Flink 中提供了 4 种不同层次的 API:
- 低级 API:提供了对时间和状态的细粒度控制,简洁性和易用性较差,主要应用在对一些复杂事件的处理逻辑上。
- 核心 API:主要提供了针对流数据和离线数据的处理,对低级 API 进行了一些封装,提供了 filter、sum、max、min 等高级函数,简单且易用,所以在工作中应用比较广泛。
- Table API:一般与 DataSet 或者 DataStream 紧密关联,首先通过一个 DataSet 或 DataStream 创建出一个 Table;然后用类似于 filter、join 或者 select 关系型转化操作来转化为一个新的 Table 对象;最后将一个 Table 对象转回一个 DataSet 或 DataStream。与 SQL 不同的是,Table API 的查询不是一个指定的 SQL 字符串,而是调用指定的 API 方法。
- SQL API:Flink 的 SQL 集成是基于 Apache Calcite 的,Apache Calcite 实现了标准的 SQL,使用起来比其他 API 更加灵活,因为可以直接使用 SQL 语句。Table API 和 SQL 可以很容易地结合在一块使用,它们都返回 Table 对象。
概念
DataStream API 主要分为3块:DataSource、Transformation、Sink。
DataSource
DataSource 是程序的数据源输入。
Flink 针对 DataStream 提供了一些已经实现的 DataSource 接口。
| 名称 | 调用 | 描述 |
|---|---|---|
| 基于文件 | readTextFile(path) | 读取文本文件,文件遵循TextInputFormat逐行读取规则并返回。 |
| 基于 Socket | socketTextStream | 从 Socket 中读取数据,元素可以通过一个分隔符分开。 |
| 基于集合 | fromCollection(Collection) | 通过 Collection 创建一个数据流,集合中的所有元素必须是相同类型的。 |
Flink 也可以通过 StreamExecutionEnvironment.addSource 实现读取第三方数据源数据。
| 连接器 | Source支持 | 语义保证 |
|---|---|---|
| Kafka | 是 | Exactly-Once |
| Netty | 是 |
当然也可以自定义数据源。自定义数据源有两种实现,通过实现 SourceFunction 接口自定义并行度为 1 的数据源;通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 来自定义有并行度的数据源。
Transformation
Transformation 是具体的操作,它对一个或多个输入数据源进行计算处理。
Flink 针对 DataStream 实现了以下算子:
| 算子 | 功能 |
|---|---|
| Map | 做一对一映射,可变更类型 |
| FlatMap | 做一对多映射,可变更类型 |
| Filter | 过滤出条件为 true 的元素 |
| KeyBy | 将相同的 key 分到同一个分区 |
| Reduce | 根据多个元素生成一个元素。算子内部会保存上一次 Reduce 的中间结果,然后将当前元素值和上一次 Reduce 的中间结果相加,并用相加结果更新中间结果 |
| Union | 将多个数据流合并成一个数据流 |
| Connect | |
| CoMap 和 CoFlatMap | |
| Split | |
| Select |
连接和分区
Flink 提供了将两个数据流合并数据的能力。
| 算子 | 功能 |
| - | - |
| Join | 两个数据源的相同窗口时间区间内元素组合成对 |
| IntervalJoin | 在事件时间轴上,以被连接数据源的每一个元素为顶点画锥形,本元素只和被锥形覆盖的另一个数据源的元素组合 |
分布式系统的通信开销通常都很大,在数据处理应用场景下传输大量数据更是如此。通过合理控制传输通道中的数据分布达到最优的网络通信性能,是实现流式数据处理引擎的一个重要课题,下图所示为数据分区前后的网络开销对比。
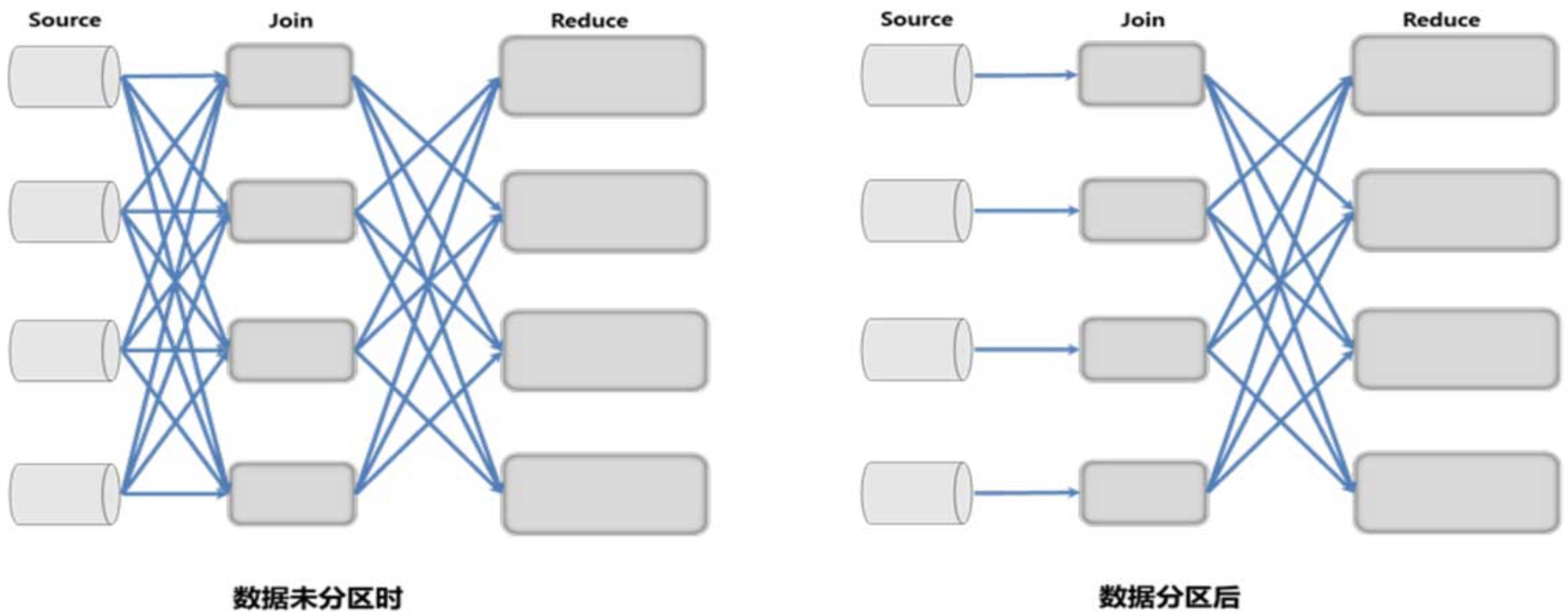
在未使用数据分区时,Join 节点的每个并行实例需要聚合来自所有 Source 节点实例的数据,大量数据传输会造成网络过载。使用数据分区后,Source 和 Join节点实例是一一相连的,可以用同一 Slot 的一个线程运行这两个相连的任务。
针对上述情况,DataStream 提供了一些数据分区规则,具体如下。
| 分区规则 | 规则名称 | 调用方式 |
|---|---|---|
| Random Partition | 随机分区 | DataStream.shuffle() |
| Rebalancing Partition | 负载均衡分区:对数据集进行再平衡、重分区和消除数据倾斜 | DataStream.rebalance() |
| Rescaling Partition | 可伸缩分区:Flink 引擎根据资源使用情况动态调节同一作业的数据分布,根据物理实例部署时的资源共享情况动态调节数据分布,目的是让数据尽可能地在同一Slot内流转,以减少网络通信开销 | DataStream.rescale() |
| Broadcasting Partition | 每一个元素都被广播到所有下一级节点 | DataStream.broadcast() |
| Custom Partition | 自定义分区 | DataStream.partitionCustom() |
资源共享
Flink 将多个任务链接成一个任务在一个线程中执行,在降低线程上下文切换的开销,减小缓存容量,提高系统吞吐量的同时降低延迟。
这种机制是可配置的:
1. 创建链
dataStream.map().map().startNewChain().map()代码中后两个map函数被链接在一起,而第一个map函数则不会被链接。
2. 关闭作业链接优化,这样任意两个算子实例可不共享线程
dataStream.map().disableChaining()3. Slot共享组,即在同一个组中所有任务的实例在同一个Slot中运行,以隔离非本组实例
dataStream.map().slotSharingGroup("groupName")Sink
Sink 是程序的输出,它可以把 Transformation 处理之后的数据输出到指定的存储介质中。
Flink 针对 DataStream 提供了一些已经实现的 Sink 接口。
| 名称 | 调用 | 描述 |
|---|---|---|
| 打印至标准输出 | print() | 从 Socket 中读取数据,元素可以通过一个分隔符分开。 |
| 打印至标准错误输出 | printToErr() | 通过 Collection 创建一个数据流,集合中的所有元素必须是相同类型的。 |
Flink 也可以通过 StreamExecutionEnvironment.addSink 实现把数据输出到第三方存储介质。
| 连接器 | Sink支持 | 语义保证 |
|---|---|---|
| Kafka | 是 | Exactly-Once |
| ElasticSearch | 是 | At-least-once |
| Redis | 是 | At-least-once |
当然也可以自定义 Sink。有两种实现,通过实现 SinkFunction 接口或者继承 RichSinkFunction 来自定义有并行度的数据源。
相关内容可以参考 RedisSink。
原理
DataStream 代表一系列同类型数据的集合,可以通过转换操作生成新的 DataStream。DataStream 用于表达业务转换逻辑,实际上并没有存储真实数据。
public class DataStream<T> {
protected final StreamExecutionEnvironment environment;
protected final Transformation<T> transformation;
...
}DataStream 数据结构包含两个主要成员:StreamExecutionEnvironment 和 Transformation<T>。其中 transformation 是当前 DataStream 对应的上一次的转换操作,换句话讲,就是通过 transformation 生成当前的 DataStream。当用户通过 DataStream API 构建 Flink 作业时,StreamExecutionEnvironment 会将 DataStream 之间的转换操作存储至 StreamExecutionEnvironment 的 List<Transformation<?>> transformations 集合,然后基于这些转换操作构建作业 Pipeline 拓扑,用于描述整个作业的计算逻辑。其中流式作业对应的 Pipeline 实现类为 StreamGraph,批作业对应的 Pipeline 实现类为 Plan。
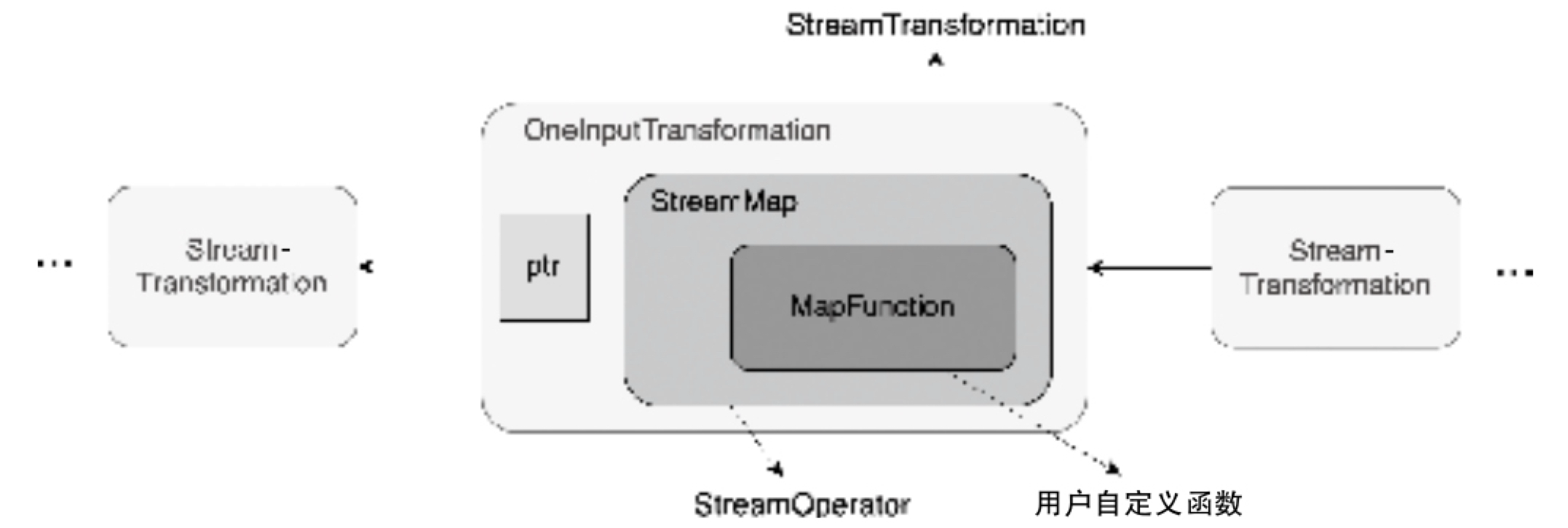
每个 StreamTransformation 都包含相应的 StreamOperator,例如执行 DataStream.map-(new MapFunction(...)) 转换之后,内部生成的便是 StreamMap 算子。StreamOperator 涵盖了用户自定义函数的信息,如上图所示,StreamMap 算子包含了 MapFunction。MapFunction 就是用户自定义的 map 转换函数。当然还有其他类型的函数,例如 ProcessFunction、SourceFunction 和 SinkFunction 等,不同的转换操作,对应的函数也有所不同。
通常情况下,用户是不直接参与定义 StreamOperator 的,而是由 Flink 根据用户执行的 DataStream 转换操作以及函数共同生成 StreamOperator,之后 Task 运行时会运行定义的 StreamOperator。
DataStream Map 实现
以 DataStream 中的 map 转换操作为例,对 DataStream 底层源码实现进行说明。
public <R> SingleOutputStreamOperator<R> map(
MapFunction<T, R> mapper, TypeInformation<R> outputType) {
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}首先自定义 MapFunction 实现数据处理逻辑,然后调用 DataStream.map() 方法将 MapFunction 作为参数应用在 map 转换操作中。在 DataStream.map() 方法中可以看出,实际调用了 transform() 方法进行后续的转换处理,且调用过程会基于 MapFunction 参数创建 StreamMap 实例,StreamMap 实际上就是 StreamOperator 的实现子类。
public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}接下来在 DataStream.transform() 方法中调用 doTransform() 方法继续进行转换操作。
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}如 DataStream.doTransform() 方法主要包含如下逻辑。
- 从上一次转换操作中获取 TypeInformation 信息,确定没有出现 MissingTypeInfo 错误,以确保下游算子转换不会出现问题。
- 创建 OneInputTransformation 实例,注意 OneInputTransformation 也会包含当前 DataStream 对应的上一次转换操作。
- 基于 OneInputTransformation 实例创建 SingleOutputStreamOperator。SingleOutputStreamOperator 继承了 DataStream 类,属于特殊的 DataStream,主要用于每次转换操作后返回给用户继续操作的数据结构。SingleOutputStreamOperator 额外提供了
returns()、disableChaining()等方法供用户使用。 - 调用
getExecutionEnvironment().addOperator(resultTransform)方法,将创建好的 OneInputTransformation 添加到 StreamExecutionEnvironment 的 Transformation 集合中,用于生成 StreamGraph对象。 - 将 returnStream 返回给用户,继续执行后续的转换操作。基于这样连续的转换操作,将所有 DataStream 之间的转换按顺序存储在 StreamExecutionEnvironment 中。
在 DataStream 转换的过程中,不管是哪种类型的转换操作,都是按照同样的方式进行的:
- 将用户自定义的函数封装到 Operator 中
- 将 Operator 封装到 Transformation 转换操作结构中
- 将 Transformation 写入 StreamExecutionEnvironment 提供的 Transformation 集合
- 通过 DataStream 之间的转换操作形成 Pipeline 拓扑,即 StreamGraph 数据结构
- 最终通过 StreamGraph 生成 JobGraph 并提交到集群上运行
Transformation 详解
![[/images/SE/Transformation-UML关系图.png]]
Transformation 的实现子类涵盖了所有的 DataStream 转换操作。
常用到的 StreamMap、StreamFilter 算子封装在 OneInputTransformation 中,也就是单输入类型的转换操作。常见的双输入类型算子有 join、connect 等,对应支持双输入类型转换的 TwoInputTransformation 操作。
在 Transformation 的基础上又抽象出了 PhysicalTransformation 类。PhysicalTransformation 中提供了 setChainingStrategy() 方法,可以将上下游算子按照指定的策略连接。
ChainingStrategy 支持如下三种策略:
- ALWAYS:代表该 Transformation 中的算子会和上游算子尽可能地链化,最终将多个 Operator 组合成 OperatorChain。OperatorChain 中的 Operator 会运行在同一个 SubTask 实例中,这样做的目的主要是优化性能,减少 Operator 之间的网络传输。
- NEVER:代表该 Transformation 中的 Operator 永远不会和上下游算子之间链化,因此对应的 Operator 会运行在独立的 SubTask 实例中。
- HEAD:代表该 Transformation 对应的 Operator 为头部算子,不支持上游算子链化,但是可以和下游算子链化,实际上就是 OperatorChain 中的 HeaderOperator。
通过以上策略可以控制算子之间的连接,在生成 JobGraph 时,ALWAYS 类型连接的 Operator 形成 OperatorChain。同一个 OperatorChain 中的 Operator 会运行在同一个 SubTask 线程中,从而尽可能地避免网络数据交换,提高计算性能。当然,用户也可以显性调用 disableChaining() 等方法,设定不同的 ChainingStrategy,实现对 Operator 之间物理连接的控制。
以下是支持设定 ChainingStrategy 的 PhysicalTransformation 操作类型,也就是继承了 PhysicalTransformation 抽象的实现类。
- OneInputTransformation:单进单出的数据集转换操作,例如
DataStream.map()转换。 - TwoInputTransformation:双进单出的数据集转换操作,例如在 DataStream 与 DataStream 之间进行 Join 操作,且该转换操作中的 Operator 类型为 TwoInputStreamOperator。
- SinkTransformation:数据集输出操作,当用户调用
DataStream.addSink()方法时,会同步创建 SinkTransformation 操作,将 DataStream 中的数据输出到外部系统中。 - SourceTransformation:数据集输入操作,调用
DataStream.addSource()方法时,会创建 SourceTransformation 操作,用于从外部系统中读取数据并转换成 DataStream 数据集。 - SplitTransformation:数据集切分操作,用于将 DataStream 数据集根据指定字段进行切分,调用
DataStream.split()方法时会创建 SplitTransformation。
除了 PhysicalTransformation 之外,还有一部分转换操作直接继承自 Transformation 抽象类,这些 Transformation 本身就是物理转换操作,不支持链化操作,因此不会将其与其他算子放置在同一个SubTask中运行。
- SelectTransformation:根据用户提供的 selectedName 从上游 DataStream 中选择需要输出到下游的数据
- PartitionTransformation:支持对上游 DataStream 中的数据进行分区,分区策略通过指定的 StreamPartitioner 决定,例如当用户执行
DataStream.rebalance()方法时,就会创建 StreamPartitioner 实现类 RebalancePartitioner 实现上下游数据的路由操作。 - UnionTransformation:用于对多个输入 Transformation 进行合并,最终将上游 DataStream 数据集中的数据合并为一个 DataStream。
- SideOutputTransformation:用于根据 OutputTag 筛选上游 DataStream 中的数据并下发到下游的算子中继续处理。
- CoFeedbackTransformation:用于迭代计算中单输入反馈数据流节点的转换操作
- FeedbackTransformation:用于迭代计算中双输入反馈数据流节点的转换操作。
StreamOperator 详解
Transformation 负责描述 DataStream 之间的转换信息,而 Transformation 结构中最主要的组成部分就是 StreamOperator。
从 StreamOperator UML 关系图中可以看出,StreamOperator 作为接口,在被 OneInputStreamOperator 接口和 TwoInputStreamOperator 接口继承的同时,又分别被 AbstractStreamOperator 和 AbstractUdfStreamOperator 两个抽象类继承和实现。
其中 OneInputStreamOperator 和 TwoInputStreamOperator 定义了不同输入数量的 StreamOperator 方法,例如:单输入类型算子通常会实现 OneInputStreamOperator 接口,常见的实现有 StreamSource 和 StreamSink 等算子;TwoInputStreamOperator 则定义了双输入类型算子,常见的实现有 CoProcessOperator、CoStreamMap 等算子。从这里我们可以看出,StreamOperator 和 Transformation 基本上是一一对应的,最多支持双输入类型算子,而不支持多输入类型,用户可以通过多次关联 TwoInputTransformation 实现多输入类型的算子。
![[images/SE/StreamOperator-UML关系图.png]]
不管是 OneInputStreamOperator 还是 TwoInputStreamOperator 类型的算子,最终都会继承 AbstractStreamOperator 基本实现类。在调度和执行 Task 实例时,会通过 AbstractStreamOperator 提供的入口方法触发和执行 Operator。同时在 AbstractStreamOperator 中也定义了所有算子中公共的组成部分,如 StreamingRuntimeContext、OperatorStateBackend 等。对于 AbstractStreamOperator 如何被 SubTask 触发和执行。另外,AbstractUdfStreamOperator 基本实现类则主要包含了 UserFunction 成员变量,允许当前算子通过自定义 UserFunction 实现具体的计算逻辑。
StreamOperator 接口定义
StreamOperator 接口主要包括如下核心方法:
生命周期:
- open:在数据元素正式接入 Operator 运算之前,Task 会调用
StreamOperator.open()方法对该算子进行初始化。 - close:当所有的数据元素都添加到当前 Operator 时,会调用该方法刷新所有剩余的缓冲数据,保证算子中所有数据被正确处理。
- dispose:算子生命周期结束时会调用此方法,包括算子操作执行成功、失败或者取消时。
快照:
- prepareSnapshotPreBarrier:在 StreamOperator 正式执行 checkpoint 操作之前会调用该方法。
- snapshotState:当 SubTask 执行 checkpoint 操作时会调用该方法,用于触发该 Operator 中状态数据的快照操作。
数据恢复:
- initializeState:当算子启动或重启时,调用该方法初始化状态数据,当恢复作业任务时,算子会从检查点(checkpoint)持久化的数据中恢复状态数据。
OneInputStreamOperator 定义
OneInputStreamOperator 定义了单输入流的 StreamOperator,常见的实现类有 StreamMap、StreamFilter 等算子。
OneInputStreamOperator 接口主要包含以下方法,专门用于处理接入的单输入数据流:
// 处理输入数据元素的方法
void processElement(StreamRecord<IN> element) throws Exception;
// 处理Watermark的方法
void processWatermark(Watermark mark) throws Exception;
// 处理延时标记的方法
void processLatencyMarker(LatencyMarker latencyMarker) throws Exception;TwoInputStreamOperator 定义
TwoInputStreamOperator 定义了双输入流类型的 StreamOperator 接口实现,常见的实现类有 CoStreamMap、HashJoinOperator 等算子。
TwoInputStreamOperator 接口在实现对两个数据流转换操作的同时,还定义了两条数据流中 Watermark 和 LatencyMarker 的处理逻辑,主要包含以下方法:
// 处理输入源1的数据元素方法
void processElement1(StreamRecord<IN1> element) throws Exception;
// 处理输入源2的数据元素方法
void processElement2(StreamRecord<IN2> element) throws Exception;
// 处理输入源1的Watermark方法
void processWatermark1(Watermark mark) throws Exception;
// 处理输入源2的Watermark方法
void processWatermark2(Watermark mark) throws Exception;
// 处理输入源1的LatencyMarker方法
void processLatencyMarker1(LatencyMarker latencyMarker) throws Exception;
// 处理输入源2的LatencyMarker方法
void processLatencyMarker2(LatencyMarker latencyMarker) throws Exception;StreamOperatorFactory
StreamOperator 最终会通过 StreamOperatorFactory 封装在 Transformation 结构中,并存储在 StreamGraph 和 JobGraph 结构中,直到运行时执行 StreamTask 时,才会调用 StreamOperatorFactory.createStreamOperator() 方法生成 StreamOperator 实例。
![[images/SE/StreamOperatorFactory-UML关系图.png]]
从 SimpleOperatorFactory.of() 方法定义中可以看出,基于 StreamOperator 提供的 of() 方法对算子进行工厂类的封装,实现将 Operator 封装在 OperatorFactory 中。然后根据 Operator 类型的不同,创建不同的 SimpleOperatorFactory 实现类,例如当 Operator 类型为 StreamSource 且 UserFunction 定义属于 InputFormatSourceFunction 时,就会创建 SimpleInputFormatOperatorFactory 实现类,其他情况类似。
Function 详解
DataStream 转换操作中的数据处理逻辑主要是通过 Function 接口实现的,StreamOperator 负责对内部 Function 的调用和执行,当 StreamOperator 被 Task 调用和执行时,StreamOperator 会将接入的数据元素传递给内部 Function 进行处理,然后将 Function 处理后的结果推送给下游的算子继续处理。
![[images/SE/Function-UML关系图.png]]
RichFunction 详解
RichFunction 接口实际上对 Function 进行了补充和拓展,RichFunction 接口提供了对有状态计算的支持。RichFunction 接口除了包含 open() 和 close() 方法之外,还提供了获取 RuntimeContext 的方法,并在 AbstractRichFunction 抽象类类中提供了对 RichFunction 接口的基本实现。RichMapFunction 和 RichFlatMapFunction 接口实现类最终通过 AbstractRichFunction 提供的 getRuntimeContext() 方法获取 RuntimeContext 对象,进而操作状态数据。
RuntimeContext 包含了算子执行过程中所有运行时的上下文信息,例如 Accumulator、BroadcastVariable 和 DistributedCache 等变量。
RuntimeContext 上下文
![[images/SE/RuntimeContext-UML关系图.png]]
不同类型的 Operator 创建的 RuntimeContext 也有一定区别,因此在 Flink 中提供了不同的 RuntimeContext 实现类,以满足不同 Operator 对运行时上下文信息的获取。其中 AbstractRuntimeUDFContext 主要用于获取提供 UDF 函数的相关运行时上下文信息,且 AbstractRuntimeUDFContext 又分别被 RuntimeUDFContext、DistributedRuntimeUDFContext 以及 StreamingRuntimeContext 三个子类继承和实现。RuntimeUDFContext 主要用于 CollectionExecutor;DistributedRuntimeUDFContext 则主要用于 BatchTask、DataSinkTask 以及 DataSourceTask 等离线场景。流式数据处理中使用最多的是 StreamingRuntimeContext。
当然还有其他场景使用到的 RuntimeContext 实现类,例如 CepRuntimeContext、SavepointRuntimeContext 以及 IterationRuntimeContext,这些 RuntimeContext 实现类主要服务于相应类型的数据处理场景。
自定义 RichMapFunction 实例
public class CustomMapper extends RichMapFunction<String, String> {
private transient Counter counter;
private ValueState<Long> state;
@Override
public void open(Configuration config) {
// 获取 StreamingRuntimeContext 对象
this.counter = getRuntimeContext()
// 获取 MetricGroup 创建 Counter 指标累加器
.getMetricGroup()
.counter("myCounter");
state = getRuntimeContext()
.getState( new ValueStateDescriptor<Long>("count", LongSerializer.INSTANCE, 0L));
}
@Override
public String map(String value) throws Exception {
this.counter.inc();
long count = state.value() + 1;
state.update(count);
return value;
}
}SourceFunction 详解
SourceFunction 没有具体的数据元素输入,而是通过在 SourceFunction 实现中与具体数据源建立连接,并读取指定数据源中的数据,然后转换成 StreamRecord 数据结构发送到下游的 Operator 中。
![[images/SE/SourceFunction-UML关系图.png]]
SourceFunction 接口继承了 Function 接口,并在内部定义了数据读取使用的 run() 方法和 SourceContext 内部类,其中 SourceContext 定义了数据接入过程用到的上下文信息。在默认情况下,SourceFunction 不支持并行读取数据,因此 SourceFunction 被 ParallelSourceFunction 接口继承,以支持对外部数据源中数据的并行读取操作,比较典型的 ParallelSourceFunction 实例就是 FlinkKafkaConsumer。
在 SourceFunction 的基础上拓展了 RichParallelSourceFunction 和 RichSourceFunction 抽象实现类,这使得 SourceFunction 可以在数据接入的过程中获取 RuntimeContext 信息,从而实现更加复杂的操作,例如使用 OperatorState 保存 Kafka 中数据消费的偏移量,从而实现端到端当且仅被处理一次的语义保障。
SourceContext 上下文
SourceContext 主要用于收集 SourceFunction 中的上下文信息,SourceContext 包含如下方法:
collect()方法:用于收集从外部数据源读取的数据并下发到下游算子中。collectWithTimestamp()方法:支持直接收集数据元素以及 EventTime 时间戳。emitWatermark()方法:用于在 SourceFunction 中生成 Watermark 并发送到下游算子进行处理。getCheckpointLock()方法:用于获取检查点锁(Checkpoint Lock),例如使用 KafkaConsumer 读取数据时,可以使用检查点锁,确保记录发出的原子性和偏移状态更新。
![[SourceContext-UML关系图.png]]
从上图中可以看出,SourceContext 主要有两种类型的实现子类,分别为 NonTimestampContext 和 WatermarkContext。顾名思义,WatermarkContext 支持事件时间抽取和生成 Watermark,最终用于处理乱序事件;而 NonTimestampContext 不支持基于事件时间的操作,仅实现了从外部数据源中读取数据并处理的逻辑,主要对应 TimeCharacteristic 为 ProcessingTime 的情况。
用户设定不同的 TimeCharacteristic,就会创建不同类型的 SourceContext,这里我们梳理SourceContext类型与TimeCharacteristic的对应关系如表2-1所示。
| TimeCharacteristic | SourceContext |
|---|---|
| IngestionTime(接入时间) | AutomaticWatermarkContext |
| ProcessingTime(处理时间) | NonTimestampContext |
| EventTime(事件时间) | ManualTimestampContext |
由此也可以看出,接入时间对应的 Timestamp 和 Watermark 都是通过 Source 算子自动生成的。事件时间的实现则相对复杂,需要用户自定义 SourceContext.emitWatermark() 方法来实现。
同时,SourceFunction 接口的实现类主要通过 run() 方法完成与外部数据源的交互,以实现外部数据的读取,并将读取到的数据通过 SourceContext 提供的 collect() 方法发送给 DataStream 后续的算子进行处理。常见的实现类有 ContinuousFileMonitoringFunction、FlinkKafkaConsumer 等。
StreamSource
SourceFunction 定义完毕后,会被封装在 StreamSource 算子中,StreamSource 继承自 AbstractUdfStreamOperator。在 StreamSource 算子中提供了 run() 方法实现,其通过 SourceStreamTask 实例调用和执行,SourceStreamTask 实际上是针对 Source 类型算子实现的 StreamTask 实现类。
public void run(
final Object lockingObject,
final Output<StreamRecord<OUT>> collector,
final OperatorChain<?, ?> operatorChain)
throws Exception {
// 从 OperatorConfig 中获取 TimeCharacteristic
final TimeCharacteristic timeCharacteristic = getOperatorConfig().getTimeCharacteristic();
// Task 的环境信息 Environment 中获取 Configuration 配置信息。
final Configuration configuration =
this.getContainingTask().getEnvironment().getTaskManagerInfo().getConfiguration();
final long latencyTrackingInterval =
getExecutionConfig().isLatencyTrackingConfigured()
? getExecutionConfig().getLatencyTrackingInterval()
: configuration.getLong(MetricOptions.LATENCY_INTERVAL);
// 创建 LatencyMarksEmitter 实例,主要用于在 SourceFunction 中输出 Latency 标记,
// 也就是周期性地生成时间戳,当下游算子接收到 SourceOperator 发送的 LatencyMark 后,
// 会使用当前的时间减去 LatencyMark 中的时间戳,以此确认该算子数据处理的延迟情况,
// 最后算子会将 LatencyMark 监控指标以 Metric 的形式发送到外部的监控系统中。
LatencyMarkerEmitter<OUT> latencyEmitter = null;
if (latencyTrackingInterval > 0) {
latencyEmitter =
new LatencyMarkerEmitter<>(
getProcessingTimeService(),
collector::emitLatencyMarker,
latencyTrackingInterval,
this.getOperatorID(),
getRuntimeContext().getIndexOfThisSubtask());
}
final long watermarkInterval =
getRuntimeContext().getExecutionConfig().getAutoWatermarkInterval();
// 创建 SourceContext,根据 TimeCharacteristic 参数创建对应类型的 SourceContext
// 将SourceContext实例应用在自定义的SourceFunction中,此时SourceFunction能够
// 直接操作SourceContext,例如收集数据元素、输出Watermark事件等
this.ctx =
StreamSourceContexts.getSourceContext(
timeCharacteristic,
getProcessingTimeService(),
lockingObject,
collector,
watermarkInterval,
-1,
emitProgressiveWatermarks);
try {
// 调用 userFunction.run(ctx) 方法,调用和执行SourceFunction实例
userFunction.run(ctx);
} finally {
if (latencyEmitter != null) {
latencyEmitter.close();
} }}SinkFunction 详解
SinkFunction 接口的主要作用是将上游的数据元素输出到外部数据源中。
在 SinkFunction 中同样需要关注和外部介质的交互,尤其对于支持两阶段提交的数据源来讲,此时需要使用 TwoPhaseCommitSinkFunction 实现端到端的数据一致性。在 SinkFunction 中也会通过 SinkContext 获取与 Sink 操作相关的上下文信息。
![[SinkFunction-UML关系图.png]]
如上图所示,SinkFunction 继承自 Function 接口,且 SinkFunction 仅有 RichSinkFunction 一种类型的子类。常见的 RichSinkFunction 实现类有 SocketClientSink 和 StreamingFileSink,对于支持两阶段提交的 TwoPhaseCommitSinkFunction,实现类主要有 FlinkKafkaProducer。
在 SinkFuntion 中也会创建和使用 SinkContext,以获取 Sink 操作过程需要的上下文信息。但相比于 SourceContext,SinkFuntion 中的 SinkContext 仅包含一些基本方法,例如获取 currentProcessingTime、currentWatermark 以及 Timestamp 等变量。在 StreamSink Operator 中提供了默认 SinkContext 实现,通过 SimpleContext 可以从 ProcessingTimeService 中获取当前的处理时间、当前最大的 Watermark 和事件中的 Timestamp 等信息。
TwoPhaseCommitSinkFunction 主要用于需要严格保证数据当且仅被输出一条的语义保障的场景。在 TwoPhaseCommitSinkFunction 中实现了和外围数据交互过程的 Transaction 逻辑,也就是只有当数据真正下发到外围存储介质时,才会认为 Sink 中的数据输出成功,其他任何因素导致写入过程失败,都会对输出操作进行回退并重新发送数据。目前所有 Connector 中支持 TwoPhaseCommitSinkFunction 的只有 Kafka 消息中间件,且要求 Kafka 的版本在 0.11 以上。
ProcessFunction 详解
在 Flink API 抽象栈中,最底层的是 Stateful Function Process 接口,代码实现对应的是 ProcessFunction 接口。通过实现 ProcessFunction 接口,能够灵活地获取底层处理数据和信息,例如状态数据的操作、定时器的注册以及事件触发周期的控制等。
根据数据元素是否进行了 KeyBy 操作,可以将 ProcessFunction 分为 KeyedProcessFunction 和 ProcessFunction 两种类型,其中 KeyedProcessFunction 使用相对较多,常见的实现类有 TopNFunction、GroupAggFunction 等函数;ProcessFunction 的主要实现类是 LookupJoinRunner,主要用于实现维表的关联等操作。Table API 模块相关的 Operator 直接实现自 ProcessFunction 接口。
如下图所示,KeyedProcessFunction 主要继承了 AbstractRichFunction 抽象类,且在内部同时创建了 Context 和 OnTimerContext 两个内部类,其中 Context 主要定义了从数据元素中获取 Timestamp 和从运行时中获取 TimerService 等信息的方法,另外还有用于旁路输出的 output() 方法。OnTimerContext 则继承自 Context 抽象类,主要应用在 KeyedProcessFunction 的 OnTimer() 方法中。在 KeyedProcessFunction 中通过 processElement 方法读取数据元素并处理,会在 processElement() 方法中根据实际情况创建定时器,此时定时器会被注册到 Context 的 TimerService 定时器队列中,当满足定时器触发的时间条件后,会通过调用 OnTimer() 方法执行定时器中的计算逻辑,例如对状态数据的异步清理操作。
![[KeyedProcessFunction-UML关系图.png]]
Table API 中的 DeduplicateKeepLastRowFunction 实例实现了 KeyedProcessFunction。DeduplicateKeepLastRowFunction 主要用于对接入的数据去重,并保留最新的一行记录。可以学习一下。