当对象分配失败,会进入到 Evac 失败过程,在 GC 日志详情中会打印相关信息。发生失败一般意味着不能继续分配,此时需要做两件事:
- 处理失败
- 再次尝试分配,仍不成功,进行Full GC(FGC)
Evac 失败
假设在根处理时对象 3 复制发生失败,不能复制。则把对象 3 里面的 Pointer 标记指向自己,形成自引用。然后继续向下处理,注意这里的处理类似于跳过失败的对象,然后进行正常路径的处理。只不过需要一个额外的动作,即把对象放入到一个特殊的 dirty card 队列中。
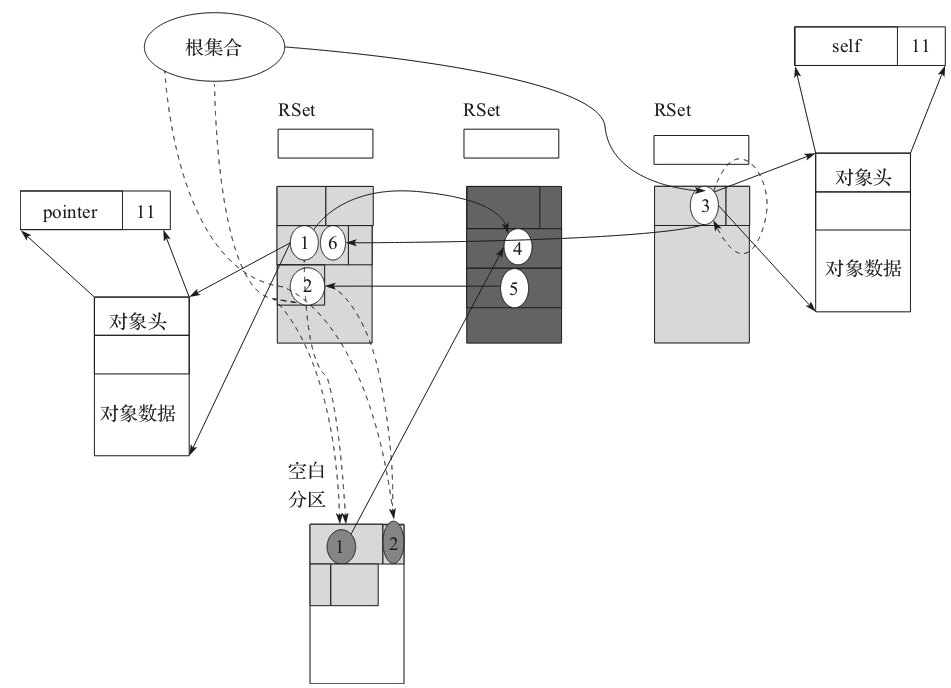
继续向下即处理 RSet,处理RSet时发现对象 2 已经成功复制,所以正常更新指针,即用对象 2 的新地址更新对象 5 的 field。假设之后对象都不能成功复制,最终的内存布局如下图所示。
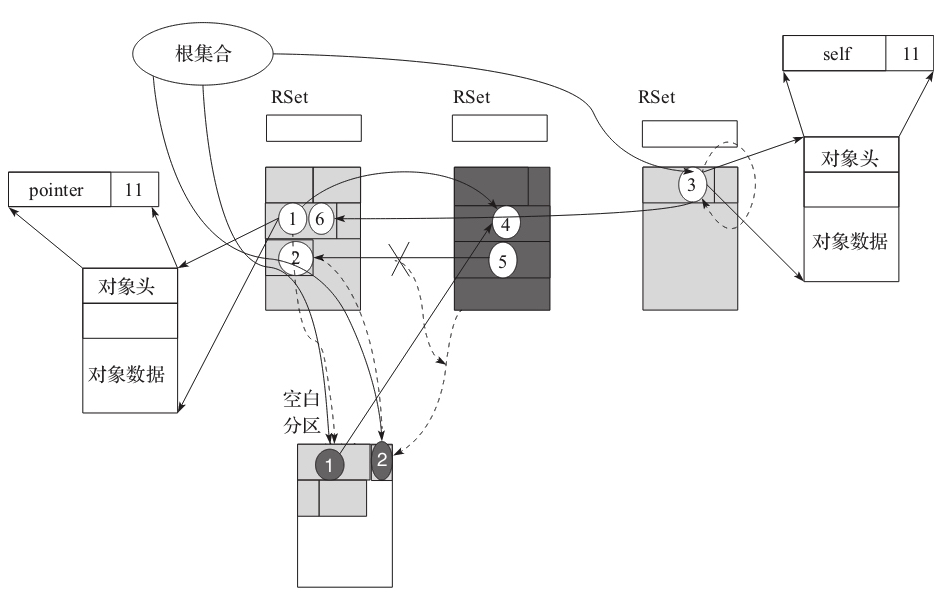
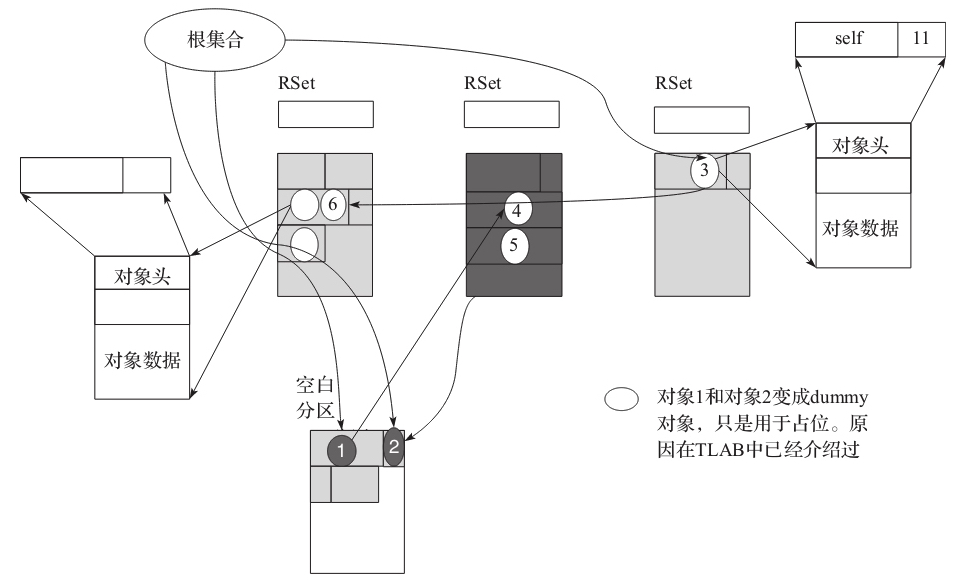
接下来就是 Evac 特有的步骤,删除自引用。自引用对象都应该是活跃对象。同时对于已经被复制的对象需要把他们变成 dummy 对象,因为这个时候他们已经可以被回收了。
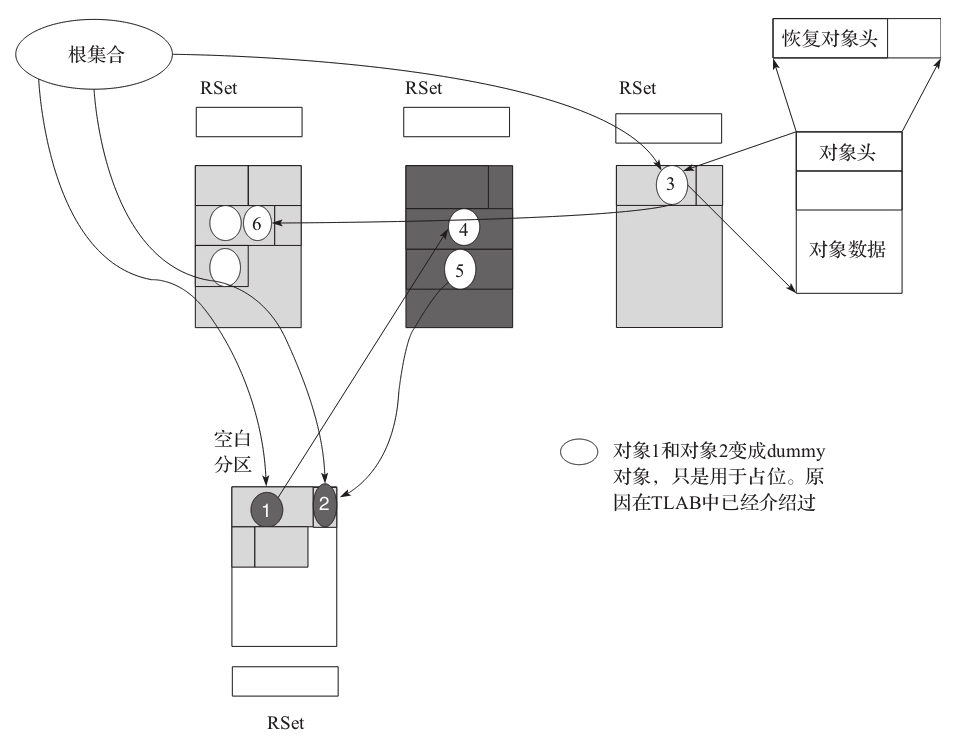
最后一步也是执行 Redirty 重构整个 RSet,如下图所示,确保引用的正确性。
FGC 算法过程
串行 FGC
Evac 失败后会进入到 FGC,在 JDK 10 之前 FGC 都是串行回收。在串行回收之前需要做一些预处理,主要有停止并发标记、停止增量回收等动作。串行回收采用的标记清除算法,主要分为 4 步:
- 标记活跃对象
- 计算新对象的地址
- 把所有的引用都更新到新的地址上
- 移动对象
- 后处理
标记活跃对象
与 YGC 标记类似,且是串行执行的。
以下是标记活跃对象的处理内容:
- 所有的根要顺序处理(处理对象的时候会把对象对应的 klass 对象也标记处理)
- 对 reference 对象的标记处理
- 对系统字典、符号表标记、编译代码、klass 做卸载处理。(卸载:从全局对象中删除无用对象,但不释放)
下图是 FGC 开始之前的内存情况
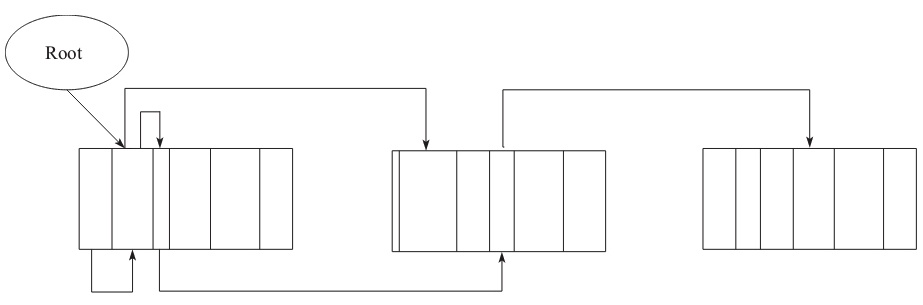
在标记完活跃对象后,内存情况如下图:
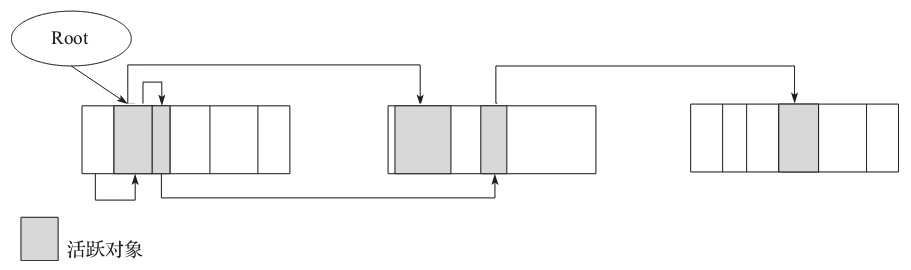
计算新对象地址
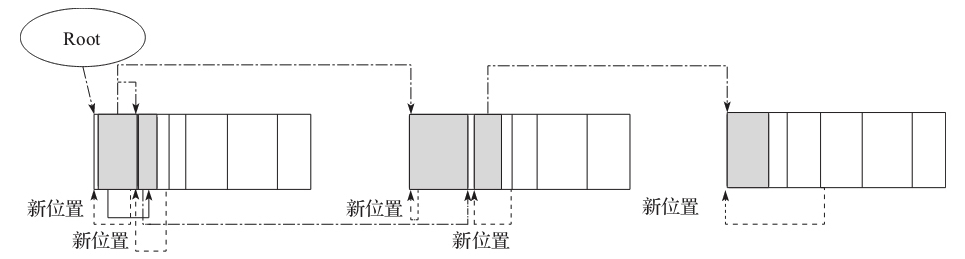
第二步最主要的工作就是找到每个对象应该在什么位置。从分区的底部开始扫描,同时设置 compact top 也为底部,当对象被标记,即活跃时,把对象的 oop 指针设置为 compact top,这个值就是对象应该所处的位置。
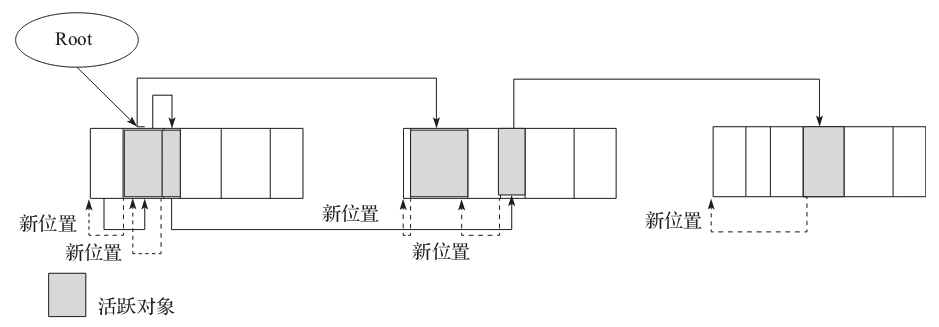
更新引用对象的地址
在上一步中,我们找到了对象的新位置,然后通过对象头里面的指针指向新位置。这一步最主要的工作就是遍历活跃对象,然后把活跃对象和活跃对象中的引用更新到新位置。
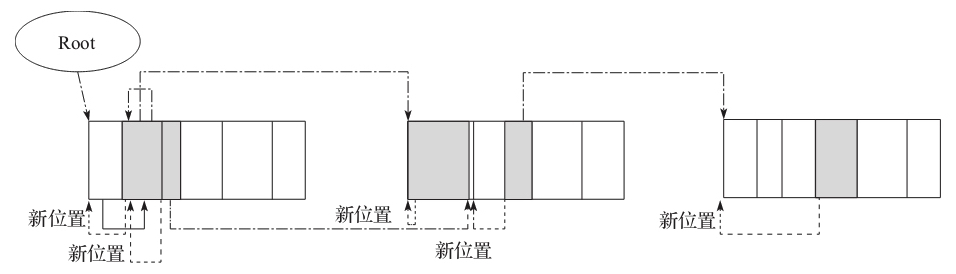
虚线指针表示对象的新位置
点划线指针表示对象引用所在的新位置
移动对象完成压缩
最后一步就是完成空间的压缩。遍历时必须从前向后依次开始,否则数据会被破坏。
复制之后,通过双点划指针还是可以有效地访问对象,而虚线指针变成无用的。
后处理
在第四步压缩结束以后,实际上我们看到分区并没有发生调整,仅仅是把已经死亡的对象回收,而活跃的对象仍然保留在本分区内。所以还需要进行后处理,下面是几个主要的步骤:
尝试调整整个堆空间的大小
根据GC发生后已经使用的内存除以期望的占比得到期望的空间大小,然后利用期望值和实际值的比较来判断是否需要扩展或者收缩堆空间。扩展堆空间我们在前面已经介绍,这里稍微提一下收缩空间,收缩主要发生的动作就是把空闲分区标记为uncommit,用于后续分配。
遍历堆,重构RSet
因为所有的分区里面的对象位置都发生了变化,我们在第三步的时候也把对象位置变化的指针都更新了,但是这里还有一个重要的事情,就是重构 RSet,否则下一次发生 GC 就会丢失根集合,导致回收错误。重构 Rset 主要通过 ParRebuildRSTask 完成,对每一个分区根据对象的引用关系重构 RSet。
清除 Dirty Card 队列,并把所有的分区都认为是 Old 分区
最后记录各种信息,同时会调整 YGC 的大小,重建Eden,用于下一次回收。
并行 FGC
在 JDK 10 以后,G1 的 FGC 也被优化为可并行执行的过程。并行调用可以分为:
- 收集前处理(保存一些信息,如对象头、偏向锁等)
- 并行收集
而并行收集的过程和串行 FGC 类似,分为以下四步:
- 并行标记活跃对象(从 Root Set 出发,并且还会对引用进行处理)
- 针对 C2 的优化(记录对象的派生关系,开始 GC 前先暂停更新)
- 并行准备压缩,找到对象的新位置
- 并行调整指针
- 并行压缩
- 后处理(恢复对象头等信息)
并行标记活跃对象
FGC 的并行标记类似于并发标记,
以下是标记活跃对象的处理内容:
- 从根出发,做并行标记。
- 对 reference 对象的标记处理
- 对系统字典、符号表标记、编译代码、klass 做卸载处理。(卸载:从全局对象中删除无用对象,但不释放)
计算对象的新地址
并行处理是针对每一个分区,计算对象的新地址。与串行 FGC 不一样的地方就是,串行处理中,每一个分区的有效对象都会移动到该分区的头部。而并行处理的时候,一个并发线程通常要处理多个分区,所以在计算对象的新地址时可以把这一批分区里面的对象进行压缩,这样就可能出现完全空闲的分区。
由于并行处理可能需要跨多个分区,所以引入了 G1FullGCCompactionPoint,就是为了记录单个 GC 线程在计算对象位置时所用的分区情况。这里需要提示的是,除了大对象,对象是不能垮分区存放。例如前面一个分区剩下 1KB,新的对象需要 2KB,此时这个分区就不能存放这个对象,分区里面的起始地址都是对象的起始地址,对象不能跨分区存放,否则在对分区进行遍历的时候问题就大了。
与串行处理一样,该步完成之后,每个对象头存储的都是新地址。
更新引用对象的地址
在上一步中,我们找到了所有对象的新位置,并通过对象头里面的指针指向新的位置。这一步最主要的工作就是从根集合出发遍历活跃对象,然后把活跃对象和活跃对象中的引用都更新到新的位置。
移动对象完成压缩
第二步中每个线程处理一部分分区,都已经计算好了对象的位置,这一步直接把对象复制到新的位置。
后处理
更新对象头等。
FGC 过程日志
如果堆内存空间不足以分配新的对象,或者是 Metasapce 空间使用率达到了设定的阈值,那么就会触发 Full GC——你在使用 G1 的时候应该尽量避免这种情况发生,因为 G1 的 Full GC 是单线程、会 Stop The World,代价非常高。
2021-09-24T09:56:34.055+0800: 47.663:
[Full GC (Allocation Failure) 11G->519M(12G), 2.8735228 secs]
# Full GC 的原因,图示里是 Allocation Failure
# Full GC 的耗时,图示里是接近 3s
[
Eden: 0.0B(12.0G)->0.0B(12.0G)
Survivors: 0.0B->0.0B
Heap: 12.0G(12.0G)->519.7M(12.0G)
],
[
Metaspace: 49287K->48778K(1093632K)
]FGC 参数
MinHeapFreeRatio
参数 MinHeapFreeRatio,这个值用于判断是否可以扩展堆空间,增大该值扩展概率变小,减小该值扩展几率变大。
MaxHeapFreeRatio
参数 MaxHeapFreeRatio,这个值用于判断是否可以收缩堆空间,增大该值收缩概率变小,减小该值收缩概率变大。
MarkSweepAlwaysCompactCount
参数 MarkSweepAlwaysCompactCount,默认值为 4,这个值表示经过一定次数的 GC 之后,允许当前区域空间中一定比例的空间用来将死亡对象当作存活对象处理,这里姑且将这些对象称为弥留对象,把这片空间称为弥留。这个比例由 MarkSweepDeadRatio 控制,默认值为 5,该参数的作用是加快FGC的处理速度。