Elasticsearch 是位于 Elastic Stack 核心的分布式搜索和分析引擎。Logstash 和 Beats 有助于收集、聚合和丰富您的数据并将其存储在 Elasticsearch 中。Kibana 使您能够以交互方式探索、可视化和分享对数据的见解,并管理和监控堆栈。Elasticsearch 是索引、搜索和分析魔法发生的地方。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch 都能以支持快速搜索的方式高效地存储和索引它。您可以超越简单的数据检索和聚合信息来发现数据中的趋势和模式。随着您的数据和查询量的增长,Elasticsearch 的分布式特性使您的部署能够随之无缝增长。
基本概念
在使用ES进行数据的索引和搜索时,会用到一些基本概念,下面分别进行介绍。
索引
在使用传统的关系型数据库时,如果对数据有存取和更新操作,需要建立一个数据表。相应地,在 ES 中则需要建立索引。用户的数据新增、搜索和更新等操作的对象全部对应索引。但是,ES 中的索引和 Lucene 中的索引不是一一对应的。ES 中的一个索引对应一个或多个 Lucene 索引,这是由其分布式的设计方案决定的。
注意:
- 索引名称不支持大写
- 索引名称最大支持 256 个字符长度
- 字段名称支持大写,但建议统一使用小写
文档
在使用传统的关系型数据库时,需要把数据封装成数据库中的一条记录,而在 ES 中对应的则是文档。ES 的文档中可以有一个或多个字段,每个字段可以是各种类型。用户对数据操作的最细粒度对象就是文档。ES 文档操作使用了版本的概念,即文档的初始版本为 1,每次的写操作会把文档的版本加 1,每次使用文档时,ES 返回给用户的是最新版本的文档。另外,为了减轻集群负载和提升效率,ES 提供了文档的批量索引、更新和删除功能。
字段
一个文档可以包含一个或多个字段,每个字段都有一个类型与其对应。除了常用的数据类型(如字符串型、文本型和数值型)外,ES 还提供了多种数据类型,如数组类型、经纬度类型和IP地址类型等。ES 对不同类型的字段可以支持不同的搜索功能。例如,当使用文本类型的数据时,可以按照某种分词方式对数据进行搜索,并且可以设定搜索后的打分因子来影响最终的排序。再如,使用经纬度的数据时,ES 可以搜索某个地点附近的文档,也可以查询地理围栏内的文档。在排序函数的使用上,ES 也可以基于某个地点按照衰减函数进行排序。
映射
建立索引时需要定义文档的数据结构,这种结构叫作映射。在映射中,文档的字段类型一旦设定后就不能更改。因为字段类型在定义后,ES 已经针对定义的类型建立了特定的索引结构,这种结构不能更改。借助映射可以给文档新增字段。另外,ES 还提供了自动映射功能,即在添加数据时,如果该字段没有定义类型,ES 会根据用户提供的该字段的真实数据来猜测可能的类型,从而自动进行字段类型的定义。
分片
在分布式系统中,为了能存储和计算海量的数据,会先对数据进行切分,然后再将它们存储到多台计算机中。这样不仅能分担集群的存储和计算压力,而且在该架构基础上进一步优化,还可以提升系统中数据的高可用性。在 ES 中,一个分片对应的就是一个 Lucene 索引,每个分片可以设置多个副分片,这样当主分片所在的计算机因为发生故障而离线时,副分片会充当主分片继续服务。索引的分片个数只能设置一次,之后不能更改。在默认情况下,ES 的每个索引设置为 5 个分片。
副分片
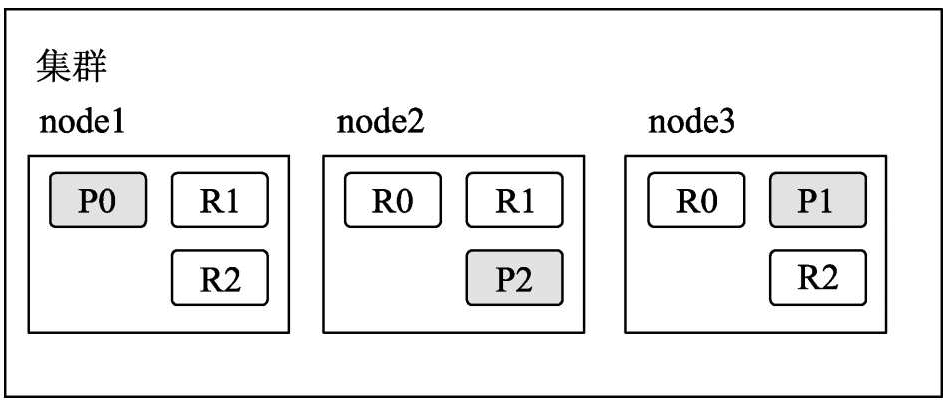
为了提升系统索引数据的高可用性并减轻集群搜索的负载,可以启用分片的副本,该副本叫作副分片,而原有分片叫作主分片。在一个索引中,主分片的副分片个数是没有限制的,用户可以按需设定。在默认情况下,ES 不会为索引的分片开启副分片,用户需要手动设置。副分片的个数设定后,也可以进行更改。一个分片的主分片和副分片分别存储在不同的计算机上,如下图所示为一个 3 个节点的集群,某个索引设置了 3 个主分片,每个主分片分配两个副分片。图中深色方框中的 P 表示该分片为主分片,R 表示该分片为副分片,P 和 R 后面的数字表示其编号。在极端情况下,当只有一个节点时,如果索引的副分片个数设置大于 1,则系统只分配主分片,而不会分配副分片。
DSLES
使用 DSL(Domain Specific Language,领域特定语言),来定义查询。与编程语言不同,DSL 是在特定领域解决特定任务的语言,它可以有多种表达形式,如我们常见的 HTML、CSS、SQL 等都属于 DSL。ES 中的 DSL 采用JSON进行表达,相应地,ES 也将响应客户端请求的返回数据封装成了 JSON形式。这样不仅可以简单明了地表达请求/响应内容,而且还屏蔽了各种编程语言之间数据通信的差异。
基本操作
官方文档参考如下 Elastic Search 官方文档
索引
创建索引
PUT /${index_name}
{
"settings": {
...
},
"mappings": {
...
},
"aliases": {
...
}
}示例:
PUT /test-20220906
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"time": {
"type": "date"
}
}
}
}删除索引
DELETE /${index_name}关闭索引
在有些场景下,某个索引暂时不使用,但是后期可能又会使用,这里的使用是指数据写入和数据搜索。这个索引在某一时间段内属于冷数据或者归档数据,这时可以使用索引的关闭功能。索引关闭时,只能通过 ES 的 API 或者监控工具看到索引的元数据信息,但是此时该索引不能写入和搜索数据,待该索引被打开后,才能写入和搜索数据。
POST /${index_name}/_close打开索引
索引关闭后,需要开启读写服务时可以将其设置为打开状态。
POST /${index_name}/_open索引别名
添加索引别名
POST /_aliases
{
"actions": [
{
"add": { //为索引january_log建立别名last_three_month
"index": "january_log",
"alias": "last_three_month"
}
}
]
}删除索引别名
POST /_aliases
{
"actions": [
{
"remove": { //为索引I删除别名A
"index": "I",
"alias": "A"
}
}
]
}应用场景
聚合多索引
将 A、B、C 三个索引的别名都设置为 S,查询 S 时会同时查询三个索引的结果。
需要指出的是,在默认情况下,当一个别名只指向一个索引时,写入数据的请求可以指向这个别名,如果这个别名指向多个索引,则写入数据的请求是不可以指向这个别名的。
当然,我们可以通过设置 is_write_index 属性来指定该索引可用于执行数据写入操作。
POST /_aliases
{
"actions": [
{
"add": { //设置january_log为索引别名last_three_month的数据写入转发对象
"index": "january_log",
"alias": "last_three_month",
"is_write_index":true
}
}
]
}在设置完成后,再向 last_three_month 写入文档,会将请求转发给索引 january_log。
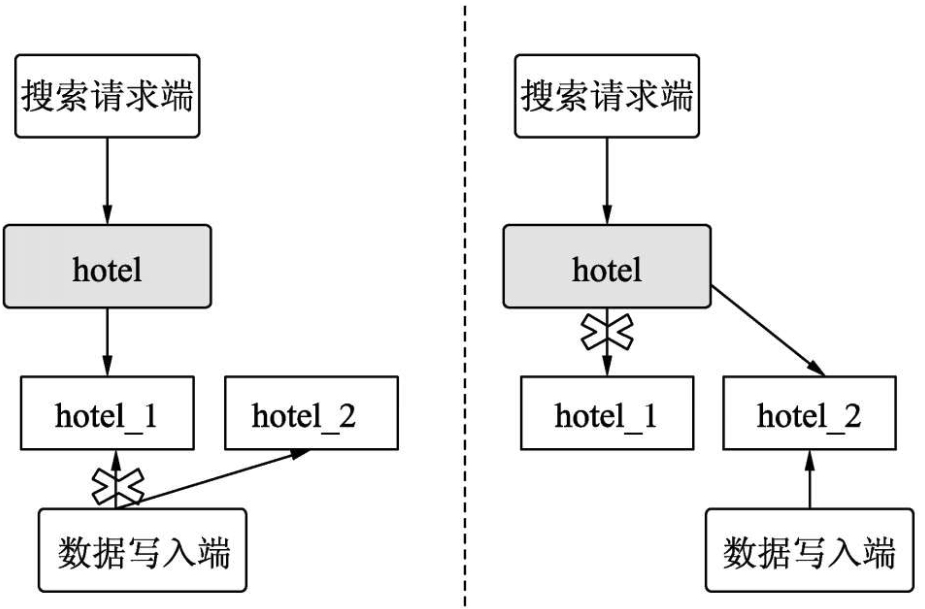
平滑切换
在某个索引被创建后,有些参数是不能更改的(如主分片的个数),但随着业务发展,索引中的数据增多,需要更改索引参数进行优化。我们需要平滑地解决该问题,既要更改索引的设置,又不能改变索引名称,这时就可以使用索引别名。
通过将新的索引应用新的配置,并且将别名设置成生产用的索引。
映射
在使用数据之前,需要构建数据的组织结构。这种组织结构在关系型数据库中叫作表结构,在 ES 中叫作映射。作为无模式搜索引擎,ES 可以在数据写入时猜测数据类型,从而自动创建映射。但有时 ES 创建的映射中的数据类型和目标类型可能不一致。当需要严格控制数据类型时,还是需要用户手动创建映射。
查看映射
GET /${index_name}/_mapping扩展映射
映射中的字段类型不可以修改,但字段可以扩展。
POST /hotel/_mapping
{
"properties": {
"tag": { //索引中新增字段tag,类型为keyword
"type": "keyword"
}
}
}基本的数据类型
keyword
不进行切分的字符串类型
在索引时,对keyword类型的数据不进行切分,直接构建倒排索引;在搜索时,对该类型的查询字符串不进行切分后的部分匹配。keyword类型数据一般用于对文档的过滤、排序和聚合。
一般使用 term 匹配(精准匹配)。
text
可进行切分的字符串类型
在索引时,可按照相应的切词算法对文本内容进行切分,然后构建倒排索引;在搜索时,对该类型的查询字符串按照用户的切词算法进行切分,然后对切分后的部分匹配打分。
一般使用 match 匹配(模糊匹配)。如果使用 term 搜索用于与文档进行精准匹配,由于 text 类型的数据在建立索引时 ES 就已经进行了切分并建立了倒排索引,因此使用 term 没有搜索到数据。
数值类型
ES 支持的数值类型有 long、integer、short、byte、double、float、half_float、scaled_float 和 unsigned_long 等。
一般使用 term 匹配和 range 匹配。
布尔类型
布尔类型使用boolean定义,用于业务中的二值表示,如商品是否售罄,房屋是否已租,酒店房间是否满房等。写入或者查询该类型的数据时,其值可以使用true和false,或者使用字符串形式的”true”和”false”。
日期类型
在 ES 中,日期类型的名称为 date。ES 中存储的日期是标准的 UTC 格式。
日期类型的默认格式为 strict_date_optional_time||epoch_millis。其中,strict_date_optional_time 的含义是严格的时间类型,支持 yyyy-MM-dd、yyyyMMdd、yyyyMMddHHmmss、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS 和 yyyy-MM-ddTHH:mm:ss.SSSZ 等格式,epoch_millis 的含义是从1970年1月1日0点到现在的毫秒数。
日期类型默认不支持 yyyy-MM-dd HH:mm:ss 格式,如果经常使用这种格式,可以在索引的 mapping 中设置日期字段的 format 属性为自定义格式。
PUT /hotel
{
"mappings": {
"properties": {
"create_time":{ //指定日期型字段的格式
"type":"date",
"format": "yyyy-MM-dd HH:mm:ss"
}
}
}
}复杂的数据类型
数组类型
ES 数组没有定义方式,其使用方式是开箱即用的,即无须事先声明,在写入时把数据用中括号 [] 括起来,由 ES 对该字段完成定义。
对象类型
地理类型
该类型的定义需要在 mapping 中指定目标字段的数据类型为 geo_point 类型。
多字段
针对同一个字段,有时需要不同的数据类型,这通常表现在为了不同的目的以不同的方式索引相同的字段。例如,在订单搜索系统中,既希望能够按照用户姓名进行搜索,又希望按照姓氏进行排列,可以在 mapping 定义中将姓名字段先后定义为 text 类型和 keyword 类型,其中,keyword 类型的字段叫作子字段,这样 ES 在建立索引时会将姓名字段建立两份索引,即 text 类型的索引和 keyword 类型的索引。
PUT /hotel_order
{
"mappings": {
"properties": {
"order_id": { //定义order_id字段类型为keyword
"type": "keyword"
},
"user_id": { //定义user_id字段类型为keyword
"type": "keyword"
},
"user_name": { //定义user_name字段类型为text
"type": "text",
"fields": { //定义user_name多字段
//定义user_name字段的子字段user_name_keyword,并定义其类型为keyword
"user_name_keyword": {
"type": "keyword"
}
}
}
}
}
} 文档
获取文档
根据ID获取文档内容
GET /test-20220906/_doc/1写入文档
单条写入
POST /${index_name}/_doc/${_id}
{
...
}批量写入
POST /_bulk //批量请求
//指定批量写入的索引
{"index": {"_index":"${index_name}"}}
//设定写入的文档内容
{…}
//指定批量写入的索引(也可以指定ID)
{"index":{"_index":"${index_name}", "_id": "1"}}
//设定写入的文档内容
{…} 请求体的第一行表示写入的第一条文档对应的元数据,其中,index_name 表示写入的目标索引,第2行表示数据体,第3行表示写入的第二条文档对应的元数据,第4行表示数据体。以此类推,在一次请求里可以写入多条数据。
更新文档
单条更新
POST /${index_name}/_update/${_id}
{ //需要更新的数据,在URL中指定文档_id …
}除了普通的 update 功能,ES 还提供了 upsert。upsert 即是 update 和 insert 的合体字,表示更新/插入数据。如果目标文档存在,则执行更新逻辑;否则执行插入逻辑。
POST /hotel/_update/001
{
"doc": {
"title": "好再来酒店",
"city": "北京",
"price": 659.45
},
"upsert": {
"title": "好再来酒店",
"city": "北京",
"price": 659.45
}
}批量更新
POST /_bulk //批量请求
//指定批量更新的索引和文档_id
{"update":{"_index":"${index_name}",”_id”:”${_id}”}}
//设定更新的文档内容
{“doc”:{ …} #JSON数据}
//指定批量更新的索引和文档_id
{"update":{"_index":"${index_name}",”_id”:”${_id}”}}
//设定更新的文档内容
{“doc”:{ …}#JSON数据} 条件更新
在索引数据的更新操作中,有些场景需要根据某些条件同时更新多条数据。
POST /${index_name}/_update_by_query
{
"query": { //条件更新的查询条件 … },
"script": { //条件更新的具体更新脚本代码 … }
}删除文档
单条删除
DELETE /${index_name}/_doc/${_id}批量删除
POST /_bulk
//批量删除文档,指定文档_id
{"delete":{"_index":"${index_name}",”_id”:”${_id}”}}
//批量删除文档,指定文档_id
{"delete":{"_index":"${index_name}",”_id”:”${_id}”}} 条件删除
POST /${index_name}/_delete_by_query
{ //删除文档的查询条件
"query": { … }
}