存储层次是在计算机体系结构下存储系统层次结构的排列顺序。每一层于下一层相比都拥有较高的速度和较低延迟性,以及较小的容量。大部分现今的中央处理器的速度都非常的快。大部分程序工作量需要存储器访问。由于高速缓存的效率和存储器传输位于层次结构中的不同档次,所以实际上会限制处理的速度,导致中央处理器花费大量的时间等待存储器I/O完成工作。
到目前为止,在对系统的研究中,我们依赖于一个简单的计算机系统模型,CPU 执行指令,而存储器系统为 CPU 存放指令和数据。在简单模型中,存储器系统是一个线性的字节数组,而 CPU 能够在一个常数时间内访问每个存储器位置。虽然迄今为止这都是一个有效的模型,但是它没有反映现代系统实际工作的方式。
实际上,存储器系统(memory system)是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU 寄存器保存着最常用的数据。靠近 CPU 的小的、快速的高速缓存存储器(cache memory)作为一部分存储在相对慢速的主存储器(main memory)中数据和指令的缓冲区域。主存缓存存储在容量较大的、慢速磁盘上的数据,而这些磁盘常常又作为存储在通过网络连接的其他机器的磁盘或磁带上的数据的缓冲区域。
存储器层次结构是可行的,这是因为与下一个更低层次的存储设备相比来说,一个编写良好的程序倾向于更频繁地访问某一个层次上的存储设备。所以,下一层的存储设备可以更慢速一点,也因此可以更大,每个比特位更便宜。整体效果是一个大的存储器池,其成本与层次结构底层最便宜的存储设备相当,但是却以接近于层次结构顶部存储设备的高速率向程序提供数据。
存储器层次结构对应用程序的性能有着巨大的影响。如果你的程序需要的数据是存储在 CPU 寄存器中的,那么在指令的执行期间,在 0 个周期内就能访问到它们。如果存储在高速缓存中,需要 4~75 个周期。如果存储在主存中,需要上百个周期。而如果存储在磁盘上,需要大约几千万个周期!
这个思想围绕着计算机程序的一个称为局部性(locality)的基本属性。具有良好局部性的程序倾向于一次又一次地访问相同的数据项集合,或是倾向于访问邻近的数据项集合。具有良好局部性的程序比局部性差的程序更多地倾向于从存储器层次结构中较高层次处访问数据项,因此运行得更快。例如,在 Core i7 系统,不同的矩阵乘法核心程序执行相同数量的算术操作,但是有不同程度的局部性,它们的运行时间可以相差 40 倍!
存储技术
计算机技术的成功很大程度上源自于存储技术的巨大进步。早期的计算机只有几千字节的随机访问存储器。最早的 IBM PC 甚至于没有硬盘。1982 年引入的 IBM PC-XT 有 10M 字节的磁盘。到 2015 年,典型的计算机已有 300 000 倍于 PC-XT 的磁盘存储,而且磁盘的容量以每两年加倍的速度增长。
随机访问存储器
随机访问存储器(Random-Access Memory,RAM)分为两类:静态的和动态的。静态 RAM(SRAM)比动态 RAM(DRAM)更快,但也贵得多。SRAM 用来作为高速缓存存储器,既可以在 CPU 芯片上,也可以在片下。DRAM 用来作为主存以及图形系统的帧缓冲区。典型地,一个桌面系统的 SRAM 不会超过几兆字节,但是 DRAM 却有几百或几千兆字节。
静态 RAM
SRAM 将每个位存储在一个双稳态的(bistable)存储器单元里。每个单元是用一个六晶体管电路来实现的。这个电路有这样一个属性,它可以无限期地保持在两个不同的电压配置(configuration)或状态(state)之一。其他任何状态都是不稳定的——从不稳定状态开始,电路会迅速地转移到两个稳定状态中的一个。这样一个存储器单元类似于图 6-1 中画出的倒转的钟摆。
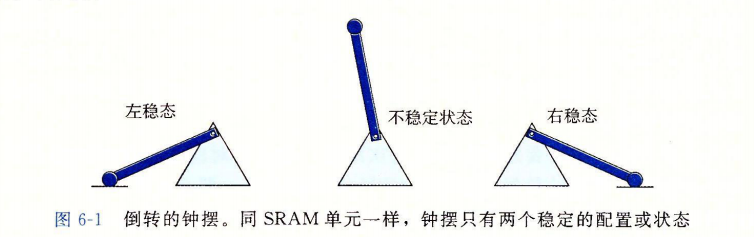
当钟摆倾斜到最左边或最右边时,它是稳定的。从其他任何位置,钟摆都会倒向一边或另一边。原则上,钟摆也能在垂直的位置无限期地保持平衡,但是这个状态是亚稳态的(metastable)——最细微的扰动也能使它倒下,而且一旦倒下就永远不会再恢复到垂直的位置。
由于 SRAM 存储器单元的双稳态特性,只要有电,它就会永远地保持它的值。即使有干扰((例如电子噪音)来扰乱电压,当干扰消除时,电路就会恢复到稳定值。
动态 RAM
DRAM 将每个位存储为对一个电容的充电。这个电容非常小,通常只有大约 30 毫微微法拉(femtofarad)—— $30 \times 10^{-15}$ 法拉。 不过,回想一下法拉是一个非常大的计量单位。DRAM 存储器可以制造得非常密集——每个单元由一个电容和一个访问晶体管组成。但是,与 SRAM 不同,DRAM 存储器单元对干扰非常敏感。当电容的电压被扰乱之后,它就永远不会恢复了。暴露在光线下会导致电容电压改变。实际上,数码照相机和摄像机中的传感器本质上就是 DRAM 单元的阵列。
很多原因会导致漏电,使得 DRAM 单元在 10~100 毫秒时间内失去电荷。幸运的是,计算机运行的时钟周期是以纳秒来衡量的,所以相对而言这个保持时间是比较长的。内存系统必须周期性地通过读出,然后重写来刷新内存每一位。有些系统也使用纠错码,其中计算机的字会被多编码几个位(例如64位的字可能用72位来编码),这样一来,电路可以发现并纠正一个字中任何单个的错误位。
图6-2 总结了 SRAM 和 DRAM 存储器的特性。只要有供电,SRAM 就会保持不变。与 DRAM 不同,它不需要刷新。SRAM 的存取比 DRAM 快。SRAM 对诸如光和电噪声这样的干扰不敏感。代价是 SRAM 单元比 DRAM 单元使用更多的晶体管,因而密集度低,而且更贵,功耗更大。

传统的 DRAM
DRAM 芯片中的单元(位)被分成 d 个超单元(supercell),每个超单元都由 w 个 DRAM 单元组成。一个 $d \times w$ 的 DRAM 总共存储了 $dw$ 位信息。超单元被组织成一个 r 行 c 列的长方形阵列,这里 $rc=d$。每个超单元有形如 $(i, j)$ 的地址,这里 i 表示行,而 j 表示列。
例如,图 6-3 展示的是一个 $16 \times 8$ 的 DRAM 芯片的组织,有 d=16 个超单元,每个超单元有 w=8 位,r=4 行,c=4 列。带阴影的方框表示地址 $(2,1)$ 处的超单元。信息通过称为引脚(pin)的外部连接器流人和流出芯片。每个引脚携带一个 1 位的信号。图6-3 给出了两组引脚:8 个 data 引脚,它们能传送一个字节到芯片或从芯片传出一个字节,以及 2 个 addr 引脚,它们携带 2 位的行和列超单元地址。其他携带控制信息的引脚没有显示出来。
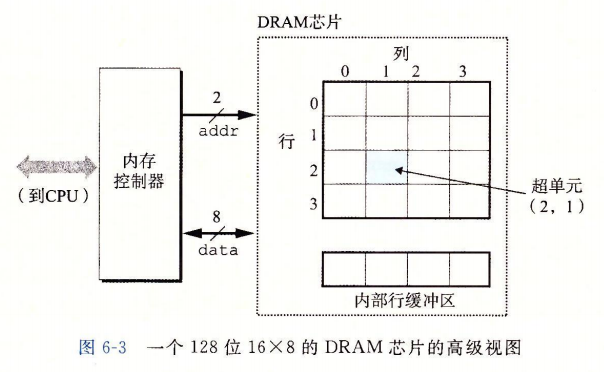
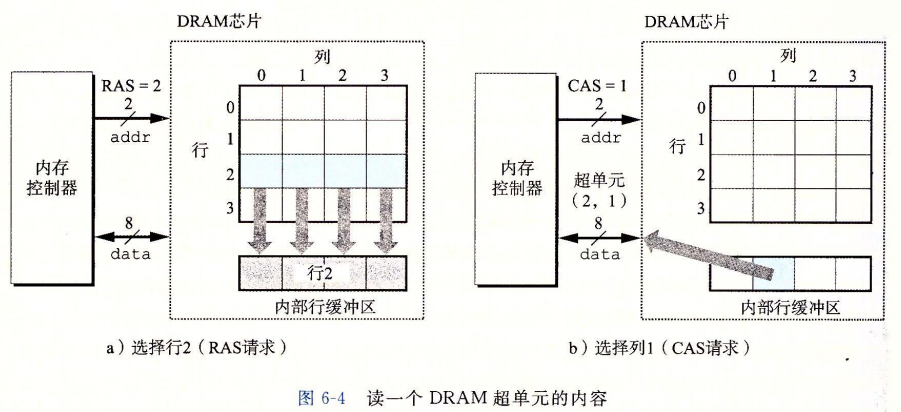
每个 DRAM 芯片被连接到某个称为内存控制器(memory controller)的电路,这个电路可以一次传送 w 位到每个 DRAM 芯片或一次从每个 DRAM 芯片传出 w 位。为了读出超单元 $(i,j)$ 的内容,内存控制器将行地址 i 发送到 DRAM,然后是列地址 j。DRAM 把超单元 $(i,j)$ 的内容发回给控制器作为响应。行地址 i 称为 RAS(Row Access Strobe,行访问选通脉冲)请求。列地址 j 称为 CAS(Column Access Strobe,列访问选通脉冲)请求。
注意,RAS 和 CAS 请求共享相同的 DRAM 地址引脚。
例如,要从图 6-3 中 $16\times8$ 的 DRAM 中读出超单元 $(2,1)$,内存控制器发送行地址 2,如图 6-4a 所示。DRAM 的响应是将行 2 的整个内容都复制到一个内部行缓冲区。接下来,内存控制器发送列地址 1,如图 6-4b 所示。DRAM 的响应是从行缓冲区复制出超单元 $(2,1)$ 中的 8 位,并把它们发送到内存控制器。
电路设计者将 DRAM 组织成二维阵列而不是线性数组的一个原因是降低芯片上地址引脚的数量。例如,如果示例的 128 位 DRAM 被组织成一个 16 个超单元的线性数组,地址为 0~15,那么芯片会需要 4 个地址引脚而不是 2 个。二维阵列组织的缺点是必须分两步发送地址,这增加了访问时间。
内存模块
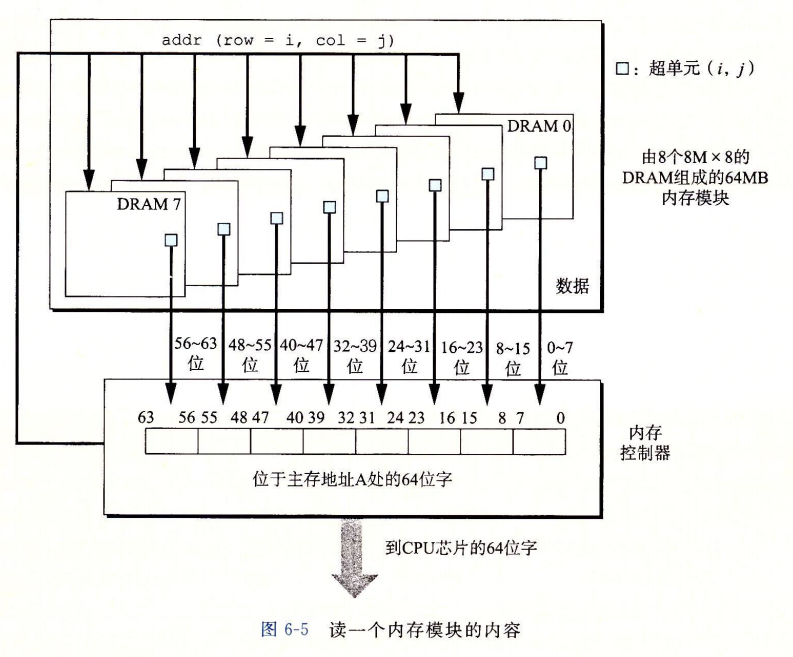
DRAM 芯片封装在内存模块(memory module)中,它插到主板的扩展槽上。Core i7 系统使用的 240 个引脚的双列直插内存模块(Dual Inline Memory Module, DIMM),它以 64 位为块传送数据到内存控制器和从内存控制器传出数据。
图 6-5 展示了一个内存模块的基本思想。示例模块用 8 个 64 Mbit 的 8 MX8 的 DRAM 芯片,总共存储 64MB(兆字节),这 8 个芯片编号为 0~7。每个超单元存储主存的一个字节,而用相应超单元地址为 $(i,j)$ 的 8 个超单元来表示主存中字节地址 A 处的 64 位字。在图 6-5 的示例中,DRAM 0 存储第一个(低位)字节,DRAM 1 存储下一个字节,依此类推。
要取出内存地址 A 处的一个字,内存控制器将 A 转换成一个超单元地址 $(i, j)$,并将它发送到内存模块,然后内存模块再将 i 和 j 广播到每个 DRAM。作为响应,每个 DRAM 输出它的 $(i,j)$ 超单元的 8 位内容。模块中的电路收集这些输出,并把它们合并成一个 64 位字,再返回给内存控制器。
通过将多个内存模块连接到内存控制器,能够聚合成主存。在这种情况中,当控制器收到一个地址 A 时,控制器选择包含 A 的模块 k,将 A 转换成它的 $(i, j)$ 的形式,并将 $(i,j)$ 发送到模块 k。
增强的 DRAM
有许多种 DRAM 存储器,而生产厂商试图跟上迅速增长的处理器速度,市场上就会定期推出新的种类。每种都是基于传统的 DRAM 单元,并进行一些优化,提高访问基本 DRAM 单元的速度。
快页模式 DRAM(Fast Page Mode DRAM,FPM DRAM)。传统的 DRAM 将超单元的一整行复制到它的内部行缓冲区中,使用一个,然后丟弃剩余的。FPM DRAM允许对同一行连续地访问可以直接从行缓冲区得到服务,从而改进了这一点。例如,要从一个传统的 DRAM 的行 i 中读 4 个超单元,内存控制器必须发送 4 个 RAS/CAS 请求,即使是行地址 i 在每个情况中都是一样的。要从一个 FPM DRAM 的同一行中读取超单元,内存控制器发送第一个 RAS/CAS 请求,后面跟三个 CAS 请求。初始的 RAS/CAS 请求将行 i 复制到行缓冲区,并返回 CAS 寻址的那个超单元。接下来三个超单元直接从行缓冲区获得,因此返回得比初始的超单元更快。
扩展数据输出 DRAM(Extended Data Out DRAM,EDO DRAM)。FPM DRAM 的一个增强的形式,它允许各个 CAS 信号在时间上靠得更紧密一点。
同步 DRAM(Synchronous DRAM,SDRAM)。 就它们与内存控制器通信使用一组显式的控制信号来说,常规的、FPM 和 EDO DRAM 都是异步的。SDRAM 用与驱动内存控制器相同的外部时钟信号的上升沿来代替许多这样的控制信号。我们不会深入讨论细节,
最终效果就是 SDRAM 能够比那些异步的存储器更快地输出它的超单元的内容。
双倍数据速率同步 DRAM(Double Data-Rate Synchronous DRAM,DDR SDRAM)。DDR SDRAM 是对 SDRAM 的一种增强,它通过使用两个时钟沿作为控制信号,从而使 DRAM 的速度翻倍。不同类型的DDRS DRAM 是用提高有效带宽的很小的预取缓冲区的大小来划分的: DDR(2位)、DDR2(4位)和 DDR3(8位)。
视频 RAM(Video RAM,VRAM)。它用在图形系统的帧缓冲区中。VRAM 的思想与 FPM DRAM 类似。两个主要区别是:1)VRAM 的输出是通过依次对内部缓冲区的整个内容进行移位得到的; 2)VRAM 允许对内存并行地读和写。因此,系统可以在写下一次更新的新值(写)的同时,用帧缓冲区中的像素刷屏幕(读)。
旁注:DRAM 技术流行的历史
直到 1995 年,大多数 PC 都是用 FPM DRAM 构造的。1996~1999年,EDO DRAM 在市场上占据了主导,而 FPM DRAM 几乎销声匿迹了。
SDRAM 最早出现在 1995 年的高端系统中,到 2002 年,大多数 PC 都是用 SDRAM 和 DDR SDRAM 制造的。到 2010 年之前,大多数服务器和桌面系统都是用 DDR3 SDRAM 构造的。实际上,Intel Core i7 只支持 DDR3 SDRAM。
非易失性存储器
如果断电,DRAM 和 SRAM 会丢失它们的信息,从这个意义上说,它们是易失的(volatile)。另一方面,非易失性存储器(nonvolatile memory)即使是在关电后,仍然保存着它们的信息。现在有很多种非易失性存储器。由于历史原因,虽然 ROM 中有的类型既可以读也可以写,但是它们整体上都被称为只读存储器(Read-Only Memory,ROM)。ROM 是以它们能够被重编程(写)的次数和对它们进行重编程所用的机制来区分的。
PROM(Programmable ROM,可编程ROM)只能被编程一次。PROM 的每个存储器单元有一种熔丝(fuse),只能用高电流熔断一次。
可擦写可编程 ROM(Erasable Programmable ROM,EPROM)有一个透明的石英窗口,允许光到达存储单元。紫外线光照射过窗口,EPROM 单元就被清除为 0。对 EPROM 编程是通过使用一种把 1 写入 EPROM 的特殊设备来完成的。EPROM 能够被擦除和重编程的次数的数量级可以达到 1000 次。电子
可擦除 PROM(Electrically Erasable PROM,EEPROM)类似于 EPROM,但是它不需要一个物理上独立的编程设备,因此可以直接在印制电路卡上编程。EEPROM 能够被编程的次数的数量级可以达到 $10^5$ 次。
闪存(flash memory)是一类非易失性存储器,基于 EEPROM,它已经成为了一种重要的存储技术。闪存无处不在,为大量的电子设备提供快速而持久的非易失性存储,包括数码相机、手机、音乐播放器、PDA 和笔记本、台式机和服务器计算机系统。在 6.1.3 节中,我们会仔细研究一种新型的基于闪存的磁盘驱动器,称为固态硬盘(Solid State Disk,SSD),它能提供相对于传统旋转磁盘的一种更快速、更强健和更低能耗的选择。
存储在 ROM 设备中的程序通常被称为固件(firmware)。当一个计算机系统通电以后,它会运行存储在 ROM 中的固件。一些系统在固件中提供了少量基本的输入和输出函数——例如 PC 的 BIOS(基本输入/输出系统)例程。复杂的设备,像图形卡和磁盘驱动控制器,也依赖固件翻译来自 CPU 的 I/O(输人/输出)请求。
访问主存
数据流通过称为总线(bus)的共享电子电路在处理器和 DRAM 主存之间来来回回。每次 CPU 和主存之间的数据传送都是通过一系列步骤来完成的,这些步骤称为总线事务(bus transaction)。读事务(read transaction)从主存传送数据到 CPU。写事务(write transaction)从 CPU 传送数据到主存。
总线是一组并行的导线,能携带地址、数据和控制信号。取决于总线的设计,数据和地址信号可以共享同一组导线,也可以使用不同的。同时,两个以上的设备也能共享同一总线。控制线携带的信号会同步事务,并标识出当前正在被执行的事务的类型。例如,当前关注的这个事务是到主存的吗?还是到诸如磁盘控制器这样的其他 I/O 设备?这个事务是读还是写?总线上的信息是地址还是数据项?
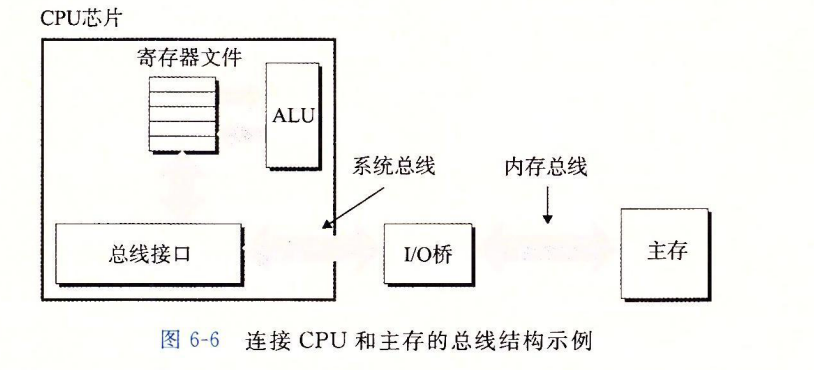
图 6-6 展示了一个示例计算机系统的配置。主要部件是 CPU 芯片、我们将称为 I/O 桥接器(I/O bridge)的芯片组(其中包括内存控制器),以及组成主存的 DRAM 内存模块。这些部件由一对总线连接起来,其中一条总线是系统总线(system bus),它连接 CPU 和 I/O 桥接器,另一条总线是内存总线(memory bus),它连接 I/O 桥接器和主存。I/O 桥接器将系统总线的电子信号翻译成内存总线的电子信号。正如我们看到的那样,I/O 桥也将系统总线和内存总线连接到 I/O 总线,像磁盘和图形卡这样的 I/O 设备共享 I/O 总线。不
过现在,我们将注意力集中在内存总线上。
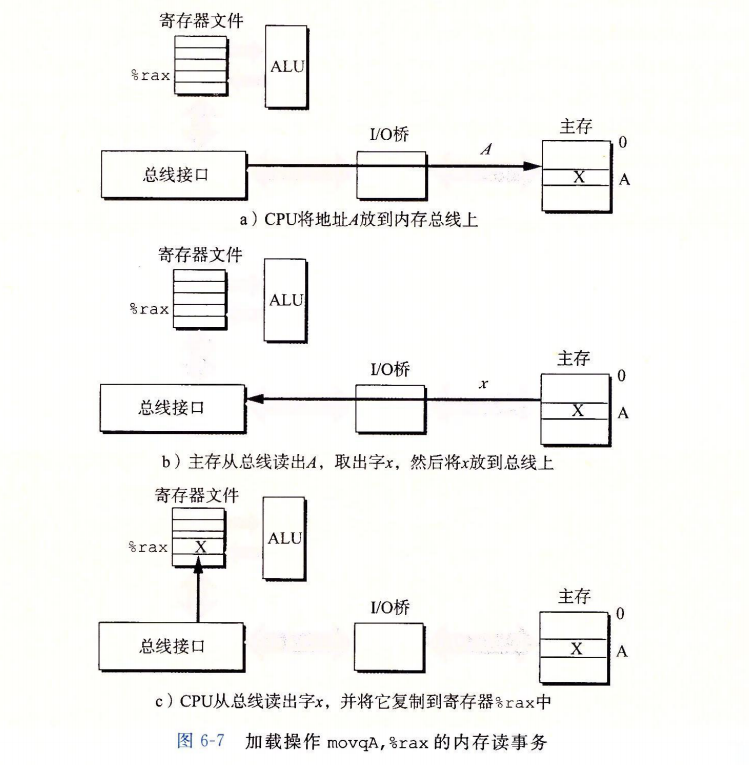
考虑当 CPU 执行一个如下加载操作时会发生什么
movq A,%rax这里,地址 A 的内容被加载到寄存器 %rax 中。CPU 芯片。上称为总线接口(bus interface)的电路在总线上发起读事务。读事务是由三个步骤组成的。首先,CPU 将地址 A 放到系统总线上。I/O 桥将信号传递到内存总线(图 6-7a)。接下来,主存感觉到内存总线上的地址信号,从内存总线读地址,从 DRAM 取出数据字,并将数据写到内存总线。I/O 桥将内存总线信号翻译成系统总线信号,然后沿着系统总线传递(图 6-7b)。最后,CPU 感觉到系统总线上的数据,从总线上读数据,并将数据复制到寄存器 %rax(图6-7c)。
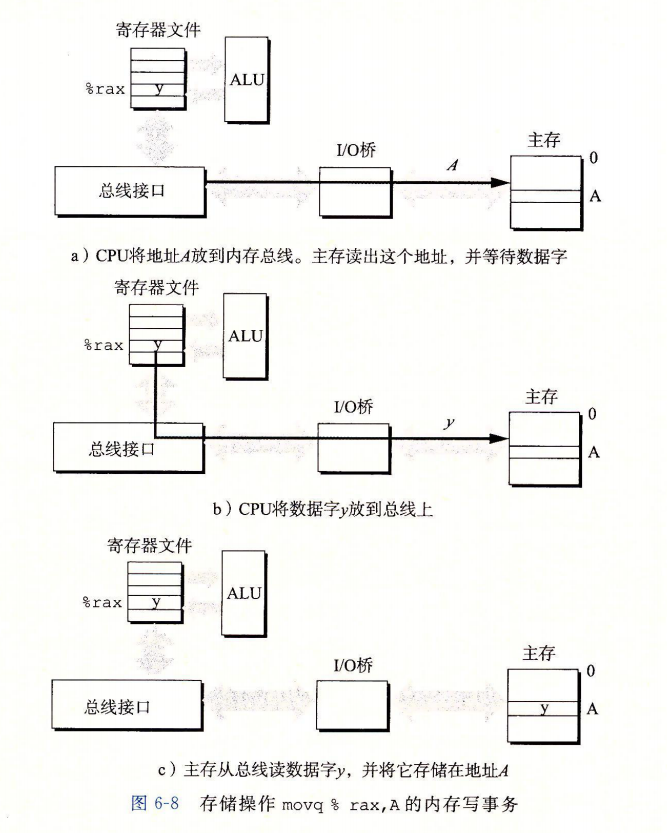
磁盘存储
磁盘是广为应用的保存大量数据的存储设备,存储数据的数量级可以达到几百到几千千兆字节,而基于 RAM 的存储器只能有几百或几千兆字节。不过,从磁盘上读信息的时间为毫秒级,比从 DRAM 读慢了 10 万倍,比从 SRAM 读慢了 100 万倍。
磁盘构造
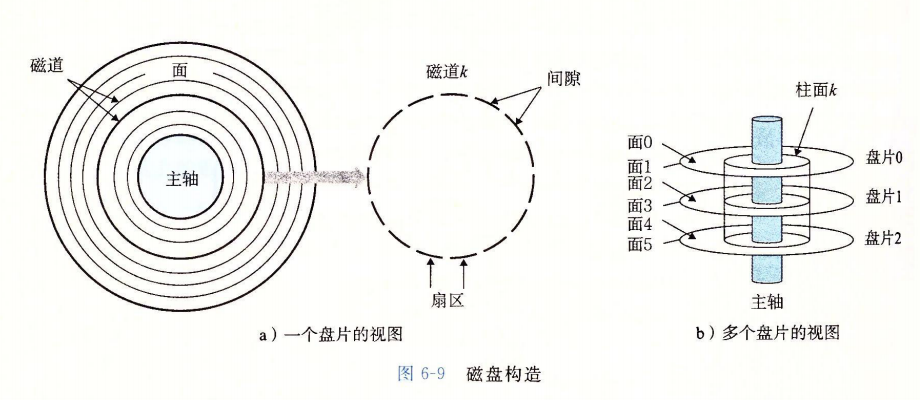
磁盘是由盘片(platter)构成的。每个盘片有两面或者称为表面(surface),表面覆盖着磁性记录材料。盘片中央有一个可以旋转的主轴(spindle),它使得盘片以固定的旋转速率(ratational rate)旋转,通常是 5400~15000 转每分钟(Revolution Per Minute, RPM)。磁盘通常包含一个或多个这样的盘片,并封装在一个密封的容器内。
图 6-9a 展示了一个典型的磁盘表面的结构。每个表面是由一组称为磁道(track)的同心圆组成的。每个磁道被划分为一组扇区(sector)。每个扇区包含相等数量的数据位(通常是 512 字节),这些数据编码在扇区上的磁性材料中。扇区之间由一些间隙(gap)分隔开,这些间隙中不存储数据位。间隙存储用来标识扇区的格式化位。
磁盘是由一个或多个叠放在一起的盘片组成的,它们被封装在一个密封的包装里,如图 6-9b 所示。整个装置通常被称为磁盘驱动器(disk drive),我们通常简称为磁盘(disk)。有时,我们会称磁盘为旋转磁盘(rotating disk),以使之区别于基于闪存的固态硬盘(SSD),SSD 是没有移动部分的。
磁盘制造商通常用术语柱面(cylinder)来描述多个盘片驱动器的构造,这里,柱面是所有盘片表面上到主轴中心的距离相等的磁道的集合。例如,如果一个驱动器有三个盘片和六个面,每个表面上的磁道的编号都是一致的,那么柱面 k 就是 6 个磁道 k 的集合。
磁盘容量
一个磁盘上可以记录的最大位数称为它的最大容量,或者简称为容量。磁盘容量是由以下技术因素决定的:
- 记录密度(recording density)(位/英寸):磁道——英寸的段中可以放入的位数。
- 磁道密度(track density)(道/英寸):从盘片中心出发半径上一英寸的段内可以有的磁道数。
- 面密度(areal density)(位/平方英寸):记录密度与磁道密度的乘积。
磁盘制造商不懈地努力以提高面密度(从而增加容量),而面密度每隔几年就会翻倍。最初的磁盘,是在面密度很低的时代设计的,将每个磁道分为数目相同的扇区,扇区的数目是由最靠内的磁道能记录的扇区数决定的。为了保持每个磁道有固定的扇区数,越往外的磁道扇区隔得越开。在面密度相对比较低的时候,这种方法还算合理。不过,随着面密度的提高,扇区之间的间隙(那里没有存储数据位)变得不可接受地大。因此,现代大容量磁盘使用一种称为多区记录(multiple zone recording)的技术,在这种技术中,柱面的集合被分割成不相交的子集合,称为记录区(recording zone)。每个区包含一组连续的柱面。一个区中的每个柱面中的每条磁道都有相同数量的扇区,这个扇区的数量是由该区中最里面的磁道所能包含的扇区数确定的。
下面的公式给出了一个磁盘的容量:
例如,假设我们有一个磁盘,有 5 个盘片,每个扇区 512 个字节,每个面 20000 条磁道,每条磁道平均 300 个扇区。那么这个磁盘的容量是:
磁盘操作
磁盘用读/写头(read/write head)来读写存储在磁性表面的位,而读写头连接到一个传动臂(actuator arm)一端,如图 6-10a 所示。通过沿着半径轴前后移动这个传动臂,驱动器可以将读/写头定位在盘面上的任何磁道上。这样的机械运动称为寻道(seek)。一旦读/写头定位到了期望的磁道上,那么当磁道上的每个位通过它的下面时,读/写头可以感知到这个位的值(读该位),也可以修改这个位的值(写该位)。有多个盘片的磁盘针对每个盘面都有一个独立的读/写头,如图 6-10b 所示。读/写头垂直排列,一致行动。在任何时刻,所有的读/写头都位于同一个柱面上。
在传动臂末端的读/写头在磁盘表面高度大约 0.1 微米处的一层薄薄的气垫上飞翔,速度大约为 80 km/h。在这样小的间隙里,盘面上一粒微小的灰尘都像一块巨石。如果读/写头碰到了这样的一块巨石,读/写头会停下来,撞到盘面——所谓的读/写头冲撞(head crash)。为此,磁盘总是密封包装的。
磁盘读取
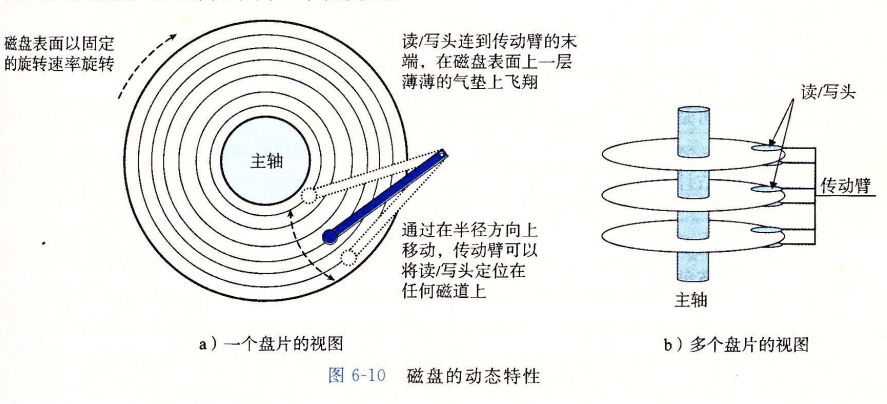
一次性读取扇区0到扇区2的内容。
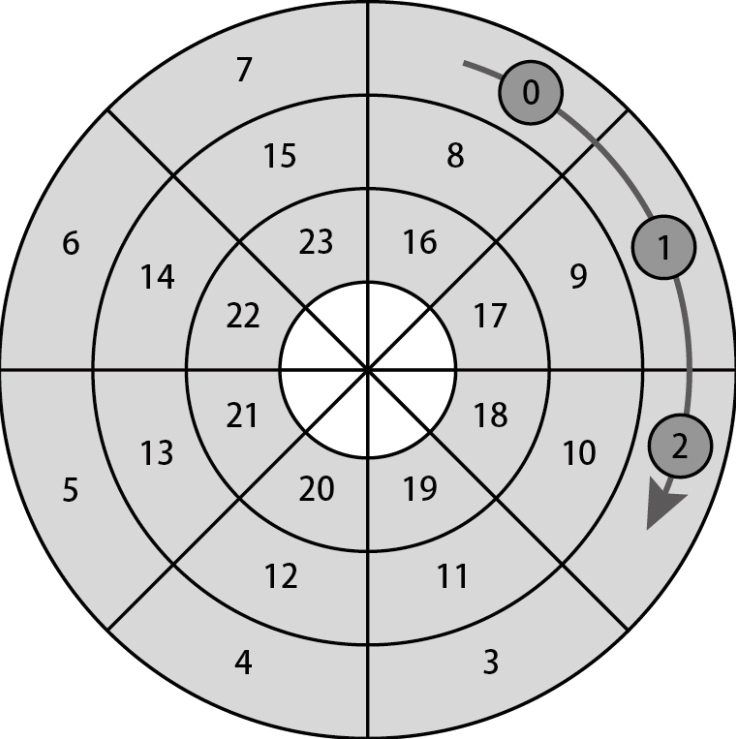
如果需要访问的扇区是连续的,却要分成多次来访问,就会增加访问处理的时间开销。
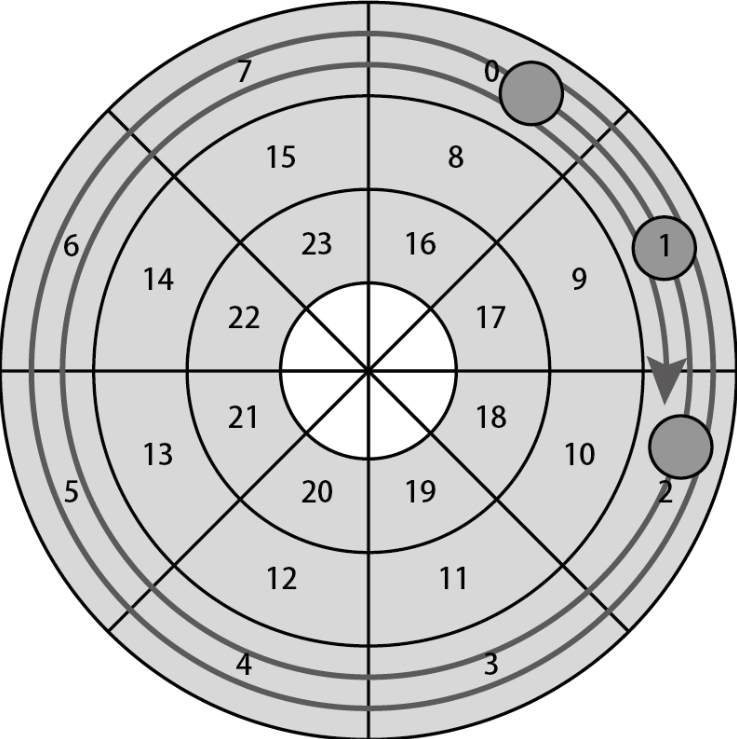
与访问连续的扇区时的情形不同,在访问扇区0、11、23这种不连续的扇区时,则需要将访问请求分成多次发送给HDD,这时访问轨迹会变长。
磁盘以扇区大小的块来读写数据。对扇区的访问时间(access time)有三个主要的部分:寻道时间(seek time)、旋转时间(rotational latency)和传送时间(transfer time):
寻道时间:为了读取某个目标扇区的内容,传动臂首先将读/写头定位到包含目标扇区的磁道上。移动传动臂所需的时间称为寻道时间。寻道时间 $T{seek}$ 依赖于读/写头以前的位置和传动臂在盘面上移动的速度。现代驱动器中平均寻道时间 $T{avg seek}$ 是通过对几千次对随机扇区的寻道求平均值来测量的,通常为 3~9 ms。一次寻道的最大时间 $T_{max seek}$ 可以高达 20 ms。
旋转时间:一旦读/写头定位到了期望的磁道,驱动器等待目标扇区的第一个位旋转到读/写头下。这个步骤的性能依赖于当读/写头到达目标扇区时盘面的位置以及磁盘的旋转速度。在最坏的情况下,读/写头刚刚错过了目标扇区,必须等待磁盘转一整圈。因此,最大旋转延迟(以秒为单位)是
而平均旋转时间是最大旋转时间的一半。
传送时间:当目标扇区的第一个位位于读/写头下时,驱动器就可以开始读或者写该扇区的内容了。一个扇区的传送时间依赖于旋转速度和每条磁道的扇区数目。因此,我们可以粗略地估计一个扇区以秒为单位的平均传送时间如下:
估算磁盘扇区访问的平均时间:
| 参数 | 值 |
| —————————— | ———— |
| 旋转速率 | 7200 RPM |
| $T_{avg \ seek}$ | 9 ms |
| 每条磁道的平均扇区数 | 400 |
逻辑磁盘块
正如我们看到的那样,现代磁盘构造复杂,有多个盘面,这些盘面上有不同的记录区。为了对操作系统隐藏这样的复杂性,现代磁盘将它们的构造呈现为一个简单的视图,一个B 个扇区大小的逻辑块的序列,编号为 0,1,.,B-1。磁盘封装中有一个小的硬件/固件设备,称为磁盘控制器,维护着逻辑块号和实际(物理)磁盘扇区之间的映射关系。
当操作系统想要执行一个 I/O 操作时,例如读一个磁盘扇区的数据到主存,操作系统会发送一个命令到磁盘控制器,让它读某个逻辑块号。控制器上的固件执行一个快速表查找,将一个逻辑块号翻译成一个(盘面, 磁道,扇区)的三元组,这个三元组唯一地标识了对应的物理扇区。控制器上的硬件会解释这个三元组,将读/写头移动到适当的柱面,等待扇区移动到读/写头下,将读/写头感知到的位放到控制器上的一个小缓冲区中, 然后将它们复制到主存中。
旁注:格式化的磁盘容量
磁盘控制器必须对磁盘进行格式化,然后才能在该磁盘上存储数据。格式化包括用标识扇区的信息填写扇区之间的间隙,标识出表面有故障的柱面并且不使用它们,以及在每个区中预留出一组柱面作为备用,如果区中一个或多个柱面在磁盘使用过程中坏掉了,就可以使用这些备用的柱面。因为存在着这些备用的柱面,所以磁盘制造商所说的格式化容量比最大容量要小。
连接I/O设备
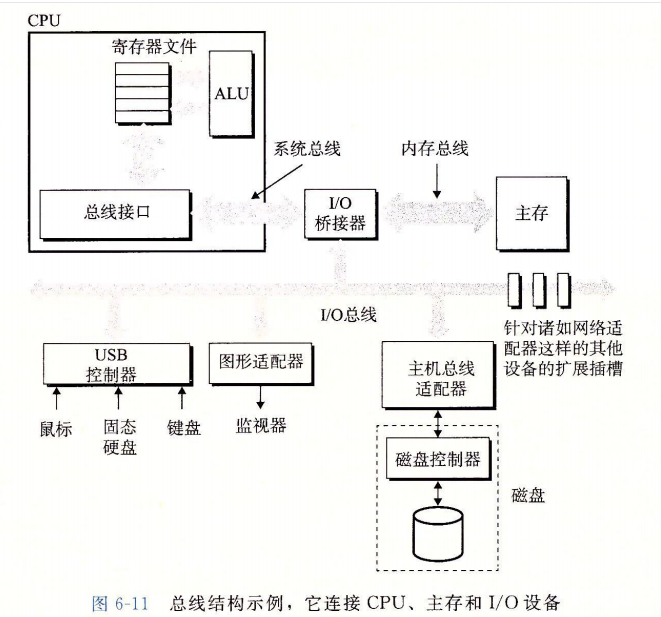
例如图形卡、监视器、鼠标、键盘和磁盘这样的输人/输出(I/O)设备,都是通过 I/O 总线,例如Intel的外围设备互连(Peripheral Component Interconnect,PCI)总线连接到 CPU 和主存的。系统总线和内存总线是与 CPU 相关的,与它们不同,诸如 PCI 这样的 I/O 总线设计成与底层 CPU 无关。例如,PC 和 Mac 都可以使用 PCI 总线。图 6-11 展示了一个典型的 I/O 总线结构,它连接了 CPU、主存和 I/O 设备。
虽然 I/O 总线比系统总线和内存总线慢,但是它可以容纳种类繁多的第三方 I/O 设备。例如,在图 6-11 中,有三种不同类型的设备连接到总线。
- 通用串行总线(Universal Serial Bus,USB)控制器是一个连接到 USB 总线的设备的中转机构,USB 总线是一个广泛使用的标准,连接各种外围 I/O 设备,包括键盘、鼠标、调制解调器、数码相机、游戏操纵杆、打印机、外部磁盘驱动器和固态硬盘。USB 3.0 总线的最大带宽为 625MB/s。USB 3.1 总线的最大带宽为 1250MB/s。
- 图形卡(或适配器)包含硬件和软件逻辑,它们负责代表 CPU 在显示器上画像素。
- 主机总线适配器将一个或多个磁盘连接到 I/O 总线,使用的是一个特别的主机总线接口定义的通信协议。两个最常用的这样的磁盘接口是 SCSI(读作“ scuzzy”)和 SATA (读作“sat-uh”。 SCSI 磁盘通常比 SATA 驱动器更快但是也更贵。SCSI 主机总线适配器(通常称为 SCSI 控制器)可以支持多个磁盘驱动器,与 SATA 适配器不同,它只能支持一个驱动器。
其他的设备,例如网络适配器,可以通过将适配器插人到主板上空的扩展槽中,从而连接到 I/O 总线,这些插槽提供了到总线的直接电路连接。
访问磁盘
I/O 设备是如何工作的
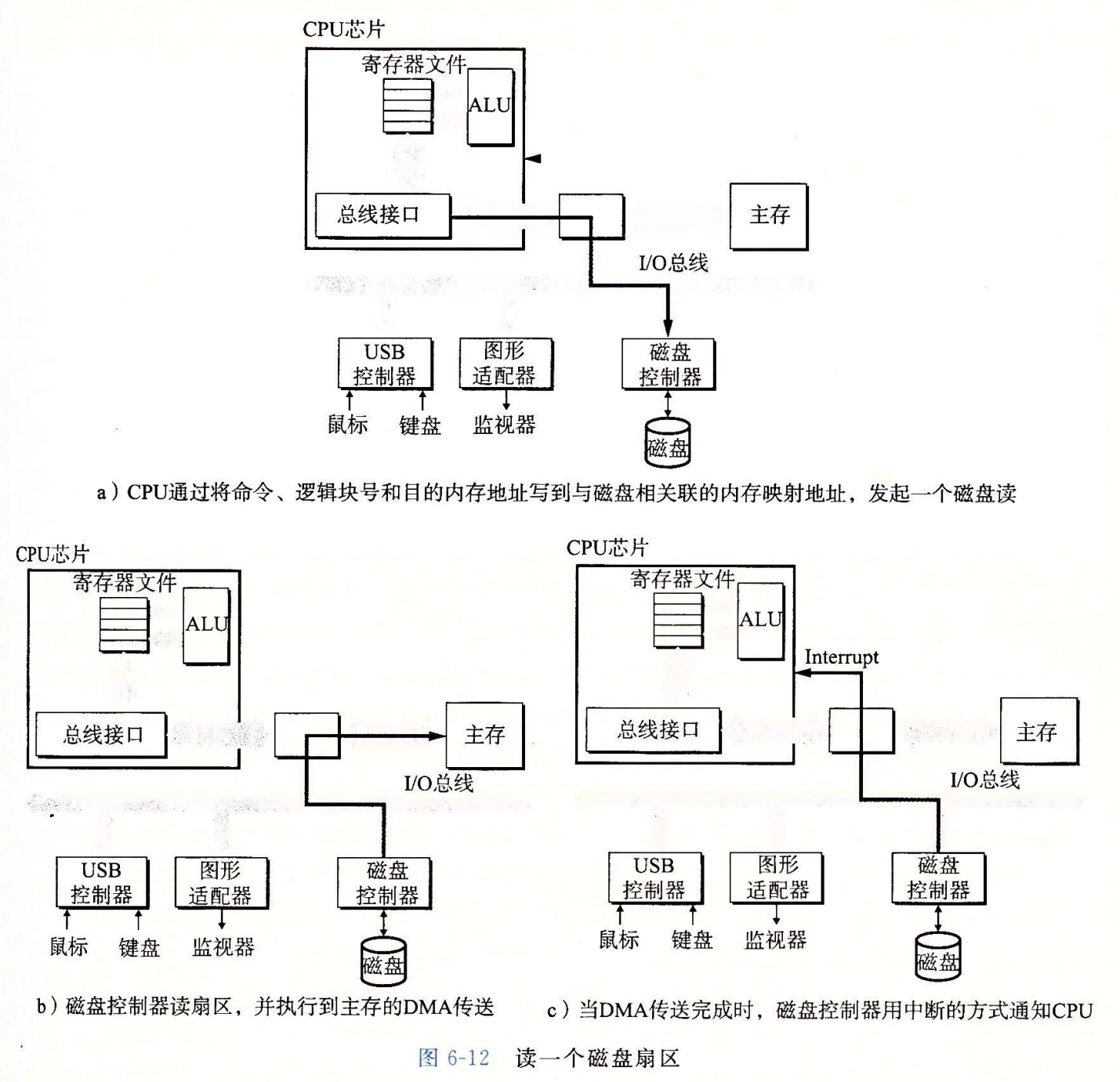
虽然详细描述 I/O 设备是如何工作的以及如何对它们进行编程超出了我们讨论的范围,但是我们可以给你一个概要的描述。例如,图 6-12 总结了当 CPU 从磁盘读数据时发生的步骤。
旁注:I/O 总线设计进展
图 6-11 中的 I/O 总线是一个简单的抽象,使得我们可以具体描述但又不必和某个系统的细节联系过于紧密。它是基于外围设备互联(Peripheral Component Interconnect, PCI)总线的,在 2010 年前使用非常广泛。PCI 模型中,系统中所有的设备共享总线,一个时刻只能有一台设备访问这些线路。在现代系统中,共享的 PCI 总线已经被 PCEe(PCI express)总线取代,PCIe 是一组高速串行、通过开关连接的点到点链路。PCIe 总线,最大吞吐率为 16GB/s,比 PCI 总线快一个数量级,PCI 总线的最大吞吐率为 533MB/s。除了测量出的 I/O 性能,不同总线设计之间的区别对应用程序来说是不可见的,所以在本书中,我们只使用简单的共享总线抽象。
CPU 使用一种称为内存映射 I/O(memory-mapped I/O)的技术来向 I/O 设备发射命令(图 6-12a)。在使用内存映射 I/O 的系统中,地址空间中有一块地址是为与 I/O 设备通信保留的。每个这样的地址称为一个 I/O 端口(I/O port)。当一个设备连接到总线时,它与一个或多个端口相关联(或它被映射到一个或多个端口)。
来看一个简单的例子,假设磁盘控制器映射到端口 0xa0。随后 CPU 可能通过执行三个对地址 0xa0 的存储指令,发起磁盘读:第一条指令是发送一个命令字,告诉磁盘发起一个读,同时还发送了其他的参数,例如当读完成时,是否中断 CPU(我们会在 8.1 节中讨论中断)。第二条指令指明应该读的逻辑块号。第三条指令指明应该存储磁盘扇区内容的主存地址。
当 CPU 发出了请求之后,在磁盘执行读的时候,它通常会做些其他的工作。回想一下,一个 1GHz 的处理器时钟周期为 1ns,在用来读磁盘的 16ms 时间里,它潜在地可能执行 1600 万条指令。在传输进行时,只是简单地等待,什么都不做,是一种极大的浪费。
在磁盘控制器收到来自 CPU 的读命令之后,它将逻辑块号翻译成一个扇区地址,读该扇区的内容,然后将这些内容直接传送到主存,不需要 CPU 的干涉(图6-12b)。设备可以自己执行读或者写总线事务而不需要 CPU 干涉的过程,称为直接内存访问(Direct Memory Access,DMA)。这种数据传送称为 DMA 传送(DMA transfer)。
在 DMA 传送完成,磁盘扇区的内容被安全地存储在主存中 CPU 发送一个中断信号来通知 CPU(图6-12c)。基本思想是中断会发信号到 CPU 芯片的一个外部引脚上。这会导致 CPU 暂停它当前正在做的工作,跳转到一个操作系统例程。这个程序会记录下 I/O 已经完成,然后将控制返回到 CPU 被中断的地方。
通过通用块层读取
Linux 中将 HDD 和 SSD 这类可以随机访问、并且能以一定的大小(在 HDD 与 SSD 中是扇区)访问的设备统一归类为块设备。块设备可以通过设备文件直接访问,也可以通过在其上构建的文件系统来间接访问。大部分软件采用的是后一种方式。由于各种块设备通用的处理有很多,所以这些处理并不会在设备各自的驱动程序中实现,而是被集成到内核中名为通用块层的组件上来实现。
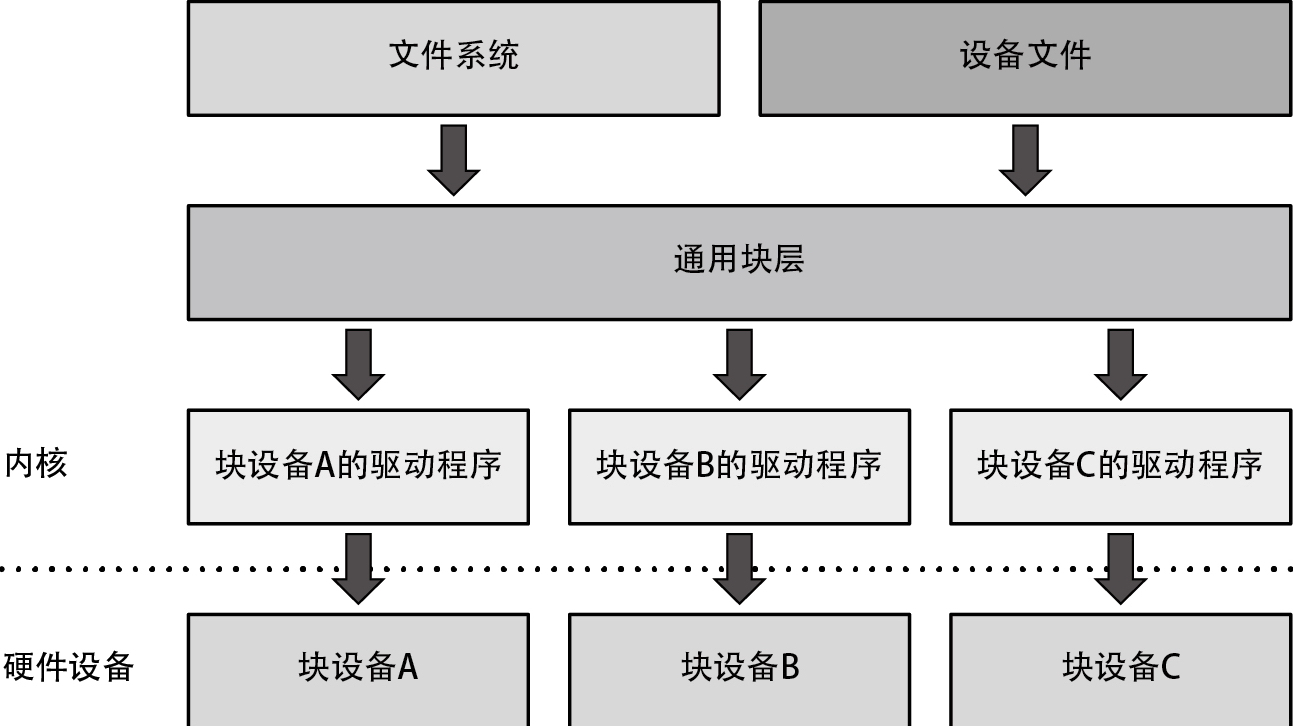
I/O调度器
通用块层中的 I/O 调度器会将访问块设备的请求积攒一定时间,并在向设备驱动程序发出 I/O 请求前对这些请求进行如下加工,以提高 I/O 的性能。
- 合并:将访问连续扇区的多个 I/O 请求合并为一个请求
- 排序:按照扇区的序列号对访问不连续的扇区的多个 I/O 请求进行排序
也存在先排序再执行合并的情况,那样可以更大程度地提高 I/O 性能。
I/O 调度器的运作方式如下图所示。

有了 I/O 调度器,即便用户程序的开发人员不太了解块设备的性能特性,也能够在一定程度上发挥块设备的性能。
预读
在程序访问数据时具有空间局部性这一特征。通用块层中的预读(read-ahead)机制就是利用这一特征来提升性能的。
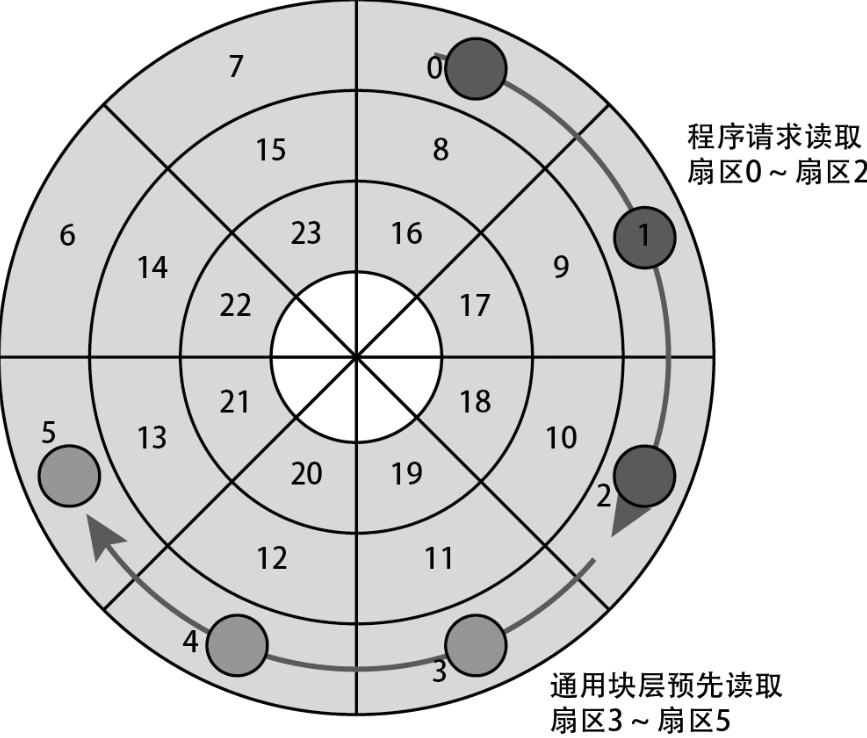
如果之后与推测的一样,程序申请读取后面那部分区域,就可以省略该读取请求的 I/O 处理,因为这些数据已经被预先读取出来了。
固态硬盘
固态硬盘(Solid State Disk,SSD)是一种基于闪存的存储技术,在某些情况下是传统旋转磁盘的极有吸引力的替代产品。图 6-13 展示了它的基本思想。SSD 封装插到 I/O 总线上标准硬盘插槽(通常是 USB 或 SATA)中,行为就和其他硬盘一样,处理来自 CPU 的读写逻辑磁盘块的请求。一个 SSD 封装由一个或多个闪存芯片和闪存翻译层(flash translation layer)组成,闪存芯片替代传统旋转磁盘中的机械驱动器,而闪存翻译层是一个硬件/固件设备,扮演与磁盘控制器相同的角色,将对逻辑块的请求翻译成对底层物理设备的访问。
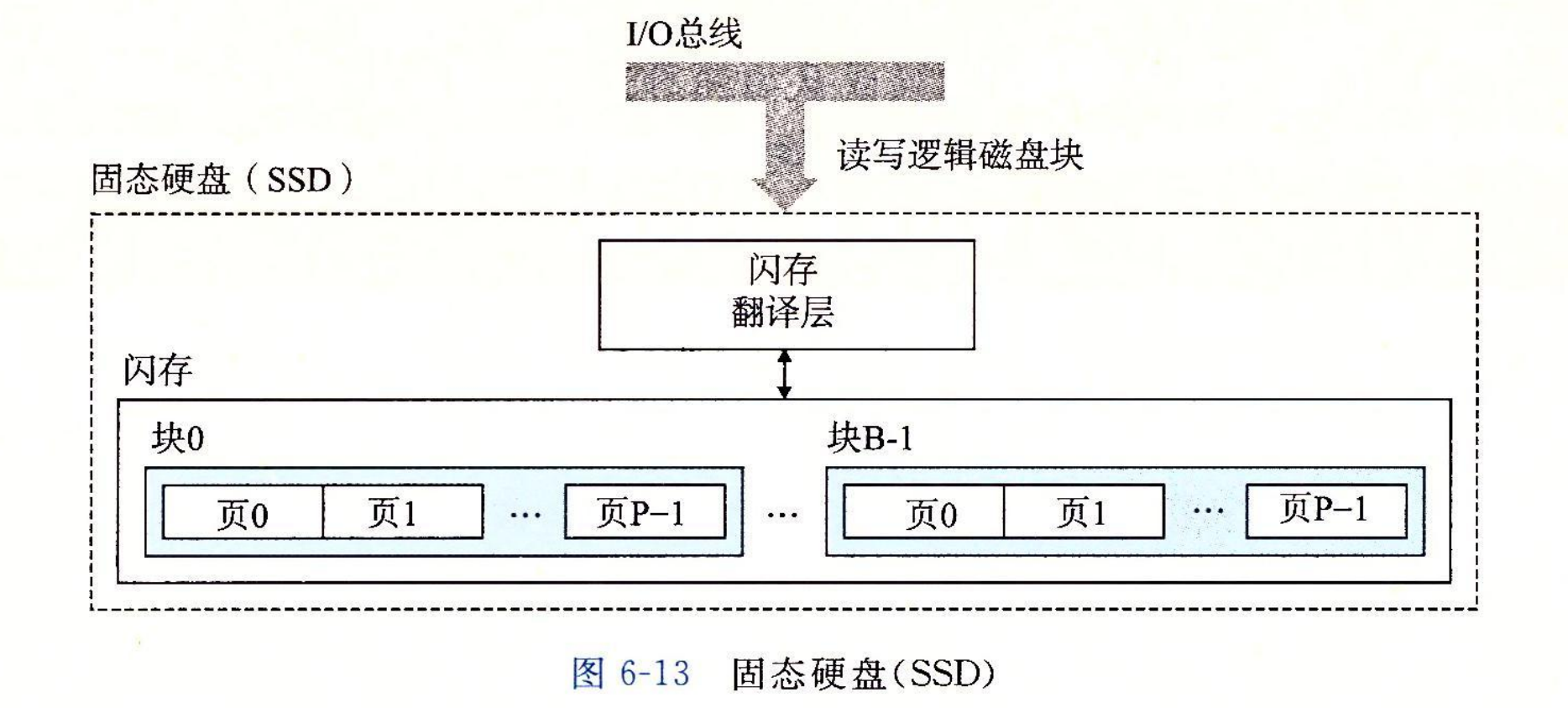
图 6-14 展示了典型 SSD 的性能特性。注意,读 SSD 比写要快。随机读和写的性能差别是由底层闪存基本属性决定的。如图 6-13 所示,一个闪存由 B 个块的序列组成,每个块由 Р 页组成。通常,页的大小是 512B~4KB,块是由 32~128 页组成的,块的大小为 16KB ~ 512KB。数据是以页为单位读写的。只有在一页所属的块整个被擦除之后,才能写这一页(通常是指该块中的所有位都被设置为 1)。不过,一旦一个块被擦除了,块中每一个页都可以不需要再进行擦除就写一次。在大约进行 100 000 次重复写之后,块就会磨损坏。一旦一个块磨损坏之后,就不能再使用了。

随机写很慢,有两个原因。首先,擦除块需要相对较长的时间,1ms 级的,比访问页所需时间要高一个数量级。其次,如果写操作试图修改一个包含已经有数据(也就是不是全为 1)的页 p,那么这个块中所有带有用数据的页都必须被复制到一个新(擦除过的)块,然后才能进行对页 p 的写。制造商已经在闪存翻译层中实现了复杂的逻辑,试图抵消擦写块的高昂代价,最小化内部写的次数,但是随机写的性能不太可能和读一样好。
比起旋转磁盘,SSD 有很多优点。它们由半导体存储器构成,没有移动的部件,因而随机访问时间比旋转磁盘要快,能耗更低,同时也更结实。不过,也有一些缺点。首先,因为反复写之后,闪存块会磨损,所以 SSD 也容易磨损。闪存翻译层中的平均磨损(wear leveling)逻辑试图通过将擦除平均分布在所有的块上来最大化每个块的寿命。实际上平均磨损逻辑处理得非常好,要很多年 SSD 才会磨损坏。其次,SSD 每字节比旋转磁盘贵大约 30 倍,因此常用的存储容量比旋转磁盘小 100 倍。不过,随着 SSD 变得越来越受欢迎,它的价格下降得非常快,而两者的价格差也在减少。
在便携音乐设备中,SSD 已经完全的取代了旋转磁盘,在笔记本电脑中也越来越多地作为硬盘的替代品,甚至在台式机和服务器中也开始出现了。虽然旋转磁盘还会继续存在,但是显然,SSD 是一项重要的替代选择。
SSD 的一个潜在的缺陷是底层闪存会磨损。例如,图6-14所示的 SSD,Intel 保证能够经得起 128PB(128×1015字节)的写。给定这样的假设,根据下面的工作负载,估计这款 SSD 的寿命(以年为单位):
- 顺序写的最糟情况:以 470MB/s(该设备的平均顺序写吞吐量)的速度持续地写 SSD
- 随机写的最糟情况:以 303MB/s(该设备的平均随机写吞吐量)的速度持续地写 SSD
- 平均情况:以 20GB/天(某些计算机制造商在他们的移动计算机工作负载模拟测试中假设的平均每天写速率)的速度写 SSD
存储技术趋势
从我们对存储技术的讨论中,可以总结出几个很重要的思想:不同的存储技术有不同的价格和性能折中。SRAM 比 DRAM 快一点,而 DRAM 比磁盘要快很多。另一方面,快速存储总是比慢速存储要贵的。SRAM 每字节的造价比 DRAM 高,DRAM 的造价又比磁盘高得多。SSD 位于 DRAM 和旋转磁盘之间。
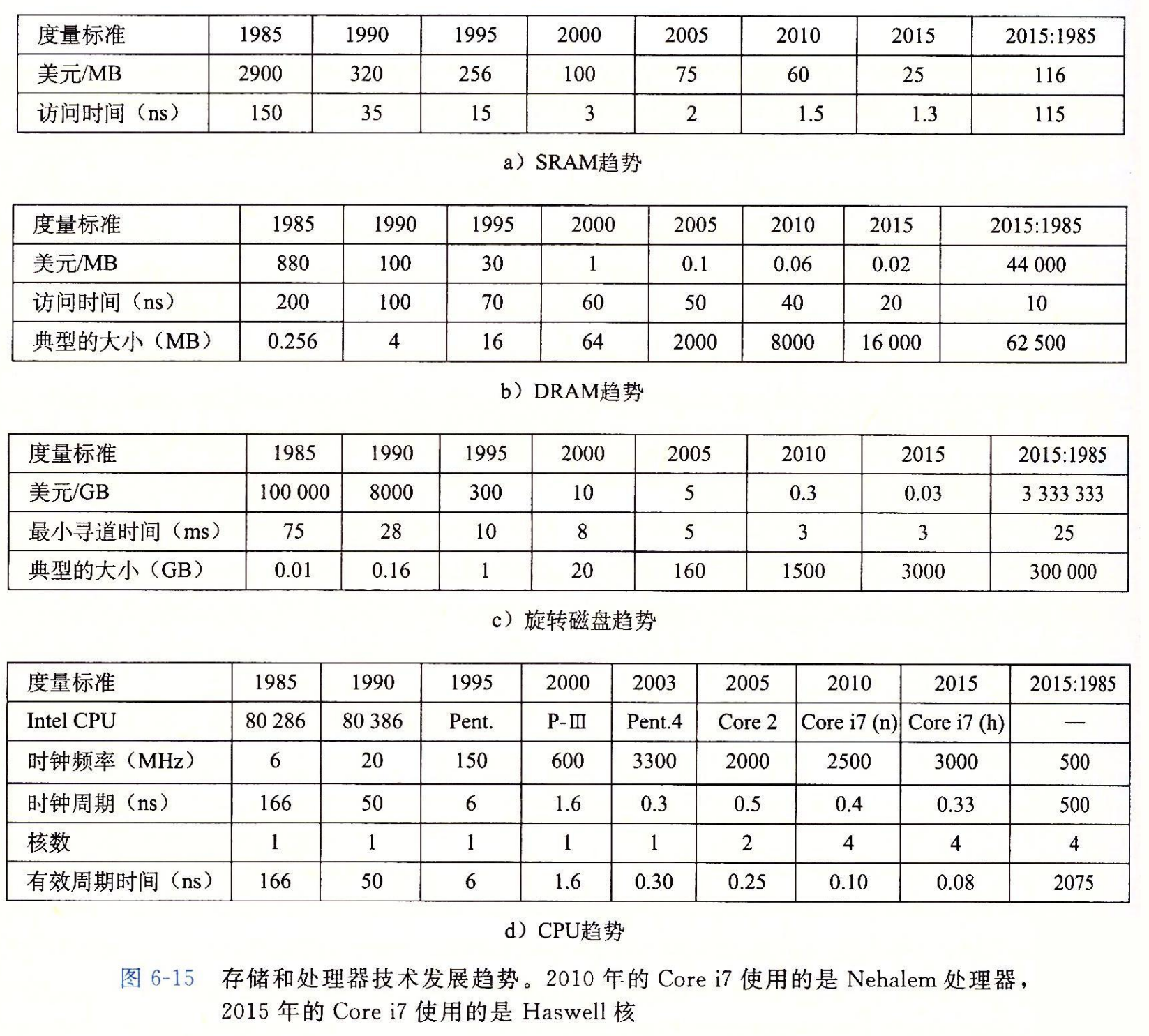
不同存储技术的价格和性能属性以截然不同的速率变化着。图 6-15 总结了从 1985 年以来的存储技术的价格和性能属性,那时第一台 PC 刚刚发明不久。这些数字是从以前的商业杂志中和 Web上挑选出来的。虽然它们是从非正式的调查中得到的,但是这些数字还是能揭示出一些有趣的趋势。
自从 1985 年以来,SRAM 技术的成本和性能基本上是以相同的速度改善的。访问时间和每兆字节成本下降了大约100 倍(图6-15a)。不过,DRAM 和磁盘的变化趋势更大,而且更不一致。DRAM 每兆字节成本下降了 44 000 倍(超过了四个数量级),而 DRAM 的访问时间只下降了大约 10 倍(图 6-15 b)。磁盘技术有和 DRAM 相同的趋势,甚至变化更大。从 1985 年以来,磁盘存储的每兆字节成本暴跌了 3 000 000倍(超过了六个数量级),但是访问时间提高得很慢,只有 25 倍左右(图6-15c)。这些惊人的长期趋势突出了内存和磁盘技术的一个基本事实:增加密度(从而降低成本)比降低访问时间容易得多 DRAM 和磁盘的性能滞后于 CPU 的性能。正如我们在图 6-15d 中看到的那样,从 1985 年到 2010 年,CPU 周期时间提高了 500 倍。如果我们看有效周期时间(effective cycle time)—— 我们定义为一个单独的 CPU(处理器)的周期时间除以它的处理器核数——那么从 1985 年到 2010 年的提高还要大一些,为 2000 倍。CPU 性能曲线在 2003 年附近的突然变化反映的是多核处理器的出现,在这个分割点之后,单个核的周期时间实际上增加了一点点,然后又开始下降,不过比以前的速度要慢一些。
注意,虽然 SRAM 的性能滞后于 CPU 的性能,但还是在保持增长。不过,DRAM 和磁盘性能与 CPU 性能之间的差距实际上是在加大的。直到 2003 年左右多核处理器的出现,这个性能差距都是延迟的函数,DRAM 和磁盘的访问时间比单个处理器的周期时间提高得更慢。不过,随着多核的出现,这个性能越来越成为了吞吐量的函数,多个处理器核并发地向 DRAM 和磁盘发请求。
图 6-16 清楚地表明了各种趋势,以半对数为比例(semi-log scale),画出了图 6-15 中的访问时间和周期时间。
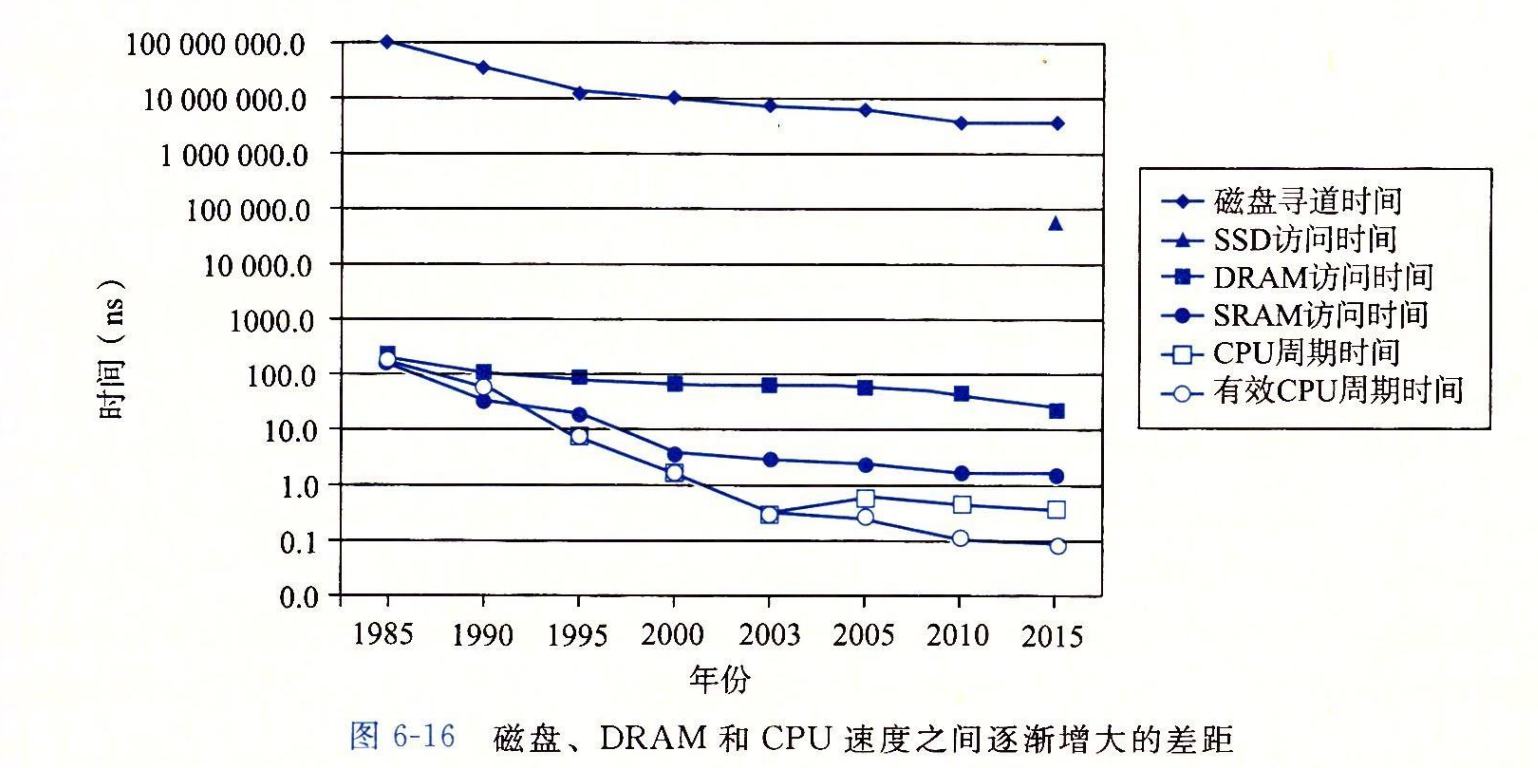
正如我们将在 6.4 节中看到的那样,现代计算机频繁地使用基于 SRAM 的高速缓存,试图弥补处理器-内存之间的差距。这种方法行之有效是因为应用程序的一个称为局部性(locality)的基本属性,接下来我们就讨论这个问题。
旁注:当周期时间保持不变:多核处理器的到来
计算机历史是由一些在工业界和整个世界产生深远变化的单个事件标记出来的。有趣的是,这些变化点趋向于每十年发生一次:20 世纪 50 年代 Fortran 的提出,20 世纪 60 年代早期 IBM 360 的出现,20 世纪 70 年代早期 Internet 的曙光(当时称为 APRANET),20 世纪 80 年代早期 IBM PC 的出现,以及 20 世纪 90 年代万维网(World Wide Web)的出现。
最近这样的事件出现在 21 世纪初,当计算机制造商迎头撞上了所谓的“能量墙(powerwall)”,发现他们无法再像以前一样迅速地增加 CPU 的时钟频率了,因为如果那样芯片的功耗会太大。解决方法是用多个小处理器核(core)取代单个大处理器,从而提高性能,每个完整的处理器能够独立地、与其他核并行地执行程序。这种多核(multi-core)方法部分有效,因为一个处理器的功耗正比于 $P=fCv^2$,这里 f 是时钟频率,C 是电容,而 v 是电压。电容 C 大致上正比于面积,所以只要所有核的总面积不变,多核造成的能耗就能保持不变。只要特征尺寸继续按照摩尔定律指数性地下降,每个处理器中的核数,以及每个处理器的有效性能,都会继续增加。
从这个时间点以后,计算机越来越快,不是因为时钟频率的增加,而是因为每个处理器中核数的增加,也因为体系结构上的创新提高了在这些核上运行程序的效率。我们可以从图 6-16 中很清楚地看到这个趋势。CPU 周期时间在 2003 年达到最低点,然后实际上是又开始上升的,然后变得平稳,之后又开始以比以前慢一些的速率下降。不过,由于多核处理器的出现(2004 年出现双核,2007 年出现四核),有效周期时间以接近于以前的速率持续下降。
局部性
一个编写良好的计算机程序常常具有良好的局部性(locality)。也就是,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身。这种倾向性,被称为局部性原理(principle of locality),是一个持久的概念,对硬件和软件系统的设计和性能都有着极大的影响。
局部性通常有两种不同的形式:时间局部性(temporal locality)和空间局部性(spatial locality)。在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来再被多次引用。在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
存储器层次结构
6.1 节和 6.2 节描述了存储技术和计算机软件的一些基本的和持久的属性:
- 存储技术:不同存储技术的访问时间差异很大。速度较快的技术每字节的成本要比速度较慢的技术高,而且容量较小。CPU 和主存之间的速度差距在增大。
- 计算机软件:一个编写良好的程序倾向于展示出良好的局部性。
计算中一个喜人的巧合是,硬件和软件的这些基本属性互相补充得很完美。它们这种相互补充的性质使人想到一种组织存储器系统的方法,称为存储器层次结构(memory hierarchy),所有的现代计算机系统中都使用了这种方法。图 6-21 展示了一个典型的存储器层次结构。一般而言,从高层往底层走,存储设备变得更慢、更便宜和更大。在最高层(L0),是少量快速的 CPU 寄存器,CPU 可以在一个时钟周期内访问它们。接下来是一个或多个小型到中型的基于 SRAM 的高速缓存存储器,可以在几个 CPU 时钟周期内访问它们。然后是一个大的基于 DRAM 的主存,可以在几十到几百个时钟周期内访问它们。接下来是慢速但是容量很大的本地磁盘。最后,有些系统甚至包括了一层附加的远程服务器上的磁盘,要通过网络来访问它们。例如,像安德鲁文件系统(Andrew File System,AFS)或者网络文件系统(Network File System,NFS)这样的分布式文件系统,允许程序访问存储在远程的网络服务器上的文件。类似地,万维网允许程序访问存储在世界上任何地方的 Web 服务器上的远程文件。
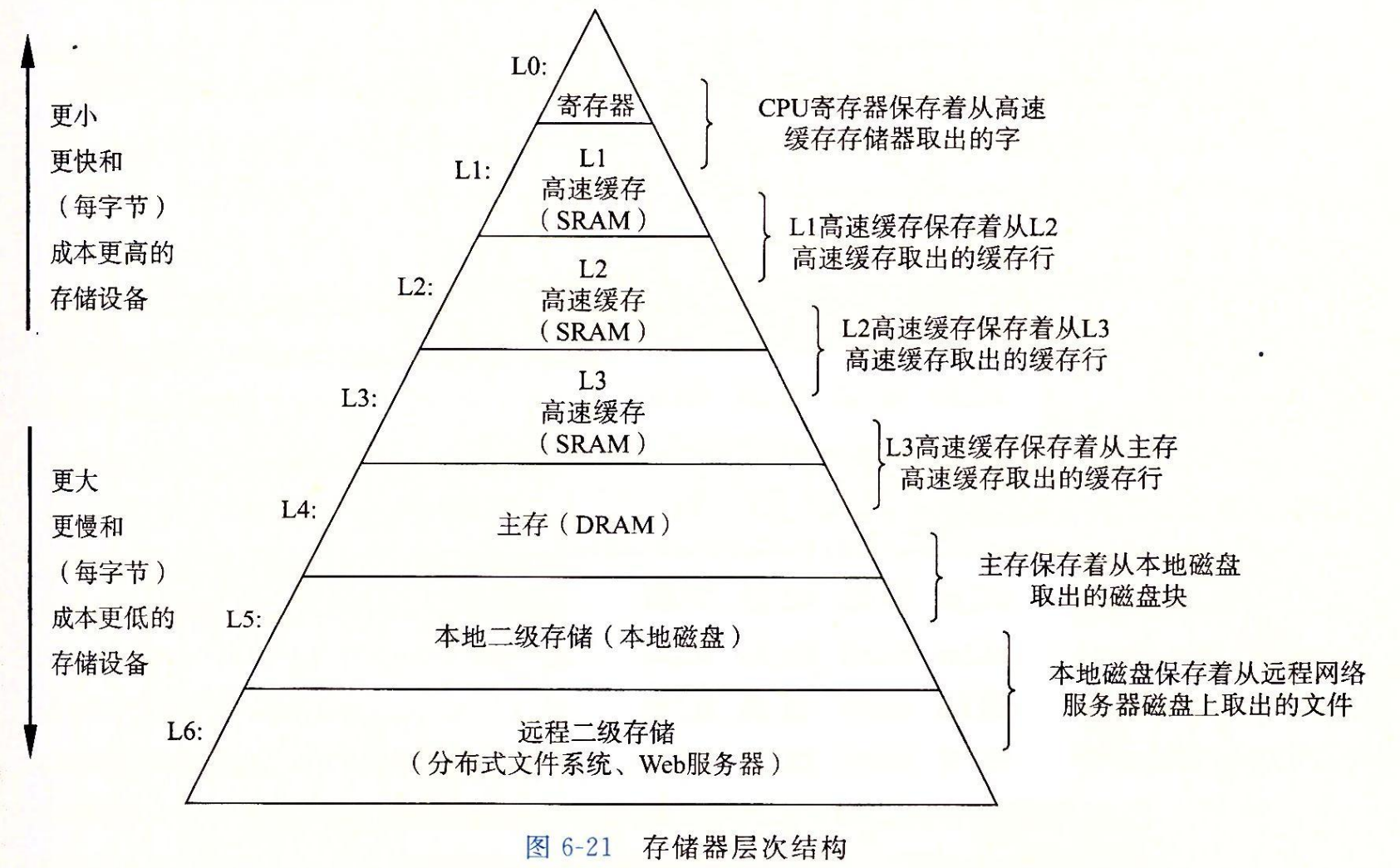
概括来说,基于缓存的存储器层次结构行之有效,是因为较慢的存储设备比较快的存储设备更便宜,还因为程序倾向于展示局部性:
- 利用时间局部性:由于时间局部性,同一数据对象可能会被多次使用。一旦一个数据对象在第一次不命中时被复制到缓存中,我们会期望后面对该目标有一系列的访问命中。因为缓存比低一层的存储设备更快,对后面的命中的服务会比最开始的不命中快很多。
- 利用空间局部性:块通常包含有多个数据对象。由于空间局部性,我们会期望后面对该块中其他对象的访问能够补偿不命中后复制该块的花费。
现代系统中到处都使用了缓存,下图展示了它在现代计算机系统中是多么普遍。
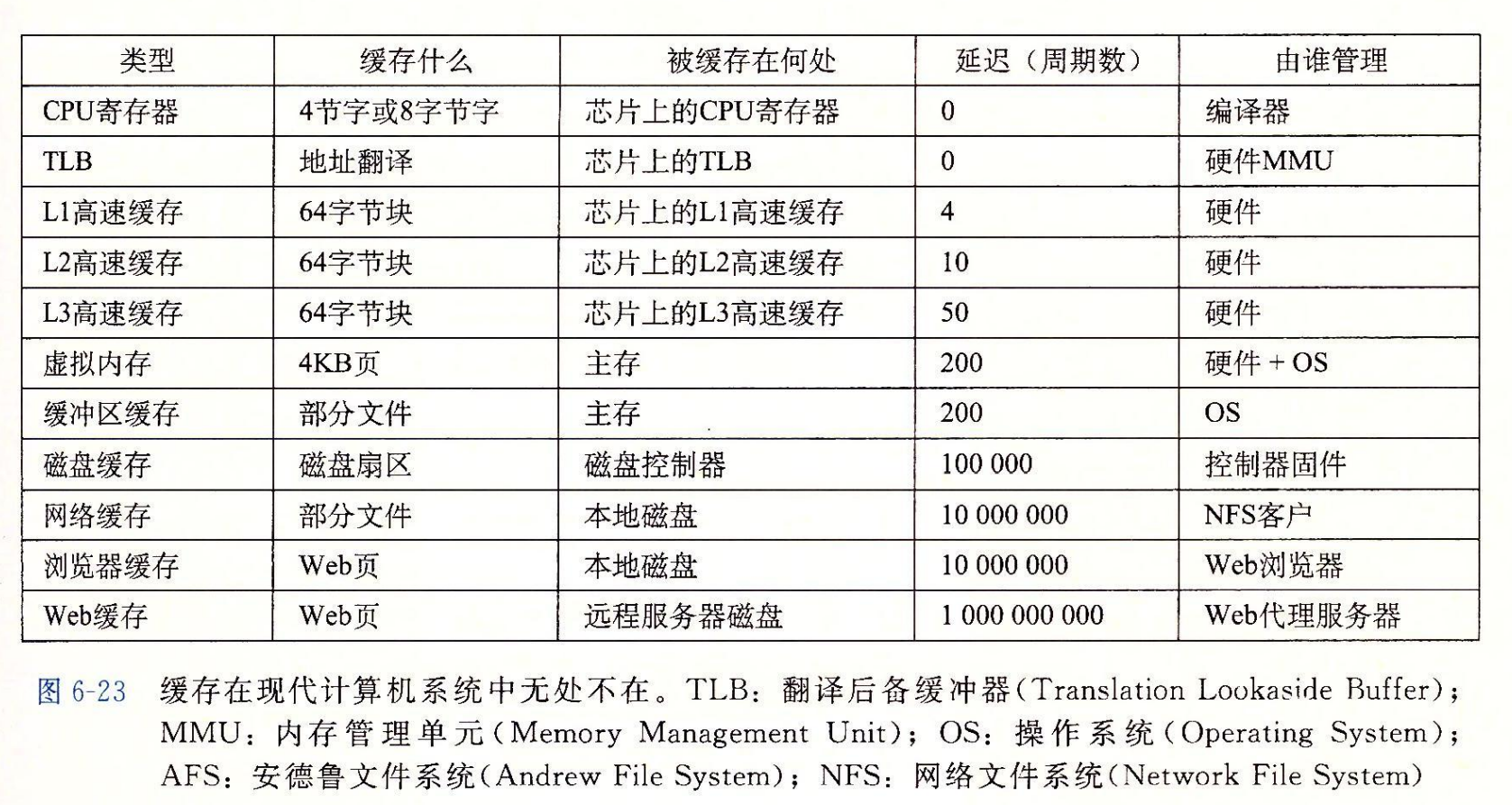
高速缓存存储器
早期计算机系统的存储器层次结构只有三层:CPU 寄存器、DRAM 主存储器和磁盘存储。不过,由于 CPU 和主存之间逐渐增大的差距,系统设计者被迫在 CPU 寄存器文件和主存之间插入了一个小的 SRAM 高速缓存存储器,称为 L1 高速缓存(一级缓存),如图 6-24 所示。L1 高速缓存的访问速度几乎和寄存器一样快,典型地是大约 4 个时钟周期。
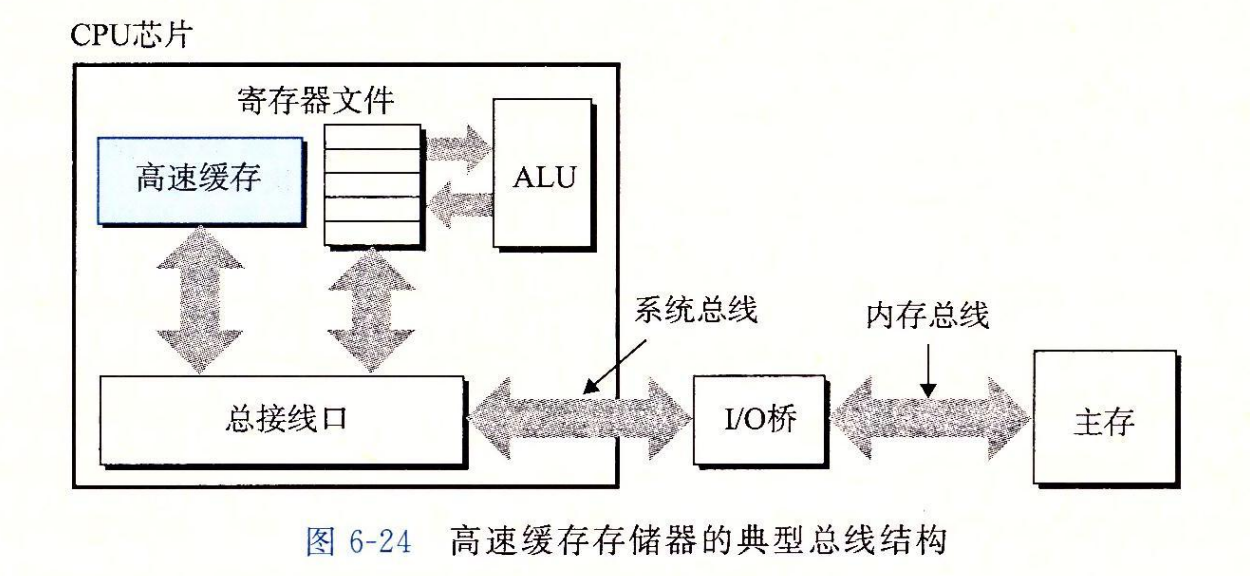
随着 CPU 和主存之间的性能差距不断增大,系统设计者在 L1 高速缓存和主存之间又插入了一个更大的高速缓存,称为 L2 高速缓存,可以在大约 10 个时钟周期内访问到它。有些现代系统还包括有一个更大的高速缓存,称为 L3 高速缓存,在存储器层次结构中,它位于 L2 高速缓存和主存之间,可以在大约 50 个周期内访问到它。虽然安排上有相当多的变化,但是通用原则是一样的。对于下一节中的讨论,我们会假设一个简单的存储器层次结构,CPU 和主存之间只有一个 L1 高速缓存。
通用的高速缓存存储器组织结构
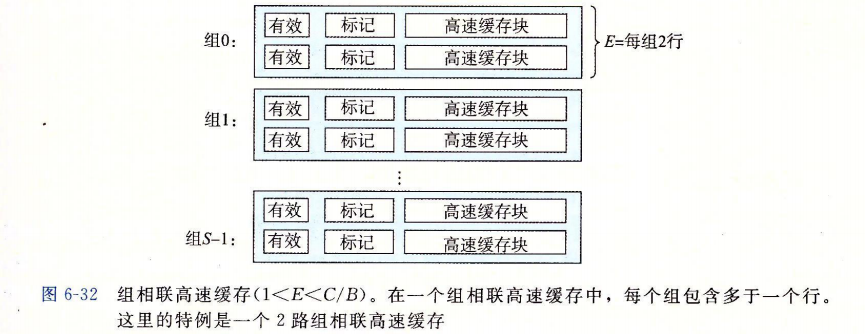
考虑一个计算机系统,其中每个存储器地址有 m 位形成 $M=2^m$ 个不同的地址。如图 6-25a 所示,这样一个机器的高速缓存被组织成一个有 $S=2^s$ 个高速缓存组(cache set)的数组。每个组包含 E 个高速缓存行(cache line)。每个行是由一个 $B=2^b$ 字节的数据块(block)组成的,一个有效位(valid bit)指明这个行是否包含有意义的信息,还有t=m-(b十s)个标记位( tag bit)(是当前块的内存地址的位的一个子集),它们唯一地标识存储在这个高速缓存行中的块。
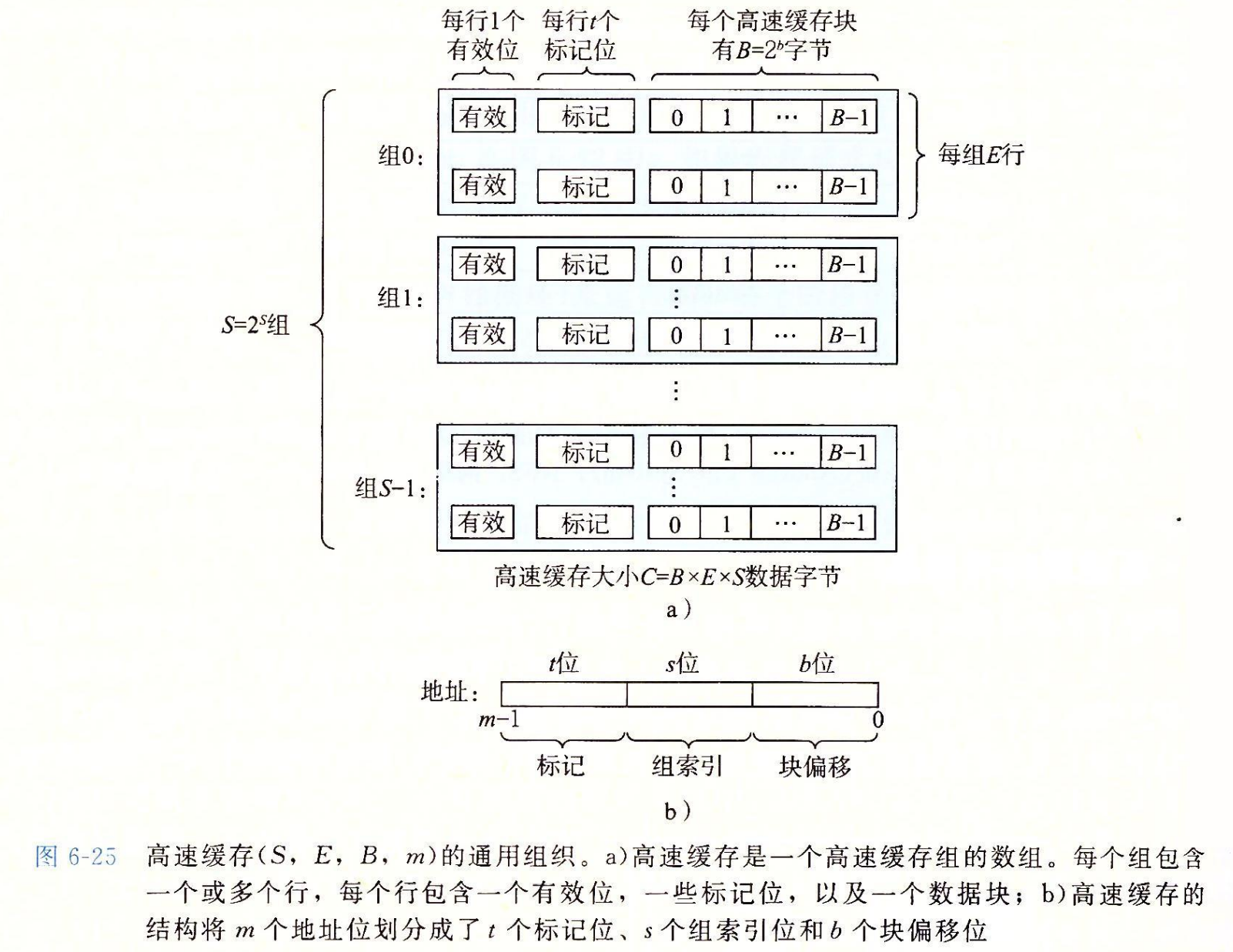
一般而言,高速缓存的结构可以用元组(S,E,B,m)来描述。高速缓存的大小(或容量)C 指的是所有块的大小的和。标记位和有效位不包括在内。因此,$C=S \times E \times B$。
当一条加载指令指示 CPU 从主存地址 A 中读一个字时,它将地址 A 发送到高速缓存。如果高速缓存正保存着地址 A 处那个字的副本,它就立即将那个字发回给 CPU。那么高速缓存如何知道它是否包含地址 A 处那个字的副本的呢?高速缓存的结构使得它能通过简单地检查地址位,找到所请求的字,类似于使用极其简单的哈希函数的哈希表。下面介绍它是如何工作的:
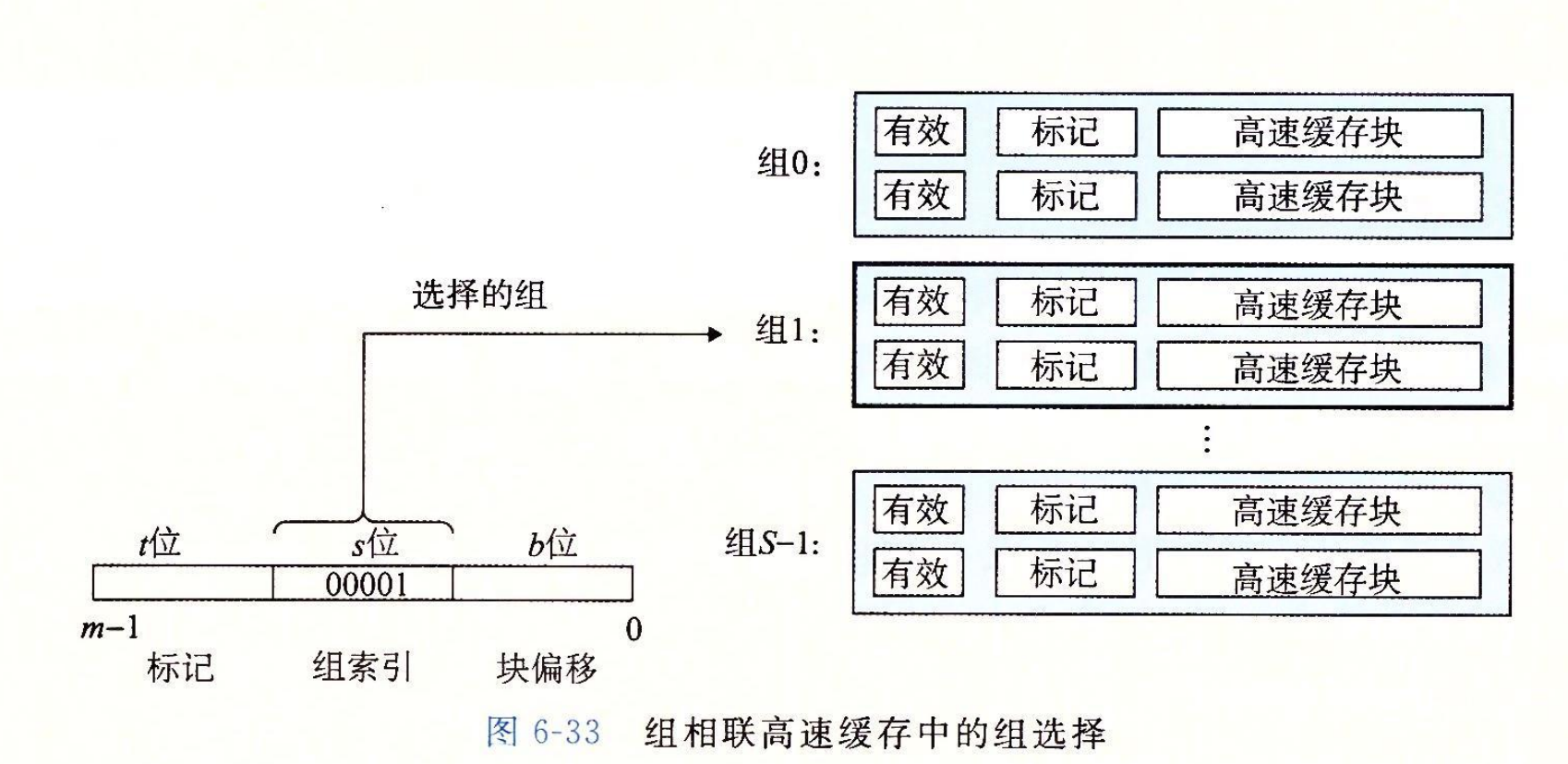
参数 S 和 B 将 m 个地址位分为了三个字段,如图 6-25b 所示。A 中 s 个组索引位是一个到 S 个组的数组的索引。第一个组是组 0,第二个组是组 1,依此类推。组索引位被解释为一个无符号整数,它告诉我们这个字必须存储在哪个组中。一旦我们知道了这个字必须放在哪个组中,A 中的 t 个标记位就告诉我们这个组中的哪一行包含这个字(如果有的话)。当且仅当设置了有效位并且该行的标记位与地址 A 中的标记位相匹配时,组中的这一行才包含这个字。一旦我们在由组索引标识的组中定位了由标号所标识的行,那么 b 个块偏移位给出了在 B 个字节的数据块中的字偏移。
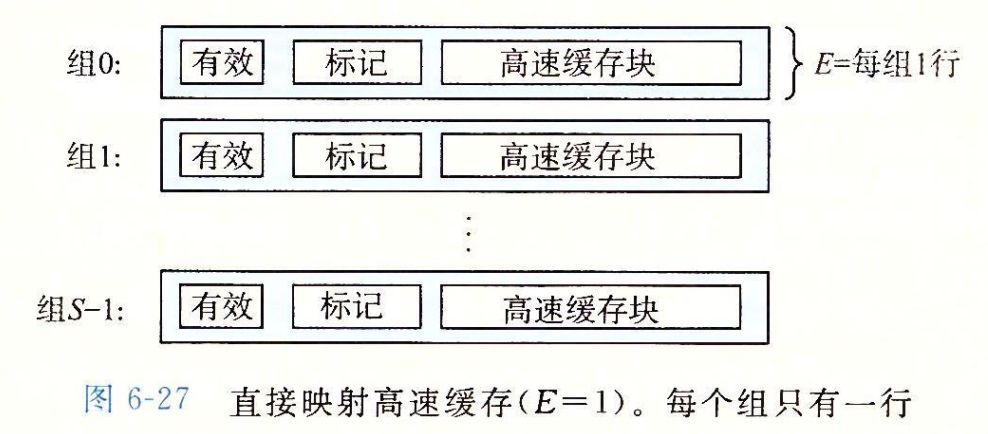
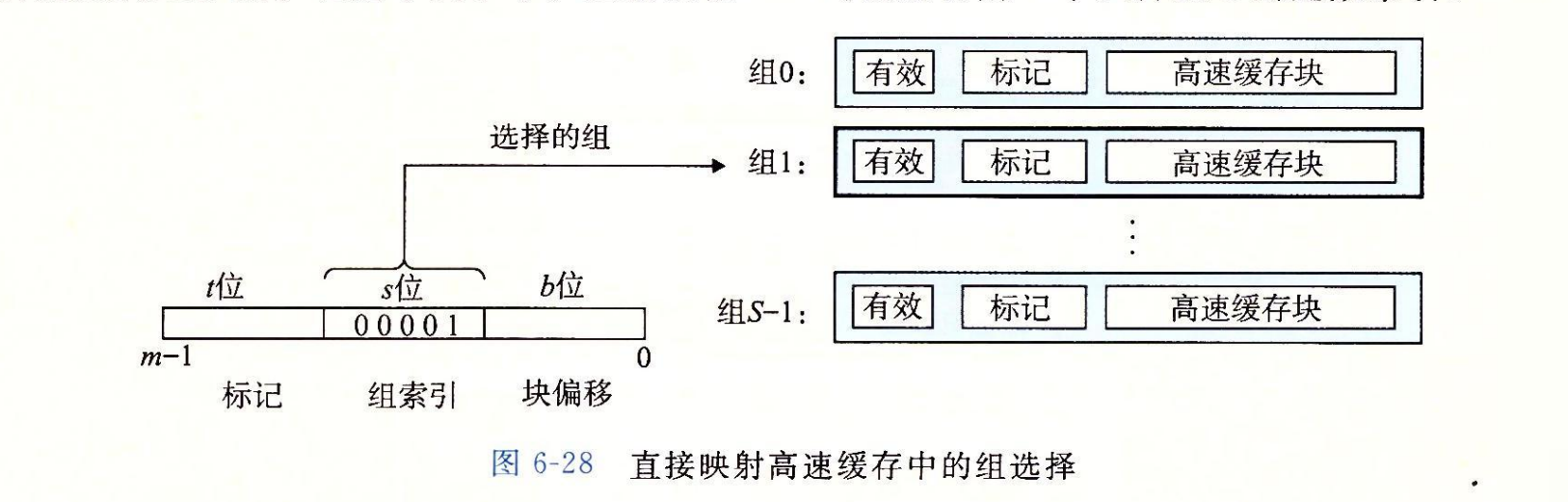
直接映射高级缓存
根据每个组的高速缓存行数 E,高速缓存被分为不同的类。每个组只有一行(E-1)的高速缓存称为直接映射高速缓存(direct-mapped cache)(见图 6-27)。直接映射高速缓存是最容易实现和理解的,所以我们会以它为例来说明一些高速缓存工作方式的通用概念。
假设我们有这样一个系统,它有一个 CPU、一个寄存器文件、一个 L1 高速缓存和一个主存。当 CPU 执行一条读内存字 w 的指令,它向 L1 高速缓存请求这个字。如果 L1 高速缓存有 w 的一个缓存的副本,那么就得到 L1 高速缓存命中,高速缓存会很快抽取出 w,并将它返回给 CPU。否则就是缓存不命中,当 L1 高速缓存向主存请求包含 w 的块的一个副本时,CPU 必须等待。当被请求的块最终从内存到达时,L1 高速缓存将这个块存放在它的一个高速缓存行里,从被存储的块中抽取出字 w,然后将它返回给 CPU。高速缓存确定一个请求是否命中,然后抽取出被请求的字的过程,分为三步:1)组选择;2)行匹配;3)字抽取。
直接映射高速缓存中的组选择
在这一步中,高速缓存从 w 的地址中间抽取出 s 个组索引位。这些位被解释成一个对应于一个组号的无符号整数。换句话来说,如果我们把高速缓存看成是一个关于组的一维数组,那么这些组索引位就是一个到这个数组的索引。图 6-28 展示了直接映射高速缓存的组选择是如何工作的。在这个例子中,组索引位 $00001_2$ 被解释为一个选择组 1 的整数索引。
直接映射高速缓存中的行匹配
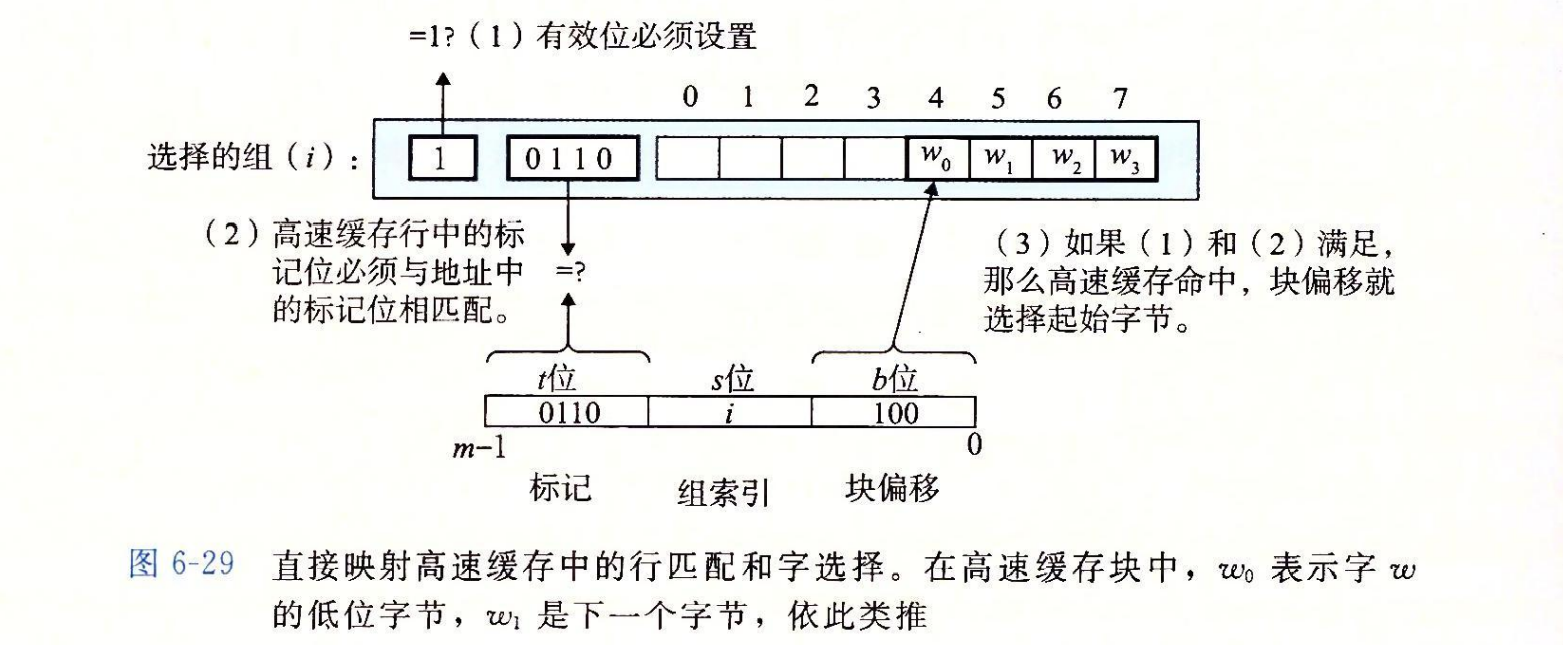
在上一步中我们已经选择了某个组 i,接下来的一步就要确定是否有字 w 的一个副本存储在组 i 包含的一个高速缓存行中。在直接映射高速缓存中这很容易,而且很快,这是因为每个组只有一行。当且仅当设置了有效位,而且高速缓存行中的标记与 w 的地址中的标记相匹配时,这一行中包含 w 的一个副本。
图 6-29 展示了直接映射高速缓存中行匹配是如何工作的。在这个例子中,选中的组中只有一个高速缓存行。这个行的有效位设置了,所以我们知道标记和块中的位是有意义的。因为这个高速缓存行中的标记位与地址中的标记位相匹配,所以我们知道我们想要的那个字的一个副本确实存储在这个行中。换句话说,我们得到一个缓存命中。另一方面,如果有效位没有设置,或者标记不相匹配,那么我们就得到一个缓存不命中。
直接映射高速缓存中的字选择
一旦命中,我们知道 w 就在这个块中的某个地方。最后一步确定所需要的字在块中是从哪里开始的。如图 6-29 所示,块偏移位提供了所需要的字的第一个字节的偏移。就像我们把高速缓存看成一个行的数组一样,我们把块看成一个字节的数组,而字节偏移是到这个数组的一个索引。在这个示例中,块偏移位是 1002,它表明 w 的副本是从块中的字节 4 开始的(我们假设字长为 4 字节)。
直接映射高速缓存中不命中时的行替换
如果缓存不命中,那么它需要从存储器层次结构中的下一层取出被请求的块,然后将新的块存储在组索引位指示的组中的一个高速缓存行中。一般而言,如果组中都是有效高速缓存行了,那么必须要驱逐出一个现存的行。对于直接映射高速缓存来说,每个组只包含有一行,替换策略非常简单:用新取出的行替换当前的行。
综合:运行中的直接映射高速缓存
高速缓存用来选择组和标识行的机制极其简单,因为硬件必须在几个纳秒的时间内完成这些工作。不过,用这种方式来处理位是很令人困惑的。一个具体的例子能帮助解释清楚这个过程。假设我们有一个直接映射高速缓存,描述如下
换句话说,高速缓存有 4 个组,每个组一行,每个块 2 个字节,而地址是 4 位的。我们还假设每个字都是单字节的。当然,这样一些假设完全是不现实的,但是它们能使示例保持简单。
当你初学高速缓存时,列举出整个地址空间并划分好位是很有帮助的,就像我们在图 6-30 对 4 位的示例所做的那样。关于这个列举出的空间,有一些有趣的事情值得注意:
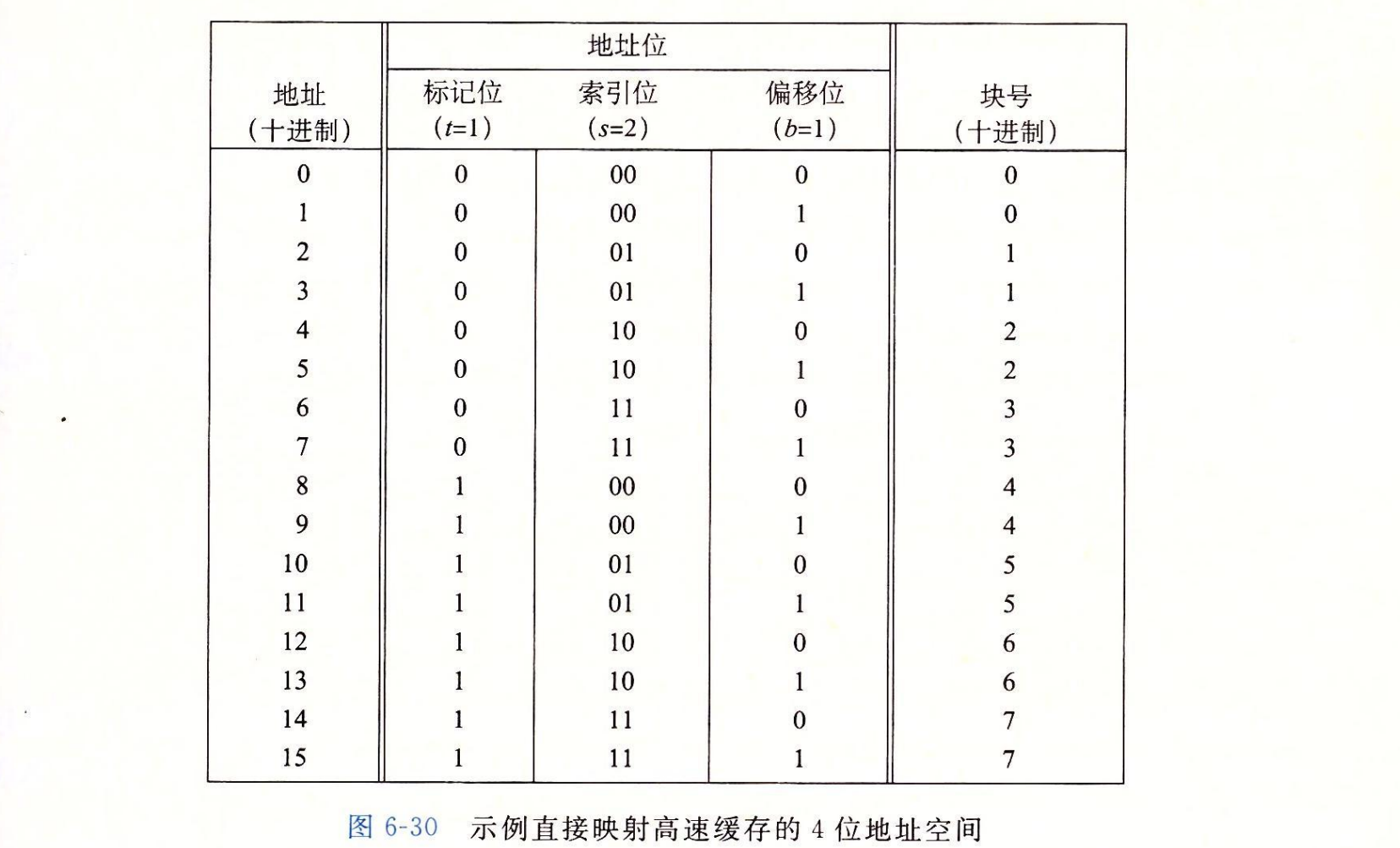
- 标记位和索引位连起来唯一地标识了内存中的每个块。例如,块 0 是由地址 0 和 1 组成的,块 1 是由地址 2 和 3 组成的,块 2 是由地址 4 和 5 组成的,依此类推。
- 因为有 8 个内存块,但是只有 4 个高速缓存组,所以多个块会映射在同一个高速缓存组(即它们有相同的组索引)。例如,块 0 和 4 都映射到组 0,块 1 和 5 都映射到组 1,等等。
- 映射到同一个高速缓存组的块由标记位唯一地标识。例如,块 0 的标记位为 0,而块 4 的标记位为 1,块 1 的标记位为 0,而块 5 的标记位为 1,以此类推。
让我们来模拟一下当 CPU 执行一系列读的时候,高速缓存的执行情况。

内存抖动
冲突不命中在真实的程序中很常见,会导致令人困惑的性能问题。当程序访问大小为 2 的幂的数组时,直接映射高速缓存中通常会发生冲突不命中。例如,考虑一个计算两个向量点积的函数:
float dotprod(float x[8], float y[8])
{
float sum = 0.0;
int i;
for (i = 0; i < 8; i++) {
sum += x[i] * y[i];
}
return sum;
}对于 x 和 y 来说,这个函数有良好的空间局部性,因此我们期望它的命中率会比较高。每当缓存不命中时,会将内存块加入当高速缓存当中,如下图

不幸的是,并不总是如此。假设浮点数是 4 个字节,x 被加载到从地址 0 开始的 32 字节连续内存中,而 y 紧跟在 x 之后,从地址 32 开始。为了简便,假设一个块是 16 个字节(足够容纳 4 个浮点数),高速缓存由两个组组成,高速缓存的整个大小为 32 字节。我们会假设变量 sum 实际上存放在一个 CPU 寄存器中,因此不需要内存引用。根据这些假设每个 x[i] 和 y[i] 会映射到相同的高速缓存组:
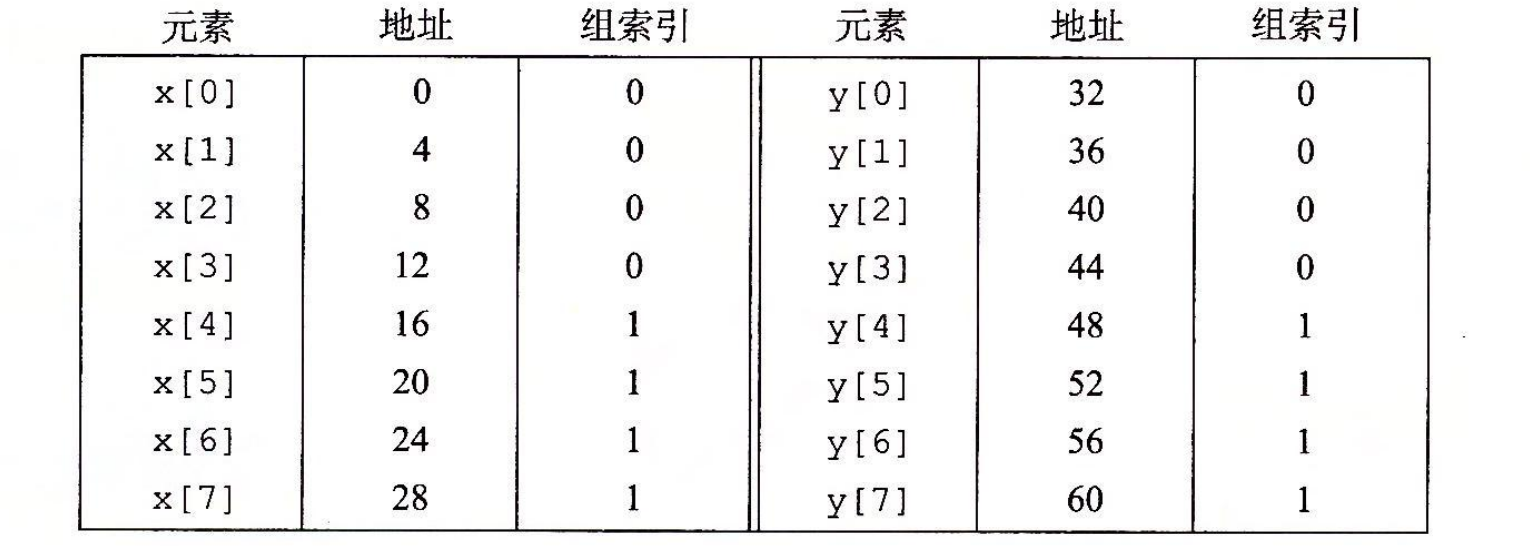
在运行时,循环的第一次迭代引用 x[0],缓存不命中会导致包含 x[0]~x[3] 的块被加载到组 0。接下来是对 y[0] 的引用,又一次缓存不命中,导致包含 y[0]~y[3] 的块被复制到组 0,覆盖前一次引用复制进来的 x 的值。在下一次迭代中,对 x[1] 的引用不命中,导致 x[0]~x[3] 的块被加载回组 0,覆盖掉 y[0]~y[3] 的块。因而现在我们就有了一个冲突不命中,而且实际上后面每次对 x 和 y 的引用都会导致冲突不命中,因为我们在 x 和 y 的块之间抖动(thrash)。术语“抖动”描述的是这样一种情况,即高速缓存反复地加载和驱逐相同的高速缓存块的组。
简要来说就是,即使程序有良好的空间局部性,而且我们的高速缓存中也有足够的空间来存放 x[i] 和 y[i] 的块,每次引用还是会导致冲突不命中,这是因为这些块被映射到了同一个高速缓存组。这种抖动导致速度下降 2 或 3 倍并不稀奇。另外,还要注意虽然我们的示例极其简单,但是对于更大、更现实的直接映射高速缓存来说,这个问题也是很真实的。
幸运的是,一旦程序员意识到了正在发生什么,就很容易修正抖动问题。一个很简单的方法是在每个数组的结尾放 B 字节的填充。例如,不是将 x 定义为 float x[8],而是定义成 float x[12]。假设在内存中 y 紧跟在 x 后面,我们有下面这样的从数组元素到组的映射:
在 x 结尾加了填充,x[i] 和 y[i] 现在就映射到了不同的组,消除了抖动冲突不命中。
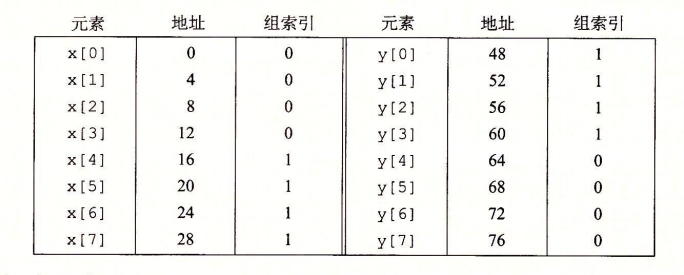
为什么用中间的位做索引?
如果高位用做索引,那么一些连续的内存块就会映射到相同的高速缓存块。例如,在图中,头四个块映射到第一个高速缓存组,第二个四个块映射到第二个组,依此类推。如果一个程序有良好的空间局部性,顺序扫描一个数组的元素,那么在任何时刻,高速缓存都只保存着一个块大小的数组内容。这样对高速缓存的使用效率很低。相比较而言,以中间位作为索引,相邻的块总是映射到不同的高速缓存行。在这里的情况中,高速缓存能够存放整个大小为C的数组片,这里C是高速缓存的大小。
组相联高速缓存
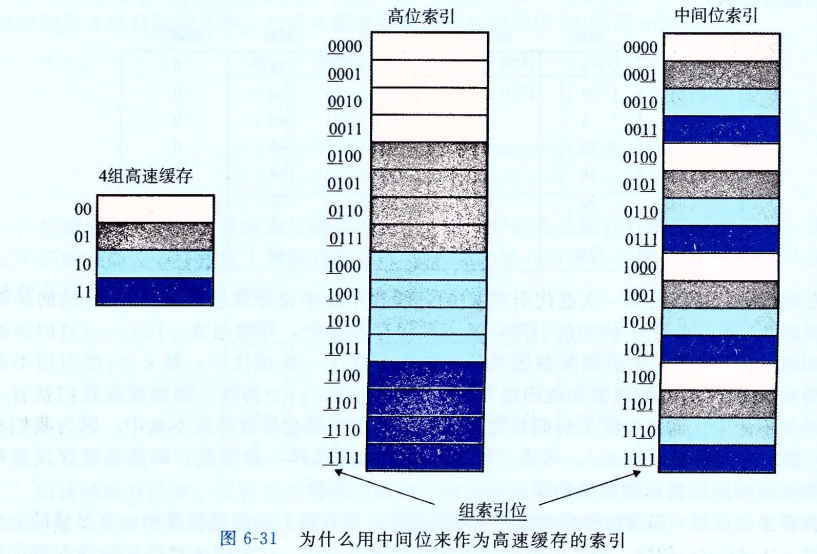
直接映射高速缓存中冲突不命中造成的问题源于每个组只有一行(或者,按照我们的术语来描述就是E=1)这个限制。组相联高速缓存(set associative cache)放松了这条限制,所以每个组都保存有多于一个的高速缓存行。一个 1<E<C/B 的高速缓存通常称为 E 路组相联高速缓存。图 6-32 展示了一个 2 路组相联高速缓存的结构。
组相联高速缓存中的组选择
它的组选择与直接映射高速缓存的组选择一样,组索引位标识组。图 6-33 总结了这个原理。
组相联高速缓存中的行匹配和字选择
组相联高速缓存中的行匹配比直接映射高速缓存中的更复杂,因为它必须检查多个行的标记位和有效位,以确定所请求的字是否在集合中。传统的内存是一个值的数组,以地址作为输入,并返回存储在那个地址的值。另一方面,相联存储器是一个(key,value)对的数组,以 key 为输入,返回与输入的 key 相匹配的(key,value)对中的 value 值。因此,我们可以把组相联高速缓存中的每个组都看成一个小的相联存储器,key 是标记和有效位,而 value 就是块的内容。
图 6-34 展示了相联高速缓存中行匹配的基本思想。这里的一个重要思想就是组中的任何一行都可以包含任何映射到这个组的内存块。所以高速缓存必须搜索组中的每一行,寻找一个有效的行,其标记与地址中的标记相匹配。如果高速缓存找到了这样一行,那么我们就命中,块偏移从这个块中选择一个字,和前面一样。
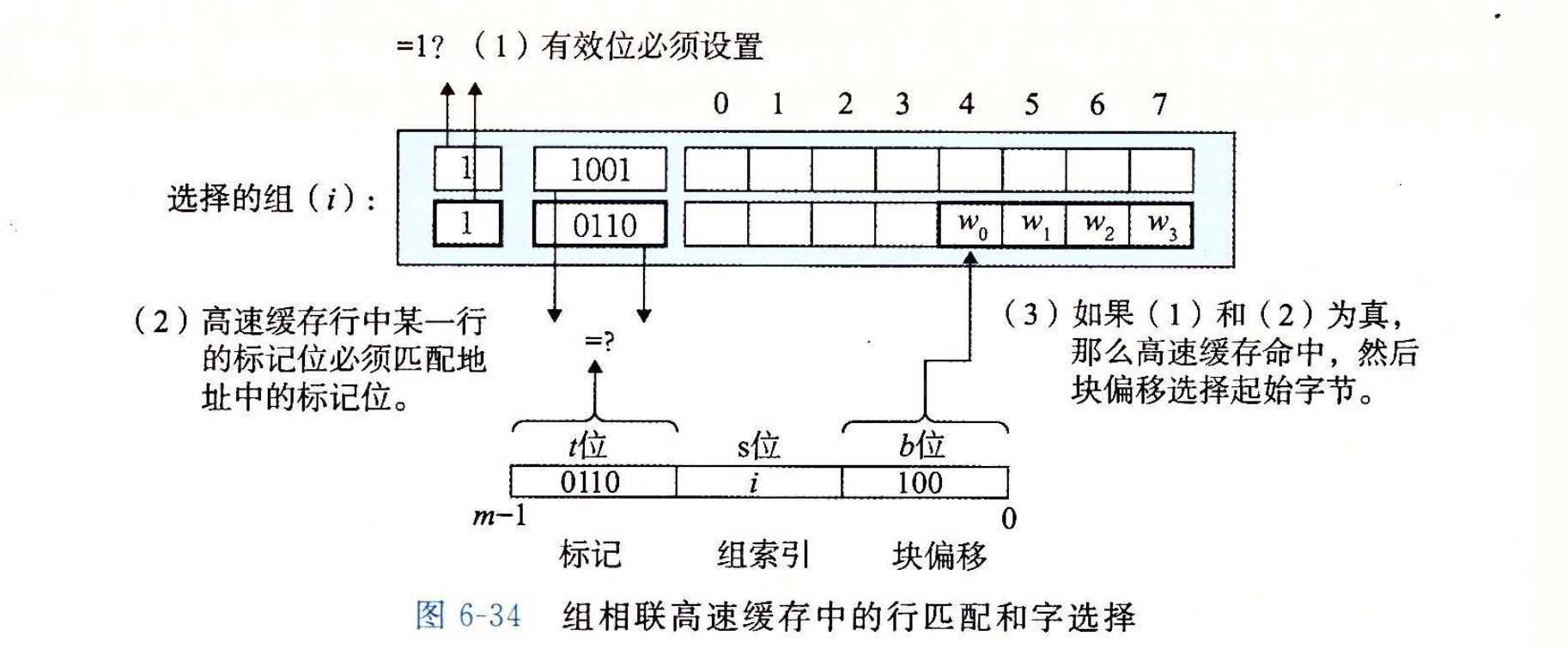
组相联高速缓存中不命中时的行替换
如果 CPU 请求的字不在组的任何一行中,那么就是缓存不命中,高速缓存必须从内存中取出包含这个字的块。不过,一旦高速缓存取出了这个块,该替换哪个行呢?当然,如果有一个空行,那它就是个很好的候选。但是如果该组中没有空行,那么我们必须从中选择一个非空的行,希望 CPU 不会很快引用这个被替换的行。
程序员很难在代码中利用高速缓存替换策略,所以在此我们不会过多地讲述其细节。最简单的替换策略是随机选择要替换的行。其他更复杂的策略利用了局部性原理,以使在比较近的将来引用被替换的行的概率最小。例如,最不常使用(Least-Frequently-Used,LFU)策略会替换在过去某个时间窗口内引用次数最少的那一行。最近最少使用(Least-Recently-Used,LRU)策略会替换最后一次访问时间最久远的那一行。所有这些策略都需要额外的时间和硬件。但是,越往存储器层次结构下面走,远离 CPU,一次不命中的开销就会更加昂贵,用更好的替换策略使得不命中最少也变得更加值得了。
全相连高速缓存
全相联高速缓存(fully associative cache)是由一个包含所有高速缓存行的组(即 E=C/B)组成的。图 6-35 给出了基本结构。
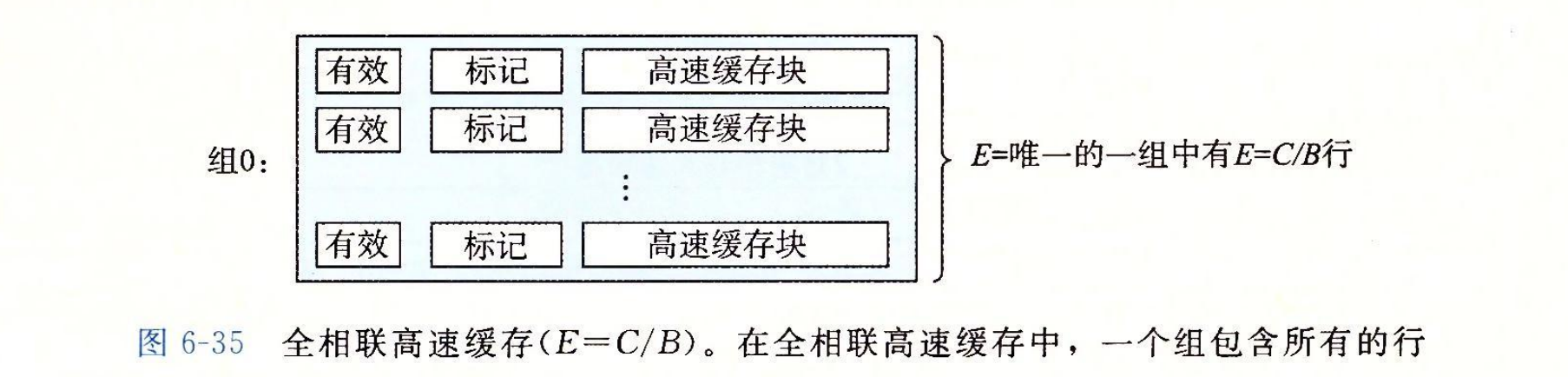
全相联高速缓存中的组选择
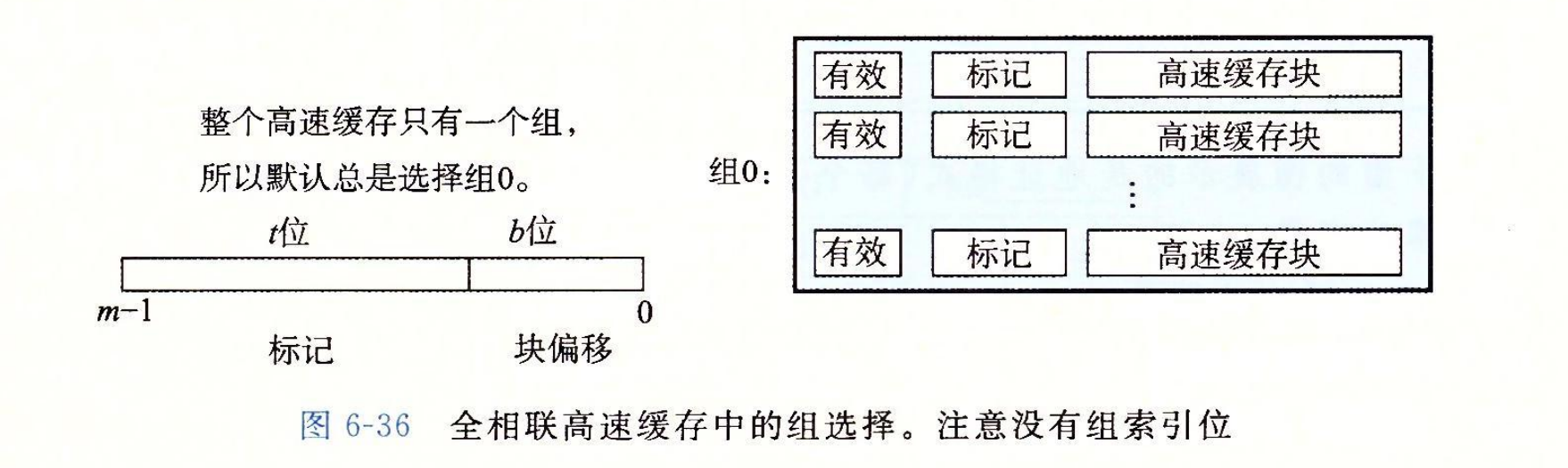
全相联高速缓存中的组选择非常简单,因为只有一个组,图 6-36 做了个小结。注意地址中没有组索引位,地址只被划分成了一个标记和一个块偏移。
全相联高速缓存中的行匹配和字选择
全相联高速缓存中的行匹配和字选择与组相联高速缓存中的是一样的,如图 6-37 所示。它们之间的区别主要是规模大小的问题。
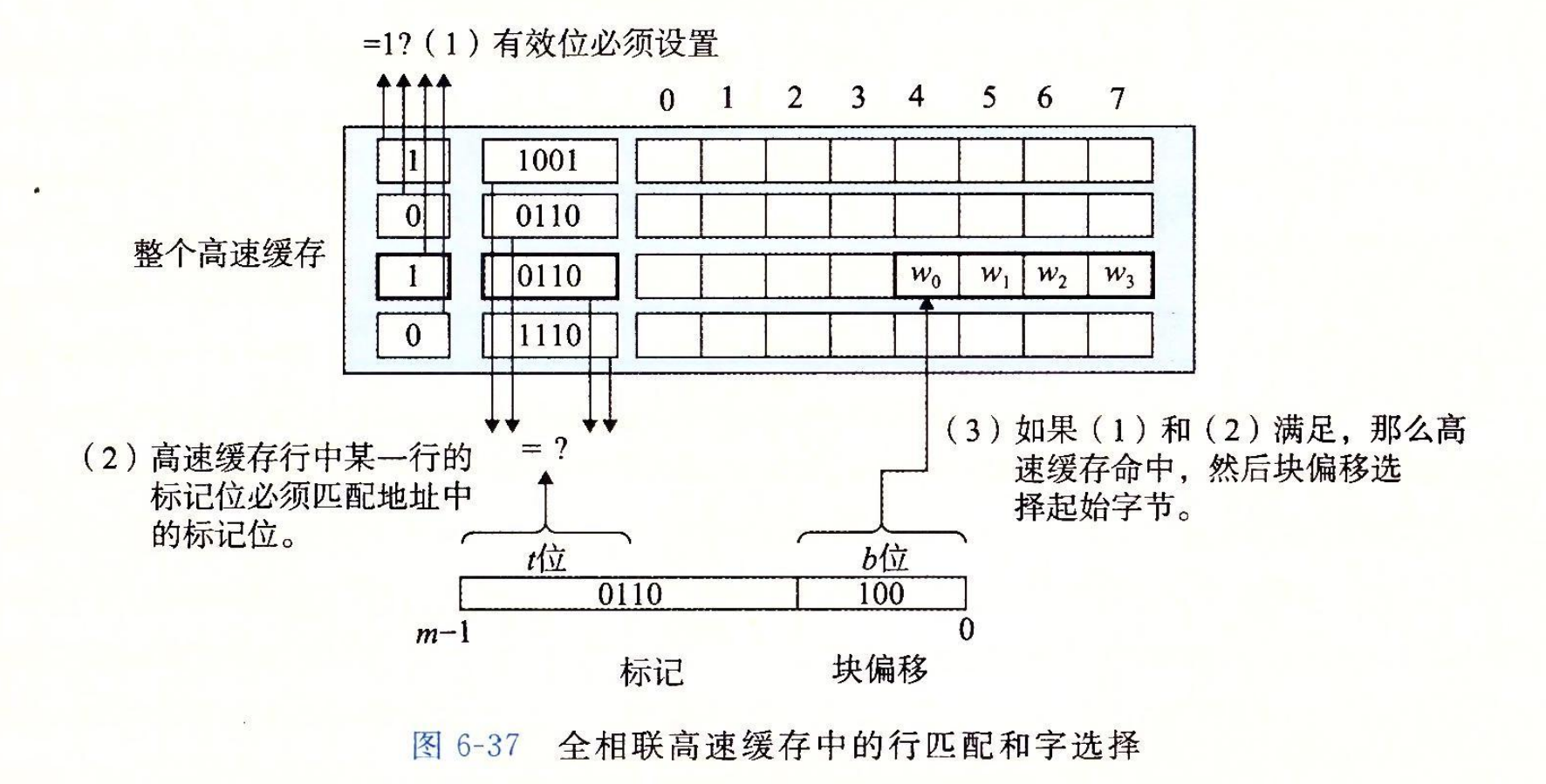
因为高速缓存电路必须并行地搜索许多相匹配的标记,构造一个又大又快的相联高速缓存很困难,而且很昂贵。因此,全相联高速缓存只适合做小的高速缓存,例如虚拟内存系统中的翻译备用缓冲器(TLB)。
有关写的问题
正如我们看到的,高速缓存关于读的操作非常简单。首先,在高速缓存中查找所需字 w 的副本。如果命中,立即返回字 w 给 CPU。如果不命中,从存储器层次结构中较低层中取出包含字 w 的块,将这个块存储到某个高速缓存行中(可能会驱逐一个有效的行),然后返回字 w。
写的情况就要复杂一些了。假设我们要写一个已经缓存了的字 w(写命中,write hit)。在高速缓存更新了它的 w 的副本之后,怎么更新 w 在层次结构中紧接着低一层中的副本呢?最简单的方法,称为直写(write-through),就是立即将 w 的高速缓存块写回到紧接着的低一层中。虽然简单,但是直写的缺点是每次写都会引起总线流量。另一种方法,称为写回(write-back),尽可能地推迟更新,只有当替换算法要驱逐这个更新过的块时,才把它写到紧接着的低一层中。由于局部性,写回能显著地减少总线流量,但是它的缺点是增加了复杂性。高速缓存必须为每个高速缓存行维护一个额外的修改位(dirty bit),表明这个高速缓存块是否被修改过。
另一个问题是如何处理写不命中。一种方法,称为写分配(write-allocate),加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块。写分配试图利用写的空间局部性,但是缺点是每次不命中都会导致一个块从低一层传送到高速缓存。另一种方法,称为非写分配(not-write-allocate),避开高速缓存,直接把这个字写到低一层中。直写高速缓存通常是非写分配的。写回高速缓存通常是写分配的。
为写操作优化高速缓存是一个细致而困难的问题,在此我们只略讲皮毛。细节随系统的不同而不同,而且通常是私有的,文档记录不详细。
一个真实的高速缓存层次结构的解剖
到目前为止,我们一直假设高速缓存只保存程序数据。不过,实际上,高速缓存既保存数据,也保存指令。只保存指令的高速缓存称为 i-cache。只保存程序数据的高速缓存称为 d-cache。既保存指令又包括数据的高速缓存称为统一的高速缓存(unified cache)。现代处理器包括独立的 i-cache 和 d-cache。这样做有很多原因。有两个独立的高速缓存,处理器能够同时读一个指令字和一个数据字。i-cache 通常是只读的,因此比较简单。通常会针对不同的访问模式来优化这两个高速缓存,它们可以有不同的块大小,相联度和容量。使用不同的高速缓存也确保了数据访问不会与指令访问形成冲突不命中,反过来也是一样,代价就是可能会引起容量不命中增加。
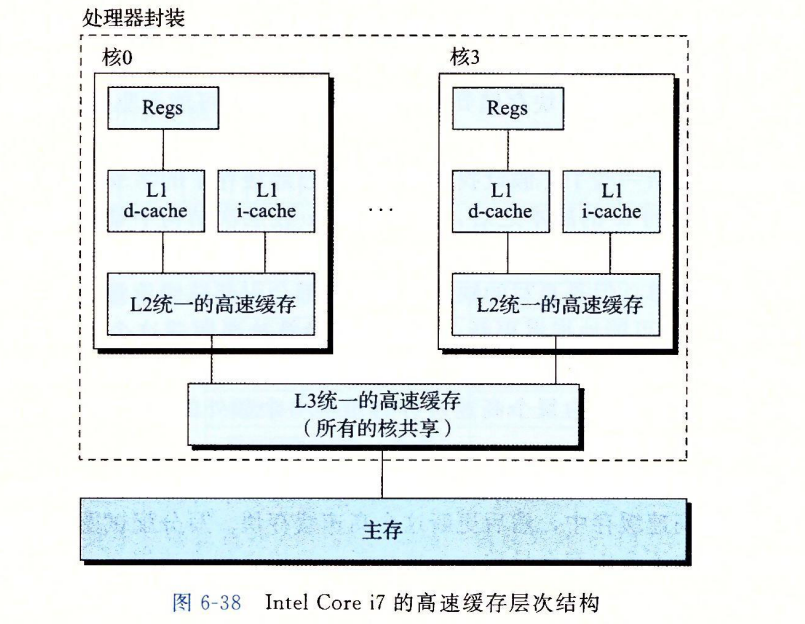
图 6-38 给出了 Intel Core i7 处理器的高速缓存层次结构。每个 CPU 芯片有四个核。每个核有自己私有的 L1 i-cache、 L1 d-cache 和 L2 统一的高速缓存。所有的核共享片上 L3 统一的高速缓存。这个层次结构的一个有趣的特性是所有的 SRAM 高速缓存存储器都在 CPU 芯片上。
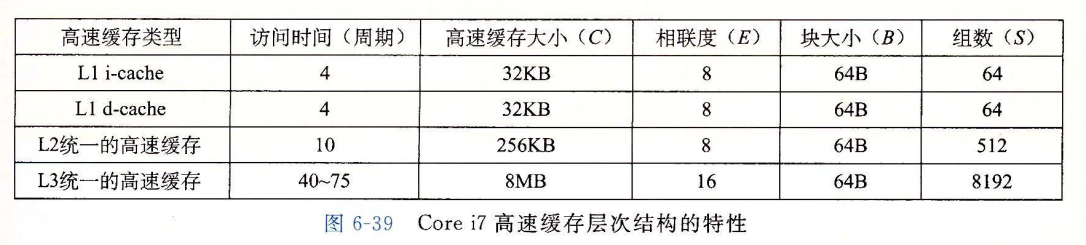
图 6-39 总结了 Core i7 高速缓存的基本特性。
高速缓存参数的性能影响
有许多指标来衡量高速缓存的性能:
- 不命中率(miss rate)。 在一个程序执行或程序的一部分执行期间,内存引用不命中的比率。它是这样计算的:不命中数量/引用数量。
- 命中率(hit rate)。命中的内存引用比率。它等于 $1-不命中率$。
- 命中时间(hit time)。 从高速缓存传送一个字到 CPU 所需的时间,包括组选择、行确认和字选择的时间。对于 L1 高速缓存来说,命中时间的数量级是几个时钟周期。
- 不命中处罚(miss penalty)。 由于不命中所需要的额外的时间。L1 不命中需要从 L2 得到服务的处罚,通常是数 10 个周期;从 L3 得到服务的处罚,50 个周期;从主存得到的服务的处罚,200 个周期。
优化高速缓存的成本和性能的折中是一项很精细的工作,它需要在现实的基准程序代码上进行大量的模拟,因此超出了我们讨论的范围。不过,还是可以认识一些定性的折中考量的。
高速缓存大小的影响
一方面,较大的高速缓存可能会提高命中率。另一方面,使大存储器运行得更快总是要难一些的。结果,较大的高速缓存可能会增加命中时间。这解释了为什么L1高速缓存
比L2高速缓存小,以及为什么L2高速缓存比L3高速缓存小。块大小的影响
大的块有利有弊。一方面,较大的块能利用程序中可能存在的空间局部性,帮助提高命中率。不过,对于给定的高速缓存大小,块越大就意味着高速缓存行数越少,这会损害时间局部性比空间局部性更好的程序中的命中率。较大的块对不命中处罚也有负面影响,因为块越大,传送时间就越长。现代系统(如 Core i7)会折中使高速缓存块包含 64 个字节。相联度的影响
这里的问题是参数 E 选择的影响,E 是每个组中高速缓存行数。较高的相联度(也就是 E 的值较大)的优点是降低了高速缓存由于冲突不命中出现抖动的可能性。不过,较高的相联度会造成较高的成本。较高的相联度实现起来很昂贵,而且很难使之速度变快。每一行需要更多的标记位,每一行需要额外的 LRU 状态位和额外的控制逻辑。较高的相联度会增加命中时间,因为复杂性增加了,另外,还会增加不命中处罚,因为选择牺牲行的复杂性也增加了。相联度的选择最终变成了命中时间和不命中处罚之间的折中。传统上,努力争取时钟频率的高性能系统会为 L1 高速缓存选择较低的相联度(这里的不命中处罚只是几个周期),而在不命中处罚比较高的较低层上使用比较小的相联度。例如,Intel Core i7 系统中,L1 和 L2 高速缓存是 8 路组相联的,而 L3 高速缓存是 16 路组相联的。
写策略的影响
直写高速缓存比较容易实现,而且能使用独立于高速缓存的写缓冲区(write buffer),用来更新内存。此外,读不命中开销没这么大,因为它们不会触发内存写。另一方面,写回高速缓存引起的传送比较少,它允许更多的到内存的带宽用于执行 DMA 的 I/O 设备。此外,越往层次结构下面走,传送时间增加,减少传送的数量就变得更加重要。一般而言,高速缓存越往下层,越可能使用写回而不是直写。
高速缓存运作方式
在从内存往寄存器读取数据时,数据先被送往高速缓存,再被送往寄存器。所读取的数据的大小取决于缓存块大小(cache line size)的值,该值由各个 CPU 规定。假设缓存块的大小为 10 字节,高速缓存的容量为 50 字节,并且存在两个长度为 10 字节的寄存器(R0与R1)。在这样的运行环境下,把内存地址 300 上的数据读取到 R0 时的情形如下图所示。
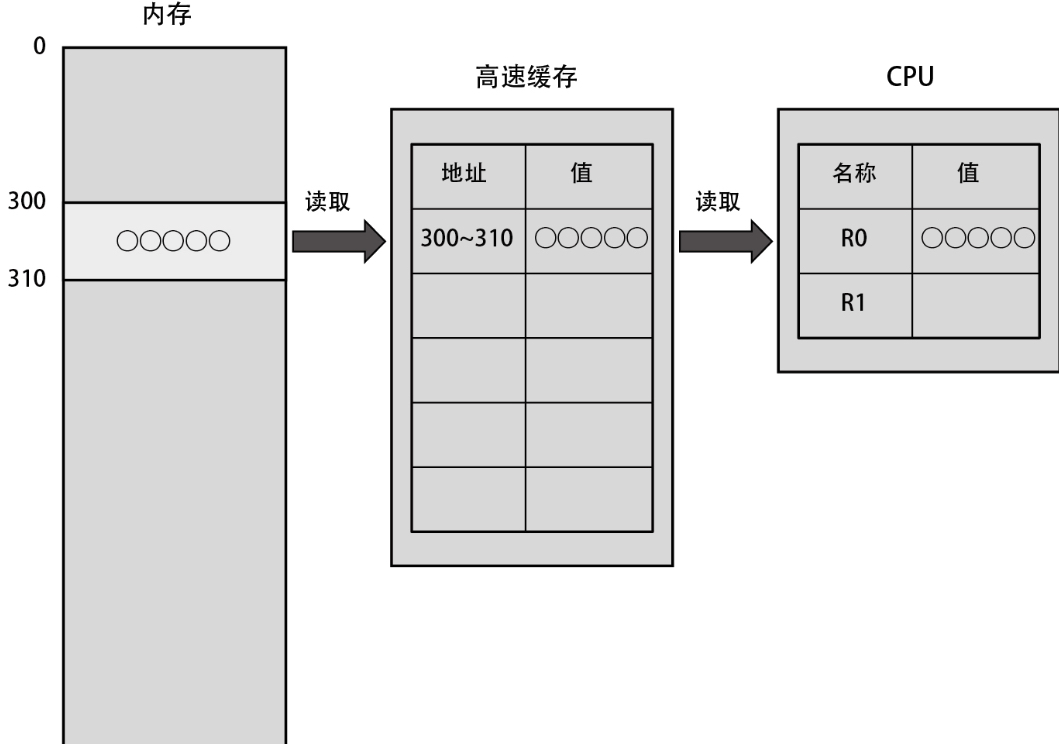
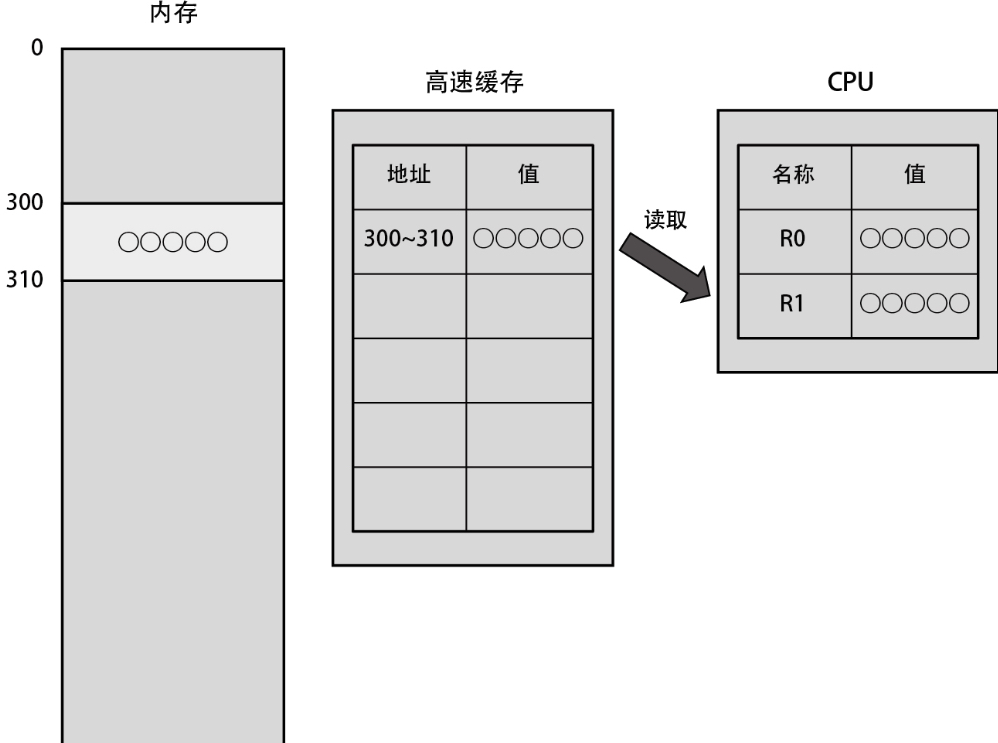
此后,当 CPU 需要再次读取地址 300 上的数据时,比如需要再次把同样的数据读取到 R1 时,将不用从内存读取数据,只需读取已经存在于高速缓存上的数据即可,如下图所示。
当我们改写 R0 上的数据时,会发生什么呢?
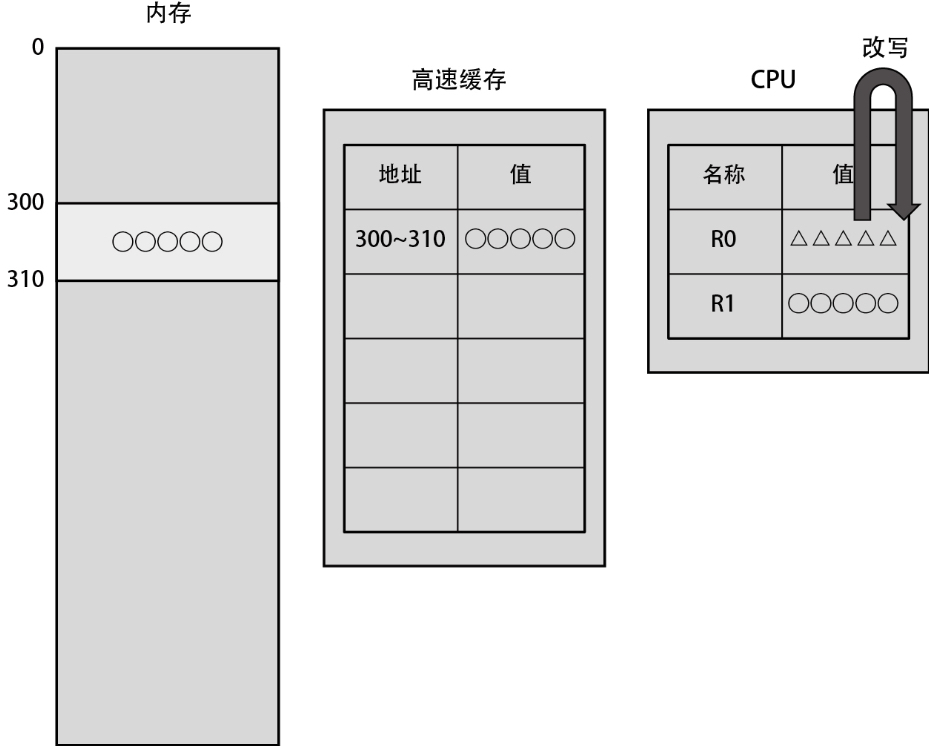
此后,当需要将寄存器上的数据重新写回到地址 300 上时,首先会把改写后的数据写入高速缓存,如下图所示。此时依然以缓存块大小为单位写入数据。然后,为这些缓存块添加一个标记,以表明这部分从内存读取的数据被改写了。通常我们会称这些被标记的缓存块“脏了”。
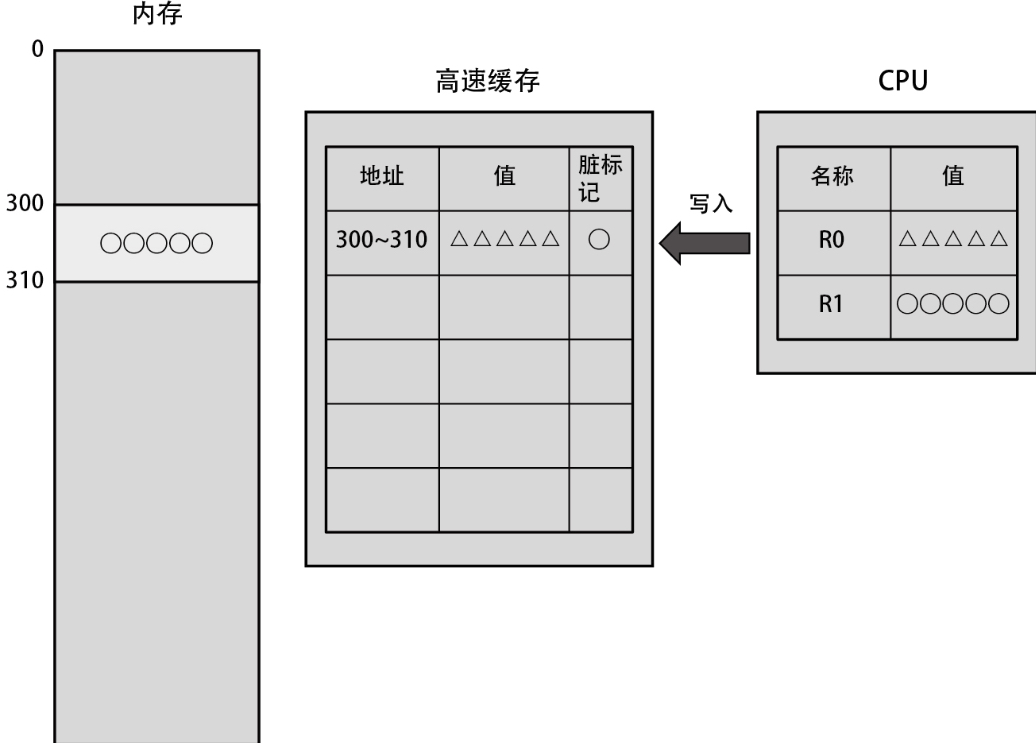
这些被标记的数据会在写入高速缓存后的某个指定时间点,通过后台处理写入内存。随之,这些缓存块就不再脏了,如下图所示。也就是说,只需要访问速度更快的高速缓存,即可完成上图中的写入操作。
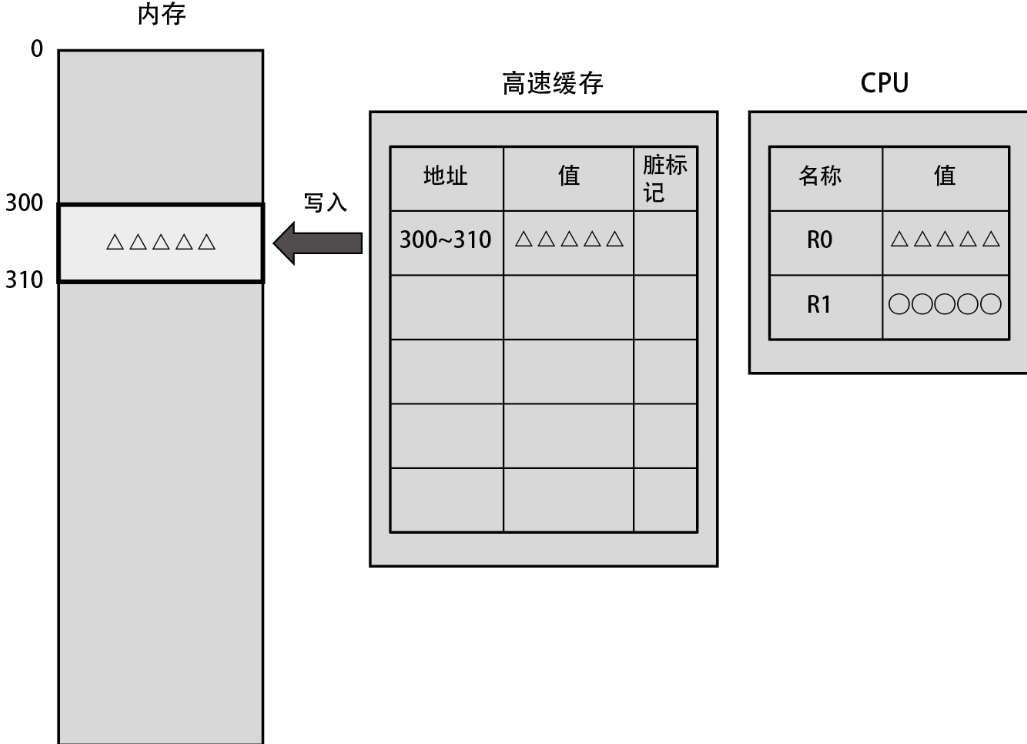
在进程运行一段时间后,高速缓存中就会充满各种各样的数据,如下图所示。
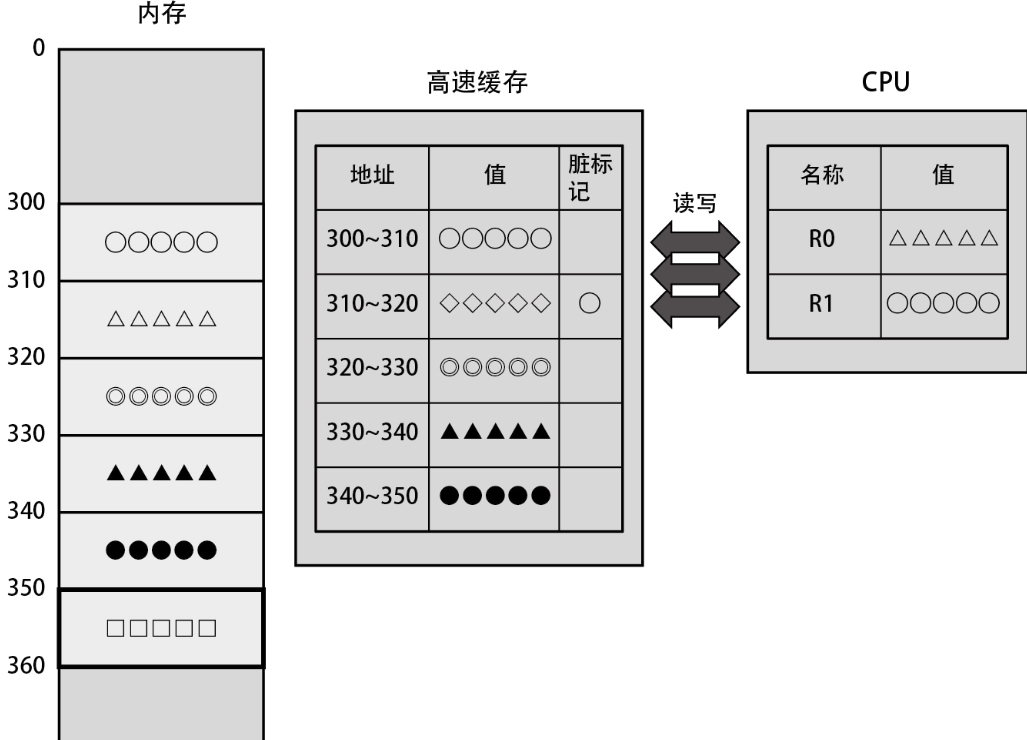
在这样的状态下,当 CPU 仅访问位于高速缓存上的数据时,访问速度比没有高速缓存时快得多,因为数据访问速度达到了高速缓存的读写速度。