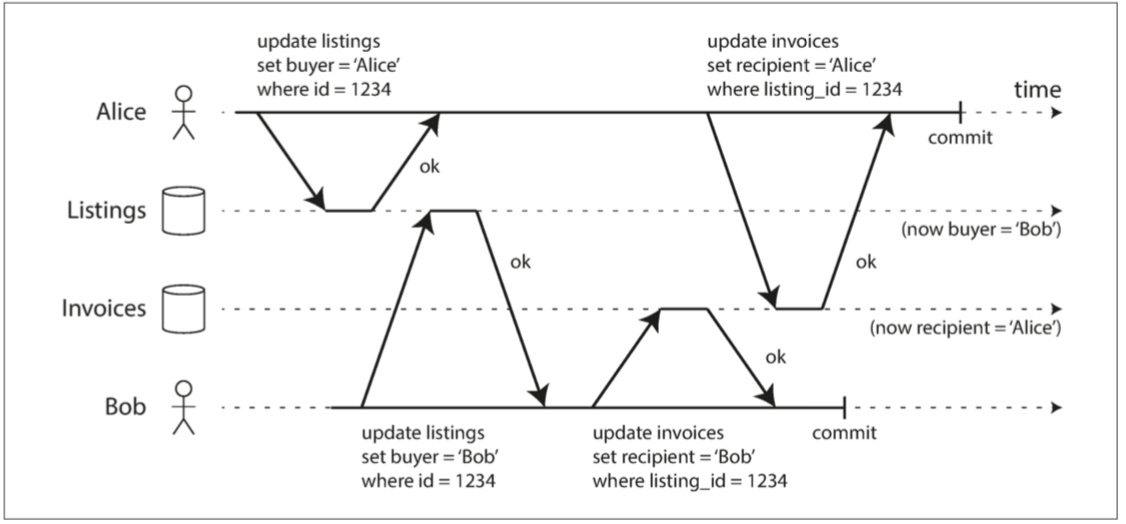
图7-5 如果存在脏写,来自不同事务的冲突写入可能会混淆在一起
实现读已提交
读已提交是一个非常流行的隔离级别。这是Oracle 11g,PostgreSQL,SQL Server 2012,MemSQL和其他许多数据库的默认设置【8】。
最常见的情况是,数据库通过使用行锁(row-level lock) 来防止脏写:当事务想要修改特定对象(行或文档)时,它必须首先获得该对象的锁。然后必须持有该锁直到事务被提交或中止。一次只有一个事务可持有任何给定对象的锁;如果另一个事务要写入同一个对象,则必须等到第一个事务提交或中止后,才能获取该锁并继续。这种锁定是读已提交模式(或更强的隔离级别)的数据库自动完成的。
如何防止脏读?一种选择是使用相同的锁,并要求任何想要读取对象的事务来简单地获取该锁,然后在读取之后立即再次释放该锁。这能确保在读取进行时,对象不会在脏的、有未提交的值的状态(因为在那段时间锁会被写入该对象的事务持有)。
但是要求读锁的办法在实践中效果并不好。因为一个长时间运行的写入事务会迫使许多只读事务等到这个慢写入事务完成。这会损失只读事务的响应时间,并且不利于可操作性:因为等待锁,应用某个部分的迟缓可能由于连锁效应,导致其他部分出现问题。
出于这个原因,大多数数据库vi使用图7-4的方式防止脏读:对于写入的每个对象,数据库都会记住旧的已提交值,和由当前持有写入锁的事务设置的新值。当事务正在进行时,任何其他读取对象的事务都会拿到旧值。 只有当新值提交后,事务才会切换到读取新值。
vi. 在撰写本文时,唯一在读已提交隔离级别使用读锁的主流数据库是使用read_committed_snapshot = off配置的IBM DB2和Microsoft SQL Server [23,36]。 ↩
快照隔离和可重复读
如果只从表面上看读已提交隔离级别你就认为它完成了事务所需的一切,那是可以原谅的。它允许中止(原子性的要求);它防止读取不完整的事务结果,并且防止并发写入造成的混乱。事实上这些功能非常有用,比起没有事务的系统来,可以提供更多的保证。
但是在使用此隔离级别时,仍然有很多地方可能会产生并发错误。例如图7-6说明了读已提交时可能发生的问题。
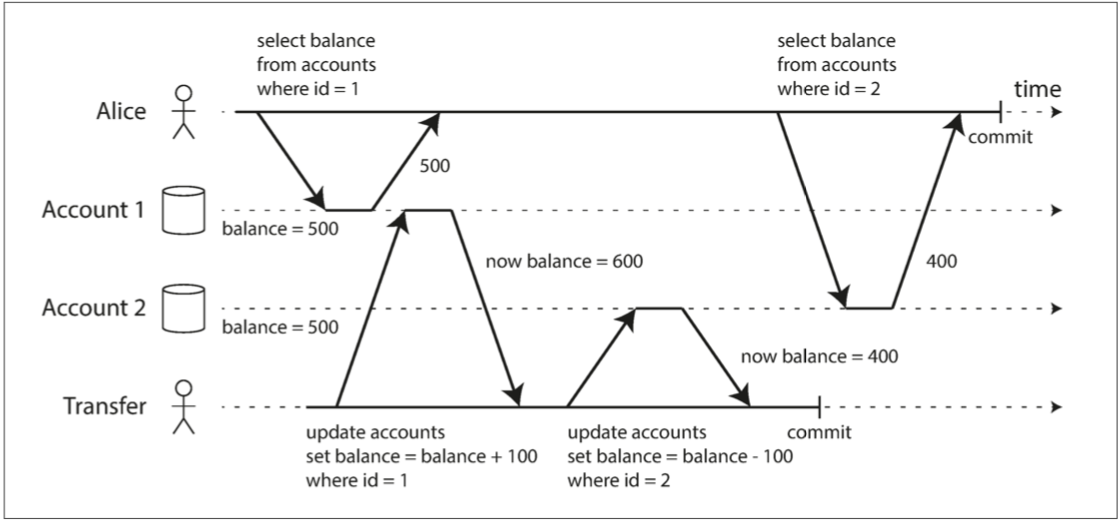
图7-6 读取偏差:Alice观察数据库处于不一致的状态
爱丽丝在银行有1000美元的储蓄,分为两个账户,每个500美元。现在一笔事务从她的一个账户转移了100美元到另一个账户。如果她在事务处理的同时查看其账户余额列表,她可能会碰巧在收款到达前看到收款账户的余额仍然是500美元,而在付款产生后看到付款账户的余额已经是400美元。对爱丽丝来说,现在她的账户似乎总共只有900美元——看起来有100美元已经凭空消失了。
这种异常被称为不可重复读(nonrepeatable read) 或读取偏差(read skew):如果Alice在事务结束时再次读取账户1的余额,她将看到与她之前的查询中看到的不同的值(600美元)。在读已提交的隔离条件下,不可重复读被认为是可接受的:Alice看到的帐户余额时确实在阅读时已经提交了。
不幸的是,术语偏差(skew) 这个词是过载的:以前使用它是因为热点的不平衡工作量(请参阅“负载偏斜与热点消除”),而这里偏差意味着异常的时序。
对于Alice的情况,这不是一个长期持续的问题。因为如果她几秒钟后刷新银行网站的页面,她很可能会看到一致的帐户余额。但是有些情况下,不能容忍这种暂时的不一致:
备份
进行备份需要复制整个数据库,对大型数据库而言可能需要花费数小时才能完成。备份进程运行时,数据库仍然会接受写入操作。因此备份可能会包含一些旧的部分和一些新的部分。如果从这样的备份中恢复,那么不一致(如消失的钱)就会变成永久的。
分析查询和完整性检查
有时,您可能需要运行一个查询,扫描大部分的数据库。这样的查询在分析中很常见(请参阅“事务处理还是分析?”),也可能是定期完整性检查(即监视数据损坏)的一部分。如果这些查询在不同时间点观察数据库的不同部分,则可能会返回毫无意义的结果。
快照隔离(snapshot isolation)【28】是这个问题最常见的解决方案。想法是,每个事务都从数据库的一致快照(consistent snapshot) 中读取——也就是说,事务可以看到事务开始时在数据库中提交的所有数据。即使这些数据随后被另一个事务更改,每个事务也只能看到该特定时间点的旧数据。
快照隔离对长时间运行的只读查询(如备份和分析)非常有用。如果查询的数据在查询执行的同时发生变化,则很难理解查询的含义。当一个事务可以看到数据库在某个特定时间点冻结时的一致快照,理解起来就很容易了。
快照隔离是一个流行的功能:PostgreSQL,使用InnoDB引擎的MySQL,Oracle,SQL Server等都支持【23,31,32】。
实现快照隔离
与读取提交的隔离类似,快照隔离的实现通常使用写锁来防止脏写(请参阅“读已提交”),这意味着进行写入的事务会阻止另一个事务修改同一个对象。但是读取不需要任何锁定。从性能的角度来看,快照隔离的一个关键原则是:读不阻塞写,写不阻塞读。这允许数据库在处理一致性快照上的长时间查询时,可以正常地同时处理写入操作。且两者间没有任何锁定争用。
为了实现快照隔离,数据库使用了我们看到的用于防止图7-4中的脏读的机制的一般化。数据库必须可能保留一个对象的几个不同的提交版本,因为各种正在进行的事务可能需要看到数据库在不同的时间点的状态。因为它同时维护着单个对象的多个版本,所以这种技术被称为多版本并发控制(MVCC, multi-version concurrency control)。
如果一个数据库只需要提供读已提交的隔离级别,而不提供快照隔离,那么保留一个对象的两个版本就足够了:提交的版本和被覆盖但尚未提交的版本。支持快照隔离的存储引擎通常也使用MVCC来实现读已提交隔离级别。一种典型的方法是读已提交为每个查询使用单独的快照,而快照隔离对整个事务使用相同的快照。
图7-7说明了如何在PostgreSQL中实现基于MVCC的快照隔离【31】(其他实现类似)。当一个事务开始时,它被赋予一个唯一的,永远增长vii的事务ID(txid)。每当事务向数据库写入任何内容时,它所写入的数据都会被标记上写入者的事务ID。
vii. 事实上,事务ID是32位整数,所以大约会在40亿次事务之后溢出。 PostgreSQL的Vacuum过程会清理老旧的事务ID,确保事务ID溢出(回卷)不会影响到数据。 ↩

图7-7 使用多版本对象实现快照隔离
表中的每一行都有一个 created_by 字段,其中包含将该行插入到表中的的事务ID。此外,每行都有一个 deleted_by 字段,最初是空的。如果某个事务删除了一行,那么该行实际上并未从数据库中删除,而是通过将 deleted_by 字段设置为请求删除的事务的ID来标记为删除。在稍后的时间,当确定没有事务可以再访问已删除的数据时,数据库中的垃圾收集过程会将所有带有删除标记的行移除,并释放其空间。译注ii
译注ii. 在PostgreSQL中,created_by的实际名称为xmin,deleted_by的实际名称为xmax↩
UPDATE 操作在内部翻译为 DELETE 和 INSERT 。例如,在图7-7中,事务13 从账户2 中扣除100美元,将余额从500美元改为400美元。实际上包含两条账户2 的记录:余额为 $500 的行被标记为被事务13删除,余额为 $400 的行由事务13创建。
观察一致性快照的可见性规则
当一个事务从数据库中读取时,事务ID用于决定它可以看见哪些对象,看不见哪些对象。通过仔细定义可见性规则,数据库可以向应用程序呈现一致的数据库快照。工作如下:
- 在每次事务开始时,数据库列出当时所有其他(尚未提交或尚未中止)的事务清单,即使之后提交了,这些事务已执行的任何写入也都会被忽略。
- 被中止事务所执行的任何写入都将被忽略。
- 由具有较晚事务ID(即,在当前事务开始之后开始的)的事务所做的任何写入都被忽略,而不管这些事务是否已经提交。
- 所有其他写入,对应用都是可见的。
这些规则适用于创建和删除对象。在图7-7中,当事务12 从账户2 读取时,它会看到 $500 的余额,因为 $500 余额的删除是由事务13 完成的(根据规则3,事务12 看不到事务13 执行的删除),且400美元记录的创建也是不可见的(按照相同的规则)。
换句话说,如果以下两个条件都成立,则可见一个对象:
- 读事务开始时,创建该对象的事务已经提交。
- 对象未被标记为删除,或如果被标记为删除,请求删除的事务在读事务开始时尚未提交。
长时间运行的事务可能会长时间使用快照,并继续读取(从其他事务的角度来看)早已被覆盖或删除的值。由于从来不原地更新值,而是每次值改变时创建一个新的版本,数据库可以在提供一致快照的同时只产生很小的额外开销。
索引和快照隔离
索引如何在多版本数据库中工作?一种选择是使索引简单地指向对象的所有版本,并且需要索引查询来过滤掉当前事务不可见的任何对象版本。当垃圾收集删除任何事务不再可见的旧对象版本时,相应的索引条目也可以被删除。
在实践中,许多实现细节决定了多版本并发控制的性能。例如,如果同一对象的不同版本可以放入同一个页面中,PostgreSQL的优化可以避免更新索引【31】。
在CouchDB,Datomic和LMDB中使用另一种方法。虽然它们也使用B树,但它们使用的是一种仅追加/写时拷贝(append-only/copy-on-write) 的变体,它们在更新时不覆盖树的页面,而为每个修改页面创建一份副本。从父页面直到树根都会级联更新,以指向它们子页面的新版本。任何不受写入影响的页面都不需要被复制,并且保持不变【33,34,35】。
使用仅追加的B树,每个写入事务(或一批事务)都会创建一颗新的B树,当创建时,从该特定树根生长的树就是数据库的一个一致性快照。没必要根据事务ID过滤掉对象,因为后续写入不能修改现有的B树;它们只能创建新的树根。但这种方法也需要一个负责压缩和垃圾收集的后台进程。
可重复读与命名混淆
快照隔离是一个有用的隔离级别,特别对于只读事务而言。但是,许多数据库实现了它,却用不同的名字来称呼。在Oracle中称为可串行化(Serializable) 的,在PostgreSQL和MySQL中称为可重复读(repeatable read)【23】。
这种命名混淆的原因是SQL标准没有快照隔离的概念,因为标准是基于System R 1975年定义的隔离级别【2】,那时候快照隔离尚未发明。相反,它定义了可重复读,表面上看起来与快照隔离很相似。 PostgreSQL和MySQL称其快照隔离级别为可重复读(repeatable read),因为这样符合标准要求,所以它们可以声称自己“标准兼容”。
不幸的是,SQL标准对隔离级别的定义是有缺陷的——模糊,不精确,并不像标准应有的样子独立于实现【28】。有几个数据库实现了可重复读,但它们实际提供的保证存在很大的差异,尽管表面上是标准化的【23】。在研究文献【29,30】中已经有了可重复读的正式定义,但大多数的实现并不能满足这个正式定义。最后,IBM DB2使用“可重复读”来引用可串行化【8】。
结果,没有人真正知道可重复读的意思。
防止丢失更新
到目前为止已经讨论的读已提交和快照隔离级别,主要保证了只读事务在并发写入时可以看到什么。却忽略了两个事务并发写入的问题——我们只讨论了脏写(请参阅“没有脏写”),一种特定类型的写-写冲突是可能出现的。
并发的写入事务之间还有其他几种有趣的冲突。其中最着名的是丢失更新(lost update) 问题,如图7-1所示,以两个并发计数器增量为例。
如果应用从数据库中读取一些值,修改它并写回修改的值(读取-修改-写入序列),则可能会发生丢失更新的问题。如果两个事务同时执行,则其中一个的修改可能会丢失,因为第二个写入的内容并没有包括第一个事务的修改,这种模式发生在各种不同的情况下:
- 增加计数器或更新账户余额(需要读取当前值,计算新值并写回更新后的值)
- 在复杂值中进行本地修改:例如,将元素添加到JSON文档中的一个列表(需要解析文档,进行更改并写回修改的文档)
- 两个用户同时编辑wiki页面,每个用户通过将整个页面内容发送到服务器来保存其更改,覆写数据库中当前的任何内容。
这是一个普遍的问题,所以已经开发了各种解决方案。
原子写
许多数据库提供了原子更新操作,从而消除了在应用程序代码中执行读取-修改-写入序列的需要。如果你的代码可以用这些操作来表达,那这通常是最好的解决方案。例如,下面的指令在大多数关系数据库中是并发安全的:
UPDATE counters SET value = value + 1 WHERE key = 'foo';类似地,像MongoDB这样的文档数据库提供了对JSON文档的一部分进行本地修改的原子操作,Redis提供了修改数据结构(如优先级队列)的原子操作。并不是所有的写操作都可以用原子操作的方式来表达,例如维基页面的更新涉及到任意文本编辑viii,但是在可以使用原子操作的情况下,它们通常是最好的选择。
viii. 将文本文档的编辑表示为原子的变化流是可能的,尽管相当复杂。请参阅“自动冲突解决”。 ↩
原子操作通常通过在读取对象时,获取其上的排它锁来实现。以便更新完成之前没有其他事务可以读取它。这种技术有时被称为游标稳定性(cursor stability)【36,37】。另一个选择是简单地强制所有的原子操作在单一线程上执行。
不幸的是,ORM框架很容易意外地执行不安全的读取-修改-写入序列,而不是使用数据库提供的原子操作【38】。如果你知道自己在做什么那当然不是问题,但它经常产生那种很难测出来的微妙Bug。
显式锁定
如果数据库的内置原子操作没有提供必要的功能,防止丢失更新的另一个选择是让应用程序显式地锁定将要更新的对象。然后应用程序可以执行读取-修改-写入序列,如果任何其他事务尝试同时读取同一个对象,则强制等待,直到第一个读取-修改-写入序列完成。
例如,考虑一个多人游戏,其中几个玩家可以同时移动相同的棋子。在这种情况下,一个原子操作可能是不够的,因为应用程序还需要确保玩家的移动符合游戏规则,这可能涉及到一些不能合理地用数据库查询实现的逻辑。但你可以使用锁来防止两名玩家同时移动相同的棋子,如例7-1所示。
例7-1 显式锁定行以防止丢失更新
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE;
-- 检查玩家的操作是否有效,然后更新先前SELECT返回棋子的位置。
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;FOR UPDATE子句告诉数据库应该对该查询返回的所有行加锁。
这是有效的,但要做对,你需要仔细考虑应用逻辑。忘记在代码某处加锁很容易引入竞争条件。
自动检测丢失的更新
原子操作和锁是通过强制读取-修改-写入序列按顺序发生,来防止丢失更新的方法。另一种方法是允许它们并行执行,如果事务管理器检测到丢失更新,则中止事务并强制它们重试其读取-修改-写入序列。
这种方法的一个优点是,数据库可以结合快照隔离高效地执行此检查。事实上,PostgreSQL的可重复读,Oracle的可串行化和SQL Server的快照隔离级别,都会自动检测到丢失更新,并中止惹麻烦的事务。但是,MySQL/InnoDB的可重复读并不会检测丢失更新【23】。一些作者【28,30】认为,数据库必须能防止丢失更新才称得上是提供了快照隔离,所以在这个定义下,MySQL下不提供快照隔离。
丢失更新检测是一个很好的功能,因为它不需要应用代码使用任何特殊的数据库功能,你可能会忘记使用锁或原子操作,从而引入错误;但丢失更新的检测是自动发生的,因此不太容易出错。
比较并设置(CAS)
在不提供事务的数据库中,有时会发现一种原子操作:比较并设置(CAS, Compare And Set)(先前在“单对象写入”中提到)。此操作的目的是为了避免丢失更新:只有当前值从上次读取时一直未改变,才允许更新发生。如果当前值与先前读取的值不匹配,则更新不起作用,且必须重试读取-修改-写入序列。
例如,为了防止两个用户同时更新同一个wiki页面,可以尝试类似这样的方式,只有当用户开始编辑页面内容时,才会发生更新:
-- 根据数据库的实现情况,这可能安全也可能不安全
UPDATE wiki_pages SET content = '新内容'
WHERE id = 1234 AND content = '旧内容';如果内容已经更改并且不再与“旧内容”相匹配,则此更新将不起作用,因此您需要检查更新是否生效,必要时重试。但是,如果数据库允许WHERE子句从旧快照中读取,则此语句可能无法防止丢失更新,因为即使发生了另一个并发写入,WHERE条件也可能为真。在依赖数据库的CAS操作前要检查其是否安全。
冲突解决和复制
在复制数据库中(请参阅第五章),防止丢失的更新需要考虑另一个维度:由于在多个节点上存在数据副本,并且在不同节点上的数据可能被并发地修改,因此需要采取一些额外的步骤来防止丢失更新。
锁和CAS操作假定只有一个最新的数据副本。但是多主或无主复制的数据库通常允许多个写入并发执行,并异步复制到副本上,因此无法保证只有一个最新数据的副本。所以基于锁或CAS操作的技术不适用于这种情况。 (我们将在“线性一致性”中更详细地讨论这个问题。)
相反,如“检测并发写入”一节所述,这种复制数据库中的一种常见方法是允许并发写入创建多个冲突版本的值(也称为兄弟),并使用应用代码或特殊数据结构在事实发生之后解决和合并这些版本。
原子操作可以在复制的上下文中很好地工作,尤其当它们具有可交换性时(即,可以在不同的副本上以不同的顺序应用它们,且仍然可以得到相同的结果)。例如,递增计数器或向集合添加元素是可交换的操作。这是Riak 2.0数据类型背后的思想,它可以防止复制副本丢失更新。当不同的客户端同时更新一个值时,Riak自动将更新合并在一起,以免丢失更新【39】。
另一方面,最后写入胜利(LWW)的冲突解决方法很容易丢失更新,如“最后写入胜利(丢弃并发写入)”中所述。不幸的是,LWW是许多复制数据库中的默认方案。
写入偏斜与幻读
前面的章节中,我们看到了脏写和丢失更新,当不同的事务并发地尝试写入相同的对象时,会出现这两种竞争条件。为了避免数据损坏,这些竞争条件需要被阻止——既可以由数据库自动执行,也可以通过锁和原子写操作这类手动安全措施来防止。
但是,并发写入间可能发生的竞争条件还没有完。在本节中,我们将看到一些更微妙的冲突例子。
首先,想象一下这个例子:你正在为医院写一个医生轮班管理程序。医院通常会同时要求几位医生待命,但底线是至少有一位医生在待命。医生可以放弃他们的班次(例如,如果他们自己生病了),只要至少有一个同事在这一班中继续工作【40,41】。
现在想象一下,Alice和Bob是两位值班医生。两人都感到不适,所以他们都决定请假。不幸的是,他们恰好在同一时间点击按钮下班。图7-8说明了接下来的事情。
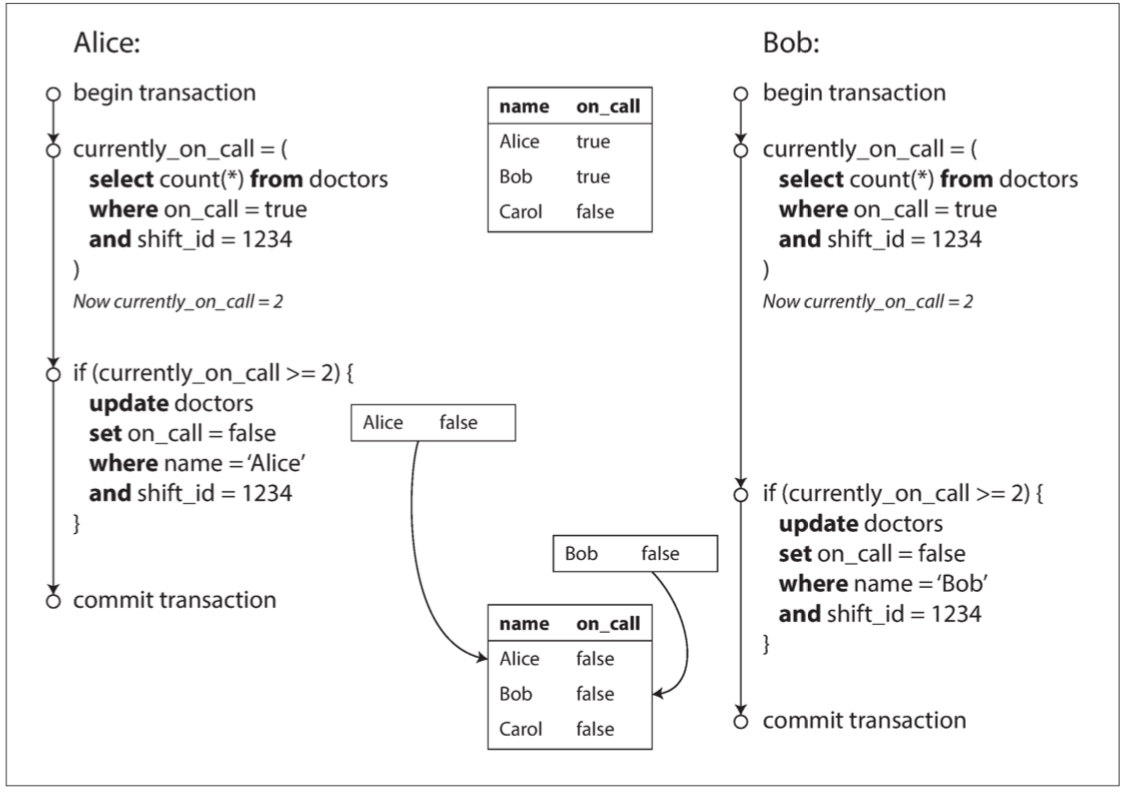
图7-8 写入偏差导致应用程序错误的示例
在两个事务中,应用首先检查是否有两个或以上的医生正在值班;如果是的话,它就假定一名医生可以安全地休班。由于数据库使用快照隔离,两次检查都返回 2 ,所以两个事务都进入下一个阶段。Alice更新自己的记录休班了,而Bob也做了一样的事情。两个事务都成功提交了,现在没有医生值班了。违反了至少有一名医生在值班的要求。
写偏差的特征
这种异常称为写偏差【28】。它既不是脏写,也不是丢失更新,因为这两个事务正在更新两个不同的对象(Alice和Bob各自的待命记录)。在这里发生的冲突并不是那么明显,但是这显然是一个竞争条件:如果两个事务一个接一个地运行,那么第二个医生就不能歇班了。异常行为只有在事务并发进行时才有可能。
可以将写入偏差视为丢失更新问题的一般化。如果两个事务读取相同的对象,然后更新其中一些对象(不同的事务可能更新不同的对象),则可能发生写入偏差。在多个事务更新同一个对象的特殊情况下,就会发生脏写或丢失更新(取决于时序)。
我们已经看到,有各种不同的方法来防止丢失的更新。但对于写偏差,我们的选择更受限制:
- 由于涉及多个对象,单对象的原子操作不起作用。
- 不幸的是,在一些快照隔离的实现中,自动检测丢失更新对此并没有帮助。在PostgreSQL的可重复读,MySQL/InnoDB的可重复读,Oracle可串行化或SQL Server的快照隔离级别中,都不会自动检测写入偏差【23】。自动防止写入偏差需要真正的可串行化隔离(请参阅“可串行化”)。
- 某些数据库允许配置约束,然后由数据库强制执行(例如,唯一性,外键约束或特定值限制)。但是为了指定至少有一名医生必须在线,需要一个涉及多个对象的约束。大多数数据库没有内置对这种约束的支持,但是你可以使用触发器,或者物化视图来实现它们,这取决于不同的数据库【42】。
- 如果无法使用可串行化的隔离级别,则此情况下的次优选项可能是显式锁定事务所依赖的行。在例子中,你可以写下如下的代码:
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = TRUE
AND shift_id = 1234 FOR UPDATE;
UPDATE doctors
SET on_call = FALSE
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;- 和以前一样,
FOR UPDATE告诉数据库锁定返回的所有行以用于更新。
写偏差的更多例子
写偏差乍看像是一个深奥的问题,但一旦意识到这一点,很容易会注意到更多可能的情况。以下是一些例子:
会议室预订系统
比如你想要规定不能在同一时间对同一个会议室进行多次的预订【43】。当有人想要预订时,首先检查是否存在相互冲突的预订(即预订时间范围重叠的同一房间),如果没有找到,则创建会议(请参阅示例7-2)ix。
ix. 在PostgreSQL中,您可以使用范围类型优雅地执行此操作,但在其他数据库中并未得到广泛支持。 ↩
例7-2 会议室预订系统试图避免重复预订(在快照隔离下不安全)
BEGIN TRANSACTION;
-- 检查所有现存的与12:00~13:00重叠的预定
SELECT COUNT(*) FROM bookings
WHERE room_id = 123 AND
end_time > '2015-01-01 12:00' AND start_time < '2015-01-01 13:00';
-- 如果之前的查询返回0
INSERT INTO bookings(room_id, start_time, end_time, user_id)
VALUES (123, '2015-01-01 12:00', '2015-01-01 13:00', 666);
COMMIT;不幸的是,快照隔离并不能防止另一个用户同时插入冲突的会议。为了确保不会遇到调度冲突,你又需要可串行化的隔离级别了。
多人游戏
在例7-1中,我们使用一个锁来防止丢失更新(也就是确保两个玩家不能同时移动同一个棋子)。但是锁定并不妨碍玩家将两个不同的棋子移动到棋盘上的相同位置,或者采取其他违反游戏规则的行为。按照您正在执行的规则类型,也许可以使用唯一约束(unique constraint),否则您很容易发生写入偏差。
抢注用户名
在每个用户拥有唯一用户名的网站上,两个用户可能会尝试同时创建具有相同用户名的帐户。可以在事务检查名称是否被抢占,如果没有则使用该名称创建账户。但是像在前面的例子中那样,在快照隔离下这是不安全的。幸运的是,唯一约束是一个简单的解决办法(第二个事务在提交时会因为违反用户名唯一约束而被中止)。
防止双重开支
允许用户花钱或积分的服务,需要检查用户的支付数额不超过其余额。可以通过在用户的帐户中插入一个试探性的消费项目来实现这一点,列出帐户中的所有项目,并检查总和是否为正值【44】。有了写入偏差,可能会发生两个支出项目同时插入,一起导致余额变为负值,但这两个事务都不会注意到另一个。
导致写入偏差的幻读
所有这些例子都遵循类似的模式:
一个
SELECT查询找出符合条件的行,并检查是否符合一些要求。(例如:至少有两名医生在值班;不存在对该会议室同一时段的预定;棋盘上的位置没有被其他棋子占据;用户名还没有被抢注;账户里还有足够余额)按照第一个查询的结果,应用代码决定是否继续。(可能会继续操作,也可能中止并报错)
如果应用决定继续操作,就执行写入(插入、更新或删除),并提交事务。
这个写入的效果改变了步骤2 中的先决条件。换句话说,如果在提交写入后,重复执行一次步骤1 的SELECT查询,将会得到不同的结果。因为写入改变了符合搜索条件的行集(现在少了一个医生值班,那时候的会议室现在已经被预订了,棋盘上的这个位置已经被占据了,用户名已经被抢注,账户余额不够了)。
这些步骤可能以不同的顺序发生。例如可以首先进行写入,然后进行SELECT查询,最后根据查询结果决定是放弃还是提交。
在医生值班的例子中,在步骤3中修改的行,是步骤1中返回的行之一,所以我们可以通过锁定步骤1 中的行(SELECT FOR UPDATE)来使事务安全并避免写入偏差。但是其他四个例子是不同的:它们检查是否不存在某些满足条件的行,写入会添加一个匹配相同条件的行。如果步骤1中的查询没有返回任何行,则SELECT FOR UPDATE锁不了任何东西。
这种效应:一个事务中的写入改变另一个事务的搜索查询的结果,被称为幻读【3】。快照隔离避免了只读查询中幻读,但是在像我们讨论的例子那样的读写事务中,幻读会导致特别棘手的写入偏差情况。
物化冲突
如果幻读的问题是没有对象可以加锁,也许可以人为地在数据库中引入一个锁对象?
例如,在会议室预订的场景中,可以想象创建一个关于时间槽和房间的表。此表中的每一行对应于特定时间段(例如15分钟)的特定房间。可以提前插入房间和时间的所有可能组合行(例如接下来的六个月)。
现在,要创建预订的事务可以锁定(SELECT FOR UPDATE)表中与所需房间和时间段对应的行。在获得锁定之后,它可以检查重叠的预订并像以前一样插入新的预订。请注意,这个表并不是用来存储预订相关的信息——它完全就是一组锁,用于防止同时修改同一房间和时间范围内的预订。
这种方法被称为物化冲突(materializing conflicts),因为它将幻读变为数据库中一组具体行上的锁冲突【11】。不幸的是,弄清楚如何物化冲突可能很难,也很容易出错,而让并发控制机制泄漏到应用数据模型是很丑陋的做法。出于这些原因,如果没有其他办法可以实现,物化冲突应被视为最后的手段。在大多数情况下。可串行化(Serializable) 的隔离级别是更可取的。
可串行化
在本章中,已经看到了几个易于出现竞争条件的事务例子。读已提交和快照隔离级别会阻止某些竞争条件,但不会阻止另一些。我们遇到了一些特别棘手的例子,写入偏差和幻读。这是一个可悲的情况:
- 隔离级别难以理解,并且在不同的数据库中实现的不一致(例如,“可重复读”的含义天差地别)。
- 光检查应用代码很难判断在特定的隔离级别运行是否安全。 特别是在大型应用程序中,您可能并不知道并发发生的所有事情。
- 没有检测竞争条件的好工具。原则上来说,静态分析可能会有帮助【26】,但研究中的技术还没法实际应用。并发问题的测试是很难的,因为它们通常是非确定性的 —— 只有在倒霉的时序下才会出现问题。
这不是一个新问题,从20世纪70年代以来就一直是这样了,当时首先引入了较弱的隔离级别【2】。一直以来,研究人员的答案都很简单:使用可串行化(serializable) 的隔离级别!
可串行化(Serializability) 隔离通常被认为是最强的隔离级别。它保证即使事务可以并行执行,最终的结果也是一样的,就好像它们没有任何并发性,连续挨个执行一样。因此数据库保证,如果事务在单独运行时正常运行,则它们在并发运行时继续保持正确 —— 换句话说,数据库可以防止所有可能的竞争条件。
但如果可串行化隔离级别比弱隔离级别的烂摊子要好得多,那为什么没有人见人爱?为了回答这个问题,我们需要看看实现可串行化的选项,以及它们如何执行。目前大多数提供可串行化的数据库都使用了三种技术之一,本章的剩余部分将会介绍这些技术:
- 字面意义上地串行顺序执行事务(请参阅“真的串行执行”)
- 两阶段锁定(2PL, two-phase locking),几十年来唯一可行的选择(请参阅“两阶段锁定”)
- 乐观并发控制技术,例如可串行化快照隔离(serializable snapshot isolation)(请参阅“可串行化快照隔离”)
现在将主要在单节点数据库的背景下讨论这些技术;在第九章中,我们将研究如何将它们推广到涉及分布式系统中多个节点的事务。
真的串行执行
避免并发问题的最简单方法就是完全不要并发:在单个线程上按顺序一次只执行一个事务。这样做就完全绕开了检测/防止事务间冲突的问题,由此产生的隔离,正是可串行化的定义。
尽管这似乎是一个明显的主意,但数据库设计人员只是在2007年左右才决定,单线程循环执行事务是可行的【45】。如果多线程并发在过去的30年中被认为是获得良好性能的关键所在,那么究竟是什么改变致使单线程执行变为可能呢?
两个进展引发了这个反思:
- RAM足够便宜了,许多场景现在都可以将完整的活跃数据集保存在内存中。(请参阅“在内存中存储一切”)。当事务需要访问的所有数据都在内存中时,事务处理的执行速度要比等待数据从磁盘加载时快得多。
- 数据库设计人员意识到OLTP事务通常很短,而且只进行少量的读写操作(请参阅“事务处理还是分析?”)。相比之下,长时间运行的分析查询通常是只读的,因此它们可以在串行执行循环之外的一致快照(使用快照隔离)上运行。
串行执行事务的方法在VoltDB/H-Store,Redis和Datomic中实现【46,47,48】。设计用于单线程执行的系统有时可以比支持并发的系统更好,因为它可以避免锁的协调开销。但是其吞吐量仅限于单个CPU核的吞吐量。为了充分利用单一线程,需要与传统形式的事务不同的结构。
在存储过程中封装事务
在数据库的早期阶段,意图是数据库事务可以包含整个用户活动流程。例如,预订机票是一个多阶段的过程(搜索路线,票价和可用座位,决定行程,在每段行程的航班上订座,输入乘客信息,付款)。数据库设计者认为,如果整个过程是一个事务,那么它就可以被原子化地执行。
不幸的是,人类做出决定和回应的速度非常缓慢。如果数据库事务需要等待来自用户的输入,则数据库需要支持潜在的大量并发事务,其中大部分是空闲的。大多数数据库不能高效完成这项工作,因此几乎所有的OLTP应用程序都避免在事务中等待交互式的用户输入,以此来保持事务的简短。在Web上,这意味着事务在同一个HTTP请求中被提交——一个事务不会跨越多个请求。一个新的HTTP请求开始一个新的事务。
即使已经将人类从关键路径中排除,事务仍然以交互式的客户端/服务器风格执行,一次一个语句。应用程序进行查询,读取结果,可能根据第一个查询的结果进行另一个查询,依此类推。查询和结果在应用程序代码(在一台机器上运行)和数据库服务器(在另一台机器上)之间来回发送。
在这种交互式的事务方式中,应用程序和数据库之间的网络通信耗费了大量的时间。如果不允许在数据库中进行并发处理,且一次只处理一个事务,则吞吐量将会非常糟糕,因为数据库大部分的时间都花费在等待应用程序发出当前事务的下一个查询。在这种数据库中,为了获得合理的性能,需要同时处理多个事务。
出于这个原因,具有单线程串行事务处理的系统不允许交互式的多语句事务。取而代之,应用程序必须提前将整个事务代码作为存储过程提交给数据库。这些方法之间的差异如图7-9 所示。如果事务所需的所有数据都在内存中,则存储过程可以非常快地执行,而不用等待任何网络或磁盘I/O。
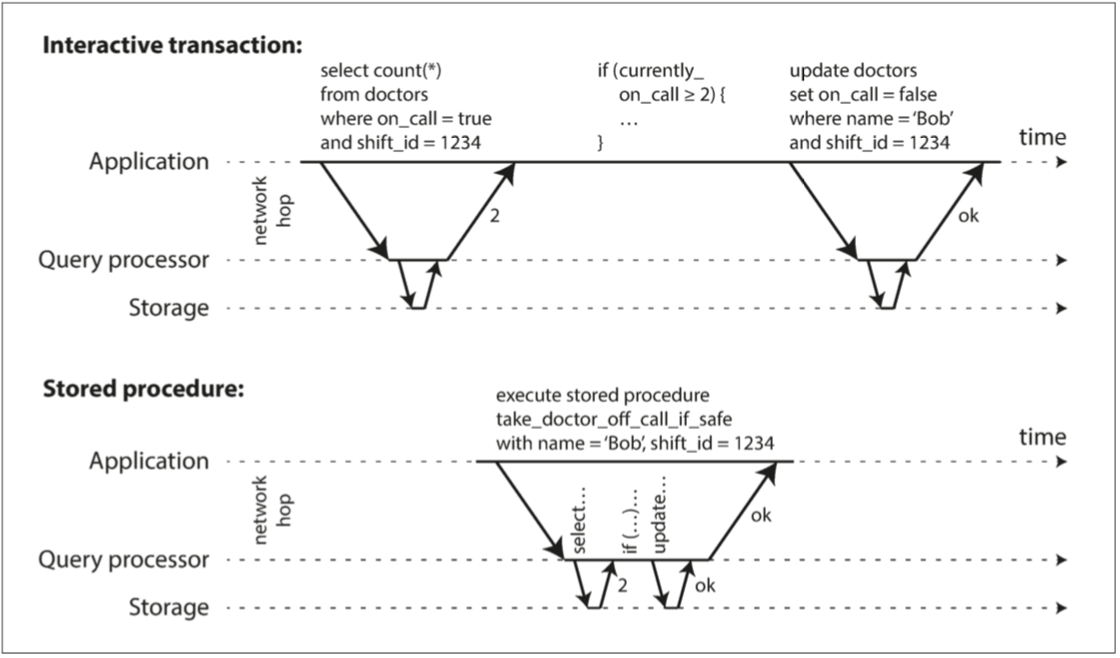
图7-9 交互式事务和存储过程之间的区别(使用图7-8的示例事务)
存储过程的优点和缺点
存储过程在关系型数据库中已经存在了一段时间了,自1999年以来它们一直是SQL标准(SQL/PSM)的一部分。出于各种原因,它们的名声有点不太好:
- 每个数据库厂商都有自己的存储过程语言(Oracle有PL/SQL,SQL Server有T-SQL,PostgreSQL有PL/pgSQL等)。这些语言并没有跟上通用编程语言的发展,所以从今天的角度来看,它们看起来相当丑陋和陈旧,而且缺乏大多数编程语言中能找到的库的生态系统。
- 与应用服务器相比,在数据库中运行的代码管理困难,调试困难,版本控制和部署起来也更为尴尬,更难测试,更难和用于监控的指标收集系统相集成。
- 数据库通常比应用服务器对性能敏感的多,因为单个数据库实例通常由许多应用服务器共享。数据库中一个写得不好的存储过程(例如,占用大量内存或CPU时间)会比在应用服务器中相同的代码造成更多的麻烦。
但是这些问题都是可以克服的。现代的存储过程实现放弃了PL/SQL,而是使用现有的通用编程语言:VoltDB使用Java或Groovy,Datomic使用Java或Clojure,而Redis使用Lua。
存储过程与内存存储,使得在单个线程上执行所有事务变得可行。由于不需要等待I/O,且避免了并发控制机制的开销,它们可以在单个线程上实现相当好的吞吐量。
VoltDB还使用存储过程进行复制:但不是将事务的写入结果从一个节点复制到另一个节点,而是在每个节点上执行相同的存储过程。因此VoltDB要求存储过程是确定性的(在不同的节点上运行时,它们必须产生相同的结果)。举个例子,如果事务需要使用当前的日期和时间,则必须通过特殊的确定性API来实现。
分区
顺序执行所有事务使并发控制简单多了,但数据库的事务吞吐量被限制为单机单核的速度。只读事务可以使用快照隔离在其它地方执行,但对于写入吞吐量较高的应用,单线程事务处理器可能成为一个严重的瓶颈。
为了伸缩至多个CPU核心和多个节点,可以对数据进行分区(请参阅第六章),在VoltDB中支持这样做。如果你可以找到一种对数据集进行分区的方法,以便每个事务只需要在单个分区中读写数据,那么每个分区就可以拥有自己独立运行的事务处理线程。在这种情况下可以为每个分区指派一个独立的CPU核,事务吞吐量就可以与CPU核数保持线性伸缩【47】。
但是,对于需要访问多个分区的任何事务,数据库必须在触及的所有分区之间协调事务。存储过程需要跨越所有分区锁定执行,以确保整个系统的可串行性。
由于跨分区事务具有额外的协调开销,所以它们比单分区事务慢得多。 VoltDB报告的吞吐量大约是每秒1000个跨分区写入,比单分区吞吐量低几个数量级,并且不能通过增加更多的机器来增加【49】。
事务是否可以是划分至单个分区很大程度上取决于应用数据的结构。简单的键值数据通常可以非常容易地进行分区,但是具有多个二级索引的数据可能需要大量的跨分区协调(请参阅“分区与次级索引”)。
串行执行小结
在特定约束条件下,真的串行执行事务,已经成为一种实现可串行化隔离等级的可行办法。
- 每个事务都必须小而快,只要有一个缓慢的事务,就会拖慢所有事务处理。
- 仅限于活跃数据集可以放入内存的情况。很少访问的数据可能会被移动到磁盘,但如果需要在单线程执行的事务中访问,系统就会变得非常慢x。
- 写入吞吐量必须低到能在单个CPU核上处理,如若不然,事务需要能划分至单个分区,且不需要跨分区协调。
- 跨分区事务是可能的,但是它们能被使用的程度有很大的限制。
x. 如果事务需要访问不在内存中的数据,最好的解决方案可能是中止事务,异步地将数据提取到内存中,同时继续处理其他事务,然后在数据加载完毕时重新启动事务。这种方法被称为反缓存(anti-caching),正如前面在“在内存中存储一切”中所述。 ↩
两阶段锁定
大约30年来,在数据库中只有一种广泛使用的串行化算法:两阶段锁定(2PL,two-phase locking) xi
xi. 有时也称为严格两阶段锁定(SS2PL, strong strict two-phase locking),以便和其他2PL变体区分。 ↩
2PL不是2PC
请注意,虽然两阶段锁定(2PL)听起来非常类似于两阶段提交(2PC),但它们是完全不同的东西。我们将在第九章讨论2PC。
之前我们看到锁通常用于防止脏写(请参阅“没有脏写”一节):如果两个事务同时尝试写入同一个对象,则锁可确保第二个写入必须等到第一个写入完成事务(中止或提交),然后才能继续。
两阶段锁定类似,但是锁的要求更强得多。只要没有写入,就允许多个事务同时读取同一个对象。但对象只要有写入(修改或删除),就需要独占访问(exclusive access) 权限:
- 如果事务A读取了一个对象,并且事务B想要写入该对象,那么B必须等到A提交或中止才能继续。 (这确保B不能在A底下意外地改变对象。)
- 如果事务A写入了一个对象,并且事务B想要读取该对象,则B必须等到A提交或中止才能继续。 (像图7-1那样读取旧版本的对象在2PL下是不可接受的。)
在2PL中,写入不仅会阻塞其他写入,也会阻塞读,反之亦然。快照隔离使得读不阻塞写,写也不阻塞读(请参阅“实现快照隔离”),这是2PL和快照隔离之间的关键区别。另一方面,因为2PL提供了可串行化的性质,它可以防止早先讨论的所有竞争条件,包括丢失更新和写入偏差。
实现两阶段锁
2PL用于MySQL(InnoDB)和SQL Server中的可串行化隔离级别,以及DB2中的可重复读隔离级别【23,36】。
读与写的阻塞是通过为数据库中每个对象添加锁来实现的。锁可以处于共享模式(shared mode) 或独占模式(exclusive mode)。锁使用如下:
- 若事务要读取对象,则须先以共享模式获取锁。允许多个事务同时持有共享锁。但如果另一个事务已经在对象上持有排它锁,则这些事务必须等待。
- 若事务要写入一个对象,它必须首先以独占模式获取该锁。没有其他事务可以同时持有锁(无论是共享模式还是独占模式),所以如果对象上存在任何锁,该事务必须等待。
- 如果事务先读取再写入对象,则它可能会将其共享锁升级为独占锁。升级锁的工作与直接获得排他锁相同。
- 事务获得锁之后,必须继续持有锁直到事务结束(提交或中止)。这就是“两阶段”这个名字的来源:第一阶段(当事务正在执行时)获取锁,第二阶段(在事务结束时)释放所有的锁。
由于使用了这么多的锁,因此很可能会发生:事务A等待事务B释放它的锁,反之亦然。这种情况叫做死锁(Deadlock)。数据库会自动检测事务之间的死锁,并中止其中一个,以便另一个继续执行。被中止的事务需要由应用程序重试。
两阶段锁定的性能
两阶段锁定的巨大缺点,以及70年代以来没有被所有人使用的原因,是其性能问题。两阶段锁定下的事务吞吐量与查询响应时间要比弱隔离级别下要差得多。
这一部分是由于获取和释放所有这些锁的开销,但更重要的是由于并发性的降低。按照设计,如果两个并发事务试图做任何可能导致竞争条件的事情,那么必须等待另一个完成。
传统的关系数据库不限制事务的持续时间,因为它们是为等待人类输入的交互式应用而设计的。因此,当一个事务需要等待另一个事务时,等待的时长并没有限制。即使你保证所有的事务都很短,如果有多个事务想要访问同一个对象,那么可能会形成一个队列,所以事务可能需要等待几个其他事务才能完成。
因此,运行2PL的数据库可能具有相当不稳定的延迟,如果在工作负载中存在争用,那么可能高百分位点处的响应会非常的慢(请参阅“描述性能”)。可能只需要一个缓慢的事务,或者一个访问大量数据并获取许多锁的事务,就能把系统的其他部分拖慢,甚至迫使系统停机。当需要稳健的操作时,这种不稳定性是有问题的。
基于锁实现的读已提交隔离级别可能发生死锁,但在基于2PL实现的可串行化隔离级别中,它们会出现的频繁的多(取决于事务的访问模式)。这可能是一个额外的性能问题:当事务由于死锁而被中止并被重试时,它需要从头重做它的工作。如果死锁很频繁,这可能意味着巨大的浪费。
谓词锁
在前面关于锁的描述中,我们掩盖了一个微妙而重要的细节。在“导致写入偏差的幻读”中,我们讨论了幻读(phantoms) 的问题。即一个事务改变另一个事务的搜索查询的结果。具有可串行化隔离级别的数据库必须防止幻读。
在会议室预订的例子中,这意味着如果一个事务在某个时间窗口内搜索了一个房间的现有预订(见例7-2),则另一个事务不能同时插入或更新同一时间窗口与同一房间的另一个预订 (可以同时插入其他房间的预订,或在不影响另一个预定的条件下预定同一房间的其他时间段)。
如何实现这一点?从概念上讲,我们需要一个谓词锁(predicate lock)【3】。它类似于前面描述的共享/排它锁,但不属于特定的对象(例如,表中的一行),它属于所有符合某些搜索条件的对象,如:
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';谓词锁限制访问,如下所示:
- 如果事务A想要读取匹配某些条件的对象,就像在这个
SELECT查询中那样,它必须获取查询条件上的共享谓词锁(shared-mode predicate lock)。如果另一个事务B持有任何满足这一查询条件对象的排它锁,那么A必须等到B释放它的锁之后才允许进行查询。 - 如果事务A想要插入,更新或删除任何对象,则必须首先检查旧值或新值是否与任何现有的谓词锁匹配。如果事务B持有匹配的谓词锁,那么A必须等到B已经提交或中止后才能继续。
这里的关键思想是,谓词锁甚至适用于数据库中尚不存在,但将来可能会添加的对象(幻象)。如果两阶段锁定包含谓词锁,则数据库将阻止所有形式的写入偏差和其他竞争条件,因此其隔离实现了可串行化。
索引范围锁
不幸的是谓词锁性能不佳:如果活跃事务持有很多锁,检查匹配的锁会非常耗时。因此,大多数使用2PL的数据库实际上实现了索引范围锁(也称为间隙锁(next-key locking)),这是一个简化的近似版谓词锁【41,50】。
通过使谓词匹配到一个更大的集合来简化谓词锁是安全的。例如,如果你有在中午和下午1点之间预订123号房间的谓词锁,则锁定123号房间的所有时间段,或者锁定12:00~13:00时间段的所有房间(不只是123号房间)是一个安全的近似,因为任何满足原始谓词的写入也一定会满足这种更松散的近似。
在房间预订数据库中,您可能会在room_id列上有一个索引,并且/或者在start_time 和 end_time上有索引(否则前面的查询在大型数据库上的速度会非常慢):
- 假设您的索引位于
room_id上,并且数据库使用此索引查找123号房间的现有预订。现在数据库可以简单地将共享锁附加到这个索引项上,指示事务已搜索123号房间用于预订。 - 或者,如果数据库使用基于时间的索引来查找现有预订,那么它可以将共享锁附加到该索引中的一系列值,指示事务已经将12:00~13:00时间段标记为用于预定。
无论哪种方式,搜索条件的近似值都附加到其中一个索引上。现在,如果另一个事务想要插入,更新或删除同一个房间和/或重叠时间段的预订,则它将不得不更新索引的相同部分。在这样做的过程中,它会遇到共享锁,它将被迫等到锁被释放。
这种方法能够有效防止幻读和写入偏差。索引范围锁并不像谓词锁那样精确(它们可能会锁定更大范围的对象,而不是维持可串行化所必需的范围),但是由于它们的开销较低,所以是一个很好的折衷。
如果没有可以挂载间隙锁的索引,数据库可以退化到使用整个表上的共享锁。这对性能不利,因为它会阻止所有其他事务写入表格,但这是一个安全的回退位置。
可串行化快照隔离
本章描绘了数据库中并发控制的黯淡画面。一方面,我们实现了性能不好(2PL)或者伸缩性不好(串行执行)的可串行化隔离级别。另一方面,我们有性能良好的弱隔离级别,但容易出现各种竞争条件(丢失更新,写入偏差,幻读等)。串行化的隔离级别和高性能是从根本上相互矛盾的吗?
也许不是:一个称为可串行化快照隔离(SSI, serializable snapshot isolation) 的算法是非常有前途的。它提供了完整的可串行化隔离级别,但与快照隔离相比只有很小的性能损失。 SSI是相当新的:它在2008年首次被描述【40】,并且是Michael Cahill的博士论文【51】的主题。
今天,SSI既用于单节点数据库(PostgreSQL9.1 以后的可串行化隔离级别)和分布式数据库(FoundationDB使用类似的算法)。由于SSI与其他并发控制机制相比还很年轻,还处于在实践中证明自己表现的阶段。但它有可能因为足够快而在未来成为新的默认选项。
悲观与乐观的并发控制
两阶段锁是一种所谓的悲观并发控制机制(pessimistic) :它是基于这样的原则:如果有事情可能出错(如另一个事务所持有的锁所表示的),最好等到情况安全后再做任何事情。这就像互斥,用于保护多线程编程中的数据结构。
从某种意义上说,串行执行可以称为悲观到了极致:在事务持续期间,每个事务对整个数据库(或数据库的一个分区)具有排它锁,作为对悲观的补偿,我们让每笔事务执行得非常快,所以只需要短时间持有“锁”。
相比之下,串行化快照隔离是一种乐观(optimistic) 的并发控制技术。在这种情况下,乐观意味着,如果存在潜在的危险也不阻止事务,而是继续执行事务,希望一切都会好起来。当一个事务想要提交时,数据库检查是否有什么不好的事情发生(即隔离是否被违反);如果是的话,事务将被中止,并且必须重试。只有可串行化的事务才被允许提交。
乐观并发控制是一个古老的想法【52】,其优点和缺点已经争论了很长时间【53】。如果存在很多争用(contention)(很多事务试图访问相同的对象),则表现不佳,因为这会导致很大一部分事务需要中止。如果系统已经接近最大吞吐量,来自重试事务的额外负载可能会使性能变差。
但是,如果有足够的备用容量,并且事务之间的争用不是太高,乐观的并发控制技术往往比悲观的要好。可交换的原子操作可以减少争用:例如,如果多个事务同时要增加一个计数器,那么应用增量的顺序(只要计数器不在同一个事务中读取)就无关紧要了,所以并发增量可以全部应用且无需冲突。
顾名思义,SSI基于快照隔离——也就是说,事务中的所有读取都是来自数据库的一致性快照(请参阅“快照隔离和可重复读取”)。与早期的乐观并发控制技术相比这是主要的区别。在快照隔离的基础上,SSI添加了一种算法来检测写入之间的串行化冲突,并确定要中止哪些事务。
基于过时前提的决策
先前讨论了快照隔离中的写入偏差(请参阅“写入偏斜与幻读”)时,我们观察到一个循环模式:事务从数据库读取一些数据,检查查询的结果,并根据它看到的结果决定采取一些操作(写入数据库)。但是,在快照隔离的情况下,原始查询的结果在事务提交时可能不再是最新的,因为数据可能在同一时间被修改。
换句话说,事务基于一个前提(premise) 采取行动(事务开始时候的事实,例如:“目前有两名医生正在值班”)。之后当事务要提交时,原始数据可能已经改变——前提可能不再成立。
当应用程序进行查询时(例如,“当前有多少医生正在值班?”),数据库不知道应用逻辑如何使用该查询结果。在这种情况下为了安全,数据库需要假设任何对该结果集的变更都可能会使该事务中的写入变得无效。 换而言之,事务中的查询与写入可能存在因果依赖。为了提供可串行化的隔离级别,如果事务在过时的前提下执行操作,数据库必须能检测到这种情况,并中止事务。
数据库如何知道查询结果是否可能已经改变?有两种情况需要考虑:
- 检测对旧MVCC对象版本的读取(读之前存在未提交的写入)
- 检测影响先前读取的写入(读之后发生写入)
检测旧MVCC读取
回想一下,快照隔离通常是通过多版本并发控制(MVCC;见图7-10)来实现的。当一个事务从MVCC数据库中的一致快照读时,它将忽略取快照时尚未提交的任何其他事务所做的写入。在图7-10中,事务43 认为Alice的 on_call = true ,因为事务42(修改Alice的待命状态)未被提交。然而,在事务43想要提交时,事务42 已经提交。这意味着在读一致性快照时被忽略的写入已经生效,事务43 的前提不再为真。
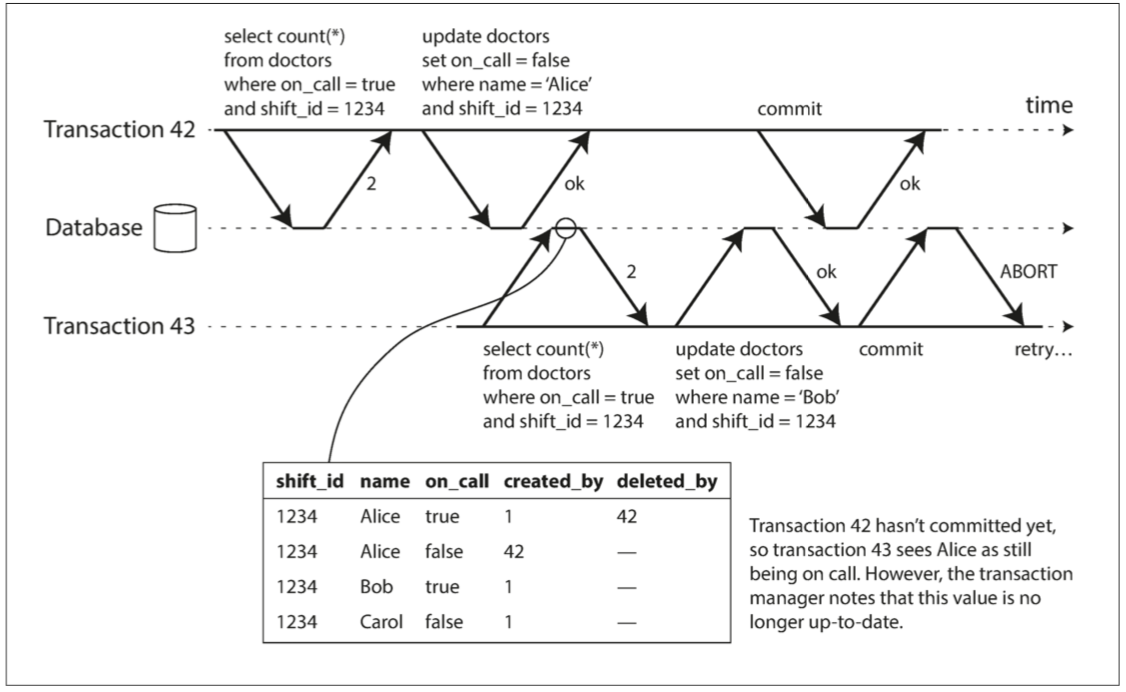
图7-10 检测事务何时从MVCC快照读取过时的值
为了防止这种异常,数据库需要跟踪一个事务由于MVCC可见性规则而忽略另一个事务的写入。当事务想要提交时,数据库检查是否有任何被忽略的写入现在已经被提交。如果是这样,事务必须中止。
为什么要等到提交?当检测到陈旧的读取时,为什么不立即中止事务43 ?因为如果事务43 是只读事务,则不需要中止,因为没有写入偏差的风险。当事务43 进行读取时,数据库还不知道事务是否要稍后执行写操作。此外,事务42 可能在事务43 被提交的时候中止或者可能仍然未被提交,因此读取可能终究不是陈旧的。通过避免不必要的中止,SSI 保留了快照隔离从一致快照中长时间读取的能力。
检测影响之前读取的写入
第二种情况要考虑的是另一个事务在读取数据之后修改数据。这种情况如图7-11所示。
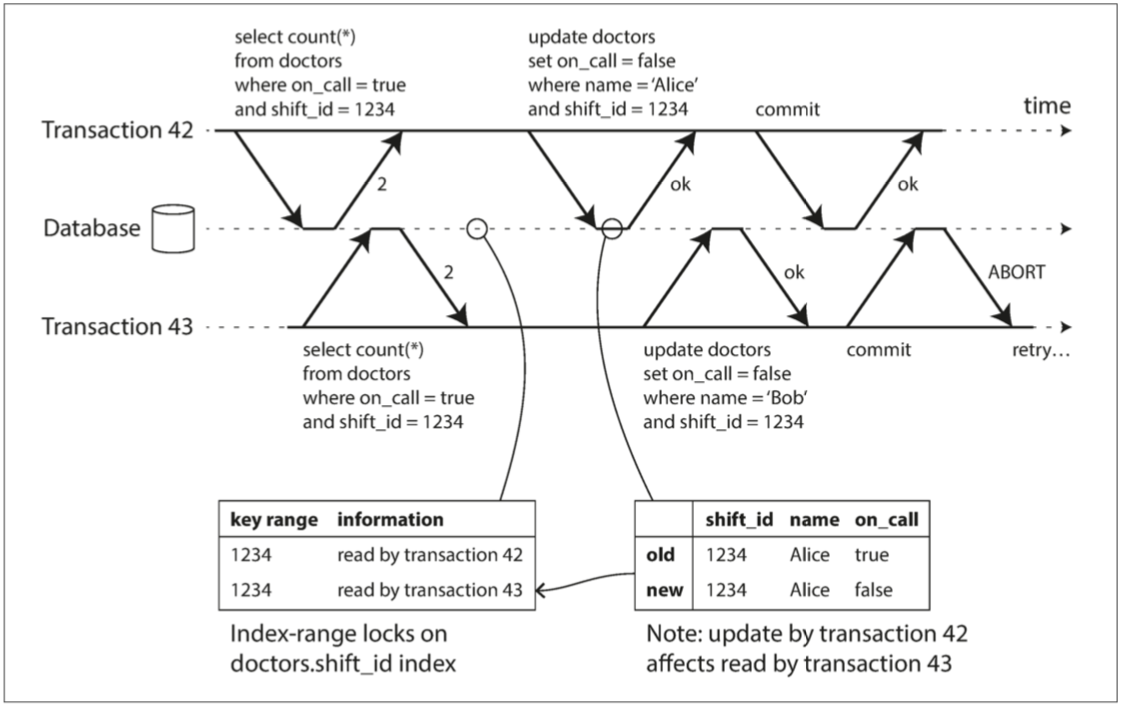
图7-11 在可串行化快照隔离中,检测一个事务何时修改另一个事务的读取。
在两阶段锁定的上下文中,我们讨论了索引范围锁(请参阅“索引范围锁”),它允许数据库锁定与某个搜索查询匹配的所有行的访问权,例如 WHERE shift_id = 1234。可以在这里使用类似的技术,除了SSI锁不会阻塞其他事务。
在图7-11中,事务42 和43 都在班次1234 查找值班医生。如果在shift_id上有索引,则数据库可以使用索引项1234 来记录事务42 和43 读取这个数据的事实。 (如果没有索引,这个信息可以在表级别进行跟踪)。这个信息只需要保留一段时间:在一个事务完成(提交或中止),并且所有的并发事务完成之后,数据库就可以忘记它读取的数据了。
当事务写入数据库时,它必须在索引中查找最近曾读取受影响数据的其他事务。这个过程类似于在受影响的键范围上获取写锁,但锁并不会阻塞事务指导其他读事务完成,而是像警戒线一样只是简单通知其他事务:你们读过的数据可能不是最新的啦。
在图7-11中,事务43 通知事务42 其先前读已过时,反之亦然。事务42首先提交并成功,尽管事务43 的写影响了42 ,但因为事务43 尚未提交,所以写入尚未生效。然而当事务43 想要提交时,来自事务42 的冲突写入已经被提交,所以事务43 必须中止。
可串行化快照隔离的性能
与往常一样,许多工程细节会影响算法的实际表现。例如一个权衡是跟踪事务的读取和写入的粒度(granularity)。如果数据库详细地跟踪每个事务的活动(细粒度),那么可以准确地确定哪些事务需要中止,但是簿记开销可能变得很显著。简略的跟踪速度更快(粗粒度),但可能会导致更多不必要的事务中止。
在某些情况下,事务可以读取被另一个事务覆盖的信息:这取决于发生了什么,有时可以证明执行结果无论如何都是可串行化的。 PostgreSQL使用这个理论来减少不必要的中止次数【11,41】。
与两阶段锁定相比,可串行化快照隔离的最大优点是一个事务不需要阻塞等待另一个事务所持有的锁。就像在快照隔离下一样,写不会阻塞读,反之亦然。这种设计原则使得查询延迟更可预测,变量更少。特别是,只读查询可以运行在一致快照上,而不需要任何锁定,这对于读取繁重的工作负载非常有吸引力。
与串行执行相比,可串行化快照隔离并不局限于单个CPU核的吞吐量:FoundationDB将检测到的串行化冲突分布在多台机器上,允许扩展到很高的吞吐量。即使数据可能跨多台机器进行分区,事务也可以在保证可串行化隔离等级的同时读写多个分区中的数据【54】。
中止率显著影响SSI的整体表现。例如,长时间读取和写入数据的事务很可能会发生冲突并中止,因此SSI要求同时读写的事务尽量短(只读的长事务可能没问题)。对于慢事务,SSI可能比两阶段锁定或串行执行更不敏感。
本章小结
事务是一个抽象层,允许应用程序假装某些并发问题和某些类型的硬件和软件故障不存在。各式各样的错误被简化为一种简单情况:事务中止(transaction abort),而应用需要的仅仅是重试。
在本章中介绍了很多问题,事务有助于防止这些问题发生。并非所有应用都易受此类问题影响:具有非常简单访问模式的应用(例如每次读写单条记录)可能无需事务管理。但是对于更复杂的访问模式,事务可以大大减少需要考虑的潜在错误情景数量。
如果没有事务处理,各种错误情况(进程崩溃,网络中断,停电,磁盘已满,意外并发等)意味着数据可能以各种方式变得不一致。例如,非规范化的数据可能很容易与源数据不同步。如果没有事务处理,就很难推断复杂的交互访问可能对数据库造成的影响。
本章深入讨论了并发控制的话题。我们讨论了几个广泛使用的隔离级别,特别是读已提交,快照隔离(有时称为可重复读)和可串行化。并通过研究竞争条件的各种例子,来描述这些隔离等级:
脏读
一个客户端读取到另一个客户端尚未提交的写入。读已提交或更强的隔离级别可以防止脏读。
脏写
一个客户端覆盖写入了另一个客户端尚未提交的写入。几乎所有的事务实现都可以防止脏写。
读取偏差(不可重复读)
在同一个事务中,客户端在不同的时间点会看见数据库的不同状态。快照隔离经常用于解决这个问题,它允许事务从一个特定时间点的一致性快照中读取数据。快照隔离通常使用多版本并发控制(MVCC) 来实现。
更新丢失
两个客户端同时执行读取-修改-写入序列。其中一个写操作,在没有合并另一个写入变更情况下,直接覆盖了另一个写操作的结果。所以导致数据丢失。快照隔离的一些实现可以自动防止这种异常,而另一些实现则需要手动锁定(SELECT FOR UPDATE)。
写偏差
一个事务读取一些东西,根据它所看到的值作出决定,并将该决定写入数据库。但是,写入时,该决定的前提不再是真实的。只有可串行化的隔离才能防止这种异常。
幻读
事务读取符合某些搜索条件的对象。另一个客户端进行写入,影响搜索结果。快照隔离可以防止直接的幻像读取,但是写入偏差上下文中的幻读需要特殊处理,例如索引范围锁定。
弱隔离级别可以防止其中一些异常情况,但要求你,也就是应用程序开发人员手动处理剩余那些(例如,使用显式锁定)。只有可串行化的隔离才能防范所有这些问题。我们讨论了实现可串行化事务的三种不同方法:
字面意义上的串行执行
如果每个事务的执行速度非常快,并且事务吞吐量足够低,足以在单个CPU核上处理,这是一个简单而有效的选择。
两阶段锁定
数十年来,两阶段锁定一直是实现可串行化的标准方式,但是许多应用出于性能问题的考虑避免使用它。
可串行化快照隔离(SSI)
一个相当新的算法,避免了先前方法的大部分缺点。它使用乐观的方法,允许事务执行而无需阻塞。当一个事务想要提交时,它会进行检查,如果执行不可串行化,事务就会被中止。
本章中的示例主要是在关系数据模型的上下文中。但是,正如在讨论中,无论使用哪种数据模型,如“多对象事务的需求”中所讨论的,事务都是有价值的数据库功能。
本章主要是在单机数据库的上下文中,探讨了各种想法和算法。分布式数据库中的事务,则引入了一系列新的困难挑战,我们将在接下来的两章中讨论。
参考文献
- Donald D. Chamberlin, Morton M. Astrahan, Michael W. Blasgen, et al.: “A History and Evaluation of System R,” Communications of the ACM, volume 24, number 10, pages 632–646, October 1981.
doi:10.1145/358769.358784 - Jim N. Gray, Raymond A. Lorie, Gianfranco R. Putzolu, and Irving L. Traiger: “Granularity of Locks and Degrees of Consistency in a Shared Data Base,” in Modelling in Data Base Management Systems: Proceedings of the IFIP Working Conference on Modelling in Data Base Management Systems, edited by G. M. Nijssen, pages 364–394, Elsevier/North Holland Publishing, 1976. Also in Readings in Database Systems, 4th edition, edited by Joseph M. Hellerstein and Michael Stonebraker, MIT Press, 2005. ISBN: 978-0-262-69314-1
- Kapali P. Eswaran, Jim N. Gray, Raymond A. Lorie, and Irving L. Traiger: “The Notions of Consistency and Predicate Locks in a Database System,” Communications of the ACM, volume 19, number 11, pages 624–633, November 1976.
- “ACID Transactions Are Incredibly Helpful,” FoundationDB, LLC, 2013.
- John D. Cook: “ACID Versus BASE for Database Transactions,” johndcook.com, July 6, 2009.
- Gavin Clarke: “NoSQL’s CAP Theorem Busters: We Don’t Drop ACID,” theregister.co.uk, November 22, 2012.
- Theo Härder and Andreas Reuter: “Principles of Transaction-Oriented Database Recovery,” ACM Computing Surveys, volume 15, number 4, pages 287–317, December 1983. doi:10.1145/289.291
- Peter Bailis, Alan Fekete, Ali Ghodsi, et al.: “HAT, not CAP: Towards Highly Available Transactions,”
at 14th USENIX Workshop on Hot Topics in Operating Systems (HotOS), May 2013. - Armando Fox, Steven D. Gribble, Yatin Chawathe, et al.: “Cluster-Based Scalable Network Services,” at
16th ACM Symposium on Operating Systems Principles (SOSP), October 1997. - Philip A. Bernstein, Vassos Hadzilacos, and Nathan Goodman: Concurrency Control and Recovery in Database Systems. Addison-Wesley, 1987. ISBN: 978-0-201-10715-9, available online at research.microsoft.com.
- Alan Fekete, Dimitrios Liarokapis, Elizabeth O’Neil, et al.: “Making Snapshot Isolation Serializable,” ACM Transactions on Database Systems, volume 30, number 2, pages 492–528, June 2005.
doi:10.1145/1071610.1071615 - Mai Zheng, Joseph Tucek, Feng Qin, and Mark Lillibridge: “Understanding the Robustness of SSDs Under Power Fault,” at 11th USENIX Conference on File and Storage Technologies (FAST), February 2013.
- Laurie Denness: “SSDs: A Gift and a Curse,” laur.ie, June 2, 2015.
- Adam Surak: “When Solid State Drives Are Not That Solid,” blog.algolia.com, June 15, 2015.
- Thanumalayan Sankaranarayana Pillai, Vijay Chidambaram, Ramnatthan Alagappan, et al.: “All File Systems Are Not Created Equal: On the Complexity of Crafting Crash-Consistent Applications,” at 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI),
October 2014. - Chris Siebenmann: “Unix’s File Durability Problem,” utcc.utoronto.ca, April 14, 2016.
- Lakshmi N. Bairavasundaram, Garth R. Goodson, Bianca Schroeder, et al.: “An Analysis of Data Corruption in the Storage Stack,” at 6th USENIX Conference on File and Storage Technologies (FAST), February 2008.
- Bianca Schroeder, Raghav Lagisetty, and Arif Merchant: “Flash Reliability in Production: The Expected and the Unexpected,” at 14th USENIX Conference on File and Storage Technologies (FAST), February 2016.
- Don Allison: “SSD Storage – Ignorance of Technology Is No Excuse,” blog.korelogic.com, March 24, 2015.
- Dave Scherer: “Those Are Not Transactions (Cassandra 2.0),” blog.foundationdb.com, September 6, 2013.
- Kyle Kingsbury: “Call Me Maybe: Cassandra,” aphyr.com, September 24, 2013.
- “ACID Support in Aerospike,” Aerospike, Inc., June 2014.
- Martin Kleppmann: “Hermitage: Testing the ‘I’ in ACID,” martin.kleppmann.com, November 25, 2014.
- Tristan D’Agosta: “BTC Stolen from Poloniex,” bitcointalk.org, March 4, 2014.
- bitcointhief2: “How I Stole Roughly 100 BTC from an Exchange and How I Could Have Stolen More!,” reddit.com, February 2, 2014.
- Sudhir Jorwekar, Alan Fekete, Krithi Ramamritham, and S. Sudarshan: “Automating the Detection of Snapshot Isolation Anomalies,” at 33rd International Conference on Very Large Data Bases (VLDB), September 2007.
- Michael Melanson: “Transactions: The Limits of Isolation,” michaelmelanson.net, March 20, 2014.
- Hal Berenson, Philip A. Bernstein, Jim N. Gray, et al.: “A Critique of ANSI SQL Isolation Levels,”
at ACM International Conference on Management of Data (SIGMOD), May 1995. - Atul Adya: “Weak Consistency: A Generalized Theory and Optimistic Implementations for Distributed Transactions,” PhD Thesis, Massachusetts Institute of Technology, March 1999.
- Peter Bailis, Aaron Davidson, Alan Fekete, et al.: “Highly Available Transactions: Virtues and Limitations (Extended Version),” at 40th International Conference on Very Large Data Bases (VLDB), September 2014.
- Bruce Momjian: “MVCC Unmasked,” momjian.us, July 2014.
- Annamalai Gurusami: “Repeatable Read Isolation Level in InnoDB – How Consistent Read View Works,” blogs.oracle.com, January 15, 2013.
- Nikita Prokopov: “Unofficial Guide to Datomic Internals,” tonsky.me, May 6, 2014.
- Baron Schwartz: “Immutability, MVCC, and Garbage Collection,” xaprb.com, December 28, 2013.
- J. Chris Anderson, Jan Lehnardt, and Noah Slater: CouchDB: The Definitive Guide. O’Reilly Media, 2010.
ISBN: 978-0-596-15589-6 - Rikdeb Mukherjee: “Isolation in DB2 (Repeatable Read, Read Stability, Cursor Stability, Uncommitted Read) with Examples,” mframes.blogspot.co.uk, July 4, 2013.
- Steve Hilker: “Cursor Stability (CS) – IBM DB2 Community,” toadworld.com, March 14, 2013.
- Nate Wiger: “An Atomic Rant,” nateware.com, February 18, 2010.
- Joel Jacobson: “Riak 2.0: Data Types,” blog.joeljacobson.com, March 23, 2014.
- Michael J. Cahill, Uwe Röhm, and Alan Fekete: “Serializable Isolation for Snapshot Databases,” at ACM International Conference on Management of Data (SIGMOD), June 2008. doi:10.1145/1376616.1376690
- Dan R. K. Ports and Kevin Grittner: “Serializable Snapshot Isolation in PostgreSQL,” at 38th International Conference on Very Large Databases (VLDB), August 2012.
- Tony Andrews: “Enforcing Complex Constraints in Oracle,” tonyandrews.blogspot.co.uk, October 15, 2004.
- Douglas B. Terry, Marvin M. Theimer, Karin Petersen, et al.: “Managing Update Conflicts in Bayou, a Weakly Connected Replicated Storage System,” at 15th ACM Symposium on Operating Systems Principles (SOSP), December 1995. doi:10.1145/224056.224070
- Gary Fredericks: “Postgres Serializability Bug,” github.com, September 2015.
- Michael Stonebraker, Samuel Madden, Daniel J. Abadi, et al.: “The End of an Architectural Era (It’s Time for a Complete Rewrite),” at 33rd International Conference on Very Large Data Bases (VLDB), September 2007.
- John Hugg: “H-Store/VoltDB Architecture vs. CEP Systems and Newer Streaming Architectures,” at Data @Scale Boston, November 2014.
- Robert Kallman, Hideaki Kimura, Jonathan Natkins, et al.: “H-Store: A High-Performance, Distributed Main Memory Transaction Processing System,” Proceedings of the VLDB Endowment, volume 1, number 2, pages 1496–1499, August 2008.
- Rich Hickey: “The Architecture of Datomic,” infoq.com, November 2, 2012.
- John Hugg: “Debunking Myths About the VoltDB In-Memory Database,” voltdb.com, May 12, 2014.
- Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton: “Architecture of a Database System,”
Foundations and Trends in Databases, volume 1, number 2, pages 141–259, November 2007.
doi:10.1561/1900000002 - Michael J. Cahill: “Serializable Isolation for Snapshot Databases,” PhD Thesis, University of Sydney, July 2009.
- D. Z. Badal: “Correctness of Concurrency Control and Implications in Distributed Databases,” at 3rd International IEEE Computer Software and Applications Conference (COMPSAC), November 1979.
- Rakesh Agrawal, Michael J. Carey, and Miron Livny: “Concurrency Control Performance Modeling: Alternatives and Implications,” ACM Transactions on Database Systems (TODS), volume 12, number 4, pages 609–654, December 1987. doi:10.1145/32204.32220
- Dave Rosenthal: “Databases at 14.4MHz,” blog.foundationdb.com, December 10, 2014.