LangChain 是一个用于开发由语言模型支持的应用程序的框架。它支持以下应用程序:
- Data-aware:将语言模型连接到其他数据源
- Agentic:允许语言模型与其环境交互
LangChain 的主要价值有:
- Components:用于处理语言模型的抽象,以及每个抽象的实现集合。
- Off-the-shelf chains:用于完成特定更高级别任务的组件的结构化组装
LangChain
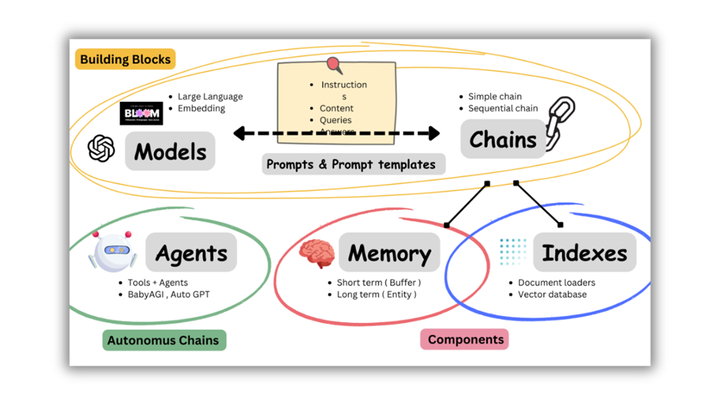
LangChain 提供了各种不同的组件帮助使用 LLM,如下图所示,核心组件有 Models、Indexes、Chains、Memory 以及 Agent。
模型 Models
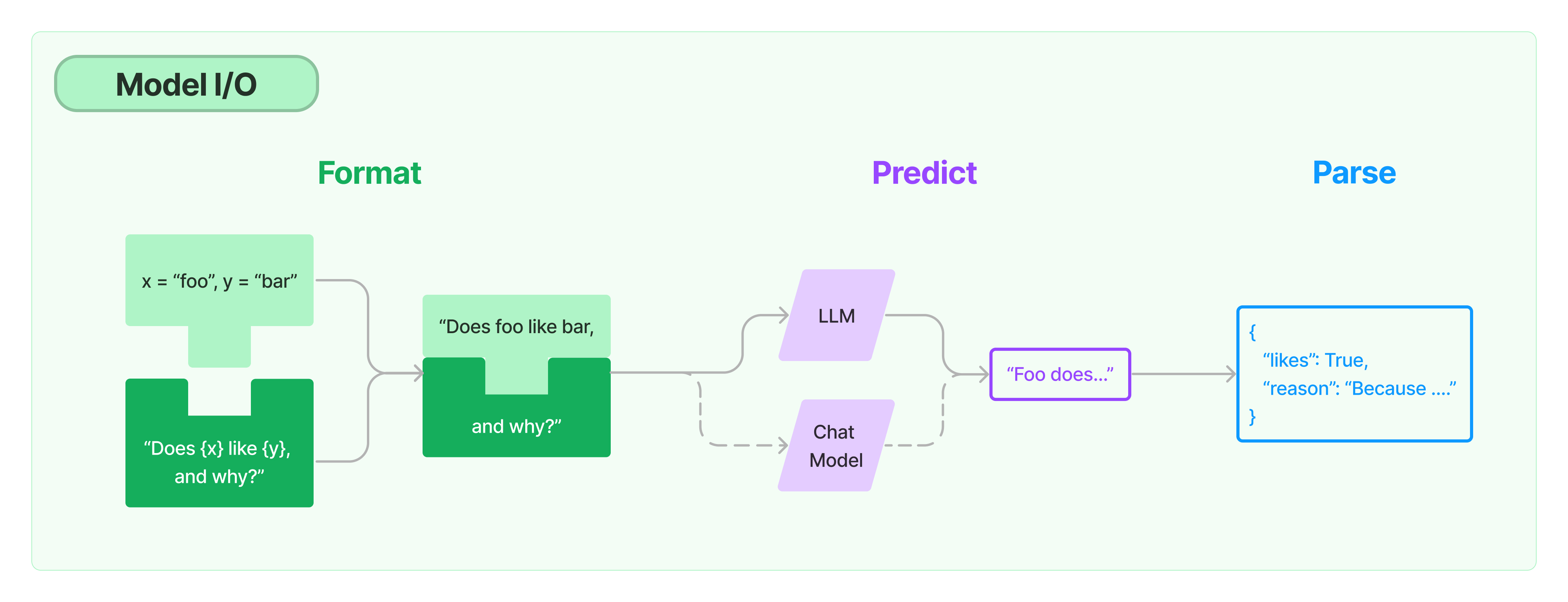
LangChain 本身不提供 LLM,仅提供了连接任何语言模型的通用接口。主要由以下三部分组成
- 提示 Prompt: 模板化、动态选择和管理模型输入
- 语言模型 Language Models: 通过通用接口调用语言模型
- 输出分析器 Output Parser: 从模型输出中提取信息
提示 Prompts
编程模型是通过提示 Prompt。提示 Prompt 指的是模型的输入,输入通常由多个部分构成。
- 提示模版 Prompt Templates:参数化模型输入
- 示例选择器 Example Selectors:动态选择要包含在提示中的示例
语言模型 Language Models
LangChain 提供了两种类型模型的抽象和实现。
- LLMS:输入输出都为文本的语言模型
- Chat Models:输入输出都为聊天信息 Chat Message 的语言模型
LLMS 和 Chat Models 的区别
LLMs(Language Model)和 Chat Models(聊天模型)在细微但重要的方面有所不同。LangChain 中的 LLMs 指的是纯文本补全模型。它们包装的 API 接受一个字符串提示作为输入,并输出一个字符串补全结果。OpenAI 的 GPT-3 就是一个 LLM 实现。Chat Models 通常基于 LLMs,但专门用于进行对话,并且它们的提供者 API 公开了与纯文本补全模型不同的接口。它们接受的不是单个字符串,而是一个包含对话消息的列表作为输入。通常,这些消息会标记说话者(通常是”System”、”AI”和”Human”之一)。然后它们会返回一个(”AI”)聊天消息作为输出。GPT-4 和 Anthropic 的 Claude 都是作为 Chat Models 实现的。
为了能够交换 LLMs 和 Chat Models,两者都实现了 Base Language Model 接口。该接口提供了共同的方法”predict”,它接受一个字符串并返回一个字符串,以及”predict messages”方法,它接受消息并返回一个消息。如果您正在使用特定的模型,建议使用该模型类的特定方法(即 LLMs 使用 “predict”,Chat Models 使用 “predict messages”),但如果您正在创建一个可以与不同类型的模型一起使用的应用程序,共享的接口可能会很有帮助。
LLMS
Large Language Models (LLMs) 是 LangChain 的核心组件。LangChain 并没有自己的 LLMs 实现,而是为 LLMs 们提供了标准的接口。
from langchain.llms import OpenAI
# openai_api_key 也可以放到环境变量里自动加载
llm = OpenAI(openai_api_key="...")
# 单次调用
llm("Tell me a joke")
# 批次调用
llm.generate(["Tell me a joke", "Tell me a poem"]*15)Chat Models
Chat Model 是 Large Language Model 的变体。虽然聊天模型在底层使用语言模型,但它们的界面有点不同。它们不是公开“文本输入、文本输出”API,而是公开一个接口,其中“聊天消息”是输入和输出。
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI()
# 单次调用
chat([HumanMessage(content="Translate this sentence from English to French: I love programming.")])
# 批次调用
batch_messages = [
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love programming.")
],
[
SystemMessage(content="You are a helpful assistant that translates English to French."),
HumanMessage(content="I love artificial intelligence.")
],
]
result = chat.generate(batch_messages)Caching
LangChain 为 Chat Model 提供了一个可选的缓存层。它会缓存询问的问题以及 LLM 给出的回答,当再次访问时,回答缓存的内容。
import langchain
from langchain.chat_models import ChatOpenAI
from langchain.cache import InMemoryCache
llm = ChatOpenAI()
langchain.llm_cache = InMemoryCache()
# The first time, it is not yet in cache, so it should take longer
llm.predict("Tell me a joke")CPU times: user 35.9 ms, sys: 28.6 ms, total: 64.6 ms
Wall time: 4.83 s
"\n\nWhy couldn't the bicycle stand up by itself? It was...two tired!"# The second time it is, so it goes faster
llm.predict("Tell me a joke")CPU times: user 238 µs, sys: 143 µs, total: 381 µs
Wall time: 1.76 ms
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'除了内存缓存,也提供了 SQLite 的方式
# We can do the same thing with a SQLite cache
from langchain.cache import SQLiteCache
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")Streaming
有一些语言模型提供了流式响应能力,即无需等待完整响应返回即可接收到部分内容。
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
HumanMessage,
)
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()], temperature=0)
resp = chat([HumanMessage(content="Write me a song about sparkling water.")])输出分析器 Output Parser
Output Parser 可以帮助结构化 LLM 的输出。
LangChain 提供了多种实现,也支持自定义:
- List Parser
- DateTime Parser
- Enum Parser
- Auto-fixing Parser
- Pydantic(JSON)Parser
- Retry Parser
- Structured Output Parser
多种实现详见 [LangChain] Models I/O - Output Parser
数据连接 Data Connection
许多 LLM 应用需要用户特定的数据,这些数据不属于模型的训练集。
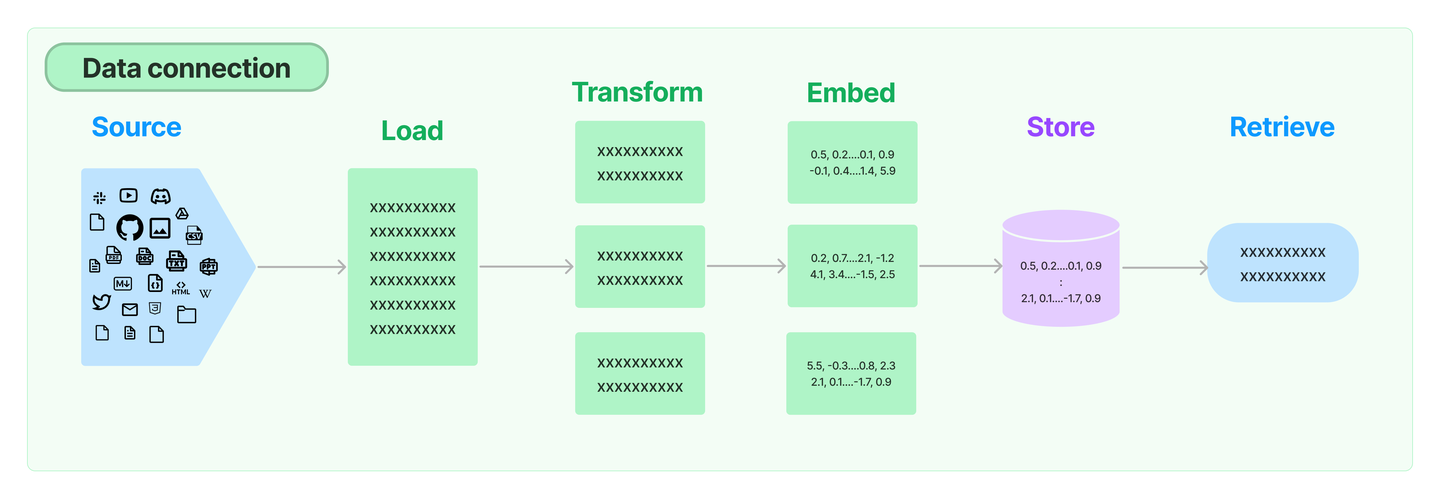
LangChain 通过以下方式为你提供了加载、转换、存储和查询数据的构建模块:
- 通过 Document Loaders 加载各种不同来源的数据源
- 通过 Document Transformers 进行文档内容的数据转换(如:Text Splitters 进行文本语义分割)
- 通过 Text Embedding Models 将非结构化文本转为 Vectors
- 通过 Vectorstore 进行非结构化数据的向量存储
- 通过 Retriever 进行文档数据检索
依赖包
pip install langchain
pip install unstructured
pip install jq文档加载器 Document Loaders
将不同类型的文档格式转为统一的 Document 领域对象,并提供了多种实现。大致分为以下几类:
- 文件加载器 File Loader
- 目录加载器 Directory
- Web加载器 WebLoader
多种实现详见 [LangChain] Document Loader
Document 类型主要包含两个属性:page_content 包含该文档的内容,meta_data 为文档相关的描述性数据,类似文档所在的路径等。
文档转换器 Document Transformers
将通过 Document Loaders 加载的数据进行转换,变得适用于应用理解。
处理文档通常有下述步骤:
- 将文本切分成小的、具有语义意义的块 chunks(通常是句子)
- 将小的 chunks 组合成一个符合模型通用输入的标准 chunks
- 将标准 chunks 进行部分重叠,以保留文本的上下文结构
实现上述逻辑的叫做文本切分器 Text Splitter,其通常以两个维度进行自定义:
- 文本怎样切分
- 块大小如何测量
文本切分器大致可以分为以下几类:
- 字符切分器(仅按照字符进行分割)
- 代码切分器(允许通过不同的编程语法进行切分)
- MarkDown 切分器(切分 MarkDown 文本)
- Token 切分器(按照语言模型的限制来切分)
多种实现详见 [LangChain] DocumentTransform - Text Splitters
文本嵌入模型 Text Embedding Models
文本嵌入模型是输入一段文本并输出其的矢量表示。这意味着我们可以在向量空间中思考文本,并执行语义搜索之类的操作,在向量空间中查找最相似的文本片段。
LangChain 中的 Embeddings 类是设计用于与文本嵌入模型交互的类。有很多嵌入模型提供者(OpenAI、Cohere、Hugging Face 等)——此类旨在为所有提供者提供标准接口。Embeddings 基类公开了两种方法:一种用于嵌入文档,另一种用于嵌入查询。前者采用多个文本作为输入,而后者采用单个文本。将它们作为两种单独方法的原因是,某些嵌入提供程序对文档(要搜索的)与查询(搜索查询本身)有不同的嵌入方法。
多种实现详见 [LangChain] Text Embedding Models
向量检索 Retrievers
Retriever 是非结构化数据查询的通用接口,且不包含存储文档。
多种实现详见 [LangChain] Retrievers
向量存储 Vector Stores
向量存储 Vector Stores 是 向量检索 Retrievers 的扩展。在存储非结构化数据,通常会先 embedding 数据并存储生成的向量 vector。在查询时,先 embedding 非结构化查询文本并检索与嵌入查询“最相似”的嵌入向量。
多种实现详见 [LangChain] Vector Stores
链 Chains
复杂的程序需要将 LLMs 链接编排达到最大化的能力。例如:我们可以通过创建一个 Chain 获取用户的输入,并使用 PromptTemplate 结构化,然后将转化后的内容传递给 LLM。我们能构建更多复杂的 Chain 并通过一个 Chain 串联,或者与其他组件进行串联。
Chain
所有链的基类。
| 参数 | 解释 |
|---|---|
| verbose | 设置为 True 时,详细输出每个链的输入及输出 |
| memory | 通过定义 memory 可以实现跨链调用持久化数据,用法详见 《内存 Memory》 |
| callbacks | |
| tags |
基于 Documents 的链
LLM
LLMChain 包含 PromptTemplate、LLM 和 OutputParser。LLMChain 运行时会将传入的参数拼接到 PromptTemplate 上(Memory 中如果有有效的 KV 值也可以)形成 Prompt,然后将其传入 LLM 中并返回 LLM 的输出,并通过 OutputParser 让 LLM 结构化输出并进行结果解析。
其调用方式见 [LangChain] Chains - LLM
Router
RouterChain 是根据输入动态的选择下一个链,每条链处理特定类型的输入。
RouterChain 由两个组件组成:
- 路由器链本身,负责选择要调用的下一个链,主要有 2 种 RouterChain,其中 LLMRouterChain 通过 LLM 进行路由决策,EmbeddingRouterChain 通过向量搜索的方式进行路由决策。
- 目标链列表,路由器链可以路由到的子链。
from langchain.chains.router import MultiPromptChain
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
# 1. 定义不同的模版以及对应的描述
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{input}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{input}"""
prompt_infos = [
{
"name": "physics",
"description": "Good for answering questions about physics",
"prompt_template": physics_template,
},
{
"name": "math",
"description": "Good for answering math questions",
"prompt_template": math_template,
},
]
# 2. 指定路由链的多个目的地
llm = OpenAI()
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_template = p_info["prompt_template"]
prompt = PromptTemplate(template=prompt_template, input_variables=["input"])
chain = LLMChain(llm=llm, prompt=prompt)
destination_chains[name] = chain
default_chain = ConversationChain(llm=llm, output_key="text")LLMRouterChain
LLM Router 通过 LLM 来决定目标链。
一般通过如下步骤执行:
- 定义不同的模版以及对应的描述
- 指定路由链的目的地
- 使用LLM选择路由的目的地
- 具体执行路由
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import MULTI_PROMPT_ROUTER_TEMPLATE
# 3. 使用LLM选择路由的目的地
destinations = [f"{p['name']}: {p['description']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(destinations=destinations_str)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 4. 具体执行路由
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
print(chain.run("What is black body radiation?"))EmbeddingRouterChain
Embedding Router 使用嵌入和相似度来决定目标链。
一般通过如下步骤执行:
- 定义不同的模版以及对应的描述
- 指定路由链的目的地
- 根据 Embedding 的相似度比较决定目标链
- 具体执行路由
from langchain.chains.router.embedding_router import EmbeddingRouterChain
from langchain.embeddings import CohereEmbeddings
from langchain.vectorstores import Chroma
names_and_descriptions = [
("physics", ["for questions about physics"]),
("math", ["for questions about math"]),
]
router_chain = EmbeddingRouterChain.from_names_and_descriptions(
names_and_descriptions, Chroma, CohereEmbeddings(), routing_keys=["input"]
)
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)Sequential
Sequential 用于链式调用 LLM,且将上一个模型的输出当作下一个模型的输入。
Sequential 链有两种类型:
SimpleSequentialChain:顺序链的最简单形式,其中每个步骤都有一个单一的输入/输出,并且一个步骤的输出是下一步的输入。SequentialChain:更通用的顺序链形式,允许多个输入/输出。
Transformation
Transformation 是用于通用转换的链,input_variables 用于指定输入的变量, output_variables 用于指定输出的变量,transform 指定转换的函数。
from langchain import TransformChain
TransformChain(input_variables=["text"], output_variables["entities"], transform=func())链的工作模式
全部的链实现了一个通用接口:
class BaseCombineDocumentsChain(Chain, ABC):
"""Base interface for chains combining documents."""
@abstractmethod
def combine_docs(self, docs: List[Document], **kwargs: Any) -> Tuple[str, dict]:
"""Combine documents into a single string."""Stuff
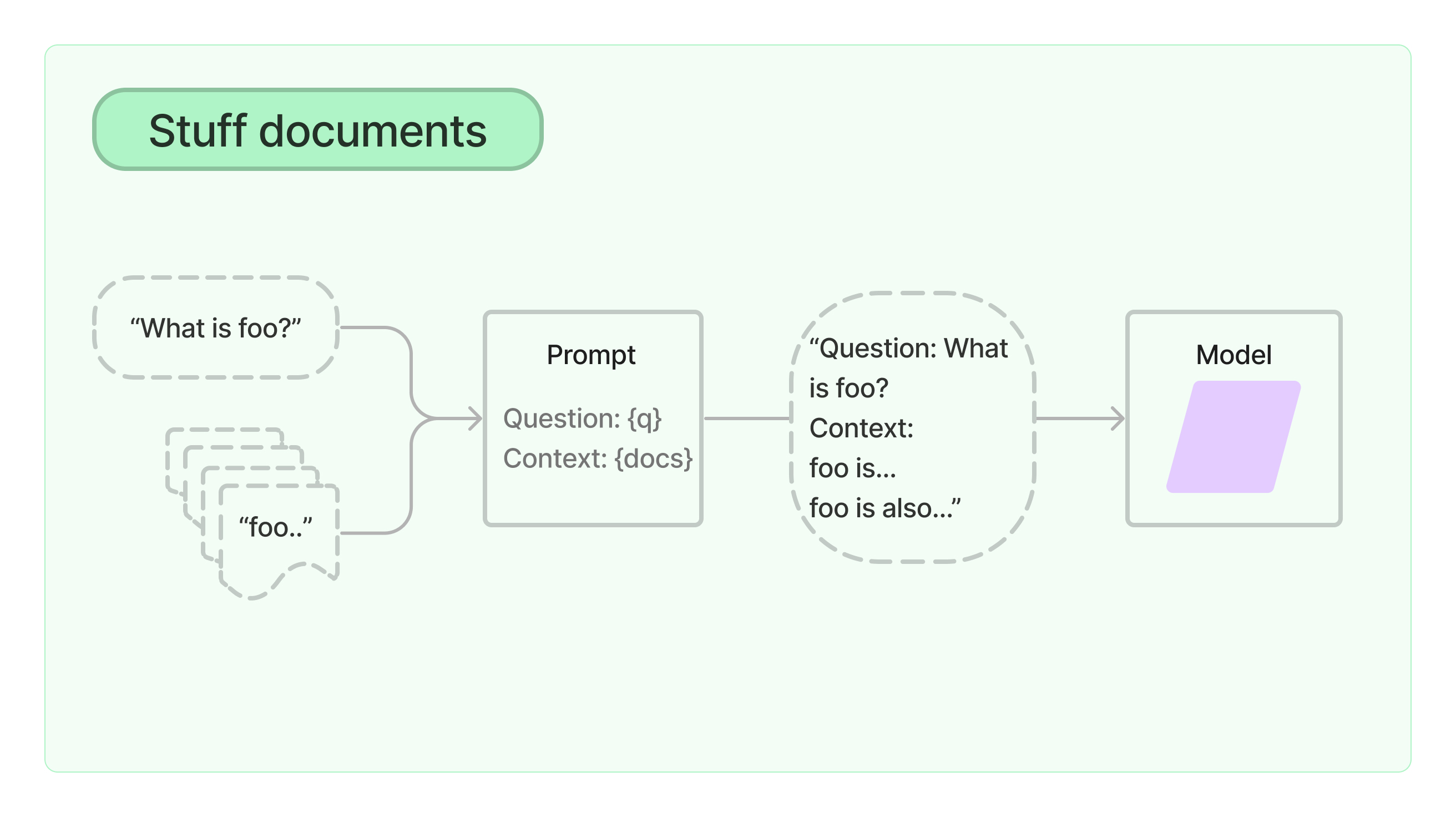
Stuff Documents Chain 也就是填充文档链,他将问题和相关的内容全部填充在 PromptTemplate 中,并且将 Prompt 传递给 LLM。
适用于小文档并且大多数调用只传少数文档。
Refine
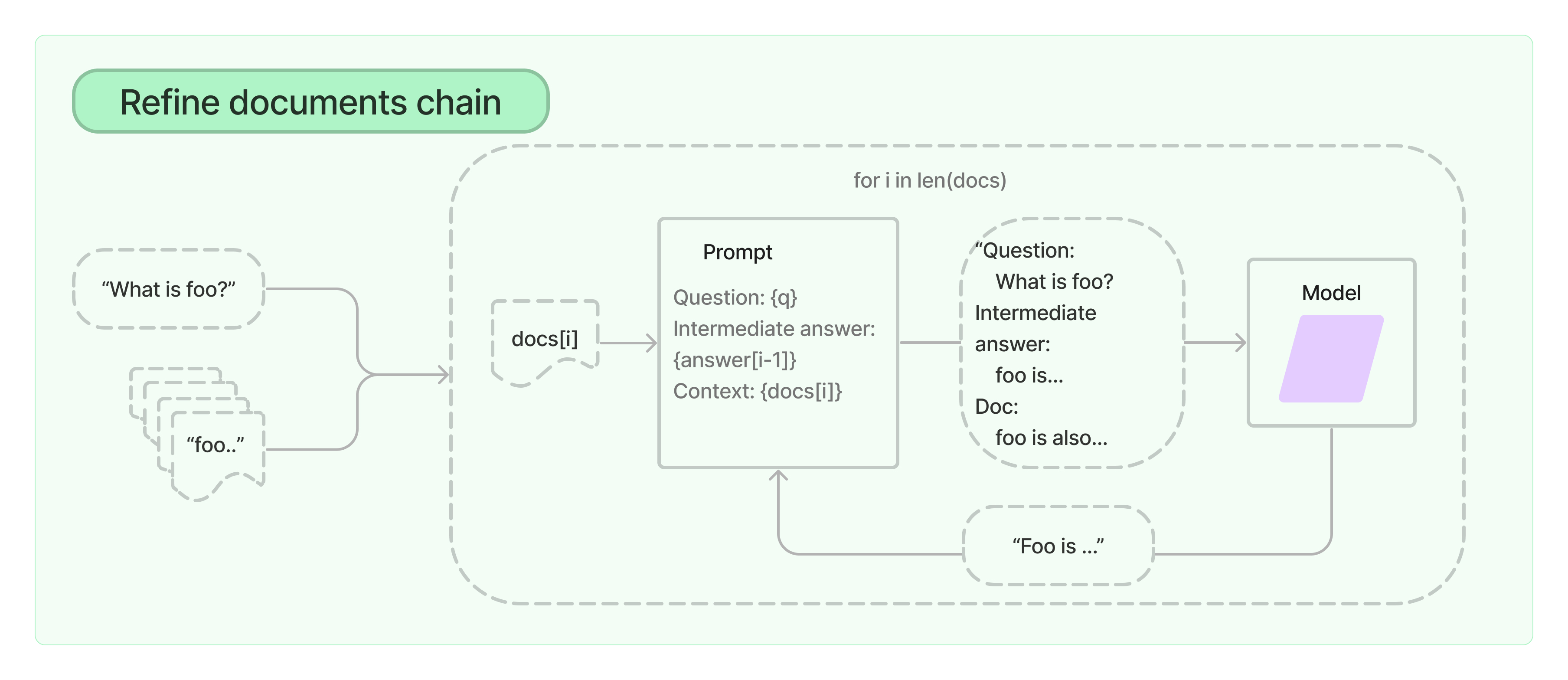
Refine Document Chain 通过循环输入文档并且迭代更新其结果。对于每个文档,它将所有非文档输入、当前文档和最新的中间答案传递给 LLM 链以获得新答案。
由于 Refine 链一次仅将单个文档传递给 LLM,因此它非常适合需要分析的文档数量多于模型上下文的任务。明显的权衡是,该链将比 Stuff 文档链进行更多的 LLM 调用。还有一些任务很难迭代完成。例如,当文档频繁相互交叉引用或一项任务需要来自许多文档的详细信息时,Refine 链可能会表现不佳。
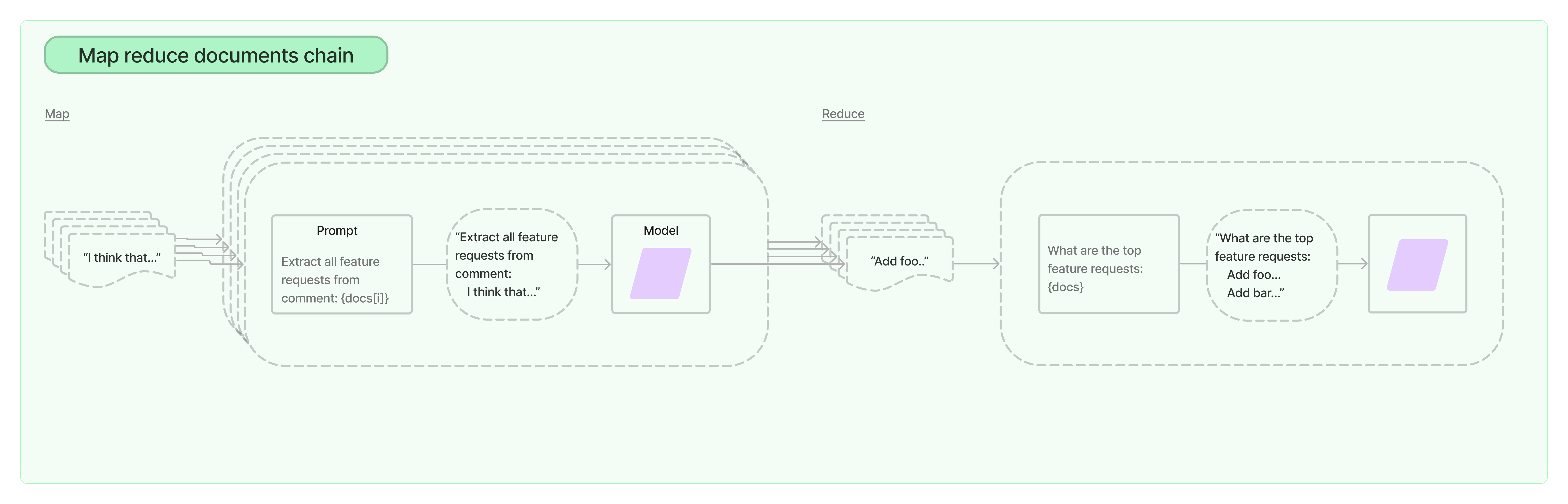
Map Reduce
MapReduce Documents Chain 首先将 LLM 链单独应用于每个文档(Map 步骤),将链输出视为新文档。然后,它将所有新文档传递到单独的组合文档链以获得单个输出(Reduce 步骤)。它可以选择首先压缩或折叠映射的文档,以确保它们适合组合文档链(这通常会将它们传递给 LLM)。如有必要,该压缩步骤会递归执行。
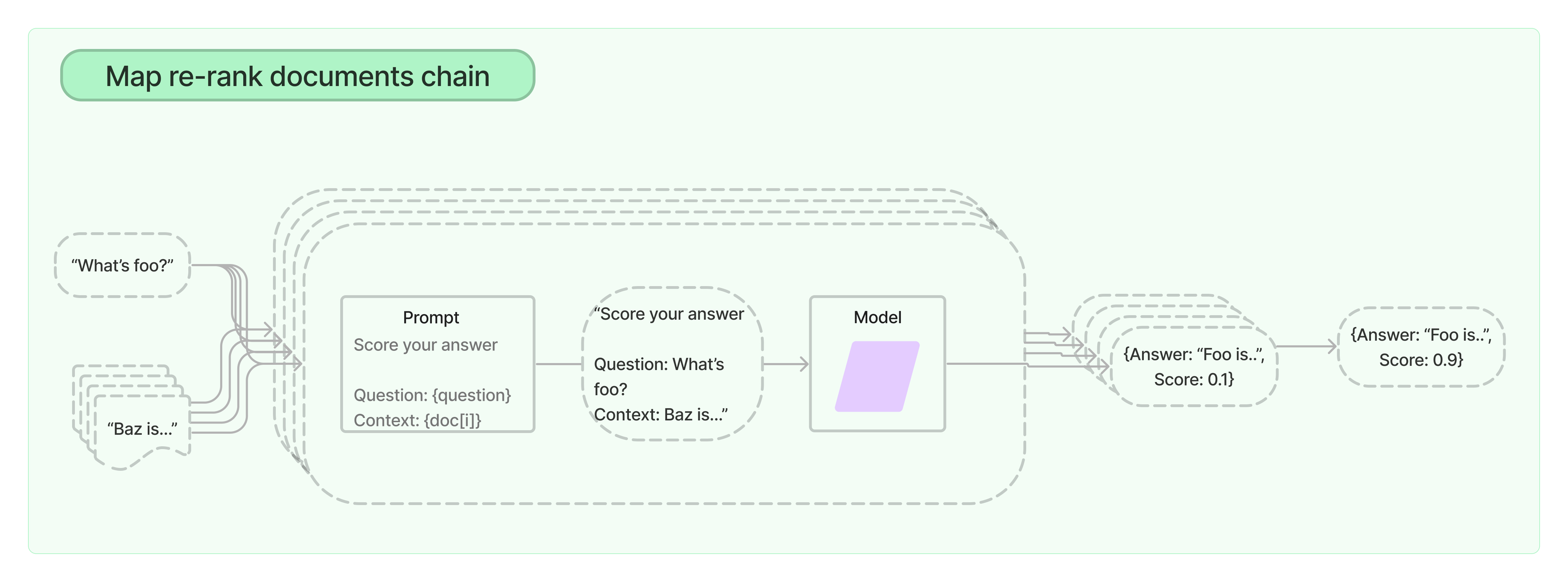
Map Re-rank
Map Re-rank Documents Chain 会对每个文档运行初始 Prompt,这不仅会尝试完成任务,还会对其答案的确定性进行评分,并返回得分最高的响应。
流行用法
API Chains
API 链主要是使用 LLM 与 API 进行交互。
Retrieval QA
Retrieval QA 是构建在索引上的问答模式。他可以设置不同的工作模式:Stuff、Refine、Map Reduce、Map Re-rank。
默认调用
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
loader = TextLoader("../../state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)自定义 Prompts
from langchain.prompts import PromptTemplate
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer in Italian:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), chain_type_kwargs=chain_type_kwargs)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)返回原文档
支持通过配置指定参数来返回关联的原文档。
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True)Conversational Retrieval QA
Conversational Retrieval QA 基于 Retrieval QA 构建。
SQL
使用SQLDatabaseChain回答有关 SQL 数据库的问题。
Summarization
摘要链可用于汇总多个文档。一种方法是输入多个较小的文档,将它们分为块后,并使用 MapReduceDocumentsChain 对它们进行操作。您还可以选择将进行汇总的链改为 StuffDocumentsChain 或 RefineDocumentsChain。
Using OpenAI functions
调用 OpenAI Function API 并合并到链中。
Additional
[LangChain] Chains - Additional
LangChainHub
通过 LangChainHub 加载 Chains。涉及的序列化相关见[LangChain] Serialization。
from langchain.chains import load_chain
chain = load_chain("lc://chains/llm-math/chain.json")
chain.run("whats 2 raised to .12")内存 Memory
正常情况下 Chain 无状态的,每次交互都是独立的,无法知道之前历史交互的信息。LangChain 使用 Memory 组件保存和管理历史消息,这样可以跨多轮进行对话,在当前会话中保留历史会话的上下文。Memory 组件支持多种存储介质,可以与 Monogo、Redis、SQLite 等进行集成,以及简单直接形式就是 Buffer Memory。常用的 Buffer Memory 有
- ConversationSummaryMemory :以摘要的信息保存记录
- ConversationBufferWindowMemory:以原始形式保存最新的 n 条记录
- ConversationBufferMemory:以原始形式保存所有记录
代理 Agents
某些应用程序需要根据用户输入对 LLM 和其他工具进行灵活的调用。Agents 接口为此类应用程序提供了灵活性。代理可以访问一套工具,并根据用户输入确定使用哪些工具。代理可以使用多种工具,并使用一个工具的输出作为下一个工具的输入。
代理主要有两种类型:
- Action agents:在每个时间步,使用所有先前动作的输出来决定下一个动作
- Plan-and-execute agents:预先决定完整的操作顺序,然后执行所有操作而不更新计划
Action agents 适合小型任务,而 Plan-and-execute agents 更适合需要维护长期目标和复杂的焦点或长期运行的任务。通常,最好的方法是通过让计划和执行代理使用行动代理来执行计划,将行动代理的活力与计划和执行代理的规划能力结合起来。
有关代理类型的完整列表,请参阅Agent types。代理涉及的其他抽象包括:
- Tools:LangChain 有许多内置的工具,也可以自定义工具。
- Toolkits:对可在特定用例中一起使用的工具集合的包装。例如,为了让代理与 SQL 数据库交互,它可能需要一个工具来执行查询,另一个工具来检查表。
Action Agents
一个高级的 Action Agents 的执行过程以下:
- 接收用户输入
- 决定使用哪个工具(如果有)以及工具输入
- 调用该工具并记录输出(也称为“观察”)
- 使用工具历史记录、工具输入和观察结果决定下一步
- 重复3-4,直到确定可以直接响应用户
操作代理被包装在 agents executors 中,代理执行器负责调用代理,获取操作和操作输入,使用生成的输入调用操作引用的工具,获取工具的输出,然后将所有信息传回进入代理以获取它应该采取的下一步行动。
尽管代理可以通过多种方式构建,但它通常涉及以下组件:
- 提示模板:负责获取用户输入和之前的步骤并构建发送到语言模型的提示
- 语言模型:接受使用输入和操作历史记录的提示,并决定下一步做什么
- 输出解析器:获取语言模型的输出并将其解析为下一个动作或最终答案
Plan-and-execute Agents
一个高级的 Plan-and-execute Agents 的执行过程以下:
- 接收用户输入
- 计划要采取的完整步骤顺序
- 按顺序执行步骤,将过去步骤的输出作为未来步骤的输入传递
最典型的实现是让规划器成为语言模型,执行器成为动作代理。
回调 Callbacks
LangChain 提供了一个回调系统,允许您连接到 LLM 申请的各个阶段。这对于日志记录、监控、流传输和其他任务非常有用。