本文主要对 Flink Time 和 Window 进行分析。
Time 时间
在整个流数据处理的过程中,针对时间信息的处理可以说是非常普遍的,尤其在涉及窗口计算时,会根据设定的 TimeCharacteristic 是事件时间还是处理时间,选择不同的数据方式处理接入的数据。每个 Operator 内部都维系了一个 TimerService,专门用于处理与时间相关的操作。例如获取当前算子中最新的处理时间以及 Watermark、注册不同时间类型的定时器等。
Flink 数据中的 Time(时间)分为以下 3 种:
- Event Time:事件产生的时间,它通常由事件中的时间戳描述
- Ingestion Time:事件进入Flink的时间
- Processing Time:事件被处理时当前系统的时间
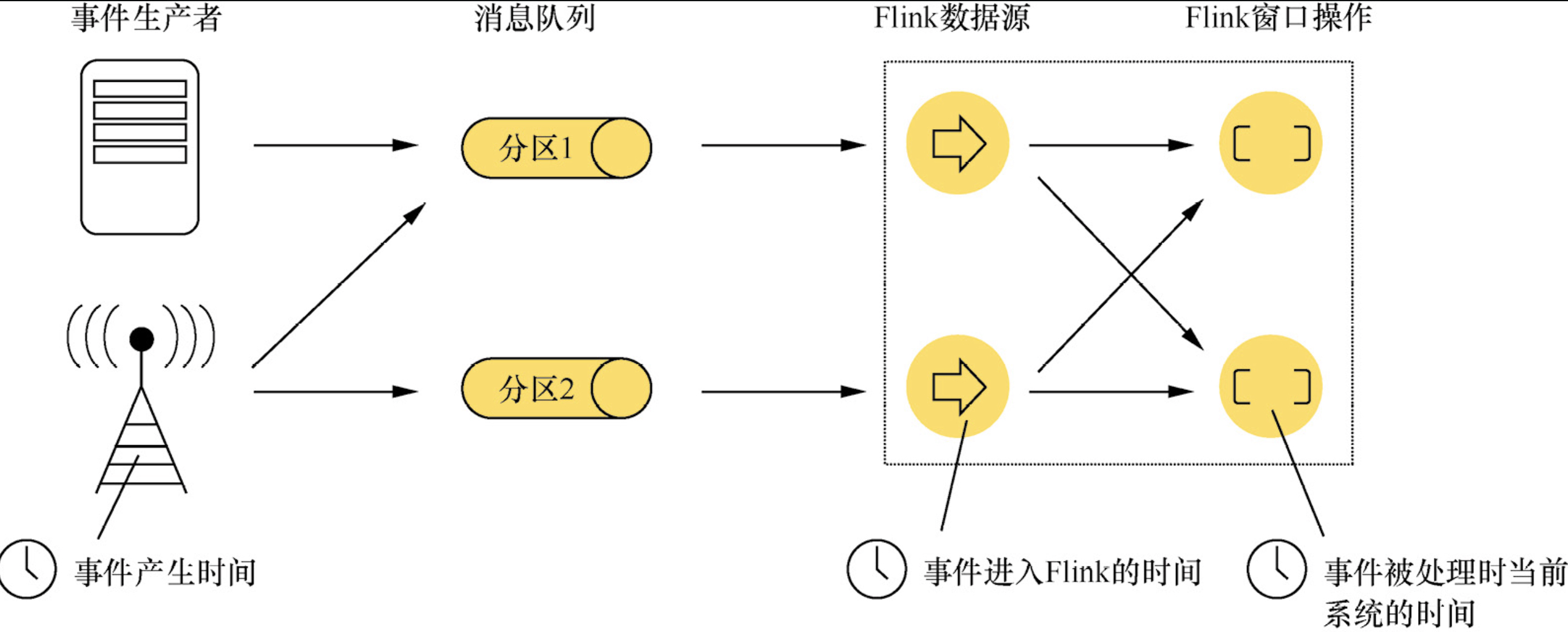
默认情况下,Flink 在 Stream 程序中处理数据使用的时间是 ProcessingTime,想要修改使用时间可以使用 setStreamTimeCharacteristic()。
![[Flink时间概念对比.png]]
抽取 Timestamp 和生成 Watermark 的方式
在 SourceFunction 中抽取 Timestamp 和生成 Watermark
在 SourceFunction 中读取数据元素时,SourceContext 接口中定义了抽取 Timestamp 和生成 Watermark 的方法,如 collectWithTimestamp(T element, long timestamp) 和 emitWatermark(Watermark mark) 方法。如果 Flink 作业基于事件时间的概念,就会使用 StreamSourceContexts.ManualWatermarkContext 处理 Watermark 信息。
WatermarkContext.collectWithTimestamp() 方法直接从 Source 算子接入的数据中抽取事件时间的时间戳信息。
@Override
public final void collectWithTimestamp(T element, long timestamp) {
synchronized (checkpointLock) {
processAndEmitWatermarkStatus(WatermarkStatus.ACTIVE);
if (nextCheck != null) {
this.failOnNextCheck = false;
} else {
scheduleNextIdleDetectionTask();
}
// 抽取 Timestamp 信息
processAndCollectWithTimestamp(element, timestamp);
}
}生成 Watermark 主要是通过调用 WatermarkContext.emitWatermark() 方法进行的。生成的 Watermark 首先会更新当前 Source 算子中的 CurrentWatermark,然后将 Watermark 传递给下游的算子继续处理。当下游算子接收到 Watermark 事件后,也会更新当前算子内部的 CurrentWatermark。
@Override
public final void emitWatermark(Watermark mark) {
if (allowWatermark(mark)) {
synchronized (checkpointLock) {
processAndEmitWatermarkStatus(WatermarkStatus.ACTIVE);
if (nextCheck != null) {
this.failOnNextCheck = false;
} else {
scheduleNextIdleDetectionTask();
}
processAndEmitWatermark(mark);
}
}
}SourceFunction 接口主要调用 WatermarkContext.emitWatermark() 方法生成并输出 Watermark 事件,在 emitWatermark() 方法中会调用 processAndEmitWatermark() 方法将生成的 Watermark 实时发送到下游算子中继续处理。
通过 DataStream 中的独立算子抽取 Timestamp 和生成 Watermark
在 DataStream API 中 assignTimestampsAndWatermarks 提供了抽取 Timestamp 和生成 Watermark 的能力,其支持 Watermark 空闲,并且不再区别 periodic 和 punctuated。
当没有新数据到达时,WatermarkGenerator 是无法生成 Watermark 的,这会导致任务无法继续运行。例如 Kafka Topic 有 2 个 Partition,其中一个 Partition 数据量比较少,可能存在长时间没有新数据的情况,这就导致该 Watermark 一直是较早数据产生的。即使另一个 Partition 始终有新数据,那么任务也不会往下运行,因为水印对齐取的是最小值。为了解决这个问题,WatermarkStrategy 提供了 withIdleness 方法,允许传入一个 timeout 的时间。
在 DataStream API 中提供了 3 种与抽取 Timestamp 和生成 Watermark 相关的 Function 接口,分别为TimestampExtractor、AssignerWithPeriodicWatermarks 以及 AssignerWithPunctuatedWatermarks。
如下图所示,在 TimestampAssigner 接口中定义抽取 Timestamp 的方法。然后分别在 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 接口中定义生成 Watermark 的方法。
AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 的区别如下所示:
- AssignerWithPeriodicWatermarks:事件时间驱动,会周期性地根据事件时间与当前算子中最大的 Watermark 进行对比,如果当前的 EventTime 大于 Watermark,则触发 Watermark 更新逻辑,将最新的 EventTime 赋予 CurrentWatermark,并将新生成的 Watermark 推送至下游算子。
- AssignerWithPunctuatedWatermarks:特殊事件驱动,主要根据数据元素中的特殊事件生成 Watermark。例如数据中有产生 Watermark 的标记,接入数据元素时就会根据该标记调用相关方法生成 Watermark。
https://stackoverflow.com/questions/70718596/upgrading-flink-deprecated-function-calls
https://zhuanlan.zhihu.com/p/344540564
Window
Flink 认为 Batch 是 Streaming 的一个特例,因此 Flink 底层引擎是一个流式引擎,在上面实现了流处理和批处理。而 Window 就是从 Streaming 到 Batch 的桥梁。
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,从而在有界的数据集上进行操作的一种机制。也可以说,窗口是另一类算子,是 DataStream 的逻辑边界,在第一个元素到达后被创建,在生命周期结束后被销毁,但引擎不会确保及时销毁诸如全局窗口(Global Window)这类与时间无关的窗口。
除了开窗机制,应用程序还可以定义触发器(Trigger)、迟到生存期、窗口聚合函数(Window Function)及清除器(Evictor)。
Window 分类
按操作分类
窗口分为两大类,即 Keyed Window 和 Non-Keyed Window。在 KeyedStream 上定义 window(...)得到 Keyed Window,在 DataStream 上定义 windowAll(...)得到 Non-Keyed Window。以下是这两类窗口的定义与转换,并不是所有转换应用程序都需要,其中标记为 […] 的转换是可选的操作:
// Keyed Window 定义与转换
stream
.keyBy(...)
.window(...)
[.trigger(...)]
[.evictor(...)]
[.allowedLateness(...)]
[.sideOutputLateData(...)]
.reduce/aggregate/...
[.getSideOutput(...)]
// Non-Keyed Window 定义与转换
stream
.windowAll(...)
[.trigger(...)]
[.evictor(...)]
[.allowedLateness(...)]
[.sideOutputLateData(...)]
.reduce/aggregate/...
[.getSideOutput(...)]按边界分类
对流中的所有元素进行计数是不可能的,因为通常流是无限的(无界的)。因此,流上的聚合需要由 Window 来划定范围,比如 “计算过去的5min” 或者 “最后100个元素的和”。Window 可以由时间(Time Window)(如每30s)或者数据(Count Window)(如每100个元素)驱动。
DataStream API 提供了 Time 和 Count 的 Window。同时,由于某些特殊的需要,DataStream API 也提供了定制化的 Window 操作,供用户自定义 Window。

Window 根据类型可以分为两种:
- Tumbling Window 滚动窗口:滚动窗口的时间长度是固定的,且不同时间区间的窗口不会重叠,可根据事件时间和处理时间定义。除了时间长度,还可以设定窗口的时间对齐方式。
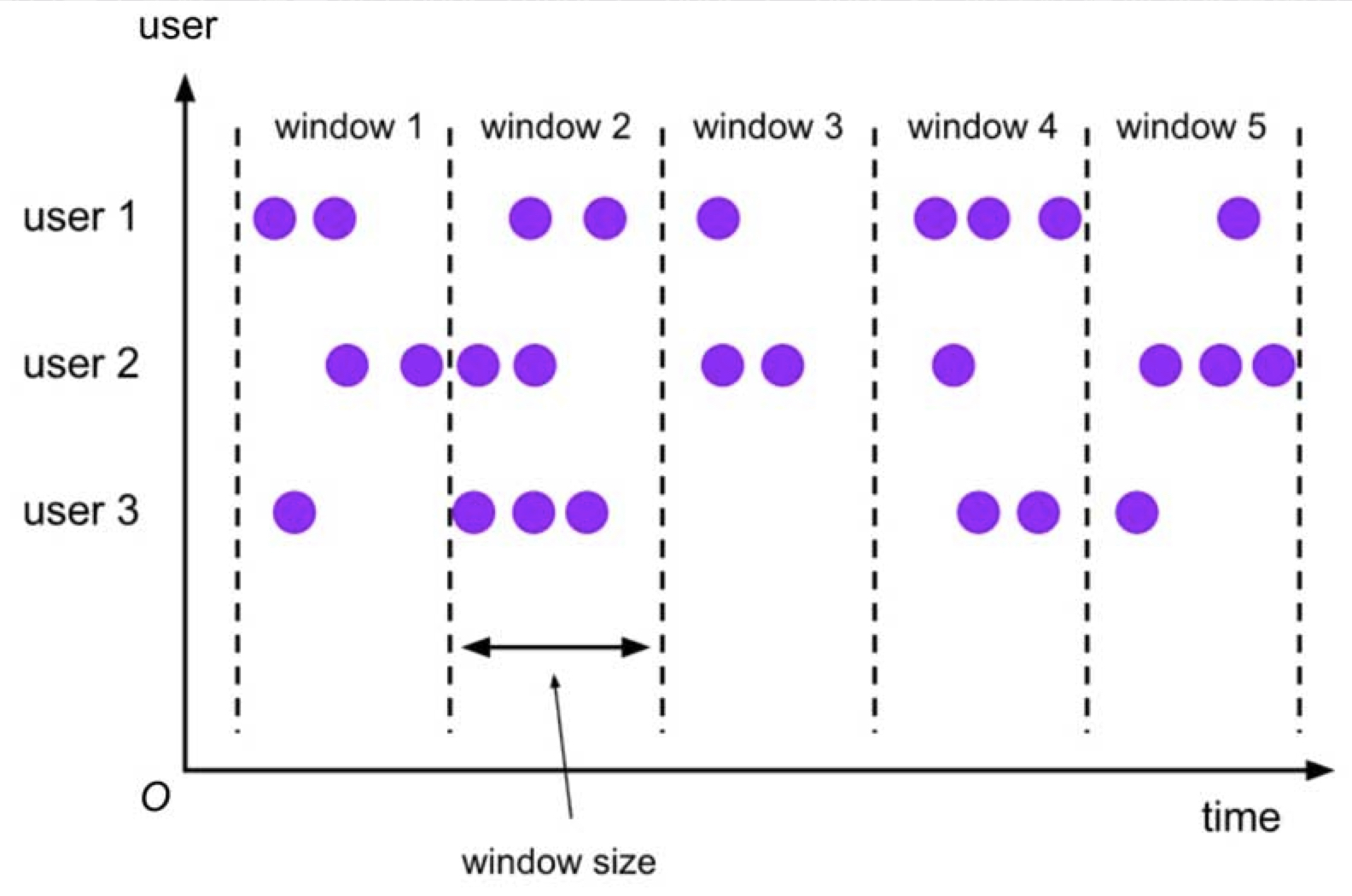
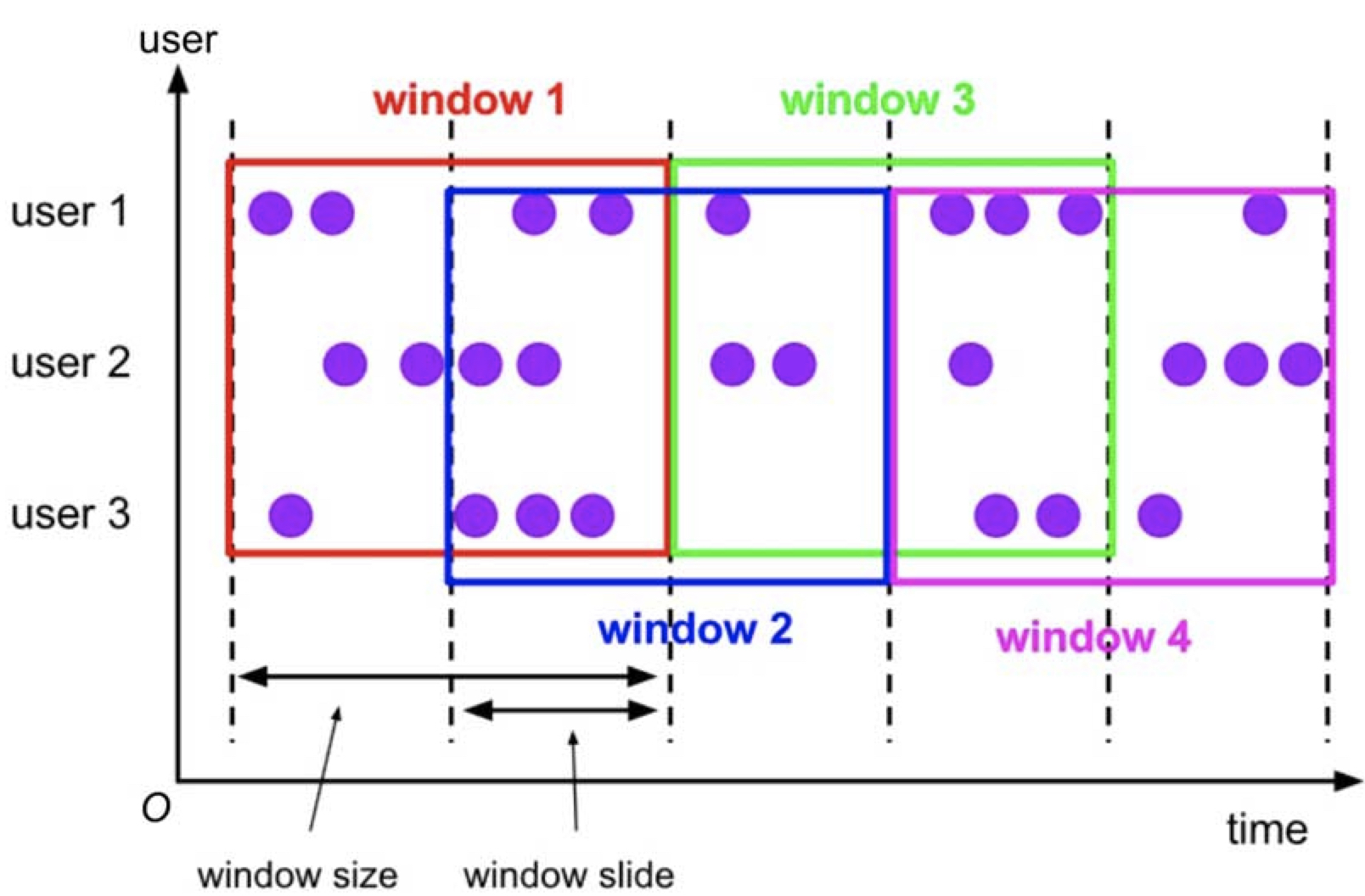
- Sliding Window 滑动窗口:滑动窗口按照滑动步长将时间拆分成固定长度的窗口,当滑动步长小于窗口长度时,相邻窗口间会重叠。
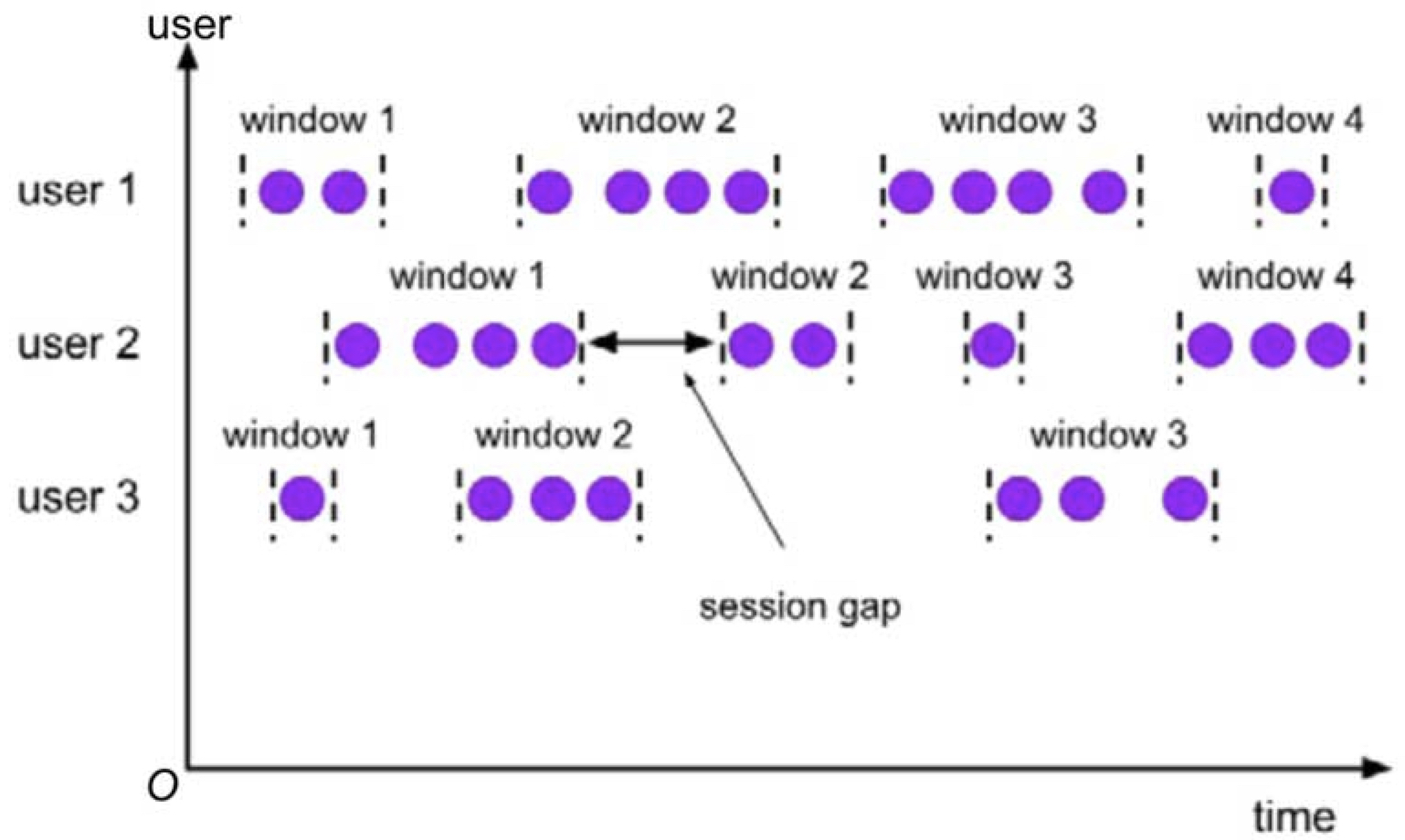
- Session Window 会话窗口:根据相邻元素之间的时间间隔确定会话窗口的边界,其分为固定时间间隔(Static Gap)和动态时间间隔(Dynamic Gap)两种类型,其中动态时间间隔由应用程序编程实现。
- Global Window 全局窗口:将相同 key 的所有元素聚在一起,但是这种窗口没有起点也没有终点,因此必须自定义触发器。
按聚合分类
Window 聚合操作分为两种:一种是增量聚合,一种是全量聚合。
增量聚合
增量聚合是指窗口每进入一条数据就计算一次。
常见的增量聚合函数:reduce、aggregate、sum、min、max。
全量聚合
全量聚合是指在窗口触发的时候才会对窗口内的所有数据进行一次计算。
常见的全量聚合函数:apply、process。
触发器
public abstract class Trigger<T, W extends Window>
触发器原型中包括 4 类触发机制,基于事件驱动。
- onElement:窗口每收到一个元素调用一次该方法,返回结果决定是否触发算子函数。
- onProcessingTime:根据注册的处理时间定时器触发,定时时间由参数 time(long time)设定。
- onEventTime:根据注册的事件时间定时器触发,定时时间由参数 time 设定。
- onMerge:两个窗口合并时触发。
前三类触发机制的结果(TriggerResult)分为以下 4 种情况。
- 忽略(CONTINUE)
- 触发(FIRE)
- 清除(PURGE):清空窗口内所有元素,窗口被销毁
- 触发并清除(FIRE_AND_PURGE):触发窗口函数,并在函数执行结束后清空窗口内所有元素,窗口被销毁
Flink 提供几类内置触发器:
| 触发器 | 介绍 |
|---|---|
| EventTimeTrigger | 根据事件时间轴上的水印触发 |
| ProcessingTimeTrigger | 根据处理时间触发 |
| CountTrigger | 根据窗口内元素的数量触发 |
| ContinuousEventTimeTrigger | 将事件时间轴分成等间隔的窗格,在每一个窗格内判断水印来决定是否触发 |
| ContinuousProcessingTimeTrigger | 将处理时间轴分成等间隔的窗格,在每一个窗格内触发一次,但是需要根据相关条件判断是否调用窗口函数 |
| DeltaTrigger | 根据某种特征是否超过指定的阈值决定是否触发 |
| PurgingTrigger | 将其他触发器转化成清除触发器,即销毁窗口 |
清除器
清除器(Evictor)在触发器触发后,窗口函数执行前或执行后清除窗口内元素,相应地,有以下两个方法:
@PublicEvolving
public interface Evictor<T, W extends Window> extends Serializable {
// 在触发器被触发后,窗口函数执行前清除窗口内元素
void evictBefore(
Iterable<TimestampedValue<T>> elements,
int size,
W window,
EvictorContext evictorContext);
// 在触发器被触发后,窗口函数执行后清除窗口内元素
void evictAfter(
Iterable<TimestampedValue<T>> elements,
int size,
W window,
EvictorContext evictorContext);Flink提供三种内置清除器:
| 清除器 | 介绍 |
|---|---|
| CountEvictor | 保持窗口内元素数量为预定值 |
| DeltaEvictor | 根据元素之间的关系,清除超过指定阈值的元素 |
| TimeEvictor | 根据窗口内元素的时间戳决定清除哪些元素 |
Time
Watermark
在使用 EventTime 处理 Stream 数据的时候会遇到数据乱序的问题,流处理从 Event(事件)产生,流经 Source,再到 Operator,这中间需要一定的时间。虽然大部分情况下,传输到 Operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因而导致乱序的产生,特别是使用 Kafka 的时候,多个分区之间的数据无法保证有序。因此,在进行 Window 计算的时候,不能无限期地等下去,必须要有个机制来保证在特定的时间后,必须触发 Window 进行计算,这个特别的机制就是 Watermark。
Watermark 是用于处理乱序事件的。
应用场景
Watermark 有三种应用场景:
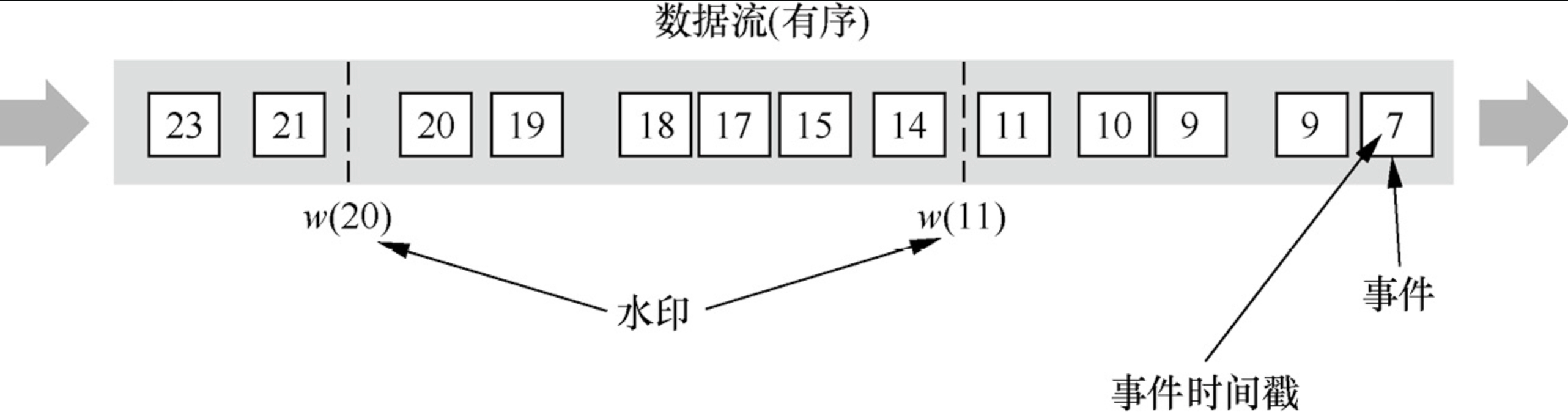
1. 有序的 Stream 中的 Watermark
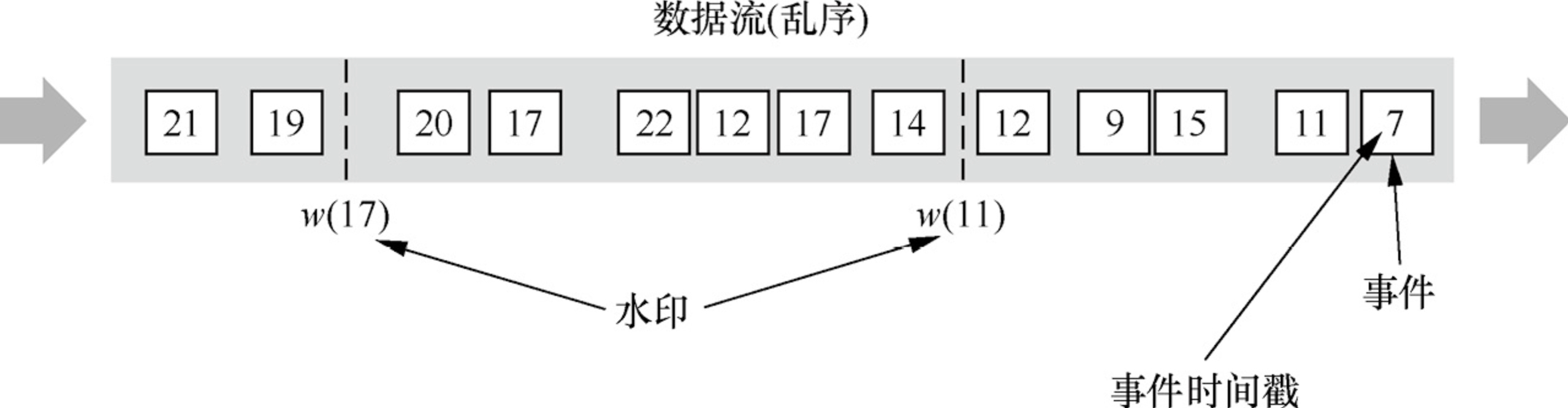
2. 无序的 Stream 中的 Watermark
3. 多并行度的 Stream 中的 Watermark
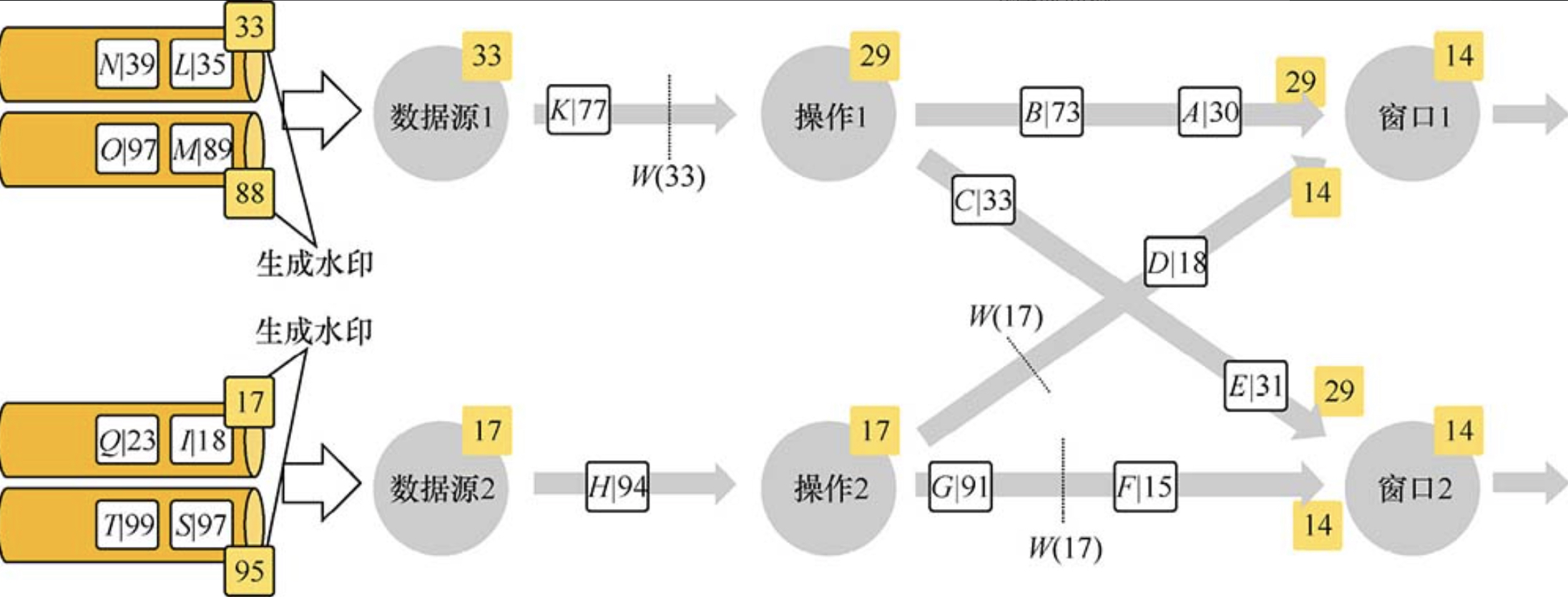
注意:在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel 中最小的 Watermark,图中的 14 和 29 这两个 Watermark 的最终取值为 14。
生成方式
通常情况下,在接收到 Source 的数据后,应该立刻生成 Watermark,但是也可以在应用简单的 Map 或者 Filter 操作后再生成 Watermark。注意:如果指定多次 Watermark,后面指定的值会覆盖前面的值。
Watermark 的生成方式有两种:
1. With Periodic Watermarks:周期性地触发 Watermark 的生成和发送
周期性地触发 Watermark 的生成和发送,默认是 100ms。每隔 N 秒自动向流里注入一个 Watermark,时间间隔由 ExecutionConfig.setAutoWatermarkInterval 决定。每次调用 getCurrentWatermark 方法,如果得到的 Watermark 不为空并且比之前的大,就注入流中。可以定义一个最大允许乱序的时间,这种比较常用。实现 AssignerWithPeriodicWatermarks 接口。
2. With Punctuated Watermarks:基于事件触发 Watermark 的生成和发送
基于事件向流里注入一个 Watermark,每一个元素都有机会判断是否生成一个 Watermark。如果得到的 Watermark 不为空并且比之前的大,就注入流中。实现 AssignerWithPunctuatedWatermarks 接口。
3. With Ascending Watermark:递增式 Watermark 的生成和发送
在使用 Kafka 作为数据源时,每个分区的消息时间通常是递增的,但 Source 节点从多个消息分区并行拉取数据时这种时间特征会被破坏,这时可以在连接器端创建 Kafka 分区水印(Kafka-partition-aware watermark),以确保多分区消息的升序排列
Window 触发的条件:
- Watermark 的时间大于
window_end_time- 在窗口时间
[window_start_time, window_end_time)中有数据存在
延后数据的处理
针对延迟数据,Flink 有 3 种处理方案:
丢弃(默认)
输入的数据所在的窗口已经执行过了,Flink 默认对这些延迟的数据的处理方案就是丢弃。
允许数据延迟
Flink 提供了 allowedLateness 方法,它可以实现对延迟的数据设置一个延迟时间,在指定延迟时间内到达的数据可以触发 Window。且每条延迟时间到达的数据都会触发一次 Window。
收集延迟数据
通过 sideOutputLateData 函数可以把延迟数据统一收集、统一存储,方便后期排查问题。