本文主要对 Flink State(状态)进行分析,包含状态的管理和恢复,以及 Flink 中的任务重启策略。
State
State 一般指一个具体的 Task/Operator 的状态,State 数据默认保存在 Java 的堆内存中。而 CheckPoint(可以理解为 CheckPoint 是把 State 数据持久化存储了)则表示了一个 Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有 Task/Operator 的状态。注意:Task 是 Flink 中执行的基本单位,Operator 是算子(Transformation)。State 可以被记录,在失败的情况下数据还可以恢复。
Flink 中有两种基本类型的 State:Keyed State、Operator State。
Keyed State 和 Operator State 以两种形式存在。
- 原始状态(Raw State):由用户自行管理状态具体的数据结构,框架在做 CheckPoint 的时候,使用
byte[]读写状态内容,对其内部数据结构一无所知。 - 托管状态(Managed State):由Flink框架管理的状态。通常在 DataStream 上推荐使用托管状态,当实现一个用户自定义的 Operator 时使用到原始状态。
Keyed State
Keyed State,顾名思义就是基于 KeyedStream 上的状态,这个状态是跟特定的 Key 绑定的。KeyedStream 流上的每一个 Key,都对应一个 State。
Flink 针对 Keyed State 提供了以下可以保存 State 的数据结构。
ValueState<T>:单值状态,可以通过 update 方法更新状态值,通过 value 方法获取状态值。ListState<T>:List 状态,可以通过 add 方法往列表中附加值,也可以通过 get 方法返回一个Iterable<T>来遍历状态值。ReducingState<T>:Reduce状态,每次调用 add 方法添加值的时候,会调用用户传入的 ReduceFunction,最后合并到一个单一的状态值。MapState<UK, UV>:Map 状态,用户通过 put 或 putAll 方法添加元素。
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值有可能存在于内存、磁盘或者其他分布式存储系统中,相当于我们只是持有了这个状态的句柄。
Operator State
Operator State 与 Operator 绑定,整个 Operator 只对应一个 State。
Flink 针对 Operator State 提供了 ListState<T>。
State 容错
State 的容错需要依靠 CheckPoint 机制,这样才可以保证 Exactly-once 这种语义,但是注意,它只能保证 Flink 系统内的 Exactly-once,比如 Flink 内置支持的算子。针对 Source 和 Sink 组件,如果想要保证 Exactly-once 的话,则这些组件本身应支持这种语义。
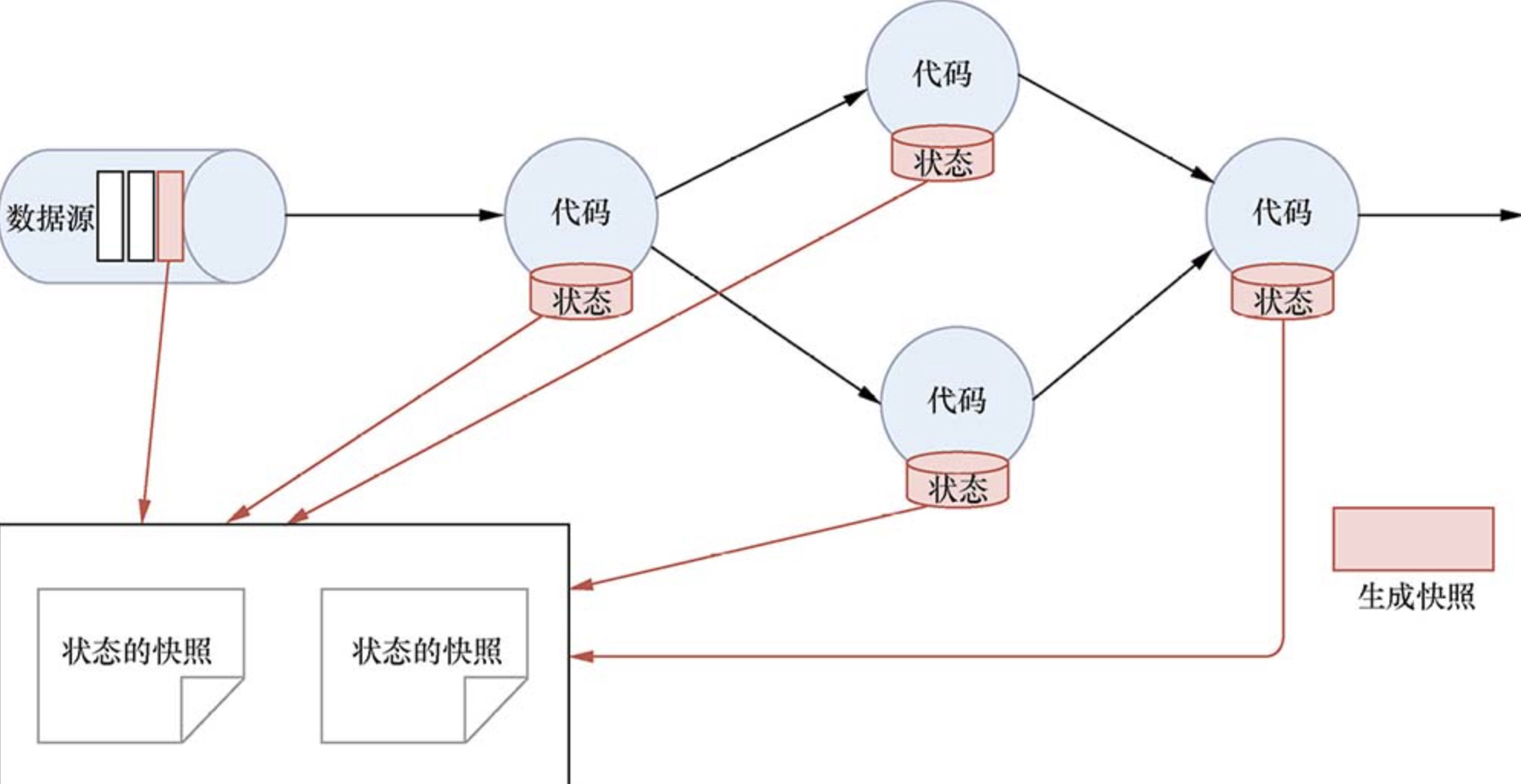
1. 生成快照
Flink通过CheckPoint机制可以实现对Source中的数据和Task中的State数据进行存储。
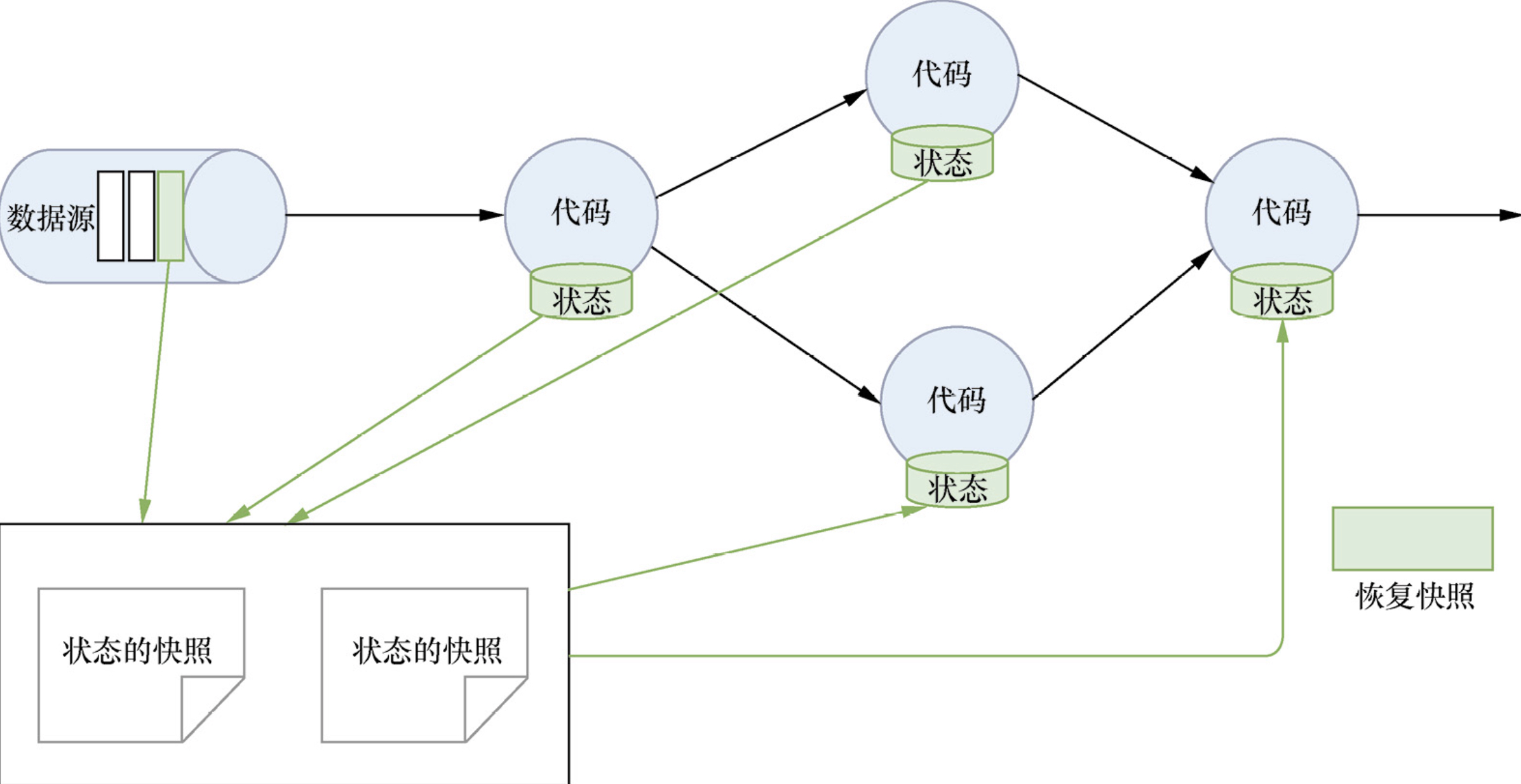
2. 恢复快照
Flink 还可以通过 Restore 机制来恢复之前 CheckPoint 快照中保存的 Source 数据和 Task 中的 State 数据。
CheckPoint
为了保证 State 的容错性,Flink 需要对 State 进行 CheckPoint。CheckPoint 是 Flink 实现容错机制的核心功能,它能够根据配置周期性地基于 Stream 中各个 Operator/Task 的状态来生成快照,从而将这些状态数据定期持久化存储下来。Flink 程序一旦意外崩溃,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常。
Flink 的 CheckPoint 机制可以与 Stream 和 State 持久化存储交互的前提有以下两点。
- 需要有持久化的 Source,它需要支持在一定时间内重放事件,这种 Source 的典型例子就是持久化的消息队列(如 Apache Kafka、RabbitMQ 等)或文件系统(如 HDFS、S3、GFS 等)。
- 需要有用于 State 的持久化存储介质,比如分布式文件系统(如HDFS、S3、GFS等)。
默认情况下,CheckPoint 功能是 Disabled(禁用)的,使用时需要先开启它。
env.enableCheckpointing(1000, CheckpointingMode.EXACTLY_ONCE);
// 其中 1000 设置了 CheckpointInterval
// EXACTLY_ONCE 设置了 CheckPointMode其他配置项的设置方式为 (StreamExecutionEnvironment) env.getCheckpointConfig().xxx。
| 配置 | 含义 | 备注 |
|---|---|---|
| CheckPointMode | 检查点模式 | EXACTLY_ONCE 确保一次,AT_LEAST_ONCE 至少一次 |
| CheckpointInterval | 检查点间隔 | 间隔指定时间创建检查点 |
| MinPauseBetweenCheckpoints | 检查点最小间隔 | |
| CheckpointTimeout | 检查点超时时间 | 检查点必须在指定时间内完成,或者被丢弃 |
| MaxConcurrentCheckpoints | 最大检查点并发数 | 同一时间只允许操作指定个数的检查点 |
| ExternalizedCheckpointCleanup | 具体的检查点清理策略 | DELETE_ON_CANCELLATION JOB失败时保存检查点、取消时不保存, RETAIN_ON_CANCELLATION JOB失败或取消时均保存检查点, NO_EXTERNALIZED_CHECKPOINTS 不保存检查点 |
TODO
env.getCheckpointConfig().setTolerableCheckpointFailureNumber();
env.getCheckpointConfig().setAlignedCheckpointTimeout();
env.getCheckpointConfig().setCheckpointStorage();
env.getCheckpointConfig().setCheckpointIdOfIgnoredInFlightData();
env.getCheckpointConfig().setForceUnalignedCheckpoints();
env.getCheckpointConfig().enableApproximateLocalRecovery();
env.getCheckpointConfig().enableUnalignedCheckpoints();设置检查点持久化
默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint 会存储在 JobManager 的内存中。State 和 CheckPoint 的存储位置取决于 StateBackend 的配置。Flink 提供了多种场景下的 StateBackend:
- 内存存储 CheckPoint
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());- 文件存储 CheckPoint
// 本地文件
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///data/checkpoint.data");
// 分布式文件- RocksDB CheckPoint
env.setStateBackend(new EmbeddedRocksDBStateBackend());
env.getCheckpointConfig().setCheckpointStorage("hdfs:///flink-checkpoints");以上只是在代码中修改配置,还可以通过 YAML 的方式设置 state.backend、state.checkpoints.dir 。另外,默认情况下,Flink 只保留最近成功生成的 1 个 CheckPoint,而当 Flink 程序失败时,可以通过最近的 CheckPoint 来进行恢复。但是,如果希望保留多个 CheckPoint,需要在 YAML
中进行配置 state.checkpoints.num-retained,并且能够根据实际需要选择其中一个进行恢复。
SavePoint
Flink 通过 SavePoint 功能可以升级程序,然后继续从升级前的那个点开始执行计算,保证数据不中断。SavePoint 可以生成全局、一致性的快照,也可以保存数据源、Offset、Operator 操作状态等信息,还可以从应用在过去任意做了 SavePoint 的时刻开始继续执行。
与 CheckPoint 不同的是,CheckPoint 是定时触发,且会过期,在内部应用失败重启的时候使用。SavePoint 是用户手动触发,是指向 CheckPoint 的指针,其不会过期,一般在升级的情况下使用。
注意:为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐通过 UID (String)方法手动给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变,就能从保存点(SavePoint)恢复程序。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动设置 ID。
- 设置 SavePoint 存储位置
设置该配置项并不是必须的,但是在设置后,如果要创建指定 Job 的 SavePoint 可以不需要手动执行命令时指定 SavePoint 位置。
state.savepoints.dir: hdfs://hadoop100:9000/Flink/savepoints- 触发 SavePoint
直接触发 SavePoint
bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]在调用 cancel 的时候触发 SavePoint
bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]- 从指定的 SavePoint 启动Job
bin/flink run -s savepointPath [runArgs]Restart Strategy
集群在启动时会伴随一个默认的重启策略 ,在没有定义具体重启策略时会使用该默认策略;如果在任务提交时指定了一个重启策略,该策略会覆盖集群的默认策略。
常用的策略如下。
1. 无重启
如果没有启用 CheckPoint,则使用无重启策略。
YAML 全局配置
restart-strategy: none任务独立配置
env.setRestartStrategy(RestartStrategies.noRestart());1. 固定间隔
如果启用了 CheckPoint,但没有配置重启策略,则使用固定间隔策略,其中 Integer.MAX_VALUE 参数是允许尝试重启的次数。
YAML 全局配置
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10 s任务独立配置
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 间隔
));2. 失败率
YAML 全局配置
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s任务独立配置
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 一个时间段内的最大失败次数
Time.of(5, TimeUnit.MINUTES), // 衡量失败次数的是时间段
Time.of(10, TimeUnit.SECONDS) // 间隔
));