当内存分配的时候,剩余的空间不能满足要分配的对象时就会优先触发新生代回收(Young GC,YGC)。G1的 YGC 收集的内存是不固定的,每次回收的内存可能并不相同,即每次回收的分区数目是不固定的,但是每一次 YGC 都是收集所有的新生代分区,所以每一次 GC 之后都会调整新生代分区的数目。
YGC 简述
完全年轻代 GC 是只选择年轻代区域(Eden/Survivor)进入回收集合(Collection Set,简称CSet)进行回收的模式。新创建的对象分配至 Eden 区域,当 Eden 区域内存耗尽时触发 YGC,将选择的年轻代区域内标记存活的对象移动至 Survivor 区,达到晋升年龄的就晋升到老年代区域,然后清空原区域。
下面是一个完全年轻代GC过程的简单示意图:
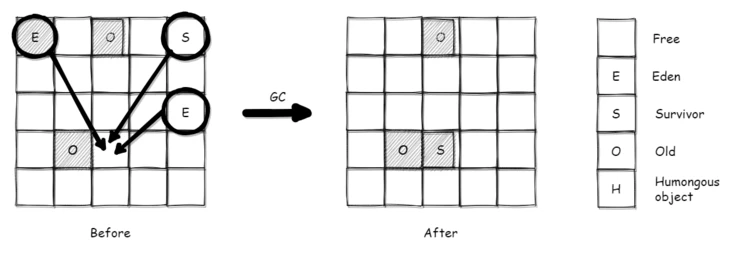
YGC 算法过程
当 JVM 无法将新对象分配到 Eden 区域时,会触发年轻代的垃圾回收(年轻代垃圾回收是完全暂停的,虽然部分过程是并行,但暂停和并行并不冲突)。也会称为“evacuation pause”。
STW
STW: Stop The World
进行收集之前需要 STW。
选择收集集合
选择收集集合: Choose CSet
G1会在遵循用户设置的 GC 暂停时间上限的基础上,选择一个最大年轻带区域数,将这个数量的所有年轻代区域作为收集集合。
如下图所示,此时 A/B/C 三个年轻代区域都已经作为收集集合,区域A中的 A 对象和区域 B 中的 E 对象,被 ROOTS 直接引用。
图上为了简单,将RS直接引用到对象,实际上 RS 引用的是对象所在的 CardPage
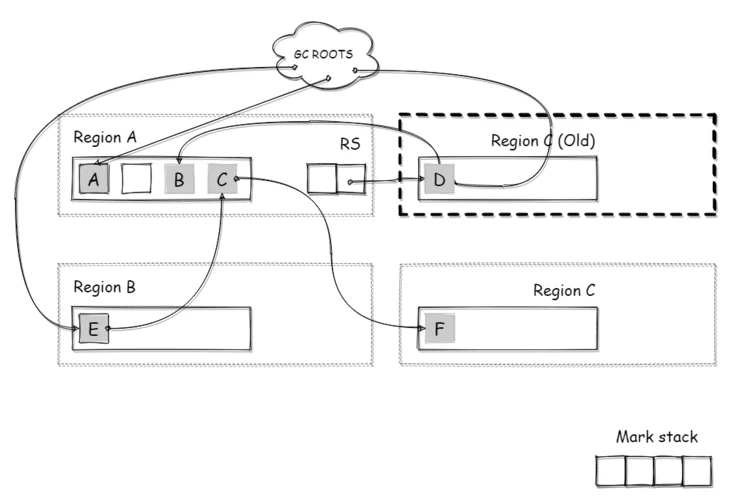
(并行)根处理
(并行)根处理: Root Scanning
接下来,需要从 GC ROOTS 遍历,查找从 ROOTS 直达到收集集合的对象,移动他们到 Survivor 区域的同时将他们的引用对象加入标记栈。
如下图所示,在根处理阶段,被 GC ROOTS 直接引用的 A/E 两个对象直接被复制到了 Survivor 区域 M,同时 A/E 两个对象所引用路线上的所有对象,都被加入了标记栈(Mark Stack),这里包括 E->C->F,这个 F 对象也会被加入标记栈中。
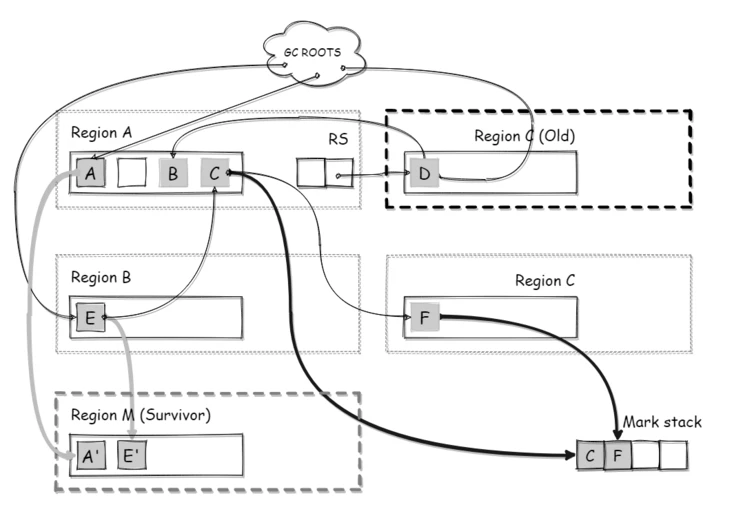
(并行)RSet扫描
(并行)RSet扫描: Scan RS
将 RSet 作为 ROOTS 遍历,查找可直达到收集集合的对象,移动他们到 Survivor 区域的同时将他们的引用对象加入标记栈。
在 RSet 扫描之前,还有一步更新 RSet(Update RS)的步骤,因为 RSet 是先写日志,再通过一个 Refine 线程进行处理日志来维护 RSet 数据的,这里的更新 RSet 就是为了保证 RSet 日志被处理完成,RSet 数据完整才可以进行扫描
如下图所示,老年代区域 C 中引用年轻代 A 的这个引用关系,被记录在年轻代的 RSet 中,此时遍历这个 RS。由于老年代 C 区域中 D 对象在 OHR 并不包含在 CSet 中,因此不处理,将其引用的年轻代 A 中的 B 对象移动到 Survivor 区域,并将年轻代 A 中的 B 对象的引用对象添加到标记栈中。
当 D 对象不处理,将 B 对象添加到标记栈?还是将 D 对象移动到 Survivor 后续引用添加到标记栈?需要追源码确认。
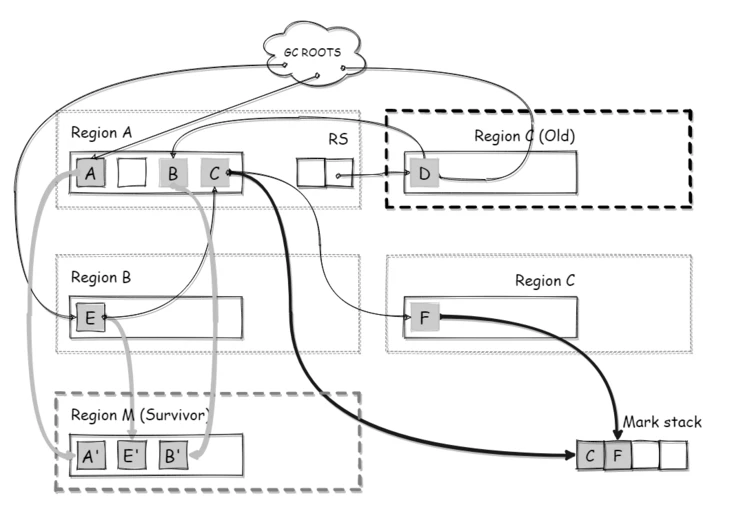
(并行)复制
(并行)复制: Evacuation / Object Copy
遍历上面的标记栈,将栈内的所有所有的对象移动至 Survivor 区域(其实说是移动,本质上还是复制)。
如下图所示,标记栈中记录的 C/F/B 对象被移动到 Survivor 区域中
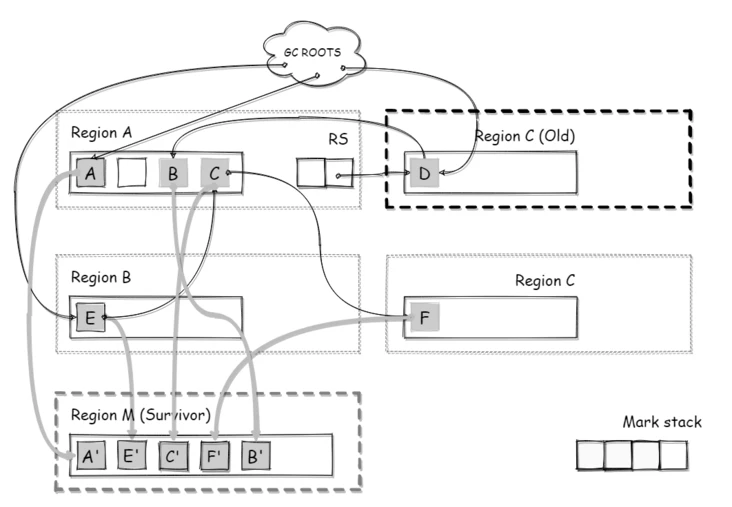
当对象年龄超过晋升的阈值时,对象会直接移动到老年代区域,而不是 Survivor 区域。
Redirty
Redirty 的目的就是为了重构 RSet,保证引用关系的正确性。我们发现因为对象发生了复制,此时 老年代 C 区域中 D 对象指向年轻代 M 区域的 B 对象,但 RSet 的引用还没有变化,所以需要重构 RSet。
RSet 引用没有变化,此时 Region A 的 RSet 的存储状态是啥?RSet 的结构是什么?我并不清楚。
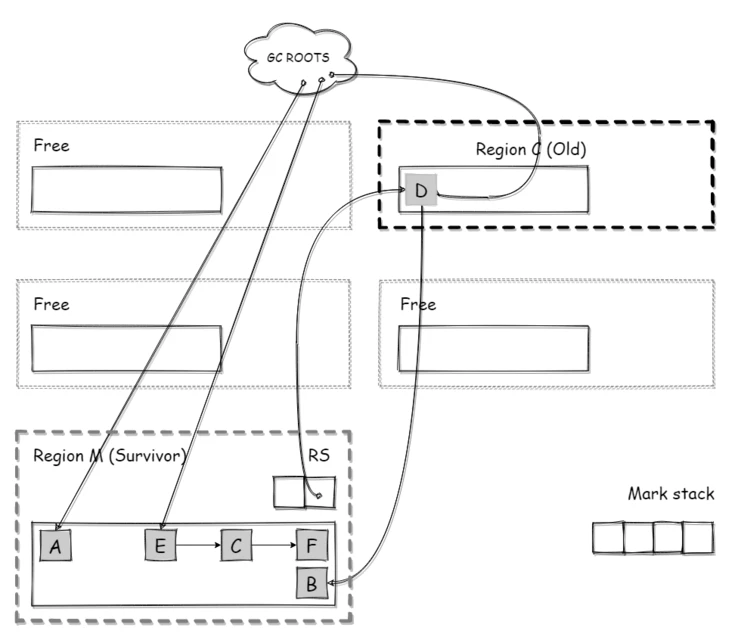
释放空间
Clear CT(清理Card Table),Free CSet(清理回收集合),清空移动前的区域添加到空闲区等等,这些操作一般耗时都很短。
YGC 过程日志
3.378: [GC pause (G1 Evacuation Pause) (young), 0.0015185 secs]
# JVM启动后的相对时间 3.378
# 进行收集的类型 YoungGC
# 收集耗费的时间 0.0015185 secs
[Parallel Time: 0.7 ms, GC Workers: 4]
# 并行收集任务在运行过程中引发的 STW(Stop The World)时间,从新生代垃圾收集开始到最后一个任务结束,共花费 0.7 ms
[GC Worker Start (ms): Min: 3378.1, Avg: 3378.3, Max: 3378.6, Diff: 0.5]
# Min 最早开始的线程时间 Max 最晚开始时间 Avg 平均开始时间 Diff 最早最晚时间差
# 理想情况下,希望他们几乎是同时开始,即 diff 趋近于 0。
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.6]
# 根扫描,包含所有强引用根,类型如下:
# 1. Java根:Thread、JNI、CLDG
# 2. JVM根: StringTable、Universe、JNI Handles、ObjectSynchronizer、
# FlatProfiler、Management、SystemDictionary、JVMTI
# 还会扫描 CodeCache Roots 处理 RSet 时的统计值,包含下面的:
# UpdateRS、ScanRS 和 Code Root Scan
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
# 每个分区都有自己的 RSet,用来记录其他分区指向当前分区的指针,如果 RSet 有更新,
# G1 中会有一个 post-write barrier 管理跨分区的引用——新的被引用的 card 会被标记
# 为 dirty,并放入一个日志缓冲区,如果这个日志缓冲区满了会被加入到一个全局的缓冲区,
# 在 JVM 运行的过程中还有线程在并发处理这个全局日志缓冲区的 dirty card。
# 这个是 GC 线程更新 RSet 的时间花费,且区别于在 Refine 里面处理 RSet 的时间,该
# 过程表示允许垃圾收集线程处理本次垃圾收集开始前没有处理好的日志缓冲区,这可以确保当前
# 分区的RSet是最新的。
[Processed Buffers: Min: 0, Avg: 0.2, Max: 1, Diff: 1, Sum: 1]
# 表示在 Update RS 这个过程中处理多少个日志缓冲区
[Scan RS (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.3]
# 扫描每个新生代分区的RSet并找出有多少指向当前分区的引用来自CSet
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0
# 扫描代码中的 root节点(局部变量)花费的时间
[Object Copy (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
# 在疏散暂停期间,所有在 CSet 中的分区必须被转移疏散,Object Copy 就负责将当前分区中存活的对象拷贝到新的分区
[Termination (ms): Min: 0.0, Avg: 0.2, Max: 0.3, Diff: 0.3, Sum: 0.7]
# 当一个垃圾收集线程完成任务时,它就会进入一个临界区,并尝试帮助其他垃圾线程完成任务
#(steal outstanding tasks),min 表示该垃圾收集线程什么时候尝试 terminatie,
# max表示该垃圾收集回收线程什么时候真正 terminated
[Termination Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 4]
# 如果一个垃圾收集线程成功盗取了其他线程的任务,那么它会再次盗取更多的任务或
# 再次尝试 terminate,每次重新 terminate 的时候,这个数值就会增加
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
# 并行处理时其他处理花费的时间,基本都是释放资源
[GC Worker Total (ms): Min: 0.1, Avg: 0.4, Max: 0.6, Diff: 0.6, Sum: 1.8]
# 并行GC花费的时间
[GC Worker End (ms): Min: 3378.7, Avg: 3378.7, Max: 3378.8, Diff: 0.1]
# GC线程结束的时间信息,min表示最早结束的垃圾收集线程结束时该JVM启动后的时间;
# max表示最晚结束的垃圾收集线程结束时该JVM启动后的时间。
# 理想情况下,你希望它们快速结束,并且最好是同一时间结束。
# 下面是其他任务部分
[Code Root Fixup: 0.0 ms]
# 释放用于管理并行垃圾收集活动的数据结构,应该接近于0,该步骤是线性执行的
[Code Root Purge: 0.0 ms]
# 代码扫描属于并行部分,包含了代码的调整和回收
[Clear CT: 0.1 ms]
# 清除 Card Table 的时间
[Other: 0.7 ms]
[Choose CSet: 0.0 ms]
# 选择要进行回收的分区放入CSet(G1选择的标准是垃圾最多的分区优先,也就是存活对象率
# 最低的分区优先)
[Ref Proc: 0.5 ms]
# 引用处理,发现哪些引用可以被清除(soft、weak、final、phantom、JNI等等)
[Ref Enq: 0.0 ms]
# 遍历所有的引用,将不能回收的放入pending列表
[Redirty Cards: 0.1 ms]
# 在回收过程中被修改的 card 将会被重置为 dirty
[Humongous Register: 0.0 ms]
# JDK8新特性可以让巨型对象在新生代收集的时候被回收,默认开启
# 通过 G1ReclaimDeadHumongousObjectsAtYoungGC 设置
[Humongous Total: 2]
# 有两个大对象
[Humongous Candidate: 0]
# 可回收大对象0个
[Humongous Reclaim: 0.1 ms]
# 做下列任务的时间:确保巨型对象可以被回收、释放该巨型对象所占的分区,重置分区类型,
# 并将分区还到 free 列表,并且更新空闲空间大小
[Free CSet: 0.1 ms]
# 将要释放的分区还回到 free 列表
[Eden: 304.0M(304.0M)->0.0B(304.0M) Survivors: 2048.0K->2048.0K Heap: 304.5M(512.0M)->529.0K(512.0M)]
# 垃圾回收内存的对比
[Times: user=0.01 sys=0.00, real=0.00 secs]
# user 垃圾收集线程在新生代垃圾收集过程中消耗的CPU时间,这个时间跟垃圾收集线程的个数有关,可能会比 real time 大很多
# sys 内核态线程消耗的CPU时间
# real 本次垃圾收集真正消耗的时间在GC日志的最后稍微提一下日志为什么需要对Code Root扫描和调整?
Java 代码在满足一定条件之后(比如执行多次),JIT 编译器会把这样的代码进行编译,这样的代码中有直接访问 OOP 对象的语句,因此当对象发生移动之后,必须重新调整代码中对象的引用位置,所以需要对Code Root进行扫描、调整,如果能释放的话还会进行释放。
并发 GC 过程日志
需要注意的是,如果 GC 日志开头有 [GC pause (G1 Humongous Allocation) (young) (initial-mark) 表示这次的 YGC 发生后,就会开始并发标记。Concurrent GC 触发条件有很多,但是做的工作都相同,它的日志如下图所示:
- 标志着并发垃圾收集阶段的开始:
- GC pause(G1 Evacuation Pause)(young)(initial-mark):为了充分利用 STW 的机会来 trace 所有可达(存活)的对象,initial-mark 阶段是作为新生代垃圾收集中的一部分存在的。initial-mark 设置了两个 TAMS(top-at-mark-start)变量,用来区分存活的对象和在并发标记阶段新分配的对象。在 TAMS 之前的所有对象,在当前周期内都会被视作存活的。
- 表示第并发标记阶段做的第一个事情:根分区扫描
- GC concurrent-root-region-scan-start:根分区扫描开始,根分区扫描主要扫描的是新的 survivor 分区,找到这些分区内的对象指向当前分区的引用,如果发现有引用,则做个记录;
- GC concurrent-root-region-scan-end:根分区扫描结束,并标明耗时;
- 表示并发标记阶段
- GC Concurrent-mark-start:并发标记阶段开始。(1)并发标记阶段的线程是跟应用线程一起运行的,不会 STW,所以称为并发;并发标记阶段的垃圾收集线程,默认值是 Parallel Thread 个数的 25%,这个值也可以用参数
-XX:ConcGCThreads设置;(2)trace 整个堆,并使用位图标记所有存活的对象,因为在 top TAMS 之前的对象是隐式存活的,所以这里只需要标记出那些在 top TAMS 之后、阈值之前的;(3)记录在并发标记阶段的变更,G1 这里使用了 SATB 算法,该算法要求在垃圾收集开始的时候给堆做一个快照,在垃圾收集过程中这个快照是不变的,但实际上肯定有些对象的引用会发生变化,这时候G1使用了 pre-write barrier 记录这种变更,并将这个记录存放在一个SATB缓冲区中,如果该缓冲区满了就会将它加入到一个全局的缓冲区,同时G1有一个线程在并行得处理这个全局缓冲区;(4)在并发标记过程中,会记录每个分区的存活对象占整个分区的大小的比率; - GC Concurrent-mark-end:并发标记阶段结束,并标明耗时;
- GC Concurrent-mark-start:并发标记阶段开始。(1)并发标记阶段的线程是跟应用线程一起运行的,不会 STW,所以称为并发;并发标记阶段的垃圾收集线程,默认值是 Parallel Thread 个数的 25%,这个值也可以用参数
- 重新标记阶段(GC Remark),会 Stop the World
- Finalize Marking:Finalizer列表里的Finalizer对象处理,会标明耗时时间;
- GC ref-proc:引用(soft、weak、final、phantom、JNI等等)处理,会标明耗时时间;
- Unloading:类卸载,会标明耗时时间;
- 除了前面这几个事情,这个阶段最关键的结果是:绘制出当前并发周期中整个堆的最后面貌,剩余的 SATB 缓冲区会在这里被处理,所有存活的对象都会被标记;
- 清理阶段(GC Cleanup),也会 Stop the World
- 计算出最后存活的对象:标记出 initial-mark 阶段后分配的对象;标记出至少有一个存活对象的分区;
- 为下一个并发标记阶段做准备,previous 和 next 位图会被清理;
- 没有存活对象的老年代分区和巨型对象分区会被释放和清理;
- 处理没有任何存活对象的分区的 RSet;
- 所有的老年代分区会按照自己的存活率(存活对象占整个分区大小的比例)进行排序,为后面的 CSet 选择过程做准备;
- 并发清理阶段
- GC concurrent-cleanup-start:并发清理阶段启动。完成第 5 步剩余的清理工作;将完全清理好的分区加入到二级 free 列表,等待最终还会到总体的 free 列表;
- GC concurrent-cleanup-end:并发清理阶段结束,会标明耗时时间
YGC 参数
ParallelGCThreads
ParallelGCThreads,默认值为 0,表示的是并行执行 GC 的线程个数。G1 可以根据 CPU 的个数自行推断线程数;GC 是 CPU 密集型的任务,通常来说线程个数不应该超过 CPU 核数,一般不用设置该值。这个参数的值的设置,跟 CPU 有关,如果物理 CPU 支持的线程个数小于 8,则最多设置为 8;如果物理 CPU 支持的线程个数大于 8,则默认值为 8 + ((N - 8) * 5/8)。在非常大的 CPU 或多 CPU 系统上,额外线程的收益递减,因此线性缩放因子减少到 8 个内核以上。
MaxTenuringThreshold
在对新生代收集的过程中,如果对象在 YGC 发生了一定次数之后还存活,这意味着对象有很大的概率存活更长的时间,所以通常会把它晋升到老生代。而这个次数可以通过参数 MaxTenuringThreshold 控制,默认值是 15,即发生 15 次 YGC 后,对象仍然存活,存活的对象会晋升到老生代。这个值最大只能是 15。减小该值可以会把对象更早地提升到老生代。这个参数并非能达到绝对控制,比如晋升失败会导致对象原地不动,如果 survival 区不够大,可能直接放到老年代。
G1RsetScanBlockSize
参数 G1RsetScanBlockSize,默认值为 64,指扫描 Rset 时一次处理的量,其目的是为了加速处理速度;如果计算能力较强,可以增大该值。
SurvivorRatio
参数 SurvivorRatio,默认值为 8,指 Eden 和 Survivor 分区之间的比例;减小该值,将导致 Survivor 分区大小变大,G1 中并不会因为增大该值直接导致 Eden 变小,Eden 是根据 GC 的时间来预测的。
TargetSurvivorRatio
参数 TargetSurvivorRatio,默认值为 50,表示期望 Survivor 的大小。增大该值,则用于下一次 Survivor 的空间变大,晋升到 Old 分区的概率会减少。
ParGCArrayScanChunk
参数 ParGCArrayScanChunk,默认值为 50,表示当一个对象数组的长度超过这个阈值之后,不会一次性遍历它,而是分多次处理,每次的长度都是这个阈值,只有最后一次处理的长度在 ParGCArrayScanChunk 和 2×ParGCArrayScanChunk 之间。减小该值会减少栈溢出的情况,增大该值效率会略有提升。
ResizePLAB
参数 ResizePLAB,默认值为 true,表示在垃圾回收结束后会根据内存的使用情况来调整 PLAB 的大小,但是目前 G1 中的 GC 线程在不同的阶段如 Evac,引用处理等都会涉及内存分配,所以在 PLAB 的调整上是根据整体内存的使用情况进行的,这个成本比较高。因此在一些基准测试中发现禁止该选项可能有更好的效果,但这并不一定也适用于你的应用,关于 PLAB 效率和性能有一个 bug,如果使用该选项也可以进行调整并测试。关于 PLAB 在 JDK9 等后面的版本中会引入相关参数。
YoungPLABSize
参数 YoungPLABSize,默认值为 4096,是新生代 PLAB 缓存大小。在 32 位 JVM 中 PLAB 为 16KB,在 64 位 JVM 中为 32KB,表示对象从 Eden 复制到 Survivor 时,每次请求 16KB 作为分配缓存,提高分配效率。增大该值可以提高分配的效率,但是可能增加内存碎片,同时可能使得S分区很快耗尽;实际调优中可以尝试先减小该值。
OldPLABSize
参数 OldPLABSize,默认值为 1024,指老生代 PLAB 缓存大小。在 32 位JVM中 PLAB 为 4KB,64 位 JVM 中为 8KB,表示对象从 Eden 复制到 Old 时,每次请求 4KB 作为分配缓存,提高分配效率。增大该值可以提高分配的效率,但是可能增加内存碎片;通常来说 Old 分区空间更大,实际调优中可以尝试先增大该值。
ParallelGCBufferWastePct
参数 ParallelGCBufferWastePct,默认值为10,表示对象从 Eden 到 Survivor 或者 Old 区的时候,如果剩余空间小于这个比例,且不能分配新对象时可以丢弃这个 PLAB 块,申请一个新的 PLAB,所以这个值越大分配的效率越高,内存浪费也越严重;这个参数和 TLABRefillWasteFraction 类似。
G1EagerReclaimHumongousObjects
参数 G1EagerReclaimHumongousObjects,默认值为true,表示在 YGC 时收集大对象;有应用测试发现 YGC 时回收大对象会引起性能问题,如果遇到可以关闭选项。
G1EagerReclaimHumongousObjectsWithStaleRefs
参数 G1EagerReclaimHumongousObjectsWithStaleRefs,默认值为 true,表示在 YGC 时判定哪些大对象分区可以收集,如果为 true 表示当时大对象分区 RSet 的引用关系数小于 G1RSetSparseRegionEntries(默认值为0)可以尝试收集,如果为 false 则只有 RSet 中的引用数为 0 才会收集。