Linux 在访问外部存储器中的数据时,通常会使用文件系统来进行访问。
Linux 文件系统
Linux 能使用的文件系统不止一种,ext4、XFS、Btrfs 等不同的文件系统可以共存于 Linux 上。这些文件系统在外部存储器中的数据结构以及用于处理数据的程序各不相同。各种文件系统所支持的文件大小、文件系统本身的大小以及各种文件操作(创建、删除与读写文件等)的速度也不相同。但是,不管使用哪种文件系统,面向用户的访问接口都统一为下面这些系统调用。
- 创建与删除文件:
create()、unlink() - 打开与关闭文件:
open()、close() - 从已打开的文件中读取与写入数据:
read()、write() - 将已打开的文件移动到指定位置:
lseek() - 除了以上这些操作以外的依赖于文件系统的特殊处理:
ioctl()
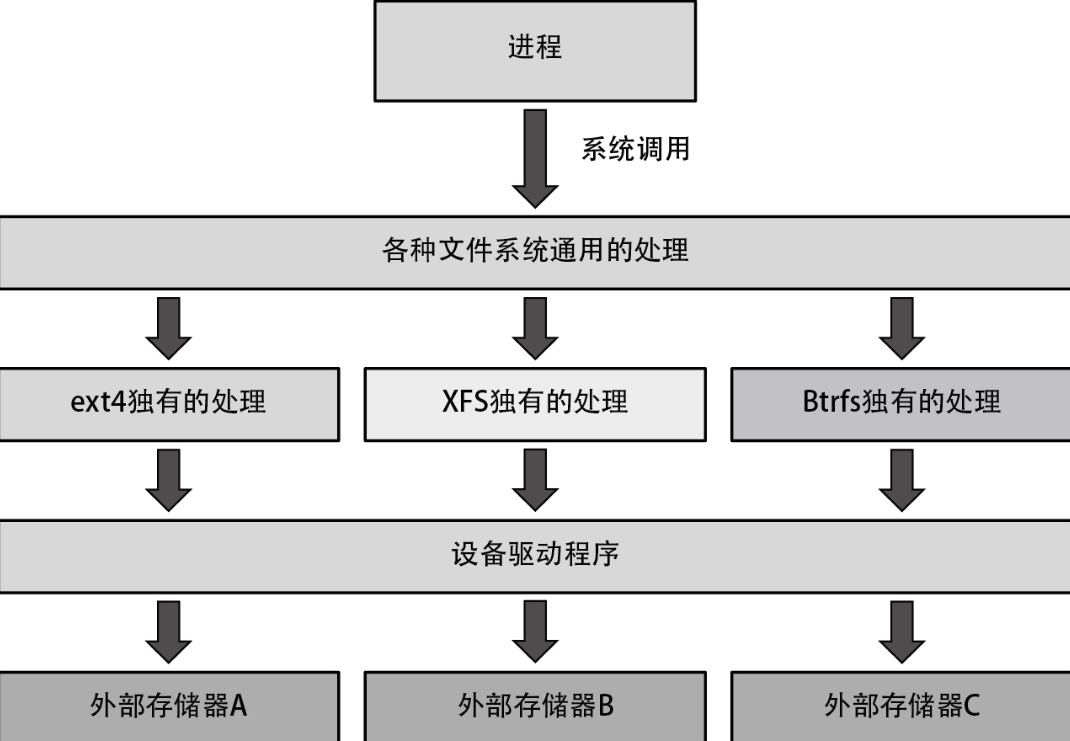
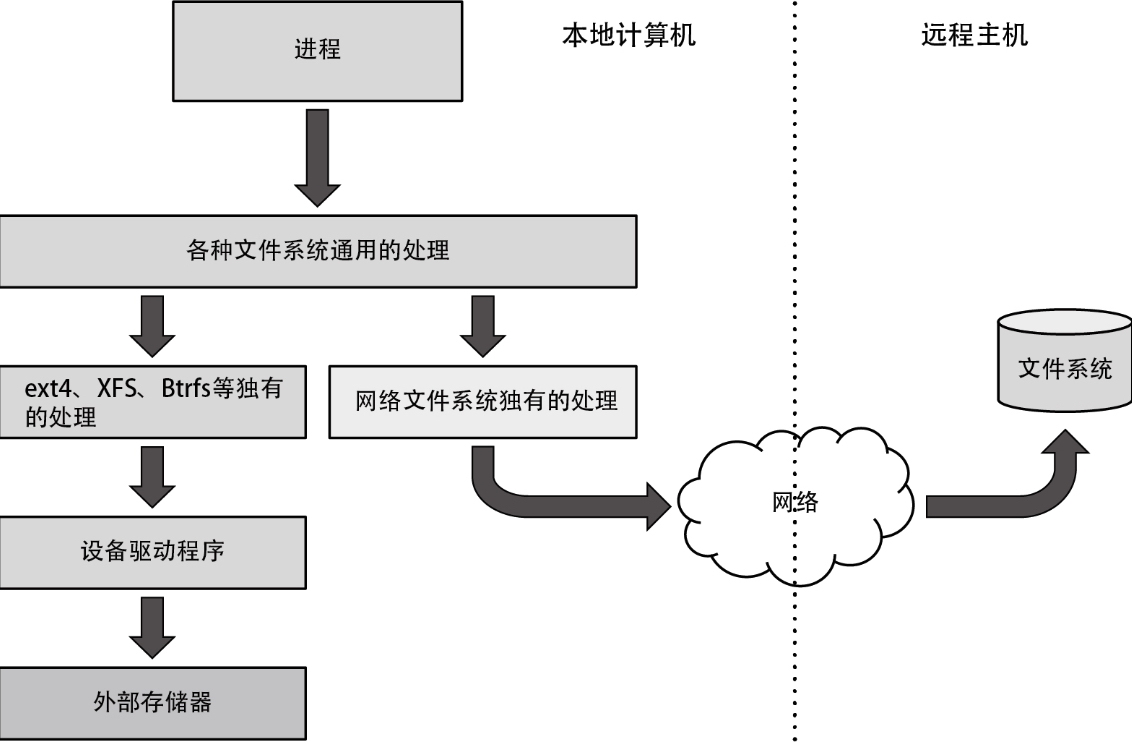
在请求这些系统调用时,将按照下列流程读取文件中的数据。
- 执行内核中的全部文件系统通用的处理,并判断作为操作对象的文件保存在哪个文件系统上。
- 调用文件系统专有的处理,并执行与请求的系统调用对应的处理。
- 在读写数据时,调用设备驱动程序执行操作。
- 由设备驱动程序执行数据的读写操作。
数据与元数据
文件系统上存在两种数据类型,分别是数据与元数据。
- 数据:用户创建的文档、图片、视频和程序等数据内容
- 元数据:文件的名称、文件在外部存储器中的位置和文件大小等辅助信息
另外,元数据分为以下几种。
- 种类:用于判断文件是保存数据的普通文件,还是目录或其他类型的文件的信息
- 时间信息:包括文件的创建时间、最后一次访问的时间,以及最后一次修改的时间
- 权限信息:表明该文件允许哪些用户访问
注意:通过 df 命令得到的文件系统所用的存储空间,不但包括大家在文件系统上创建的所有文件所占用的空间,还包括所有元数据所占用的空间。
容量限制
当系统被同时用于多种用途时,假如针对某一用途不限制文件系统的容量,就有可能导致其他用途所需的存储容量不足。为了避免这样的情况出现,可以通过磁盘配额(quota)功能来限制各种用途的文件系统的容量。
磁盘配额有以下几种类型。
- 用户配额:限制作为文件所有者的用户的可用容量。例如防止某个用户用光
/home目录的存储空间。ext4 与 XFS 上可以设置用户配额 - 目录配额:限制特定目录的可用容量。例如限制项目成员共用的项目目录的可用容量。ext4 与 XFS 上可以设置目录配额
- 子卷配额:限制文件系统内名为子卷的单元的可用容量。大致上与目录配额的使用方式相同。Btrfs 上可以设置子卷配额
文件系统不一致
只要使用系统,那么文件系统的内容就可能不一致。比如,在对外部存储器读写文件系统的数据时被强制切断电源的情况,就是一个典型的例子。
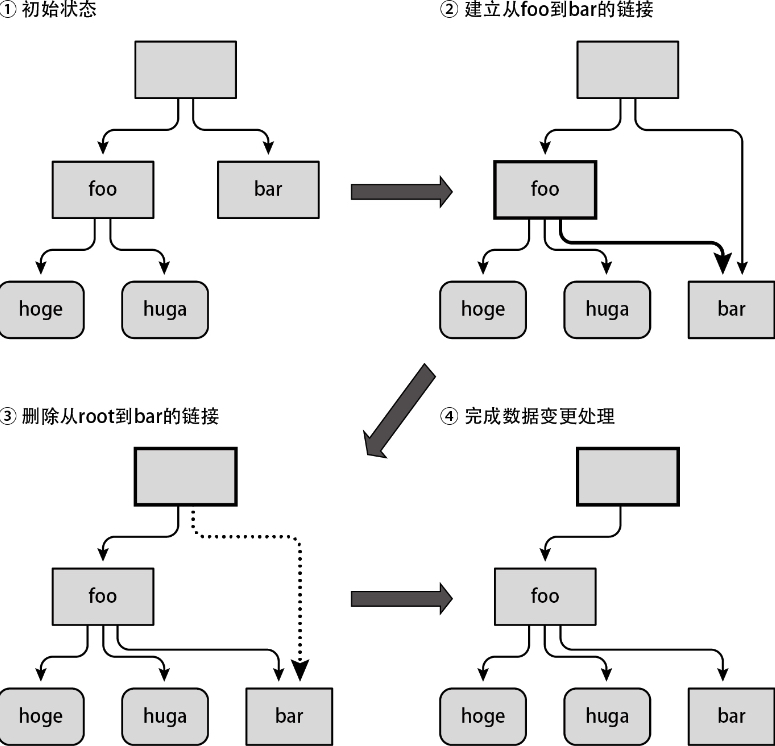
这一连串的操作是不可分割的,称为原子操作。这里,由于对外部存储器的读写操作一次只能执行一步,所以如果在第一次写入操作(foo文件的数据更新)完成后、第二次写入操作(root的数据更新)开始前中断处理,文件系统就会变成不一致的状态,如下图所示。
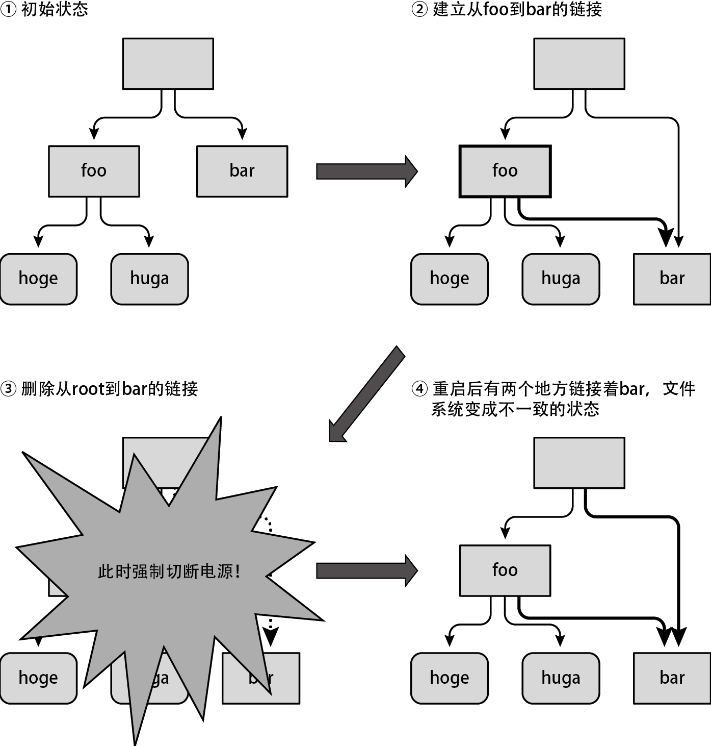
只要发生过这种不一致的状况,迟早会被文件系统检查出来。如果在挂载时检测到不一致,就会导致文件系统无法被挂载;如果在访问过程中检测到不一致,则可能会以只读模式重新挂载该文件系统,在最坏的情况下甚至可能导致系统出错。
目前,防止文件系统不一致的技术有很多,常用的是日志(journaling)与写时复制。ext4 与 XFS 利用的是日志,而 Btrfs 利用的是写时复制。
Linux 文件类型
文件有三种类型:
- 保存用户数据的普通文件
- 保存其他文件的目录
- 设备文件
在需要执行设备特有的复杂操作时,需要使用 ioctl() 系统调用。
Linux 将以文件形式存在的设备分为两种类型:
- 字符设备
- 块设备
所有设备文件都保存在 /dev目录下。通过设备文件的元数据中保存的以下信息,我们可以识别各个设备。
- 文件的种类(字符设备或块设备)
- 设备的主设备号
- 设备的次设备号
字符设备
字符设备虽然能执行读写操作,但是无法自行确定读取数据的位置。下面列出了几个比较具有代表性的字符设备。
- 终端
- 键盘
- 鼠标
以终端为例,我们可以对其设备文件执行下列操作。
- write() 系统调用:向终端输出数据
- read() 系统调用:从终端输入数据
$ ps ax | grep bash
6417 pts/9 Ss 0:00 -bash
6432 pts/9 S+ 0:00 grep bash
$ echo hello >/dev/pts/9
hello块设备
块设备除了能执行普通的读写操作以外,还能进行随机访问,比较具有代表性的块设备是 HDD 与 SSD 等外部存储器。只需像读写文件一样读写块设备的数据,即可访问外部存储器中指定的数据。
正如之前提到的那样,通常不会直接访问块设备,而是在设备上创建一个文件系统并将其挂载,然后通过文件系统进行访问,但在以下几种情况下,需要直接操作块设备。
- 更新分区表(利用parted命令等)
- 块设备级别的数据备份与还原(利用dd命令等)
- 创建文件系统(利用各文件系统的mkfs命令等)
- 挂载文件系统(利用mount命令等)
- fsck
对块设备进行操作
首先,选择一个合适的分区,在上面创建一个ext4文件系统。
# mkfs.ext4 /dev/sdc7 mke2fs 1.42.13 (17-May-2015) Creating filesystem with 244224 4k blocks and 61056 inodes Filesystem UUID: ele22ad6-a569-47aa-9242-af61b11ee1a3 Superblock backups stored on blocks: 32768, 98304, 163840, 229376 Allocating group tables: done Writing inode tables: done Creating journal (4096 blocks): done Writing superblocks and filesystem accounting information: done然后,挂载创建好的文件系统,并在上面创建一个文件,随意写入一些内容。
# mount /dev/sdc7 /mnt/ # echo "hello world" >/mnt/testfile # ls /mnt/ lost+found testfile ←在创建ext4文件系统时,必定会创建一个lost+found文件 # cat /mnt/testfile Hello world # umount /mnt下面来看一下该文件系统的原生数据。这里利用 strings 命令,从包含文件系统数据的
/dev/sdc7中提取出字符串信息。通过string -t x命令,可以以一行一个字符串的格式列出文件中的字符串,每行中的第1个字段为文件偏移量,第2个字段为查找到的字符串。# strings -t x /dev/sdc7 ( 略 ) f35020 lost+found f35034 testfile ... 803d000 hello world 10008020 lost+found 10008034 testfile ( 略 ) #通过上面的输出结果可以得知,在 /dev/sdc7中保存着下列信息。
- lost+found 目录以及文件名 testfile(元数据)
- testfile 文件中的内容,即字符串 hello world(数据)
接下来,尝试直接在块设备上更改testfile的内容。
$ echo "HELLO WORLD" >testfile-overwrite # cat testfile-overwrite HELLO WORLD # dd if=testfile-overwrite of=/dev/sdc7 seek=$((0x803d000)) ↵ bs=1 ←把HELLO WORLD覆写到testfile中 # strings -t x /dev/sdc7 ( 略) 803d000 HELLO WORLD ←直到刚才都还是hello world ( 略) #testfile 中的内容被成功地替换了。通过这一系列的实验,大家应该能明白,通过直接操作块设备的设备文件,即可操作外部存储器,并且隐藏在文件系统下的只是保存在外部存储器中的数据而已。
Linux 文件系统类型
基于内存的文件系统
tmpfs 是一种创建于内存(而非外部存储器)上的文件系统。虽然这个文件系统中保存的数据会在切断电源后消失,但由于访问该文件系统时不再需要访问外部存储器,所以能提高访问速度,如下图所示。
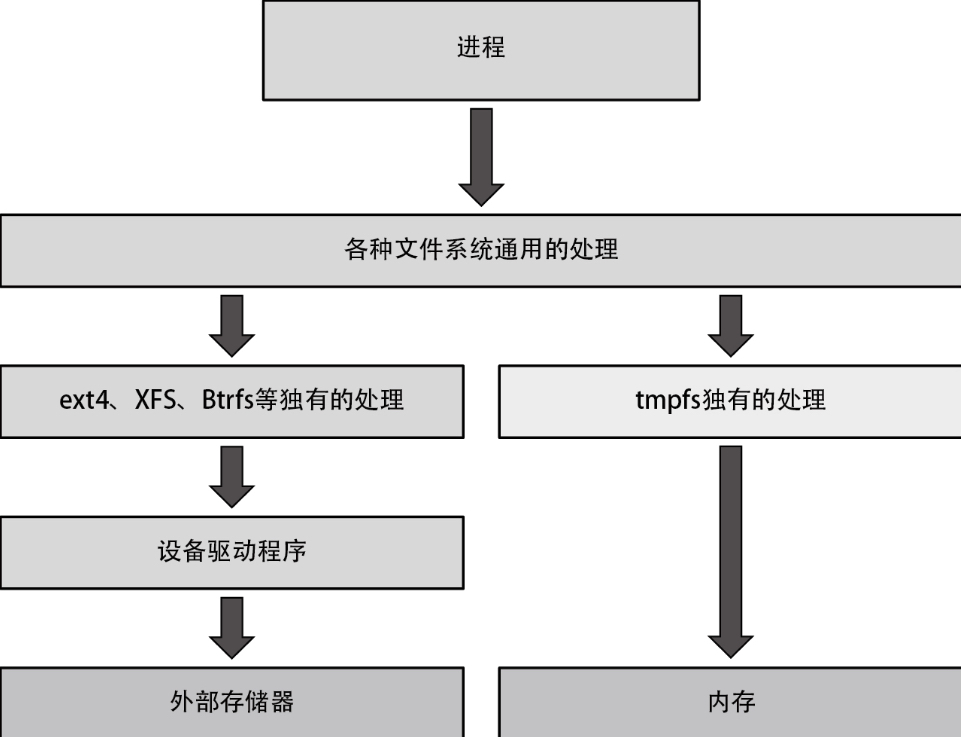
tmpfs 通常被用于 /tmp 与 /var/run 这种“文件内容无须保存到下一次启动时”的文件上。
$ mount | grep ^tmpfs
tmpfs on /run type tmpfs (rw,nosuid,noexec,relatime,size ↵
=3294200k,mode=755)
tmpfs on /dev/shm type tmpfs (rw,nosudid,nodev)
tmpfs on /run/lock type tmpfs (rw,nosudio,nodev,noexec, ↵
relatime,size=5120k)
tmpfs on /sys/fs/cgroup type tmpfs (rw,mode=755)
tmpfs on /run/user/108 type tmpfs (rw,nosuid,nodev,relatime, ↵
size=3294200k,mode=700,uid=108,gid=114)
tmpfs on /run/user/1000 type tmpfs (rw,nosuid,nodev,relatime, ↵
size=3294200k,mode=700,uid=1000,gid=1000)
$tmpfs 创建于挂载的时候。在挂载时,通过 size 选项指定最大容量。不过,并不是说从一开始就直接占用指定的内存量,而是在初次访问文件系统中的区域时,以页为单位申请相应大小的内存。通过查看 free 命令的输出结果中 shared 字段的值,可以得知 tmpfs 实际占用的内存量。
网络文件系统
网络文件系统则可以通过网络访问远程主机上的文件。
虽然网络文件系统同样存在许多种类,但基本上,在访问 Windows 主机上的文件时,使用名为 cifs 的文件系统;而在访问搭载 Linux 等类 UNIX 系统的主机上的文件时,则使用名为 nfs 的文件系统。
虚拟文件系统
系统上存在着各种各样的文件系统,用于获取内核中的各种信息,以及更改内核的行为。
Procfs
procfs 用于获取系统上所有进程的信息。它通常被挂载在 /proc 目录下。通过访问 /proc/*/ 目录下的文件,即可获取各个进程的信息。
下面列举了部分在 /proc/{pid} 路径下的部分文件
| 路径 | 描述 | 备注 |
|---|---|---|
| /proc/{pid}/maps | 进程内存映射 | |
| /proc/{pid}/cmdline | 启动当前进程的完整命令,但僵尸进程目录中的此文件不包含任何信息 | |
| /proc/{pid}/stat | 当前进程的状态信息,包含一系统格式化后的数据列 | 可读性差,通常由 ps 命令使用 |
| /proc/{pid}/root | 指向当前进程运行根目录的符号链接 | 在 Unix 和 Linux 系统上,通常采用 chroot 命令使每个进程运行于独立的根目录 |
| /proc/{pid}/cwd | 指向当前进程运行目录的一个符号链接 | |
| /proc/{pid}/environ | 当前进程的环境变量列表 | 彼此间用空字符(\0)隔开;变量用大写字母表示,其值用小写字母表示; |
| /proc/{pid}/exe | 指向启动当前进程的可执行文件(完整路径)的符号链接 | 通过 /proc/{pid}/exe 可以启动当前进程的一个拷贝 |
| /proc/{pid}/fd | fd 目录包含由进程打开文件的文件描述符(file descriptor) | 通过 ll 命令可以查看 fd 软连接的路径,即资源真正存放的地方 |
| /proc/{pid}/mem | 进程虚拟内存 | |
| /proc/{pid}/mounts | 进程的安装点 | |
| /proc/{pid}/status | 与stat所提供信息类似,但可读性较好 | |
| /proc/{pid}/limits | 当前进程所使用的每一个受限资源的软限制、硬限制和管理单元 | 此文件仅可由实际启动当前进程的UID用户读取 |
| /proc/{pid}/status | 当前进程的状态表 | 可读性强 |
| /proc/{pid}/statm | 当前进程占用内存的状态信息,通常以“页面”(page)表示 | |
| /proc/{pid}/task | 包含由当前进程所运行的每个线程的相关信息 | 每个线程的相关信息文件均保存在一个由线程号(tid)命名的目录中,这类似于其内容类似于每个进程目录中的内容 |
除了进程的信息之外,使用 procfs 还能得到以下几点信息。
| 路径 | 描述 | 备注 |
|---|---|---|
| /proc/fb | 帧缓冲设备列表文件,包含帧缓冲设备的设备号和相关驱动信息 | |
| /proc/buddyinfo | 用于诊断内存碎片问题的相关信息文件 | |
| /proc/meminfo | 系统中关于当前内存的利用状况等的信息 | 常由 free 命令使用 |
| /proc/cpuinfo | 处理器的相关信息的文件 | |
| /proc/slabinfo | 在内核中频繁使用的对象(如 inode、dentry 等)都有自己的 Cache,即 slab pool,而 /proc/slabinfo 文件列出了这些对象相关 slab 的信息 | |
| /proc/zoneinfo | 内存区域(zone)的详细信息列表 | |
| /proc/devices | 系统已经加载的所有块设备和字符设备的信息,包含主设备号和设备组(与主设备号对应的设备类型)名 | |
| /proc/diskstats | 每块磁盘设备的磁盘I/O统计信息列表 | |
| /proc/execdomains | 内核当前支持的执行域 | |
| /proc/filesystems | 当前被内核支持的文件系统类型列表文件,被标示为 nodev 的文件系统表示不需要块设备的支持; | 通常 mount 一个设备时,如果没有指定文件系统类型将通过此文件来决定其所需文件系统的类型 |
| /proc/interrupts | X86 或 X86_64 体系架构系统上每个 IRQ 相关的中断号列表; | 多路处理器平台上每个 CPU 对于每个 I/O 设备均有自己的中断号 |
| /proc/locks | 保存当前由内核锁定的文件的相关信息,包含内核内部的调试数据。 | 每个锁定占据一行,且具有一个惟一的编号; POSIX 表示目前较新类型的文件锁,由 lockf 系统调用产生,FLOCK 是传统的 UNIX 文件锁,由 flock 系统调用产生; ADVISORY 表示不允许其他用户锁定此文件,但允许读取,MANDATORY 表示此文件锁定期间不允许其他用户任何形式的访问; |
| /proc/mounts | 在内核 2.4.29 版本以前,此文件的内容为系统当前挂载的所有文件系统,在 2.4.19 以后的内核中引进了每个进程使用独立挂载名称空间的方式,此文件则随之变成了指向 /proc/self/mounts(每个进程自身挂载名称空间中的所有挂载点列表) | 其中第一列表示挂载的设备,第二列表示在当前目录树中的挂载点,第三点表示当前文件系统的类型,第四列表示挂载属性(ro或者rw),第五列和第六列用来匹配/etc/mtab文件中的转储(dump)属性 |
| /proc/modules | 当前装入内核的所有模块名称列表,可以由 lsmod 命令使用,也可以直接查看 | 第一列表示模块名,第二列表示此模块占用内存空间大小,第三列表示此模块有多少实例被装入,第四列表示此模块依赖于其它哪些模块,第五列表示此模块的装载状态(Live:已经装入;Loading:正在装入;Unloading:正在卸载),第六列表示此模块在内核内存(kernel memory)中的偏移量 |
| /proc/partitions | 块设备每个分区的主设备号(major)和次设备号(minor)等信息,同时包括每个分区所包含的块(block)数目 | |
| /proc/swaps | 当前系统上的交换分区及其空间利用信息 | 如果有多个交换分区的话,则会每个交换分区的信息分别存储于 /proc/swap 目录中的单独文件中,而其优先级数字越低,被使用到的可能性越大 |
| /proc/cmdline | 在启动时传递至内核的相关参数信息,这些信息通常由 lilo 或 grub 等启动管理工具进行传递 | |
| /proc/crypto | 系统上已安装的内核使用的密码算法及每个算法的详细信息列表 | |
| /proc/dma | 每个正在使用且注册的 ISA DMA 通道的信息列表 | |
| /proc/ioports | 当前正在使用且已经注册过的与物理设备进行通讯的输入-输出端口范围信息列表 | |
| /proc/iomem | 每个物理设备上的记忆体(RAM或者ROM)在系统内存中的映射信息 | |
| /proc/kcore | 系统使用的物理内存,以ELF核心文件(core file)格式存储,其文件大小为已使用的物理内存(RAM)加上4KB; | 这个文件用来检查内核数据结构的当前状态,因此,通常由GBD通常调试工具使用,但不能使用文件查看命令打开此文件; |
| /proc/kmsg | 此文件用来保存由内核输出的信息。 | 通常由 /sbin/klogd 或 /bin/dmsg 等程序使用,不要试图使用查看命令打开此文件 |
| /proc/loadavg | 保存关于 CPU 和磁盘 I/O 的负载平均值。 | 其前三列分别表示每 1 秒钟、每 5 秒钟及每 15 秒的负载平均值; 第四列是由斜线隔开的两个数值,前者表示当前正由内核调度的实体(进程和线程)的数目,后者表示系统当前存活的内核调度实体的数目; 第五列表示此文件被查看前最近一个由内核创建的进程的PID; |
| /proc/mdstat | 保存RAID相关的多块磁盘的当前状态信息 | |
| /proc/vmstat | 当前系统虚拟内存的多种统计数据 | |
| /proc/stat | 实时追踪自系统上次启动以来的多种统计信息 | “cpu”行后的八个值分别表示以1/100(jiffies)秒为单位的统计值(包括系统运行于用户模式、低优先级用户模式,运系统模式、空闲模式、I/O等待模式的时间等); “intr”行给出中断的信息,第一个为自系统启动以来,发生的所有的中断的次数;然后每个数对应一个特定的中断自系统启动以来所发生的次数; “ctxt”给出了自系统启动以来CPU发生的上下文交换的次数。 “btime”给出了从系统启动到现在为止的时间,单位为秒; “processes (total_forks) 自系统启动以来所创建的任务的个数目; “procs_running”:当前运行队列的任务的数目; “procs_blocked”:当前被阻塞的任务的数目; |
| /proc/uptime | 系统上次启动以来的运行时间 | 第一个数字表示系统运行时间,第二个数字表示系统空闲时间,单位是秒 |
| /proc/version | 当前系统运行的内核版本号 |
Sysfs
在 Linux 引入 procfs 后不久,越来越多的乱七八糟的信息也被塞入其中,导致出现了许多与进程无关的信息。为了防止 procfs 被滥用,Linux 又引入了一个名为 sysfs 的文件系统,用来存放那些信息。sysfs 通常被挂载在 /sys 目录下。sysfs 包括但不限于下列文件。
/sys/devices目录下的文件:搭载于系统上的设备的相关信息/sys/fs目录下的文件:系统上的各种文件系统的相关信息
CGroupfs
CGroup 用于限制单个进程或者由多个进程组成的群组的资源使用量。CGroupfs 通常被挂载在 /sys/fs/cgroup 目录下。通过 cgroup 添加限制的资源有很多种,举例如下。
- CPU:设置能够使用的比例,比如令某群组只能够使用 CPU 资源总量的50%等。通过读写
/sys/fs/cgroup/cpu目录下的文件进行控制 - 内存:限制群组的物理内存使用量,比如令某群组最多只能够使用 1GB 内存等。通过读写
/sys/fs/cgroup/memory目录下的文件进行控制
Btrfs
ext4与XFS虽然存在些许差别,但两者都是从UNIX(Linux的根基)诞生之时就存在的文件系统,且两者都仅提供了创建、删除和读写文件等基本功能。近年来出现了许多功能更加丰富的新文件系统,其中比较具有代表性的就是Btrfs。
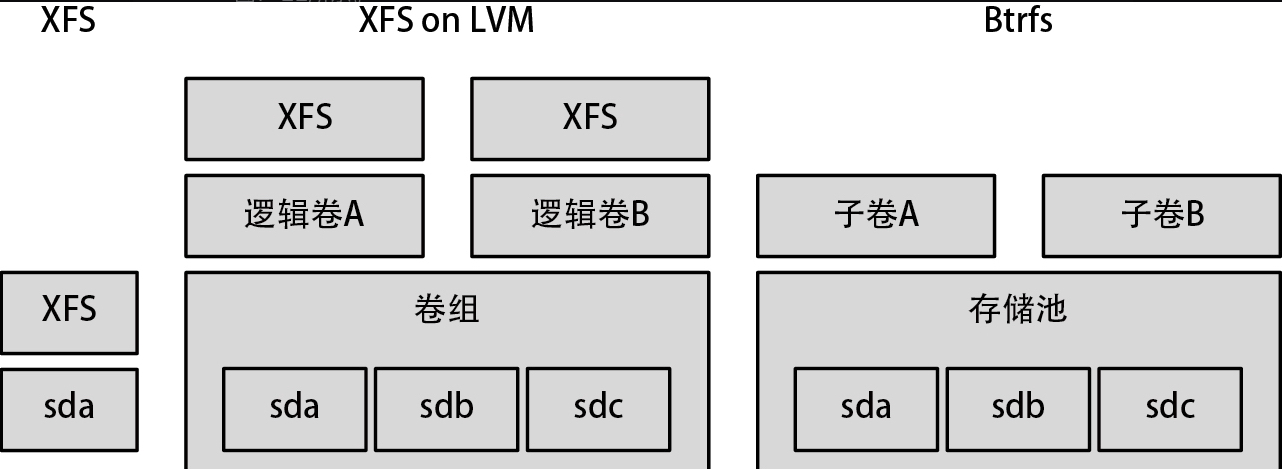
多物理卷
在 ext4 与 XFS 上需要为每个分区创建文件系统,但在 Btrfs 中不需要这样。Btrfs 可以创建一个包含多个外部存储器或分区的存储池,然后在存储池上创建可被挂载的区域,该区域称为子卷。存储池相当于 LVM 中的卷组,而子卷则类似于 LVM 中的逻辑卷与文件系统的融合。因此,为了便于理解 Btrfs 的机制,与其把它当成传统意义上的文件系统,不如把它当作文件系统与LVM等逻辑卷管理器融合后的产物,如下图所示。
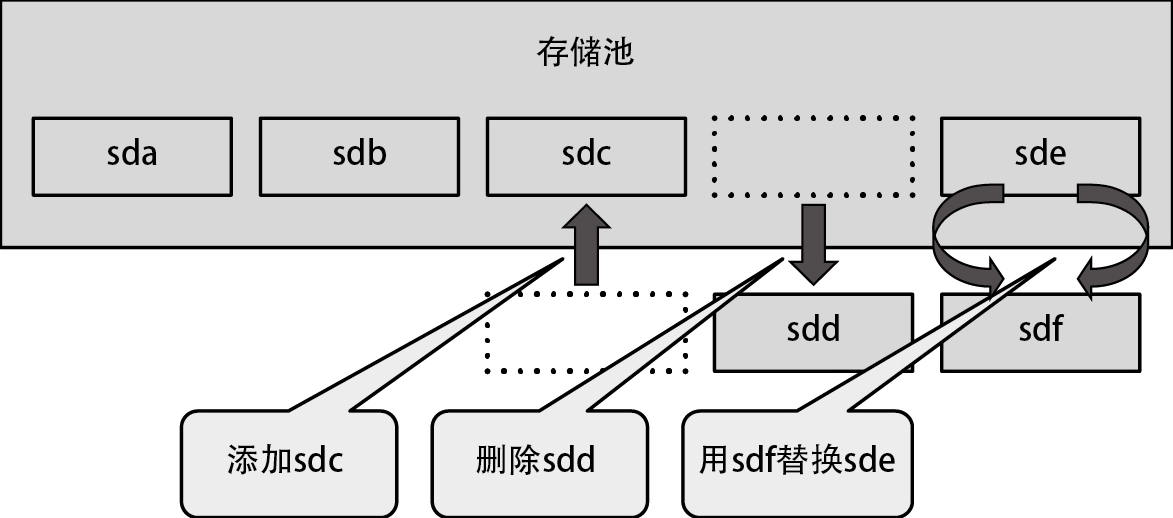
在 Btrfs 中,甚至还可以向现存的文件系统添加、删除以及替换外部存储器。即便这些操作导致容量发生变化,也无须调整文件系统大小,如下图所示。另外,这些操作都能在文件系统已挂载的状态下进行,无须卸载文件系统。
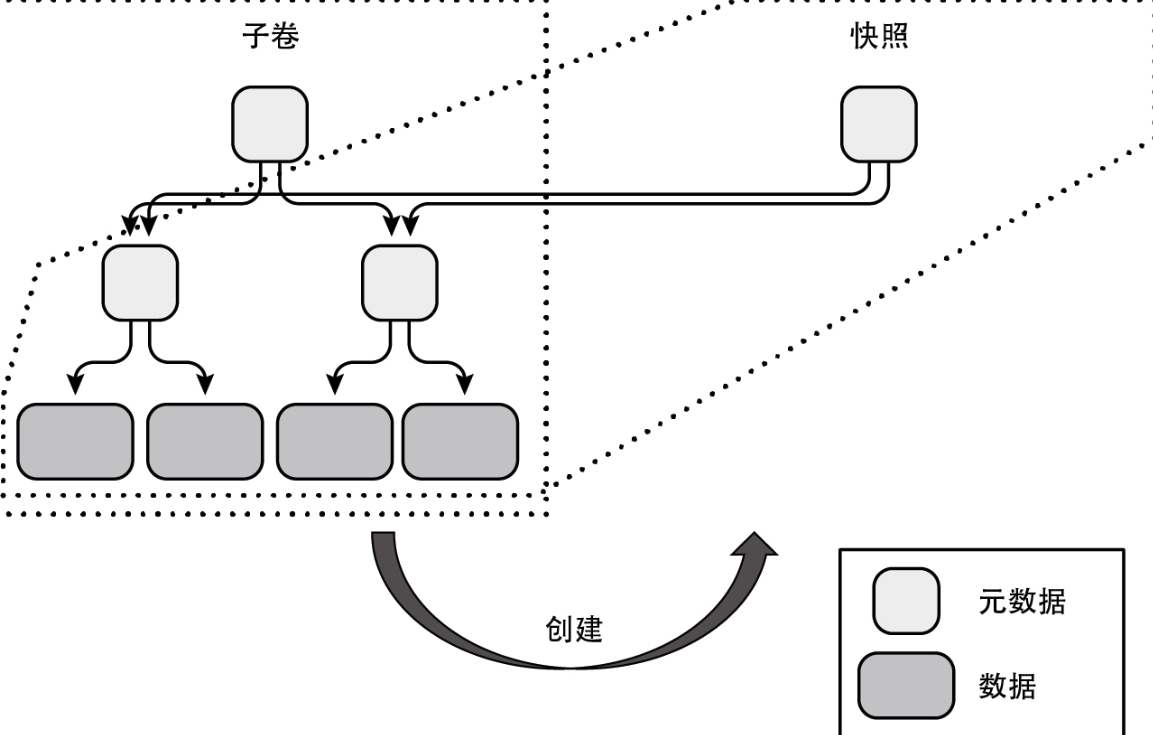
快照
Btrfs 可以以子卷为单位创建快照。创建快照并不需要复制所有的数据,只需根据数据创建其元数据,并回写快照内的脏页即可,因此创建快照与平常的复制操作比起来要快得多。而且,由于快照与子卷共享数据,所以创建快照的存储空间成本也很低。
下面就来看一下通常的复制操作与在Btrfs中创建子卷快照这两种备份方式在存储空间成本上的差距。首先是复制操作的情形,如下图所示。
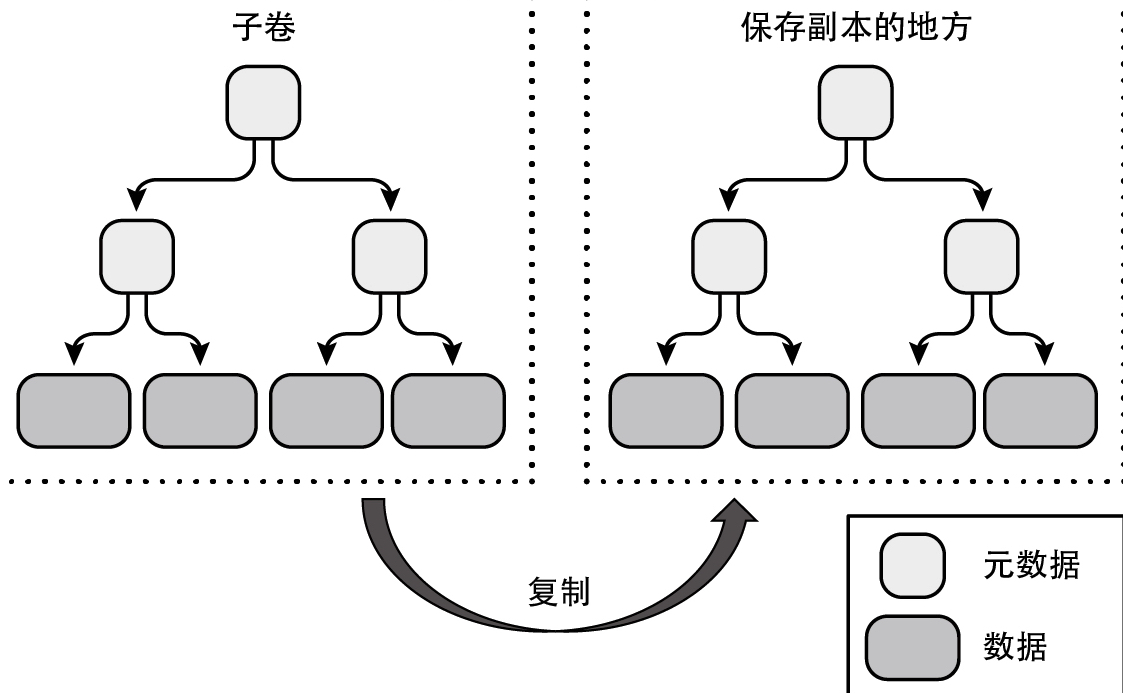
可以看到,不但需要创建新的元数据,还需要为所有数据创建一份副本。接着,来看一下在Btrfs上是如何创建快照的。
RAID
Btrfs 可以在文件系统级别上配置 RAID,支持的 RAID 级别有 RAID 0、RAID 1、RAID 10、RAID 5、RAID 6 以及 dup(在同一个外部存储器中对一份数据创建两份副本,适用于单设备)。另外,在配置 RAID 时,不是以子卷为单位,而是以整个 Btrfs 文件系统为单位。
首先来看一下没有配置 RAID 时的结构。假设在一个仅由 sda 构成的单设备 Btrfs 文件系统上存在一个子卷A。在这种情况下,一旦sda出现故障,子卷A上所有的数据就会丢失,如下图所示。

与此相对,如果为文件系统配置了 RAID 1,那么所有数据都会被写入两台外部存储器(在本例中为 sda 与 sdb),所以即便 sda 出现故障,在 sdb 上也还保留着一份子卷 A 的数据,如下图所示。

数据损坏的检测与恢复
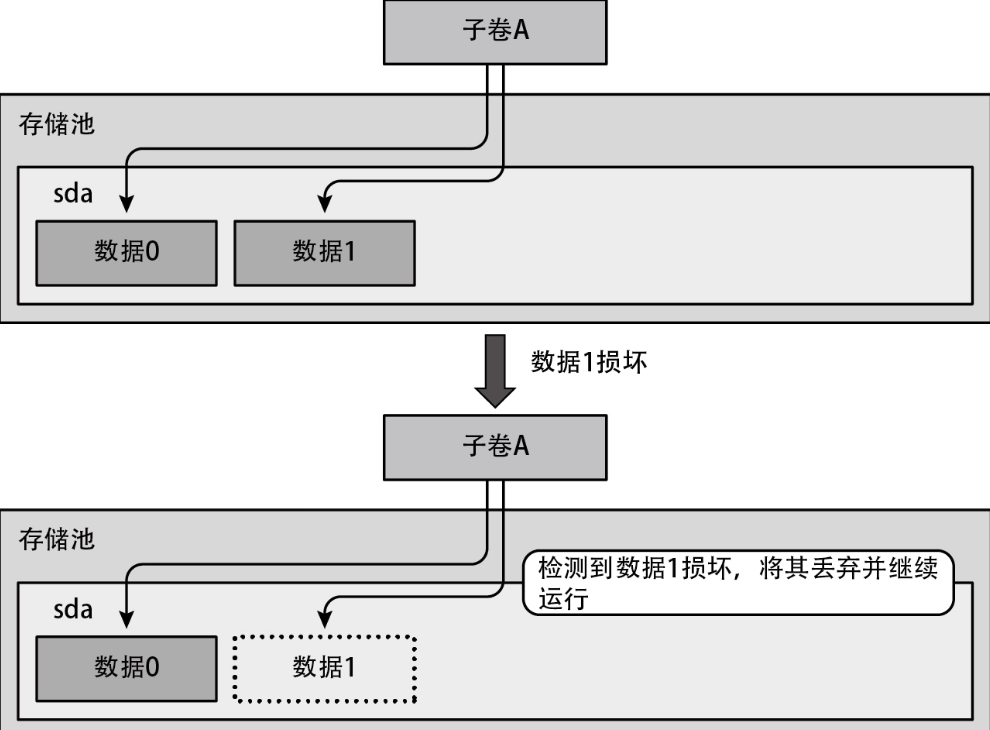
当外部存储器中的部分数据损坏时,Btrfs 能够检测出来,如果配置了某些级别的 RAID,还能修复这些损坏的数据。而在那些没有这类功能的文件系统中,即便在写入时外部存储器中的数据因比特差错等而损坏了,也无法检测出这些损坏的数据,而是在数据损坏的状态下继续运行,如下图所示。

这有可能导致更多的数据被损坏,而且我们很难查明这种故障的起因。
与此相对,Btrfs拥有一种被称为校验和(checksum)的机制,用于检测数据与元数据的完整性。通过这种机制,可以检测出数据损坏。如图7-29所示,如果在读取数据或者元数据时出现校验和报错,将丢弃这部分数据,并通知发出读取请求的进程出现了I/O异常。
在检测到损坏时,如果配置的 RAID 级别是 RAID 1、RAID 10、RAID 5、RAID 6 或者 dup 之一,Btrfs 就能基于校验和正确的另一份数据副本修复破损的数据。在 RAID 5 和 RAID 6 中,还能通过奇偶校验(parity check)实现同样的功能。下图所示为 RAID 1 的数据修复流程。
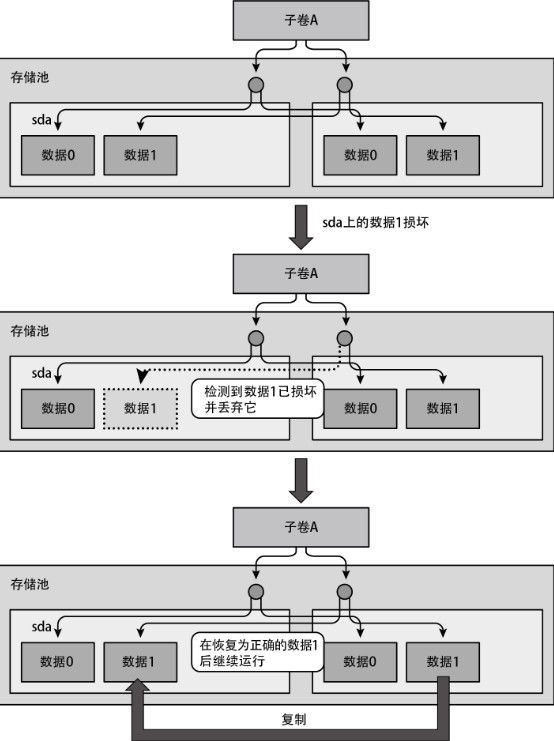
这种方式可以在申请读取的一方未发现数据损坏的情况下完成数据修复。