通常我们所说的 GC 是指垃圾回收,但是在 JVM 的实现中 GC 更为准确的意思是指内存管理器,它有两个职能,第一是内存的分配管理,第二是垃圾回收。这两者是一个事物的两个方面,每一种垃圾回收策略都和内存的分配策略息息相关,脱离内存的分配去谈垃圾回收是没有任何意义的。
分区 Region
分区(Heap Region,HR)或称堆分区,是 G1 堆和操作系统交互的最小管理单位。G1 的分区类型(HeapRegionType)大致可以分为四类:
- 自由分区(Free Heap Region,FHR)
- 新生代分区(Young Heap Region,YHR)
- 大对象分区(Humongous Heap Region,HHR)
- 老生代分区(Old Heap Region,OHR)
其中新生代分区又可以分为 Eden 和 Survivor;大对象分区又可以分为:大对象头分区和大对象连续分区。
// hotspot/share/gc/g1/heapRegionType.hpp
// We encode the value of the heap region type so the generation can be
// determined quickly. The tag is split into two parts:
//
// major type (young, old, humongous, archive) : top N-1 bits
// minor type (eden / survivor, starts / cont hum, etc.) : bottom 1 bit
//
// If there's need to increase the number of minor types in the
// future, we'll have to increase the size of the latter and hence
// decrease the size of the former.
//
// 00000 0 [ 0] Free
//
// 00001 0 [ 2] Young Mask
// 00001 0 [ 2] Eden
// 00001 1 [ 3] Survivor
//
// 00010 0 [ 4] Humongous Mask
// 00100 0 [ 8] Pinned Mask
// 00110 0 [12] Starts Humongous
// 00110 1 [13] Continues Humongous
//
// 01000 0 [16] Old Mask
//卡表 CardTable
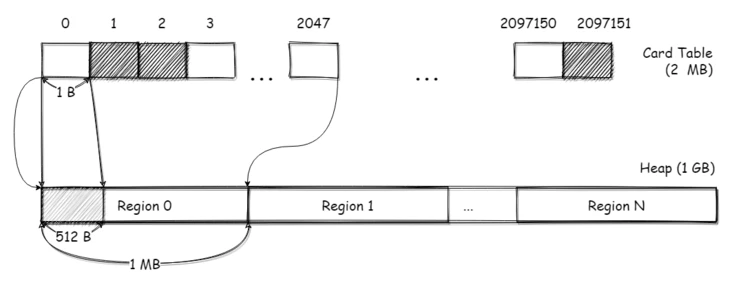
在 G1 堆中,存在 CardTable 的概念,CardTable 是由元素为 1B 的数组来实现的,数组里的元素称之为卡片/卡页(Page)。这个 CardTable 会映射到整个堆的空间,每个卡片会对应堆中的 512B 空间。
为什么卡表可以对应堆中 512B 的空间?
不知道——
如下图所示,在一个大小为 1 GB 的堆下,那么 CardTable 的长度为 2097151 (1GB / 512B);每个 Region 大小为 1 MB,每个 Region 都会对应 2048 个 Card Page。
收集集 CSet
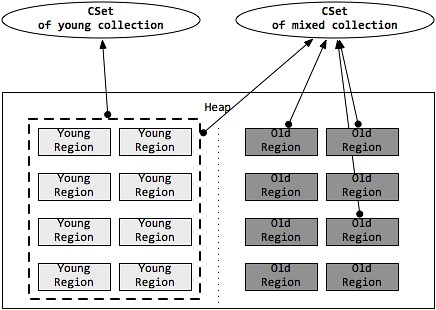
收集集合(CSet)代表每次 GC 暂停时回收的一系列目标分区。在任意一次收集暂停中,CSet 所有分区都会被释放,内部存活的对象都会被转移到分配的空闲分区中。因此无论是年轻代收集,还是混合收集,工作的机制都是一致的。年轻代收集 CSet 只容纳年轻代分区,而混合收集会通过启发式算法,在老年代候选回收分区中,筛选出回收收益最高的分区添加到 CSet 中。
候选老年代分区的 CSet 准入条件,可以通过活跃度阈值 -XX:G1MixedGCLiveThresholdPercent (默认85%)进行设置,从而拦截那些回收开销巨大的对象;同时,每次混合收集可以包含候选老年代分区,可根据 CSet 对堆的总大小占比 -XX:G1OldCSetRegionThresholdPercent (默认10%) 设置数量上限。
由上述可知,G1 的收集都是根据 CSet 进行操作的,年轻代收集与混合收集没有明显的不同,最大的区别在于两种收集的触发条件。
记忆集 RSet
记忆集 RSet 是一种抽象概念,记录对象在不同代际之间的引用关系,目的是为了加速垃圾回收的速度。JVM 使用根对象引用的收集算法,即从根集合出发,标记所有存活的对象,然后遍历对象的每一个字段继续标记,直到所有的对象标记完毕。在分代GC中,我们知道新生代和老生代处于不同的收集阶段,如果还是按照这样的标记方法,既不合理也没必要。假设我们只收集新生代,我们把老生代全部标记,但是并没有收集老生代,浪费了时间。同理,在收集老生代时有同样的问题。当且仅当,我们要进行Full GC才需要做全部标记。所以算法设计者做了这样的设计,用一个 RSet 记录从非收集部分指向收集部分的指针的集合,而这个集合描述对象的引用关系。