即使只限定在“软件架构设计”这个语境下,系统安全仍然是一个很大的话题。我们谈论的计算机系统安全,不仅仅是指“防御系统被黑客攻击”这样狭隘的安全,,还至少应包括(不限于)以下这些问题的具体解决方案:
- 认证(Authentication):系统如何正确分辨出操作用户的真实身份?
- 授权( Authorization):系统如何控制一个用户该看到哪些数据、能操作哪些功能?
- 凭证(Credential):系统如何保证它与用户之间的承诺是双方当时真实意图的体现,是准确、完整且不可抵赖的?
- 保密(Confidentiality):系统如何保证敏感数据无法被包括系统管理员在内的内外部人员所窃取、滥用?
- 传输(Transport Security):系统如何保证通过网络传输的信息无法被第三方窃听、篡改和冒充?
- 验证(Verification):系统如何确保提交到每项服务中的数据是合乎规则的,不会对系统稳定性、数据一致性、正确性产生风险?
与安全相关的问题,一般不会直接创造价值,解决起来又烦琐复杂,费时费力,因此经常性被开发者有意无意地忽略掉。庆幸的是这些问题基本上也都是与具体系统、具体业务无关的通用性问题,这意味着它们往往会存在着业界通行的、已被验证过是行之有效的解决方案,乃至已经形成行业标准,不需要开发者自己从头去构思如何解决。
认证
认证(Authentication)
系统如何正确分辨出操作用户的真实身份?
认证、授权和凭证可以说是一个系统中最基础的安全设计,哪怕再简陋的信息系统,大概也不可能忽略掉“用户登录”功能。信息系统为用户提供服务之前,总是希望先弄清楚“你是谁?”(认证)、“你能干什么?”(授权)以及“你如何证明?”(凭证)这三个基本问题。账户和权限信息作为一种必须最大限度保障安全和隐私,同时又要兼顾各个系统模块甚至系统间共享访问的基础主数据,它的存储、管理与使用都面临一系列复杂的问题。对于某些大规模的信息系统,账户和权限的管理往往要由专门的基础设施来负责,譬如微软的活动目录(Active Directory,AD)或者轻量目录访问协议(Lightweight Directory Access Protocol,LDAP),跨系统的共享使用甚至会用到区块链技术。
另外还有一个认知偏差:尽管“认证”是解决“你是谁?”的问题,但这里的“你”并不一定是指人,也可能是指外部的代码,即第三方的类库或者服务。最初,对代码认证的重要程度甚至高于对最终用户的认证,譬如在早期的 Java 系统里,安全认证默认是特指“代码级安全”,即你是否信任要在你的电脑中运行的代码。这是由 Java 当时的主要应用形式——Java Applets 所决定的:类加载器从远端下载一段字节码,以 Applets 的形式在用户的浏览器中运行,由于 Java 操控计算机资源的能力要远远强于 JavaScript,因此必须先确保这些代码不会损害用户的计算机,否则就谁都不敢去用。这一阶段的安全观念催生了现在仍然存在于 Java 技术体系中的“安全管理器”(java.lang.SecurityManager)、“代码权限许可”(java.lang.RuntimePermission)等概念。如今,对外部类库和服务的认证需求依然普遍,但相比起五花八门的最终用户认证来说,代码认证的研究发展方向已经很固定,基本上都统一到证书签名上。在本节中,认证的范围只限于对最终用户的认证,而代码认证会安排在“分布式的基石”中的“服务安全”去讲解。
认证的标准
世纪之交,Java 迎来了 Web 时代的辉煌,互联网的迅速兴起促使 Java 进入了快速发展时期。这时候,基于 HTML 和 JavaScript 的超文本 Web 应用迅速超过了“Java 2 时代”之前的 Java Applets 应用,B/S 系统对最终用户认证的需求使得“安全认证”的重点逐渐从“代码级安全”转为“用户级安全”,即你是否信任正在操作的用户。在 1999 年,随 J2EE 1.2(它是 J2EE 的首个版本,为了与 J2SE 同步,初始版本号直接就是 1.2)发布的 Servlet 2.2 中,添加了一系列用于认证的 API,主要包括下列两部分内容:
- 标准方面,添加了四种内置的、不可扩展的认证方案,即 Client-Cert、Basic、Digest 和 Form。
- 实现方面,添加了与认证和授权相关的一套程序接口,譬如
HttpServletRequest::isUserInRole()、HttpServletRequest::getUserPrincipal()等方法。
一项发布超过 20 年的老旧技术,原本并没有什么专门提起的必要性,笔者之所以引用这件事,是希望从它包含的两部分内容中引出一个架构安全性的经验原则:以标准规范为指导、以标准接口去实现。安全涉及的问题很麻烦,但解决方案已相当成熟,对于 99%的系统来说,在安全上不去做轮子,不去想发明创造,严格遵循标准就是最恰当的安全设计。
引用 J2EE 1.2 对安全的改进还有另一个原因,它内置的 Basic、Digest、Form 和 Client-Cert 这四种认证方案都很有代表性,刚好分别覆盖了通信信道、协议和内容层面的认证。而这三种层面认证恰好涵盖了主流的三种认证方式,具体含义和应用场景列举如下。
- 通信信道上的认证:你和我建立通信连接之前,要先证明你是谁。在网络传输(Network)场景中的典型是基于 SSL/TLS 传输安全层的认证。
- 通信协议上的认证:你请求获取我的资源之前,要先证明你是谁。在互联网(Internet)场景中的典型是基于 HTTP 协议的认证。
- 通信内容上的认证:你使用我提供的服务之前,要先证明你是谁。在万维网(World Wide Web)场景中的典型是基于 Web 内容的认证。
关于通信信道上的认证,由于内容较多,又与后续介绍微服务安全方面的话题关系密切,将会独立放到本章的“传输”里,而且 J2EE 中的 Client-Cert 其实并不是用于 TLS 的,以它引出 TLS 并不合适。下面重点了解基于通信协议和通信内容的两种认证方式。
HTTP 认证
前文已经提前用到了一个技术名词——认证方案(Authentication Schemes),它是指生成用户身份凭证的某种方法,这个概念最初源于 HTTP 协议的认证框架(Authentication Framework)。IETF 在RFC 7235中定义了 HTTP 协议的通用认证框架,要求所有支持 HTTP 协议的服务器,在未授权的用户意图访问服务端保护区域的资源时,应返回 401 Unauthorized 的状态码,同时应在响应报文头里附带以下两个分别代表网页认证和代理认证的 Header 之一,告知客户端应该采取何种方式产生能代表访问者身份的凭证信息:
WWW-Authenticate: <认证方案> realm=<保护区域的描述信息>
Proxy-Authenticate: <认证方案> realm=<保护区域的描述信息>接收到该响应后,客户端必须遵循服务端指定的认证方案,在请求资源的报文头中加入身份凭证信息,由服务端核实通过后才会允许该请求正常返回,否则将返回 403 Forbidden 错误。请求头报文应包含以下 Header 项之一:
Authorization: <认证方案> <凭证内容>
Proxy-Authorization: <认证方案> <凭证内容>HTTP 认证框架提出认证方案是希望能把认证“要产生身份凭证”的目的与“具体如何产生凭证”的实现分离开来,无论客户端通过生物信息(指纹、人脸)、用户密码、数字证书抑或其他方式来生成凭证,都属于是如何生成凭证的具体实现,都可以包容在 HTTP 协议预设的框架之内。HTTP 认证框架的工作流程如图 5-1 所示。
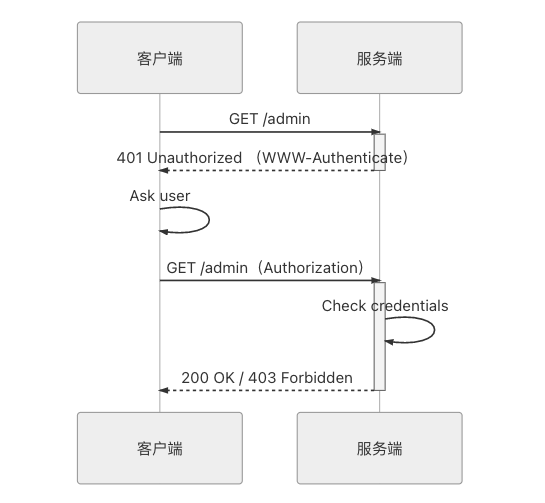
图 5-1 HTTP 认证框架的工作流程时序图
以上概念性的介绍可能会有些枯燥抽象,下面笔者将以最基础的认证方案——HTTP Basic 认证为例来介绍认证是如何工作的。HTTP Basic 认证是一种主要以演示为目的的认证方案,也应用于一些不要求安全性的场合,譬如家里的路由器登录等。Basic 认证产生用户身份凭证的方法是让用户输入用户名和密码,经过 Base64 编码“加密”后作为身份凭证。譬如请求资源GET /admin后,浏览器会收到来自服务端的如下响应:
HTTP/1.1 401 Unauthorized
Date: Mon, 24 Feb 2020 16:50:53 GMT
WWW-Authenticate: Basic realm="example from icyfenix.cn"此时,浏览器必须询问最终用户,即弹出类似图 5-2 所示的 HTTP Basic 认证对话框,要求提供用户名和密码。.
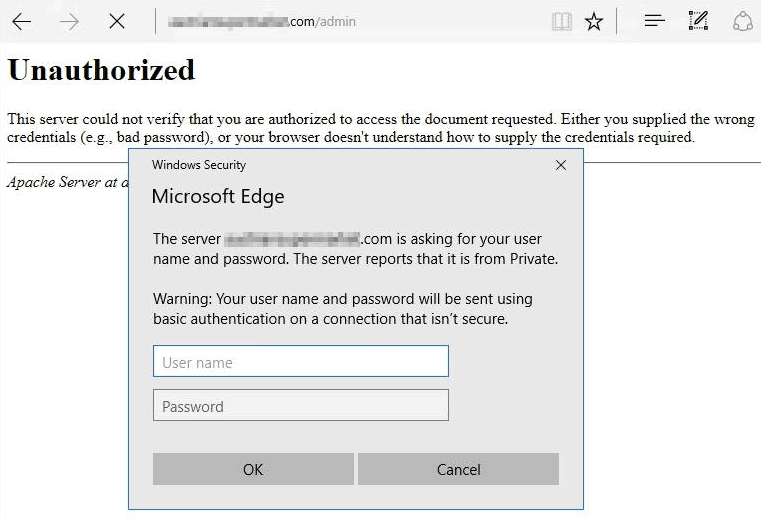
图 5-2 HTTP Basic 认证对话框
用户在对话框中输入密码信息,譬如输入用户名icyfenix,密码123456,浏览器会将字符串icyfenix:123456编码为aWN5ZmVuaXg6MTIzNDU2,然后发送给服务端,HTTP 请求如下所示:
GET /admin HTTP/1.1
Authorization: Basic aWN5ZmVuaXg6MTIzNDU2服务端接收到请求,解码后检查用户名和密码是否合法,如果合法就返回/admin的资源,否则就返回 403 Forbidden 错误,禁止下一步操作。注意 Base64 只是一种编码方式,并非任何形式的加密,所以 Basic 认证的风险是显而易见的。除 Basic 认证外,IETF 还定义了很多种可用于实际生产环境的认证方案,列举如下。
- Digest:RFC 7616,HTTP 摘要认证,可视为 Basic 认证的改良版本,针对 Base64 明文发送的风险,Digest 认证把用户名和密码加盐(一个被称为 Nonce 的变化值作为盐值)后再通过 MD5/SHA 等哈希算法取摘要发送出去。但是这种认证方式依然是不安全的,无论客户端使用何种加密算法加密,无论是否采用了 Nonce 这样的动态盐值去抵御重放和冒认,遇到中间人攻击时依然存在显著的安全风险。关于加解密的问题,将在“保密”小节中详细讨论。
- Bearer:RFC 6750,基于 OAuth 2 规范来完成认证,OAuth2 是一个同时涉及认证与授权的协议,在“授权”小节将详细介绍 OAuth 2。
- HOBA:RFC 7486 ,HOBA(HTTP Origin-Bound Authentication)是一种基于自签名证书的认证方案。基于数字证书的信任关系主要有两类模型:一类是采用 CA(Certification Authority)层次结构的模型,由 CA 中心签发证书;另一种是以 IETF 的 Token Binding 协议为基础的 OBC(Origin Bound Certificate)自签名证书模型。在“传输”小节将详细介绍数字证书。
HTTP 认证框架中的认证方案是允许自行扩展的,并不要求一定由 RFC 规范来定义,只要用户代理(User Agent,通常是浏览器,泛指任何使用 HTTP 协议的程序)能够识别这种私有的认证方案即可。因此,很多厂商也扩展了自己的认证方案。
- AWS4-HMAC-SHA256:亚马逊 AWS 基于 HMAC-SHA256 哈希算法的认证。
- NTLM / Negotiate:这是微软公司 NT LAN Manager(NTLM)用到的两种认证方式。
- Windows Live ID:微软开发并提供的“统一登入”认证。
- Twitter Basic:一个不存在的网站所改良的 HTTP 基础认证。
- ……
Web 认证
IETF 为 HTTP 认证框架设计了可插拔(Pluggable)的认证方案,原本是希望能涌现出各式各样的认证方案去支持不同的应用场景。尽管上节列举了一些还算常用的认证方案,但目前的信息系统,尤其是在系统对终端用户的认证场景中,直接采用 HTTP 认证框架的比例其实十分低,这不难理解,HTTP 是“超文本传输协议”,传输协议的根本职责是把资源从服务端传输到客户端,至于资源具体是什么内容,只能由客户端自行解析驱动。以 HTTP 协议为基础的认证框架也只能面向传输协议而不是具体传输内容来设计,如果用户想要从服务器中下载文件,弹出一个 HTTP 服务器的对话框,让用户登录是可接受的;但如果用户访问信息系统中的具体服务,身份认证肯定希望是由系统本身的功能去完成的,而不是由 HTTP 服务器来负责认证。这种依靠内容而不是传输协议来实现的认证方式,在万维网里被称为“Web 认证”,由于实现形式上登录表单占了绝对的主流,因此通常也被称为“表单认证”(Form Authentication)。
直至 2019 年以前,表单认证都没有什么行业标准可循,表单是什么样,其中的用户字段、密码字段、验证码字段是否要在客户端加密,采用何种方式加密,接受表单的服务地址是什么等,都完全由服务端与客户端的开发者自行协商决定。“没有标准的约束”反倒成了表单认证的一大优点,表单认证允许我们做出五花八门的页面,各种程序语言、框架或开发者本身都可以自行决定认证的全套交互细节。
可能你还记得开篇中说的“遵循规范、别造轮子就是最恰当的安全”,这里又将表单认证的高自由度说成是一大优点,好话都让笔者给说全了。笔者提倡用标准规范去解决安全领域的共性问题,这条原则完全没有必要与界面是否美观合理、操作流程是否灵活便捷这些应用需求对立起来。譬如,想要支持密码或扫码等多种登录方式、想要支持图形验证码来驱逐爬虫与机器人、想要支持在登录表单提交之前进行必要的表单校验,等等,这些需求十分具体,不具备写入标准规范的通用性,却具备足够的合理性,应当在实现层面去满足。同时,如何控制权限保证不产生越权操作、如何传输信息保证内容不被窃听篡改、如何加密敏感内容保证即使泄漏也不被逆推出明文,等等,这些问题已有通行的解决方案,明确定义在规范之中,也应当在架构层面去遵循。
表单认证与 HTTP 认证不见得是完全对立的,两者有不同的关注点,可以结合使用。以 Fenix’s Bookstore 的登录功能为例,页面表单是一个自行设计的 Vue.js 页面,但认证的整个交互过程遵循 OAuth 2 规范的密码模式。
2019 年 3 月,万维网联盟(World Wide Web Consortium,W3C)批准了由FIDO(Fast IDentity Online,一个安全、开放、防钓鱼、无密码认证标准的联盟)领导起草的世界首份 Web 内容认证的标准“WebAuthn”(在这节里,我们只讨论 WebAuthn,不会涉及 CTAP、U2F 和 UAF),这里也许又有一些思维严谨的读者会感到矛盾与奇怪,不是才说了 Web 表单长什么样、要不要验证码、登录表单是否在客户端校验等等是十分具体的需求,不太可能定义在规范上的吗?确实如此,所以 WebAuthn 彻底抛弃了传统的密码登录方式,改为直接采用生物识别(指纹、人脸、虹膜、声纹)或者实体密钥(以 USB、蓝牙、NFC 连接的物理密钥容器)来作为身份凭证,从根本上消灭了用户输入错误产生的校验需求和防止机器人模拟产生的验证码需求等问题,甚至可以省掉表单界面,所以这个规范不关注界面该是什么样子、要不要验证码、是否要前端校验这些问题。
由于 WebAuthn 相对复杂,在阅读下面内容之前,如果你的设备和环境允许,建议先在GitHub 网站的 2FA 认证功能中实际体验一下如何通过 WebAuthn 完成两段式登录,再继续阅读后面的内容。硬件方面,要求用带有 Touch ID 的 MacBook,或者其他支持指纹、FaceID 验证的手机(目前在售的移动设备基本都带有生物识别装置)。软件方面,直至 iOS 13.6,iPhone 和 iPad 仍未支持 WebAuthn,但 Android 和 Mac OS 系统中的 Chrome,以及 Windows 的 Edge 浏览器都已经可以正常使用 WebAuthn 了。图 5-3 展示了使用 WebAuthn 登录不同浏览器的操作界面。
WebAuthn 规范涵盖了“注册”与“认证”两大流程,先来介绍注册流程,它大致可以分为以下步骤:
- 用户进入系统的注册页面,这个页面的格式、内容和用户注册时需要填写的信息均不包含在 WebAuthn 标准的定义范围内。
- 当用户填写完信息,点击“提交注册信息”的按钮后,服务端先暂存用户提交的数据,生成一个随机字符串(规范中称为 Challenge)和用户的 UserID(在规范中称作凭证 ID),返回给客户端。
- 客户端的 WebAuthn API 接收到 Challenge 和 UserID,把这些信息发送给验证器(Authenticator),验证器可理解为用户设备上 TouchID、FaceID、实体密钥等认证设备的统一接口。
- 验证器提示用户进行验证,如果支持多种认证设备,还会提示用户选择一个想要使用的设备。验证的结果是生成一个密钥对(公钥和私钥),由验证器存储私钥、用户信息以及当前的域名。然后使用私钥对 Challenge 进行签名,并将签名结果、UserID 和公钥一起返回客户端。
- 浏览器将验证器返回的结果转发给服务器。
- 服务器核验信息,检查 UserID 与之前发送的是否一致,并用公钥解密后得到的结果与之前发送的 Challenge 相比较,一致即表明注册通过,由服务端存储该 UserID 对应的公钥。
以上步骤的时序如图 5-4 所示。
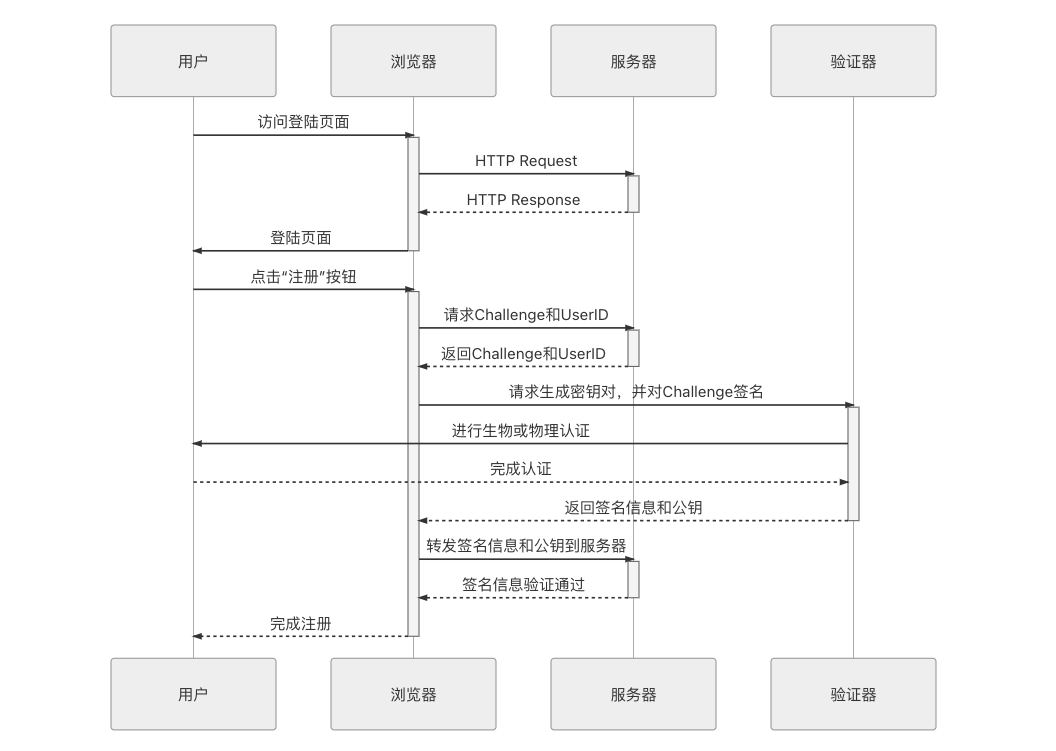
图 5-4 注册流程时序图
登录流程与注册流程类似,如果你理解了注册流程,就很容易理解登录流程了。登录流程大致可以分为以下步骤:
- 用户访问登录页面,填入用户名后即可点击登录按钮。
- 服务器返回随机字符串 Challenge、用户 UserID。
- 浏览器将 Challenge 和 UserID 转发给验证器。
- 验证器提示用户进行认证操作。由于在注册阶段验证器已经存储了该域名的私钥和用户信息,所以如果域名和用户都相同的话,就不需要生成密钥对了,直接以存储的私钥加密 Challenge,然后返回给浏览器。
- 服务端接收到浏览器转发来的被私钥加密的 Challenge,以此前注册时存储的公钥进行解密,如果解密成功则宣告登录成功。
WebAuthn 采用非对称加密的公钥、私钥替代传统的密码,这是非常理想的认证方案,私钥是保密的,只有验证器需要知道它,连用户本人都不需要知道,也就没有人为泄漏的可能;公钥是公开的,可以被任何人看到或存储。公钥可用于验证私钥生成的签名,但不能用来签名,除了得知私钥外,没有其他途径能够生成可被公钥验证为有效的签名,这样服务器就可以通过公钥是否能够解密来判断最终用户的身份是否合法。
WebAuthn 还一揽子地解决了传统密码在网络传输上的风险,在“保密”一节中我们会讲到无论密码是否客户端进行加密、如何加密,对防御中间人攻击来说都是没有意义的。更值得夸赞的是 WebAuthn 为登录过程带来极大的便捷性,不仅注册和验证的用户体验十分优秀,而且彻底避免了用户在一个网站上泄漏密码,所有使用相同密码的网站都受到攻击的问题,这个优点使得用户无须再为每个网站想不同的密码。
当前的 WebAuthn 还很年轻,普及率暂时还很有限,但笔者相信几年之内它必定会发展成 Web 认证的主流方式,被大多数网站和系统所支持。
认证的实现
了解过业界标准的认证规范以后,这部分简要介绍一下在 Java 技术体系内通常是如何实现安全认证的。Java 其实也有自己的认证规范,第一个系统性的 Java 认证规范发布于 Java 1.3 时代,是由 Sun 公司提出的同时面向代码级安全和用户级安全的认证授权服务——JAAS(Java Authentication and Authorization Service,Java 认证和授权服务,Java 1.3 处于扩展包中,Java 1.4 时纳入标准包)。尽管 JAAS 已经考虑了最终用户的认证,但代码级安全在规范中仍然占更主要的地位。可能今天用过甚至听过 JAAS 的 Java 程序员都已经不多了,但是这个规范提出了很多在今天仍然活跃于主流 Java 安全框架中的概念,譬如一般把用户存放在“Principal”之中、密码存在“Credentials”之中、登录后从安全上下文“Context”中获取状态等常见的安全概念,都可以追溯到这一时期所定下的 API:
- LoginModule (javax.security.auth.spi.LoginModule)
- LoginContext (javax.security.auth.login.LoginContext)
- Subject (javax.security.auth.Subject)
- Principal (java.security.Principal)
- Credentials(javax.security.auth.Destroyable、javax.security.auth.Refreshable)
JAAS 开创了这些沿用至今的安全概念,但规范本身实质上并没有得到广泛的应用,笔者认为有两大原因,一方面是由于 JAAS 同时面向代码级和用户级的安全机制,使得它过度复杂化,难以推广。在这个问题上 Java 社区一直有做持续的增强和补救,譬如 Java EE 6 中的 JASPIC、Java EE 8 中的 EE Security:
- JSR 115:Java Authorization Contract for Containers(JACC)
- JSR 196:Java Authentication Service Provider Interface for Containers(JASPIC)
- JSR 375: Java EE Security API(EE Security)
而另一方面,可能是更重要的一个原因,在 21 世纪的第一个十年里,以“With EJB”为口号,以 WebSphere、Jboss 等为代表的 J2EE 容器环境,与以“Without EJB”为口号、以 Spring、Hibernate 等为代表的轻量化开发框架产生了激烈的竞争,结果是后者获得了全面胜利。这个结果使得依赖于容器安全的 JAAS 无法得到大多数人的认可。
在今时今日,实际活跃于 Java 安全领域的是两个私有的(私有的意思是不由 JSR 所规范的,即没有 java/javax.*作为包名的)的安全框架:Apache Shiro和Spring Security。
相较而言,Shiro 更便捷易用,而 Spring Security 的功能则要复杂强大一些。无论是单体架构还是微服务架构的 Fenix’s Bookstore,笔者都选择了 Spring Security 作为安全框架,这个选择与功能、性能之类的考量没什么关系,就只是因为 Spring Boot、Spring Cloud 全家桶的缘故。这里不打算罗列代码来介绍 Shiro 与 Spring Security 的具体使用,如感兴趣可以参考 Fenix’s Bookstore 的源码仓库。只从目标上看,两个安全框架提供的功能都很类似,大致包括以下四类:
- 认证功能:以 HTTP 协议中定义的各种认证、表单等认证方式确认用户身份,这是本节的主要话题。
- 安全上下文:用户获得认证之后,要开放一些接口,让应用可以得知该用户的基本资料、用户拥有的权限、角色,等等。
- 授权功能:判断并控制认证后的用户对什么资源拥有哪些操作许可,这部分内容会放到“授权”介绍。
- 密码的存储与验证:密码是烫手的山芋,存储、传输还是验证都应谨慎处理,我们会放到“保密”去具体讨论。
授权
授权( Authorization)
系统如何控制一个用户该看到哪些数据、能操作哪些功能?
授权这个概念通常伴随着认证、审计、账号一同出现,并称为 AAAA(Authentication、Authorization、Audit、Account,也有一些领域把 Account 解释为计费的意思)。授权行为在程序中的应用非常广泛,给某个类或某个方法设置范围控制符(public、protected、private、
- 确保授权的过程可靠:对于单一系统来说,授权的过程是比较容易做到可控的,以前很多语境上提到授权,实质上讲的都是访问控制,理论上两者是应该分开的。而在涉及多方的系统中,授权过程则是一个比较困难却必须严肃对待的问题:如何既让第三方系统能够访问到所需的资源,又能保证其不泄露用户的敏感数据呢?常用的多方授权协议主要有 OAuth2 和 SAML 2.0(两个协议涵盖的功能并不是直接对等的)。
- 确保授权的结果可控:授权的结果用于对程序功能或者资源的访问控制(Access Control),成理论体系的权限控制模型有很多,譬如自主访问控制(Discretionary Access Control,DAC)、强制访问控制(Mandatory Access Control,MAC)、基于属性的访问控制(Attribute-Based Access Control,ABAC),还有最为常用的基于角色的访问控制(Role-Based Access Control,RBAC)。
由于篇幅原因,在这一节里我们只介绍 Fenix’s Bookstore 的代码中直接使用到的,也是日常开发中最常用到的 RBAC 和 OAuth2 这两种访问控制和授权方案。
RBAC
所有的访问控制模型,实质上都是在解决同一个问题:“谁(User)拥有什么权限(Authority)去操作(Operation)哪些资源(Resource)”。
这个问题初看起来并不难,一种直观的解决方案就是在用户对象上设定一些权限,当用户使用资源时,检查是否有对应的操作权限即可。很多著名的安全框架,譬如 Spring Security 的访问控制本质上就是支持这么做的。不过,这种把权限直接关联在用户身上的简单设计,在复杂系统上确实会导致一些比较烦琐的问题。试想一下,如果某个系统涉及到成百上千的资源,又有成千上万的用户,一旦两者搅合到一起,要为每个用户访问每个资源都分配合适的权限,必定导致巨大的操作量和极高的出错概率,这也正是 RBAC 所关注的问题之一。
RBAC 模型在业界中有多种说法,其中以美国 George Mason 大学信息安全技术实验室提出的 RBAC96 模型最具有系统性,得到普遍的认可。为了避免对每一个用户设定权限,RBAC 将权限从用户身上剥离,改为绑定到“角色”(Role)上,将权限控制变为对“角色拥有操作哪些资源的许可”这个逻辑表达式的值是否为真的求解过程。RBAC 的主要元素的关系可以图 5-5 来表示。

图 5-5 RBAC 的主要元素的关系示意图
图 5-5 中出现了一个新的名词“许可”(Permission)。许可是抽象权限的具象化体现,权限在 RBAC 系统中的含义是“允许何种操作作用于哪些资源之上”,这句话的具体实例即为“许可”。提出许可这个概念的目的其实与提出角色的目的是完全一致的,只是更为抽象。角色为的是解耦用户与权限之间的多对多关系,而许可为的是解耦操作与资源之间的多对多关系,譬如不同的数据都能够有增、删、改等操作,如果将数据与操作搅和在一起也会面临配置膨胀问题。这里举个更具体的例子帮助你理清众多名词之间的关系,譬如某个论文管理系统的 UserStory 中,与访问控制相关的 Backlog 可能会是这样描述的:
Backlog:
周同学(User)是某 SCI 杂志的审稿人(Role),职责之一是在系统中审核论文(Authority)。在审稿过程(Session)中,当他认为某篇论文(Resource)达到了可以公开发表标准时,就会在后台点击通过按钮(Operation)来完成审核。
以上 Backlog 中“给论文点击通过按钮”就是一种许可,它是“审核论文”这项权限的具象化体现。
采用 RBAC 不仅是为了简化配置操作,还天然地满足了计算机安全中的“最小特权原则”(Least Privilege)。在 RBAC 模型中,角色拥有许可的数量是根据完成该角色工作职责所需的最小权限来赋予的,最典型例子是操作系统权限管理中的用户组,根据对不同角色的职责分工,如管理员(Administrator)、系统用户(System)、验证用户(Authenticated Users)、普通用户(Users)、来宾用户(Guests)等分配各自的权限,既保证用户能够正常工作,也避免用户出现越权操作的风险。当用户的职责发生变化时,在系统中就体现为它所隶属的角色被改变,譬如将“普通用户角色”改变“管理员角色”,就可以迅速让该用户具备管理员的多个细分权限,降低权限分配错误的风险。
RBAC 还允许对不同角色之间定义关联与约束,进一步强化它的抽象描述能力。如不同的角色之间可以有继承性,典型的是 RBAC-1 模型的角色权限继承关系。譬如描述开发经理应该和开发人员一样具有代码提交的权限,描述开发人员都应该和任何公司员工一样具有食堂就餐的权限,就可以直接将食堂就餐赋予公司员工的角色上,把代码提交赋予到开发人员的角色上,再让开发人员的角色从公司员工派生,开发经理的角色从开发人员中派生即可。
不同角色之间也可以具有互斥性,典型的是 RBAC-2 模型的角色职责分离关系。互斥性要求权限被赋予角色时,或角色被赋予用户时应遵循的强制性职责分离规定。举个例子,角色的互斥约束可限制同一用户只能分配到一组互斥角色集合中至多一个角色,譬如不能让同一名员工既当会计,也当出纳,否则资金安全无法保证。角色的基数约束可限制某一个用户拥有的最大角色数目,譬如不能让同一名员工从产品、设计、开发、测试全部包揽,否则产品质量无法保证。
建立访问控制模型的基本目的是为了管理垂直权限和水平权限。垂直权限即功能权限,譬如前面提到的审稿编辑有通过审核的权限、开发经理有代码提交的权限、出纳有从账户提取资金的权限,这一类某个角色完成某项操作的许可,都可以直接翻译为功能权限。由于实际应用与权限模型具有高度对应关系,将权限从具体的应用中抽离出来,放到通用的模型中是相对容易的,Spring Security、Apache Shiro 等权限框架就是这样的抽象产物,大多数系统都能采用这些权限框架来管理功能权限。
与此相对,水平权限即数据权限管理起来则要困难许多。譬如用户 A、B 都属于同一个角色,但它们各自在系统中产生的数据完全有可能是私有的,A 访问或删除了 B 的数据也照样属于越权。一般来说,数据权限是很难抽象与通用的,仅在角色层面控制并不能满足全部业务的需要,很多时候只能具体到用户,甚至要具体管理到发生数据的某一行、某一列之上,因此数据权限基本只能由信息系统自主来来完成,并不存在能放之四海皆准的通用数据权限框架。
本书后面章节中的“重要角色”Kubernetes 完全遵循了 RBAC 来进行服务访问控制,Fenix’s Bookstore 所使用的 Spring Security 也参考了(但并没有完全遵循)RBAC 来设计它的访问控制功能。Spring Security 的设计里,用户和角色都可以拥有权限,譬如在它的 HttpSecurity 接口就同时有着 hasRole()和 hasAuthority()方法,可能刚接触的程序员会疑惑,混淆它们之间的关系。Spring Security 的访问控制模型如图 5-6 所示,可与前面 RBAC 的关系图对比一下。
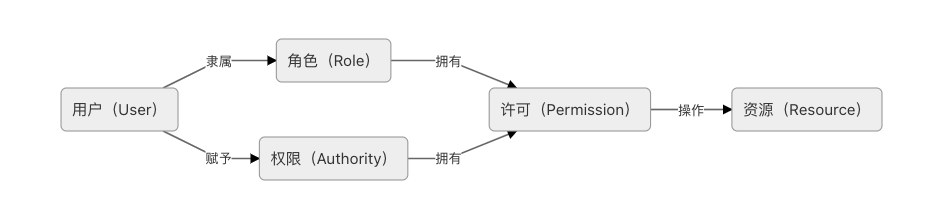
图 5-6 Spring Security 的访问控制模型
从实现角度来看,Spring Security 中的 Role 和 Authority 的差异很小,它们完全共享同一套存储结构,唯一的差别仅是 Role 会在存储时自动带上“ROLE_”前缀罢了。但从使用角度来看,Role 和 Authority 的差异可以很大,用户可以自行决定系统中到底 Permission 只能对应到角色身上,还是可以让用户也拥有某些角色中没有的权限。这一点不符合 RBAC 的思想,但笔者个人认同这是一种创新而非破坏,在 Spring Security 的文档上说的很清楚:这取决于你自己如何使用。
The core difference between these two(注:指 Role 和 Authority) is the semantics we attach to how we use the feature. For the framework, the difference is minimal – and it basically deals with these in exactly the same way.
Role 和 Authority 的核心差异取决于用户打算如何使用这些特性,在框架层面它们的差别是极小的,基本采用了完全相同的方式来进行处理。
通过 RBAC 很容易控制最终用户在广义和精细级别上能够做什么,可以指定用户是管理员、专家用户抑或普通用户,并使角色和访问权限与组织中员工的身份职位保持一致,仅根据需要为员工完成工作的最低限度来分配权限。这些都是大量软件系统、长时间积累下来的经验,将这些经验运用在软件产品上,绝大多数情况下要比自己发明创造一个新的轮子更加安全。
OAuth2
了解过 RBAC 的内容后,下面我们再来看看相对更复杂烦琐的 OAuth2 认证授权协议(更烦琐的 OAuth1 已经完全被废弃了)。OAuth2 是在RFC 6749中定义的国际标准,在 RFC 6749 正文的第一句就阐明了 OAuth2 是面向于解决第三方应用(Third-Party Application)的认证授权协议。如果你的系统并不涉及第三方,譬如我们单体架构的 Fenix’s Bookstore 中就既不为第三方提供服务,也不使用第三方的服务,那引入 OAuth2 其实并无必要。为什么强调第三方?在多方系统授权过程具体会有什么问题需要专门制订一个标准协议来解决呢?笔者举个现实的例子来解释。
譬如你现在正在阅读的这个网站(https://icyfenix.cn),它的建设和更新大致流程是:笔者以 Markdown 形式写好了某篇文章,上传到由GitHub 提供的代码仓库,接着由Travis-CI提供的持续集成服务会检测到该仓库发生了变化,触发一次 Vuepress 编译活动,生成目录和静态的 HTML 页面,然后推送回GitHub Pages,再触发国内的 CDN 缓存刷新。这个过程要能顺利进行,就存在一系列必须解决的授权问题,Travis-CI 只有得到了我的明确授权,GitHub 才能同意它读取我代码仓库中的内容,问题是它该如何获得我的授权呢?一种最简单粗暴的方案是把我的用户账号和密码都告诉 Travis-CI,但这显然导致了以下这些问题:
- 密码泄漏:如果 Travis-CI 被黑客攻破,将导致我的 GitHub 的密码也同时被泄漏。
- 访问范围:Travis-CI 将有能力读取、修改、删除、更新我放在 GitHub 上的所有代码仓库,而我并不希望它能够修改删除文件。
- 授权回收:只有修改密码才能回收我授予给 Travis-CI 的权力,可是我在 GitHub 的密码只有一个,授权的应用除了 Travis-CI 之外却还有许多,修改了意味着所有别的第三方的应用程序会全部失效。
以上列举的这些问题,也正是 OAuth2 所要解决的问题,尤其是要求第三方系统没有支持 HTTPS 传输安全的环境下依然能够解决这些问题,这并非易事。
OAuth2 给出了多种解决办法,这些办法的共同特征是以令牌(Token)代替用户密码作为授权的凭证。有了令牌之后,哪怕令牌被泄漏,也不会导致密码的泄漏;令牌上可以设定访问资源的范围以及时效性;每个应用都持有独立的令牌,哪个失效都不会波及其他。这样上面提出的三个问题就都解决了。有了一层令牌之后,整个授权的流程如图 5-7 所示。
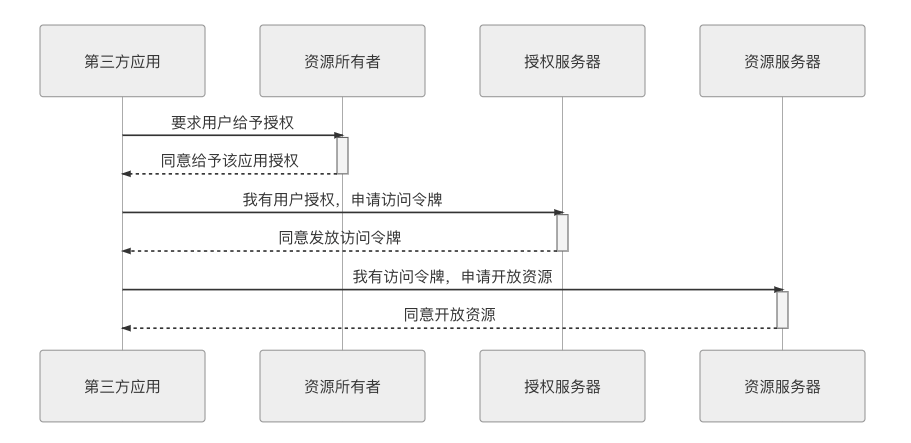
图 5-7 加令牌后的授权流程示意图
这个时序图里面涉及到了 OAuth2 中几个关键术语,我们通过前面那个具体的上下文语境来解释其含义,这对理解后续几种认证流程十分重要:
- 第三方应用(Third-Party Application):需要得到授权访问我资源的那个应用,即此场景中的“Travis-CI”。
- 授权服务器(Authorization Server):能够根据我的意愿提供授权(授权之前肯定已经进行了必要的认证过程,但它与授权可以没有直接关系)的服务器,即此场景中的“GitHub”。
- 资源服务器(Resource Server):能够提供第三方应用所需资源的服务器,它与认证服务可以是相同的服务器,也可以是不同的服务器,此场景中的“我的代码仓库”。
- 资源所有者(Resource Owner): 拥有授权权限的人,即此场景中的“我”。
- 操作代理(User Agent):指用户用来访问服务器的工具,对于人类用户来说,这个通常是指浏览器,但在微服务中一个服务经常会作为另一个服务的用户,此时指的可能就是 HttpClient、RPCClient 或者其他访问途径。
“用令牌代替密码”确实是解决问题的好方法,但这充其量只能算个思路,距离可实施的步骤还是不够具体的,时序图中的“要求/同意授权”、“要求/同意发放令牌”、“要求/同意开放资源”几个服务请求、响应该如何设计,这就是执行步骤的关键了。对此,OAuth2 一共提出了四种不同的授权方式(这也是 OAuth2 复杂烦琐的主要原因),分别为:
- 授权码模式(Authorization Code)
- 隐式授权模式(Implicit)
- 密码模式(Resource Owner Password Credentials)
- 客户端模式(Client Credentials)
授权码模式
授权码模式是四种模式中最严(luō)谨(suō)的,它考虑到了几乎所有敏感信息泄漏的预防和后果。具体步骤的时序如图 5-8 所示。
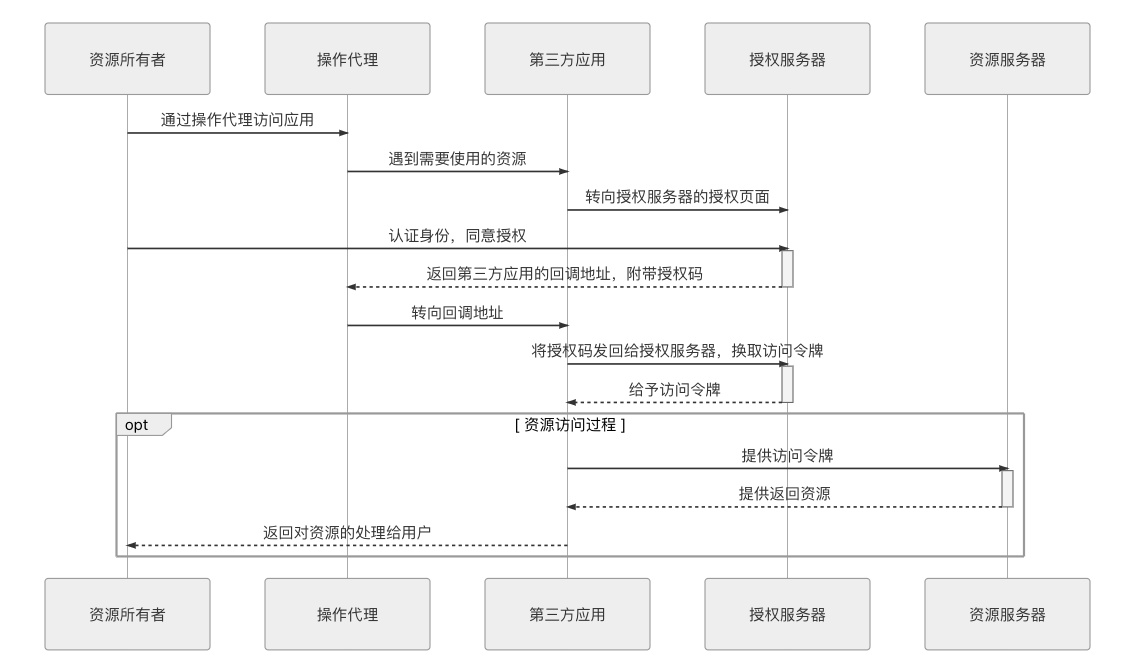
图 5-8 授权码模式的调用时序图
开始进行授权过程以前,第三方应用先要到授权服务器上进行注册,所谓注册,是指向认证服务器提供一个域名地址,然后从授权服务器中获取 ClientID 和 ClientSecret,以便能够顺利完成如下授权过程:
- 第三方应用将资源所有者(用户)导向授权服务器的授权页面,并向授权服务器提供 ClientID 及用户同意授权后的回调 URI,这是一次客户端页面转向。
- 授权服务器根据 ClientID 确认第三方应用的身份,用户在授权服务器中决定是否同意向该身份的应用进行授权,用户认证的过程未定义在此步骤中,在此之前应该已经完成。
- 如果用户同意授权,授权服务器将转向第三方应用在第 1 步调用中提供的回调 URI,并附带上一个授权码和获取令牌的地址作为参数,这是第二次客户端页面转向。
- 第三方应用通过回调地址收到授权码,然后将授权码与自己的 ClientSecret 一起作为参数,通过服务器向授权服务器提供的获取令牌的服务地址发起请求,换取令牌。该服务器的地址应与注册时提供的域名处于同一个域中。
- 授权服务器核对授权码和 ClientSecret,确认无误后,向第三方应用授予令牌。令牌可以是一个或者两个,其中必定要有的是访问令牌(Access Token),可选的是刷新令牌(Refresh Token)。访问令牌用于到资源服务器获取资源,有效期较短,刷新令牌用于在访问令牌失效后重新获取,有效期较长。
- 资源服务器根据访问令牌所允许的权限,向第三方应用提供资源。
这个过程设计,已经考虑到了几乎所有合理的意外情况,笔者再举几个最容易遇到的意外状况,以便你能够更好地理解为何要这样设计 OAuth2。
- 会不会有其他应用冒充第三方应用骗取授权?
ClientID 代表一个第三方应用的“用户名”,这项信息是可以完全公开的。但 ClientSecret 应当只有应用自己才知道,这个代表了第三方应用的“密码”。在第 5 步发放令牌时,调用者必须能够提供 ClientSecret 才能成功完成。只要第三方应用妥善保管好 ClientSecret,就没有人能够冒充它。 - 为什么要先发放授权码,再用授权码换令牌?
这是因为客户端转向(通常就是一次 HTTP 302 重定向)对于用户是可见的,换而言之,授权码可能会暴露给用户以及用户机器上的其他程序,但由于用户并没有 ClientSecret,光有授权码也是无法换取到令牌的,所以避免了令牌在传输转向过程中被泄漏的风险。 - 为什么要设计一个时限较长的刷新令牌和时限较短的访问令牌?不能直接把访问令牌的时间调长吗?
这是为了缓解 OAuth2 在实际应用中的一个主要缺陷,通常访问令牌一旦发放,除非超过了令牌中的有效期,否则很难(需要付出较大代价)有其他方式让它失效,所以访问令牌的时效性一般设计的比较短,譬如几个小时,如果还需要继续用,那就定期用刷新令牌去更新,授权服务器就可以在更新过程中决定是否还要继续给予授权。至于为什么说很难让它失效,我们将放到下一节“凭证”中去解释。
尽管授权码模式是严谨的,但是它并不够好用,这不仅仅体现在它那繁复的调用过程上,还体现在它对第三方应用提出了一个“貌似不难”的要求:第三方应用必须有应用服务器,因为第 4 步要发起服务端转向,而且要求服务端的地址必须与注册时提供的地址在同一个域内。不要觉得要求一个系统要有应用服务器是天经地义理所当然的事情,你现在阅读文章的这个网站就没有任何应用服务器的支持,里面使用到了 Gitalk 作为每篇文章的留言板,它对 GitHub 来说照样是第三方应用,需要 OAuth2 授权来解决。除基于浏览器的应用外,现在越来越普遍的是移动或桌面端的客户端 Web 应用(Client-Side Web Applications),譬如现在大量的基于 Cordova、Electron、Node-Webkit.js 的PWA 应用,它们都没有应用服务器的支持。由于有这样的实际需求,因此引出了 OAuth2 的第二种授权模式:隐式授权。
隐式授权模式
隐式授权省略掉了通过授权码换取令牌的步骤,整个授权过程都不需要服务端支持,一步到位。代价是在隐式授权中,授权服务器不会再去验证第三方应用的身份,因为已经没有应用服务器了,ClientSecret 没有人保管,就没有存在的意义了。但其实还是会限制第三方应用的回调 URI 地址必须与注册时提供的域名一致,尽管有可能被 DNS 污染之类的攻击所攻破,但仍算是尽可能努力一下。同样的原因,也不能避免令牌暴露给资源所有者,不能避免用户机器上可能意图不轨的其他程序、HTTP 的中间人攻击等风险了。
隐式授权的调用时序如图 5-9(从此之后的授权模式,时序中笔者就不再画出资源访问部分的内容了,就是前面 opt 框中的那一部分,以便更聚焦重点)所示。
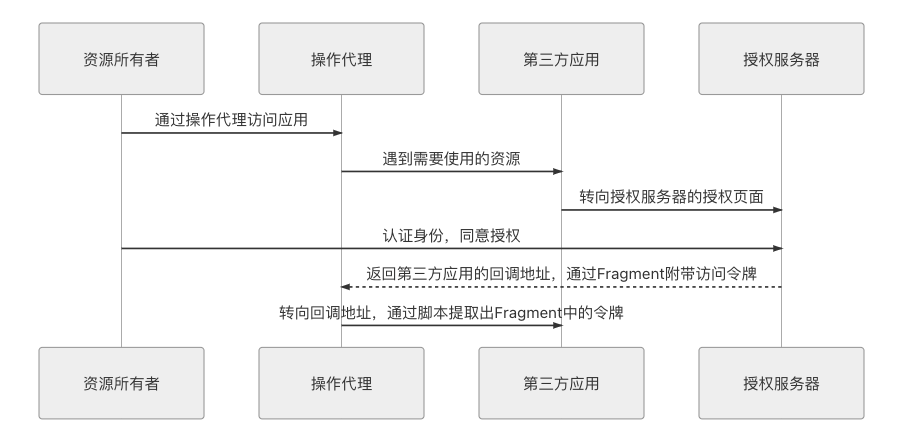
图 5-9 隐式授权的调用时序图
在时序图所示的交互过程里,隐式模式与授权码模式的显著区别是授权服务器在得到用户授权后,直接返回了访问令牌,这显著地降低了安全性,但 OAuth2 仍然努力尽可能地做到相对安全,譬如在前面提到的隐式授权中,尽管不需要用到服务端,但仍然需要在注册时提供回调域名,此时会要求该域名与接受令牌的服务处于同一个域内。此外,同样基于安全考虑,在隐式模式中明确禁止发放刷新令牌。
还有一点,在 RFC 6749 对隐式授权的描述中,特别强调了令牌必须是“通过 Fragment 带回”的。部分对超文本协议没有了解的读者,可能还根本不知道Fragment是个什么东西?
额外知识:Fragment
In computer hypertext, a fragment identifier is a string of characters that refers to a resource that is subordinate to another, primary resource. The primary resource is identified by a Uniform Resource Identifier (URI), and the fragment identifier points to the subordinate resource.
——URI Fragment,Wikipedia
看了这段英文定义还是觉得概念不好的话,我简单告诉你,Fragment 就是地址中#号后面的部分,譬如这个地址:
后面的/detail/1便是 Fragment,这个语法是在RFC 3986中定义的,RFC 3986 中解释了 Fragment 是用于客户端定位的 URI 从属资源,譬如 HTML 中就可以使用 Fragment 来做文档内的跳转而不会发起服务端请求,你现在可以点击一下这篇文章左边菜单中的几个子标题,看看浏览器地址栏的变化。此外,RFC 3986 还规定了如果浏览器对一个带有 Fragment 的地址发出 Ajax 请求,那 Fragment 是不会跟随请求被发送到服务端的,只能在客户端通过 Script 脚本来读取。所以隐式授权巧妙地利用这个特性,尽最大努力地避免了令牌从操作代理到第三方服务之间的链路存在被攻击而泄漏出去的可能性。至于认证服务器到操作代理之间的这一段链路的安全,则只能通过 TLS(即 HTTPS)来保证中间不会受到攻击了,我们可以要求认证服务器必须都是启用 HTTPS 的,但无法要求第三方应用同样都支持 HTTPS。
密码模式
前面所说的授权码模式和隐私模式属于纯粹的授权模式,它们与认证没有直接的联系,如何认证用户的真实身份是与进行授权互相独立的过程。但在密码模式里,认证和授权就被整合成了同一个过程了。
密码模式原本的设计意图是仅限于用户对第三方应用是高度可信任的场景中使用,因为用户需要把密码明文提供给第三方应用,第三方以此向授权服务器获取令牌。这种高度可信的第三方是极为较罕见的,尽管介绍 OAuth2 的材料中,经常举的例子是“操作系统作为第三方应用向授权服务器申请资源”,但真实应用中极少遇到这样的情况,合理性依然十分有限。
笔者认为,如果要采用密码模式,那“第三方”属性就必须弱化,把“第三方”视作是系统中与授权服务器相对独立的子模块,在物理上独立于授权服务器部署,但是在逻辑上与授权服务器仍同属一个系统,这样将认证和授权一并完成的密码模式才会有合理的应用场景。
譬如 Fenix’s Bookstore 便直接采用了密码模式,将认证和授权统一到一个过程中完成,尽管 Fenix’s Bookstore 中的 Frontend 工程和 Account 工程都能直接接触到用户名和密码,但它们事实上都是整个系统的一部分,这个前提下密码模式才具有可用性。关于分布式系统各个服务之间的信任关系,后续会在“零信任网络”与“服务安全”中作进一步讨论。
理解了密码模式的用途,它的调用过程就很简单了,就是第三方应用拿着用户名和密码向授权服务器换令牌而已。具体时序如图 5-10 所示。
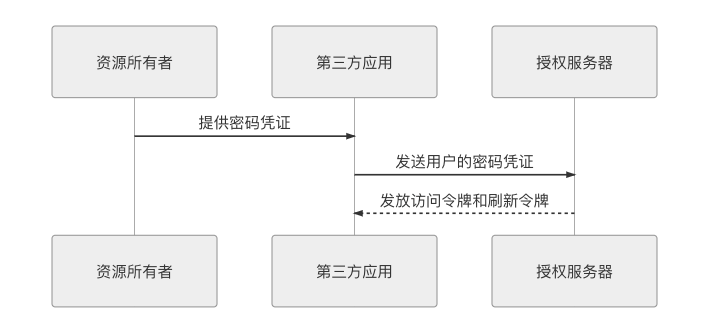
图 5-10 密码模式的调用时序图
密码模式下“如何保障安全”的职责无法由 OAuth2 来承担,只能由用户和第三方应用来自行保障,尽管 OAuth2 在规范中强调到“此模式下,第三方应用不得保存用户的密码”,但这并没有任何技术上的约束力。
客户端模式
客户端模式是四种模式中最简单的,它只涉及到两个主体,第三方应用和授权服务器。如果严谨一点,现在称“第三方应用”其实已经不合适了,因为已经没有了“第二方”的存在,资源所有者、操作代理在客户端模式中都是不必出现的。甚至严格来说叫“授权”都已不太恰当,资源所有者都没有了,也就不会有谁授予谁权限的过程。
客户端模式是指第三方应用(行文一致考虑,还是继续沿用这个称呼)以自己的名义,向授权服务器申请资源许可。此模式通常用于管理操作或者自动处理类型的场景中。举个具体例子,譬如笔者开了一家叫 Fenix’s Bookstore 的书店,因为小本经营,不像京东那样全国多个仓库可以调货,因此必须保证只要客户成功购买,书店就必须有货可发,不允许超卖。但经常有顾客下了订单又拖着不付款,导致部分货物处于冻结状态。所以 Fenix’s Bookstore 中有一个订单清理的定时服务,自动清理超过两分钟还未付款的订单。在这个场景里,订单肯定是属于下单用户自己的资源,如果把订单清理服务看作一个独立的第三方应用的话,它是不可能向下单用户去申请授权来删掉订单的,而应该直接以自己的名义向授权服务器申请一个能清理所有用户订单的授权。客户端模式的时序如图 5-11 所示。
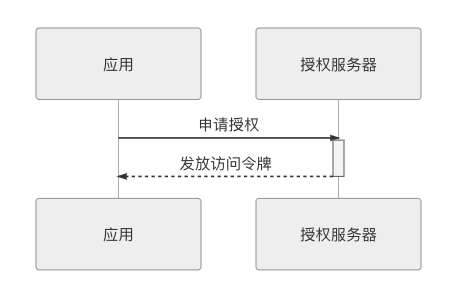
图 5-11 客户端模式的调用时序图
微服务架构并不提倡同一个系统的各服务间有默认的信任关系,所以服务之间调用也需要先进行认证授权,然后才能通信。此时,客户端模式便是一种常用的服务间认证授权的解决方案。Spring Cloud 版本的 Fenix’s Bookstore是采用这种方案来保证微服务之间的合法调用的,Istio 版本的 Fenix’s Bookstore则启用了双向 mTLS 通信,使用客户端证书来保障安全,它们可作为上一节介绍认证时提到的“通信信道认证”和“通信内容认证”例子,感兴趣的读者可以对比一下这两种方式的差异优劣。
OAuth2 中还有一种与客户端模式类似的授权模式,在RFC 8628中定义为“设备码模式”(Device Code),这里顺带提一下。设备码模式用于在无输入的情况下区分设备是否被许可使用,典型的应用便是手机锁网解锁(锁网在国内较少,但在国外很常见)或者设备激活(譬如某游戏机注册到某个游戏平台)的过程。它的时序如图 5-12 所示。
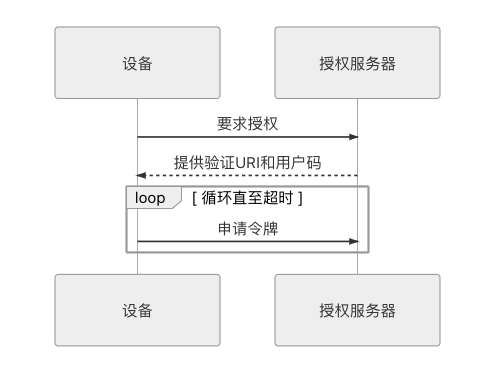
图 5-12 设备码模式的调用时序图
进行验证时,设备需要从授权服务器获取一个 URI 地址和一个用户码,然后需要用户手动或设备自动地到验证 URI 中输入用户码。在这个过程中,设备会一直循环,尝试去获取令牌,直到拿到令牌或者用户码过期为止。
凭证
凭证(Credentials)
系统如何保证它与用户之间的承诺是双方当时真实意图的体现,是准确、完整且不可抵赖的?
在前面介绍 OAuth2 的内容中,每一种授权模式的最终目标都是拿到访问令牌,但从未涉及过拿回来的令牌应该长什么样子。反而还挖了一些坑没有填(为何说 OAuth2 的一个主要缺陷是令牌难以主动失效)。这节讨论的主角是令牌,同时,还会讨论如果不使用 OAuth2,如何以最传统的方式完成认证、授权。
“如何承载认证授权信息”这个问题的不同看法,代表了软件架构对待共享状态信息的两种不同思路:状态应该维护在服务端,抑或是在客户端之中?在分布式系统崛起以前,这个问题原本已是有了较为统一的结论的,以 HTTP 协议的 Cookie-Session 机制为代表的服务端状态存储在三十年来都是主流的解决方案。不过,到了最近十年,由于分布式系统中共享数据必然会受到 CAP 不兼容原理的打击限制,迫使人们重新去审视之前已基本放弃掉的客户端状态存储,这就让原本通常只在多方系统中采用的 JWT 令牌方案,在分布式系统中也有了另一块用武之地。本节的话题,也就围绕着 Cookie-Session 和 JWT 之间的相同与不同而展开。
Cookie-Session
大家知道 HTTP 协议是一种无状态的传输协议,无状态是指协议对事务处理没有上下文的记忆能力,每一个请求都是完全独立的,但是我们中肯定有许多人并没有意识到 HTTP 协议无状态的重要性。假如你做了一个简单的网页,其中包含了 1 个 HTML、2 个 Script 脚本、3 个 CSS、还有 10 张图片,这个网页成功展示在用户屏幕前,需要完成 16 次与服务端的交互来获取上述资源,由于网络传输各种等因素的影响,服务器发送的顺序与客户端请求的先后并没有必然的联系,按照可能出现的响应顺序,理论上最多会有 P(16,16) = 20,922,789,888,000 种可能性。试想一下,如果 HTTP 协议不是设计成无状态的,这 16 次请求每一个都有依赖关联,先调用哪一个、先返回哪一个,都会对结果产生影响的话,那协调工作会有多么复杂。
可是,HTTP 协议的无状态特性又有悖于我们最常见的网络应用场景,典型就是认证授权,系统总得要获知用户身份才能提供合适的服务,因此,我们也希望 HTTP 能有一种手段,让服务器至少有办法能够区分出发送请求的用户是谁。为了实现这个目的,RFC 6265规范定义了 HTTP 的状态管理机制,在 HTTP 协议中增加了 Set-Cookie 指令,该指令的含义是以键值对的方式向客户端发送一组信息,此信息将在此后一段时间内的每次 HTTP 请求中,以名为 Cookie 的 Header 附带着重新发回给服务端,以便服务端区分来自不同客户端的请求。一个典型的 Set-Cookie 指令如下所示:
Set-Cookie: id=icyfenix; Expires=Wed, 21 Feb 2020 07:28:00 GMT; Secure; HttpOnly收到该指令以后,客户端再对同一个域的请求中就会自动附带有键值对信息id=icyfenix,譬如以下代码所示:
GET /index.html HTTP/2.0
Host: icyfenix.cn
Cookie: id=icyfenix根据每次请求传到服务端的 Cookie,服务器就能分辨出请求来自于哪一个用户。由于 Cookie 是放在请求头上的,属于额外的传输负担,不应该携带过多的内容,而且放在 Cookie 中传输也并不安全,容易被中间人窃取或被篡改,所以通常是不会像例子中设置id=icyfenix这样的明文信息。一般来说,系统会把状态信息保存在服务端,在 Cookie 里只传输的是一个无字面意义的、不重复的字符串,习惯上以sessionid或者jsessionid为名,服务器拿这个字符串为 Key,在内存中开辟一块空间,以 Key/Entity 的结构存储每一个在线用户的上下文状态,再辅以一些超时自动清理之类的管理措施。这种服务端的状态管理机制就是今天大家非常熟悉的 Session,Cookie-Session 也是最传统但今天依然广泛应用于大量系统中的,由服务端与客户端联动来完成的状态管理机制。
Cookie-Session 方案在本章的主题“安全性”上其实是有一定先天优势的:状态信息都存储于服务器,只要依靠客户端的同源策略和 HTTPS 的传输层安全,保证 Cookie 中的键值不被窃取而出现被冒认身份的情况,就能完全规避掉上下文信息在传输过程中被泄漏和篡改的风险。Cookie-Session 方案的另一大优点是服务端有主动的状态管理能力,可根据自己的意愿随时修改、清除任意上下文信息,譬如很轻易就能实现强制某用户下线的这样功能。
Session-Cookie 在单节点的单体服务环境中是最合适的方案,但当需要水平扩展服务能力,要部署集群时就开始面临麻烦了,由于 Session 存储在服务器的内存中,当服务器水平拓展成多节点时,设计者必须在以下三种方案中选择其一:
- 牺牲集群的一致性(Consistency),让均衡器采用亲和式的负载均衡算法,譬如根据用户 IP 或者 Session 来分配节点,每一个特定用户发出的所有请求都一直被分配到其中某一个节点来提供服务,每个节点都不重复地保存着一部分用户的状态,如果这个节点崩溃了,里面的用户状态便完全丢失。
- 牺牲集群的可用性(Availability),让各个节点之间采用复制式的 Session,每一个节点中的 Session 变动都会发送到组播地址的其他服务器上,这样某个节点崩溃了,不会中断都某个用户的服务,但 Session 之间组播复制的同步代价高昂,节点越多时,同步成本越高。
- 牺牲集群的分区容忍性(Partition Tolerance),让普通的服务节点中不再保留状态,将上下文集中放在一个所有服务节点都能访问到的数据节点中进行存储。此时的矛盾是数据节点就成为了单点,一旦数据节点损坏或出现网络分区,整个集群都不再能提供服务。
通过前面章节的内容,我们已经知道只要在分布式系统中共享信息,CAP 就不可兼得,所以分布式环境中的状态管理一定会受到 CAP 的局限,无论怎样都不可能完美。但如果只是解决分布式下的认证授权问题,并顺带解决少量状态的问题,就不一定只能依靠共享信息去实现。这句话的言外之意是提醒读者,接下来的 JWT 令牌与 Cookie-Session 并不是完全对等的解决方案,它只用来处理认证授权问题,充其量能携带少量非敏感的信息,只是 Cookie-Session 在认证授权问题上的替代品,而不能说 JWT 要比 Cookie-Session 更加先进,更不可能全面取代 Cookie-Session 机制。
JWT
Cookie-Session 机制在分布式环境下会遇到 CAP 不可兼得的问题,而在多方系统中,就更不可能谈什么 Session 层面的数据共享了,哪怕服务端之间能共享数据,客户端的 Cookie 也没法跨域。所以我们不得不重新捡起最初被抛弃的思路,当服务器存在多个,客户端只有一个时,把状态信息存储在客户端,每次随着请求发回服务器去。笔者才说过这样做的缺点是无法携带大量信息,而且有泄漏和篡改的安全风险。信息量受限的问题并没有太好的解决办法,但是要确保信息不被中间人篡改则还是可以实现的,JWT 便是这个问题的标准答案。
JWT(JSON Web Token)定义于RFC 7519标准之中,是目前广泛使用的一种令牌格式,尤其经常与 OAuth2 配合应用于分布式的、涉及多方的应用系统中。介绍 JWT 的具体构成之前,我们先来直观地看一下它是什么样子的,如图 5-13 所示。
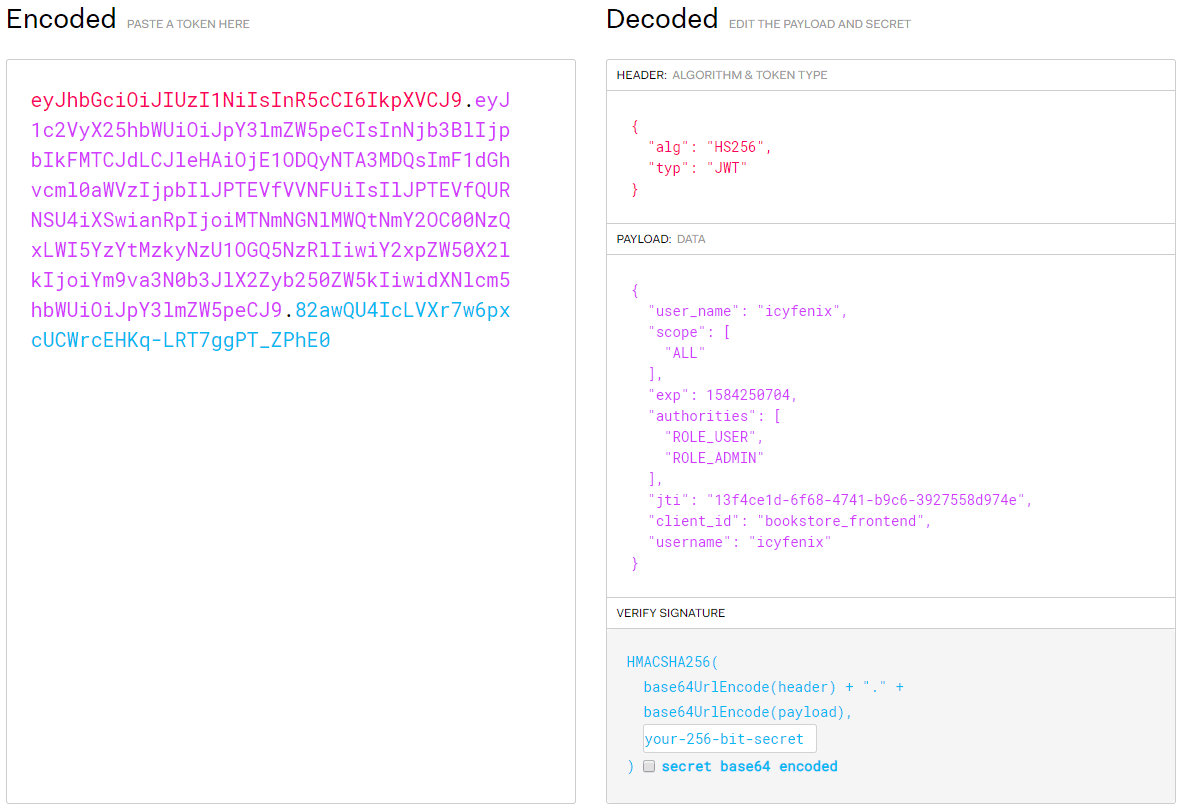 图 5-13 JWT 令牌结构
图 5-13 JWT 令牌结构
以上截图来自 JWT 官网(https://jwt.io),数据则是笔者随意编的。右边的 JSON 结构是 JWT 令牌中携带的信息,左边的字符串呈现了 JWT 令牌的本体。它最常见的使用方式是附在名为 Authorization 的 Header 发送给服务端,前缀在RFC 6750中被规定为 Bearer。如果你没有忘记“认证方案”与“OAuth 2”的内容,那看到 Authorization 这个 Header 与 Bearer 这个前缀时,便应意识到它是 HTTP 认证框架中的 OAuth 2 认证方案。如下代码展示了一次采用 JWT 令牌的 HTTP 实际请求:
GET /restful/products/1 HTTP/1.1
Host: icyfenix.cn
Connection: keep-alive
Authorization: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VyX25hbWUiOiJpY3lmZW5peCIsInNjb3BlIjpbIkFMTCJdLCJleHAiOjE1ODQ5NDg5NDcsImF1dGhvcml0aWVzIjpbIlJPTEVfVVNFUiIsIlJPTEVfQURNSU4iXSwianRpIjoiOWQ3NzU4NmEtM2Y0Zi00Y2JiLTk5MjQtZmUyZjc3ZGZhMzNkIiwiY2xpZW50X2lkIjoiYm9va3N0b3JlX2Zyb250ZW5kIiwidXNlcm5hbWUiOiJpY3lmZW5peCJ9.539WMzbjv63wBtx4ytYYw_Fo1ECG_9vsgAn8bheflL8图 5-13 中右边的状态信息是对令牌使用 Base64URL 转码后得到的明文,请特别注意是明文,JWT 只解决防篡改的问题,并不解决防泄漏的问题,因此令牌默认是不加密的。尽管你自己要加密也并不难做到,接收时自行解密即可,但这样做其实没有太大意义,原因笔者将在下一节“保密”中去解释。
从明文中可以看到 JWT 令牌是以 JSON 结构(毕竟名字就叫 JSON Web Token)存储的,结构总体上可划分为三个部分,每个部分间用点号.分隔开。
第一部分是令牌头(Header),内容如下所示:
{
"alg": "HS256",
"typ": "JWT"
}它描述了令牌的类型(统一为 typ:JWT)以及令牌签名的算法,示例中 HS256 为 HMAC SHA256 算法的缩写,其他各种系统支持的签名算法可以参考https://jwt.io/网站所列。
额外知识:散列消息认证码
在本节及后面其他关于安全的内容中,经常会在某种哈希算法前出现“HMAC”的前缀,这是指散列消息认证码(Hash-based Message Authentication Code,HMAC)。可以简单将它理解为一种带有密钥的哈希摘要算法,实现形式上通常是把密钥以加盐方式混入,与内容一起做哈希摘要。
HMAC 哈希与普通哈希算法的差别是普通的哈希算法通过 Hash 函数结果易变性保证了原有内容未被篡改,HMAC 不仅保证了内容未被篡改过,还保证了该哈希确实是由密钥的持有人所生成的。如图 5-14 所示。
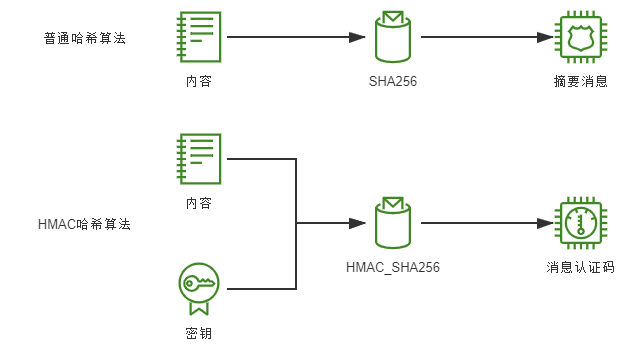
图 5-14 HMAC 哈希与普通哈希算法的差别
令牌的第二部分是负载(Payload),这是令牌真正需要向服务端传递的信息。针对认证问题,负载至少应该包含能够告知服务端“这个用户是谁”的信息,针对授权问题,令牌至少应该包含能够告知服务端“这个用户拥有什么角色/权限”的信息。JWT 的负载部分是可以完全自定义的,根据具体要解决的问题不同,设计自己所需要的信息,只是总容量不能太大,毕竟要受到 HTTP Header 大小的限制。一个 JWT 负载的例子如下所示:
{
"username": "icyfenix",
"authorities": [
"ROLE_USER",
"ROLE_ADMIN"
],
"scope": [
"ALL"
],
"exp": 1584948947,
"jti": "9d77586a-3f4f-4cbb-9924-fe2f77dfa33d",
"client_id": "bookstore_frontend"
}而 JWT 在 RFC 7519 中推荐(非强制约束)了七项声明名称(Claim Name),如有需要用到这些内容,建议字段名与官方的保持一致:
- iss(Issuer):签发人。
- exp(Expiration Time):令牌过期时间。
- sub(Subject):主题。
- aud (Audience):令牌受众。
- nbf (Not Before):令牌生效时间。
- iat (Issued At):令牌签发时间。
- jti (JWT ID):令牌编号。
此外在 RFC 8225、RFC 8417、RFC 8485 等规范文档,以及 OpenID 等协议中,都定义有约定好公有含义的名称,内容比较多,笔者就不贴出来了,可以参考IANA JSON Web Token Registry。
令牌的第三部分是签名(Signature),签名的意思是:使用在对象头中公开的特定签名算法,通过特定的密钥(Secret,由服务器进行保密,不能公开)对前面两部分内容进行加密计算,以例子里使用的 JWT 默认的 HMAC SHA256 算法为例,将通过以下公式产生签名值:
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret)签名的意义在于确保负载中的信息是可信的、没有被篡改的,也没有在传输过程中丢失任何信息。因为被签名的内容哪怕发生了一个字节的变动,也会导致整个签名发生显著变化。此外,由于签名这件事情只能由认证授权服务器完成(只有它知道 Secret),任何人都无法在篡改后重新计算出合法的签名值,所以服务端才能够完全信任客户端传上来的 JWT 中的负载信息。
JWT 默认的签名算法 HMAC SHA256 是一种带密钥的哈希摘要算法,加密与验证过程均只能由中心化的授权服务来提供,所以这种方式一般只适合于授权服务与应用服务处于同一个进程中的单体应用。在多方系统或者授权服务与资源服务分离的分布式应用中,通常会采用非对称加密算法来进行签名,这时候除了授权服务端持有的可以用于签名的私钥外,还会对其他服务器公开一个公钥,公开方式一般遵循JSON Web Key 规范。公钥不能用来签名,但是能被其他服务用于验证签名是否由私钥所签发的。这样其他服务器也能不依赖授权服务器、无须远程通信即可独立判断 JWT 令牌中的信息的真伪。
在 Fenix’s Bookstore 的单体服务版本中,采用了默认的 HMAC SHA256 算法来加密签名,而 Istio 服务网格版本里,终端用户认证会由服务网格的基础设施参来完成,此时就改用了非对称加密的 RSA SHA256 算法来进行签名,希望深入了解凭证安全的读者,不妨对比一下这两部分的代码。更多关于哈希摘要、对称和非对称加密的讨论,将会在“传输”一节中继续进行。
JWT 令牌是多方系统中一种优秀的凭证载体,它不需要任何一个服务节点保留任何一点状态信息,就能够保障认证服务与用户之间的承诺是双方当时真实意图的体现,是准确、完整、不可篡改、且不可抵赖的。同时,由于 JWT 本身可以携带少量信息,这十分有利于 RESTful API 的设计,能够较容易地做成无状态服务,在做水平扩展时就不需要像前面 Cookie-Session 方案那样考虑如何部署的问题。现实中也确实有一些项目直接采用 JWT 来承载上下文来实现完全无状态的服务端,这能获得任意加入或移除服务节点的巨大便利,天然具有完美的水平扩缩能力。譬如,在调试 Fenix’s Bookstore 的代码时,你随时都可以重启服务,重启后,客户端仍然能毫无感知地继续操作流程;而对于有状态的系统,就必须通过重新登录、进行前置业务操作来为服务端重建状态。尽管大型系统中只使用 JWT 来维护上下文状态,服务端完全不持有状态是不太现实的,不过将热点的服务单独抽离出来做成无状态,仍是一种有效提升系统吞吐能力的架构技巧。但是,JWT 也并非没有缺点的完美方案,它存在着以下几个经常被提及的缺点:
- 令牌难以主动失效:JWT 令牌一旦签发,理论上就和认证服务器再没有什么瓜葛了,在到期之前就会始终有效,除非服务器部署额外的逻辑去处理失效问题,这对某些管理功能的实现是很不利的。譬如一种颇为常见的需求是:要求一个用户只能在一台设备上登录,在 B 设备登录后,之前已经登录过的 A 设备就应该自动退出。如果采用 JWT,就必须设计一个“黑名单”的额外的逻辑,用来把要主动失效的令牌集中存储起来,而无论这个黑名单是实现在 Session、Redis 或者数据库中,都会让服务退化成有状态服务,降低了 JWT 本身的价值,但黑名单在使用 JWT 时依然是很常见的做法,需要维护的黑名单一般是很小的状态量,许多场景中还是有存在价值的。
- 相对更容易遭受重放攻击:首先说明 Cookie-Session 也是有重放攻击问题的,只是因为 Session 中的数据控制在服务端手上,应对重放攻击会相对主动一些。要在 JWT 层面解决重放攻击需要付出比较大的代价,无论是加入全局序列号(HTTPS 协议的思路)、Nonce 字符串(HTTP Digest 验证的思路)、挑战应答码(当下网银动态令牌的思路)、还是缩短令牌有效期强制频繁刷新令牌,在真正应用起来时都很麻烦。真要处理重放攻击,建议的解决方案是在信道层次(譬如启用 HTTPS)上解决,而不提倡在服务层次(譬如在令牌或接口其他参数上增加额外逻辑)上解决。
- 只能携带相当有限的数据:HTTP 协议并没有强制约束 Header 的最大长度,但是,各种服务器、浏览器都会有自己的约束,譬如 Tomcat 就要求 Header 最大不超过 8KB,而在 Nginx 中则默认为 4KB,因此在令牌中存储过多的数据不仅耗费传输带宽,还有额外的出错风险。
- 必须考虑令牌在客户端如何存储:严谨地说,这个并不是 JWT 的问题而是系统设计的问题。如果授权之后,操作完关掉浏览器就结束了,那把令牌放到内存里面,压根不考虑持久化那是最理想的方案。但并不是谁都能忍受一个网站关闭之后下次就一定强制要重新登录的。这样的话,想想客户端该把令牌存放到哪里?Cookie?localStorage?Indexed DB?它们都有泄漏的可能,而令牌一旦泄漏,别人就可以冒充用户的身份做任何事情。
- 无状态也不总是好的:这个其实不也是 JWT 的问题。如果不能想像无状态会有什么不好的话,我给你提个需求:请基于无状态 JWT 的方案,做一个在线用户实时统计功能。兄弟,难搞哦。
保密
保密(Confidentiality)
系统如何保证敏感数据无法被包括系统管理员在内的内外部人员所窃取、滥用?
保密是加密和解密的统称,是指以某种特殊的算法改变原有的信息数据,使得未授权的用户即使获得了已加密的信息,但因不知解密的方法,或者知晓解密的算法但缺少解密所需的必要信息,仍然无法了解数据的真实内容。
按照需要保密信息所处的环节不同,可以划分为“信息在客户端时的保密”、“信息在传输时的保密”和“信息在服务端时的保密”三类,或者进一步概括为“端的保密”和“链路的保密”两类。我们把最复杂、最有效,又早有标准解决方案的“传输环节”单独提取出来,放到下一个小节去讨论,本节将结合笔者的一些个人观点,重点讨论密码等敏感信息如何保障安全等级、是否应该从客户端开始加密、应该如何存储及如何验证等常见的安全保密问题。
保密的强度
保密是有成本的,追求越高的安全等级,就要付出越多的工作量与算力消耗。连国家保密法都会把秘密信息划分为秘密、机密、绝密三级来区别对待,可见即使是信息安全,也应该有所取舍。笔者以用户登录为例,列举几种不同强度的保密手段,讨论它们的防御关注点与弱点:
- 以摘要代替明文:如果密码本身比较复杂,那一次简单的哈希摘要至少可以保证即使传输过程中有信息泄漏,也不会被逆推出原信息;即使密码在一个系统中泄漏了,也不至于威胁到其他系统的使用,但这种处理不能防止弱密码被彩虹表攻击所破解。
- 先加盐值)再做哈希是应对弱密码的常用方法:盐值可以替弱密码建立一道防御屏障,一定程度上防御已有的彩虹表攻击,但并不能阻止加密结果被监听、窃取后,攻击者直接发送加密结果给服务端进行冒认。
- 将盐值变为动态值能有效防止冒认:如果每次密码向服务端传输时都掺入了动态的盐值,让每次加密的结果都不同,那即使传输给服务端的加密结果被窃取了,也不能冒用来进行另一次调用。尽管在双方通信均可能泄漏的前提下协商出只有通信双方才知道的保密信息是完全可行的(后续介绍“传输安全层”时会提到),但这样协商出盐值的过程将变得极为复杂,而且每次协商只保护一次操作,也难以阻止对其他服务的重放攻击。
- 给服务加入动态令牌,在网关或其他流量公共位置建立校验逻辑,服务端愿意付出在集群中分发令牌信息等代价的前提下,可以做到防止重放攻击,但是依然不能抵御传输过程中被嗅探而泄漏信息的问题。
- 启用 HTTPS 可以防御链路上的恶意嗅探,也能在通信层面解决了重放攻击的问题。但是依然有因客户端被攻破产生伪造根证书风险、有因服务端被攻破产生的证书泄漏而被中间人冒认的风险、有因CRL更新不及时或者OCSP Soft-fail 产生吊销证书被冒用的风险、有因 TLS 的版本过低或密码学套件选用不当产生加密强度不足的风险。
- 为了抵御上述风险,保密强度还要进一步提升,譬如银行会使用独立于客户端的存储证书的物理设备(俗称的 U 盾)来避免根证书被客户端中的恶意程序窃取伪造;大型网站涉及到账号、金钱等操作时,会使用双重验证开辟一条独立于网络的信息通道(如手机验证码、电子邮件)来显著提高冒认的难度;甚至一些关键企业(如国家电网)或机构(如军事机构)会专门建设遍布全国各地的与公网物理隔离的专用内部网络来保障通信安全。
听了上述这些逐步升级的保密措施,你应该能对“更高安全强度同时也意味着更多代价”有更具体的理解,不是任何一个网站、系统、服务都需要无限拔高的安全性。也许这时候你会好奇另一个问题:安全的强度有尽头吗?存不存在某种绝对安全的保密方式?答案可能出乎多数人的意料,确实是有的。信息论之父香农严格证明了一次性密码(One Time Password)的绝对安全性。但是使用一次性密码必须有个前提,就是已经提前安全地把密码或密码列表传达给对方。譬如,给你给朋友人肉送去一本存储了完全随机密码的密码本,然后每次使用其中一条密码来进行加密通信,用完一条丢弃一条,理论上这样可以做到绝对的安全,但显然这种绝对安全对于互联网没有任何的可行性。
客户端加密
客户端在用户登录、注册一类场景里是否需要对密码进行加密,这个问题一直存有争议。笔者的观点很明确:为了保证信息不被黑客窃取而做客户端加密没有太多意义,对绝大多数的信息系统来说,启用 HTTPS 可以说是唯一的实际可行的方案。但是!为了保证密码不在服务端被滥用,在客户端就开始加密是很有意义的。大网站被拖库的事情层出不穷,密码明文被写入数据库、被输出到日志中之类的事情也屡见不鲜,做系统设计时就应该把明文密码这种东西当成是最烫手的山芋来看待,越早消灭掉越好,将一个潜在的炸弹从客户端运到服务端,对绝大多数系统来说都没有必要。
为什么客户端加密对防御泄密会没有意义?原因是网络通信并非由发送方和接收方点对点进行的,客户端无法决定用户送出的信息能不能到达服务端,或者会经过怎样的路径到达服务端,在传输链路必定是不安全的假设前提下,无论客户端做什么防御措施,最终都会沦为“马其诺防线”。之前笔者已经提到多次的中间人攻击,它是通过劫持掉了客户端到服务端之间的某个节点,包括但不限于代理(通过 HTTP 代理返回赝品)、路由器(通过路由导向赝品)、DNS 服务(直接将你机器的 DNS 查询结果替换为赝品地址)等,来给你访问的页面或服务注入恶意的代码,极端情况下,甚至可能把要访问的服务或页面整个给取代掉,此时不论你在页面上设计了多么精巧严密的加密措施,都不会有保护作用。而攻击者只需地劫持路由器,或在局域网内其他机器释放 ARP 病毒便有可能做到这一点。
额外知识:中间人攻击(Man-in-the-Middle Attack,MitM)
在消息发出方和接收方之间拦截双方通信。用日常生活中的写信来类比的话:你给朋友写了一封信,邮递员可以把每一份你寄出去的信都拆开看,甚至把信的内容改掉,然后重新封起来,再寄出去给你的朋友。朋友收到信之后给你回信,邮递员又可以拆开看,看完随便改,改完封好再送到你手上。你全程都不知道自己寄出去的信和收到的信都经过邮递员这个“中间人”转手和处理——换句话说,对于你和你朋友来讲,邮递员这个“中间人”角色是不可见的。
对于“不应把明文传递到服务端”的观点,也是有一些不同意见的。譬如其中一种保存明文密码的理由是为了便于客户端做动态加盐,因为这需要服务端存储了明文,或者某种盐值/密钥固定的加密结果,才能每次用新的盐值重新加密来与客户端传上来的加密结果进行比对。笔者的看法是每次从服务端请求动态盐值,在客户端加盐传输的做法通常都得不偿失,客户端无论是否动态加盐,都不可能代替 HTTPS。真正防御性的密码加密存储确实应该在服务端中进行,但这是为了防御服务端被攻破而批量泄漏密码的风险,并不是为了增加传输过程的安全。
密码存储和验证
这节笔者以 Fenix’s Bookstore 中的真实代码为例,介绍对一个普通安全强度的信息系统,密码如何从客户端传输到服务端,然后存储进数据库的全过程。“普通安全强度”是指在具有一定保密安全性的同时,避免消耗过多的运算资源,验证起来也相对便捷。对多数信息系统来说,只要配合一定的密码规则约束,譬如密码要求长度、特殊字符等,再配合 HTTPS 传输,已足防御大多数风险了。即使在用户采用了弱密码、客户端通信被监听、服务端被拖库、泄漏了存储的密文和盐值等问题同时发生,也能够最大限度避免用户明文密码被逆推出来。下面先介绍密码创建的过程:
用户在客户端注册,输入明文密码:
123456。password = 123456客户端对用户密码进行简单哈希摘要,可选的算法有 MD2/4/5、SHA1/256/512、BCrypt、PBKDF1/2,等等。为了突出“简单”的哈希摘要,这里笔者故意没有排除掉 MD 系这些已经有了高效碰撞手段的算法。
client_hash = MD5(password) // e10adc3949ba59abbe56e057f20f883e为了防御彩虹表攻击应加盐处理,客户端加盐只取固定的字符串即可,如实在不安心,最多用伪动态的盐值(“伪动态”是指服务端不需要额外通信可以得到的信息,譬如由日期或用户名等自然变化的内容,加上固定字符串构成)。
client_hash = MD5(MD5(password) + salt) // SALT = $2a$10$o5L.dWYEjZjaejOmN3x4Qu假设攻击者截获了客户端发出的信息,得到了摘要结果和采用的盐值,那攻击者就可以枚举遍历所有 8 位字符以内(“8 位”只是举个例子,反正就是指弱密码,你如果拿 1024 位随机字符当密码用,加不加盐,彩虹表都跟你没什么关系)的弱密码,然后对每个密码再加盐计算,就得到一个针对固定盐值的对照彩虹表。为了应对这种暴力破解,并不提倡在盐值上做动态化,更理想的方式是引入慢哈希函数来解决。
慢哈希函数是指这个函数执行时间是可以调节的哈希函数,通常是以控制调用次数来实现的。BCrypt 算法就是一种典型的慢哈希函数,它做哈希计算时接受盐值 Salt 和执行成本 Cost 两个参数(代码层面 Cost 一般是混入在 Salt 中,譬如上面例子中的 Salt 就是混入了 10 轮运算的盐值,10 轮的意思是 210次哈希,Cost 参数是放在指数上的,最大取值就 31)。如果我们控制 BCrypt 的执行时间大概是 0.1 秒完成一次哈希计算的话,按照 1 秒生成 10 个哈希值的速度,算完所有的 10 位大小写字母和数字组成的弱密码大概需要 P(62,10)/(3600×24×365)/0.1=1,237,204,169 年时间。
client_hash = BCrypt(MD5(password) + salt) // MFfTW3uNI4eqhwDkG7HP9p2mzEUu/r2只需防御被拖库后针对固定盐值的批量彩虹表攻击。具体做法是为每一个密码(指客户端传来的哈希值)产生一个随机的盐值。笔者建议采用“密码学安全伪随机数生成器”(Cryptographically Secure Pseudo-Random Number Generator,CSPRNG)来生成一个长度与哈希值长度相等的随机字符串。对于 Java 语言,从 Java SE 7 起提供了
java.security.SecureRandom类,用于支持 CSPRNG 字符串生成。SecureRandom random = new SecureRandom(); byte server_salt[] = new byte[36]; random.nextBytes(server_salt); // tq2pdxrblkbgp8vt8kbdpmzdh1w8bex将动态盐值混入客户端传来的哈希值再做一次哈希,产生出最终的密文,并和上一步随机生成的盐值一起写入到同一条数据库记录中。由于慢哈希算法占用大量处理器资源,笔者并不推荐在服务端中采用。不过,如果你阅读了 Fenix’s Bookstore 的源码,会发现这步依然采用了 Spring Security 5 中的
BcryptPasswordEncoder,但是请注意它默认构造函数中的 Cost 参数值为-1,经转换后实际只进行了 210=1024 次计算,并不会对服务端造成太大的压力。此外,代码中并未显式传入 CSPRNG 生成的盐值,这是因为BCryptPasswordEncoder本身就会自动调用 CSPRNG 产生盐值,并将该盐值输出在结果的前 32 位之中,因此也无须专门在数据库中设计存储盐值字段。这个过程以伪代码表示如下:server_hash = SHA256(client_hash + server_salt); // 55b4b5815c216cf80599990e781cd8974a1e384d49fbde7776d096e1dd436f67 DB.save(server_hash, server_salt);
以上加密存储的过程相对复杂,但是运算压力最大的过程(慢哈希)是在客户端完成的,对服务端压力很小,也不惧怕因网络通信被截获而导致明文密码泄漏。密码存储后,以后验证的过程与加密是类似的,步骤如下:
客户端,用户在登录页面中输入密码明文:
123456,经过与注册相同的加密过程,向服务端传输加密后的结果。authentication_hash = MFfTW3uNI4eqhwDkG7HP9p2mzEUu/r2服务端,接受到客户端传输上来的哈希值,从数据库中取出登录用户对应的密文和盐值,采用相同的哈希算法,对客户端传来的哈希值、服务端存储的盐值计算摘要结果。
result = SHA256(authentication_hash + server_salt); // 55b4b5815c216cf80599990e781cd8974a1e384d49fbde7776d096e1dd436f67比较上一步的结果和数据库储存的哈希值是否相同,如果相同那么密码正确,反之密码错误。
authentication = compare(result, server_hash) // yes
传输
传输(Transport Security)
系统如何保证通过网络传输的信息无法被第三方窃听、篡改和冒充?
前文中笔者已经为传输安全层挖下了不少坑,譬如:基于信道的认证是怎样实现的?为什么 HTTPS 是绝大部分信息系统防御通信被窃听和篡改的唯一可行手段?传输安全层难道不也是一种自动化的加密吗?为何说客户端如何加密都不能代替 HTTPS?
本节将以“假设链路上的安全得不到保障,攻击者如何摧毁之前认证、授权、凭证、保密中所提到的种种安全机制”为场景,讲解传输层安全所要解决的问题,同时也是对前面这些疑问句的回答。
摘要、加密与签名
我们从 JWT 令牌的一小段“题外话”来引出现代密码学算法的三种主要用途:摘要、加密与签名。JWT 令牌携带信息的可信度源自于它是被签名过的信息,因此是不可篡改的,是令牌签发者真实意图的体现。然而,你是否了解过签名具体做了什么?为什么有签名就能够让负载中的信息变得不可篡改和不可抵赖呢?要解释数字签名(Digital Signature),必须先从密码学算法的另外两种基础应用“摘要”和“加密”说起。
摘要也称之为数字摘要(Digital Digest)或数字指纹(Digital Fingerprint)。JWT 令牌中默认的签名信息是对令牌头、负载和密钥三者通过令牌头中指定的哈希算法(HMAC SHA256)计算出来的摘要值,如下所示:
signature = SHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload) , secret)理想的哈希算法都具备两个特性:一是易变性,这是指算法的输入端发生了任何一点细微变动,都会引发雪崩效应(Avalanche Effect),使得输出端的结果产生极大的变化。这个特性常被用来做校验,保护信息未被篡改,譬如互联网上下载大文件,常会附有一个哈希校验码,以确保下载下来的文件没有因网络或其他原因与原文件产生任何偏差。二是不可逆性,摘要的过程是单向的,不可能从摘要的结果中逆向还原出输入值来。这点只要具备初中数学知识就能想明白,世间的信息有无穷多种,而摘要的结果无论其位数是 32、128、512 Bits,再大也总归是个有限的数字,因此输入数据与输出的摘要结果必然不是一一对应的关系,如果我把一部电影做摘要形成 256 Bits 的哈希值,应该没有人会指望能从这个哈希值中还原出一部电影的。偶尔能听到 MD5、SHA1 或其他哈希算法被破解了的新闻,这里的“破解”并不是“解密”的意思,而是指找到了该算法的高效率碰撞方法,能够在合理的时间内生成两个摘要结果相同的输入比特流,但并不能指定这两个输入流中的某一个,更不代表碰撞产生的比特流就会是原来的输入源。
由这两个特点可见,摘要的意义是在源信息不泄漏的前提下辨别其真伪。易变性保证了从公开的特征上可以甄别出是否来自于源信息,不可逆性保证了从公开的特征并不会暴露出源信息,这与今天用做身份甄别的指纹、面容和虹膜的生物特征是具有高度可比性的。在一些场合中,摘要也会被借用来做加密(如保密中介绍的慢哈希 Bcrypt 算法)和签名(如 JWT 签名中的 HMAC SHA256 算法),但在严格意义上看,摘要与这两者是有本质的区别。
加密与摘要的本质区别在于加密是可逆的,逆过程就是解密。在经典密码学时代,加密的安全主要是依靠机密性来保证的,即依靠保护加密算法或算法的执行参数不被泄漏来保障信息的安全。而现代密码学不依靠机密性,加解密算法都是完全公开的,安全建立在特定问题的计算复杂度之上,具体是指算法根据输入端计算输出结果耗费的算力资源很小,但根据输出端的结果反过来推算原本的输入,耗费的算力就极其庞大。一个经常在课堂中用来说明计算复杂度的例子是大数的质因数分解,我们可以轻而易举的地(以 O(nlogn)的复杂度)计算出两个大素数的乘积,譬如:
97667323933 * 128764321253 = 12576066674829627448049根据算术基本定理,质因数的分解形式是唯一的,且前面计算条件中给出的运算因子已经是质数,所以 12,576,066,674,829,627,448,049 的分解形式就只有唯一的形式,即上面所示的唯一答案。然而如何对大数进行质因数分解,迄今没有找到多项式时间的算法,甚至无法确切地知道这个问题属于哪个复杂度类(Complexity Class)。所以尽管这个过程理论上一定是可逆的,但实际上算力差异决定了逆过程无法实现。(注:24 位十进制数的因数分解完全在现代计算机的暴力处理能力范围内,这里只是举例。但目前很多计算机科学家都相信大数分解问题就是一种P!=NP的证例,尽管也并没有人能证明它一定不存在多项式时间的解法。除了质因数分解外,离散对数和椭圆曲线也是具备实用性的复杂问题)
根据加密与解密是否采用同一个密钥,现代密码学算法可分为对称加密算法和非对称加密两大类型,这两类算法各自有很明确的优劣势与应用场景。对称加密的缺点显而易见,加密和解密使用相同的密钥,当通信的成员数量增加时,为保证两两通信都都采用独立的密钥,密钥数量就与成员数量的平方成正比,这必然面临密钥管理的难题。而更尴尬的难题是当通信双方原本就不存在安全的信道时,如何才能将一个只能让通信双方才能知道的密钥传输给对方?如果有通道可以安全地传输密钥,那为何不使用现有的通道传输信息?这个“蛋鸡悖论”曾在很长的时间里严重阻碍了密码学在真实世界中推广应用。
20 世纪 70 年代中后期出现的非对称加密算法从根本上解决了密钥分发的难题,它将密钥分成公钥和私钥,公钥可以完全公开,无须安全传输的保证。私钥由用户自行保管,不参与任何通信传输。根据这两个密钥加解密方式的不同,使得算法可以提供两种不同的功能:
- 公钥加密,私钥解密,这种就是加密,用于向私钥所有者发送信息,这个信息可能被他人篡改,但是无法被他人得知。如果甲想给乙发一个安全保密的数据,那么应该甲乙各自有一个私钥,甲先用乙的公钥加密这段数据,再用自己的私钥加密这段加密后的数据。最后再发给乙,这样确保了内容即不会被读取,也不能被篡改。
- 私钥加密,公钥解密,这种就是签名,用于让所有公钥所有者验证私钥所有者的身份,并且用来防止私钥所有者发布的内容被篡改。但是不用来保证内容不被他人获得。
这两种用途理论上肯定是成立的,现实中却一般不成立,单靠非对称加密算法,既做不了加密也做不了签名。原因是不论是加密还是解密,非对称加密算法的计算复杂度都相当高,性能比对称加密要差上好几个数量级(不是好几倍)。加解密性能不仅影响速度,还导致了现行的非对称加密算法都没有支持分组加密模式。分组是指由于明文长度与密钥长度在安全上具有相关性,通俗地说就是多长的密钥决定了它能加密多长的明文,如果明文太短就需要进行填充,太长就需要进行分组。因非对称加密本身的效率所限,难以支持分组,所以主流的非对称加密算法都只能加密不超过密钥长度的数据,这决定了非对称加密不能直接用于大量数据的加密。
在加密方面,现在一般会结合对称与非对称加密的优点,以混合加密来保护信道安全,具体做法是用非对称加密来安全地传递少量数据给通信的另一方,然后再以这些数据为密钥,采用对称加密来安全高效地大量加密传输数据,这种由多种加密算法组合的应用形式被称为“密码学套件”。非对称加密在这个场景中发挥的作用称为“密钥协商”。
在签名方面,现在一般会结合摘要与非对称加密的优点,以对摘要结果做加密的形式来保证签名的适用性。由于对任何长度的输入源做摘要之后都能得到固定长度的结果,所以只要对摘要的结果进行签名,即相当于对整个输入源进行了背书,保证一旦内容遭到篡改,摘要结果就会变化,签名也就马上失效了。
表 5-1 汇总了前面提到的三种算法,并列举了它们的主要特征、用途和局限性。
表 5-1 三种密码学算法的对比
| 类型 | 特点 | 常见实现 | 主要用途 | 主要局限 |
|---|---|---|---|---|
| 哈希摘要 | 不可逆,即不能解密,所以并不是加密算法,只是一些场景把它当作加密算法使用。 易变性,输入发生 1 Bit 变动,就可能导致输出结果 50%的内容发生改变。 无论输入长度多少,输出长度固定(2 的 N 次幂)。 | MD2/4/5/6、SHA0/1/256/512 | 摘要 | 无法解密 |
| 对称加密 | 加密是指加密和解密是一样的密钥。 设计难度相对较小,执行速度相对较块。 加密明文长度不受限制。 | DES、AES、RC4、IDEA | 加密 | 要解决如何把密钥安全地传递给解密者。 |
| 非对称加密 | 加密和解密使用的是不同的密钥。 明文长度不能超过公钥长度。 | RSA、BCDSA、ElGamal | 签名、传递密钥 | 性能与加密明文长度受限。 |
现在,让我们再回到开篇关于 JWT 令牌的几个问题中来。有了哈希摘要、对称和非对称加密,JWT 令牌的签名就能保证负载中的信息不可篡改、不可抵赖吗?其实还是不行的,这个场景里,数字签名的安全性仍存在一个致命的漏洞:公钥虽然是公开的,但在网络世界里“公开”具体是一种什么操作?如何保证每一个获取公钥的服务,拿到的公钥就是授权服务器所希望它拿到的?
在网络传输是不可信任的前提下,公钥在网络传输过程中可能已经被篡改,如果获取公钥的网络请求被攻击者截获并篡改,返回了攻击者自己的公钥,那以后攻击者就可以用自己的私钥来签名,让资源服务器无条件信任它的所有行为了。现实世界中公开公钥,可以通过打电话、发邮件、短信息、登报纸、同时发布在多个网站上等等,很多网络通信之外的途径来达成,但在程序与网络的世界中,就必须找到一种可信任的公开方法,而且这种方法不能依赖加密来实现,否则又将陷入蛋鸡问题之中。
数字证书
当我们无法以“签名”的手段来达成信任时,就只能求助于其他途径。不妨想想真实的世界中,我们是如何达成信任的,其实不外乎以下两种:
- 基于共同私密信息的信任
譬如某个陌生号码找你,说是你的老同学,生病了要找你借钱。你能够信任他的方式是向对方询问一些你们两个应该知道,且只有你们两个知道的私密信息,如果对方能够回答上来,他有可能真的是你的老同学,否则他十有八九就是个诈骗犯。 - 基于权威公证人的信任
如果有个陌生人找你,说他是警察,让你把存款转到他们的安全账号上。你能够信任他的方式是去一趟公安局,如果公安局担保他确实是个警察,那他有可能真的是警察,否则他十有八九就是个诈骗犯。
回到网络世界中,我们并不能假设授权服务器和资源服务器是互相认识的,所以通常不太会采用第一种方式,而第二种就是目前标准的保证公钥可信分发的标准,这个标准有一个名字:公开密钥基础设施(Public Key Infrastructure,PKI)。
额外知识:公开密钥基础设施
又称公开密钥基础架构、公钥基础建设、公钥基础设施、公开密码匙基础建设或公钥基础架构,是一组由硬件、软件、参与者、管理政策与流程组成的基础架构,其目的在于创造、管理、分配、使用、存储以及撤销数字证书。
密码学上,公开密钥基础建设借着数字证书认证中心(Certificate Authority,CA)将用户的个人身份跟公开密钥链接在一起。对每个证书中心用户的身份必须是唯一的。链接关系通过注册和发布过程创建,根据担保级别的差异,创建过程可由 CA 的各种软件或者在人为监督下完成。PKI 的确定链接关系的这一角色称为注册管理中心(Registration Authority,RA)。RA 确保公开密钥和个人身份链接,可以防抵赖。
咱们不必纠缠于 PKI 概念上的内容,只要知道里面定义的“数字证书认证中心”相当于前面例子中“权威公证人”的角色,是负责发放和管理数字证书的权威机构即可。任何人包括你我都可以签发证书,只是不权威罢了。CA 作为受信任的第三方,承担公钥体系中公钥的合法性检验的责任。可是,这里和现实世界仍然有一些区别,现实世界你去找公安局,那大楼不大可能是剧场布景冒认的;而网络世界,在假设所有网络传输都有可能被截获冒认的前提下,“去 CA 中心进行认证”本身也是一种网络操作,这与之前的“去获取公钥”本质上不是没什么差别吗?其实还是有差别的,世间公钥成千上万不可枚举,而权威的 CA 中心则应是可数的,“可数”意味着可以不通过网络,而是在浏览器与操作系统出厂时就预置好,或者提前安装好(如银行的证书),图 5-15 是笔者机器上现存的根证书。
图 5-15 Windows 系统的 CA 证书
到这里出现了本节的主角之一:证书(Certificate),证书是权威 CA 中心对特定公钥信息的一种公证载体,也可以理解为是权威 CA 对特定公钥未被篡改的签名背书。由于客户的机器上已经预置了这些权威 CA 中心本身的证书(称为 CA 证书或者根证书),使得我们能够在不依靠网络的前提下,使用根证书里面的公钥信息对其所签发的证书中的签名进行确认。到此,终于打破了鸡生蛋、蛋生鸡的循环,使得整套数字签名体系有了坚实的逻辑基础。
PKI 中采用的证书格式是X.509 标准格式,它定义了证书中应该包含哪些信息,并描述了这些信息是如何编码的,里面最关键的就是认证机构的数字签名和公钥信息两项内容。一个数字证书具体包含以下内容:
版本号(Version):指出该证书使用了哪种版本的 X.509 标准(版本 1、版本 2 或是版本 3),版本号会影响证书中的一些特定信息,目前的版本为 3。
Version: 3 (0x2)序列号(Serial Number): 由证书颁发者分配的本证书的唯一标识符。
Serial Number: 04:00:00:00:00:01:15:4b:5a:c3:94签名算法标识符(Signature Algorithm ID):用于签发证书的算法标识,由对象标识符加上相关的参数组成,用于说明本证书所用的数字签名算法。譬如,SHA1 和 RSA 的对象标识符就用来说明该数字签名是利用 RSA 对 SHA1 的摘要结果进行加密。
Signature Algorithm: sha1WithRSAEncryption认证机构的数字签名(Certificate Signature):这是使用证书发布者私钥生成的签名,以确保这个证书在发放之后没有被篡改过。
认证机构(Issuer Name): 证书颁发者的可识别名。
Issuer: C=BE, O=GlobalSign nv-sa, CN=GlobalSign Organization Validation CA - SHA256 - G2有效期限(Validity Period): 证书起始日期和时间以及终止日期和时间,指明证书在这两个时间内有效。
Validity Not Before: Nov 21 08:00:00 2020 GMT Not After : Nov 22 07:59:59 2021 GMT主题信息(Subject):证书持有人唯一的标识符(Distinguished Name),这个名字在整个互联网上应该是唯一的,通常使用的是网站的域名。
Subject: C=CN, ST=GuangDong, L=Zhuhai, O=Awosome-Fenix, CN=*.icyfenix.cn公钥信息(Public-Key): 包括证书持有人的公钥、算法(指明密钥属于哪种密码系统)的标识符和其他相关的密钥参数。
传输安全层
到此为止,数字签名的安全性已经可以完全自洽了,但相信你大概也已经感受到了这条信任链的复杂与烦琐,如果从确定加密算法、生成密钥、公钥分发、CA 认证、核验公钥、签名、验证,每一个步骤都要由最终用户来完成的话,这种意义的“安全”估计只能一直是存于实验室中的阳春白雪。如何把这套烦琐的技术体系自动化地应用于无处不在的网络通信之中,便是本节的主题。
在计算机科学里,隔离复杂性的最有效手段(没有之一)就是分层,如果一层不够就再加一层,这点在网络中更是体现得淋漓尽致。OSI 模型、TCP/IP 模型将网络从物理特性(比特流)开始,逐层封装隔离,到了 HTTP 协议这种面向应用的协议里,使用者就已经不会去关心网卡/交换机如何处理数据帧、MAC 地址;不会去关心 ARP 如何做地址转换;不会去关心 IP 寻址、TCP 传输控制等细节。想要在网络世界中让用户无感知地实现安全通信,最合理的做法就是在传输层之上、应用层之下加入专门的安全层来实现,这样对上层原本基于 HTTP 的 Web 应用来说,影响甚至是无法察觉的。构建传输安全层这个想法,几乎可以说是和万维网的历史一样长,早在 1994 年,就已经有公司开始着手去实践了:
- 1994 年,网景(Netscape)公司开发了 SSL 协议(Secure Sockets Layer)的 1.0 版,这是构建传输安全层的起源,但是 SSL 1.0 从未正式对外发布过。
- 1995 年,Netscape 把 SSL 升级到 2.0 版,正式对外发布,但是刚刚发布不久就被发现有严重漏洞,所以并未大规模使用。
- 1996 年,修补好漏洞的 SSL 3.0 对外发布,这个版本得到了广泛的应用,很快成为 Web 网络安全层的事实标准。
- 1999 年,互联网标准化组织接替 Netscape,将 SSL 改名 TLS(Transport Layer Security)后形成了传输安全层的国际标准。第一个正式的版本是RFC 2246定义的 TLS 1.0,该版 TLS 的生命周期极长,直至笔者写下这段文字的 2020 年 3 月,主流浏览器(Chrome、Firefox、IE、Safari)才刚刚宣布同时停止 TLS 1.0/1.1 的支持。而讽刺的是,由于停止后许多政府网站被无法被浏览,此时又正值新冠病毒(COVID-19)爆发期,Firefox 紧急发布公告宣布撤回该改动,TLS 1.0 的生命还在顽强延续。
- 2006 年,TLS 的第一个升级版 1.1 发布(RFC 4346),但却沦为了被遗忘的孩子,很少人使用 TLS 1.1,甚至到了 TLS 1.1 从来没有已知的协议漏洞被提出的程度。
- 2008 年,TLS 1.1 发布 2 年之后,TLS 1.2 标准发布(RFC 5246),迄今超过 90%的互联网 HTTPS 流量是由 TLS 1.2 所支持的,现在仍在使用的浏览器几乎都完美支持了该协议。
- 2018 年,最新的 TLS 1.3(RFC 8446)发布,比起前面版本相对温和的升级,TLS 1.3 做了出了一些激烈的改动,修改了从 1.0 起一直没有大变化的两轮四次(2-RTT)握手,首次连接仅需一轮(1-RTT)握手即可完成,在有连接复用支持时,甚至将 TLS 1.2 原本的 1-RTT 下降到了 0-RTT,显著提升了访问速度。
接下来,笔者以 TLS 1.2 为例,介绍传输安全层是如何保障所有信息都是第三方无法窃听(加密传输)、无法篡改(一旦篡改通信算法会立刻发现)、无法冒充(证书验证身份)的。TLS 1.2 在传输之前的握手过程一共需要进行上下两轮、共计四次通信,时序如图 5-16 所示。
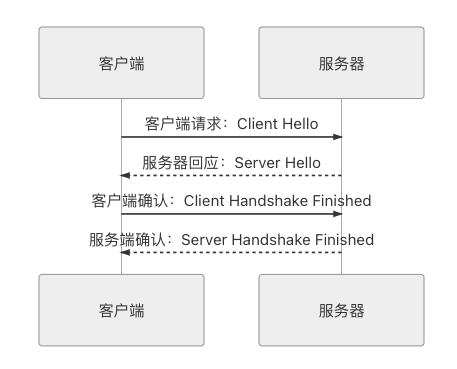
图 5-16 TLS 连接握手时序
- 客户端请求:Client Hello
客户端向服务器请求进行加密通信,在这个请求里面,它会以明文的形式,向服务端提供以下信息。- 支持的协议版本,譬如 TLS 1.2。但是要注意,1.0 至 3.0 分别代表 SSL1.0 至 3.0,TLS1.0 则是 3.1,一直到 TLS1.3 的 3.4。
- 一个客户端生成的 32 Bytes 随机数,这个随机数将稍后用于产生加密的密钥。
- 一个可选的 SessionID,注意不要和前面 Cookie-Session 机制混淆了,这个 SessionID 是指传输安全层的 Session,是为了 TLS 的连接复用而设计的。
- 一系列支持的密码学算法套件,例如
TLS_RSA_WITH_AES_128_GCM_SHA256,代表着密钥交换算法是 RSA,加密算法是 AES128-GCM,消息认证码算法是 SHA256 - 一系列支持的数据压缩算法。
- 其他可扩展的信息,为了保证协议的稳定,后续对协议的功能扩展大多都添加到这个变长结构中。譬如 TLS 1.0 中由于发送的数据并不包含服务器的域名地址,导致了一台服务器只能安装一张数字证书,这对虚拟主机来说就很不方便,所以 TLS 1.1 起就增加了名为“Server Name”的扩展信息,以便一台服务器给不同的站点安装不同的证书。
- 服务器回应:Server Hello
服务器接收到客户端的通信请求后,如果客户端声明支持的协议版本和加密算法组合与服务端相匹配的话,就向客户端发出回应。如果不匹配,将会返回一个握手失败的警告提示。这次回应同样以明文发送的,包括以下信息:- 服务端确认使用的 TLS 协议版本。
- 第二个 32 Bytes 的随机数,稍后用于产生加密的密钥。
- 一个 SessionID,以后可通过连接复用减少一轮握手。
- 服务端在列表中选定的密码学算法套件。
- 服务端在列表中选定的数据压缩方法。
- 其他可扩展的信息。
- 如果协商出的加密算法组合是依赖证书认证的,服务端还要发送出自己的 X.509 证书,而证书中的公钥是什么,也必须根据协商的加密算法组合来决定。
- 密钥协商消息,这部分内容对于不同密码学套件有着不同的价值,譬如对于 ECDH + anon 这样得密钥协商算法组合(基于椭圆曲线的ECDH 算法可以在双方通信都公开的情况下协商出一组只有通信双方知道的密钥)就不需要依赖证书中的公钥,而是通过 Server Key Exchange 消息协商出密钥。
- 客户端确认:Client Handshake Finished
由于密码学套件的组合复杂多样,这里仅以 RSA 算法为密钥交换算法为例介绍后续过程。
客户端收到服务器应答后,先要验证服务器的证书合法性。如果证书不是可信机构颁布的,或者证书中信息存在问题,譬如域名与实际域名不一致、或者证书已经过期、或通过在线证书状态协议得知证书已被吊销,等等,都会向访问者显示一个“证书不可信任”的警告,由用户自行选择是否还要继续通信。如果证书没有问题,客户端就会从证书中取出服务器的公钥,并向服务器发送以下信息:- 客户端证书(可选)。部分服务端并不是面向全公众,只对特定的客户端提供服务,此时客户端需要发送它自身的证书来证明身份。如果不发送,或者验证不通过,服务端可自行决定是否要继续握手,或者返回一个握手失败的信息。客户端需要证书的 TLS 通信也称为“双向 TLS”(Mutual TLS,常简写为 mTLS),这是云原生基础设施的主要认证方法,也是基于信道认证的最主流形式。
- 第三个 32 Bytes 的随机数,这个随机数不再是明文发送,而是以服务端传过来的公钥加密的,它被称为 PreMasterSecret,将与前两次发送的随机数一起,根据特定算法计算出 48 Bytes 的 MasterSecret ,这个 MasterSecret 即为后续内容传输时的对称加密算法所采用的私钥。
- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时也是前面发送的所有内容的哈希值,以供服务器校验。
- 服务端确认:Server Handshake Finished
服务端向客户端回应最后的确认通知,包括以下信息。- 编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
- 服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的哈希值,以供客户端校验。
至此,整个 TLS 握手阶段宣告完成,一个安全的连接就已成功建立。每一个连接建立时,客户端和服务端均通过上面的握手过程协商出了许多信息,譬如一个只有双方才知道的随机产生的密钥、传输过程中要采用的对称加密算法(例子中的 AES128)、压缩算法等,此后该连接的通信将使用此密钥和加密算法进行加密、解密和压缩。这种处理方式对上层协议的功能上完全透明的,在传输性能上会有下降,但在功能上完全不会感知到有 TLS 的存在。建立在这层安全传输层之上的 HTTP 协议,就被称为“HTTP over SSL/TLS”,也即是大家所熟知的 HTTPS。
从上面握手协商的过程中我们还可以得知,HTTPS 并非不是只有“启用了 HTTPS”和“未启用 HTTPS”的差别,采用不同的协议版本、不同的密码学套件、证书是否有效、服务端/客户端对面对无效证书时的处理策略如何都导致了不同 HTTPS 站点的安全强度的不同,因此并不能说只要启用了 HTTPS 就必定能够安枕无忧。
验证
验证(Verification)
系统如何确保提交到每项服务中的数据是合乎规则的,不会对系统稳定性、数据一致性、正确性产生风险?
数据验证与程序如何编码是密切相关的,许多开发者都不会把它归入安全的范畴之中。但请细想一下,关注“你是谁”(认证)、“你能做什么”(授权)等问题是很合理的,关注“你做得对不对”(验证)不也同样合理吗?从数量来讲,数据验证不严谨而导致的安全问题比其他安全攻击导致的要多得多;而风险上讲,由数据质量导致的问题,风险有高有低,真遇到高风险的数据问题,面临的损失不一定就比被黑客拖库来得小。
相比其他富有挑战性的安全措施,如防御与攻击两者缠斗的精彩,数学、心理、社会工程和计算机等跨学科知识的结合运用,数据验证确实有些无聊、枯燥,这项常规的工作在日常的开发中贯穿于代码的各个层次,每个程序员都肯定写过。但这种常见的代码反而是迫切需要被架构约束的,缺失的校验影响数据质量,过度的校验不会使得系统更加健壮,某种意义上反而会制造垃圾代码,甚至有副作用。
具体介绍见《Bean Validator》