计算图是 Flink 组织流处理节点的架构形式,将复杂事件处理抽象成模式图的形式是这种思路的延续。类比计算图中的节点,模式图由基本模式构建,并以拼合、分组的方式形成复杂的处理模式。FlinkCEP(Complex Event Process for Flink)是以库的形式提供的,是一种全新的、定义在流式架构上的模式匹配 API,如复杂谓词、多种匹配模式、闭包。在 Maven 工程中需要加入 flink-cep 依赖。
复杂事件处理的自动机理论
有穷自动机模型 NFA
有穷自动机是为计算机建模而引入的,因此在有穷自动机 M1 中我们假定状态机的输入是由 0 和 1 组成的字符串。有穷自动机 M1 有三个状态,记作 q1、q2 和 q3:用一个无出发点的箭头表示起始状态(如图 7-1 中起始状态 q1 左侧的箭头所示);用双圈表示接受状态(如图 7-1 中的 q3 所示);用从一个状态指向另一个状态的箭头表示转移,箭头上的数字表示状态转移的条件;这个机器处理接收的输入字符串,输出是接受或拒绝,即模式匹配中的匹配或不匹配。
![[Pasted image 20230321093340.png]]
当这个机器接收到字符串 110 时,状态的转移过程如下:
- 初始状态为
q1 - 读入第一个字符 1,状态转移到
q2 - 读入字符 1,状态保持为
q2 - 读入字符 0,状态转移到
q3 - 最终状态为接受状态,因此输出为接受
有穷状态机定义为一个五元组 (Q, W, R, q0, F):
- 称有穷集合
Q为状态集 - 称有穷集合
W为字母表,即允许的输入符号的集合。在有穷自动机 M1 中,字母表中仅有 0 和 1 两个字符 - 称
R: Q ✖️ W -> Q为转移函数。转移函数描述了有穷自动机状态图中所有的状态转移规则 q0是初始状态F是接受状态集,有穷自动机允许有多个接受状态,也允许没有接受状态。
在确定型有穷自动机(DFA,Deterministic Finite Automaton)M1 中,我们发现每一个状态的所有转移条件是互斥的,或者说,自动机每次读入一个符号时可以事先知道机器的下一个状态,如状态 q1 在转移条件为 0 时转移至 q1,在转移条件为 1 时转移至 q2。而在非确定型有穷自动机(NFA,Nondeterministic Finite Automaton)中,对于任何一个状态,要转移的下一个状态可能存在若干个非互斥的选择,下图所示为非确定型有穷自动机 M2。
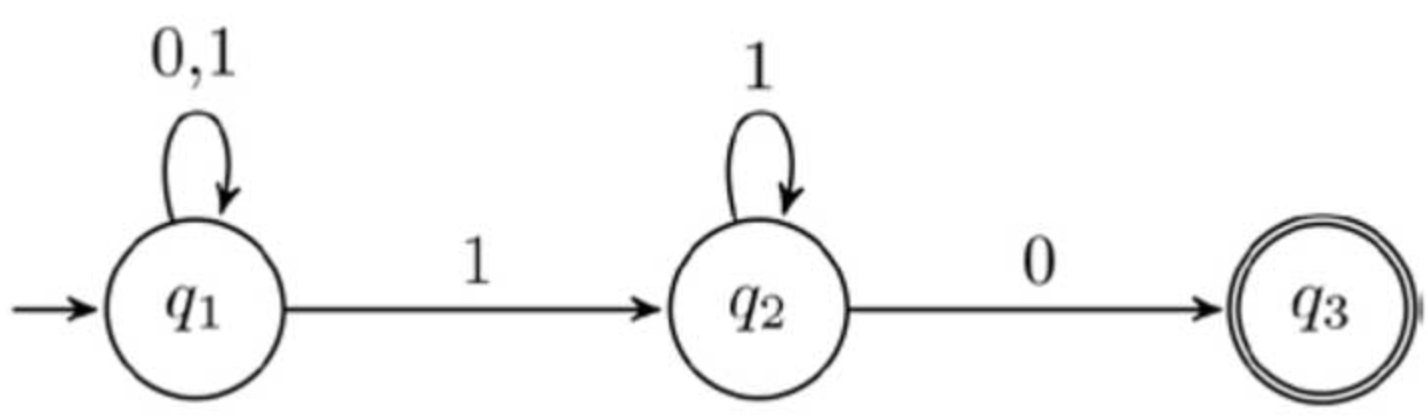
状态 q1 对转移条件 1 有两个转移箭头,因此,当读入 1 时状态机分为两个过程,其中一个过程中的机器状态为 q2,另一个过程中的机器停留在 q1 状态,当再次读入 1 时,一个过程继续分为两个过程。因此,可以将一台 NFA 拆解成一台 DFA,即每一台非确定型有穷自动机都等价于某一台确定型有穷自动机,但是由于构造 NFA 通常比直接构造 DFA 更容易,且 NFA 的功能更易于理解,在基于自动机的构造设计中通常采用 NFA 形式论证,如接下来要分析的 NFA b 模型。
$NFA^b$ 模型
事件处理 $NFA^b$ 模型包括一台 NFA 和一个匹配缓冲区(match buffer),表示为 A = (Q, E, θ, q1, F),其中 Q 为状态集,E 为有向边,θ 为状态转移条件,q1 为初始状态,F 为接受状态。下图所示为 Query 2 程序对应的自动机 $NFA^b$ 模型(以下简称为 Query 2 自动机)。
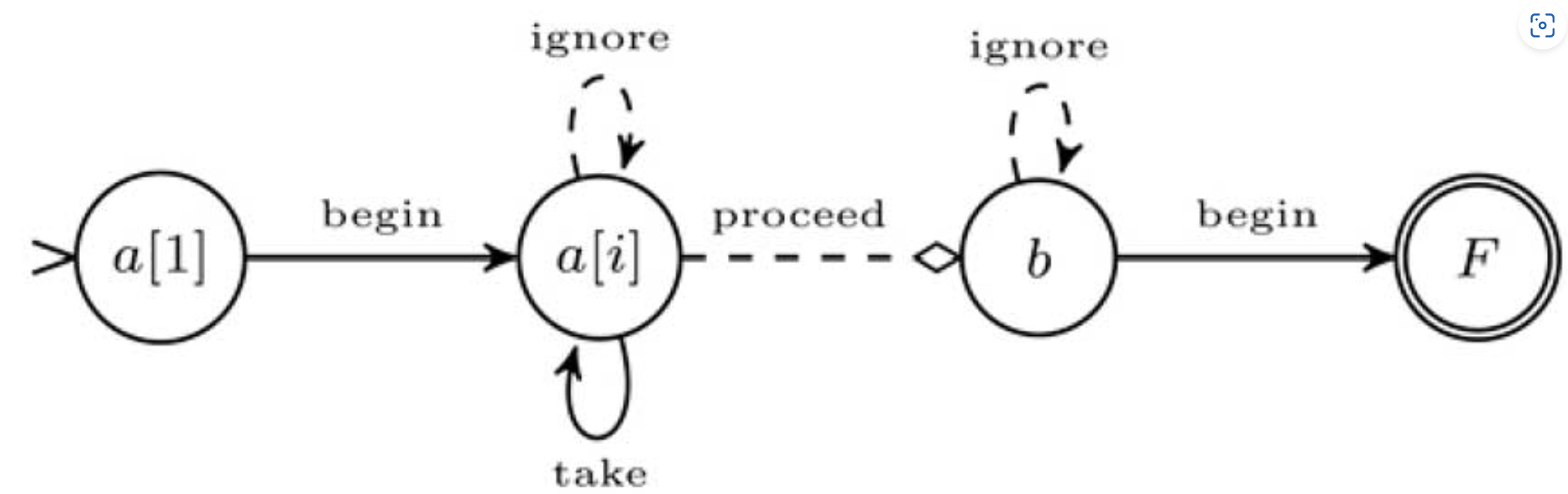
1. 状态
在 Query 2 自动机中,以缓存名称命名状态,以起始状态 $a[1]$ 为例,自动机将初始事件存储在 $a[1]$ 中,这是 Kleene 闭包的起始点。后续匹配的事件将存储在 $a[i]$ 中,对应状态为 $a[i]$。在 Kleene 闭包匹配完成后,b 存储下一个匹配事件。
2. 边
每一条边定义一种状态转移路径。有 4 类边:
take表示事件匹配成功,用于当前状态到自身的转移,如 Query 2 自动机中的 $a[i]$ 状态,take 将当前事件存储在 $a[i]$ 中ignore表示事件匹配不成功,当前状态不转移,与 take 的区别是当前事件不存储在 $a[i]$ 中proceed表示转移下一个状态,当前事件不存储在当前状态对应的缓存中begin表示当前状态的开始,在 Query 2 自动机中,状态 $a[1]$ 匹配成功后,下一个事件将进入 $a[i]$ 状态
边有三个转移属性:
- 转移条件,用状态加转移类型表示,如 $θ_{a[i]_take}$
- 对输入的操作,如消费当前事件(匹配当前事件,再读入新的事件)
- 匹配缓存的操作,如将匹配的事件写入缓存。
无界数据集上的 $NFA^b$ 模型是复杂的,因为无法定义自动机的匹配起点。因此,同一个窗口内的数据可能会对应多个并行的模式匹配过程。此外,非确定型有穷自动机在执行过程中也会存在多个分叉过程。这种并行模式匹配过程不仅导致运行时异常复杂,也会拉长执行时间。
FlinkCEP API
计算图是 Flink 组织流处理节点的架构形式,将复杂事件处理抽象成模式图的形式是这种思路的延续。类比计算图中的节点,模式图由基本模式构建,并以拼合、分组的方式形成复杂的处理模式。
FlinkCEP(Complex Event Process for Flink)是以库的形式提供的,需要加入
flink-cep的 Maven 依赖。
模式API
模式 API 可以让你定义想从输入流中抽取的复杂模式序列。
每个复杂的模式序列包括多个简单的模式,比如,寻找拥有相同属性事件序列的模式。从现在开始,我们把这些简单的模式称作 patterns, 把我们在数据流中最终寻找的复杂模式序列称作 pattern sequence,你可以把模式序列看作是这样的模式构成的图, 这些模式基于用户指定的条件从一个转换到另外一个。 一个 match 是输入事件的一个序列,这些事件通过一系列有效的模式转换,能够访问到复杂模式图中的所有模式。
每个模式必须有一个独一无二的名字,你可以在后面使用它来识别匹配到的事件。
模式的名字不能包含字符
":"。
单个模式
一个 patterns 可以是一个单例或者循环模式。单例模式只接受一个事件,循环模式可以接受多个事件。 在模式匹配表达式中,模式"a b+ c? d", a,c?,和 d 都是单例模式,b+ 是一个循环模式。默认情况下,模式都是单例的,你可以通过使用量词把它们转换成循环模式。 每个模式可以有一个或者多个条件来决定它接受哪些事件。
量词
在 FlinkCEP 中,你可以通过这些方法指定循环模式:
| 方法 | 描述 | 解释 |
|---|---|---|
| oneOrMore() | 指定模式期望匹配到的事件至少出现一次 | 默认(在子事件间)使用松散的内部连续性。 关于内部连续性的更多信息可以参考连续性 |
times(#ofTimes) |
指定期望一个给定事件出现特定次数的模式 | start.times(4) 期望出现4次 |
timesOrMore(#times) |
指定模式期望匹配到的事件至少出现 times 次 | |
times(#fromTimes, #toTimes) |
指定期望一个给定事件出现次数在一个最小值和最大值中间的模式 | start.times(2, 4) 期望出现2、3或者4次 |
| greedy() | 让循环模式变成贪心的 | start.times(2, 4).greedy() 期望出现2、3或者4次,并且尽可能的重复次数多 |
| optional() | 让指定的模式变成可选的(可以不被匹配),不管是否是循环模式 | start.times(4).optional() 期望出现0或者4次 |
条件
对每个模式你可以指定一个条件来决定一个进来的事件是否被接受进入这个模式。 指定判断事件属性的条件可以通过下表方法。 这些可以是 IterativeCondition 或者 SimpleCondition。
| 方法 | 描述 | 解释 |
|---|---|---|
pattern.where() |
为当前模式定义一个条件。为了匹配这个模式,一个事件必须满足某些条件。 多个连续的where()语句取与组成判断条件 | |
pattern.or() |
增加一个新的判断,和当前的判断取或。一个事件只要满足至少一个判断条件就匹配到模式 | |
pattern.until() |
为循环模式指定一个停止条件。意思是满足了给定的条件的事件出现后,就不会再有事件被接受进入模式了 | 只适用于和 oneOrMore() 同时使用。在基于事件的条件中,它可用于清理对应模式的状态。 |
迭代条件
这是最普遍的条件类型。使用它可以获取当前事件,也可以根据上下文获取某个状态下对应的事件集合。通过上述事件代表的条件来决定是否接受时间序列的条件。
middle.oneOrMore()
.subtype(SubEvent.class)
.where(new IterativeCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value, Context<SubEvent> ctx) throws Exception {
// 根据当前事件作出判断
if (!value.getName().startsWith("foo")) {
return false;
}
double sum = value.getPrice();
// 根据 middle 状态对应的事件集合来作出判断
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.getPrice();
}
return Double.compare(sum, 5.0) < 0;
}
});调用
ctx.getEventsForPattern(...)可以获得所有前面已经接受作为可能匹配的事件。 调用这个操作的代价可能很小也可能很大,所以在实现你的条件时,尽量少使用它。
描述的上下文提供了获取事件时间属性的方法。更多细节可以看时间上下文。
简单条件
这种类型的条件扩展了前面提到的 IterativeCondition 类,它决定是否接受一个事件只取决于事件自身的属性。
start.subtype(SubEvent.class)
.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return value.getName().startsWith("foo");
}
});最后,你可以通过 pattern.subtype(subClass) 方法限制接受的事件类型是初始事件的子类型。
组合条件
你可以把 subtype 条件和其他的条件结合起来使用。这适用于任何条件,你可以通过依次调用 where() 来组合条件。 最终的结果是每个单一条件的结果的逻辑 AND。如果想使用 OR 来组合条件,你可以像下面这样使用 or() 方法。
pattern.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ...; // 一些判断条件
}
}).or(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ...; // 一些判断条件
}
});停止条件
如果使用循环模式(oneOrMore() 和 oneOrMore().optional()),你可以指定一个停止条件,例如,接受事件的值大于 5 直到值的和小于 50。
为了更好的理解它,看下面的例子。给定
模式如
"(a+ until b)"(一个或者更多的"a"直到"b")到来的事件序列
"a1" "c" "a2" "b" "a3"输出结果会是:
{a1 a2} {a1} {a2} {a3}.
你可以看到{a1 a2 a3}和{a2 a3}由于停止条件没有被输出。
组合模式
组合模式是将单个模式连接起来组成一个完整的模式序列。
模式序列由一个初始模式作为开头,如下所示:
Pattern<Event, ?> start = Pattern.<Event>begin("start");接下来,你可以增加更多的模式到模式序列中并指定它们之间所需的连续条件。FlinkCEP 支持事件之间如下形式的连续策略:
- 严格连续: 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。
- 松散连续: 忽略匹配的事件之间的不匹配的事件。
- 不确定的松散连续: 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。
可以使用下面的方法来指定模式之间的连续策略:
next(),指定严格连续,匹配的事件必须直接跟在前面匹配到的事件后面followedBy(),指定松散连续,可以有其他事件出现在匹配的事件和之前匹配到的事件中间(松散连续)followedByAny(),指定不确定的松散连续,可以有其他事件出现在匹配的事件和之前匹配到的事件中间, 每个可选的匹配事件都会作为可选的匹配结果输出(不确定的松散连续)
或者
notNext(),增加一个新的否定模式。匹配的(否定)事件必须直接跟在前面匹配到的事件之后(严格连续)来丢弃这些部分匹配notFollowedBy(),增加一个新的否定模式。即使有其他事件在匹配的(否定)事件和之前匹配的事件之间发生, 部分匹配的事件序列也会被丢弃(松散连续)
模式序列不能以
notFollowedBy()结尾。一个 NOT 模式前面不能是可选的模式。
可以使用 within 定义一个有效时间约束,事件必须在指定时间完成。如果未完成的事件序列超过了这个事件,就会被丢弃。需要注意的是,一个模式序列只能有一个时间限制。如果限制了多个时间在不同的单个模式上,会使用最小的那个时间限制。
// 严格连续
Pattern<Event, ?> strict = start.next("middle").where(...);
// 松散连续
Pattern<Event, ?> relaxed = start.followedBy("middle").where(...);
// 不确定的松散连续
Pattern<Event, ?> nonDetermin = start.followedByAny("middle").where(...);
// 严格连续的NOT模式
Pattern<Event, ?> strictNot = start.notNext("not").where(...);
// 松散连续的NOT模式
Pattern<Event, ?> relaxedNot = start.notFollowedBy("not").where(...);松散连续意味着跟着的事件中,只有第一个可匹配的事件会被匹配上,而不确定的松散连接情况下,有着同样起始的多个匹配会被输出。 举例来说,模式"a b",给定事件序列 "a","c","b1","b2",会产生如下的结果:
"a"和"b"之间严格连续:{}(没有匹配),"a"之后的"c"导致"a"被丢弃。"a"和"b"之间松散连续:{a b1},松散连续会”跳过不匹配的事件直到匹配上的事件”。"a"和"b"之间不确定的松散连续:{a b1},{a b2},这是最常见的情况。
也可以为模式定义一个有效时间约束。 例如,你可以通过 pattern.within() 方法指定一个模式应该在 10 秒内发生。 这种时间模式支持处理时间和事件时间。
一个模式序列只能有一个时间限制。如果限制了多个时间在不同的单个模式上,会使用最小的那个时间限制。
循环模式中的连续性
你可以在循环模式中使用和前面章节讲过的同样的连续性。 连续性会被运用在被接受进入模式的事件之间。 用这个例子来说明上面所说的连续性,一个模式序列"a b+ c"("a"后面跟着一个或者多个(不确定连续的)"b",然后跟着一个"c") 输入为"a","b1","d1","b2","d2","b3","c",输出结果如下:
- 严格连续:
{a b1 c},{a b2 c},{a b3 c}- 没有相邻的"b"。 - 松散连续:
{a b1 c},{a b1 b2 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c}-"d"都被忽略了。 - 不确定松散连续:
{a b1 c},{a b1 b2 c},{a b1 b3 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c}- 注意{a b1 b3 c},这是因为"b"之间是不确定松散连续产生的。
对于循环模式(例如 oneOrMore() 和 times())),默认是松散连续。如果想使用严格连续,你需要使用 consecutive() 方法明确指定, 如果想使用不确定松散连续,你可以使用 allowCombinations() 方法。
匹配后跳过策略
对于一个给定的模式,同一个事件可能会分配到多个成功的匹配上。为了控制一个事件会分配到多少个匹配上,你需要指定跳过策略AfterMatchSkipStrategy。 有五种跳过策略,如下:
- NO_SKIP: 每个成功的匹配都会被输出。
- SKIP_TO_NEXT: 丢弃以相同事件开始的所有部分匹配。
- SKIP_PAST_LAST_EVENT: 丢弃起始在这个匹配的开始和结束之间的所有部分匹配。
- SKIP_TO_FIRST: 丢弃起始在这个匹配的开始和第一个出现的名称为 PatternName 事件之间的所有部分匹配。
- SKIP_TO_LAST: 丢弃起始在这个匹配的开始和最后一个出现的名称为 PatternName 事件之间的所有部分匹配。
注意当使用 SKIP_TO_FIRST 和 SKIP_TO_LAST 策略时,需要指定一个合法的 PatternName。
例如,给定一个模式 b+ c 和一个数据流 b1 b2 b3 c,不同跳过策略之间的不同如下:
| 跳过策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | b1 b2 b3 cb2 b3 cb3 c |
找到匹配b1 b2 b3 c之后,不会丢弃任何结果。 |
| SKIP_TO_NEXT | b1 b2 b3 cb2 b3 cb3 c |
找到匹配b1 b2 b3 c之后,不会丢弃任何结果,因为没有以b1开始的其他匹配 |
| SKIP_PAST_LAST_EVENT | b1 b2 b3 c |
找到匹配b1 b2 b3 c之后,会丢弃其他所有的部分匹配 |
| SKIP_TO_FIRST | b1 b2 b3 cb2 b3 cb3 c |
找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b1之前开始的部分匹配,但没有这样的匹配,所以没有任何匹配被丢弃 |
| SKIP_TO_LAST | b1 b2 b3 cb3 c |
找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b3之前开始的部分匹配,有一个这样的b2 b3 c被丢弃。 |
再看另外一个例子来说明 NO_SKIP 和 SKIP_TO_FIRST 之间的差别: 模式: (a | b | c) (b | c) c+.greedy d,输入:a b c1 c2 c3 d,结果将会是:
| 跳过策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | a b c1 c2 c3 d b c1 c2 c3 d c1 c2 c3 d |
找到匹配a b c1 c2 c3 d之后,不会丢弃任何结果 |
| SKIP_TO_FIRST | a b c1 c2 c3 d c1 c2 c3 d |
找到匹配a b c1 c2 c3 d之后,会丢弃所有在c1之前开始的部分匹配,有一个这样的b c1 c2 c3 d被丢弃 |
为了更好的理解 NO_SKIP 和 SKIP_TO_NEXT 之间的差别,看下面的例子: 模式:a b+,输入:a b1 b2 b3,结果将会是:
| 跳过策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | a b1 a b1 b2a b1 b2 b3 |
找到匹配a b1之后,不会丢弃任何结果 |
| SKIP_TO_NEXT | a b1 |
找到匹配a b1之后,会丢弃所有以a开始的部分匹配。这意味着不会产生a b1 b2和a b1 b2 b3了 |
想指定要使用的跳过策略,只需要调用下面的方法创建 AfterMatchSkipStrategy:
| 方法 | 描述 |
|---|---|
AfterMatchSkipStrategy.noSkip() |
创建 NO_SKIP 策略 |
AfterMatchSkipStrategy.skipToNext() |
创建 SKIP_TO_NEXT 策略 |
AfterMatchSkipStrategy.skipPastLastEvent() |
创建 SKIP_PAST_LAST_EVENT 策略 |
AfterMatchSkipStrategy.skipToFirst(patternName) |
创建引用模式名称为 patternName 的 SKIP_TO_FIRST 策略 |
AfterMatchSkipStrategy.skipToLast(patternName) |
创建引用模式名称为patternName的 SKIP_TO_LAST 策略 |
可以通过调用下面方法将跳过策略应用到模式上:
AfterMatchSkipStrategy skipStrategy = ...;
Pattern.begin("patternName", skipStrategy);使用 SKIP_TO_FIRST/LAST 时,有两个选项可以用来处理没有事件可以映射到对应的变量名上的情况。 默认情况下会使用 NO_SKIP 策略,另外一个选项是抛出异常。 可以使用如下的选项:
AfterMatchSkipStrategy.skipToFirst(patternName).throwExceptionOnMiss();检测模式
在指定了要寻找的模式后,该把它们应用到输入流上来发现可能的匹配了。为了在事件流上运行你的模式,需要创建一个 PatternStream。 给定一个输入流 input,一个模式 pattern 和一个可选的用来对使用事件时间时有同样时间戳或者同时到达的事件进行排序的比较器 comparator, 你可以通过调用如下方法来创建 PatternStream:
DataStream<Event> input = ...;
Pattern<Event, ?> pattern = ...;
EventComparator<Event> comparator = ...; // 可选的
PatternStream<Event> patternStream = CEP.pattern(input, pattern, comparator);输入流根据你的使用场景可以是 keyed 或者 non-keyed。
在 non-keyed 流上使用模式将会使你的作业并发度被设为1。
从模式中选取
在获得到一个 PatternStream 之后,你可以应用各种转换来发现事件序列。推荐使用 PatternProcessFunction。
PatternProcessFunction 有一个 processMatch 的方法在每找到一个匹配的事件序列时都会被调用。 它按照 Map<String, List<IN>> 的格式接收一个匹配,映射的键是你的模式序列中的每个模式的名称,值是被接受的事件列表(IN 是输入事件的类型)。 模式的输入事件按照时间戳进行排序。为每个模式返回一个接受的事件列表的原因是当使用循环模式(比如 oneToMany() 和 times() )时, 对一个模式会有不止一个事件被接受。
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT> out) throws Exception;
IN startEvent = match.get("start").get(0);
IN endEvent = match.get("end").get(0);
out.collect(OUT(startEvent, endEvent));
}
}PatternProcessFunction 可以访问 Context 对象。有了它之后,你可以访问时间属性,比如 currentProcessingTime 或者当前匹配的 timestamp (最新分配到匹配上的事件的时间戳)。 更多信息可以看时间上下文。 通过这个上下文也可以将结果输出到侧输出.
处理超时的部分匹配
当一个模式上通过 within 加上窗口长度后,部分匹配的事件序列就可能因为超过窗口长度而被丢弃。可以使用 TimedOutPartialMatchHandler 接口来处理超时的部分匹配。这个接口可以和其它的混合使用。也就是说你可以在自己的 PatternProcessFunction 里另外实现这个接口。
TimedOutPartialMatchHandler 提供了另外的 processTimedOutMatch 方法,这个方法对每个超时的部分匹配都会调用。
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT> implements TimedOutPartialMatchHandler<IN> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT> out) throws Exception;
...
}
@Override
public void processTimedOutMatch(Map<String, List<IN>> match, Context ctx) throws Exception;
IN startEvent = match.get("start").get(0);
ctx.output(outputTag, T(startEvent));
}
}
processTimedOutMatch不能访问主输出。 但你可以通过Context对象把结果输出到侧输出。
按照事件时间处理迟到事件
在 CEP 中,事件的处理顺序很重要。在使用事件时间时,为了保证事件按照正确的顺序被处理,一个事件到来后会先被放到一个缓冲区中, 在缓冲区里事件都按照时间戳从小到大排序,当水位线到达后,缓冲区中所有小于水位线的事件被处理。这意味着水位线之间的数据都按照时间戳被顺序处理。
这个库假定按照事件时间时水位线一定是正确的。
为了保证跨水位线的事件按照事件时间处理,Flink CEP 库假定水位线一定是正确的,并且把时间戳小于最新水位线的事件看作是晚到的。 晚到的事件不会被处理。你也可以指定一个侧输出标志来收集比最新水位线晚到的事件。
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
OutputTag<String> lateDataOutputTag = new OutputTag<String>("late-data"){};
SingleOutputStreamOperator<ComplexEvent> result = patternStream
.sideOutputLateData(lateDataOutputTag)
.select(
new PatternSelectFunction<Event, ComplexEvent>() {...}
);
DataStream<String> lateData = result.getSideOutput(lateDataOutputTag);