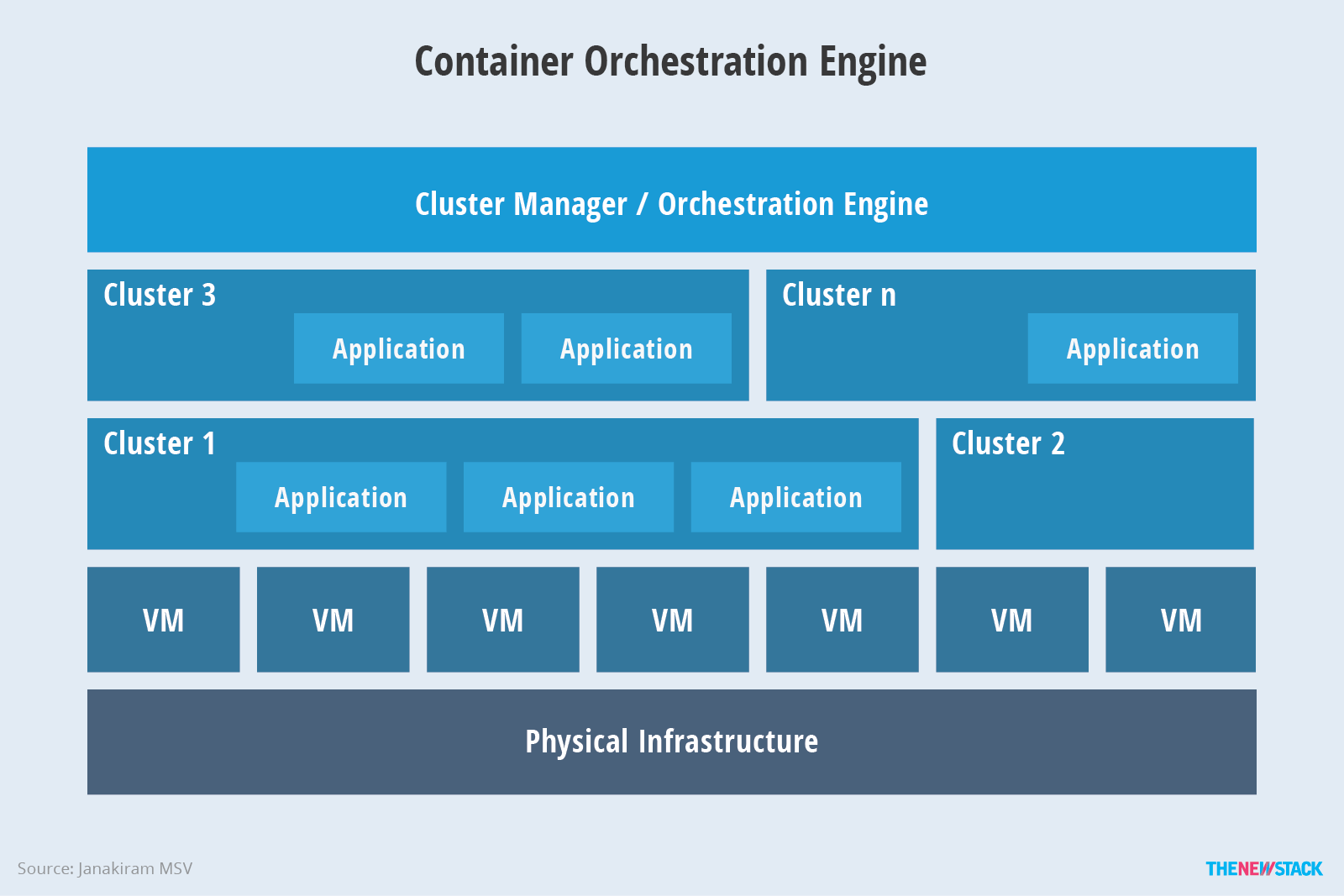
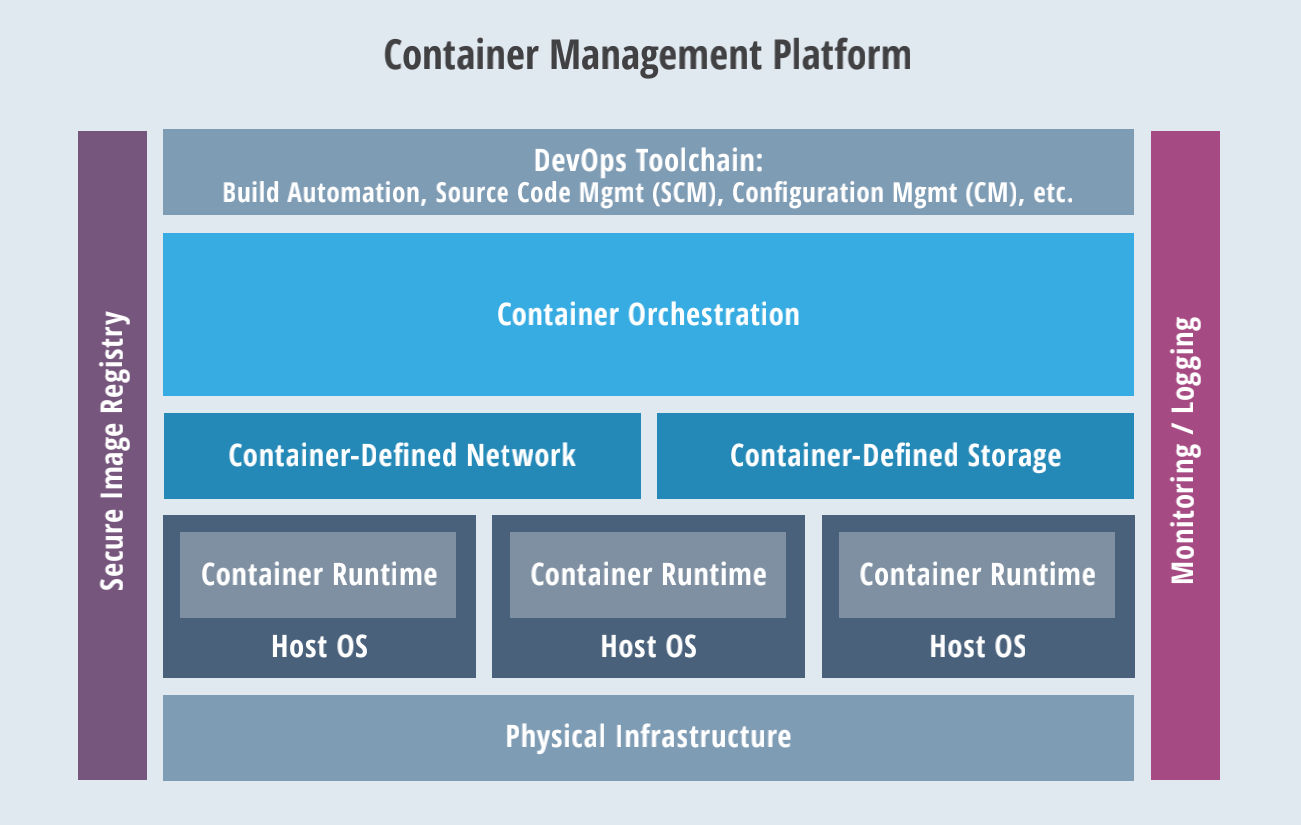
容器编排(Container orchestration)提供了一个开放有影响力的模型,包含打包(packaging)、发布(deployment)、隔离(isolation)、服务发现(service discovery)、伸缩(scaling)和滚动更新(rolling upgrades)。
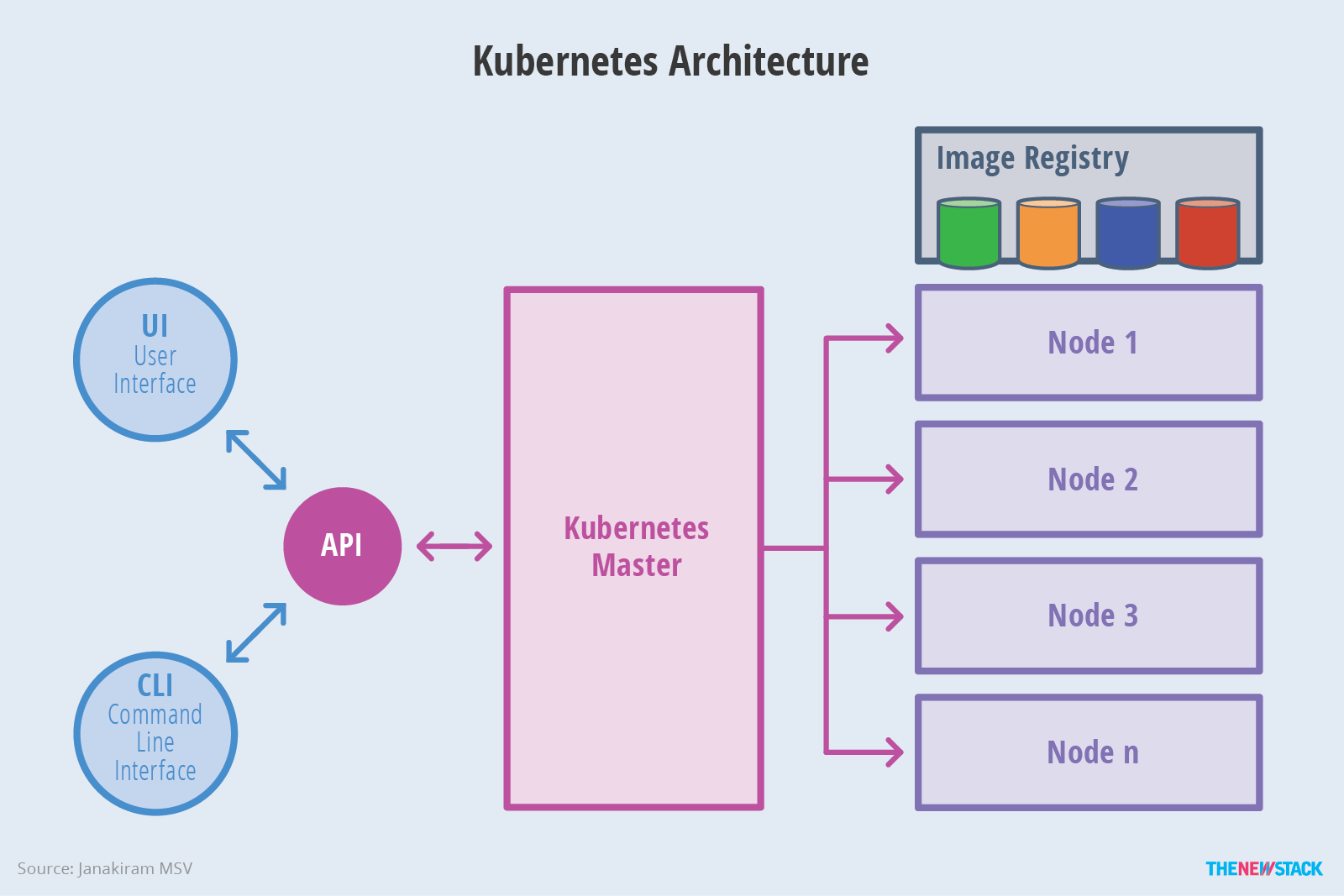
Kubernetes Architecture
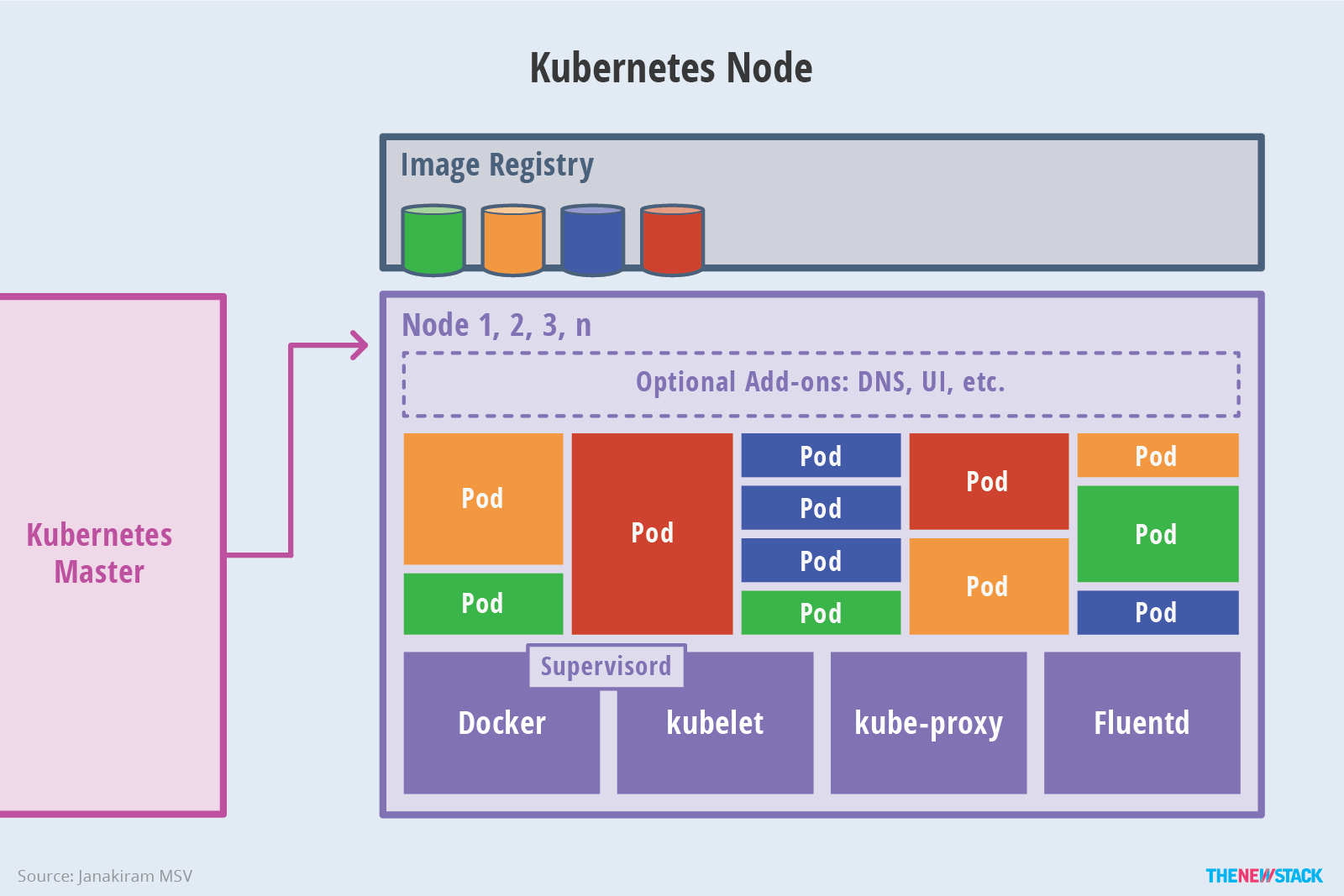
Kubernetes Architecture 提供了一个 flexible, loosely-coupled 的服务发现机制。像大多数分布式计算平台一样,Kubernetes 集群提供了at least one master and multiple compute nodes 的结构。master 可响应暴露的 the application program interface (API),调度 deployments 和管理 cluster。而每个 node 上运行着 container runtime 和与 master 通信的 Agent。当然为了更好的了解和记录 Application 的状态,node 上也会运行一些诸如 logging、monitoring、service discovery 等的可扩展插件。Nodes 可以理解为 kubernetes 集群的工作负载,暴露计算、网络、存储资源给应用,并可以在任何环境下运行。
作为 Kubernetes 核心管理单元,pod 中可包含多个 Docker Container。Kubernetes 通过 pod 的概念划分了共享上下文和资源。pod 的组机制弥补了容器化(containerization)和虚拟化(virtualization)的差异,使其可以一起运行多个相互依赖的进程。在运行时,Pods 可通过创建 replica sets 伸缩,确保总有期望数量的 pod 在运行。
Replica sets 中定义了期望的伸缩性和可用性。单个 pod 或 Replica set 可以将服务暴露给 Consumers,Services 可通过 the discovery of pods 将一系列 Pods 通过指定的规则联系起来。这些将 Pods 和 Services 联系起来的键值对被叫做 labels,相对应匹配的规则叫做 selectors。
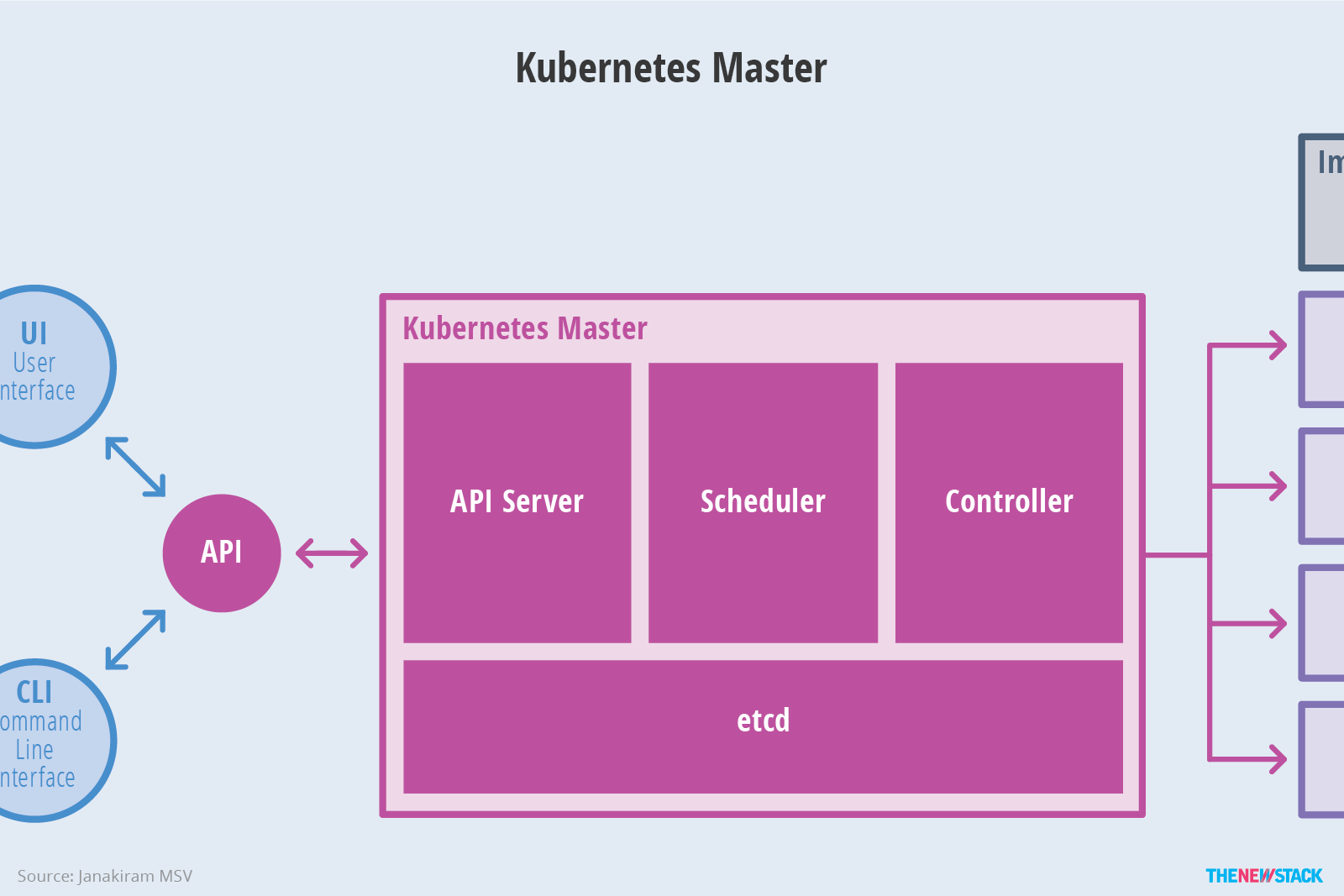
The definition of Kubernetes objects(such as pods, replica sets and services)会被提交给 master。基于定义文件和可用资源,master 会调度特定 node 上的 pod。node 则会从 the container image registry 上拉取容器镜像并且协调本地 Container Runtime 运行容器。
etcd 是一个开源分布式 KV 数据库。master 会查询 etcd 中存储的 nodes、pods、containers 实时变化的状态。
Kubernetes 的这种架构通过在应用程序和底层基础设施之间创建抽象,使其模块化和可伸缩。
Key Design Principles
Kubernetes 设计了 scalability, availability, security, portability 方面的规则,通过在可用资源之间有效地安排工作,优化了底层架构的成本。
工作负载伸缩(Workload Scalability)
应用程序发布在 Kubernetes 被打包为 microservices。这些 microservices 被组织为聚合了 Containers 的 Pods。每个 container 被设计为执行一个 Task,而 Pod 也可被分为无状态 Container 组成的 Pod 和有状态 Container 组成的 Pod。无状态 Pods 能轻松的被按需伸缩或者动态扩容。
Kubernetes 1.4 支持了根据 CPU utilization 动态扩容,未来还可能支持根据 metrics 和定义的伸缩和吞吐规则扩容
高可用(High Availability)
当代的工作负载要求基础设施和应用程序级别的可用性。在大规模的集群中,一切都很容易发生故障,这使得生产工作负载的高可用性变得非常必要。虽然大多数容器编排引擎和 PaaS 产品都提供应用程序可用性,但 Kubernetes 的目的是同时处理基础设施和应用程序的可用性。
在 application front,Kubernetes 通过 replica sets、replication controllers、和 stateful sets 来确保高可用性。Operators 可以声明在任何给定时间点需要运行的 pod 的最小数量。如果 container 或 pod 由于错误而崩溃,声明性策略可以将部署恢复到所需的配置。可以通过 stateful sets 配置有状态工作负载以实现高可用性。
对于 infrastructure availability,Kubernetes 提供了非常广泛的 storage backends(如 NFS 等)。添加一个可靠的、有效的存储层给 Kubernetes,保证高可用的有状态工作负载。
每个 Kubernetes cluster 的组件都能被配置为高可用,应用能利用负载均衡和健康检查确保可用性。
安全性(Security)
Security 在 Kubernetes 中有着多层级的配置。
- API endpoints:在 API endpoints 通过 transport layer security (TLS) 传输
- Users mechanism:通过对职责的区分保证集群的安全
- Secret object:用于保存敏感信息,且对于相同集群命名空间的所有用户是有效的
- NetworkPolicy object:管理 Pods 间通信,避免在多层架构设计中端口暴露给非关联应用
可移植性(Portability)
Kubernetes 设计的初衷是为了提供 freedom of choice,你可以自由地选择操作系统、Container Runtime、Processor Architectures、云平台和 Paas。
通过联邦制度,混合和匹配多个云服务提供商和内部自建集群(on-premises)成为可能,这将混合云架构方案发展为容器工作负载架构。顾客可以无缝地(seamlessly)从某一个 deployment target 切换到另一个。
Kubernetes Network Model
Kubernetes 设计网络模型的基础原则是:
- 所有容器都可以在不用 NAT 的方式下同别的容器通信。
- 所有节点都可以在不用 NAT 的方式下同所有容器通信,反之亦然。
- Pod 看到自己的 IP 跟别人看见它所用的 IP 是一样的,中间不能经过转换。
在有了一个好的设计容器网络的前提,我们需要考虑外部网络如何一步一步连接到容器内部的应用?
- 同 Pod 中 Container-to-Container networking
- 同 Node 中 Pod-to-Pod networking
- 跨 Node 之间 Pod-to-Pod networking
- Pod-to-Service networking
由于容器网络发展复杂性在于它其实是寄生在 Host 网络之上的。从这个角度讲,可以把容器网络方案大体分为 Underlay/Overlay 两大派别:
- Underlay 的标准是它与 Host 网络是同层的,从外在可见的一个特征就是它是不是使用了 Host 网络同样的网段、输入输出基础设备、容器的 IP 地址是不是需要与 Host 网络取得协同(来自同一个中心分配或统一划分)。这就是 Underlay;
- Overlay 不一样的地方就在于它并不需要从 Host 网络的 IPM 的管理的组件去申请 IP,一般来说,它只需要跟 Host 网络不冲突,这个 IP 可以自由分配的。
而 Kuberbetes 采用了 per-pod-per-ip 的模型,摒弃了显式端口映射等 NAT 配置,统一了容器网络对外服务的视角。
Container Inner-Network Schema
Network namespace(NS)
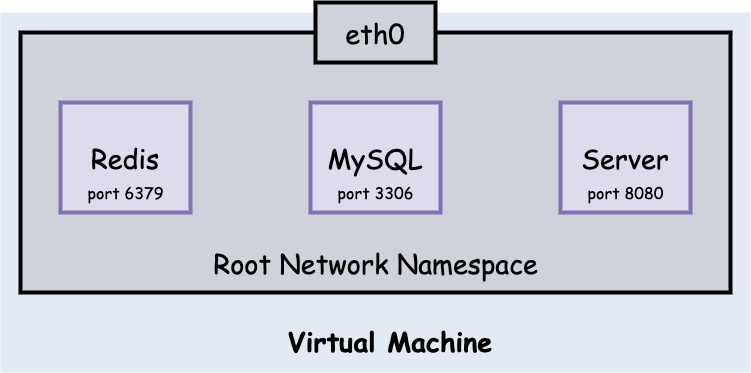
Linux networking namespace 为进程通讯提供了一个逻辑网络栈,包括 network devices、routes、firewall rules。Network namespace(NS)管理实际是为其中的所有进程提供了一个独立的逻辑网络 Stack。在缺省状态下,Linux 将每个进程挂载在 Root NS 下,这些进程通过 eth0 通往外面的世界。
同 Pod, Container-to-Container networking
在了解 Pod 之间 Container-to-Container 是如何通信之前,需要了解进程间通过 Socket 是如何通信的。
同 NS, Socket-to-Socket networking
除了某些特殊情况,端口是不可被不同进程绑定的。并且对于同一 networking namespace 内部是互通的。
下面介绍在主进程绑定端口后 fork 子进程,端口可以被父子进程同时绑定的特殊情况。
同 Pod, Container-to-Container networking
在保证了同一 NS 下进程间能正常通信,我们需要进一步考虑不同 NS 下的通信情况。
以目前的容器化方案举例,Docker 通过 Linux networking namespace 对网络环境进行了隔离,不同命名空间需要通过网卡才能相互通信,而不像同 NS 间进程访问那么方便。
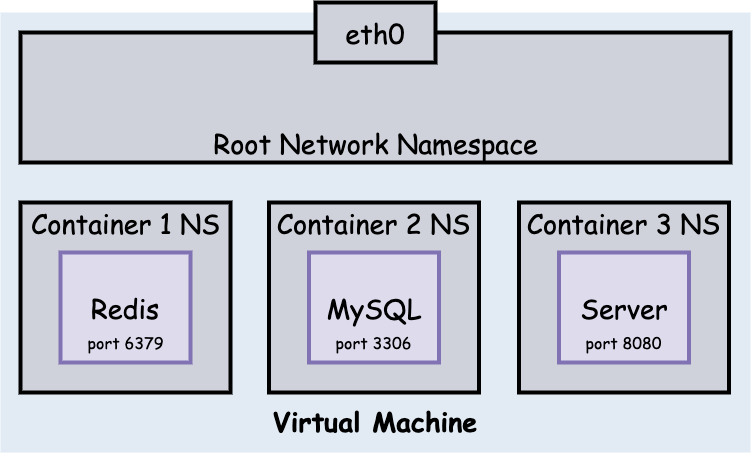
因此在上图中三个 Container 间并不能进行正常的网络通信。但在 Pod 中,所有 Container 都共享同一个 NS,因此 Pod 内部网络是可以随意访问的,其结构图如下。
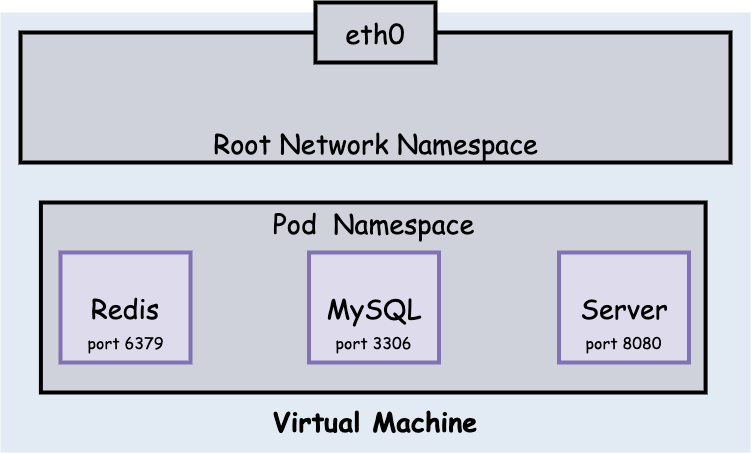
同 Node, Pod-to-Pod networking
上面提到,不同的 NS 需要网卡才能正常提供网络访问,因此同一 Node 下的 Pod 之间访问的实现方式就明晰了,即通过 Virtual Ethernet Device (or veth pair) 来实现跨 NS 的连接。
Veth Pair
使用 Veth Pair 即通过网线将 Pod NS 与 Root NS 相连,使得 Root NS 可通过 Veth Pair 与相连 Pod 通信,效果如下图:
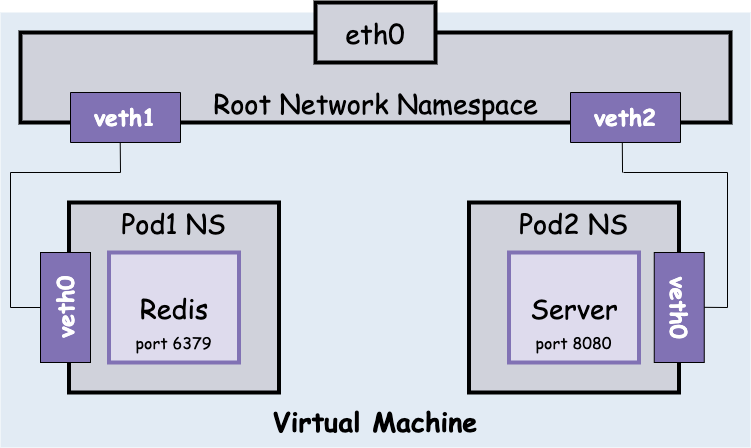
通过 Veth Pair 我们可以简单的连接两个不同的 interface,但每两个 interface 相连就需要一对 Veth Pair,当同一个 Node 节点有多个 Pod 时,Veth Pair 会无限的增长下去。
Ethernet Bridge
那么如何优雅的传输不同 Pod 间的 package 呢?答案是通过 Ethernet Bridge,一个虚拟的 Layer2 网络设备来实现不同 network segments 之间的 Ethernet packet switching。ARP 实现了 MAC 地址到 IP 地址的发现协议。Bridge 广播 ethframe 到所有连接的设备(除发送者外),收到 ARP 回复后将 packet forward 到对应 veth 设备上。如下图:
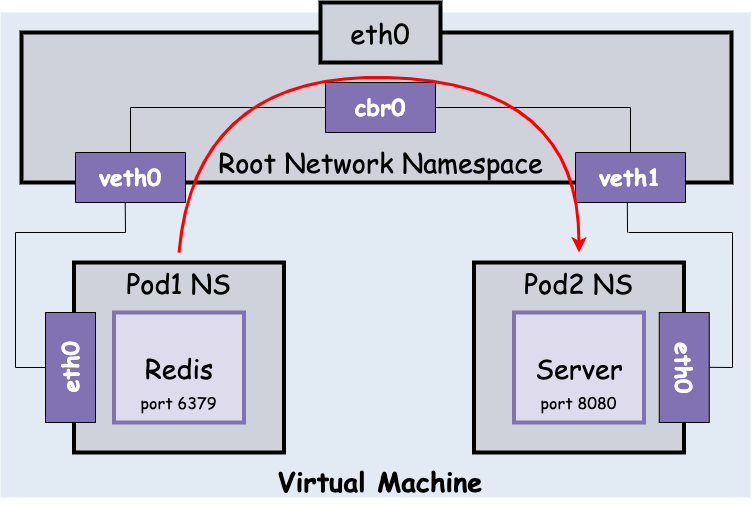
Pause Pod
在介绍完 Veth Pair 以及 Ethernet Bridge,不得不介绍 Pause Pod。在 Kubernetes 的基本设计中,Pod 是完全平等的关系,它们共享 Network Namespace、Volume 等资源。因此需要有一个所有容器的父进程 Pause 进程来创建共享的 Network Namespace、共享文件。
没有 Pause 容器的情况:
没有 Pause 进程则 Pod 中容器启动有先后的顺序,即有拓扑关系,而非平等关系。例如 Container A 需要共享 Container B 的网络和存储,则必须 B 先启动,A 后启动。
有 Pause 容器的情况:
Kubernetes 通过中间容器 Infra(初始化容器)改变了集群应有的拓扑关系。在 Pod 中,Infra 容器第一个被创建并与 Pod 同生命周期,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起,并与之共享 Pod 内的网络资源。
Container Outer-Network Schema
跨 Node, Pod-to-Pod networking
在 Pod 获得 IP 之前,kubelet 为每个 Node 分配一个 CIDR 地址段(Classless inter-domain routing),每个 Pod 在其中获取唯一 IP,CIDR 地址块的大小对应于每个 Node 的最大 Pod 数量(默认 110 个)。在 Pod IP 和跨 Node 网络层部署成功后,从源 Pod1 到目的 Pod4 的通讯如图:
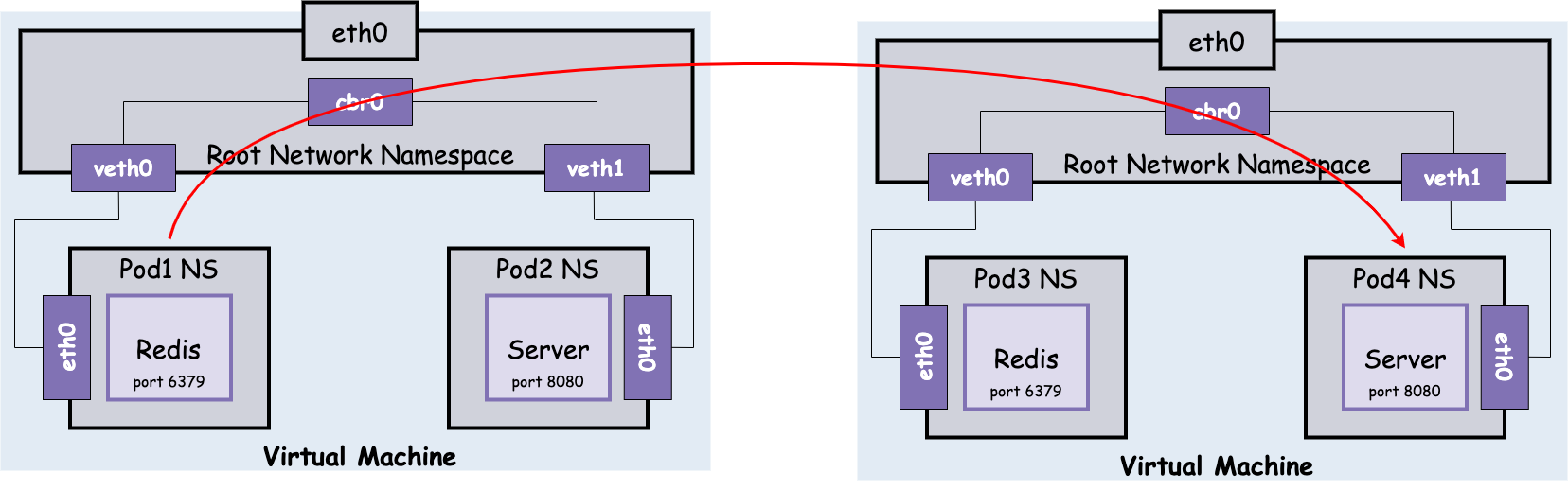
需要注意的是,这里的跨 Node 访问忽略了对 Node-to-Node 连通性的关注,这会在下一节进行介绍。目前且认为 Node/Pod IP 的网络通达性是确保的。
Node-to-Node networking
简要来看,K8s 网络模型要求 Pod IP 在整个网络中都能通达。具体实现方案有三方面:
- Overlay Solution,如 Flannel
- Layer2(Switching)Solution
- Layer3(Routing)Solution,如 Calico, Terway
Overlay Networking: Flannel
Flannel 的设计原理很简洁,在 Host 网络之上创建另一个扁平网络(所谓的 overlay)。在每个 Host 主机上运行一个 flanneld agent,其作用如下:
- 在整个 Hosts 集群中保证每个 subnet 的唯一性
- 为 Host 上的每个 Container 分配 IP
- 即使在不同的 Host,Container 也可通过 Flannel 维护的路由规则相互通信
每个 flanneld agent 会将容器子网 CIDR 和所属主机 IP 的映射保存在 etcd 中,因此 agent 能获取到各个容器的网络信息,并在发送报文时正确的转发。
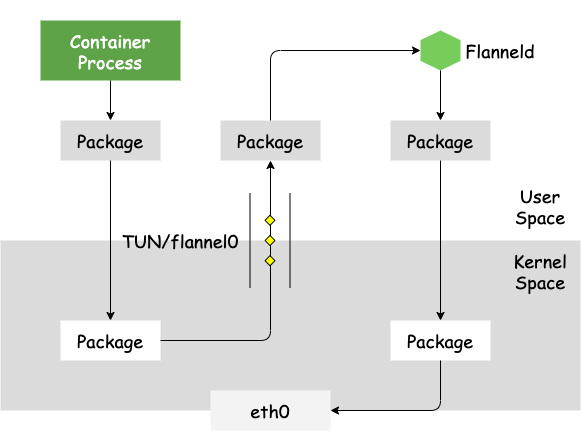
下图是 Flannel 网络中两个互相通信容器的 architecture 和 data flow:
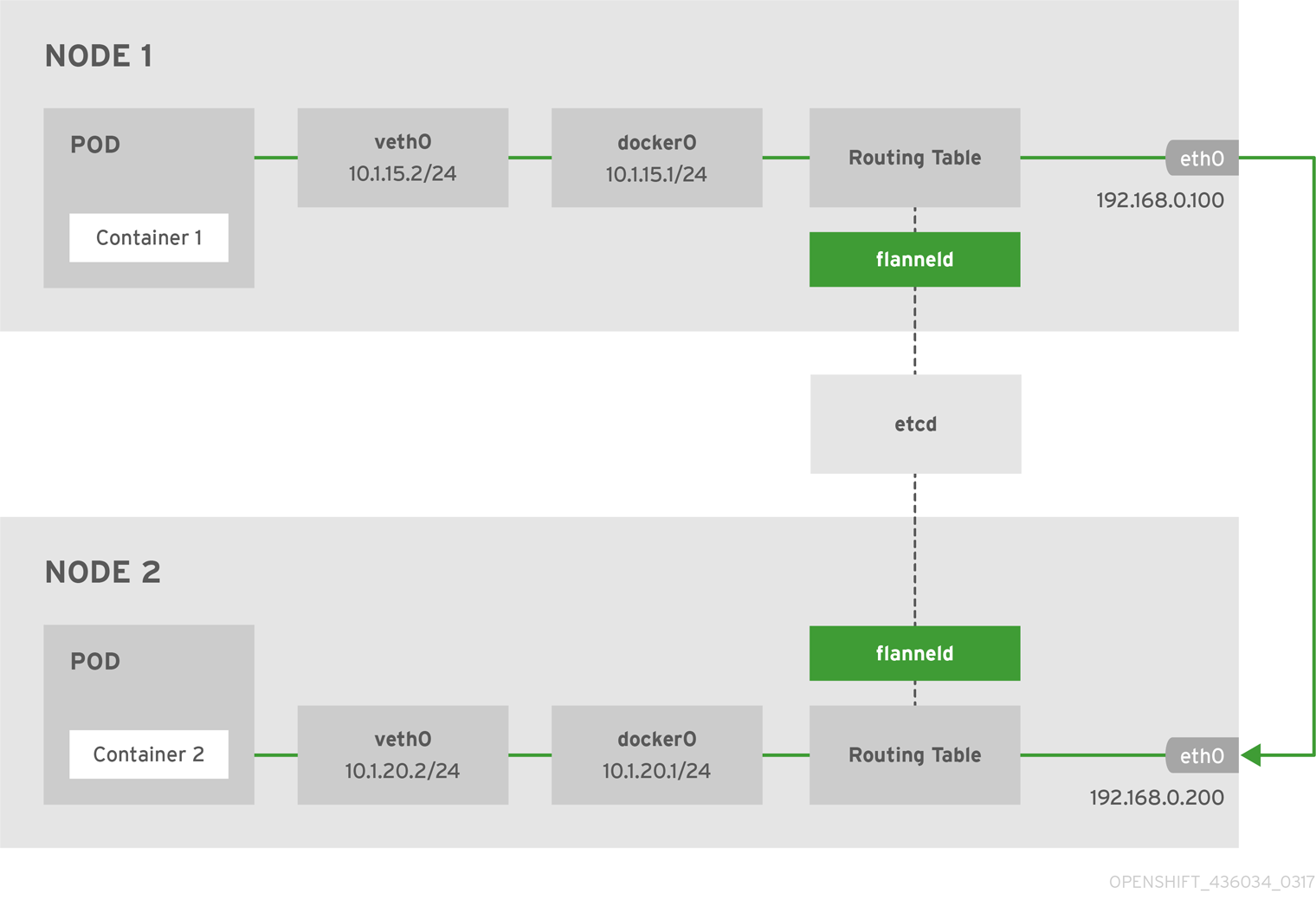
主机内容器网络在 docker bridge(docker0)上完成通讯,不再赘述。主机间通讯使用内核路由表和 IP-over-UDP 封装进行实现。容器 IP 包流经 docker bridge 会转发到 flannel0 网卡(TUN)设备上,进而流入到 flanneld 进程中。flanneld 会对 packet 目标 IP 地址所属的网段信息查询其对应的下一跳主机 IP,并将 IP packet 封装到一个 UDP payload 发送到目标主机。到达目标主机后,UDP packet 会流经 flanneld 并在这里解封出 IP packet,再发送至 flanneld、docker0 最后到达目标容器 IP 地址上。
TUN 设备主要是将容器 IP 伪装成目标 IP,达到连接分配 IP 的效果。
值得一提是,容器 CIDR 和下一跳主机 IP 的映射条目容量没有特殊限制。在阿里云 ACK 产品上该条目容量需要在 VPC/vSwitch 控制面中进行分发,考虑到整体性能因素,在数量上做了一定数量限制(缺省 48 个)。但在自建主机网络部署中,该数量限制就不会明显了,因为主机下一跳主机网络在一个大二层平面上。
Flannel 新版本 backend 不建议采用 UDP 封装方式,因为 traffic 存在 3 次用户空间与内核空间的数据拷贝,性能上存在比较大的损耗。新版本推荐用 VxLan 和云服务商版本的 backends 进行优化。
L3 networking: Calico
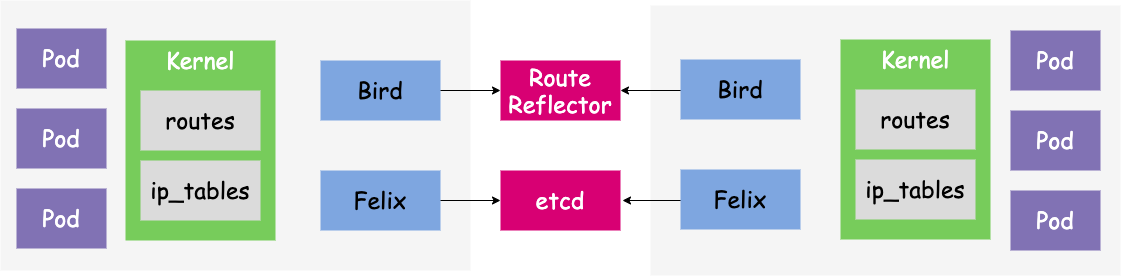
Calico 是 L3 Routing 上非常流行容器网络架构方案。用于容器、虚拟机、宿主机之间的网络连接。Bird 和 Felix 都是运行在 Node 节点中的 deamon 进程。
组件介绍
Felix
Calico 的核心组件。主要的功能有:
- 接口管理:Felix 为内核编写一些接口信息,以便让内核能正确的处理主机 endpoint 的流量。特别是主机之间的 ARP 请求和处理 IP 转发。
- 路由规则:Felix 负责主机之间路由信息写到 Linux 内核的 FIB(Forwarding Information Base)转发信息库,保证数据包可以在主机之间相互转发。
- ACL 规则:Felix 负责将 ACL 策略写入到 Linux 内核中,保证主机 endpoint 的为有效流量不能绕过 Calico 的安全措施。
- 状态报告:Felix 负责提供关于网络健康状况的数据。特别是,它报告配置主机时出现的错误和问题。这些数据被写入 etcd,使其对网络的其他组件和操作人员可见。
Bird
BGP 客户端,其作用是将 Felix 的路由信息读入内核,并通过 BGP 协议在集群中分发。当 Felix 将路由插入到 Linux 内核 FIB 中时,BGP 客户端将获取这些路由并将它们分发到部署中的其他节点。这可以确保在部署时有效地路由流量。
BGP 介绍
BGP 边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。BGP不使用传统的内部网关协议(IGP)的指标。
Node-to-Node Mesh(全互联模式):Calico 维护的网络默认是(Node-to-Node Mesh)全互联模式,Calico 集群中的节点两两之间都会相互建立连接,用于路由交换。但是随着集群规模的扩大,mesh 模式将形成一个巨大服务网格,连接数成倍增加。这时就需要使用 Route Reflector(路由器反射)模式解决这个问题。Route Reflector 模式(路由反射):RR 会指定一个或多个 BGP Speaker 为 RouterReflection,它与网络中其他 Speaker 建立连接,每个 Speaker 只要与 Router Reflection 建立 BGP 就可以获得全网的路由信息。在 Calico 中可以通过 Global Peer 实现 RR 模式。IPIP模式:把 IP 层封装到 IP 层的一个 tunnel。作用其实基本上就相当于一个基于IP层的网桥!一般来说,普通的网桥是基于 MAC 层的,根本不需 IP,而这个 IPIP 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
特点
优势:
- 没有封包和解包过程,完全基于两端宿主机的路由表进行转发
- 可以配合使用
Network Policy做 pod 和 pod 之前的访问控制 - 可以做细粒度的网络访问控制,可以做多租户网络方面的控制 ACL,Flannel 不支持
劣势:
- 要求宿主机处于同一个2层网络下,也就是连在一台交换机上
- 路由的数目与容器数目相同,非常容易超过路由器、三层交换、甚至 Node 的处理能力,从而限制了整个网络的扩张。(可以使用大规模方式解决)
- 每个 Node 上会设置大量(海量)的 iptables 规则、路由,运维、排障难度大
- 原理决定了它不可能支持 VPC,容器只能从 Calico 设置的网段中获取 IP
Pod-to-Service networking
Service 是 Kubernetes 最核心的概念,通过创建 Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。并且由于 Pod 和 Service 是 Kubernetes 集群范围内的虛拟概念,所以集群外的客户端系统无法通过 Pod 的 IP 地址或者 Service 的虚拟 IP 地址和虛拟端口号访问到它们。为了让外部客户端可以访问这些服务,可以将 Pod 或 Service 的端口号映射到宿主机,以使得客户端应用能够通过物理机访问容器应用。
Kubernetes Storage Model
Kubernetes 对于有状态的容器应用或者对数据需要持久化的应用,不仅需要将容器内的目录挂载到宿主机的目录或者 emptyDir 临时存储卷,而且需要更加可靠的存储来保存应用产生的重要数据,以便容器应用在重建之后,仍然可以使用之前的数据。不过,存储资源和计算资源(CPU/内存)的管理方式完全不同。为了能够屏蔽底层存储实现的细节,让用户方便使用,同时能让管理员方便管理,Kubernetes 引入 PersistentVolume 和 PersistentVolumeClaim 两个资源对象来实现对存储的管理子系统。后来又引入了 StorageClass 来实现资源动态供应。
PersistentVolume (PV) 是对底层网络共享存储的抽象,将共享存储定义为一种“资源”,比如节点 (Node) 也是一种容器 应用可以“消费”的资源。PV 由管理员进行创建和配置,它与共享存储的具体实现直接相关,例如 GlusterFS、iSCSI. RBD 或 GCE/AWS 公有云提供的共享存储,通过插件式的机制完成与共享存储的对接,以供应用访问和使用。
PersistentVolumeClaim (PVC) 则是用户对于存储资源的一个“申请”。就像 Pod “消费” Node 的资源一样,PVC 会“消费” PV 资源。PVC 可以申请特定的存储空间和访问模式。使用 PVC “申请”到一定的存储空间仍然不足以满足应用对于存储设备的各种需求。
StorageClass 对存储设备的特性和性能进行标记,包括读写速度、并发性能、数据冗余等,并提供了动态资源供应的机制。