微服务架构是由大型单体服务拆分为小型服务的哲学,其需要以下四个设计原则:服务化、流量治理、可靠通讯、可观测性。
从类库到服务
通过服务来实现组件
Microservice architectures will use libraries, but their primary way of componentizing their own software is by breaking down into services.
微服务架构也会使用到类库,但构成软件系统组件的主要方式是将其拆分为一个个服务。
—— Martin Fowler / James Lewis, Microservices, 2014
微服务架构其中一个重要设计原则是“通过服务来实现独立自治的组件”(Componentization via Services),强调应采用“服务”(Service)而不再是“类库”(Library)来构建组件化的程序,这两者的差别在于类库是在编译期静态链接到程序中的,通过调用本地方法来使用其中的功能,而服务是进程外组件,通过调用远程方法来使用其中的功能。
采用服务来构建程序,获得的收益是软件系统“整体”与“部分”在物理层面的真正隔离,这对构筑可靠的大型软件系统来说无比珍贵,但另一面,其付出的代价也同样无可忽视,微服务架构在复杂性与执行性能方面做出了极大的让步。一套由多个微服务相互调用才能正常运作的分布式系统中,每个节点都互相扮演着服务的生产者与消费者的多重角色,形成了一套复杂的网状调用关系,此时,至少有(但不限于)以下三个问题是必须考虑并得到妥善解决的:
- 对消费者来说,外部的服务由谁提供?具体在什么网络位置?
- 对生产者来说,内部哪些服务需要暴露?哪些应当隐藏?应当以何种形式暴露服务?以什么规则在集群中分配请求?
- 对调用过程来说,如何保证每个远程服务都接收到相对平均的流量,获得尽可能高的服务质量与可靠性?
这三个问题的解决方案,在微服务架构中通常被称为“服务发现”、“服务的网关路由”和“服务的负载均衡”。
服务发现
类库封装被大规模使用,令计算机实现了通过位于不同模块的方法调用来组装复用指令序列,打开了软件达到更大规模的一扇大门。无论是编译期链接的 C、C++语言,抑或是运行期链接的 Java 语言,都要通过链接器)(Linker)将代码里的符号引用转换为模块入口或进程内存地址的直接引用。而服务化的普及,令软件系统得以通过分布于网络中不同机器的互相协作来复用功能,这是软件发展规模的第二次飞跃,此时,如何确定目标方法的确切位置,便是与编译链接有着等同意义的研究课题,解决该问题的过程便被称作“服务发现”(Service Discovery)。
服务发现的意义
所有的远程服务调用都是使用全限定名(Fully Qualified Domain Name,FQDN)、端口号与服务标识所构成的三元组来确定一个远程服务的精确坐标的。全限定名代表了网络中某台主机的精确位置,端口代表了主机上某一个提供了 TCP/UDP 网络服务的程序,服务标识则代表了该程序所提供的某个具体的方法入口。其中“全限定名、端口号”的含义对所有的远程服务来说都一致,而“服务标识”则与具体的应用层协议相关,不同协议具有不同形式的标识,譬如 REST 的远程服务,标识是 URL 地址;RMI 的远程服务,标识是 Stub 类中的方法;SOAP 的远程服务,标识是 WSDL 中定义方法,等等。远程服务标识的多样性,决定了“服务发现”也可以有两种不同的理解,一种是以 UDDI 为代表的“百科全书式”的服务发现,上至提供服务的企业信息(企业实体、联系地址、分类目录等等),下至服务的程序接口细节(方法名称、参数、返回值、技术规范等等)都在服务发现的管辖范围之内;另一种是类似于 DNS 这样“门牌号码式”的服务发现,只满足从某个代表服务提供者的全限定名到服务实际主机 IP 地址的翻译转换,并不关心服务具体是哪个厂家提供的,也不关心服务有几个方法,各自由什么参数构成,默认这些细节信息是服务消费者本身已完全了解的,此时服务坐标就可以退化为更简单的“全限定名+端口号”。当今,后一种服务发现占主流地位,本文后续所说的服务发现,如无说明,均是特指的是后者。
原本服务发现只依赖 DNS 将一个全限定名翻译为一至多个 IP 地址或者 SRV 等其他类型的记录便可,位于 DNS 之后的负载均衡器也实质上承担了一部分服务发现的职责,完成了外部 IP 地址到各个服务内部实际 IP 的转换,这些内容笔者在“透明多级分流系统”一节中曾经详细解析过。这种做法在软件追求不间断长时间运行的时代是很合适的,但随着微服务的逐渐流行,服务的非正常宕机、重启和正常的上线、下线变得越发频繁,仅靠着 DNS 服务器和负载均衡器等基础设施就显得逐渐疲于应对,无法跟上服务变动的步伐了。人们最初是尝试使用 ZooKeeper 这样的分布式 K/V 框架,通过软件自身来完成服务注册与发现,ZooKeeper 也的确曾短暂统治过远程服务发现,是微服务早期的主流选择,但毕竟 ZooKeeper 是很底层的分布式工具,用户自己还需要做相当多的工作才能满足服务发现的需求。到了 2014 年,在 Netflix 内部经受过长时间实际考验的、专门用于服务发现的 Eureka 宣布开源,并很快被纳入 Spring Cloud,成为 Spring 默认的远程服务发现的解决方案。从此 Java 程序员再无须再在服务注册这件事情上花费太多的力气。到 2018 年,Spring Cloud Eureka 进入维护模式以后,HashiCorp 的 Consul 和阿里巴巴的 Nacos 很就快从 Eureka 手上接过传承的衣钵。
到这个阶段,服务发现框架已经发展得相当成熟,考虑到几乎方方面面的问题,不仅支持通过 DNS 或者 HTTP 请求进行符号与实际地址的转换,还支持各种各样的服务健康检查方式,支持集中配置、K/V 存储、跨数据中心的数据交换等多种功能,可算是应用自身去解决服务发现的一个顶峰。如今,云原生时代来临,基础设施的灵活性得到大幅度的增强,最初的使用基础设施来透明化地做服务发现的方式又重新被人们所重视,如何在基础设施和网络协议层面,对应用尽可能无感知、方便地实现服务发现是目前服务发现的一个主要发展方向。
可用与可靠
本章笔者并不打算介绍具体某一种服务发现工具的具体功能与操作,而是会去分析服务发现的通用的共性设计,探讨对比时下服务发现最常见的不同形式。这里要讨论的第一个问题是“服务发现”具体是指进行过什么操作?这其实包含三个必须的过程。
- 服务的注册(Service Registration):当服务启动的时候,它应该通过某些形式(如调用 API、产生事件消息、在 ZooKeeper/Etcd 的指定位置记录、存入数据库,等等)将自己的坐标信息通知到服务注册中心,这个过程可能由应用程序本身来完成,称为自注册模式,譬如 Spring Cloud 的@EnableEurekaClient 注解;也可能有容器编排框架或第三方注册工具来完成,称为第三方注册模式,譬如 Kubernetes 和 Registrator。
- 服务的维护(Service Maintaining):尽管服务发现框架通常都有提供下线机制,但并没有什么办法保证每次服务都能优雅地下线(Graceful Shutdown)而不是由于宕机、断网等原因突然失联。所以服务发现框架必须要自己去保证所维护的服务列表的正确性,以避免告知消费者服务的坐标后,得到的服务却不能使用的尴尬情况。现在的服务发现框架,往往都能支持多种协议(HTTP、TCP 等)、多种方式(长连接、心跳、探针、进程状态等)去监控服务是否健康存活,将不健康的服务自动从服务注册表中剔除。
- 服务的发现(Service Discovery):这里的发现是特指狭义上消费者从服务发现框架中,把一个符号(譬如 Eureka 中的 ServiceID、Nacos 中的服务名、或者通用的 FQDN)转换为服务实际坐标的过程,这个过程现在一般是通过 HTTP API 请求或者通过 DNS Lookup 操作来完成,也还有一些相对少用的方式,譬如 Kubernetes 也支持注入环境变量来做服务发现。
以上三点只是列举了服务发现必须提供的功能,在此之余还会有一些可选的扩展功能,譬如在服务发现时进行的负载均衡、流量管控、键值存储、元数据管理、业务分组,等等,这部分后续章节会有专门介绍,不在此展开。这里,笔者想借服务发现为样本,展示分布式环境里可用性与一致性的矛盾。从 CAP 定理开始,到分布式共识算法,我们已在理论上探讨过多次服务的可用和数据的可靠之间需有所取舍,但服务发现却面临着两者都难以舍弃的困境。
服务发现既要高可用,也要高可靠是由它在整个系统中所处的位置所决定的。在概念模型里,服务发现的位置是如图 7-1 所示这样的:服务提供者在服务注册中心中注册、续约和下线自己的真实坐标,服务消费者根据某种符号从服务注册中心中获取到真实坐标,无论是服务注册中心、服务提供者还是服务消费者,它们都是系统服务中的一员,相互间的关系应是对等的。
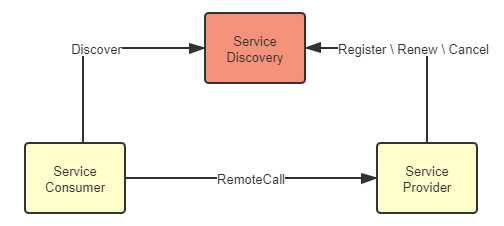
图 7-1 概念模型中的服务发现
但在真实的系统里,注册中心的地位是特殊的,不能为完全视其为一个普通的服务。注册中心不依赖其他服务,但被所有其他服务共同依赖,是系统中最基础的服务(类似地位的大概就数配置中心了,现在服务发现框架也开始同时提供配置中心的功能,以避免配置中心又去专门摆弄出一集群的节点来),几乎没有可能在业务层面进行容错。这意味着服务注册中心一旦崩溃,整个系统都不再可用,因此,必须尽最大努力保证服务发现的可用性。实际用于生产的分布式系统,服务注册中心都是以集群的方式进行部署的,通常使用三个或者五个节点(通常最多七个,一般也不会更多了,否则日志复制的开销太高)来保证高可用,如图 7-2 所示:
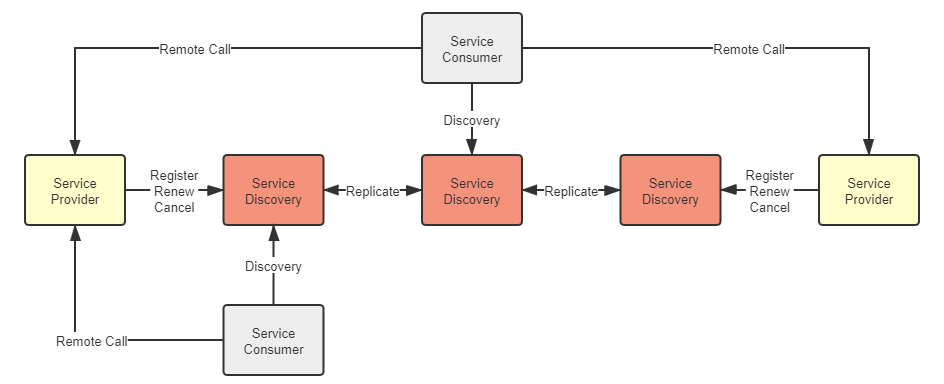
图 7-2 真实系统中的服务发现
同时,也请注意到上图中各服务注册中心节点之间的“Replicate”字样,作为用户,我们当然期望服务注册中心一直可用永远健康的同时,也能够在访问每一个节点中都能取到可靠一致的数据,而不是从注册中心拿到的服务地址可能已经下线,这两个需求就构成了 CAP 矛盾,不可能同时满足。以最有代表性的 Netflix Eureka 和 Hashicorp Consul 为例:
Eureka 的选择是优先保证高可用性,相对牺牲系统中服务状态的一致性。Eureka 的各个节点间采用异步复制来交换服务注册信息,当有新服务注册进来时,并不需要等待信息在其他节点复制完成,而是马上在该服务发现节点宣告服务可见,只是不保证在其他节点上多长时间后才会可见。同时,当有旧的服务发生变动,譬如下线或者断网,只会由超时机制来控制何时从哪一个服务注册表中移除,变动信息不会实时的同步给所有服务端与客户端。这样的设计使得不论是 Eureka 的服务端还是客户端,都能够持有自己的服务注册表缓存,并以 TTL(Time to Live)机制来进行更新,哪怕服务注册中心完全崩溃,客户端在仍然可以维持最低限度的可用。Eureka 的服务发现模型对节点关系相对固定,服务一般不会频繁上下线的系统是很合适的,以较小的同步代价换取了最高的可用性;Eureka 能够选择这种模型的底气在于万一客户端拿到了已经发生变动的错误地址,也能够通过 Ribbon 和 Hystrix 模块配合来兜底,实现故障转移(Failover)或者快速失败(Failfast)。
Consul 的选择是优先保证高可靠性,相对牺牲系统服务发现的可用性。Consul 采用Raft 算法,要求多数派节点写入成功后服务的注册或变动才算完成,严格地保证了在集群外部读取到的服务发现结果必定是一致的;同时采用 Gossip 协议,支持多数据中心之间更大规模的服务同步。Consul 优先保证高可靠性一定程度上是基于产品现实情况而做的技术决策,它不像 Netflix OSS 那样有着全家桶式的微服务组件,万一从服务发现中取到错误地址,就没有其他组件为它兜底了。Eureka 与 Consul 的差异带来的影响主要不在于服务注册的快慢(当然,快慢确实是有差别),而在于你如何看待以下这件事情:
假设系统形成了 A、B 两个网络分区后,A 区的服务只能从区域内的服务发现节点获取到 A 区的服务坐标,B 区的服务只能取到在 B 区的服务坐标,这对你的系统会有什么影响?
- 如果这件事情对你并没有太大的影响,甚至有可能还是有益的,就应该倾向于选择 AP 式的服务发现。譬如假设 A、B 就是不同的机房,是机房间的网络交换机导致服务发现集群出现的分区问题,但每个分区中的服务仍然能独立提供完整且正确的服务能力,此时尽管不是有意而为,但网络分区在事实上避免了跨机房的服务请求,反而还带来了服务调用链路优化的效果。
- 如果这件事情也可能对你影响非常之大,甚至可能带来比整个系统宕机更坏的结果,就应该倾向于选择 CP 式的服务发现。譬如系统中大量依赖了集中式缓存、消息总线、或者其他有状态的服务,一旦这些服务全部或者部分被分隔到某一个分区中,会对整个系统的操作的正确性产生直接影响的话,那与其最后弄出一堆数据错误,还不如直接停机来得痛快。
注册中心实现
可用性与一致性的矛盾,是分布式系统永恒的话题,在服务发现这个场景里,权衡的主要关注点是相对更能容忍出现服务列表不可用的后果,还是出现服务数据不准确的后果,其次才到性能高低,功能是否强大,使用是否方便等因素。有了选择权衡,很自然就引来了一下个“务实”的话题,现在那么多的服务发现框架,哪一款最好?或者说应该如何挑选适合的?当下,直接以服务发现、服务注册中心为目标的组件库,或者间接用来实现这个目标的工具主要有以下三类:
- 在分布式 K/V 存储框架上自己开发的服务发现,这类的代表是 ZooKeeper、Doozerd、Etcd。
这些 K/V 框架提供了分布式环境下读写操作的共识算法,Etcd 采用的是我们学习过的 Raft 算法,ZooKeeper 采用的是 ZAB 算法,这也是一种 Multi Paxos 的派生算法,所以采用这种方案,就不必纠结 CP 还是 AP 的问题,它们都是 CP 的(也曾有公司采用 Redis 来做服务发现,这种自然是 AP 的)。这类框架的宣传语中往往会主动提及“高可用性”,潜台词其实是“在保证一致性和分区容忍性的前提下,尽最大努力实现最高的可用性”,譬如 Etcd 的宣传语就是“高可用的集中配置和服务发现”(Highly-Available Key Value Store for Shared Configuration and Service Discovery)。这些 K/V 框架的一个共同特点是在整体较高复杂度的架构和算法的外部,维持着极为简单的应用接口,只有基本的 CRUD 和 Watch 等少量 API,所以要在上面完成功能齐全的服务发现,很多基础的能力,譬如服务如何注册、如何做健康检查,等等都必须自己去实现,如今一般也只有“大厂”才会直接基于这些框架去做服务发现了。 - 以基础设施(主要是指 DNS 服务器)来实现服务发现,这类的代表是 SkyDNS、CoreDNS。
在 Kubernetes 1.3 之前的版本使用 SkyDNS 作为默认的 DNS 服务,其工作原理是从 API Server 中监听集群服务的变化,然后根据服务生成 NS、SRV 等 DNS 记录存放到 Etcd 中,kubelet 会为每个 Pod 设置 DNS 服务的地址为 SkyDNS 的地址,需要调用服务时,只需查询 DNS 把域名转换成 IP 列表便可实现分布式的服务发现。在 Kubernetes 1.3 之后,SkyDNS 不再是默认的 DNS 服务器,而是由不使用 Etcd,只将 DNS 记录存储在内存中的 KubeDNS 代替,到了 1.11 版,就更推荐采用扩展性很强的 CoreDNS,此时可以通过各种插件来决定是否要采用 Etcd 存储、重定向、定制 DNS 记录、记录日志,等等。
采用这种方案,是 CP 还是 AP 就取决于后端采用何种存储,如果是基于 Etcd 实现的,那自然是 CP 的,如果是基于内存异步复制的方案实现的,那就是 AP 的(仅针对 DNS 服务器本身,不考虑本地 DNS 缓存的 TTL 刷新)。以基础设施来做服务发现,好处是对应用透明,任何语言、框架、工具都肯定是支持 HTTP、DNS 的,所以完全不受程序技术选型的约束,但坏处是透明的并不一定是简单的,你必须自己考虑如何去做客户端负载均衡、如何调用远程方法等这些问题,而且必须遵循或者说受限于这些基础设施本身所采用的实现机制,譬如服务健康检查里,服务的缓存期限就应该由 TTL 来决定,这是 DNS 协议所规定的,如果想改用 KeepAlive 长连接来实时判断服务是否存活就相对麻烦。 - 专门用于服务发现的框架和工具,这类的代表是 Eureka、Consul 和 Nacos。
这一类框架中,你可以自己决定是 CP 还是 AP 的问题,譬如 CP 的 Consul、AP 的 Eureka,还有同时支持 CP 和 AP 的 Nacos(Nacos 采用类 Raft 协议做的 CP,采用自研的 Distro 协议做的 AP,这里“同时”是“都支持”的意思,它们必须二取其一,不是说 CAP 全能满足)。将它们划归一类是由于它们对应用并不是透明的,尽管 Consul 的主体逻辑是在服务进程之外,以边车的形式提供的,尽管 Consul、Nacos 也支持基于 DNS 的服务发现,尽管这些框架都基本上做到了以声明代替编码,譬如在 Spring Cloud 中只改动 pom.xml、配置文件和注解即可实现,但它们依然是可以被应用程序感知的。所以或多或少还需要考虑你所用的程序语言、技术框架的集成问题。但这个特点其实并不见得全是坏处,譬如采用 Eureka 做服务注册,那在远程调用服务时你就可以用 OpenFeign 做客户端,它们本身就已做好了集成,写个声明式接口就能跑;在做负载均衡时你就可以采用 Ribbon 做客户端,要换均衡算法改个配置就成,这些“不透明”实际上都为编码开发带来了一定便捷,而前提是你选用的语言和框架必须支持。如果老板提出要在 Rust 上用 Eureka,那就只能无奈叹息了(原本这里我写的是 Node、Go、Python 等,查了一下这些居然都有非官方的 Eureka 客户端,用的人多什么问题都会有解决方案)。
网关路由
网关(Gateway)这个词在计算机科学中,尤其是计算机网络中很常见,它用来表示位于内部区域边缘,与外界进行交互的某个物理或逻辑设备,譬如你家里的路由器就属于家庭内网与互联网之间的网关。
网关的职责
在单体架构下,我们一般不太强调“网关”这个概念,为各个单体系统的副本分发流量的负载均衡器实质上承担了内部服务与外部请求之间的网关角色。在微服务环境中,网关的存在感就极大地增强了,甚至成为了微服务集群中必不可少的设施之一。其中原因并不难理解:微服务架构下,每个服务节点都可能由不同团队负责,都有着自己独立的、互不相同的接口,如果服务集群缺少一个统一对外交互的代理人角色,那外部的服务消费者就必须知道所有微服务节点在集群中的精确坐标(在服务发现中解释过“服务坐标”的概念),这样,消费者不仅会受到服务集群的网络限制(不能确保集群中每个节点都有外网连接)、安全限制(不仅是服务节点的安全,外部自身也会受到如浏览器同源策略的约束)、依赖限制(服务坐标这类信息不属于对外接口承诺的内容,随时可能变动,不应该依赖它),就算是调用服务的程序员,自己也不会愿意记住每一个服务的坐标位置来编写代码。由此可见,微服务中网关的首要职责就是作为统一的出口对外提供服务,将外部访问网关地址的流量,根据适当的规则路由到内部集群中正确的服务节点之上,因此,微服务中的网关,也常被称为“服务网关”或者“API 网关”,微服务中的网关首先应该是个路由器,在满足此前提的基础上,网关还可以根据需要作为流量过滤器来使用,提供某些额外的可选的功能,譬如安全、认证、授权、限流、监控、缓存,等等(这部分内容在后续章节中有专门讲解,这里不会涉及)。简而言之:
网关 = 路由器(基础职能) + 过滤器(可选职能)
针对“路由”这个基础职能,服务网关主要考量的是能够支持路由的“网络协议层次”和“性能与可用性”两方面的因素。网络协议层次是指负载均衡中介绍过的四层流量转发与七层流量代理,仅从技术实现角度来看,对于路由这项工作,负载均衡器与服务网关在实现上是没有什么差别的,很多服务网关本身就是基于老牌的负载均衡器来实现的,譬如基于 Nginx、HAProxy 开发的 Ingress Controller,基于 Netty 开发的 Zuul 2.0 等;但从目的角度看,负载均衡器与服务网关会有一些区别,具体在于前者是为了根据均衡算法对流量进行平均地路由,后者是为了根据流量中的某种特征进行正确地路由。网关必须能够识别流量中的特征,这意味着网关能够支持的网络通信协议的层次将会直接限制后端服务节点能够选择的服务通信方式。如果服务集群只提供像 Etcd 这样直接基于 TCP 的访问的服务,那只部署四层网关便可满足,网关以 IP 报文中源地址、目标地址为特征进行路由;如果服务集群要提供 HTTP 服务的话,那就必须部署一个七层网关,网关根据 HTTP 报文中的 URL、Header 等信息为特征进行路由;如果服务集群还要提供更上层的 WebSocket、SOAP 等服务,那就必须要求网关同样能够支持这些上层协议,才能从中提取到特征。
举个例子,以下是一段基于 SpringCloud 实现的 Fenix’s Bookstore中用到的 Netflix Zuul 网关的配置,Zuul 是 HTTP 网关,/restful/accounts/**和/restful/pay/**是 HTTP 中 URL 的特征,而配置中的serviceId就是路由的目标服务。
routes:
account:
path: /restful/accounts/**
serviceId: account
stripPrefix: false
sensitiveHeaders: "*"
payment:
path: /restful/pay/**
serviceId: payment
stripPrefix: false
sensitiveHeaders: "*"今天围绕微服务的各种技术仍处于快速发展期,笔者不提倡针对每一种工具、框架本身去记忆配置细节,就是无须纠结上面代码清单中配置的确切写法、每个指令的含义。如果你从根本上理解了网关的原理,参考一下技术手册,很容易就能够将上面的信息改写成 Kubernetes Ingress Controller、Istio VirtualServer 或者其他服务网关所需的配置形式。
网关的另一个主要关注点是它的性能与可用性。由于网关是所有服务对外的总出口,是流量必经之地,所以网关的路由性能将导致全局的、系统性的影响,如果经过网关路由会有 1 毫秒的性能损失,就意味着整个系统所有服务的响应延迟都会增加 1 毫秒。网关的性能与它的工作模式和自身实现算法都有关系,但毫无疑问工作模式是最关键的因素,如果能够采用 DSR 三角传输模式,原理上就决定了性能一定会比代理模式来的强(DSR、IP Tunnel、NAT、代理等这些都是网络基础知识,笔者曾在介绍负载均衡器时详细讲解过)。不过,因为今天 REST 和 JSON-RPC 等基于 HTTP 协议的服务接口在对外部提供的服务中占绝对主流的地位,所以我们所讨论的服务网关默认都必须支持七层路由,通常就默认无法直接进行流量转发,只能采用代理模式。在这个前提约束下,网关的性能主要取决于它们如何代理网络请求,也即它们的网络 I/O 模型,下面笔者正好借这个场景介绍一下网络 I/O 的基础知识。
网络 I/O 模型
在套接字接口抽象下,网络 I/O 的出入口就是 Socket 的读和写,Socket 在操作系统接口中被抽象为数据流,网络 I/O 可以理解为对流的操作。每一次网络访问,从远程主机返回的数据会先存放到操作系统内核的缓冲区中,然后内核的缓冲区复制到应用程序的地址空间,所以当发生一次网络请求发生后,将会按顺序经历“等待数据从远程主机到达缓冲区”和“将数据从缓冲区拷贝到应用程序地址空间”两个阶段,根据实现这两个阶段的不同方法,人们把网络 I/O 模型总结为两类、五种模型:两类是指同步 I/O与异步 I/O,五种是指在同步 IO 中又分有划分出阻塞 I/O、非阻塞 I/O、多路复用 I/O和信号驱动 I/O四种细分模型。
具体内容见《Unix IO模型和线程模型》的 IO 模型小节
显而易见,异步 I/O 模型是最方便的,但受限于操作系统,Windows NT 内核早在 3.5 以后,就通过IOCP实现了真正的异步 I/O 模型。而 Linux 系统下,是在 Linux Kernel 2.6 才首次引入,目前也还并不算很完善,因此在 Linux 下实现高并发网络编程时仍是以多路复用 I/O 模型模式为主。
回到服务网关的话题上,有了网络 I/O 模型的知识,我们就可以在理论上定性分析不同七层网关的性能差异了。七层服务网关处理一次请求代理时,包含了两组网络操作,分别是作为服务端对外部请求的应答,和作为客户端对内部服务的请求,理论上这两组网络操作可以采用不同的模型去完成,但一般来说并没有必要这样做。
以 Zuul 网关为例,在 Zuul 1.0 时,它采用的是阻塞 I/O 模型来进行最经典的“一条线程对应一个连接”(Thread-per-Connection)的方式来代理流量,采用阻塞 I/O 意味着它会有线程休眠,就有上下文切换的成本,所以如果后端服务普遍属于计算密集型(CPU Bound,可以通俗理解为服务耗时比较长,主要消耗在 CPU 上)时,这种模式能够相对节省网关的 CPU 资源,但如果后端服务普遍都是 I/O 密集型(I/O Bound,可以理解服务都很快返回,主要消耗在 I/O 上),它就会由于频繁的上下文切换而降低性能。在 Zuul 的 2.0 版本,最大的改进就是基于 Netty Server 实现了异步 I/O 模型来处理请求,大幅度减少了线程数,获得了更高的性能和更低的延迟。根据 Netflix 官方自己给出的数据,Zuul 2.0 大约要比 Zuul 1.0 快上 20%左右。甚至还有一些网关,支持自行配置,或者根据环境选择不同的网络 I/O 模型,典型的就是 Nginx,可以支持在配置文件中指定 select、poll、epoll、kqueue 等并发模型。
网关的性能高低一般只去定性分析,要定量地说哪一种网关性能最高、高多少是很困难的,就像我们都认可 Chrome 要比 IE 快,但脱离了具体场景,快上多少就很难说的清楚。尽管笔者上面引用了 Netflix 官方对 Zuul 两个版本的量化对比,网络上也有不少关于各种网关的性能对比数据,但要是脱离具体应用场景去定量地比较不同网关的性能差异还是难以令人信服,不同的测试环境和后端服务都会直接影响结果。
网关还有最后一点必须关注的是它的可用性问题。任何系统的网络调用过程中都至少会有一个单点存在,这是由用户只通过唯一的一个地址去访问系统所决定的。即使是淘宝、亚马逊这样全球多数据中心部署的大型系统也不例外。对于更普遍的小型系统(小型是相对淘宝这些而言)来说,作为后端对外服务代理人角色的网关经常被视为整个系统的入口,往往很容易成为网络访问中的单点,这时候它的可用性就尤为重要。由于网关的地址具有唯一性,就不像之前服务发现那些注册中心那样直接做个集群,随便访问哪一台都可以解决问题。为此,对网关的可用性方面,我们应该考虑到以下几点:
- 网关应尽可能轻量,尽管网关作为服务集群统一的出入口,可以很方便地做安全、认证、授权、限流、监控,等等的功能,但给网关附加这些能力时还是要仔细权衡,取得功能性与可用性之间的平衡,过度增加网关的职责是危险的。
- 网关选型时,应该尽可能选择较成熟的产品实现,譬如 Nginx Ingress Controller、KONG、Zuul 这些经受过长期考验的产品,而不能一味只考虑性能选择最新的产品,性能与可用性之间的平衡也需要权衡。
- 在需要高可用的生产环境中,应当考虑在网关之前部署负载均衡器或者等价路由器(ECMP),让那些更成熟健壮的设施(往往是硬件物理设备)去充当整个系统的入口地址,这样网关也可以进行扩展了。
BFF 网关
提到网关的唯一性、高可用与扩展,笔者顺带也说一下近年来随着微服务一起火起来的概念“BFF”(Backends for Frontends)。这个概念目前还没有权威的中文翻译,在我们讨论的上下文里,它的意思是,网关不必为所有的前端提供无差别的服务,而是应该针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持。譬如,运行于浏览器的 Web 程序,由于浏览器一般只支持 HTTP 协议,服务网关就应提供 REST 等基于 HTTP 协议的服务,但同时我们亦可以针对运行于桌面系统的程序部署另外一套网关,它能与 Web 网关有完全不同的技术选型,能提供出基于更高性能协议(如 gRPC)的接口来获得更好的体验。在网关这种边缘节点上,针对同一样的后端集群,裁剪、适配、聚合出适应不一样的前端的服务,有助于后端的稳定,也有助于前端的赋能。
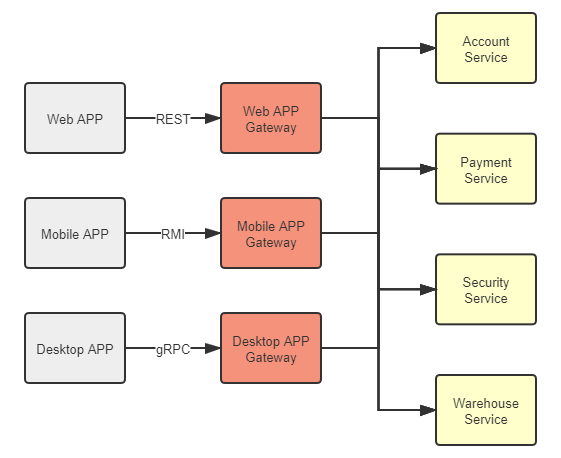
图 7-3 BFF 网关
客户端负载均衡
前置知识
关于经典的集中式负载均衡的工作原理,笔者已在“负载均衡”一节中介绍过,其中许多知识是相通的,笔者在本篇中将不再重复,建议读者先行阅读。
在正式开始讨论之前,我们先来明确区分清楚几个容易混淆的相似概念,分别是本章节中频繁提到的服务发现、网关路由、负载均衡以及在服务流量治理章节中将会介绍的服务容错。这几个技术名词都带有着“从服务集群中寻找到一个合适的服务来调用”的含义,笔者通过以下具体场景来说明它们之间的差别:
案例场景:
假设你身处广东,要上 Fenix’s Bookstore 购买一本书,在程序业务逻辑里,购书其中一个关键步骤是调用商品出库服务来完成货物准备,在代码中该服务的调用请求为:
PATCH https://warehouse:8080/restful/stockpile/3 {amount: -1}又假设 Fenix’s Bookstore 是个大书店,在北京、武汉、广州的机房均部署有服务集群,你的购物请求从浏览器发出后,服务端按顺序发生了如下事件:
首先是将
warehouse这个服务名称转换为恰当的服务地址,“恰当”是个宽泛的描述,一种典型的“恰当”便是因调用请求来自广东,优先分配给传输距离最短的广州机房来应答。其实按常理来说这次出库服务的调用应该是集群内的流量,而不是用户浏览器直接发出的请求,所以尽管结果没有不同,但更接近实际的的情况是用户访问首页时已经被 DNS 服务器分配到了广州机房,请求出库服务时,应优先选择同机房的服务进行调用,此时请求变为:PATCH https://guangzhou-ip-wan:8080/restful/stockpile/3广州机房的服务网关将该请求与配置中的特征进行比对,由 URL 中的
/restful/stockpile/**得知该请求访问的是商品出库服务,因此,将请求的 IP 地址转换为内网中 warehouse 服务集群的入口地址:PATCH https://warehouse-gz-lan:8080/restful/stockpile/3集群中部署有多个 warehouse 服务,收到调用请求后,负载均衡器要在多个服务中根据某种标准——可能是随机挑选,也可能是按顺序轮询,抑或是选择此前调用次数最少那个,等等。根据均衡策略找出要响应本次调用的服务,称其为
warehouse-gz-lan-node1。PATCH https://warehouse-gz-lan-node1:8080/restful/stockpile/3如果访问
warehouse-gz-lan-node1服务,没有返回需要的结果,而是抛出 500 错。HTTP/1.1 500 Internal Server Error根据预置的故障转移(Failover)策略,重试将调用分配给能够提供该服务的其他节点,称其为
warehouse-gz-lan-node2。PATCH https://warehouse-gz-lan-node2:8080/restful/stockpile/3
warehouse-gz-lan-node2服务返回商品出库成功。HTTP/1.1 200 OK
以上过程从整体上看,步骤 1、2、3、5,分别对应了服务发现、网关路由、负载均衡和服务容错,在细节上看,其中部分职责又是有交叉的,并不是服务注册中心就只关心服务发现,网关只关心路由,均衡器只关心流量负载均衡。譬如,步骤 1 服务发现的过程中,“根据请求来源的物理位置来分配机房”这个操作本质上是根据请求中的特征(地理位置)进行流量分发,这实际是一种路由行为。实际系统中,在 DNS 服务器(DNS 智能线路)、服务注册中心(如 Eureka 等框架中的 Region、Zone 概念)或者负载均衡器(可用区负载均衡,如 AWS 的 NLB,或 Envoy 的 Region、Zone、Sub-zone)中都有可能实现。
此外,你是否感觉到以上网络调用过程似乎过于烦琐了,一个从广州机房内网发出的服务请求,绕到了网络边缘的网关、负载均衡器这些设施上,再被分配回内网中另外一个服务去响应,不仅消耗了带宽,降低了性能,也增加了链路上的风险和运维的复杂度。可是,如果流量不经过这些设施,它们相应的职责就无法发挥作用,譬如不经过负载均衡器的话,连请求应该具体交给哪一个服务去处理都无法确定,这有办法简化吗?
客户端负载均衡器
对于任何一个大型系统,负载均衡器都是必不可少的设施。以前,负载均衡器大多只部署在整个服务集群的前端,将用户的请求分流到各个服务进行处理,这种经典的部署形式现在被称为集中式的负载均衡。随着微服务日渐流行,服务集群的收到的请求来源不再局限于外部,越来越多的访问请求是由集群内部的某个服务发起,由集群内部的另一个服务进行响应的,对于这类流量的负载均衡,既有的方案依然是可行的,但针内部流量的特点,直接在服务集群内部消化掉,肯定是更合理更受开发者青睐的办法。由此一种全新的、独立位于每个服务前端的、分散式的负载均衡方式正逐渐变得流行起来,这就是本节我们要讨论的主角:客户端负载均衡器(Client-Side Load Balancer),如图 7-4 所示:
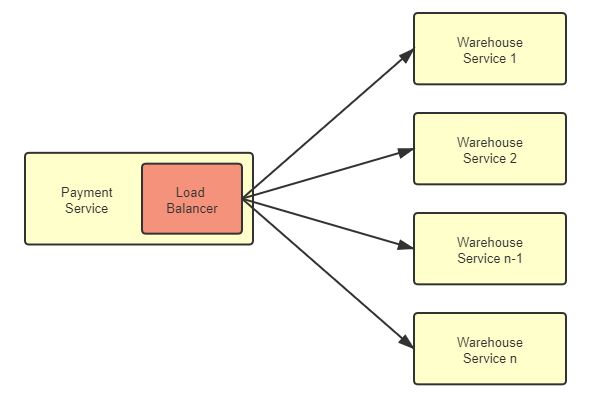
图 7-4 客户端负载均衡器
客户端负载均衡器的理念提出以后,此前的集中式负载均衡器也有了一个方便与它对比的名字“服务端负载均衡器”(Server-Side Load Balancer)。从图中能够清晰地看到客户端负载均衡器的特点,也是它与服务端负载均衡器的关键差别所在:客户端均衡器是和服务实例一一对应的,而且与服务实例并存于同一个进程之内。这个特点能为它带来很多好处,如:
- 均衡器与服务之间信息交换是进程内的方法调用,不存在任何额外的网络开销。
- 不依赖集群边缘的设施,所有内部流量都仅在服务集群的内部循环,避免了出现前文那样,集群内部流量要“绕场一周”的尴尬局面。
- 分散式的均衡器意味着天然避免了集中式的单点问题,它的带宽资源将不会像集中式均衡器那样敏感,这在以七层均衡器为主流、不能通过 IP 隧道和三角传输这样方式节省带宽的微服务环境中显得更具优势。
- 客户端均衡器要更加灵活,能够针对每一个服务实例单独设置均衡策略等参数,访问某个服务,是不是需要具备亲和性,选择服务的策略是随机、轮询、加权还是最小连接等等,都可以单独设置而不影响其它服务。
- ……
但是,客户端均衡器也不是银弹,它得到上述诸多好处的同时,缺点同样也是不少的:
- 它与服务运行于同一个进程之内,意味着它的选型受到服务所使用的编程语言的限制,譬如用 Golang 开发的微服务就不太可能搭配 Spring Cloud Load Balancer 来使用,要为每种语言都实现对应的能够支持复杂网络情况的均衡器是非常难的。客户端均衡器的这个缺陷有违于微服务中技术异构不应受到限制的原则。
- 从个体服务来看,由于是共用一个进程,均衡器的稳定性会直接影响整个服务进程的稳定性,消耗的 CPU、内存等资源也同样影响到服务的可用资源。从集群整体来看,在服务数量达成千乃至上万规模时,客户端均衡器消耗的资源总量是相当可观的。
- 由于请求的来源可能是来自集群中任意一个服务节点,而不再是统一来自集中式均衡器,这就使得内部网络安全和信任关系变得复杂,当攻破任何一个服务时,更容易通过该服务突破集群中的其他部分。
- 服务集群的拓扑关系是动态的,每一个客户端均衡器必须持续跟踪其他服务的健康状况,以实现上线新服务、下线旧服务、自动剔除失败的服务、自动重连恢复的服务等均衡器必须具备的功能。由于这些操作都需要通过访问服务注册中心来完成,数量庞大的客户端均衡器一直持续轮询服务注册中心,也会为它带来不小的负担。
- ……
代理负载均衡器
在 Java 领域,客户端均衡器中最具代表性的产品是 Netflix Ribbon 和 Spring Cloud Load Balancer,随着微服务的流行,它们在 Java 微服务中已积聚了相当可观的使用者。直到最近两三年,服务网格(Service Mesh)开始逐渐盛行,另外一种被称为“代理客户端负载均衡器”(Proxy Client-Side Load Balancer,后文简称“代理均衡器”)的客户端均衡器变体形式开始引起不同编程语言的微服务开发者共同关注,它解决了此前客户端均衡器的大多数缺陷。代理均衡器对此前的客户端负载均衡器的改进是将原本嵌入在服务进程中的均衡器提取出来,作为一个进程之外,同一 Pod 之内的特殊服务,放到边车代理中去实现,它的流量关系如图 7-5 所示。
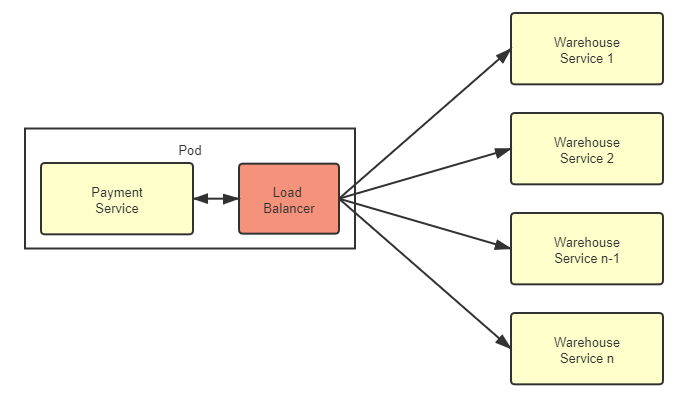
图 7-5 代理负载均衡器
虽然代理均衡器与服务实例不再是进程内通信,而是通过网络协议栈进行数据交换的,数据要经过操作系统的协议栈,要进行打包拆包、计算校验和、维护序列号等网络数据的收发步骤,流量比起之前的客户端均衡器确实多增加了一系列处理步骤。不过,Kubernetes 严格保证了同一个 Pod 中的容器不会跨越不同的节点,这些容器共享着同一个网络名称空间,因此代理均衡器与服务实例的交互,实质上是对本机回环设备的访问,仍然要比真正的网络交互高效且稳定得多。代理均衡器付出的代价较小,但从服务进程中分离出来所获得的收益却是非常显著的:
- 代理均衡器不再受编程语言的限制。发展一个支持 Java、Golang、Python 等所有微服务应用服务的通用的代理均衡器具有很高的性价比。集中不同编程语言的使用者的力量,更容易打造出能面对复杂网络情况的、高效健壮的均衡器。即使退一步说,独立于服务进程的均衡器也不会由于自身的稳定性影响到服务进程的稳定。
- 在服务拓扑感知方面代理均衡器也要更有优势。由于边车代理接受控制平面的统一管理,当服务节点拓扑关系发生变化时,控制平面就会主动向边车代理发送更新服务清单的控制指令,这避免了此前客户端均衡器必须长期主动轮询服务注册中心所造成的浪费。
- 在安全性、可观测性上,由于边车代理都是一致的实现,有利于在服务间建立双向 TLS 通信,也有利于对整个调用链路给出更详细的统计信息。
- ……
总体而言,边车代理这种通过同一个 Pod 的独立容器实现的负载均衡器是目前处理微服务集群内部流量最理想的方式,只是服务网格本身仍是初生事物,还不足够成熟,对操作系统、网络和运维方面的知识要求也较高,但有理由相信随着时间的推移,未来这将会是微服务的主流通信方式。
地域与区域
最后,借助前文已经铺设好的上下文场景,笔者想再谈一个与负载均衡相关,但又不仅仅应用于负载均衡的概念:地域与区域。你是否有注意到在微服务相关的许多设施中,都带有着 Region、Zone 参数,如前文中提到过的服务注册中心 Eureka 的 Region、Zone、边车代理 Envoy 中的 Region、Zone、Sub-zone,如果你有云计算 IaaS 的使用经历,也会发现几乎所有云计算设备都有类似的概念。Region 和 Zone 是公有云计算先驱亚马逊 AWS提出的概念,它们的含义是指:
- Region 是地域的意思,譬如华北、东北、华东、华南,这些都是地域范围。面向全球或全国的大型系统的服务集群往往会部署在多个不同地域,譬如本节开头列举的案例场景,大型系统就是通过不同地域的机房来缩短用户与服务器之间的物理距离,提升响应速度,对于小型系统,地域一般就只在异地容灾时才会涉及到。需要注意,不同地域之间是没有内网连接的,所有流量都只能经过公众互联网相连,如果微服务的流量跨越了地域,实际就跟调用外部服务商提供的互联网服务没有任何差别了。所以集群内部流量是不会跨地域的,服务发现、负载均衡器默认也是不会支持跨地域的服务发现和负载均衡。
- Zone 是区域的意思,它是可用区域(Availability Zones)的简称,区域指在地理上位于同一地域内,但电力和网络是互相独立的物理区域,譬如在华东的上海、杭州、苏州的不同机房就是同一个地域的几个可用区域。同一个地域的可用区域之间具有内网连接,流量不占用公网带宽,因此区域是微服务集群内流量能够触及的最大范围。但你的应用是只部署在同一区域内,还是部署到几个不同可用区域中,要取决于你是否有做异地双活的需求,以及对网络延时的容忍程度。
- 可用区域对应于城市级别的区域的范围,一些场景中仍是过大了一些,即使是同一个区域中的机房,也可能存在具有差异的不同子网络,所以在部分微服务框架也提供了 Group、Sub-zone 等做进一步的细分控制,这些参数的意思通常是加权或优先访问同一个子区域的服务,但如果子区域中没有合适的,仍然会访问到可用区域中的其他服务。
- 地域和区域原本是云计算中的概念,对于一些中小型的微服务系统,尤其是非互联网的企业信息系统,很多仍然没有使用云计算设施,只部署在某个专有机房内部,只为特定人群提供服务,这就不需要涉及地理上地域、区域的概念了。此时完全可以自己灵活延拓 Region、Zone 参数的含义,达到优化虚拟化基础设施流量的目的。譬如,将服务发现的区域设置与 Kubernetes 的标签、选择器配合,实现内部服务请求其他服务时,优先使用同一个 Node 中提供的服务进行应答,以降低真实的网络消耗。
流量治理
容错性设计
Since services can fail at any time, it’s important to be able to detect the failures quickly and, if possible, automatically restore service
由于服务随时都有可能崩溃,因此快速的失败检测和自动恢复就显得至关重要。
—— Martin Fowler / James Lewis, Microservices, 2014
“容错性设计”(Design for Failure)是微服务的另一个核心原则,也是笔者书中多次反复强调的开发观念转变。不过,即使已经有一定的心理准备,大多数首次将微服务架构引入实际生产系统的开发者,在服务发现、网关路由等支持下,踏出了服务化的第一步以后,很可能仍会经历一段阵痛期,随着拆分出的服务越来越多,随之而来会面临以下两个问题的困扰:
- 由于某一个服务的崩溃,导致所有用到这个服务的其他服务都无法正常工作,一个点的错误经过层层传递,最终波及到调用链上与此有关的所有服务,这便是雪崩效应。如何防止雪崩效应便是微服务架构容错性设计原则的具体实践,否则服务化程度越高,整个系统反而越不稳定。
- 服务虽然没有崩溃,但由于处理能力有限,面临超过预期的突发请求时,大部分请求直至超时都无法完成处理。这种现象产生的后果跟交通堵塞是类似的,如果一开始没有得到及时的治理,后面就需要长时间才能使全部服务都恢复正常。
本章我们将围绕以上两个问题,提出服务容错、流量控制等一系列解决方案。这些措施并不是孤立的,它们相互之间存在很多联系,其中许多功能必须与此前介绍过的服务注册中心、服务网关、负载均衡器配合才能实现。理清楚这些技术措施背后的逻辑链条,是了解它们工作原理的捷径。
服务容错
Martin Fowler 与 James Lewis 提出的“微服务的九个核心特征”是构建微服务系统的指导性原则,但不是技术规范,并没有严格的约束力。在实际构建系统时候,其中多数特征可能会有或多或少的妥协,譬如分散治理、数据去中心化、轻量级通信机制、演进式设计,等等。但也有一些特征是无法做出妥协的,其中的典型就是今天我们讨论的主题:容错性设计。
容错性设计不能妥协源于分布式系统的本质是不可靠的,一个大的服务集群中,程序可能崩溃、节点可能宕机、网络可能中断,这些“意外情况”其实全部都在“意料之中”。原本信息系统设计成分布式架构的主要动力之一就是为了提升系统的可用性,最低限度也必须保证将原有系统重构为分布式架构之后,可用性不出现倒退下降才行。如果服务集群中出现任何一点差错都能让系统面临“千里之堤溃于蚁穴”的风险,那分布式恐怕就根本没有机会成为一种可用的系统架构形式。
容错策略
要落实容错性设计这条原则,除了思想观念上转变过来,正视程序必然是会出错的,对它进行有计划的防御之外,还必须了解一些常用的容错策略和容错设计模式,作为具体设计与编码实践的指导。这里容错策略指的是“面对故障,我们该做些什么”,稍后将讲解的容错设计模式指的是“要实现某种容错策略,我们该如何去做”。常见的容错策略有以下几种:
故障转移(Failover):高可用的服务集群中,多数的服务——尤其是那些经常被其他服务所依赖的关键路径上的服务,均会部署有多个副本。这些副本可能部署在不同的节点(避免节点宕机)、不同的网络交换机(避免网络分区)甚至是不同的可用区(避免整个地区发生灾害或电力、骨干网故障)中。故障转移是指如果调用的服务器出现故障,系统不会立即向调用者返回失败结果,而是自动切换到其他服务副本,尝试其他副本能否返回成功调用的结果,从而保证了整体的高可用性。
故障转移的容错策略应该有一定的调用次数限制,譬如允许最多重试三个服务,如果都发生报错,那还是会返回调用失败。原因不仅是因为重试是有执行成本的,更是因为过度的重试反而可能让系统处于更加不利的状况。譬如有以下调用链:Service A → Service B → Service C
假设 A 的超时阈值为 100 毫秒,而 B 调用 C 花费 60 毫秒,然后不幸失败了,这时候做故障转移其实已经没有太大意义了,因为即时下一次调用能够返回正确结果,也很可能同样需要耗费 60 毫秒时间,时间总和就已经触及 A 服务的超时阈值,所以在这种情况下故障转移反而对系统是不利的。
快速失败(Failfast):还有另外一些业务场景是不允许做故障转移的,故障转移策略能够实施的前提是要求服务具备幂等性,对于非幂等的服务,重复调用就可能产生脏数据,引起的麻烦远大于单纯的某次服务调用失败,此时就应该以快速失败作为首选的容错策略。譬如,在支付场景中,需要调用银行的扣款接口,如果该接口返回的结果是网络异常,程序是很难判断到底是扣款指令发送给银行时出现的网络异常,还是银行扣款后返回结果给服务时出现的网络异常的。为了避免重复扣款,此时最恰当可行的方案就是尽快让服务报错,坚决避免重试,尽快抛出异常,由调用者自行处理。
安全失败(Failsafe):在一个调用链路中的服务通常也有主路和旁路之分,并不见得其中每个服务都是不可或缺的,有部分服务失败了也不影响核心业务的正确性。譬如开发基于 Spring 管理的应用程序时,通过扩展点、事件或者 AOP 注入的逻辑往往就属于旁路逻辑,典型的有审计、日志、调试信息,等等。属于旁路逻辑的另一个显著特征是后续处理不会依赖其返回值,或者它的返回值是什么都不会影响后续处理的结果,譬如只是将返回值记录到数据库,并不使用它参与最终结果的运算。对这类逻辑,一种理想的容错策略是即使旁路逻辑调用实际失败了,也当作正确来返回,如果需要返回值的话,系统就自动返回一个符合要求的数据类型的对应零值,然后自动记录一条服务调用出错的日志备查即可,这种策略被称为安全失败。
沉默失败(Failsilent):如果大量的请求需要等到超时(或者长时间处理后)才宣告失败,很容易由于某个远程服务的请求堆积而消耗大量的线程、内存、网络等资源,进而影响到整个系统的稳定。面对这种情况,一种合理的失败策略是当请求失败后,就默认服务提供者一定时间内无法再对外提供服务,不再向它分配请求流量,将错误隔离开来,避免对系统其他部分产生影响,此即为沉默失败策略。
故障恢复(Failback):故障恢复一般不单独存在,而是作为其他容错策略的补充措施,一般在微服务管理框架中,如果设置容错策略为故障恢复的话,通常默认会采用快速失败加上故障恢复的策略组合。它是指当服务调用出错了以后,将该次调用失败的信息存入一个消息队列中,然后由系统自动开始异步重试调用。
故障恢复策略一方面是尽力促使失败的调用最终能够被正常执行,另一方面也可以为服务注册中心和负载均衡器及时提供服务恢复的通知信息。故障恢复显然也是要求服务必须具备幂等性的,由于它的重试是后台异步进行,即使最后调用成功了,原来的请求也早已经响应完毕,所以故障恢复策略一般用于对实时性要求不高的主路逻辑,同时也适合处理那些不需要返回值的旁路逻辑。为了避免在内存中异步调用任务堆积,故障恢复与故障转移一样,应该有最大重试次数的限制。并行调用(Forking):上面五种以“Fail”开头的策略是针对调用失败时如何进行弥补的,以下这两种策略则是在调用之前就开始考虑如何获得最大的成功概率。并行调用策略很符合人们日常对一些重要环节进行的“双重保险”或者“多重保险”的处理思路,它是指一开始就同时向多个服务副本发起调用,只要有其中任何一个返回成功,那调用便宣告成功,这是一种在关键场景中使用更高的执行成本换取执行时间和成功概率的策略。
广播调用(Broadcast):广播调用与并行调用是相对应的,都是同时发起多个调用,但并行调用是任何一个调用结果返回成功便宣告成功,广播调用则是要求所有的请求全部都成功,这次调用才算是成功,任何一个服务提供者出现异常都算调用失败,广播调用通常会被用于实现“刷新分布式缓存”这类的操作。
容错策略并非计算机科学独有的,在交通、能源、航天等很多领域都有容错性设计,也会使用到上面这些策略,并在自己的行业领域中进行解读与延伸。这里介绍到的容错策略并非全部,只是最常见的几种,笔者将它们各自的优缺点、应用场景总结为表 8-1,供大家使用时参考:
表 8-1 常见容错策略优缺点及应用场景对比
| 容错策略 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 故障转移 | 系统自动处理,调用者对失败的信息不可见 | 增加调用时间,额外的资源开销 | 调用幂等服务 对调用时间不敏感的场景 |
| 快速失败 | 调用者有对失败的处理完全控制权 不依赖服务的幂等性 | 调用者必须正确处理失败逻辑,如果一味只是对外抛异常,容易引起雪崩 | 调用非幂等的服务 超时阈值较低的场景 |
| 安全失败 | 不影响主路逻辑 | 只适用于旁路调用 | 调用链中的旁路服务 |
| 沉默失败 | 控制错误不影响全局 | 出错的地方将在一段时间内不可用 | 频繁超时的服务 |
| 故障恢复 | 调用失败后自动重试,也不影响主路逻辑 | 重试任务可能产生堆积,重试仍然可能失败 | 调用链中的旁路服务 对实时性要求不高的主路逻辑也可以使用 |
| 并行调用 | 尽可能在最短时间内获得最高的成功率 | 额外消耗机器资源,大部分调用可能都是无用功 | 资源充足且对失败容忍度低的场景 |
| 广播调用 | 支持同时对批量的服务提供者发起调用 | 资源消耗大,失败概率高 | 只适用于批量操作的场景 |
容错设计模式
为了实现各种各样的容错策略,开发人员总结出了一些被实践证明是有效的服务容错设计模式,譬如微服务中常见的断路器模式、舱壁隔离模式,重试模式,等等,以及将在下一节介绍的流量控制模式,如滑动时间窗模式、漏桶模式、令牌桶模式,等等。
断路器模式
断路器模式是微服务架构中最基础的容错设计模式,以至于像 Hystrix 这种服务治理工具往往被人们忽略了它的服务隔离、请求合并、请求缓存等其他服务治理职能,直接将它称之为微服务断路器或者熔断器。这个设计模式最早由技术作家 Michael Nygard 在《Release It!》一书中提出的,后又因 Martin Fowler 的《Circuit Breaker》一文而广为人知。
断路器的基本思路是很简单的,就是通过代理(断路器对象)来一对一地(一个远程服务对应一个断路器对象)接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它状态就自动变为“OPEN”,后续此断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求。通过断路器对远程服务的熔断,避免因持续的失败或拒绝而消耗资源,因持续的超时而堆积请求,最终的目的就是避免雪崩效应的出现。由此可见,断路器本质是一种快速失败策略的实现方式,它的工作过程可以通过下面图 8-1 来表示:
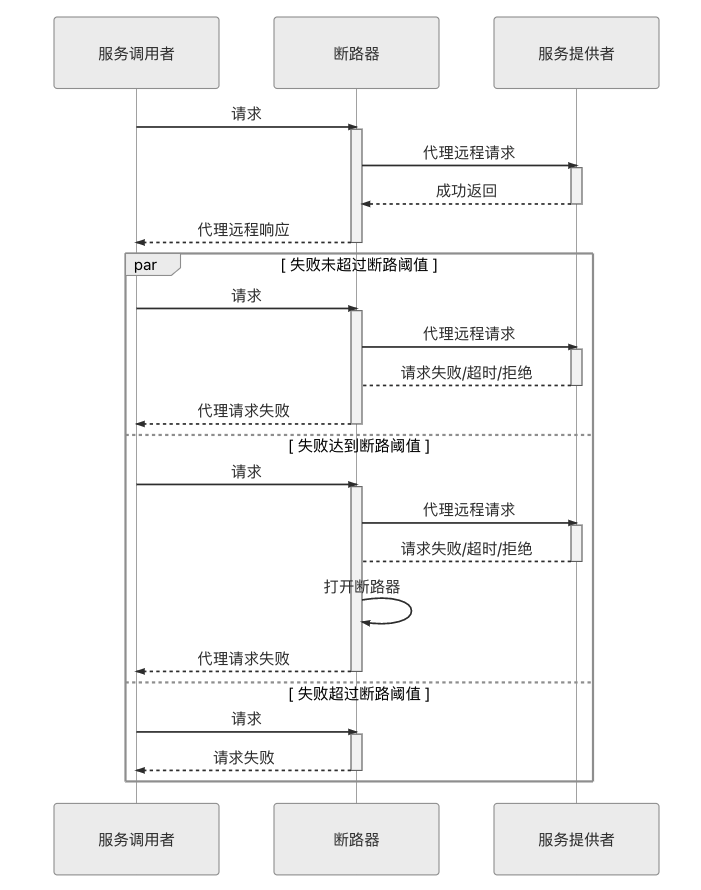
图 8-1 断路器工作过程时序图
从调用序列来看,断路器就是一种有限状态机,断路器模式就是根据自身状态变化自动调整代理请求策略的过程。一般要设置以下三种断路器的状态:
- CLOSED:表示断路器关闭,此时的远程请求会真正发送给服务提供者。断路器刚刚建立时默认处于这种状态,此后将持续监视远程请求的数量和执行结果,决定是否要进入 OPEN 状态。
- OPEN:表示断路器开启,此时不会进行远程请求,直接给服务调用者返回调用失败的信息,以实现快速失败策略。
- HALF OPEN:这是一种中间状态。断路器必须带有自动的故障恢复能力,当进入 OPEN 状态一段时间以后,将“自动”(一般是由下一次请求而不是计时器触发的,所以这里自动带引号)切换到 HALF OPEN 状态。该状态下,会放行一次远程调用,然后根据这次调用的结果成功与否,转换为 CLOSED 或者 OPEN 状态,以实现断路器的弹性恢复。
这些状态的转换逻辑与条件如图 8-2 所示:
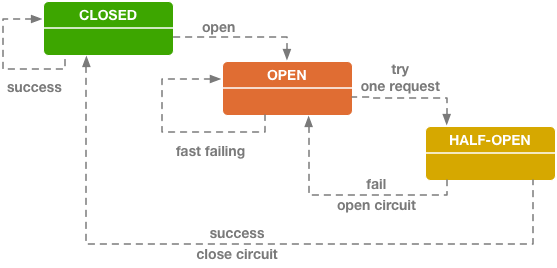
图 8-2 断路器的状态转换逻辑(图片来源)
OPEN 和 CLOSED 状态的含义是十分清晰的,与我们日常生活中电路的断路器并没有什么差别,值得讨论的是这两者的转换条件是什么?最简单直接的方案是只要遇到一次调用失败,那就默认以后所有的调用都会接着失败,断路器直接进入 OPEN 状态,但这样做的效果是很差的,虽然避免了故障扩散和请求堆积,却使得外部看来系统将表现极其不稳定。现实中,比较可行的办法是在以下两个条件同时满足时,断路器状态转变为 OPEN:
- 一段时间(譬如 10 秒以内)内请求数量达到一定阈值(譬如 20 个请求)。这个条件的意思是如果请求本身就很少,那就用不着断路器介入。
- 一段时间(譬如 10 秒以内)内请求的故障率(发生失败、超时、拒绝的统计比例)到达一定阈值(譬如 50%)。这个条件的意思是如果请求本身都能正确返回,也用不着断路器介入。
以上两个条件同时满足时,断路器就会转变为 OPEN 状态。括号中举例的数值是 Netflix Hystrix 的默认值,其他服务治理的工具,譬如 Resilience4j、Envoy 等也同样会包含有类似的设置。
借着断路器的上下文,笔者顺带讲一下服务治理中两个常见的易混淆概念:服务熔断和服务降级之间的联系与差别。断路器做的事情是自动进行服务熔断,这是一种快速失败的容错策略的实现方法。在快速失败策略明确反馈了故障信息给上游服务以后,上游服务必须能够主动处理调用失败的后果,而不是坐视故障扩散,这里的“处理”指的就是一种典型的服务降级逻辑,降级逻辑可以包括,但不应该仅仅限于是把异常信息抛到用户界面去,而应该尽力想办法通过其他路径解决问题,譬如把原本要处理的业务记录下来,留待以后重新处理是最低限度的通用降级逻辑。举个例子:你女朋友有事想召唤你,打你手机没人接,响了几声气冲冲地挂断后(快速失败),又打了你另外三个不同朋友的手机号(故障转移),都还是没能找到你(重试超过阈值)。这时候她生气地在微信上给你留言“三分钟不回电话就分手”,以此来与你取得联系。在这个不是太吉利的故事里,女朋友给你留言这个行为便是服务降级逻辑。
服务降级不一定是在出现错误后才被动执行的,许多场景里面,人们所谈论的降级更可能是指需要主动迫使服务进入降级逻辑的情况。譬如,出于应对可预见的峰值流量,或者是系统检修等原因,要关闭系统部分功能或关闭部分旁路服务,这时候就有可能会主动迫使这些服务降级。当然,此时服务降级就不一定是出于服务容错的目的了,更可能属于下一节要将的讲解的流量控制的范畴。
舱壁隔离模式
介绍过服务熔断和服务降级,我们再来看看另一个微服务治理中常听见的概念:服务隔离。舱壁隔离模式是常用的实现服务隔离的设计模式,舱壁这个词是来自造船业的舶来品,它原本的意思是设计舰船时,要在每个区域设计独立的水密舱室,一旦某个舱室进水,也只是影响这个舱室中的货物,而不至于让整艘舰艇沉没。这种思想就很符合容错策略中失败静默策略。
前面断路器中已经多次提到,调用外部服务的故障大致可以分为“失败”(如 400 Bad Request、500 Internal Server Error 等错误)、“拒绝”(如 401 Unauthorized、403 Forbidden 等错误)以及“超时”(如 408 Request Timeout、504 Gateway Timeout 等错误)三大类,其中“超时”引起的故障尤其容易给调用者带来全局性的风险。这是由于目前主流的网络访问大多是基于 TPR 并发模型(Thread per Request)来实现的,只要请求一直不结束(无论是以成功结束还是以失败结束),就要一直占用着某个线程不能释放。而线程是典型的整个系统的全局性资源,尤其是 Java 这类将线程映射为操作系统内核线程来实现的语言环境中,为了不让某一个远程服务的局部失败演变成全局性的影响,就必须设置某种止损方案,这便是服务隔离的意义。
我们来看一个更具体的场景,当分布式系统所依赖的某个服务,譬如下图中的“服务 I”发生了超时,那在高流量的访问下——或者更具体点,假设平均 1 秒钟内对该服务的调用会发生 50 次,这就意味着该服务如果长时间不结束的话,每秒会有 50 条用户线程被阻塞。如果这样的访问量一直持续,我们按 Tomcat 默认的 HTTP 超时时间 20 秒来计算,20 秒内将会阻塞掉 1000 条用户线程,此后才陆续会有用户线程因超时被释放出来,回归 Tomcat 的全局线程池中。一般 Java 应用的线程池最大只会设置到 200 至 400 之间,这意味着此时系统在外部将表现为所有服务的全面瘫痪,而不仅仅是只有涉及到“服务 I”的功能不可用,因为 Tomcat 已经没有任何空余的线程来为其他请求提供服务了。
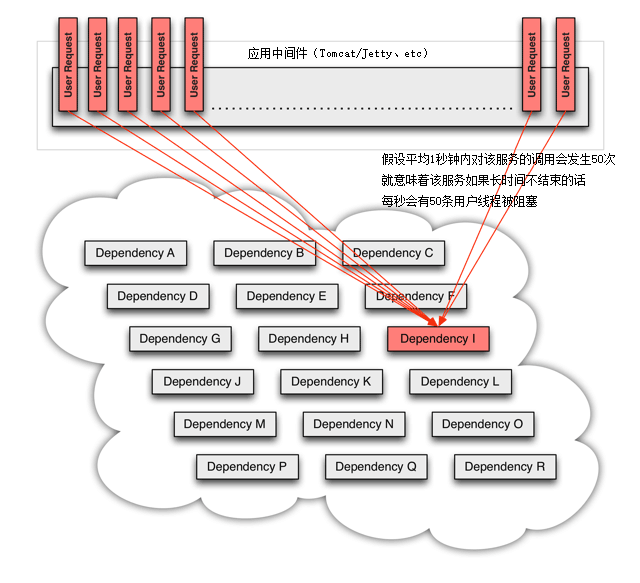
图 8-3 由于某个外部服务导致的阻塞(图片来自 Hystrix 使用文档)
对于这类情况,一种可行的解决办法是为每个服务单独设立线程池,这些线程池默认不预置活动线程,只用来控制单个服务的最大连接数。譬如,对出问题的“服务 I”设置了一个最大线程数为 5 的线程池,这时候它的超时故障就只会最多阻塞 5 条用户线程,而不至于影响全局。此时,其他不依赖“服务 I”的用户线程依然能够正常对外提供服务,如图 8-4 所示。
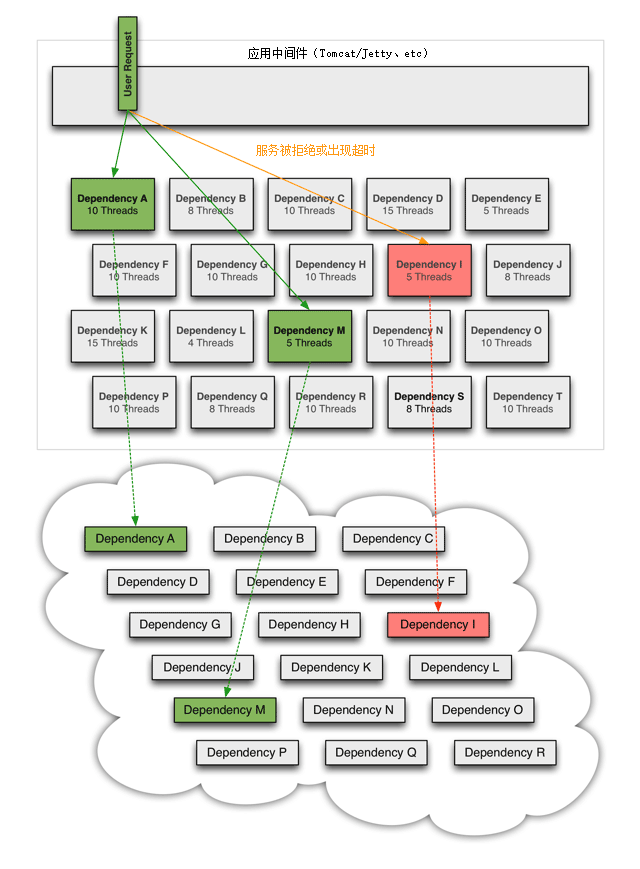
图 8-4 通过线程池将阻塞限制在一定范围内(图片来自 Hystrix 使用文档)
使用局部的线程池来控制服务的最大连接数有许多好处,当服务出问题时能够隔离影响,当服务恢复后,还可以通过清理掉局部线程池,瞬间恢复该服务的调用,而如果是 Tomcat 的全局线程池被占满,再恢复就会十分麻烦。但是,局部线程池有一个显著的弱点,它额外增加了 CPU 的开销,每个独立的线程池都要进行排队、调度和下文切换工作。根据 Netflix 官方给出的数据,一旦启用 Hystrix 线程池来进行服务隔离,大概会为每次服务调用增加约 3 毫秒至 10 毫秒的延时,如果调用链中有 20 次远程服务调用,那每次请求就要多付出 60 毫秒至 200 毫秒的代价来换取服务隔离的安全保障。
为应对这种情况,还有一种更轻量的可以用来控制服务最大连接数的办法:信号量机制(Semaphore)。如果不考虑清理线程池、客户端主动中断线程这些额外的功能,仅仅是为了控制一个服务并发调用的最大次数,可以只为每个远程服务维护一个线程安全的计数器即可,并不需要建立局部线程池。具体做法是当服务开始调用时计数器加 1,服务返回结果后计数器减 1,一旦计数器超过设置的阈值就立即开始限流,在回落到阈值范围之前都不再允许请求了。由于不需要承担线程的排队、调度、切换工作,所以单纯维护一个作为计数器的信号量的性能损耗,相对于局部线程池来说几乎可以忽略不计。
以上介绍的是从微观的、服务调用的角度应用的舱壁隔离设计模式,舱壁隔离模式还可以在更高层、更宏观的场景中使用,不是按调用线程,而是按功能、按子系统、按用户类型等条件来隔离资源都是可以的,譬如,根据用户等级、用户是否 VIP、用户来访的地域等各种因素,将请求分流到独立的服务实例去,这样即使某一个实例完全崩溃了,也只是影响到其中某一部分的用户,把波及范围尽可能控制住。一般来说,我们会选择将服务层面的隔离实现在服务调用端或者边车代理上,将系统层面的隔离实现在 DNS 或者网关处。
重试模式
行文至此,笔者讲解了使用断路器模式实现快速失败策略,使用舱壁隔离模式实现静默失败策略,在断路器中举例的主动对非关键的旁路服务进行降级,亦可算作是对安全失败策略的一种体现。那还剩下故障转移和故障恢复两种策略的实现尚未涉及。接下来,笔者以重试模式来介绍这两种容错策略的主流实现方案。
故障转移和故障恢复策略都需要对服务进行重复调用,差别是这些重复调用有可能是同步的,也可能是后台异步进行;有可能会重复调用同一个服务,也可能会调用到服务的其他副本。无论具体是通过怎样的方式调用、调用的服务实例是否相同,都可以归结为重试设计模式的应用范畴。重试模式适合解决系统中的瞬时故障,简单的说就是有可能自己恢复(Resilient,称为自愈,也叫做回弹性)的临时性失灵,网络抖动、服务的临时过载(典型的如返回了 503 Bad Gateway 错误)这些都属于瞬时故障。重试模式实现并不困难,即使完全不考虑框架的支持,靠程序员自己编写十几行代码也能够完成。在实践中,重试模式面临的风险反而大多来源于太过简单而导致的滥用。我们判断是否应该且是否能够对一个服务进行重试时,应同时满足以下几个前提条件:
- 仅在主路逻辑的关键服务上进行同步的重试,不是关键的服务,一般不把重试作为首选容错方案,尤其不该进行同步重试。
- 仅对由瞬时故障导致的失败进行重试。尽管一个故障是否属于可自愈的瞬时故障并不容易精确判定,但从 HTTP 的状态码上至少可以获得一些初步的结论,譬如,当发出的请求收到了 401 Unauthorized 响应,说明服务本身是可用的,只是你没有权限调用,这时候再去重试就没有什么意义。功能完善的服务治理工具会提供具体的重试策略配置(如 Envoy 的Retry Policy),可以根据包括 HTTP 响应码在内的各种具体条件来设置不同的重试参数。
- 仅对具备幂等性的服务进行重试。如果服务调用者和提供者不属于同一个团队,那服务是否幂等其实也是一个难以精确判断的问题,但仍可以找到一些总体上通用的原则。譬如,RESTful 服务中的 POST 请求是非幂等的,而 GET、HEAD、OPTIONS、TRACE 由于不会改变资源状态,这些请求应该被设计成幂等的;PUT 请求一般也是幂等的,因为 n 个 PUT 请求会覆盖相同的资源 n-1 次;DELETE 也可看作是幂等的,同一个资源首次删除会得到 200 OK 响应,此后应该得到 204 No Content 响应。这些都是 HTTP 协议中定义的通用的指导原则,虽然对于具体服务如何实现并无强制约束力,但我们自己建设系统时,遵循业界惯例本身就是一种良好的习惯。
- 重试必须有明确的终止条件,常用的终止条件有两种:
- 超时终止:并不限于重试,所有调用远程服务都应该要有超时机制避免无限期的等待。这里只是强调重试模式更加应该配合上超时机制来使用,否则重试对系统很可能反而是有害的,笔者已经在前面介绍故障转移策略时举过具体的例子,这里就不重复了。
- 次数终止:重试必须要有一定限度,不能无限制地做下去,通常最多就只重试 2 至 5 次。重试不仅会给调用者带来负担,对于服务提供者也是同样是负担。所以应避免将重试次数设的太大。此外,如果服务提供者返回的响应头中带有Retry-After的话,尽管它没有强制约束力,我们也应该充分尊重服务端的要求,做个“有礼貌”的调用者。
由于重试模式可以在网络链路的多个环节中去实现,譬如客户端发起调用时自动重试,网关中自动重试、负载均衡器中自动重试,等等,而且现在的微服务框架都足够便捷,只需设置一两个开关参数就可以开启对某个服务甚至全部服务的重试机制。所以,对于没有太多经验的程序员,有可能根本意识不到其中会带来多大的负担。这里笔者举个具体例子:一套基于 Netflix OSS 建设的微服务系统,如果同时在 Zuul、Feign 和 Ribbon 上都打开了重试功能,且不考虑重试被超时终止的话,那总重试次数就相当于它们的重试次数的乘积。假设按它们都重试 4 次,且 Ribbon 可以转移 4 个服务副本来计算,理论上最多会产生高达 4×4×4×4=256 次调用请求。
熔断、隔离、重试、降级、超时等概念都是建立具有韧性的微服务系统必须的保障措施。目前,这些措施的正确运作,还主要是依靠开发人员对服务逻辑的了解,以及运维人员的经验去静态调整配置参数和阈值,但是面对能够自动扩缩(Auto Scale)的大型分布式系统,静态的配置越来越难以起到良好的效果,这就需要系统不仅要有能力自动根据服务负载来调整服务器的数量规模,同时还要有能力根据服务调用的统计结果,或者启发式搜索)的结果来自动变更容错策略和参数,这方面研究现在还处于各大厂商在内部分头摸索的初级阶段,是服务治理的未来重要发展方向之一。
本节介绍的容错策略和容错设计模式,最终目的均是为了避免服务集群中某个节点的故障导致整个系统发生雪崩效应,但仅仅做到容错,只让故障不扩散是远远不够的,我们还希望系统或者至少系统的核心功能能够表现出最佳的响应的能力,不受或少受硬件资源、网络带宽和系统中一两个缓慢服务的拖累。下一节,我们将面向如何解决集群中的短板效应,去讨论服务质量、流量管控等话题。
流量控制
任何一个系统的运算、存储、网络资源都不是无限的,当系统资源不足以支撑外部超过预期的突发流量时,便应该要有取舍,建立面对超额流量自我保护的机制,这个机制就是微服务中常说的“限流”。在介绍限流具体细节前,我们先一起来做一道小学三年级难度的算术四则运算场景应用题:
场景应用题
已知条件:
- 系统中一个业务操作需要调用 10 个服务协作来完成
- 该业务操作的总超时时间是 10 秒
- 每个服务的处理时间平均是 0.5 秒
集群中每个服务均部署了 20 个实例 副本
求解以下问题:
对于最后这个问题,如果仍然按照小学生的解题思路,最大处理能力为 80 TPS 的系统遇到 100 TPS 的请求,应该能完成其中的 80 TPS,也即是只有 20 TPS 的请求失败或被拒绝才对,然而这其实是最理想的情况,也是我们追求的目标。事实上,如果不做任何处理的话,更可能出现的结果是这 100 个请求中的每一个都开始了处理,但是大部分请求完成了其中 10 次服务调用中的 8 次或者 9 次,然后就超时没有然后了。多数服务调用都白白浪费掉,没有几个请求能够走完整笔业务操作。譬如早期的 12306 系统就明显存在这样的问题,全国人民都上去抢票的结果是全国人民谁都买不上票。为了避免这种状况出现,一个健壮的系统需要做到恰当的流量控制,更具体地说,需要妥善解决以下三个问题:
- 依据什么限流?:要不要控制流量,要控制哪些流量,控制力度要有多大,等等这些操作都没法在系统设计阶段静态地给出确定的结论,必须根据系统此前一段时间的运行状况,甚至未来一段时间的预测情况来动态决定。
- 具体如何限流?:解决系统具体是如何做到允许一部分请求能够通行,而另外一部分流量实行受控制的失败降级,这必须了解掌握常用的服务限流算法和设计模式。
- 超额流量如何处理?:超额流量可以有不同的处理策略,也许会直接返回失败(如 429 Too Many Requests),或者被迫使它们进入降级逻辑,这种被称为否决式限流。也可能让请求排队等待,暂时阻塞一段时间后继续处理,这种被称为阻塞式限流。
流量统计指标
要做流量控制,首先要弄清楚到底哪些指标能反映系统的流量压力大小。相较而言,容错的统计指标是明确的,容错的触发条件基本上只取决于请求的故障率,发生失败、拒绝与超时都算作故障;但限流的统计指标就不那么明确了,限流中的“流”到底指什么呢?要解答这个问题,我们先来理清经常用于衡量服务流量压力,但又较容易混淆的三个指标的定义:
- 每秒事务数(Transactions per Second,TPS):TPS 是衡量信息系统吞吐量的最终标准。“事务”可以理解为一个逻辑上具备原子性的业务操作。譬如你在 Fenix’s Bookstore 买了一本书,将要进行支付,“支付”就是一笔业务操作,支付无论成功还是不成功,这个操作在逻辑上是原子的,即逻辑上不可能让你买本书还成功支付了前面 200 页,又失败了后面 300 页。
- 每秒请求数(Hits per Second,HPS):HPS 是指每秒从客户端发向服务端的请求数(请将 Hits 理解为 Requests 而不是 Clicks,国内某些翻译把它理解为“每秒点击数”多少有点望文生义的嫌疑)。如果只要一个请求就能完成一笔业务,那 HPS 与 TPS 是等价的,但在一些场景(尤其常见于网页中)里,一笔业务可能需要多次请求才能完成。譬如你在 Fenix’s Bookstore 买了一本书要进行支付,尽管逻辑上它是原子的,但技术实现上,除非你是直接在银行开的商城中购物能够直接扣款,否则这个操作就很难在一次请求里完成,总要经过显示支付二维码、扫码付款、校验支付是否成功等过程,中间不可避免地会发生多次请求。
- 每秒查询数(Queries per Second,QPS):QPS 是指一台服务器能够响应的查询次数。如果只有一台服务器来应答请求,那 QPS 和 HPS 是等价的,但在分布式系统中,一个请求的响应往往要由后台多个服务节点共同协作来完成。譬如你在 Fenix’s Bookstore 买了一本书要进行支付,尽管扫描支付二维码时客户端只发送了一个请求,但这背后服务端很可能需要向仓储服务确认库存信息避免超卖、向支付服务发送指令划转货款、向用户服务修改用户的购物积分,等等,这里面每次内部访问都要消耗掉一次或多次查询数。
以上这三个指标都是基于调用计数的指标,在整体目标上我们当然最希望能够基于 TPS 来限流,因为信息系统最终是为人类用户来提供服务的,用户不关心业务到底是由多少个请求、多少个后台查询共同协作来实现。但是,系统的业务五花八门,不同的业务操作对系统的压力往往差异巨大,不具备可比性;而更关键的是,流量控制是针对用户实际操作场景来限流的,这不同于压力测试场景中无间隙(最多有些集合点)的全自动化操作,真实业务操作的耗时无可避免地受限于用户交互带来的不确定性,譬如前面例子中的“扫描支付二维码”这个步骤,如果用户掏出手机扫描二维码前先顺便回了两条短信息,那整个付款操作就要持续更长时间。此时,如果按照业务开始时计数器加 1,业务结束时计数器减 1,通过限制最大 TPS 来限流的话,就不能准确地反应出系统所承受的压力,所以直接针对 TPS 来限流实际上是很难操作的。
目前,主流系统大多倾向使用 HPS 作为首选的限流指标,它是相对容易观察统计的,而且能够在一定程度上反应系统当前以及接下来一段时间的压力。但限流指标并不存在任何必须遵循的权威法则,根据系统的实际需要,哪怕完全不选择基于调用计数的指标都是有可能的。譬如下载、视频、直播等 I/O 密集型系统,往往会把每次请求和响应报文的大小,而不是调用次数作为限流指标,譬如只允许单位时间通过 100MB 的流量。又譬如网络游戏等基于长连接的应用,可能会把登陆用户数作为限流指标,热门的网游往往超过一定用户数就会让你在登陆前排队等候。
限流设计模式
与容错模式类似,对于具体如何进行限流,也有一些常见常用的设计模式可以参考使用,本节将介绍流量计数器、滑动时间窗、漏桶和令牌桶四种限流设计模式。
流量计数器模式
做限流最容易想到的一种方法就是设置一个计算器,根据当前时刻的流量计数结果是否超过阈值来决定是否限流。譬如前面场景应用题中,我们计算得出了该系统能承受的最大持续流量是 80 TPS,那就控制任何一秒内,发现超过 80 次业务请求就直接拒绝掉超额部分。这种做法很直观,也确实有些简单的限流就是这么实现的,但它并不严谨,以下两个结论就很可能出乎对限流算法没有了解的同学意料之外:
- 即使每一秒的统计流量都没有超过 80 TPS,也不能说明系统没有遇到过大于 80 TPS 的流量压力。
你可以想像如下场景,如果系统连续两秒都收到 60 TPS 的访问请求,但这两个 60 TPS 请求分别是前 1 秒里面的后 0.5 秒,以及后 1 秒中的前面 0.5 秒所发生的。这样虽然每个周期的流量都不超过 80 TPS 请求的阈值,但是系统确实曾经在 1 秒内实在在发生了超过阈值的 120 TPS 请求。 - 即使连续若干秒的统计流量都超过了 80 TPS,也不能说明流量压力就一定超过了系统的承受能力。
你可以想像如下场景,如果 10 秒的时间片段中,前 3 秒 TPS 平均值到了 100,而后 7 秒的平均值是 30 左右,此时系统是否能够处理完这些请求而不产生超时失败?答案是可以的,因为条件中给出的超时时间是 10 秒,而最慢的请求也能在 8 秒左右处理完毕。如果只基于固定时间周期来控制请求阈值为 80 TPS,反而会误杀一部分请求,造成部分请求出现原本不必要的失败。
流量计数器的缺陷根源在于它只是针对时间点进行离散的统计,为了弥补该缺陷,一种名为“滑动时间窗”的限流模式被设计出来,它可以实现平滑的基于时间片段统计。
滑动时间窗模式
滑动窗口算法(Sliding Window Algorithm)在计算机科学的很多领域中都有成功的应用,譬如编译原理中的窥孔优化(Peephole Optimization)、TCP 协议的流量控制(Flow Control)等都使用到滑动窗口算法。对分布式系统来说,无论是服务容错中对服务响应结果的统计,还是流量控制中对服务请求数量的统计,都经常要用到滑动窗口算法。关于这个算法的运作过程,建议你能发挥想象力,在脑海中构造如下场景:在不断向前流淌的时间轴上,漂浮着一个固定大小的窗口,窗口与时间一起平滑地向前滚动。任何时刻静态地通过窗口内观察到的信息,都等价于一段长度与窗口大小相等、动态流动中时间片段的信息。由于窗口观察的目标都是时间轴,所以它被形象地称为“滑动时间窗模式”。
举个更具体的例子,假如我们准备观察时间片段为 10 秒,并以 1 秒为统计精度的话,那可以设定一个长度为 10 的数组(设计通常是以双头队列去实现,这里简化一下)和一个每秒触发 1 次的定时器。假如我们准备通过统计结果进行限流和容错,并定下限流阈值是最近 10 秒内收到的外部请求不要超过 500 个,服务熔断的阈值是最近 10 秒内故障率不超过 50%,那每个数组元素(图中称为 Buckets)中就应该存储请求的总数(实际是通过明细相加得到)及其中成功、失败、超时、拒绝的明细数,具体如下图所示。

滑动窗口模式示意(图片来自 Hystrix 使用文档)
文中虽然引用了 Hystrix 文档的图片,但 Hystrix 实际上是基于 RxJava 实现的,RxJava 的响应式编程思路与下面描述差异颇大。笔者的本意并不是去讨论某一款流量治理工具的具体实现细节,以下描述的步骤作为原理来理解是合适的。
当频率固定每秒一次的定时器被唤醒时,它应该完成以下几项工作,这也就是滑动时间窗的工作过程:
- 将数组最后一位的元素丢弃掉,并把所有元素都后移一位,然后在数组第一个插入一个新的空元素。这个步骤即为“滑动窗口”。
- 将计数器中所有统计信息写入到第一位的空元素中。
- 对数组中所有元素进行统计,并复位清空计数器数据供下一个统计周期使用。
滑动时间窗口模式的限流完全解决了流量计数器的缺陷,可以保证任意时间片段内,只需经过简单的调用计数比较,就能控制住请求次数一定不会超过限流的阈值,在单机限流或者分布式服务单点网关中的限流中很常用。不过,这种限流也有其缺点,它通常只适用于否决式限流,超过阈值的流量就必须强制失败或降级,很难进行阻塞等待处理,也就很难在细粒度上对流量曲线进行整形,起不到削峰填谷的作用。下面笔者继续介绍两种适用于阻塞式限流的限流模式。
漏桶模式
在计算机网络中,专门有一个术语流量整形(Traffic Shaping)用来描述如何限制网络设备的流量突变,使得网络报文以比较均匀的速度向外发送。 流量整形通常都需要用到缓冲区来实现,当报文的发送速度过快时,首先在缓冲区中暂存,然后再在控制算法的调节下均匀地发送这些被缓冲的报文。常用的控制算法有漏桶算法(Leaky Bucket Algorithm)和令牌桶算法(Token Bucket Algorithm)两种,这两种算法的思路截然相反,但达到的效果又是相似的。
所谓漏桶,就是大家小学做应用题时一定遇到过的“一个水池,每秒以 X 升速度注水,同时又以 Y 升速度出水,问水池啥时候装满”的那个奇怪的水池。你把请求当作水,水来了都先放进池子里,水池同时又以额定的速度出水,让请求进入系统中。这样,如果一段时间内注水过快的话,水池还能充当缓冲区,让出水口的速度不至于过快。不过,由于请求总是有超时时间的,所以缓冲区大小也必须是有限度的,当注水速度持续超过出水速度一段时间以后,水池终究会被灌满,此时,从网络的流量整形的角度看是体现为部分数据包被丢弃,而在信息系统的角度看就体现为有部分请求会遭遇失败和降级。
漏桶在代码实现上非常简单,它其实就是一个以请求对象作为元素的先入先出队列(FIFO Queue),队列长度就相当于漏桶的大小,当队列已满时便拒绝新的请求进入。漏桶实现起来很容易,困难在于如何确定漏桶的两个参数:桶的大小和水的流出速率。如果桶设置得太大,那服务依然可能遭遇到流量过大的冲击,不能完全发挥限流的作用;如果设置得太小,那很可能就会误杀掉一部分正常的请求,这种情况与流量计数器模式中举过的例子是一样的。流出速率在漏桶算法中一般是个固定值,对本节开头场景应用题中那样固定拓扑结构的服务是很合适的,但同时你也应该明白那是经过最大限度简化的场景,现实中系统的处理速度往往受到其内部拓扑结构变化和动态伸缩的影响,所以能够支持变动请求处理速率的令牌桶算法往往可能会是更受程序员青睐的选择。
令牌桶模式
如果说漏桶是小学应用题中的奇怪水池,那令牌桶就是你去银行办事时摆在门口的那台排队机。它与漏桶一样都是基于缓冲区的限流算法,只是方向刚好相反,漏桶是从水池里往系统出水,令牌桶则是系统往排队机中放入令牌。
假设我们要限制系统在 X 秒内最大请求次数不超过 Y,那就每间隔 X/Y 时间就往桶中放一个令牌,当有请求进来时,首先要从桶中取得一个准入的令牌,然后才能进入系统处理。任何时候,一旦请求进入桶中却发现没有令牌可取了,就应该马上失败或进入服务降级逻辑。与漏桶类似,令牌桶同样有最大容量,这意味着当系统比较空闲时,桶中令牌累积到一定程度就不再无限增加,预存在桶中的令牌便是请求最大缓冲的余量。上面这段话,可以转化为以下步骤来指导程序编码:
- 让系统以一个由限流目标决定的速率向桶中注入令牌,譬如要控制系统的访问不超过 100 次每秒,速率即设定为 100 个令牌每秒,每个令牌注入间隔为 1/100=10 毫秒。
- 桶中最多可以存放 N 个令牌,N 的具体数量是由超时时间和服务处理能力共同决定的。如果桶已满,第 N+1 个进入的令牌会被丢弃掉。
- 请求到时先从桶中取走 1 个令牌,如果桶已空就进入降级逻辑。
令牌桶模式的实现看似比较复杂,每间隔固定时间就要放新的令牌到桶中,但其实并不需要真的用一个专用线程或者定时器来做这件事情,只要在令牌中增加一个时间戳记录,每次获取令牌前,比较一下时间戳与当前时间,就可以轻易计算出这段时间需要放多少令牌进去,然后一次性放入即可,所以真正编码并不会显得复杂。
分布式限流
这节我们再向实际的信息系统前进一步,讨论分布式系统中的限流问题。此前,我们讨论的限流算法和模式全部是针对整个系统的限流,总是有意无意地假设或默认系统只提供一种业务操作,或者所有业务操作的消耗都是等价的,并不涉及到不同业务请求进入系统的服务集群后,分别会调用哪些服务、每个服务节点处理能力有何差别等问题。前面讨论过的那些限流算法,直接使用在单体架构的集群上是完全可行的,但到了微服务架构下,它们就最多只能应用于集群最入口处的网关上,对整个服务集群进行流量控制,而无法细粒度地管理流量在内部微服务节点中的流转情况。所以,我们把前面介绍的限流模式都统称为单机限流,把能够精细控制分布式集群中每个服务消耗量的限流算法称为分布式限流。
这两种限流算法实现上的核心差别在于如何管理限流的统计指标,单机限流很好办,指标都是存储在服务的内存当中,而分布式限流的目的就是要让各个服务节点的协同限流,无论是将限流功能封装为专门的远程服务,抑或是在系统采用的分布式框架中有专门的限流支持,都需要将原本在每个服务节点自己内存当中的统计数据给开放出来,让全局的限流服务可以访问到才行。
一种常见的简单分布式限流方法是将所有服务的统计结果都存入集中式缓存(如 Redis)中,以实现在集群内的共享,并通过分布式锁、信号量等机制,解决这些数据的读写访问时并发控制的问题。在可以共享统计数据的前提下,原本用于单机的限流模式理论上也是可以应用于分布式环境中的,可是其代价也显而易见:每次服务调用都必须要额外增加一次网络开销,所以这种方法的效率肯定是不高的,流量压力大时,限流本身反倒会显著降低系统的处理能力。
只要集中式存储统计信息,就不可避免地会产生网络开销,为了缓解这里产生的性能损耗,一种可以考虑的办法是在令牌桶限流模式基础上进行“货币化改造”,即不把令牌看作是只有准入和不准入的“通行证”,而看作数值形式的“货币额度”。当请求进入集群时,首先在 API 网关处领取到一定数额的“货币”,为了体现不同等级用户重要性的差别,他们的额度可以有所差异,譬如让 VIP 用户的额度更高甚至是无限的。我们将用户 A 的额度表示为 QuanityA。由于任何一个服务在响应请求时都需要消耗集群一定量的处理资源,所以访问每个服务时都要求消耗一定量的“货币”,假设服务 X 要消耗的额度表示为 CostX,那当用户 A 访问了 N 个服务以后,他剩余的额度 LimitN即表示为:
LimitN = QuanityA - ∑NCostX
此时,我们可以把剩余额度 LimitN作为内部限流的指标,规定在任何时候,只要一旦剩余额度 LimitN小于等于 0 时,就不再允许访问其他服务了。此时必须先发生一次网络请求,重新向令牌桶申请一次额度,成功后才能继续访问,不成功则进入降级逻辑。除此之外的任何时刻,即 LimitN不为零时,都无须额外的网络访问,因为计算 LimitN是完全可以在本地完成的。
基于额度的限流方案对限流的精确度有一定的影响,可能存在业务操作已经进行了一部分服务调用,却无法从令牌桶中再获取到新额度,因“资金链断裂”而导致业务操作失败。这种失败的代价是比较高昂的,它白白浪费了部分已经完成了的服务资源,但总体来说,它仍是一种并发性能和限流效果上都相对折衷可行的分布式限流方案。上一节提到过,对于分布式系统容错是必须要有、无法妥协的措施。但限流与容错不一样,做分布式限流从不追求“越彻底越好”,往往需要权衡方案的代价与收益。
可靠通讯
微服务提倡分散治理(Decentralized Governance),不追求统一的技术平台,提倡让团队有自由选择的权利,不受制于语言和技术框架。在开发阶段构建服务时,分散治理打破了由技术栈带来的约束,好处是不言自明的。但在运维阶段部署服务时,尤其是考量安全问题时,由 Java、Golang、Python、Node.js 等多种语言和框架共同组成的微服务系统,出现安全漏洞的概率肯定要比只采用其中某种语言、某种框架所构建的单体系统更高。为了避免由于单个服务节点出现漏洞被攻击者突破,进而导致整个系统和内网都遭到入侵,我们就必须打破一些传统的安全观念,以构筑更加可靠的服务间通信机制。
零信任网络
长期以来,主流的网络安全观念提倡根据某类与宿主机相关的特征,譬如机器所处的位置,或者机器的 IP 地址、子网等,把网络划分为不同的区域,不同的区域对应于不同风险级别和允许访问的网络资源权限,将安全防护措施集中部署在各个区域的边界之上,重点关注跨区域的网络流量。我们熟知的 VPN、DMZ、防火墙、内网、外网等概念,都可以说是因此而生的,这种安全模型今天被称为是基于边界的安全模型(Perimeter-Based Security Model,后文简称“边界安全”)。
边界安全是完全合情合理的做法,在“架构安全性”的“保密”一节,笔者就强调过安全不可能是绝对的,我们必须在可用性和安全性之间权衡取舍,否则,一台关掉电源拔掉网线,完全不能对外提供服务的“服务器”无疑就是最为安全的。边界安全着重对经过网络区域边界的流量进行检查,对可信任区域(内网)内部机器之间的流量则给予直接信任或者至少是较为宽松的处理策略,减小了安全设施对整个应用系统复杂度的影响,以及网络传输性能的额外损耗,这当然是很合理的。不过,今天单纯的边界安全已不足以满足大规模微服务系统技术异构和节点膨胀的发展需要。边界安全的核心问题在于边界上的防御措施即使自身能做到永远滴水不漏牢不可破,也很难保证内网中它所尽力保护的某一台服务器不会成为“猪队友”,一旦“可信的”网络区域中的某台服务器被攻陷,那边界安全措施就成了马其诺防线,攻击者很快就能以一台机器为跳板,侵入到整个内网,这是边界安全基因决定的固有的缺陷,从边界安全被提出的第一天起,这就是已经预料到的问题。微服务时代,我们已经转变了开发观念,承认了服务总是会出错的,现在我们也必须转变安全观念,承认一定会有被攻陷的服务,为此,我们需要寻找到与之匹配的新的网络安全模型。
2010 年,Forrester Research的首席分析师 John Kindervag 提出了零信任安全模型的概念(Zero-Trust Security Model,后文简称“零信任安全”),最初提出时是叫做“零信任架构”(Zero-Trust Architecture),这个概念当时并没有引发太大的关注,但随着微服务架构的日渐兴盛,越来越多的开发和运维人员注意到零信任安全模型与微服务所追求的安全目标是高度吻合的。
零信任安全模型的特征
零信任安全的中心思想是不应当以某种固有特征来自动信任任何流量,除非明确得到了能代表请求来源(不一定是人,更可能是另一个服务)的身份凭证,否则一律不会有默认的信任关系。在 2019 年,Google 发表了一篇在安全与研发领域里都备受关注的论文《BeyondProd: A New Approach to Cloud-Native Security》(BeyondCorp 和 BeyondProd 是谷歌最新一代安全框架的名字,从 2014 年起已连续发表了 6 篇关于 BeyondCorp 和 BeyondProd 的论文),此文中详细列举了传统的基于边界的网络安全模型与云原生时代下基于零信任网络的安全模型之间的差异,并描述了要完成边界安全模型到零信任安全模型的迁移所要实现的具体需求点,笔者将其翻译转述为如表 9-1 所示内容。
表 9-1 传统网络安全模型与云原生时代零信任模型对比
| 传统、边界安全模型 | 云原生、零信任安全模型 | 具体需求 |
|---|---|---|
| 基于防火墙等设施,认为边界内可信 | 服务到服务通信需认证,环境内的服务之间默认没有信任 | 保护网络边界(仍然有效);服务之间默认没有互信 |
| 用于特定的 IP 和硬件(机器) | 资源利用率、重用、共享更好,包括 IP 和硬件 | 受信任的机器运行来源已知的代码 |
| 基于 IP 的身份 | 基于服务的身份 | 同上 |
| 服务运行在已知的、可预期的服务器上 | 服务可运行在环境中的任何地方,包括私有云/公有云混合部署 | 同上 |
| 安全相关的需求由应用来实现,每个应用单独实现 | 由基础设施来实现,基础设施中集成了共享的安全性要求。 | 集中策略实施点(Choke Points),一致地应用到所有服务 |
| 对服务如何构建、评审、实施的安全需求的约束力较弱 | 安全相关的需求一致地应用到所有服务 | 同上 |
| 安全组件的可观测性较弱 | 有安全策略及其是否生效的全局视图 | 同上 |
| 发布不标准,发布频率较低 | 标准化的构建和发布流程,每个微服务变更独立,变更更频繁 | 简单、自动、标准化的变更发布流程 |
| 工作负载通常作为虚拟机部署或部署到物理主机,并使用物理机或管理程序进行隔离 | 封装的工作负载及其进程在共享的操作系统中运行,并有管理平台提供的某种机制来进行隔离 | 在共享的操作系统的工作负载之间进行隔离 |
表 9-1 已经系统地阐述了零信任安全在微服务、云原生环境中的具体落地过程了,后续的整篇论文(除了介绍 Google 自己的实现框架外)就是以此为主线来展开论述的,但由于表格过于简单,论文原文写的较为分散晦涩,笔者对其中主要观点按照自己的理解转述如下:
- 零信任网络不等同于放弃在边界上的保护设施:虽然防火墙等位于网络边界的设施是属于边界安全而不是零信任安全的概念,但它仍然是一种提升安全性的有效且必要的做法。在微服务集群的前端部署防火墙,把内部服务节点间的流量与来自互联网的流量隔离开来,这种做法无论何时都是值得提倡的,至少能够让内部服务避开来自互联网未经授权流量的饱和攻击,如最典型的DDoS 拒绝服务攻击。
- 身份只来源于服务:传统应用一般是部署在特定的服务器上的,这些机器的 IP、MAC 地址很少会发生变化,此时的系统的拓扑状态是相对静态的。基于这个前提,安全策略才会使用 IP 地址、主机名等作为身份标识符(Identifiers),无条件信任具有特性身份表示的服务。如今的微服务系统,尤其是云原生环境中的微服务系统,虚拟化基础设施已得到大范围应用,这使得服务所部署的 IP 地址、服务实例的数量随时都可能发生变化,因此,身份只能来源于服务本身所能够出示的身份凭证(通常是数字证书),而不再是服务所在的 IP 地址、主机名或者其它特征。
- 服务之间也没有固有的信任关系:这点决定了只有已知的、明确授权的调用者才能访问服务,阻止攻击者通过某个服务节点中的代码漏洞来越权调用到其他服务。如果某个服务节点被成功入侵,这一原则可阻止攻击者执行扩大其入侵范围,与微服务设计模式中使用断路器、舱壁隔离实现容错来避免雪崩效应类似,在安全方面也应当采用这种“互不信任”的模式来隔离入侵危害的影响范围。
- 集中、共享的安全策略实施点:这点与微服务的“分散治理”刚好相反,微服务提倡每个服务自己独立的负责自身所有的功能性与非功能性需求。而 Google 这个观点相当于为分散治理原则做了一个补充——分散治理,但涉及安全的非功能性需求(如身份管理、安全传输层、数据安全层)最好除外。一方面,要写出高度安全的代码极为不易,为此付出的精力甚至可能远高于业务逻辑本身,如果你有兴趣阅读基于 Spring Cloud 的 Fenix’s Bookstore 的源码,很容易就会发现在 Security 工程中的代码量是该项目所有微服务中最多的。另一方面,而且还是更重要的一个方面是让服务各自处理安全问题很容易会出现实现不一致或者出现漏洞时要反复修改多处地方,还有一些安全问题如果不立足于全局是很难彻底解决的,下一节面向于具体操作实践的“服务安全”中将会详细讲述。因此 Google 明确提出应该有集中式的“安全策略实施点”(原文中称之为 Choke Points),安全需求应该从微服务的应用代码下沉至云原生的基础设施里,这也契合其论文的标题“Cloud-Native Security”。
- 受信的机器运行来源已知的代码:限制了服务只能使用认证过的代码和配置,并且只能运行在认证过的环境中。分布式软件系统除了促使软件架构发生了重大变化之外,对软件的发布流程也有较大的改变,使其严重依赖持续集成与持续部署(Continuous Integration / Continuous Delivery,CI/CD)。从开发人员编写代码,到自动化测试,到自动集成,再到漏洞扫描,最后发布上线,这整套 CI/CD 流程被称作“软件供应链”(Software Supply Chain)。安全不仅仅局限于软件运行阶段,曾经有过XCodeGhost 风波这种针对软件供应链的有影响力的攻击事件,在编译阶段将恶意代码嵌入到软件当中,只要安装了此软件的用户就可能触发恶意代码,为此,零信任安全针对软件供应链的每一步都加入了安全控制策略。
- 自动化、标准化的变更管理:这点也是为何提倡通过基础设施而不是应用代码去实现安全功能的另一个重要理由。如果将安全放在应用上,由于应用本身的分散治理,这决定了安全也必然是难以统一和标准化的。做不到标准化就意味着做不到自动化,相反,一套独立于应用的安全基础设施,可以让运维人员轻松地了解基础设施变更对安全性的影响,并且可以在几乎不影响生产环境的情况下发布安全补丁程序。
- 强隔离性的工作负载:“工作负载”的概念贯穿了 Google 内部的 Borg 系统与后来 Kubernetes 系统,它是指在虚拟化技术支持下运行的一组能够协同提供服务的镜像。下一个部分介绍云原生基础设施时,笔者会详细介绍容器化,它仅仅是虚拟化的一个子集,容器比起传统虚拟机的隔离能力是有所降低的,这种设计对性能非常有利,却对安全相对不利,因此在强调安全性的应用里,会有专门关注强隔离性的容器运行工具出现。
Google 的实践探索
Google 认为零信任安全模型的最终目标是实现整个基础设施之上的自动化安全控制,服务所需的安全能力可以与服务自身一起,以相同方式自动进行伸缩扩展。对于程序来说,做到安全是日常,风险是例外(Secure by Default and Insecure by Exception);对于人类来说,做到袖手旁观是日常,主动干预是例外(Human Actions Should Be by Exception, Not Routine),这的确是很美好的愿景,只是这种“喊口号”式的目标在软件发展史上曾提出过多次,却一直难以真正达成,其中原因开篇就提过,安全不可能是绝对的,而是有成本的。很显然,零信任网络模型之所以在今天才真正严肃地讨论,并不是因为它本身有多么巧妙、有什么此前没有想到的好办法,而是受制于前文中提到的边界安全模型的“合理之处”,即“安全设施对整个应用系统复杂度的影响,以及网络传输性能的额外损耗”。
那到底要实现零信任安全这个目标的代价是什么?会有多大?笔者照 Google 论文所述来回答这个问题:为了保护服务集群内的代码与基础设施,Google 设计了一系列的内部工具,才最终得以实现前面所说的那些安全原则:
- 为了在网络边界上保护内部服务免受 DDoS 攻击,设计了名为 Google Front End(名字意为“最终用户访问请求的终点”)的边缘代理,负责保证此后所有流量都在 TLS 之上传输,并自动将流量路由到适合的可用区域之中。
- 为了强制身份只来源于服务,设计了名为 Application Layer Transport Security(应用层传输安全)的服务认证机制,这是一个用于双向认证和传输加密的系统,自动将服务与它的身份标识符绑定,使得所有服务间流量都不必再使用服务名称、主机 IP 来判断对方的身份。
- 为了确保服务间不再有默认的信任关系,设计了 Service Access Policy(服务访问策略)来管理一个服务向另一个服务发起请求时所需提供的认证、鉴权和审计策略,并支持全局视角的访问控制与分析,以达成“集中、共享的安全策略实施点”这条原则。
- 为了实现仅以受信的机器运行来源已知的代码,设计了名为 Binary Authorization(二进制授权)的部署时检查机制,确保在软件供应链的每一个阶段,都符合内部安全检查策略,并对此进行授权与鉴权。同时设计了名为 Host Integrity(宿主机完整性)的机器安全启动程序,在创建宿主机时自动验证包括 BIOS、BMC、Bootloader 和操作系统内核的数字签名。
- 为了工作负载能够具有强隔离性,设计了名为gVisor的轻量级虚拟化方案,这个方案与此前由 Intel 发起的Kata Containers的思路异曲同工。目的都是解决容器共享操作系统内核而导致隔离性不足的安全缺陷,做法都是为每个容器提供了一个独立的虚拟 Linux 内核,譬如 gVisor 是用 Golang 实现了一个名为Sentry的能够提供传统操作系统内核的能力的进程,严格来说无论是 gVisor 还是 Kata Containers,尽管披着容器运行时的外衣,但本质上都是轻量级虚拟机。
作为一名普通的软件开发者,看完 Google 关于零信任安全的论文,或者听完笔者这些简要的转述,了解到即使 Google 也须花费如此庞大的精力才能做到零信任安全,最有可能的感受大概不是对零信任安全心生向往,而是准备对它挥手告别了。哪怕不需要开发、不需要购买,免费将上面 Google 开发的安全组件赠送于你,大多数开发团队恐怕也没有足够的运维能力。
在微服务时代以前,传统的的软件系统与研发模式的确是很难承受零信任安全模型的代价的,只有到了云原生时代,虚拟化的基础设施长足发展,能将复杂性隐藏于基础设施之内,开发者不需要为达成每一条安全原则而专门开发或引入可感知的安全设施;只有容器与虚拟化网络的性能足够高,可以弥补安全隔离与安全通信的额外损耗的前提下,零信任网络的安全模型才有它生根发芽的土壤。
零信任安全引入了比边界安全更细致更复杂安全措施的同时,也强调自动与透明的重要性,既要保证系统各个微服务之间能安全通信,同时也不削弱微服务架构本身的设计原则,譬如集中式的安全并不抵触于分散治理原则,安全机制并不影响服务的自动伸缩和有效的封装,等等。总而言之,只有零信任安全的成本在开发与运维上都是可接受的,它才不会变成仅仅具备理论可行性的“大饼”,不会给软件带来额外的负担。如何构建零信任网络安全是一个非常大而且比较前沿的话题,下一节,笔者将从实践角度出发,更具体更量化地展示零信任安全模型的价值与权衡。
服务安全
前置知识
本文涉及到 SSL/TLS、PKI、CA、OAuth2、RBAC、JWT 等概念,直接依赖于“安全架构”部分的认证、授权、凭证、传输四节对安全基础知识的铺垫,这四篇文章中介绍过的内容,笔者在本篇中将不再重复,建议读者先行阅读。
在第五章“架构安全性”里,我们了解过那些跟具体架构形式无关的、业界主流的安全概念和技术标准(稍后就会频繁用到的 TLS、JWT、OAuth 2 等概念);上一节“零信任网络”里,我们探讨了与微服务运作特点相适应的零信任安全模型。本节里,我们将从实践和编码的角度出发,介绍在前微服务时代(以 Spring Cloud 为例)和云原生时代(以 Istio over Kubernetes 为例)分别是如何实现安全传输、认证和授权的,通过这两者的对比,探讨在微服务架构下,应如何将业界的安全技术标准引入并实际落地,实现零信任网络下安全的服务访问。
建立信任
零信任网络里不存在默认的信任关系,一切服务调用、资源访问成功与否,均需以调用者与提供者间已建立的信任关系为前提。此前我们曾讨论过,真实世界里,能够达成信任的基本途径不外乎基于共同私密信息的信任和基于权威公证人的信任两种;网络世界里,因为客户端和服务端之间一般没有什么共同私密信息,所以真正能采用的就只能是基于权威公证人的信任,它有个标准的名字:公开密钥基础设施(Public Key Infrastructure,PKI)。
PKI 是构建传输安全层(Transport Layer Security,TLS)的必要基础。在任何网络设施都不可信任的假设前提下,无论是 DNS 服务器、代理服务器、负载均衡器还是路由器,传输路径上的每一个节点都有可能监听或者篡改通信双方传输的信息。要保证通信过程不受到中间人攻击的威胁,启用 TLS 对传输通道本身进行加密,让发送者发出的内容只有接受者可以解密是唯一具备可行性的方案。建立 TLS 传输,说起来似乎不复杂,只要在部署服务器时预置好CA 根证书,以后用该 CA 为部署的服务签发 TLS 证书便是。但落到实际操作上,这事情就属于典型的“必须集中在基础设施中自动进行的安全策略实施点”,面对数量庞大且能够自动扩缩的服务节点,依赖运维人员手工去部署和轮换根证书必定是难以为继的。除了随服务节点动态扩缩而来的运维压力外,微服务中 TLS 认证的频次也显著高于传统的应用,比起公众互联网中主流单向的 TLS 认证,在零信任网络中,往往要启用双向 TLS 认证(Mutual TLS Authentication,常简写为 mTLS),即不仅要确认服务端的身份,还需要确认调用者的身份。
- 单向 TLS 认证:只需要服务端提供证书,客户端通过服务端证书验证服务器的身份,但服务器并不验证客户端的身份。单向 TLS 用于公开的服务,即任何客户端都被允许连接到服务进行访问,它保护的重点是客户端免遭冒牌服务器的欺骗。
- 双向 TLS 认证:客户端、服务端双方都要提供证书,双方各自通过对方提供的证书来验证对方的身份。双向 TLS 用于私密的服务,即服务只允许特定身份的客户端访问,它除了保护客户端不连接到冒牌服务器外,也保护服务端不遭到非法用户的越权访问。
对于以上提到的围绕 TLS 而展开的密钥生成、证书分发、签名请求(Certificate Signing Request,CSR)、更新轮换等是一套操作起来非常繁琐的流程,稍有疏忽就会产生安全漏洞,所以尽管理论上可行,但实践中如果没有自动化的基础设施的支持,仅靠应用程序和运维人员的努力,是很难成功实施零信任安全模型的。下面我们结合 Fenix’s Bookstore 的代码,聚焦于“认证”和“授权”两个最基本的安全需求,看它们在微服务架构下,有或者没有基础设施支持时,各是如何实现的。
认证
根据认证的目标对象可以把认证分为两种类型,一种是以机器作为认证对象,即访问服务的流量来源是另外一个服务,称为服务认证(Peer Authentication,直译过来是“节点认证”);另一种是以人类作为认证对象,即访问服务的流量来自于最终用户,称为请求认证(Request Authentication)。无论哪一种认证,无论是否有基础设施的支持,均要有可行的方案来确定服务调用者的身份,建立起信任关系才能调用服务。
服务认证
Istio 版本的 Fenix’s Bookstore 采用了双向 TLS 认证作为服务调用双方的身份认证手段。得益于 Istio 提供的基础设施的支持,令我们不需要 Google Front End、Application Layer Transport Security 这些安全组件,也不需要部署 PKI 和 CA,甚至无需改动任何代码就可以启用 mTLS 认证。不过,Istio 毕竟是新生事物,你准备在自己的生产系统中启用 mTLS 之前,要先想一下是否整个服务集群全部节点都受 Istio 管理?如果每一个服务提供者、调用者均受 Istio 管理,那 mTLS 就是最理想的认证方案。你只需要参考以下简单的 PeerAuthentication CRD配置,即可对某个Kubernetes 名称空间范围内所有的流量均启用 mTLS:
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: authentication-mtls
namespace: bookstore-servicemesh
spec:
mtls:
mode: STRICT如果你的分布式系统还没有达到完全云原生的程度,其中仍存在部分不受 Istio 管理(即未注入 Sidecar)的服务端或者客户端(这是颇为常见的),你也可以将 mTLS 传输声明为“宽容模式”(Permissive Mode)。宽容模式的含义是受 Istio 管理的服务会允许同时接受明文和 mTLS 两种流量,明文流量仅用于与那些不受 Istio 管理的节点进行交互,你需要自行想办法解决明文流量的认证问题;而对于服务网格内部的流量,就可以使用 mTLS 认证。宽容模式为普通微服务向服务网格迁移提供了良好的灵活性,让运维人员能够逐个服务进行 mTLS 升级,原本没有启用 mTLS 的服务在启用 mTLS 时甚至可以不中断现存已建立的明文传输连接,完全不会被最终用户感知到。一旦所有服务都完成迁移,便可将整个系统设置为严格 TLS 模式,即上面代码中的mode: STRICT。
在 Spring Cloud 版本的 Fenix’s Bookstore 里,因为没有基础设施的支持,一切认证工作就不得不在应用层面去实现。笔者选择的方案是借用OAtuh2 协议的客户端模式来进行认证,其大体思路有如下两步:
- 每一个要调用服务的客户端都与认证服务器约定好一组只有自己知道的密钥(Client Secret),这个约定过程应该是由运维人员在线下自行完成,通过参数传给服务,而不是由开发人员在源码或配置文件中直接设定。笔者在演示工程的代码注释中专门强调了这点,以免有读者被示例代码中包含密钥的做法所误导。密钥就是客户端的身份证明,客户端调用服务时,会先使用该密钥向认证服务器申请到 JWT 令牌,然后通过令牌证明自己的身份,最后访问服务。如以下代码所示,它定义了五个客户端,其中四个是集群内部的微服务,均使用客户端模式,且注明了授权范围是
SERVICE(授权范围在后面介绍授权中会用到),第一个是前端代码的微服务,使用密码模式,授权范围是BROWSER。
/**
* 客户端列表
*/
private static final List<Client> clients = Arrays.asList(
new Client("bookstore_frontend", "bookstore_secret", new String[]{GrantType.PASSWORD, GrantType.REFRESH_TOKEN}, new String[]{Scope.BROWSER}),
// 微服务一共有Security微服务、Account微服务、Warehouse微服务、Payment微服务四个客户端
// 如果正式使用,这部分信息应该做成可以配置的,以便快速增加微服务的类型。clientSecret也不应该出现在源码中,应由外部配置传入
new Client("account", "account_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}),
new Client("warehouse", "warehouse_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}),
new Client("payment", "payment_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE}),
new Client("security", "security_secret", new String[]{GrantType.CLIENT_CREDENTIALS}, new String[]{Scope.SERVICE})
);- 每一个对外提供服务的服务端,都扮演着 OAuth 2 中的资源服务器的角色,它们均声明为要求提供客户端模式的凭证,如以下代码所示。客户端要调用受保护的服务,就必须先出示能证明调用者身份的 JWT 令牌,否则就会遭到拒绝,这个操作本质上是授权,但是在授权过程中已实现了服务的身份认证。
public ClientCredentialsResourceDetails clientCredentialsResourceDetails() {
return new ClientCredentialsResourceDetails();
}由于每一个微服务都同时具有服务端和客户端两种身份,既消费其他服务,也提供服务供别人消费,所以这些代码在每个微服务中都应有包含(放在公共 infrastructure 工程里)。Spring Security 提供的过滤器会自动拦截请求、驱动认证、授权检查的执行,申请和验证 JWT 令牌等操作无论在开发期对程序员,还是运行期对用户都能做到相对透明。尽管如此,以上做法仍然是一种应用层面的、不加密传输的解决方案。前文提到在零信任网络中,面对可能的中间人攻击,TLS 是唯一可行的办法,言下之意是即使应用层的认证能一定程度上保护服务不被身份不明的客户端越权调用,但对传输过程中内容被监听、篡改、以及被攻击者在传输途中拿到 JWT 令牌后再去冒认调用者身份调用其他服务都是无法防御的。简而言之,这种方案不适用于零信任安全模型,只能在默认内网节点间具备信任关系的边界安全模型上才能良好工作。
用户认证
对于来自最终用户的请求认证,Istio 版本的 Fenix’s Bookstore 仍然能做到单纯依靠基础设施解决问题,整个认证过程无需应用程序参与(生成 JWT 令牌还是在应用中生成的,因为 Fenix’s Bookstore 并没有使用独立的用户认证服务器,只有应用本身才拥有用户信息)。当来自最终用户的请求进入服务网格时,Istio 会自动根据配置中的JWKS(JSON Web Key Set)来验证令牌的合法性,如果令牌没有被篡改过且在有效期内,就信任 Payload 中的用户身份,并从令牌的 Iss 字段中获得 Principal。
关于 Iss、Principals 等概念,在架构安全性中都有介绍过,如果忘记了可以回看前文复习一下。JWKS 倒是之前从没有提到过的名词术语,它代表了一个密钥仓库。我们知道分布式系统中,JWT 应采用非对称的签名算法(RSA SHA256、ECDSA SHA256 等,默认的 HMAC SHA256 属于对称加密),认证服务器使用私钥对 Payload 进行签名,资源服务器使用公钥对签名进行验证。常与 JWT 配合使用的 JWK(JSON Web Key)就是一种存储密钥的纯文本格式,本质上和JKS(Java Key Storage)、P12(Predecessor of PKCS#12)、PEM(Privacy Enhanced Mail)这些常见的密钥格式在功能上并没有什么差别。JWKS 顾名思义就是一组 JWK 的集合,支持 JWKS 的系统,能通过 JWT 令牌 Header 中的 KID(Key ID)来自动匹配出应该使用哪个 JWK 来验证签名。
以下是 Istio 版本的 Fenix’s Bookstore 中的用户认证配置,其中jwks字段配的就是 JWKS 全文(实际生产中并不推荐这样做,应该使用jwksUri来配置一个 JWKS 地址,以方便密钥轮换),根据这里配置的密钥信息,Istio 就能够验证请求中附带的 JWT 是否合法。
apiVersion: security.istio.io/v1beta1
kind: RequestAuthentication
metadata:
name: authentication-jwt-token
namespace: bookstore-servicemesh
spec:
jwtRules:
- issuer: "icyfenix@gmail.com"
# Envoy默认只认“Bearer”作为JWT前缀,之前其他地方用的都是小写,这里专门兼容一下
fromHeaders:
- name: Authorization
prefix: "bearer "
# 在rsa-key目录下放了用来生成这个JWKS的证书,最初是用java keytool生成的jks格式,一般转jwks都是用pkcs12或者pem格式,为方便使用也一起附带了
jwks: |
{
"keys": [
{
"e": "AQAB",
"kid": "bookstore-jwt-kid",
"kty": "RSA",
"n": "i-htQPOTvNMccJjOkCAzd3YlqBElURzkaeRLDoJYskyU59JdGO-p_q4JEH0DZOM2BbonGI4lIHFkiZLO4IBBZ5j2P7U6QYURt6-AyjS6RGw9v_wFdIRlyBI9D3EO7u8rCA4RktBLPavfEc5BwYX2Vb9wX6N63tV48cP1CoGU0GtIq9HTqbEQs5KVmme5n4XOuzxQ6B2AGaPBJgdq_K0ZWDkXiqPz6921X3oiNYPCQ22bvFxb4yFX8ZfbxeYc-1rN7PaUsK009qOx-qRenHpWgPVfagMbNYkm0TOHNOWXqukxE-soCDI_Nc--1khWCmQ9E2B82ap7IXsVBAnBIaV9WQ"
}
]
}
forwardOriginalToken: trueSpring Cloud 版本的 Fenix’s Bookstore 就略微麻烦一些,它依然是采用 JWT 令牌作为用户身份凭证的载体,认证过程依然在 Spring Security 的过滤器里中自动完成,因讨论重点不在 Spring Security 的过滤器工作原理,所以详细过程就不展开了,主要路径是:过滤器 → 令牌服务 → 令牌实现。Spring Security 已经做好了认证所需的绝大部分的工作,真正要开发者去编写的代码是令牌的具体实现,即代码中名为RSA256PublicJWTAccessToken的实现类。它的作用是加载 Resource 目录下的公钥证书public.cert(实在是怕“抄作业不改名字”的行为,笔者再一次强调不要将密码、密钥、证书这类敏感信息打包到程序中,示例代码只是为了演示,实际生产应该由运维人员管理密钥),验证请求中的 JWT 令牌是否合法。
@Named
public class RSA256PublicJWTAccessToken extends JWTAccessToken {
RSA256PublicJWTAccessToken(UserDetailsService userDetailsService) throws IOException {
super(userDetailsService);
Resource resource = new ClassPathResource("public.cert");
String publicKey = new String(FileCopyUtils.copyToByteArray(resource.getInputStream()));
setVerifierKey(publicKey);
}
}如果 JWT 令牌合法,Spring Security 的过滤器就会放行调用请求,并从令牌中提取出 Principals,放到自己的安全上下文中(即SecurityContextHolder.getContext())。开发实际项目时,你可以根据需要自行决定 Principals 的具体形式,既可以像 Istio 中那样直接从令牌中取出来,以字符串形式原样存放,节省一些数据库或者缓存的查询开销;也可以统一做些额外的转换处理,以方便后续业务使用,譬如将 Principals 自动转换为系统中用户对象。Fenix’s Bookstore 转换操作是在 JWT 令牌的父类JWTAccessToken中完成的。可见尽管由应用自己来做请求验证会有一定的代码量和侵入性,但同时自由度确实也会更高一些。
为方便不同版本实现之间的对比,在 Istio 版本中保留了 Spring Security 自动从令牌转换 Principals 为用户对象的逻辑,因此必须在 YAML 中包含forwardOriginalToken: true的配置,告诉 Istio 验证完 JWT 令牌后不要丢弃掉请求中的 Authorization Header,原样转发给后面的服务处理。
授权
经过认证之后,合法的调用者就有了可信任的身份,此时就已经不再需要区分调用者到底是机器(服务)还是人类(最终用户)了,只根据其身份角色来进行权限访问控制,即我们常说的 RBAC。不过为了更便于理解,Fenix’s Bookstore 提供的示例代码仍然沿用此前的思路,分别针对来自“服务”和“用户”的流量来控制权限和访问范围。
举个具体例子,如果我们准备把一部分微服务视为私有服务,限制它只接受来自集群内部其他服务的请求,另外一部分微服务视为公共服务,允许它可接受来自集群外部的最终用户发出的请求;又或者我们想要控制一部分服务只允许移动应用调用,另外一部分服务只允许浏览器调用。那一种可行的方案就是为不同的调用场景设立角色,进行授权控制(另一种常用的方案是做 BFF 网关)。
在 Istio 版本的 Fenix’s Bookstore 中,通过以下配置,限制了来自bookstore-servicemesh名空间的内部流量只允许访问accounts、products、pay和settlements四个端点的 GET、POST、PUT、PATCH 方法,而对于来自istio-system名空间(Istio Ingress Gateway 所在的名空间)的外部流量就不作限制,直接放行。
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: authorization-peer
namespace: bookstore-servicemesh
spec:
action: ALLOW
rules:
- from:
- source:
namespaces: ["bookstore-servicemesh"]
to:
- operation:
paths:
- /restful/accounts/*
- /restful/products*
- /restful/pay/*
- /restful/settlements*
methods: ["GET","POST","PUT","PATCH"]
- from:
- source:
namespaces: ["istio-system"]但对外部的请求(不来自bookstore-servicemesh名空间的流量),又进行了另外一层控制,如果请求中没有包含有效的登录信息,就限制不允许访问accounts、pay和settlements三个端点,如以下配置所示:
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: authorization-request
namespace: bookstore-servicemesh
spec:
action: DENY
rules:
- from:
- source:
notRequestPrincipals: ["*"]
notNamespaces: ["bookstore-servicemesh"]
to:
- operation:
paths:
- /restful/accounts/*
- /restful/pay/*
- /restful/settlements*Istio 已经提供了比较完善的目标匹配工具,如上面配置中用到的源from、目标to,还有未用到的条件匹配when,以及其他如通配符、IP、端口、名空间、JWT 字段,等等。要说灵活和功能强大,肯定还是不可能跟在应用中由代码实现的授权相媲美,但对绝大多数场景已经够用了。在便捷性、安全性、无侵入、统一管理等方面,Istio 这种在基础设施上实现授权方案显然就要更具优势。
Spring Cloud 版本的 Fenix’s Bookstore 中,授权控制自然还是使用 Spring Security、通过应用程序代码来实现的。常见的 Spring Security 授权方法有两种,一种是使用它的ExpressionUrlAuthorizationConfigurer,即类似如下编码所示的写法来进行集中配置,这与上面在 Istio 的 AuthorizationPolicy CRD 中写法在体验上是比较相似的,也是几乎所有 Spring Security 资料中都有介绍的最主流方式,适合对批量端点进行控制,不过在示例代码中并没有采用(没有什么特别理由,就是笔者的个人习惯而已)。
http.authorizeRequests()
.antMatchers("/restful/accounts/**").hasScope(Scope.BROWSER)
.antMatchers("/restful/pay/**").hasScope(Scope.SERVICE)另一种写法,即示例代码中采用的方法,是通过 Spring 的全局方法级安全(Global Method Security)以及JSR 250的@RolesAllowed注解来做授权控制。这种写法对代码的侵入性更强,要以注解的形式分散写到每个服务甚至是每个方法中,但好处是能以更方便的形式做出更加精细的控制效果。譬如要控制服务中某个方法只允许来自服务或者来自浏览器的调用,那直接在该方法上标注@PreAuthorize注解即可,还支持SpEL 表达式来做条件。表达式中用到的SERVICE、BROWSER代表授权范围,就是在声明客户端列表时传入的,具体可参见开头声明客户端列表的代码清单。
/**
* 根据用户名称获取用户详情
*/
@GET
@Path("/{username}")
@Cacheable(key = "#username")
@PreAuthorize("#oauth2.hasAnyScope('SERVICE','BROWSER')")
public Account getUser(@PathParam("username") String username) {
return service.findAccountByUsername(username);
}
/**
* 创建新的用户
*/
@POST
@CacheEvict(key = "#user.username")
@PreAuthorize("#oauth2.hasAnyScope('BROWSER')")
public Response createUser(@Valid @UniqueAccount Account user) {
return CommonResponse.op(() -> service.createAccount(user));
}可观测性
随着分布式架构渐成主流,可观测性(Observability)一词也日益频繁地被人提起。最初,它与可控制性(Controllability)一起,是由匈牙利数学家 Rudolf E. Kálmán 针对线性动态控制系统提出的一组对偶属性,原本的含义是“可以由其外部输出推断其内部状态的程度”。
在学术界,虽然“可观测性”这个名词是近几年才从控制理论中借用的舶来概念,不过其内容实际在计算机科学中已有多年的实践积累。学术界一般会将可观测性分解为三个更具体方向进行研究,分别是:事件日志、链路追踪和聚合度量,这三个方向各有侧重,又不是完全独立,它们天然就有重合或者可以结合之处,2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,Peter Bourgon 撰写了总结文章《Metrics, Tracing, and Logging》系统地阐述了这三者的定义、特征,以及它们之间的关系与差异,受到了业界的广泛认可。
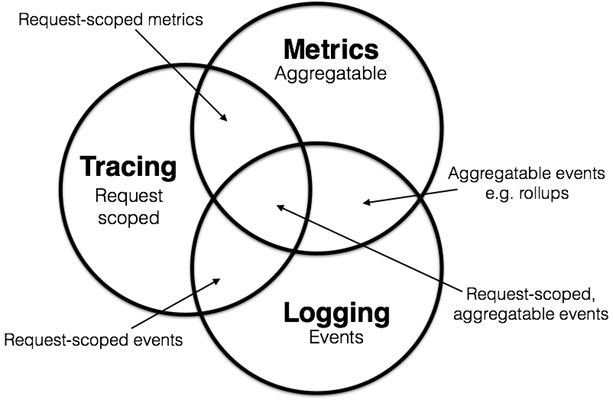
图 10-1 日志、追踪、度量的目标与结合(图片来源)
假如你平时只开发单体系统,从未接触过分布式系统的观测工作,那看到日志、追踪和度量,很有可能只会对日志这一项感到熟悉,其他两项会相对陌生。然而按照 Peter Bourgon 给出的定义来看,尽管分布式系统中追踪和度量必要性和复杂程度确实比单体系统时要更高,但是在单体时代,你肯定也已经接触过以上全部三项的工作,只是并未意识到而已,笔者将它们的特征转述如下:
- 日志(Logging):日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志被认为是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点,面对迅速滚动的事件信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
- 追踪(Tracing):单体系统时代追踪的范畴基本只局限于栈追踪(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了
Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为“全链路追踪”(后文就直接称“链路追踪”了),许多资料中也称它为“分布式追踪”(Distributed Tracing)。追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。 - 度量(Metrics):度量是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负债等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,诸如内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等都可以从 JMX 中获得。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
在工业界,目前针对可观测性的产品已经是一片红海,经过多年的角逐,日志、度量两个领域的胜利者算是基本尘埃落定。日志收集和分析大多被统一到 Elastic Stack(ELK)技术栈上,如果说未来还能出现什么变化的话,也就是其中的 Logstash 能看到有被 Fluentd 取代的趋势,让 ELK 变成 EFK,但整套 Elastic Stack 技术栈的地位已是相当稳固。度量方面,跟随着 Kubernetes 统一容器编排的步伐,Prometheus 也击败了度量领域里以 Zabbix 为代表的众多前辈,即将成为云原生时代度量监控的事实标准,虽然从市场角度来说 Prometheus 还没有达到 Kubernetes 那种“拔剑四顾,举世无敌”的程度,但是从社区活跃度上看,Prometheus 已占有绝对的优势,在 Google 和 CNCF 的推动下,未来前途可期。
额外知识:Kubernetes 与 Prometheus 的关系
Kubernetes 是 CNCF 第一个孵化成功的项目,Prometheus 是 CNCF 第二个孵化成功的项目。
Kubernetes 起源于 Google 的编排系统 Borg,Prometheus 起源于 Google 为 Borg 做的度量监控系统 BorgMon。
追踪方面的情况与日志、度量有所不同,追踪是与具体网络协议、程序语言密切相关的,收集日志不必关心这段日志是由 Java 程序输出的还是由 Golang 程序输出的,对程序来说它们就只是一段非结构化文本而已,同理,度量对程序来说也只是一个个聚合的数据指标而已。但链路追踪就不一样,各个服务之间是使用 HTTP 还是 gRPC 来进行通信会直接影响追踪的实现,各个服务是使用 Java、Golang 还是 Node.js 来编写,也会直接影响到进程内调用栈的追踪方式。这决定了追踪工具本身有较强的侵入性,通常是以插件式的探针来实现;也决定了追踪领域很难出现一家独大的情况,通常要有多种产品来针对不同的语言和网络。近年来各种链路追踪产品层出不穷,市面上主流的工具既有像 Datadog 这样的一揽子商业方案,也有 AWS X-Ray 和 Google Stackdriver Trace 这样的云计算厂商产品,还有像 SkyWalking、Zipkin、Jaeger 这样来自开源社区的优秀产品。

图 10-2 日志、追踪、度量的相关产品(图片来源)
图 10-2 是CNCF Interactive Landscape中列出的日志、追踪、度量领域的著名产品,其实这里很多不同领域的产品是跨界的,譬如 ELK 可以通过 Metricbeat 来实现度量的功能,Apache SkyWalking 的探针就有同时支持度量和追踪两方面的数据来源,由OpenTracing进化而来OpenTelemetry更是融合了日志、追踪、度量三者所长,有望成为三者兼备的统一可观测性解决方案。本章后面的讲解,也会扣紧每个领域中最具有统治性产品来进行介绍。
事件日志
日志用来记录系统运行期间发生过的离散事件。相信没有哪一个生产系统能够缺少日志功能,然而也很少人会把日志作为多么关键功能来看待。日志就像阳光与空气,无可或缺却不太被重视。程序员们会说日志简单,其实这是在说“打印日志”这个操作简单,打印日志的目的是为了日后从中得到有价值的信息,而今天只要稍微复杂点的系统,尤其是复杂的分布式系统,就很难只依靠 tail、grep、awk 来从日志中挖掘信息了,往往还要有专门的全局查询和可视化功能。此时,从打印日志到分析查询之间,还隔着收集、缓冲、聚合、加工、索引、存储等若干个步骤,如图 10-3 所示。

图 10-3 日志处理过程
这一整个链条中涉及大量值得注意的细节,复杂性并不亚于任何一项技术或业务功能的实现。接下来将以此为线索,以最成熟的 Elastic Stack 技术栈为例子,介绍该链条每个步骤的目的与方法。
输出
要是说好的日志能像文章一样,能让人读起来身心舒畅,这话肯定有夸大的成分,不过好的日志应该能做到像“流水账”一样,无有遗漏地记录信息,格式统一,内容恰当。其中“恰当”是一个难点,它要求日志不应该过多,也不应该过少。“多与少”一般不针对输出的日志行数,尽管笔者听过最夸张的系统有单节点 INFO 级别下每天的日志都能以 TB 计算(这是代码有问题的),给网络与磁盘 I/O 带来了不小压力,但笔者通常不以数量来衡量日志是否恰当,恰当是指日志中不该出现的内容不要有,该有的不要少,下面笔者先列出一些常见的“不应该有”的例子:
- 避免打印敏感信息。不用专门去提醒,任何程序员肯定都知道不该将密码,银行账号,身份证件这些敏感信息打到日志里,但笔者曾见过不止一个系统的日志中直接能找到这些信息。一旦这些敏感信息随日志流到了后续的索引、存储、归档等步骤后,清理起来将非常麻烦。不过,日志中应当包含必要的非敏感信息,譬如当前用户的 ID(最好是内部 ID,避免登录名或者用户名称),有些系统就直接用MDC(Mapped Diagnostic Context)将用户 ID 自动打印在日志模版(Pattern Layout)上。
- 避免引用慢操作。日志中打印的信息应该是上下文中可以直接取到的,如果当前上下文中根本没有这项数据,需要专门调用远程服务或者从数据库获取,又或者通过大量计算才能取到的话,那应该先考虑这项信息放到日志中是不是必要且恰当的。
- 避免打印追踪诊断信息。日志中不要打印方法输入参数、输出结果、方法执行时长之类的调试信息。这个观点是反直觉的,不少公司甚至会将其作为最佳实践来提倡,但是笔者仍坚持将其归入反模式中。日志的职责是记录事件,追踪诊断应由追踪系统去处理,哪怕贵公司完全没有开发追踪诊断方面功能的打算,笔者也建议使用BTrace或者Arthas这类“On-The-Fly”的工具来解决。之所以将其归为反模式,是因为上面说的敏感信息、慢操作等的主要源头就是这些原本想用于调试的日志。譬如,当前方法入口参数有个 User 对象,如果要输出这个对象的话,常见做法是将它序列化成 JSON 字符串然后打到日志里,这时候 User 里面的 Password 字段、BankCard 字段就很容易被暴露出来;再譬如,当前方法的返回值是个 Map,开发期的调试数据只做了三五个 Entity,觉得遍历一下把具体内容打到日志里面没什么问题,到了生产期,这个 Map 里面有可能存放了成千上万个 Entity,这时候打印日志就相当于引用慢操作。
- 避免误导他人。日志中给日后调试除错的人挖坑是十分恶劣却又常见的行为。相信程序员并不是专门要去误导别人,只是很可能会无意识地这样做了。譬如明明已经在逻辑中妥善处理好了某个异常,偏习惯性地调用 printStackTrace()方法,把堆栈打到日志中,一旦这个方法附近出现问题,由其他人来除错的话,很容易会盯着这段堆栈去找线索而浪费大量时间。
- ……
另一方面,日志中不该缺少的内容也“不应该少”,以下是部分笔者建议应该输出到日志中的内容:
- 处理请求时的 TraceID。服务收到请求时,如果该请求没有附带 TraceID,就应该自动生成唯一的 TraceID 来对请求进行标记,并使用 MDC 自动输出到日志。TraceID 会贯穿整条调用链,目的是通过它把请求在分布式系统各个服务中的执行过程串联起来。TraceID 通常也会随着请求的响应返回到客户端,如果响应内容出现了异常,用户便能通过此 ID 快速找到与问题相关的日志。TraceID 是链路追踪里的概念,类似的还有用于标识进程内调用状况的 SpanID,在 Java 程序中这些都可以用 Spring Cloud Sleuth 来自动生成。尽管 TraceID 在分布式跟踪会发挥最大的作用,但即使对单体系统,将 TraceID 记录到日志并返回给最终用户,对快速定位错误仍然十分有价值。
- 系统运行过程中的关键事件。日志的职责就是记录事件,进行了哪些操作、发生了与预期不符的情况、运行期间出现未能处理的异常或警告、定期自动执行的任务,等等,都应该在日志中完整记录下来。原则上程序中发生的事件只要有价值就应该去记录,但应判断清楚事件的重要程度,选定相匹配的日志的级别。至于如何快速处理大量日志,这是后面步骤要考虑的问题,如果输出日志实在太频繁以至于影响性能,应由运维人员去调整全局或单个类的日志级别来解决。
- 启动时输出配置信息。与避免输出诊断信息不同,对于系统启动时或者检测到配置中心变化时更新的配置,应将非敏感的配置信息输出到日志中,譬如连接的数据库、临时目录的路径等等,初始化配置的逻辑一般只会执行一次,不便于诊断时复现,所以应该输出到日志中。
- ……
收集与缓冲
写日志是在服务节点中进行的,但我们不可能在每个节点都单独建设日志查询功能。这不是资源或工作量的问题,而是分布式系统处理一个请求要跨越多个服务节点,为了能看到跨节点的全部日志,就要有能覆盖整个链路的全局日志系统。这个需求决定了每个节点输出日志到文件后,必须将日志文件统一收集起来集中存储、索引,由此便催生了专门的日志收集器。
最初,ELK 中日志收集与下一节要讲的加工聚合的职责都是由 Logstash 来承担的,Logstash 除了部署在各个节点中作为收集的客户端(Shipper)以外,它还同时设有独立部署的节点,扮演归集转换日志的服务端(Master)角色。Logstash 有良好的插件化设计,收集、转换、输出都支持插件化定制,应对多重角色本身并没有什么困难。但是 Logstash 与它的插件是基于 JRuby 编写的,要跑在单独的 Java 虚拟机进程上,而且 Logstash 的默认的堆大小就到了 1GB。对于归集部分(Master)这种消耗并不是什么问题,但作为每个节点都要部署的日志收集器就显得太过负重了。后来,Elastic.co 公司将所有需要在服务节点中处理的工作整理成以Libbeat为核心的Beats 框架,并使用 Golang 重写了一个功能较少,却更轻量高效的日志收集器,这就是今天流行的Filebeat。
现在的 Beats 已经是一个很大的家族了,除了 Filebeat 外,Elastic.co 还提供有用于收集 Linux 审计数据的Auditbeat、用于无服务计算架构的Functionbeat、用于心跳检测的Heartbeat、用于聚合度量的Metricbeat、用于收集 Linux Systemd Journald 日志的Journalbeat、用于收集 Windows 事件日志的Winlogbeat,用于网络包嗅探的Packetbeat,等等,如果再算上大量由社区维护的Community Beats,那几乎是你能想像到的数据都可以被收集到,以至于 ELK 也可以一定程度上代替度量和追踪系统,实现它们的部分职能,这对于中小型分布式系统来说是便利的,但对于大型系统,笔者建议还是让专业的工具去做专业的事情。
日志收集器不仅要保证能覆盖全部数据来源,还要尽力保证日志数据的连续性,这其实并不容易做到。譬如淘宝这类大型的互联网系统,每天的日志量超过了 10,000TB(10PB)量级,日志收集器的部署实例数能到达百万量级(数据来源),此时归集到系统中的日志要与实际产生的日志保持绝对的一致性是非常困难的,也不应该为此付出过高成本。换而言之,日志不追求绝对的完整精确,只追求在代价可承受的范围内保证尽可能地保证较高的数据质量。一种最常用的缓解压力的做法是将日志接收者从 Logstash 和 Elasticsearch 转移至抗压能力更强的队列缓存,譬如在 Logstash 之前架设一个 Kafka 或者 Redis 作为缓冲层,面对突发流量,Logstash 或 Elasticsearch 处理能力出现瓶颈时自动削峰填谷,甚至当它们短时间停顿,也不会丢失日志数据。
加工与聚合
将日志集中收集之后,存入 Elasticsearch 之前,一般还要对它们进行加工转换和聚合处理。这是因为日志是非结构化数据,一行日志中通常会包含多项信息,如果不做处理,那在 Elasticsearch 就只能以全文检索的原始方式去使用日志,既不利于统计对比,也不利于条件过滤。举个具体例子,下面是一行 Nginx 服务器的 Access Log,代表了一次页面访问操作:
14.123.255.234 - - [19/Feb/2020:00:12:11 +0800] "GET /index.html HTTP/1.1" 200 1314 "https://icyfenix.cn" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"在这一行日志里面,包含了表 10-1 所列的 10 项独立数据项:
表 10-1 日志包含的 10 项独立数据项
| 数据项 | 值 |
|---|---|
| IP | 14.123.255.234 |
| Username | null |
| Datetime | 19/Feb/2020:00:12:11 +0800 |
| Method | GET |
| URL | /index.html |
| Protocol | HTTP/1.1 |
| Status | 200 |
| Size | 1314 |
| Refer | https://icyfenix.cn |
| Agent | Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36 |
Logstash 的基本职能是把日志行中的非结构化数据,通过 Grok 表达式语法转换为上面表格那样的结构化数据,进行结构化的同时,还可能会根据需要,调用其他插件来完成时间处理(统一时间格式)、类型转换(如字符串、数值的转换)、查询归类(譬如将 IP 地址根据地理信息库按省市归类)等额外处理工作,然后以 JSON 格式输出到 Elasticsearch 中(这是最普遍的输出形式,Logstash 输出也有很多插件可以具体定制不同的格式)。有了这些经过 Logstash 转换,已经结构化的日志,Elasticsearch 便可针对不同的数据项来建立索引,进行条件查询、统计、聚合等操作的了。
提到聚合,这也是 Logstash 的另一个常见职能。日志中存储的是离散事件,离散的意思是每个事件都是相互独立的,譬如有 10 个用户访问服务,他们操作所产生的事件都在日志中会分别记录。如果想从离散的日志中获得统计信息,譬如想知道这些用户中正常返回(200 OK)的有多少、出现异常的(500 Internal Server Error)的有多少,再生成个可视化统计图表,一种解决方案是通过 Elasticsearch 本身的处理能力做实时的聚合统计,这很便捷,不过要消耗 Elasticsearch 服务器的运算资源。另一种解决方案是在收集日志后自动生成某些常用的、固定的聚合指标,这种聚合就会在 Logstash 中通过聚合插件来完成。这两种聚合方式都有不少实际应用,前者一般用于应对即席查询,后者用于应对固定查询。
存储与查询
经过收集、缓冲、加工、聚合的日志数据,终于可以放入 Elasticsearch 中索引存储了。Elasticsearch 是整个 Elastic Stack 技术栈的核心,其他步骤的工具,如 Filebeat、Logstash、Kibana 都有替代品,有自由选择的余地,唯独 Elasticsearch 在日志分析这方面完全没有什么值得一提的竞争者,几乎就是解决此问题的唯一答案。这样的结果肯定与 Elasticsearch 本身是一款优秀产品有关,然而更关键的是 Elasticsearch 的优势正好与日志分析的需求完美契合:
- 从数据特征的角度看,日志是典型的基于时间的数据流,但它与其他时间数据流,譬如你的新浪微博、微信朋友圈这种社交网络数据又稍有区别:日志虽然增长速度很快,但已写入的数据几乎没有再发生变动的可能。日志的数据特征决定了所有用于日志分析的 Elasticsearch 都会使用时间范围作为索引,根据实际数据量的大小可能是按月、按周或者按日、按时。以按日索引为例,由于你能准确地预知明天、后天的日期,因此全部索引都可以预先创建,这免去了动态创建的寻找节点、创建分片、在集群中广播变动信息等开销。又由于所有新的日志都是“今天”的日志,所以只要建立“logs_current”这样的索引别名来指向当前索引,就能避免代码因日期而变动。
- 从数据价值的角度看,日志基本上只会以最近的数据为检索目标,随着时间推移,早期的数据将逐渐失去价值。这点决定了可以很容易区分出冷数据和热数据,进而对不同数据采用不一样的硬件策略。譬如为热数据配备 SSD 磁盘和更好的处理器,为冷数据配备 HDD 磁盘和较弱的处理器,甚至可以放到更为廉价的对象存储(如阿里云的 OSS,腾讯云的 COS,AWS 的 S3)中归档。
注意,本节的主题是日志在可观测性方面的作用,另外还有一些基于日志的其他类型应用,譬如从日志记录的事件中去挖掘业务热点,分析用户习惯等等,这属于真正大数据挖掘的范畴,并不在我们讨论“价值”的范围之内,事实上它们更可能采用的技术栈是 HBase 与 Spark 的组合,而不是 Elastic Stack。 - 从数据使用的角度看,分析日志很依赖全文检索和即席查询,对实时性的要求是处于实时与离线两者之间的“近实时”,即不强求日志产生后立刻能查到,但也不能接受日志产生之后按小时甚至按天的频率来更新,这些检索能力和近实时性,也正好都是 Elasticsearch 的强项。
Elasticsearch 只提供了 API 层面的查询能力,它通常搭配同样出自 Elastic.co 公司的 Kibana 一起使用,可以将 Kibana 视为 Elastic Stack 的 GUI 部分。Kibana 尽管只负责图形界面和展示,但它提供的能力远不止让你能在界面上执行 Elasticsearch 的查询那么简单。Kibana 宣传的核心能力是“探索数据并可视化”,即把存储在 Elasticsearch 中的数据被检索、聚合、统计后,定制形成各种图形、表格、指标、统计,以此观察系统的运行状态,找出日志事件中潜藏的规律和隐患。按 Kibana 官方的宣传语来说就是“一张图片胜过千万行日志”。
图 10-4 Kibana 可视化界面(图片来自Kibana 官网)
链路追踪
虽然 2010 年之前就已经有了 X-Trace、Magpie 等跨服务的追踪系统了,但现代分布式链路追踪公认的起源是 Google 在 2010 年发表的论文《Dapper : a Large-Scale Distributed Systems Tracing Infrastructure》,这篇论文介绍了 Google 从 2004 年开始使用的分布式追踪系统 Dapper 的实现原理。此后,所有业界有名的追踪系统,无论是国外 Twitter 的Zipkin、Naver 的Pinpoint(Naver 是 Line 的母公司,Pinpoint 出现其实早于 Dapper 论文发表,在 Dapper 论文中还提到了 Pinpoint),抑或是国内阿里的鹰眼、大众点评的CAT、个人开源的SkyWalking(后进入 Apache 基金会孵化毕业)都受到 Dapper 论文的直接影响。
广义上讲,一个完整的分布式追踪系统应该由数据收集、数据存储和数据展示三个相对独立的子系统构成,而狭义上讲的追踪则就只是特指链路追踪数据的收集部分。譬如Spring Cloud Sleuth就属于狭义的追踪系统,通常会搭配 Zipkin 作为数据展示,搭配 Elasticsearch 作为数据存储来组合使用,而前面提到的那些 Dapper 的徒子徒孙们大多都属于广义的追踪系统,广义的追踪系统又常被称为“APM 系统”(Application Performance Management)。
追踪与跨度
为了有效地进行分布式追踪,Dapper 提出了“追踪”与“跨度”两个概念。从客户端发起请求抵达系统的边界开始,记录请求流经的每一个服务,直到到向客户端返回响应为止,这整个过程就称为一次“追踪”(Trace,为了不产生混淆,后文就直接使用英文 Trace 来指代了)。由于每次 Trace 都可能会调用数量不定、坐标不定的多个服务,为了能够记录具体调用了哪些服务,以及调用的顺序、开始时点、执行时长等信息,每次开始调用服务前都要先埋入一个调用记录,这个记录称为一个“跨度”(Span)。Span 的数据结构应该足够简单,以便于能放在日志或者网络协议的报文头里;也应该足够完备,起码应含有时间戳、起止时间、Trace 的 ID、当前 Span 的 ID、父 Span 的 ID 等能够满足追踪需要的信息。每一次 Trace 实际上都是由若干个有顺序、有层级关系的 Span 所组成一颗“追踪树”(Trace Tree),如图 10-5 所示。
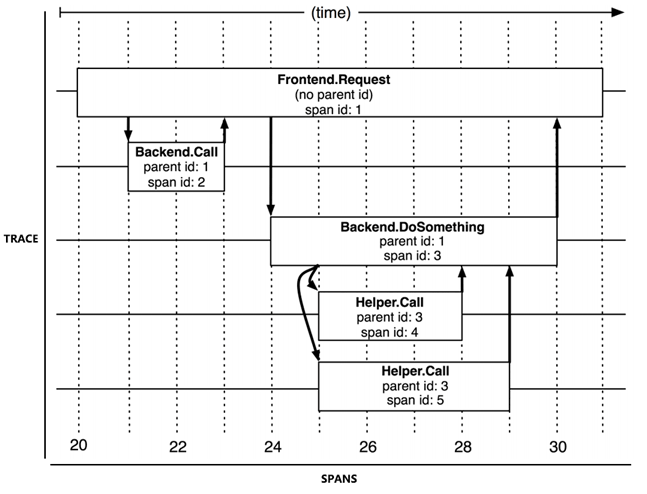
图 10-5 Trace 和 Spans(图片来源于Dapper 论文)
从目标来看,链路追踪的目的是为排查故障和分析性能提供数据支持,系统对外提供服务的过程中,持续地接受请求并处理响应,同时持续地生成 Trace,按次序整理好 Trace 中每一个 Span 所记录的调用关系,便能绘制出一幅系统的服务调用拓扑图。根据拓扑图中 Span 记录的时间信息和响应结果(正常或异常返回)就可以定位到缓慢或者出错的服务;将 Trace 与历史记录进行对比统计,就可以从系统整体层面分析服务性能,定位性能优化的目标。
从实现来看,为每次服务调用记录 Trace 和 Span,并以此构成追踪树结构,听着好像也不是很复杂,然而考虑到实际情况,追踪系统在功能性和非功能性上都有不小的挑战。功能上的挑战来源于服务的异构性,各个服务可能采用不同程序语言,服务间交互可能采用不同的网络协议,每兼容一种场景,都会增加功能实现方面的工作量。而非功能性的挑战具体就来源于以下这四个方面:
- 低性能损耗:分布式追踪不能对服务本身产生明显的性能负担。追踪的主要目的之一就是为了寻找性能缺陷,越慢的服务越是需要追踪,所以工作场景都是性能敏感的地方。
- 对应用透明:追踪系统通常是运维期才事后加入的系统,应该尽量以非侵入或者少侵入的方式来实现追踪,对开发人员做到透明化。
- 随应用扩缩:现代的分布式服务集群都有根据流量压力自动扩缩的能力,这要求当业务系统扩缩时,追踪系统也能自动跟随,不需要运维人员人工参与。
- 持续的监控:要求追踪系统必须能够 7x24 小时工作,否则就难以定位到系统偶尔抖动的行为。
数据收集
目前,追踪系统根据数据收集方式的差异,可分为三种主流的实现方式,分别是基于日志的追踪(Log-Based Tracing),基于服务的追踪(Service-Based Tracing)和基于边车代理的追踪(Sidecar-Based Tracing),笔者分别介绍如下:
基于日志的追踪的思路是将 Trace、Span 等信息直接输出到应用日志中,然后随着所有节点的日志归集过程汇聚到一起,再从全局日志信息中反推出完整的调用链拓扑关系。日志追踪对网络消息完全没有侵入性,对应用程序只有很少量的侵入性,对性能影响也非常低。但其缺点是直接依赖于日志归集过程,日志本身不追求绝对的连续与一致,这也使得基于日志的追踪往往不如其他两种追踪实现来的精准。另外,业务服务的调用与日志的归集并不是同时完成的,也通常不由同一个进程完成,有可能发生业务调用已经顺利结束了,但由于日志归集不及时或者精度丢失,导致日志出现延迟或缺失记录,进而产生追踪失真。这也是前面笔者介绍 Elastic Stack 时提到的观点,ELK 在日志、追踪和度量方面都可以发挥作用,这对中小型应用确实有一定便利,但是大型系统最好还是由专业的工具做专业的事。
日志追踪的代表产品是 Spring Cloud Sleuth,下面是一段由 Sleuth 在调用时自动生成的日志记录,可以从中观察到 TraceID、SpanID、父 SpanID 等追踪信息。# 以下为调用端的日志输出: Created new Feign span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false] 2019-06-30 09:43:24.022 [http-nio-9010-exec-8] DEBUG o.s.c.s.i.web.client.feign.TraceFeignClient - The modified request equals GET http://localhost:9001/product/findAll HTTP/1.1 X-B3-ParentSpanId: cbe97e67ce162943 X-B3-Sampled: 0 X-B3-TraceId: cbe97e67ce162943 X-Span-Name: http:/product/findAll X-B3-SpanId: bb1798f7a7c9c142 # 以下为服务端的日志输出: [findAll] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false] Adding a class tag with value [ProductController] to a span [Trace: cbe97e67ce162943, Span: bb1798f7a7c9c142, Parent: cbe97e67ce162943, exportable:false]基于服务的追踪是目前最为常见的追踪实现方式,被 Zipkin、SkyWalking、Pinpoint 等主流追踪系统广泛采用。服务追踪的实现思路是通过某些手段给目标应用注入追踪探针(Probe),针对 Java 应用一般就是通过 Java Agent 注入的。探针在结构上可视为一个寄生在目标服务身上的小型微服务系统,它一般会有自己专用的服务注册、心跳检测等功能,有专门的数据收集协议,把从目标系统中监控得到的服务调用信息,通过另一次独立的 HTTP 或者 RPC 请求发送给追踪系统。因此,基于服务的追踪会比基于日志的追踪消耗更多的资源,也有更强的侵入性,换来的收益是追踪的精确性与稳定性都有所保证,不必再依靠日志归集来传输追踪数据。
下面是一张 Pinpoint 的追踪效果截图,从图中可以看到参数、变量等相当详细方法级调用信息。笔者在上一节“日志分析”里把“打印追踪诊断信息”列为反模式,如果需要诊断需要方法参数、返回值、上下文信息,或者方法调用耗时这类数据,通过追踪系统来实现是比通过日志系统实现更加恰当的解决方案。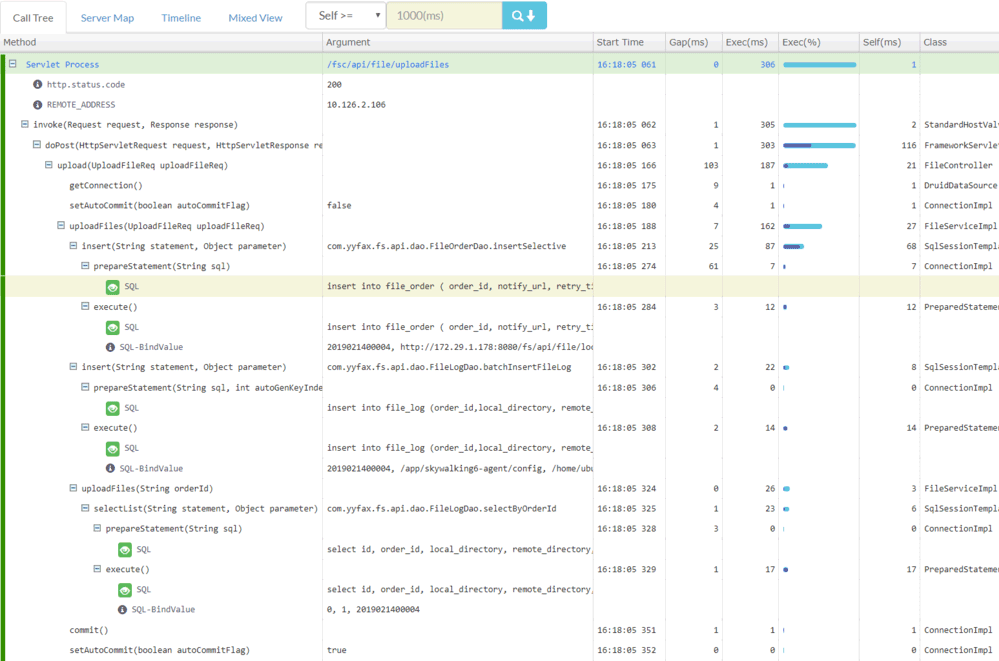
图 10-6 Pinpoint 的追踪截图(图片来自网络)
也必须说明清楚,像图 10-6 中 Pinpoint 这种详细程度的追踪对应用系统的性能压力是相当大的,一般仅在出错时开启,而且 Pinpoint 本身就是比较重负载的系统(运行它必须先维护一套 HBase),这严重制约了它的适用范围,目前服务追踪的其中一个发展趋势是轻量化,国产的 SkyWalking 正是这方面的佼佼者。
基于边车代理的追踪是服务网格的专属方案,也是最理想的分布式追踪模型,它对应用完全透明,无论是日志还是服务本身都不会有任何变化;它与程序语言无关,无论应用采用什么编程语言实现,只要它还是通过网络(HTTP 或者 gRPC)来访问服务就可以被追踪到;它有自己独立的数据通道,追踪数据通过控制平面进行上报,避免了追踪对程序通信或者日志归集的依赖和干扰,保证了最佳的精确性。如果要说这种追踪实现方式还有什么缺点的话,那就是服务网格现在还不够普及,未来随着云原生的发展,相信它会成为追踪系统的主流实现方式之一。还有就是边车代理本身的对应用透明的工作原理决定了它只能实现服务调用层面的追踪,像上面 Pinpoint 截图那样本地方法调用级别的追踪诊断是做不到的。
现在市场占有率最高的边车代理Envoy就提供了相对完善的追踪功能,但没有提供自己的界面端和存储端,所以 Envoy 和 Sleuth 一样都属于狭义的追踪系统,需要配合专门的 UI 与存储来使用,现在 SkyWalking、Zipkin、Jaeger、LightStep Tracing等系统都可以接受来自于 Envoy 的追踪数据,充当它的界面端。
追踪规范化
比起日志与度量,追踪这个领域的产品竞争要相对激烈得多。一方面,目前还没有像日志、度量那样出现具有明显统治力的产品,仍处于群雄混战的状态。另一方面,几乎市面上所有的追踪系统都是以 Dapper 的论文为原型发展出来的,基本上都算是同门师兄弟,功能上并没有太本质的差距,却又受制于实现细节,彼此互斥,很难搭配工作。这种局面只能怪当初 Google 发表的 Dapper 只是论文而不是有约束力的规范标准,只提供了思路,并没有规定细节,譬如该怎样进行埋点、Span 上下文具体该有什么数据结构,怎样设计追踪系统与探针或者界面端的 API 接口,等等,都没有权威的规定。
为了推进追踪领域的产品的标准化,2016 年 11 月,CNCF 技术委员会接受了 OpenTracing 作为基金会第三个项目。OpenTracing 是一套与平台无关、与厂商无关、与语言无关的追踪协议规范,只要遵循 OpenTracing 规范,任何公司的追踪探针、存储、界面都可以随时切换,也可以相互搭配使用。
操作层面,OpenTracing 只是制定了一个很薄的标准化层,位于应用程序与追踪系统之间,这样探针与追踪系统就可以不是同一个厂商的产品,只要它们都支持 OpenTracing 协议即可互相通讯。此外,OpenTracing 还规定了微服务之间发生调用时,应该如何传递 Span 信息(OpenTracing Payload),以上这些都如图 10-7 绿色部分所示。
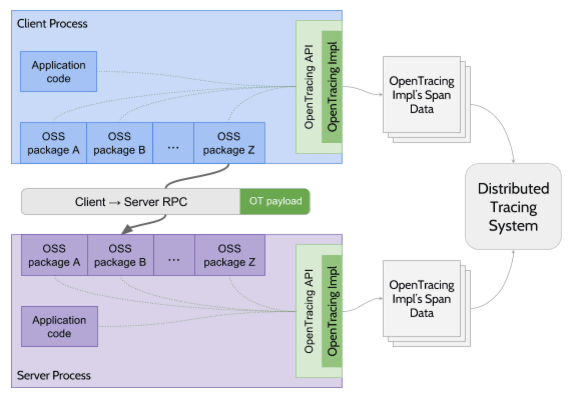
图 10-7 符合 OpenTracing 的软件架构(图片来源)
OpenTracing 规范公布后,几乎所有业界有名的追踪系统,譬如 Zipkin、Jaeger、SkyWalking 等都很快宣布支持 OpenTracing,但谁也没想到的是,Google 自己却在此时出来表示反对,并提出了与 OpenTracing 目标类似的 OpenCensus 规范,随后又得到了巨头 Microsoft 的支持和参与。OpenCensus 不仅涉及追踪,还把指标度量也纳入进来;内容上不仅涉及规范制定,还把数据采集的探针和收集器都一起以 SDK(目前支持五种语言)的形式提供出来。
OpenTracing 和 OpenCensus 迅速形成了可观测性的两大阵营,一边是在这方面深耕多年的众多老牌 APM 系统厂商,另一边是分布式追踪概念的提出者 Google,以及与 Google 同样庞大的 Microsoft。对追踪系统的规范化工作,并没有平息厂商竞争的混乱,反倒是把水搅得更加浑了。
正当群众们买好西瓜搬好板凳的时候,2019 年,OpenTracing 和 OpenCensus 又忽然宣布握手言和,它们共同发布了可观测性的终极解决方案OpenTelemetry,并宣布会各自冻结 OpenTracing 和 OpenCensus 的发展。OpenTelemetry 野心颇大,不仅包括追踪规范,还包括日志和度量方面的规范、各种语言的 SDK、以及采集系统的参考实现,它距离一个完整的追踪与度量系统,仅仅是缺了界面端和指标预警这些会与用户直接接触的后端功能,OpenTelemetry 将它们留给具体产品去实现,勉强算是没有对一众 APM 厂商赶尽杀绝,留了一条活路。
OpenTelemetry 一诞生就带着无比炫目的光环,直接进入 CNCF 的孵化项目,它的目标是统一追踪、度量和日志三大领域(目前主要关注的是追踪和度量,日志方面,官方表示将放到下一阶段再去处理)。不过,OpenTelemetry 毕竟是 2019 年才出现的新生事物,尽管背景渊源深厚,前途光明,但未来究竟如何发展,能否打败现在已经有的众多成熟系统,目前仍然言之尚早。
聚合度量
度量(Metrics)的目的是揭示系统的总体运行状态。相信大家应该见过这样的场景:舰船的驾驶舱或者卫星发射中心的控制室,在整个房间最显眼的位置,布满整面墙壁的巨型屏幕里显示着一个个指示器、仪表板与统计图表,沉稳端坐中央的指挥官看着屏幕上闪烁变化的指标,果断决策,下达命令……如果以上场景被改成指挥官双手在键盘上飞舞,双眼紧盯着日志或者追踪系统,试图判断出系统工作是否正常。这光想像一下,都能感觉到一股身份与行为不一致的违和气息。由此可见度量与日志、追踪的差别,度量是用经过聚合统计后的高维度信息,以最简单直观的形式来总结复杂的过程,为监控、预警提供决策支持。
图 10-8 Windows 系统的任务管理器界面
如果你人生经历比较平淡,没有驾驶航母的经验,甚至连一颗卫星或者导弹都没有发射过,那就只好打开电脑,按CTRL+ALT+DEL呼出任务管理器,看看上面图 10-8 这个熟悉的界面,它也是一个非常具有代表性的度量系统。
度量总体上可分为客户端的指标收集、服务端的存储查询以及终端的监控预警三个相对独立的过程,每个过程在系统中一般也会设置对应的组件来实现,你不妨现在先翻到下面,看一眼 Prometheus 的组件流程图作为例子,图中在 Prometheus Server 左边的部分都属于客户端过程,右边的部分就属于终端过程。
Prometheus在度量领域的统治力虽然还暂时不如日志领域中 Elastic Stack 的统治地位那么稳固,但在云原生时代里,基本也已经能算是事实标准了,接下来,笔者将主要以 Prometheus 为例,介绍这三部分组件的总体思路、大致内容与理论标准。
指标收集
指标收集部分要解决两个问题:“如何定义指标”以及“如何将这些指标告诉服务端”, 如何定义指标这个问题听起来应该是与目标系统密切相关的,必须根据实际情况才能讨论,其实并不绝对,无论目标是何种系统,都是具备一些共性特征。确定目标系统前我们无法决定要收集什么指标,但指标的数据类型(Metrics Types)是可数的,所有通用的度量系统都是面向指标的数据类型来设计的:
- 计数度量器(Counter):这是最好理解也是最常用的指标形式,计数器就是对有相同量纲、可加减数值的合计量,譬如业务指标像销售额、货物库存量、职工人数等等;技术指标像服务调用次数、网站访问人数等都属于计数器指标。
- 瞬态度量器(Gauge):瞬态度量器比计数器更简单,它就表示某个指标在某个时点的数值,连加减统计都不需要。譬如当前 Java 虚拟机堆内存的使用量,这就是一个瞬态度量器;又譬如,网站访问人数是计数器,而网站在线人数则是瞬态度量器。
- 吞吐率度量器(Meter):吞吐率度量器顾名思义是用于统计单位时间的吞吐量,即单位时间内某个事件的发生次数。譬如交易系统中常以 TPS 衡量事务吞吐率,即每秒发生了多少笔事务交易;又譬如港口的货运吞吐率常以“吨/每天”为单位计算,10 万吨/天的港口通常要比 1 万吨/天的港口的货运规模更大。
- 直方图度量器(Histogram):直方图是常见的二维统计图,它的两个坐标分别是统计样本和该样本对应的某个属性的度量,以长条图的形式表示具体数值。譬如经济报告中要衡量某个地区历年的 GDP 变化情况,常会以 GDP 为纵坐标,时间为横坐标构成直方图来呈现。
- 采样点分位图度量器(Quantile Summary):分位图是统计学中通过比较各分位数的分布情况的工具,用于验证实际值与理论值的差距,评估理论值与实际值之间的拟合度。譬如,我们说“高考成绩一般符合正态分布”,这句话的意思是:高考成绩高低分的人数都较少,中等成绩的较多,将人数按不同分数段统计,得出的统计结果一般能够与正态分布的曲线较好地拟合。
- 除了以上常见的度量器之外,还有 Timer、Set、Fast Compass、Cluster Histogram 等其他各种度量器,采用不同的度量系统,支持度量器类型的范围肯定会有差别,譬如 Prometheus 支持了上面提到五种度量器中的 Counter、Gauge、Histogram 和 Summary 四种。
对于“如何将这些指标告诉服务端”这个问题,通常有两种解决方案:拉取式采集(Pull-Based Metrics Collection)和推送式采集(Push-Based Metrics Collection)。所谓 Pull 是指度量系统主动从目标系统中拉取指标,相对地,Push 就是由目标系统主动向度量系统推送指标。这两种方式并没有绝对的好坏优劣,以前很多老牌的度量系统,如Ganglia)、Graphite、StatsD等是基于 Push 的,而以 Prometheus、Datadog、Collectd为代表的另一派度量系统则青睐 Pull 式采集(Prometheus 官方解释选择 Pull 的原因)。Push 还是 Pull 的权衡,不仅仅在度量中才有,所有涉及客户端和服务端通讯的场景,都会涉及该谁主动的问题,上一节中讲的追踪系统也是如此。
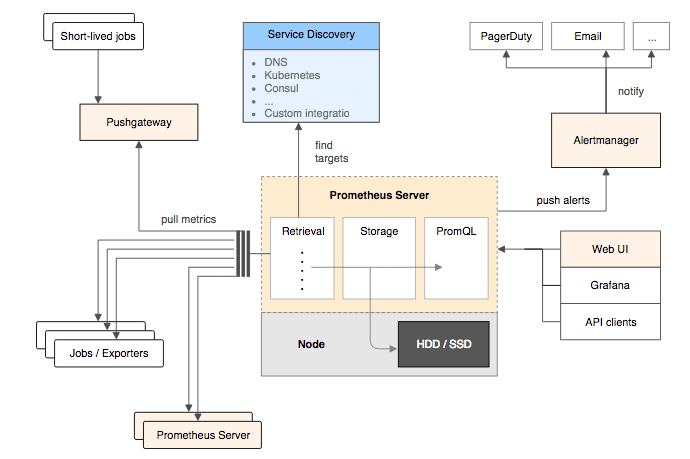
图 10-9 Prometheus 组件流程图(图片来自Prometheus 官网)
一般来说,度量系统只会支持其中一种指标采集方式,因为度量系统的网络连接数量,以及对应的线程或者协程数可能非常庞大,如何采集指标将直接影响到整个度量系统的架构设计。Prometheus 基于 Pull 架构的同时还能够有限度地兼容 Push 式采集,是因为它有 Push Gateway 的存在,如图 10-9 所示,这是一个位于 Prometheus Server 外部的相对独立的中介模块,将外部推送来的指标放到 Push Gateway 中暂存,然后再等候 Prometheus Server 从 Push Gateway 中去拉取。Prometheus 设计 Push Gateway 的本意是为了解决 Pull 的一些固有缺陷,譬如目标系统位于内网,通过 NAT 访问外网,外网的 Prometheus 是无法主动连接目标系统的,这就只能由目标系统主动推送数据;又譬如某些小型短生命周期服务,可能还等不及 Prometheus 来拉取,服务就已经结束运行了,因此也只能由服务自己 Push 来保证度量的及时和准确。
由推和拉决定该谁主动以后,另一个问题是指标应该以怎样的网络访问协议、取数接口、数据结构来获取?如同计算机科学中其他这类的问题类似,一贯的解决方向是“定义规范”,应该由行业组织和主流厂商一起协商出专门用于度量的协议,目标系统按照协议与度量系统交互。譬如,网络管理中的SNMP、Windows 硬件的WMI、以及此前提到的 Java 的JMX都属于这种思路的产物。但是,定义标准这个办法在度量领域中就不是那么有效,上述列举的度量协议,只在特定的一块小块领域上流行过。原因一方面是业务系统要使用这些协议并不容易,你可以想像一下,让订单金额存到 SNMP 中,让基于 Golang 实现的系统把指标放到 JMX Bean 里,即便技术上可行,这也不像是正常程序员会干的事;另一方面,度量系统又不会甘心局限于某个领域,成为某项业务的附属品。度量面向的是广义上的信息系统,横跨存储(日志、文件、数据库)、通讯(消息、网络)、中间件(HTTP 服务、API 服务),直到系统本身的业务指标,甚至还会包括度量系统本身(部署两个独立的 Prometheus 互相监控是很常见的)。所以,上面这些度量协议其实都没有成为最正确答案的希望。
既然没有了标准,有一些度量系统,譬如老牌的 Zabbix 就选择同时支持了 SNMP、JMX、IPMI 等多种不同的度量协议,另一些度量系统,以 Prometheus 为代表就相对强硬,选择任何一种协议都不去支持,只允许通过 HTTP 访问度量端点这一种访问方式。如果目标提供了 HTTP 的度量端点(如 Kubernetes、Etcd 等本身就带有 Prometheus 的 Client Library)就直接访问,否则就需要一个专门的 Exporter 来充当媒介。
Exporter 是 Prometheus 提出的概念,它是目标应用的代表,既可以独立运行,也可以与应用运行在同一个进程中,只要集成 Prometheus 的 Client Library 便可。Exporter 以 HTTP 协议(Prometheus 在 2.0 版本之前支持过 Protocol Buffer,目前已不再支持)返回符合 Prometheus 格式要求的文本数据给 Prometheus 服务器。
得益于 Prometheus 的良好社区生态,现在已经有大量各种用途的 Exporter,让 Prometheus 的监控范围几乎能涵盖所有用户所关心的目标,如表 10-2 所示。绝大多数用户都只需要针对自己系统业务方面的度量指标编写 Exporter 即可。
表 10-2 常用 Exporter
| 范围 | 常用 Exporter |
|---|---|
| 数据库 | MySQL Exporter、Redis Exporter、MongoDB Exporter、MSSQL Exporter 等 |
| 硬件 | Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter、Node Exporter 等 |
| 消息队列 | Beanstalkd Exporter、Kafka Exporter、NSQ Exporter、RabbitMQ Exporter 等 |
| 存储 | Ceph Exporter、Gluster Exporter、HDFS Exporter、ScaleIO Exporter 等 |
| HTTP 服务 | Apache Exporter、HAProxy Exporter、Nginx Exporter 等 |
| API 服务 | AWS ECS Exporter, Docker Cloud Exporter、Docker Hub Exporter、GitHub Exporter 等 |
| 日志 | Fluentd Exporter、Grok Exporter 等 |
| 监控系统 | Collectd Exporter、Graphite Exporter、InfluxDB Exporter、Nagios Exporter、SNMP Exporter 等 |
| 其它 | Blockbox Exporter、JIRA Exporter、Jenkins Exporter, Confluence Exporter 等 |
顺便一提,前文提到了一堆没有希望成为最终答案的协议,一种名为OpenMetrics的度量规范正在从 Prometheus 的数据格式中逐渐分离出来,有望成为监控数据格式的国际标准,最终结果如何,要看 Prometheus 本身的发展情况,还有 OpenTelemetry 与 OpenMetrics 的关系如何协调。
存储查询
指标从目标系统采集过来之后,应存储在度量系统中,以便被后续的分析界面、监控预警所使用。存储数据对于计算机软件来说是司空见惯的操作,但如果用传统关系数据库的思路来解决度量系统的存储,效果可能不会太理想。举个例子,假设你建设一个中等规模的、有着 200 个节点的微服务系统,每个节点要采集的存储、网络、中间件和业务等各种指标加一起,也按 200 个来计算,监控的频率如果按秒为单位的话,一天时间内就会产生超过 34 亿条记录,这很大概率会出乎你的意料之外:
200(节点)× 200(指标)× 86400(秒)= 3,456,000,000(记录) :::
大多数这种 200 节点规模的系统,本身一天的业务发生数据都远到不了 34 亿条,建设度量系统,肯定不能让度量反倒成了业务系统的负担,可见,度量的存储是需要专门研究解决的问题。至于如何解决,让我们先来观察一段 Prometheus 的真实度量数据,如下所示:
{
// 时间戳
"timestamp": 1599117392,
// 指标名称
"metric": "total_website_visitors",
// 标签组
"tags": {
"host": "icyfenix.cn",
"job": "prometheus"
},
// 指标值
"value": 10086
}观察这段度量数据的特征:每一个度量指标由时间戳、名称、值和一组标签构成,除了时间之外,指标不与任何其他因素相关。指标的数据总量固然是不小的,但它没有嵌套、没有关联、没有主外键,不必关心范式和事务,这些都是可以针对性优化的地方。事实上,业界早就已经存在了专门针对该类型数据的数据库了,即“时序数据库”(Time Series Database)。
额外知识:时序数据库
时序数据库用于存储跟随时间而变化的数据,并且以时间(时间点或者时间区间)来建立索引的数据库。
时序数据库最早是应用于工业(电力行业、化工行业)应用的各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均可达到成千上万的监测点,监测点每秒钟都在产生数据)。
时间序列数据是历史烙印,具有不变性,、唯一性、有序性。时序数据库同时具有数据结构简单,数据量大的特点。
写操作,时序数据通常只是追加,很少删改或者根本不允许删改。针对数据热点只集中在近期数据、多写少读、几乎不删改、数据只顺序追加这些特点,时序数据库被允许做出很激进的存储、访问和保留策略(Retention Policies):
- 以日志结构的合并树(Log Structured Merge Tree,LSM-Tree)代替传统关系型数据库中的B+Tree作为存储结构,LSM 适合的应用场景就是写多读少,且几乎不删改的数据。
- 设置激进的数据保留策略,譬如根据过期时间(TTL)自动删除相关数据以节省存储空间,同时提高查询性能。对于普通数据库来说,数据会存储一段时间后就会被自动删除这种事情是不可想象的。
- 对数据进行再采样(Resampling)以节省空间,譬如最近几天的数据可能需要精确到秒,而查询一个月前的数据时,只需要精确到天,查询一年前的数据时,只要精确到周就够了,这样将数据重新采样汇总就可以极大节省存储空间。
时序数据库中甚至还有一种并不罕见却更加极端的形式,叫作轮替型数据库(Round Robin Database,RRD),以环形缓冲(在“服务端缓存”一节介绍过)的思路实现,只能存储固定数量的最新数据,超期或超过容量的数据就会被轮替覆盖,因此也有着固定的数据库容量,却能接受无限量的数据输入。
Prometheus 服务端自己就内置了一个强大时序数据库实现,“强大”并非客气,近几年它在DB-Engines的排名中不断提升,目前已经跃居时序数据库排行榜的前三。该时序数据库提供了名为 PromQL 的数据查询语言,能对时序数据进行丰富的查询、聚合以及逻辑运算。某些时序库(如排名第一的InfluxDB)也会提供类 SQL 风格查询,但 PromQL 不是,它是一套完全由 Prometheus 自己定制的数据查询DSL,写起来风格有点像带运算与函数支持的 CSS 选择器。譬如要查找网站icyfenix.cn访问人数,会是如下写法:
// 查询命令:
total_website_visitors{host=“icyfenix.cn”}
// 返回结果:
total_website_visitors{host=“icyfenix.cn”,job="prometheus"}=(10086)通过 PromQL 可以轻易实现指标之间的运算、聚合、统计等操作,在查询界面中往往需要通过 PromQL 计算多种指标的统计结果才能满足监控的需要,语法方面的细节笔者就不详细展开了,具体可以参考Prometheus 的文档手册。
最后补充说明一下,时序数据库对度量系统来说是很合适的选择,但并不是说绝对只有用时序数据库才能解决度量指标的存储问题,Prometheus 流行之前最老牌的度量系统 Zabbix 用的就是传统关系数据库来存储指标。
监控预警
指标度量是手段,最终目的是做分析和预警。界面分析和监控预警是与用户更加贴近的功能模块,但对度量系统本身而言,它们都属于相对外围的功能。与追踪系统的情况类似,广义上的度量系统由面向目标系统进行指标采集的客户端(Client,与目标系统进程在一起的 Agent,或者代表目标系统的 Exporter 等都可归为客户端),负责调度、存储和提供查询能力的服务端(Server,Prometheus 的服务端是带存储的,但也有很多度量服务端需要配合独立的存储来使用的),以及面向最终用户的终端(Backend,UI 界面、监控预警功能等都归为终端)组成。狭义上的度量系统就只包括客户端和服务端,不包含终端。
按照定义,Prometheus 应算是处于狭义和广义的度量系统之间,尽管它确实内置了一个界面解决方案“Console Template”,以模版和 JavaScript 接口的形式提供了一系列预设的组件(菜单、图表等),让用户编写一段简单的脚本就可以实现可用的监控功能。不过这种可用程度,往往不足以支撑正规的生产部署,只能说是为把度量功能嵌入到系统的某个子系统中提供了一定便利。在生产环境下,大多是 Prometheus 配合 Grafana 来进行展示的,这是 Prometheus 官方推荐的组合方案,但该组合也并非唯一选择,如果要搭配 Kibana 甚至 SkyWalking(8.x 版之后的 SkyWalking 支持从 Prometheus 获取度量数据)来使用也都是完全可行的。
良好的可视化能力对于提升度量系统的产品力十分重要,长期趋势分析(譬如根据对磁盘增长趋势的观察判断什么时候需要扩容)、对照分析(譬如版本升级后对比新旧版本的性能、资源消耗等方面的差异)、故障分析(不仅从日志、追踪自底向上可以分析故障,高维度的度量指标也可能自顶向下寻找到问题的端倪)等分析工作,既需要度量指标的持续收集、统计,往往还需要对数据进行可视化,才能让人更容易地从数据中挖掘规律,毕竟数据最终还是要为人类服务的。
除了为分析、决策、故障定位等提供支持的用户界面外,度量信息的另一种主要的消费途径是用来做预警。譬如你希望当磁盘消耗超过 90%时给你发送一封邮件或者是一条微信消息,通知管理员过来处理,这就是一种预警。Prometheus 提供了专门用于预警的 Alert Manager,将 Alert Manager 与 Prometheus 关联后,可以设置某个指标在多长时间内达到何种条件就会触发预警状态,触发预警后,根据路由中配置的接收器,譬如邮件接收器、Slack 接收器、微信接收器、或者更通用的WebHook接收器等来自动通知用户。